CCNA Wireless 200-355 Official Cert Guide (2016)
Chapter 11. Understanding Controller Discovery
This chapter covers the following topics:
![]() Discovering a Controller—This section explains how a lightweight access point discovers and joins a wireless LAN controller.
Discovering a Controller—This section explains how a lightweight access point discovers and joins a wireless LAN controller.
![]() Designing High Availability—This section discusses what happens when a wireless LAN controller fails and APs need to find a new home. It also covers several common approaches to building networks with redundant controllers.
Designing High Availability—This section discusses what happens when a wireless LAN controller fails and APs need to find a new home. It also covers several common approaches to building networks with redundant controllers.
This chapter covers the following exam topics:
![]() 4.2—Describe the Cisco implementation of the CAPWAP discovery and join process
4.2—Describe the Cisco implementation of the CAPWAP discovery and join process
![]() 4.2a—DHCP
4.2a—DHCP
![]() 4.2b—DNS
4.2b—DNS
![]() 4.2c—Master-controller
4.2c—Master-controller
![]() 4.2d—Primary-secondary-tertiary
4.2d—Primary-secondary-tertiary
Cisco lightweight wireless access points need to be paired with a wireless LAN controller (WLC) to function. Each lightweight access point (LAP) must discover and bind itself with a controller before wireless clients can be supported. This chapter covers the discovery process in detail.
“Do I Know This Already?” Quiz
The “Do I Know This Already?” quiz allows you to assess whether you should read this entire chapter thoroughly or jump to the “Exam Preparation Tasks” section. If you are in doubt about your answers to these questions or your own assessment of your knowledge of the topics, read the entire chapter. Table 11-1 lists the major headings in this chapter and their corresponding “Do I Know This Already?” quiz questions. You can find the answers in Appendix A, “Answers to the ‘Do I Know This Already?’ Quizzes.”

Table 11-1 “Do I Know This Already?” Section-to-Question Mapping
Caution
The goal of self-assessment is to gauge your mastery of the topics in this chapter. If you do not know the answer to a question or are only partially sure of the answer, you should mark that question as wrong for purposes of the self-assessment. Giving yourself credit for an answer you correctly guess skews your self-assessment results and might provide you with a false sense of security.
1. Which one of the following comes first in an LAP’s state machine, after it boots?
a. Build a CAPWAP tunnel
b. Discover WLCs
c. Download a configuration
d. Join a WLC
2. If an LAP needs to download a new software image, how does it get the image?
a. From a TFTP server
b. From an FTP server
c. From a WLC
d. You must preconfigure it.
3. Which of the following are ways that an AP can learn of WLCs that it might join? (Choose all that apply.)
a. Primed entries
b. List from a previously joined controller
c. DHCP
d. Subnet broadcast
e. DNS
f. All of these
4. Which one of the following will an AP try first in order to select a controller to join?
a. Master controller
b. Least-loaded controller
c. Primed address
d. DHCP option 43
e. Wait for a controller to send a Join Request
5. If an AP tries every available method to discover a controller, but fails to do so, what happens next?
a. It broadcasts on every possible subnet.
b. It tries to contact the default controller at 10.0.0.1.
c. It reboots and starts discovering again.
d. It uses IP redirect on the local router.
6. You can configure the priority value on an AP to accomplish which one of the following?
a. To set the controller it will try to join first
b. To define which APs will be preferred when joining a controller
c. To set the SSID that will be advertised first
d. To identify the least-loaded controller to join
7. Which of the following is the most deterministic strategy you can use to push a specific AP to join a specific controller?
a. Select the least-loaded controller
b. Use DHCP option 43
c. Configure the master controller
d. Configure the primary controller
8. By default, which one of the following methods and intervals does an AP use to detect a failed controller?
a. ICMP, 60 seconds
b. ICMP, 30 seconds
c. CAPWAP keepalive, 60 seconds
d. CAPWAP keepalive, 30 seconds
e. CAPWAP discovery, 30 seconds
9. Suppose that an AP is joined to the WLC that is configured as the primary controller. At a later time, that controller fails and the AP joins its secondary controller. Once the primary controller is restored to service, which feature would allow the AP to rejoin it?
