Apache Hadoop YARN: Moving beyond MapReduce and Batch Processing with Apache Hadoop 2 (2014)
8. Capacity Scheduler in YARN
Typically organizations start Apache Hadoop deployments as single-user environments and/or just for a single team. As organizations start deriving more value from data processing and move toward mature cluster deployments, there are significant drivers to consolidate Hadoop clusters into a small number of scaled, shared clusters. This need is driven by the desire to minimize data fragmentation on multiple systems. Such concentration of data on a few HDFS clusters liberates data for organization-wide access, avoids data silos, and allows all-accommodating data-processing workflows. In addition, the operational costs and complexity of managing multiple small clusters are reduced.
Once the deployment architecture in an organization evolves toward centralized data repositories, shared compute clusters should follow suit for the same reasons. A successful model for this is for multiple teams, suborganizations, or business units within a single parent organization to come together to pool compute resources and share resources for efficiency. Apache Hadoop started supporting such shared clusters beginning with Hadoop version 0.20 (the version predated, and eventually evolved into, Apache Hadoop version 1.x). Initially, Hadoop supported a simple first-in, first-out (FIFO) job scheduler that allowed scheduling for shared clusters but was insufficient to address various emerging use-cases. This situation eventually led to the implementation of the Capacity scheduler. YARN and Hadoop version 2 inherit most of the same Capacity scheduler functionality, along with lots of improvements and enhancements required to take full advantage of the new capabilities unlocked in YARN.
Introduction to the Capacity Scheduler
As we discussed in Chapter 1, “Apache Hadoop YARN: A Brief History and Rationale,” the Capacity scheduler originally came about in Hadoop version 1 to address some of the issues with Hadoop on Demand (HOD)–based architecture. It is designed to run applications in a shared cluster supporting multitenancy, while maximizing application throughput and enabling high utilization of the cluster. Given the new support in YARN for applications of arbitrary frameworks and workload characteristics, the Capacity scheduler in Hadoop version 2 with YARN has been enhanced with other features to support these new use-cases.
In the HOD architecture, each user or team would have its own private compute cluster allocated dynamically but with constricted elasticity. This would lead to poor cluster utilization and poor locality of data. Sharing clusters between organizations is a cost-effective way to run multitenant Hadoop installations that leads to improvements in utilization, better performance, and the potential for more intelligent scheduling. However, resource sharing also brings up concerns about application isolation, security, and the issue of resource contention.
The Capacity scheduler is built to address all these concerns. It is designed around the following ideas.
Elasticity with Multitenancy
Organizations prefer to share resources between individuals, teams, and suborganizations in an elastic fashion. Free resources should be allocated to any entity as long as those resources remain underutilized otherwise. When there is an emergent demand for these resources, they should be pulled back with minimal impact to service level agreements (SLAs) of the originally entitled entities.
The Capacity scheduler supports these features with queue capacities, minimum user percentages, and limits. It is designed to enable sharing of a single YARN cluster while simultaneously giving each organization guarantees on the allocated capacities. To improve utilization, organizations can make use of idle capacities “belonging” to other organizations. The Capacity scheduler also enforces stringent limits to avoid a single application, user, or queue from overwhelming the cluster and impacting co-tenants.
Security
Multitenant clusters also raise concerns about security even within an umbrella organization. The Capacity scheduler provides tools like queue-level Access Control Lists (ACLs) for the administrators so that there are enough safeguards to address cross-organization security-related compliance.
Resource Awareness
Organizations should be able to use YARN to orchestrate applications with differing resource requirements and to arbitrate resources of all kinds, including memory, CPU, disks, or other cluster-wide shared resources. The current version of the Capacity scheduler supports CPU and memory resources, and support for other resources is expected. Scheduling policies exist to take into account the memory and CPU requirements of submitted applications and support the dynamic needs of ApplicationMasters.
Granular Scheduling
Organizations should be able to share individual nodes in a fine-grained manner as opposed to loaning full nodes to tenants. Assigning complete nodes hurts utilization and should be avoided.
Compared to the other traditional resource managers with which HOD worked, YARN deals with resources in a different manner—namely, by not partitioning nodes in a static way and assigning them to queues. The unit of scheduling in YARN is much more granular and dynamic. Queues in YARN are simply a logical view of resources on physical nodes. This design enables finer-grained sharing of individual nodes by various applications, users, and organizations and, therefore, facilitates high utilization.
