NoSQL For Dummies (2015)
Part III. Bigtable Clones
Chapter 11. Bigtable Use Cases
In This Chapter
![]() Restructuring data for storage in columns
Restructuring data for storage in columns
![]() Storing data for later analysis
Storing data for later analysis
Bigtable is used to manage very large amounts of data across many servers, up to petabytes of data and hundreds, if not thousands, of servers.
If you’re using relational databases but having issues with them, you might think that Bigtable clones are the natural place to start looking for help. After all, they’re tables, so they must be similar to relational databases, right? Unfortunately, that’s not the case.
Bigtable clones handle some issues well that relational database don’t solve — for example, with sparse data problems, where datasets contain many different types of values, but only a handful of those values are used. Bigtable clones are also able to analyze data while it’s in-flight, rather than in overnight batches in a separate data warehouse.
This chapter shows how managing data in relational database differs from managing the same data in a Bigtable. I also talk about how to store data effectively for later analysis, and for providing historic summaries of data analyzed.
Handling Sparse Data
At times, a relational database management system (RDBMS) may have a table design (a schema) in which the columns don’t have a value. An example is a social media site where someone hasn’t provided their photo yet.
Using an RDBMS to store sparse data
Null values(as opposed to empty strings) in relational databases typically consume a couple of bytes, which is fine normally because the field isn’t filled — which when filled would be more like a 20-byte string for, say, storing an uploaded a picture. Two bytes is better than 20 bytes.
In some situations, though, these two bytes per blank field can be a significant amount of wasted space. Consider a contacts application that supports usernames and phone numbers for every type of network — cell, home, and office phone — and social networks like Twitter, Facebook, and Baidu, with a column for each of the hundreds of options and addresses. This means hundreds of bytes wasted per record.
If you’re anything like me, each contact consumes a minimum of three fields (see Figure 11-1). If you provide a contact management service, you may be storing 297 null fields for the 300 fields you support. Scale this up to a shared global application, and you’re looking at terabytes of wasted space.
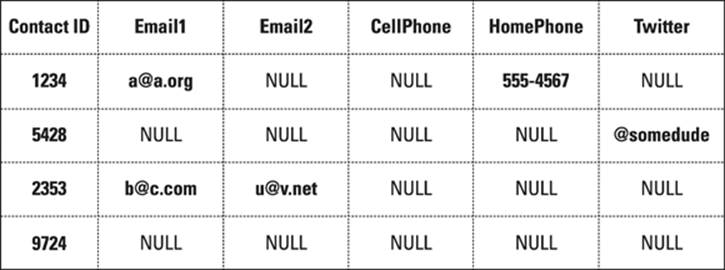
Figure 11-1: Sparse contacts table in an RDBMS.
Author: So you can’t scale up from global to worldwide, because they mean the same thing — so the scale is the same.
That’s even before you consider doing a query on a single contact and pulling back 300 columns, many of which are null. Those null columns 2 bytes markers are costly in space on the result set when being sent over the network and processed at the client.
Using a Bigtable to manage sparse data instead of a relational database alleviates this storage issue.
Using a Bigtable
In a Bigtable, you can model the same contacts application with a column family for each type of network (phone, social media, email, snail mail) and a column for each one defined (home phone, cell phone, office phone).
Bigtable stores only the columns you indicate on each record instance. If you indicate three columns — email, home phone, and cell phone — then Bigtable stores exactly those three column values. No nulls, and no wasted space, as illustrated in Figure 11-2.

Figure 11-2: Sparse data in a Bigtable clone.
If you need to find all contacts with a phone number — say, at least one column in the phone column family — then you need to consider that factor. This scenario can happen if you’re viewing all contacts in a phone in order to make a call; there’s no point in showing contacts without phone numbers here!
In this case, the database must support a column exists query for the column family and column names. Some databases, such as Hypertable, allow you to set up special qualifier indexes to ensure that these types of existential queries will operate quickly over large datasets.