a. CAPWAP Rejoin
b. AP Failover
c. AP Priority
d. AP Fallback
10. A Cisco unified wireless network architecture consists of two controllers and a number of APs. The APs are distributed equally across the two controllers. Each AP is configured with one controller as primary and the other controller as secondary. Based on this information, which one of the following redundancy models is being used?
a. No redundancy
b. N+1 redundancy
c. N+N redundancy
d. N+N+1 redundancy
Foundation Topics
Discovering a Controller
Cisco LAPs are designed to be “touch free,” so that you can simply unbox a new one and connect it to the wired network, without any need to configure it first. Naturally, you have to configure the switch port, where the AP connects, with the correct access VLAN, access mode, and inline power settings. From that point on, the AP can power up and use a variety of methods to find a viable WLC to join.
AP States
From the time it powers up until it offers a fully functional basic service set (BSS), an LAP operates in a variety of states. Each of the possible states are well defined in the Control and Provisioning of Wireless Access Points (CAPWAP) RFC, but are simplified here for clarity. The AP enters each state in a specific order; the sequence of states is called a state machine. You should become familiar with the AP state machine so that you can understand how an AP forms a working relationship with a WLC. If an AP cannot form that relationship for some reason, your knowledge of the state machine can help you troubleshoot the problem.
Tip
CAPWAP is defined in RFC 5415, and in a few other RFCs. The terms used in the RFC differ somewhat from the ones used in a Cisco unified wireless network and this book. For example, access controller (AC) refers to a WLC, whereas wireless termination point (WTP) refers to an AP.
The sequence of the most common states, as shown in Figure 11-1, is as follows:
![]()
1.AP boots: Once an AP receives power, it boots on a small IOS image so that it can work through the remaining states and communicate over its network connection. The AP must also receive an IP address from either a Dynamic Host Configuration Protocol (DHCP) server or a static configuration so that it can communicate over the network.
2.WLC discovery: The AP goes through a series of steps to find one or more controllers that it might join. The steps are explained further in the next section.
3.CAPWAP tunnel: The AP attempts to build a CAPWAP tunnel with one or more controllers. The tunnel will provide a secure Datagram Transport Layer Security (DTLS) channel for subsequent AP-WLC control messages. The AP and WLC authenticate each other through an exchange of digital certificates.
4.WLC join: The AP selects a WLC from a list of candidates, and then sends a CAPWAP Join Request message to it. The WLC replies with a CAPWAP Join Response message. The next section explains how an AP selects a WLC to join.
5.Download image: The WLC informs the AP of its software release. If the AP’s own software is a different release, the AP will download a matching image from the controller, reboot to apply the new image, and then return to step 1. If the two are running identical releases, no download is needed.
6.Download config: The AP pulls configuration parameters down from the WLC and can update existing values with those sent from the controller. Settings include RF, service set identifier (SSID), security, and quality of service (QoS) parameters.
7.Run state: Once the AP is fully initialized, the WLC places it in the “run” state. The AP and WLC then begin providing a BSS and begin accepting wireless clients.
8.Reset: If an AP is reset by the WLC, it tears down existing client associations and any CAPWAP tunnels to WLCs. The AP then reboots and starts through the entire state machine again.