Locality
Following one of YARN’s core goals, the Capacity scheduler supports specifying the locality of computation as well as node or rack affinity by applications. Furthermore, the Capacity scheduler itself is locality aware, and is very good at automatically allocating resources on not only preferred nodes/racks, but also nodes/racks that are close to the preferred ones. In doing so, it ensures that the framework developer does not have to worry about locality. This feature is one of the key differences between YARN and other, traditional, resource managers.
Scheduling Policies
Organizations may need to control various aspects of scheduling depending on their anticipated workloads. For example, there may be a need to balance data processing through batch workflows with applications driving interactive analysis. In addition, there may be requirements for support of an all-or-nothing kind of gang scheduling, or there may be a need for executing long-running services alongside applications vying for sustained throughput.
The Capacity scheduler offers support for churning through applications to attain high throughput. Given its historical roots of scheduling MapReduce applications in Hadoop version 1, the Capacity scheduler understands that even though containers may not be running, they can still consume resources in the cluster. Consider the output of MapReduce map tasks: Even after a map task completes, it still consumes resources to store its map outputs. The first-in, first-out (FIFO) scheduling policy of the Capacity scheduler strives for maximum throughput, thereby enabling efficient use of cluster resources.
At the time of this book’s writing, the YARN community was working on several innovations to support emerging use-cases like long-running services and special needs of interactive data analysis.
Capacity Scheduler Configuration
The Capacity scheduler is the default scheduler that ships with Hadoop YARN. In the event that it becomes necessary to explicitly set the scheduler in the configuration, one should set the following values in the configuration file yarn-site.xml on the ResourceManager node:
![]() Property: yarn.resourcemanager.scheduler.class
Property: yarn.resourcemanager.scheduler.class
![]() Value: org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler
Value: org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler
The Capacity scheduler itself depends on a special configuration file called capacity-scheduler.xml to be present in the ResourceManager’s class path for its settings. This location is typically in a conf directory. The scheduler reads this file both when it is starting and when an administrator modifies it and issues a special signal for reloading it.
Changing various configuration settings in the Capacity scheduler (e.g., queue properties, application limits) is very straightforward and can be done at run time. This task can be accomplished by editing capacity-scheduler.xml with the desired modifications and then running the following admin command:
$ yarn rmadmin -refreshQueues
This command can be run only by cluster administrators, and is configured using a list at the ResourceManager via the yarn.admin.acl property.
Queues
The fundamental unit of scheduling in YARN is a queue. A queue is either a logical collection of applications submitted by various users or a composition of more queues. Every queue in the Capacity scheduler has the following properties:
![]() A short queue name
A short queue name
![]() A full queue path name
A full queue path name
![]() A list of child queues and applications associated with them
A list of child queues and applications associated with them
![]() Guaranteed capacity of the queue
Guaranteed capacity of the queue
![]() Maximum capacity to which a queue can grow
Maximum capacity to which a queue can grow
![]() A list of active users and the corresponding limits of sharing between users.
A list of active users and the corresponding limits of sharing between users.
![]() State of the queue
State of the queue
![]() ACLs governing the access to the queue
ACLs governing the access to the queue
The following discussion describes what these properties are, how the Capacity scheduler uses them for making various scheduling decisions, and how they can be configured to meet specific needs.
Hierarchical Queues
In the Capacity scheduler, each queue typically represents an organization, while the capacity of the queue represents the capacity (of the cluster) that the organization is entitled to use. In Hadoop version 1, the Capacity scheduler supported only a flat list of queues, which was eventually found to be limiting. Most organizations are large and need to further share their queues among users from different suborganizations in a fine-grained manner. This desire to divide capacity further and share it among suborganizations is also accentuated by the existence of various categories of users within a given queue. For example, within an organization, some applications may belong to different categories, such as interactive and batch workloads, production and ad hoc research applications, and so on. The Capacity scheduler in YARN supports hierarchical queues to address this gap.
Key Characteristics
Some important characteristics of hierarchical queues are highlighted here:
![]() Queues are of two types: parent queues and leaf queues.
Queues are of two types: parent queues and leaf queues.
![]() Parent queues enable the management of resources across organizations and suborganizations. They can contain more parent queues or leaf queues. They do not themselves accept any application submissions directly.
Parent queues enable the management of resources across organizations and suborganizations. They can contain more parent queues or leaf queues. They do not themselves accept any application submissions directly.
![]() Leaf queues denote the queues that live under a parent queue and accept applications. Leaf queues do not have any more child queues.