Also, keep in mind that some Bigtable clones don’t provide advanced matching functions for values but store them instead as “dumb” binary data that cannot be compared with data-type specific operations — for example, searching for all contact names (a string field) starting with “Adam F”. This is a starts with query that processes a string value. Most Bigtable clones provide exact match functionality, but don’t natively support partial match or data-type-specific range queries (less than and greater than).
Hypertable’s value indexes do support exact match, starts with, and regular expression matches. If you need this functionality regularly, Hypertable may be for you.
Bigtable clones also don’t support relationships, preferring to store multiple copies of data to minimize read-time processing. This is a process called denormalization. Although, in some situations, this approach consumes more disk space, it enables very efficient reads with higher throughput than most relational databases can provide.
Analyzing Log Files
Log files are very common across a range of systems and applications. Being able to record these files for later analysis is a valuable feature.
Log-file recording and analysis is a very complex business. It’s not unusual for every system-to-system call in mission-critical Enterprise applications to include tracking code. This code enables the app to check for errors, invalid values, and security breaches, as well as the duration of each action.
This vast information is collected from hundreds of servers. It’s then analyzed in nearly real time in order to ensure that a system’s tracking capabilities and condition are up to date. In this way, problems are discovered before services to users are interrupted.
Analyzing data in-flight
The traditional relational database approach to analyzing data is to store it during the day and then at regular intervals (normally overnight) to create a different structure of that data in a data warehouse for analyzing the next day.
For your company’s current Enterprise software sales, daily data summaries may be enough. On the other hand, in countries with highly regulated financial services, this information needs to be less than five minutes old. The same can be said for system monitoring. There’s no point in having a view that’s 24 hours or more out of date; you need summaries as soon as they’re available.
Bigtable clones are great for collecting this information. They can have flexible columns, so if a particular log entry doesn’t have data for a field, it simply can’t be stored. (See Figure 11-3 for an example of a log entry.) Bigtable clones also allow you to store data in multiple structures.
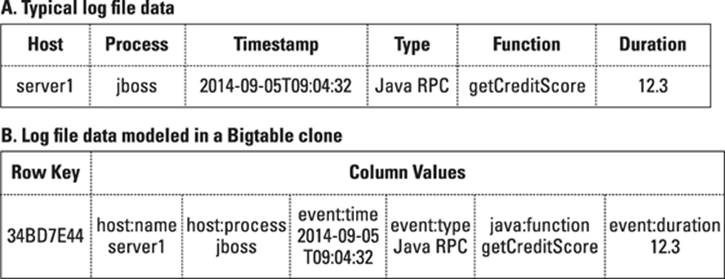
Figure 11-3: A typical log file entry.
To build a quick picture of a day in five minute, one-hour, one-day chunks, you can store the same data in alternative structures at the same time. This is an application of the denormalization pattern commonly used in NoSQL systems, as shown in Figure 11-4.
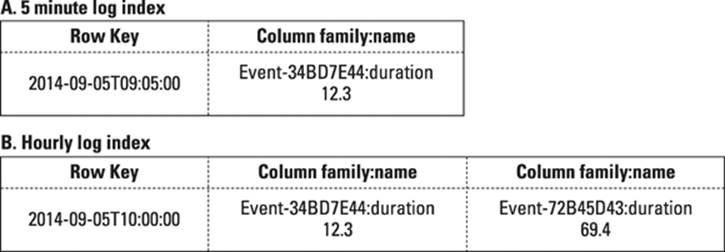
Figure 11-4: The same log entry indexed for different time periods.
The preceding denormalization approach enables quick searching for data in different systems at different time intervals, which is useful for ad-hoc querying and also for building data summaries, which I discuss next.
Building data summaries
Having extra index tables allows a daemon program to regularly and efficiently recalculate the last five minutes, hour, and daily summaries.
Instead of requiring a range index or scanning all data rows to find the last five minutes of data, you instead merely round the current time up to a five-minute interval and query for all data with that interval in your log summary table.
Using specialized system iterators (as Accumulo does) or stored procedures allows this calculation to happen within the database very efficiently. (See Figure 11-5, which shows a summary table being updated.)

Figure 11-5: Calculated summary table.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.