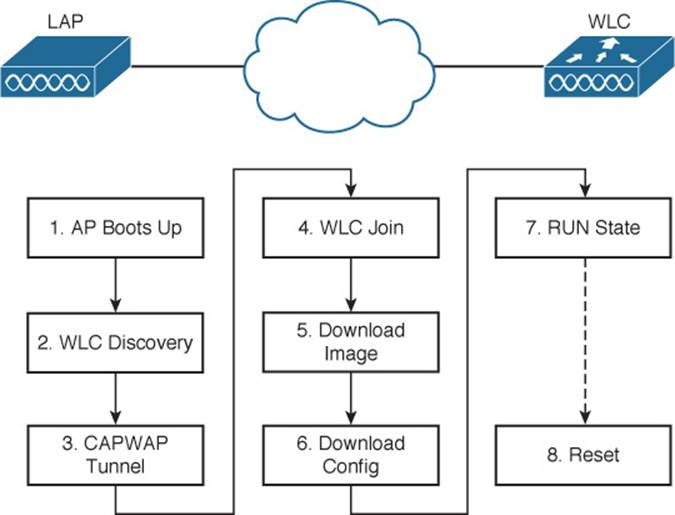
Figure 11-1 State Machine of an LAP
Be aware that you cannot control which software image release an LAP runs. Rather, the WLC that the AP joins determines the release, based on its own software version. Downloading a new image can take a considerable amount of time, especially if there are a large number of APs waiting for the same download from one WLC. That might not matter when a newly installed AP is booting and downloading code, because it does not yet have any wireless clients to support.
However, if an existing, live AP happens to reboot or join a different controller, clients can be left hanging with no AP while the image downloads. Some careful planning with your controllers and their software releases will pay off later by minimizing downtime. Consider the following scenarios when an AP might need to download a different release:
![]() The AP joins a WLC, but has a version mismatch.
The AP joins a WLC, but has a version mismatch.
![]() A code upgrade is performed on the WLC itself, requiring all associated APs to upgrade too.
A code upgrade is performed on the WLC itself, requiring all associated APs to upgrade too.
![]() The WLC fails, causing all associated APs to be dropped and join elsewhere.
The WLC fails, causing all associated APs to be dropped and join elsewhere.
If there is a chance that an AP could rehome from one WLC to another, you should make sure that both controllers are running the same code release. Otherwise, the AP move should happen under controlled circumstances, such as during a maintenance window. Fortunately, if you have downloaded a new code release to a controller, but not yet rebooted it to run the new code, you can predownload the new release to the controller’s APs. The APs will download the new image, but will keep running the previous release. When it comes time to reboot the controller on the new image, the APs will already have the new image staged without having to take time to download it. The APs can reboot on their new image and join the controller after it has booted and become stable.
Discovering a WLC
An LAP must be very diligent to discover any controllers that it can join—all without any preconfiguration on your part. To accomplish this feat, several methods of discovery are used. The goal of discovery is just to build a list of live candidate controllers that are available, using the following methods:
![]() Prior knowledge of WLCs
Prior knowledge of WLCs
![]() DHCP and DNS information to suggest some controllers
DHCP and DNS information to suggest some controllers
![]() Broadcast on the local subnet to solicit controllers
Broadcast on the local subnet to solicit controllers
To discover a WLC, an AP sends a unicast CAPWAP Discovery Request to a controller’s IP address over UDP port 5246 or a broadcast to the local subnet. If the controller exists and is working, it returns a CAPWAP Discovery Response to the AP. The sequence of discovery steps used is as follows:
![]()
Step 1.Broadcast on the local subnet—The AP will broadcast a CAPWAP Discovery Request on its local wired subnet. Any WLCs that also exist on the subnet will answer with a CAPWAP Discovery Response.
Tip
If the AP and controllers lie on different subnets, you can configure the local router to relay any broadcast requests on UDP port 5246 to specific controller addresses. Use the following configuration commands:
router(config)# ip forward-protocol udp 5246
router(config)# interface vlan n
router (config-int)# ip helper-address WLC1-MGMT-ADDR
router(config-int)# ip helper-address WLC2-MGMT-ADDR
Step 2.Use locally stored WLC addresses—An AP can be “primed” with up to three controllers—a primary, a secondary, and a tertiary. These are stored in nonvolatile memory so that the AP can remember them after a reboot or power failure. Otherwise, if an AP has previously joined with a controller, it should have stored up to 8 out of a list of 32 WLC addresses that it received from the last controller it joined. The AP will attempt to contact as many controllers as possible to build a list of candidates.
Step 3.Use DHCP—The DHCP server that supplies the AP with an IP address can also send DHCP option 43 to suggest a list of WLC addresses.
Step 4.Use DNS—The AP will attempt to resolve the name CISCO-CAPWAP-CONTROLLER.localdomain with a DNS request. The localdomain string is the domain name learned from DHCP. If the name resolves to an IP address, the controller attempts to contact a WLC at that address.
Step 5.Reset and try again—If none of the steps has been successful, the AP resets itself and starts the discovery process all over again.
Selecting a WLC
Once an AP has finished the discovery process, it should have built a list of live candidate controllers. Now it must begin a separate process to select one WLC and attempt to join it. Joining a WLC involves sending it a CAPWAP Join Request and waiting for it to return a CAPWAP Join Response. From that point on, the AP and WLC build a DTLS tunnel to secure their CAPWAP control messages.
The WLC selection process consists of the following three steps:
![]()
Step 1.Try primed addresses—If the AP has previously joined a controller and has been configured or “primed” with a primary, secondary, and tertiary controller, it will try to join those controllers in succession.
Step 2.Try the master controller—If the AP does not know of any candidate controller, it can try to discover one by broadcasting on the local subnet. If a controller has been configured as a master controller, it can respond to the AP’s broadcast.
Step 3.Try the least-loaded controller—The AP will attempt to join the least-loaded WLC, in an effort to load balance APs across a set of controllers. During the discovery phase, each controller reports its load—the ratio of the number of currently joined APs to the total AP capacity. The least-loaded WLC is the one with the lowest ratio. For example, suppose that a 5508 controller has 20 out of a possible 100 APs joined to it, while a 2504 controller has 20 out of a possible 25 APs. The 5508 would be the least loaded with a ratio of 20/100; the 2504 is more loaded with 20/25.
If an AP discovers a controller, but gets rejected when it tries to join it, what might be the reason? Every controller has a set maximum number of APs that it can support. This is defined by platform or by license. If the controller already has the maximum number of APs joined to it, it will reject any additional APs.
To provide some flexibility in supporting APs on an oversubscribed controller, where more APs are trying to join than a license allows, you can configure the APs with a priority value. All APs begin with a default priority of low. You can change the value to low, medium, high, or critical. A controller will try to accommodate as many higher-priority APs as possible. Once a controller is full of APs, it will reject an AP with the lowest priority to make room for a new one that has a higher priority.
Designing High Availability
Once an AP has discovered, selected, and joined a controller, it must stay joined to that controller to remain functional. Now consider that a single controller might support as many as 1000 or even 6000 APs—enough to cover a very large building or an entire enterprise. If something ever causes the controller to fail, a large number of APs would also fail. In the worst case, where a single controller carries the enterprise, the entire wireless network would become unavailable. That might be catastrophic.
Fortunately, a Cisco AP can discover multiple controllers—not just the one that it chooses to join. Figure 11-2 shows this scenario. If the joined controller becomes unavailable, the AP can simply select the next least-loaded controller and request to join it, as Figure 11-3 depicts. That sounds simple, but it is not very deterministic.
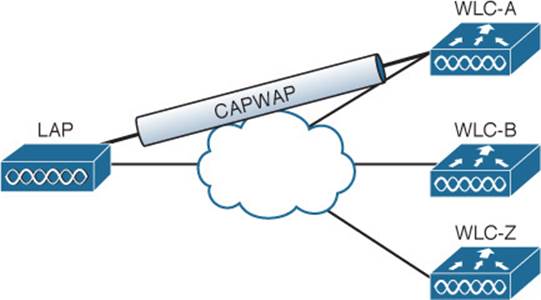
Figure 11-2 AP Joining One of Several Discovered Controllers
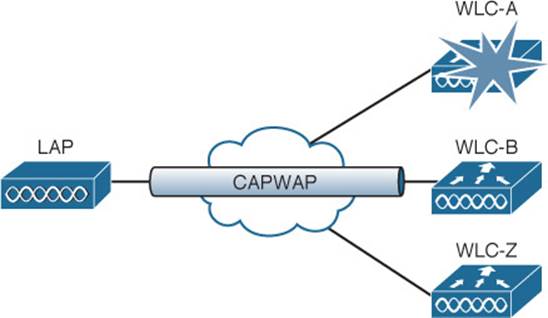
Figure 11-3 AP Joining a Different Controller After a Failure
For example, if a controller full of 1000 APs fails, all 1000 APs must detect the failure, discover other candidate controllers, and then select the least-loaded one to join. During that time, wireless clients can be left stranded with no connectivity. You might envision the controller failure as a commercial airline flight that has just been canceled; everyone that purchased a ticket suddenly joins a mad rush to find another flight out.
The most deterministic approach is to leverage the primary, secondary, and tertiary controller fields that every AP stores. If any of these fields are configured with a controller name or address, the AP knows which three controllers to try in sequence before resorting to a more generic search.
Tip
When an AP boots and builds a list of potential controllers, it can use CAPWAP to build a tunnel to more than one controller. The AP will join only one controller, which it uses as the primary unit. By building a tunnel with a second controller ahead of time, before the primary controller fails, the AP will not have to spend time building a tunnel to the backup controller before joining it.
As a wireless network grows, you might have several controllers implemented just to support the number of APs that are required. A good network design should also take failures and high availability (HA) into consideration. It is not enough just to have multiple controllers in a network. What if they are all in use and full of APs? There would not be enough room to spare for a large group of additional, displaced APs to join in their time of need. In the commercial flight analogy, there might be other flights departing the airport soon after the cancellation. If those flights are already mostly full of passengers, many people will be left waiting at the gate.
Figure 11-4 illustrates an example network that does not offer enough capacity to fully survive a controller failure. In the “Before” diagram, a group of 400 APs has joined controller WLC-A, and a group of 300 APs has joined WLC-B. Each controller has a maximum capacity of 500 APs. As long as both controllers stay up and functional, the wireless network should work fine. In the “After” diagram, WLC-A has failed. All 400 APs that were previously joined to WLC-A will discover that WLC-B is alive, so they will all try to join it. WLC-B already has 300 APs, so it has room for only 200 more. That means 200 APs will be able to join WLC-B and 200 more will be left out in the cold with no controller to join at all.
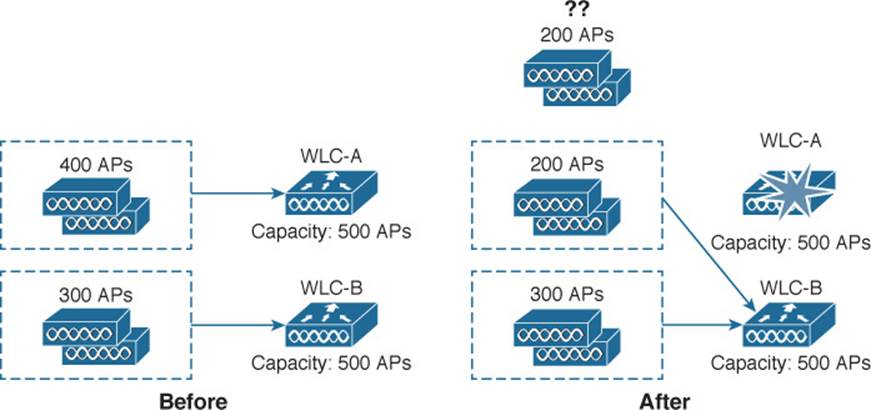
Figure 11-4 Result of Undersized Controllers During a Failure
Detecting a Controller Failure
When HA is required, make sure that you design your wireless network to support it properly. Fortunately, Cisco APs and controllers are built with HA in mind, so you have several strategies at your disposal. First, it is important to understand how APs detect a controller failure and what action they take to recover from it.
Once an AP joins a controller, it sends keepalive (also called heartbeat) messages to the controller over the wired network at regular intervals. By default, keepalives are sent every 30 seconds. The controller is expected to answer each keepalive as evidence that it is still alive and working. If a keepalive is not answered, an AP will escalate the test by sending four more keepalives at 3-second intervals. If the controller answers, all is well; if it does not answer, the AP presumes that the controller has failed. The AP then moves quickly to find a successor to join.
Using the default values, an AP can detect a controller failure in as little as 35 seconds. You can adjust the regular keepalive timer between 1 and 30 seconds and the escalated or “fast” heartbeat timer between 1 and 10 seconds. By using the minimum values, a failure can be detected after only 6 seconds.
Normally, an AP will stay joined to a controller until it fails. If the AP has been configured with primary and secondary controller information, it will join the primary controller first. If the primary fails, the AP will try to join the secondary until it fails. Even if the primary controller is put back into service, the AP will stay with the secondary. You can change that behavior by enabling the AP Fallback feature—a global controller configuration parameter. If AP Fallback is enabled (the default), an AP can try to rejoin its primary controller at any time, whether its current controller has failed or not.
Building Redundancy
Building a wireless network with one controller and some APs is straightforward, but it does not address what would happen if the controller fails for some reason. Adding another controller or two could provide some redundancy, as long as the APs know how to move from one controller to another when the time comes.
![]()
Redundancy is best configured in the most deterministic way possible. The following sections explain how you can configure APs with primary, secondary, and tertiary controller fields to implement various forms of redundancy. As you read through the sections, keep in mind that redundant controllers should be configured similarly so that APs can move from one controller to another without having to undergo any major configuration changes.
N+1 Redundancy
The simplest way to introduce HA into a Cisco unified wireless network is to provide an extra backup controller. This is commonly called N+1 or N:1 redundancy, where N represents some number of active controllers and 1 denotes the one backup controller.
By having one backup controller, N+1 redundancy can withstand a failure of only one active controller. As long as the backup controller is sized appropriately, it can accept all of a failed controller’s APs. However, once an active controller fails and all its APs rehome to the backup controller, there will be no space to accept any other APs if a second controller fails.
Figure 11-5 illustrates N+1 redundancy with a two-controller network for simplicity. The network could have any number of active controllers, but only one backup controller. WLC-A is the active controller and carries 100 percent of the network’s APs. WLC-Z is the backup controller, which normally carries no APs at all. The backup controller sits idle until an active controller fails.
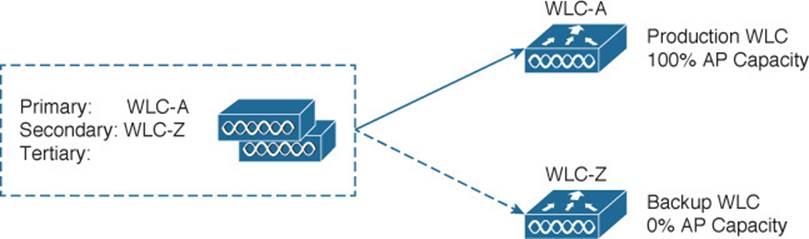
Figure 11-5 Configuring N+1 Controller Redundancy
To configure N+1 redundancy, you configure the primary controller field on all APs with the name of an active controller (WLC-A, for example). The secondary controller field is set to the name of the backup controller (WLC-Z).
N+N Redundancy
N+1 design is simple, but it has a couple of shortcomings. First, the backup controller must sit idle and empty of APs until another controller fails. That might not sound like a problem, except that the backup unit must be purchased with the same AP capacity as the active controller it supports. That means the active and backup controllers must be purchased at the same price. Having a full-price device sit empty and idle might seem like a poor use of funds.
Second, the backup controller must be configured identically to every other active controller it has to support. The idea is to make a controller failure as seamless as possible so the APs should not have any noticeable configuration differences when they move from one controller to another.
The N+N redundancy strategy tries to make better use of the available controllers. N+N gets its name from grouping controllers in pairs. If you have one active controller, you would pair it with one other controller; two controllers would be paired with two others, and so on. You might also see the same strategy called N:N or 1+1.
By grouping controllers in pairs, you can divide the active role across two separate devices. This makes better use of the AP capacity on each controller. As well, the APs, including their client loads, will be distributed across separate hardware, while still supporting redundancy during a failure. N+N redundancy can support failures of more than one controller, but only if the active controllers are configured in pairs.
Figure 11-6 illustrates the N+N scenario consisting of two controllers, WLC-A and WLC-B. The APs are divided into two groups—one that joins WLC-A as primary controller and another that joins WLC-B as primary. Notice that the primary and secondary controllers are reversed between the two groups of APs. To support the full set of APs during a failure, each controller must not be loaded with more than 50 percent of its AP capacity.
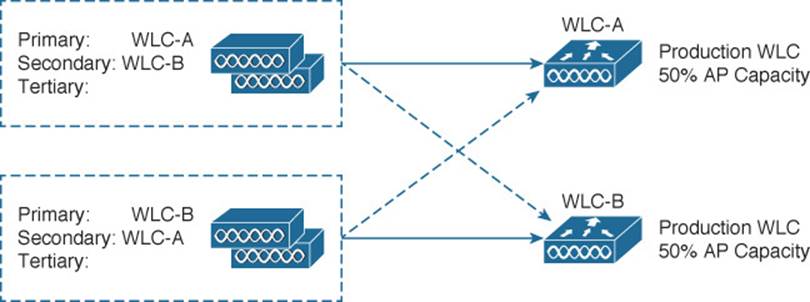
Figure 11-6 Configuring N+N Controller Redundancy
Rather than having an extra controller sitting idle waiting for another controller to die, N+N puts all of the controllers to use. However, it also requires more controllers and licenses than you actually need. N+N is an extremely reliable but extremely expensive solution.
N+N+1 Redundancy
What if a scenario calls for more resiliency than the N+N plan can provide? You can simply add one more controller to the mix, as a backup unit. As you might expect, this is commonly called N+N+1 redundancy and combines the advantages of the N+N and N+1 strategies.
Two or more active controllers are configured to share the AP and client load, while reserving some AP capacity for use during a failure. One additional backup controller is set aside as an additional safety net. Figure 11-7 shows a simple example using three controllers—two active (WLC-A and WLC-B) and one backup (WLC-Z). Like N+N redundancy, the two groups of APs are configured with primary and secondary controllers that are the reverse of each other. Each group of APs is also configured with a tertiary controller that points to the backup unit.
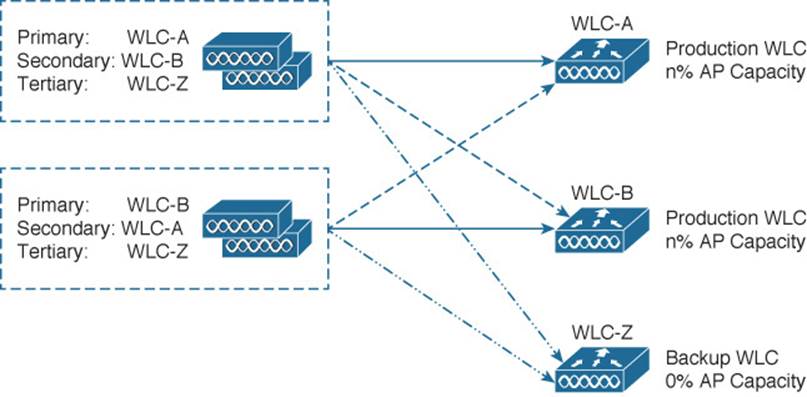
Figure 11-7 Configuring N+N+1 Controller Redundancy
If one active controller fails, APs that were joined to it will move to the secondary controller. As long as the two active controllers are not loaded with over 50 percent of their AP capacity, either one may accept the full number of APs. N+N+1 goes one step further; if the other active controller happens to fail, the backup controller is available to carry the load. This means that the active controllers can be loaded to more than 50 percent each because the backup controller will be available to share the load when an active controller fails.
SSO Redundancy
The N+1, N+N, and N+N+1 strategies all address redundancy and fault tolerance, but each still relies on the basic controller discovery and join processes. In other words, APs require a certain amount of time to seek out a new controller when they detect that one has failed.
With Controller Software Release 7.5 or later, Cisco offers AP and client stateful switchover (SSO) redundancy, in addition to the other methods. SSO groups controllers into HA pairs, where one controller takes on the active role while the other is in a hot standby mode. Only the active unit must be purchased with the appropriate license to support the AP count; the standby unit is purchased with an HA license. The standby unit can be paired with an active unit of any license size, as its AP licenses are not really used until it takes on the active role.
Figure 11-8 depicts SSO redundancy. The APs can be configured with only a primary controller name that references the active unit. Because each active controller has its own standby controller, there really is no need to configure a secondary or tertiary controller on the APs unless you need an additional layer of redundancy.
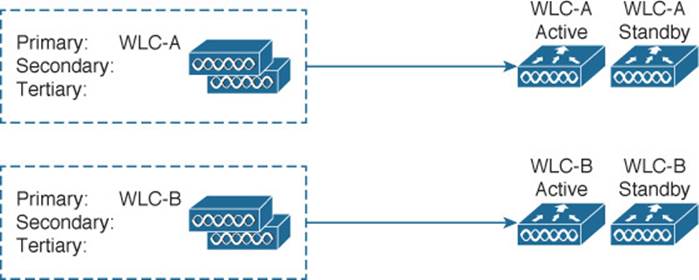
Figure 11-8 Configuring AP SSO Redundancy
Each AP learns of the HA pair during a CAPWAP discovery phase, then builds a CAPWAP tunnel to the active controller. The active unit keeps CAPWAP tunnels, AP states, client states, configurations, and image files all in sync with the hot standby unit. If the active unit fails, the hot standby unit quickly takes over the active role. The APs do not have to discover another controller to join; the controllers simply swap roles so the APs can stay joined to the active controller in the HA pair.
The APs do not even have to rebuild their CAPWAP tunnels after a failure. The tunnels are synchronized between active and standby, so they are always maintained. The SSO switch-over occurs at the controllers—not at the APs.
The active controller also synchronizes the state of each associated client that is in the RUN state with the hot standby controller. If the active fails, the standby will already have the current state information for each client, making the failover process transparent.
Tip
The active and standby controllers must always run an identical software image. When one controller is upgraded, its standby peer is also upgraded. That also means when the active unit is rebooted, the standby unit follows suit. At the time of this writing, “hitless” in-service software upgrades are not possible.
The hot standby controller monitors the active unit through keepalives that are sent every 100 ms. If a keepalive is not answered, the standby unit begins to send ICMP echo requests to the active unit to determine what sort of failure has occurred. For example, the active unit could have crashed, lost power, or had its network connectivity severed.
Once the standby unit has declared the active unit as failed, it assumes the active role. The failover may take up to 500 ms, in the case of a crash or power failure, or up to 4 seconds if a network failure has occurred.
SSO is designed to keep the failover process transparent from the AP’s perspective, as well as the client’s. In fact, the APs know only of the active unit; they are not even aware that the hot standby unit exists. The two controllers share a “mobility” MAC address that initially comes from the first active unit’s MAC address. From then on, that address is maintained by whichever unit has the active role at any given time. The controllers also share a common virtual management IP address. Keeping both MAC and IP addresses virtual and consistent allows the APs to stay in contact with the active controller—regardless of which controller currently has that role.
Exam Preparation Tasks
As mentioned in the section, “How to Use This Book,” in the Introduction, you have a couple of choices for exam preparation: the exercises here, Chapter 21, “Final Review,” and the exam simulation questions on the DVD.
Review All Key Topics
Review the most important topics in this chapter, noted with the Key Topic icon in the outer margin of the page. Table 11-2 lists a reference of these key topics and the page numbers on which each is found.
![]()

Table 11-2 Key Topics for Chapter 11
Define Key Terms
Define the following key terms from this chapter and check your answers in the glossary:
CAPWAP Discovery Request
CAPWAP Join Request
N+1 redundancy
N+N redundancy
N+N+1 redundancy
primed controller address
stateful switchover (SSO)
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.