Leaf queues denote the queues that live under a parent queue and accept applications. Leaf queues do not have any more child queues.
![]() The top-level parent queue called ROOT queue doesn’t belong to any organization and denotes the cluster itself.
The top-level parent queue called ROOT queue doesn’t belong to any organization and denotes the cluster itself.
![]() Using parent and leaf queues, administrators can do capacity allocations to various organizations and suborganizations.
Using parent and leaf queues, administrators can do capacity allocations to various organizations and suborganizations.
Scheduling Among Queues
Hierarchical queues ensure that guaranteed resources are first shared among the subqueues of an organization before queues belonging to other organizations are allowed to use free resources from this queue. This design enables each organization to have more control over how resources guaranteed to them are predictably utilized. The scheduling algorithm works as follows:
![]() At every level in the hierarchy, every parent queue keeps the list of its child queues in a sorted manner based on demand. The sorting of the queues is determined by the currently used fraction of each queue’s capacity (or the queue names [i.e., full path names] if the utilization of any two queues is equal) at any point in time.
At every level in the hierarchy, every parent queue keeps the list of its child queues in a sorted manner based on demand. The sorting of the queues is determined by the currently used fraction of each queue’s capacity (or the queue names [i.e., full path names] if the utilization of any two queues is equal) at any point in time.
![]() The ROOT queue understands how the cluster capacity has to be distributed among the first level of parent queues and invokes scheduling on each of its child queues.
The ROOT queue understands how the cluster capacity has to be distributed among the first level of parent queues and invokes scheduling on each of its child queues.
![]() Every parent queue also tries to follow the same capacity constraints for all of its child queues and schedules them accordingly.
Every parent queue also tries to follow the same capacity constraints for all of its child queues and schedules them accordingly.
![]() Leaf queues hold the list of active applications, potentially from multiple users, and schedule resources in a FIFO manner while simultaneously respecting the limits on how much a single user can take within that queue.
Leaf queues hold the list of active applications, potentially from multiple users, and schedule resources in a FIFO manner while simultaneously respecting the limits on how much a single user can take within that queue.
Defining Hierarchical Queues
Queues have evolved from a flat list to a hierarchy, and as a result their naming has also needed to change. The Capacity scheduler uses queue paths to refer to any queue in the hierarchy. The queue path names each queue in its ancestral hierarchy starting with the ROOT queue, with each name separated by a dot (“.”). As of this book’s writing, the configuration of hierarchical queues was still driven by a flat list of configuration properties. The Capacity scheduler uses the same queue paths to specify its configuration in capacity-scheduler.xml, as described earlier.
Let’s look at an example that will be used in the rest of the chapter to explain the concepts associated with the Capacity scheduler. Assume that in a company named YARNRollers, there are three organizations called grumpy-engineers, finance-wizards, and marketing-moguls. In addition, assume the grumpy-engineers organization has two subteams: infinite-monkeys and pesky-testers. The finance-wizards organization has two suborganizations: meticulous-accountants and thrifty-treasurers. Finally, the marketing-moguls are divided into brand-exploders and social-savants. The overall hierarchy of queues in this example is shown in Figure 8.1.
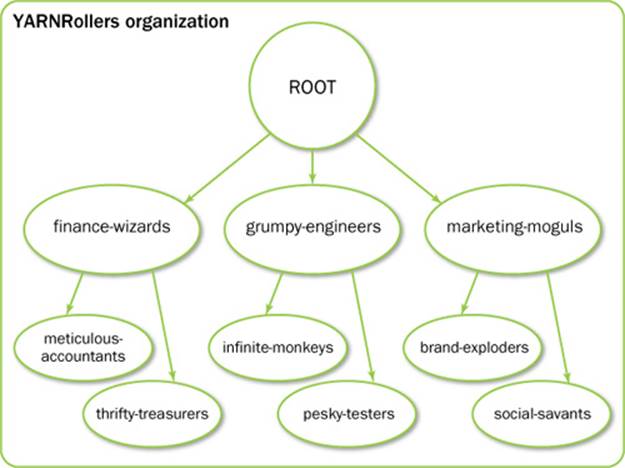
Figure 8.1 Example hierarchies for use by Capacity scheduler
Child queues are tied to their parent queue by defining the configuration property yarn.scheduler.capacity.<queue-path>.queues. For example, the top-level queues (grumpy-engineers, finance-wizards, and marketing-moguls) should be tied to the ROOT queue. Thus the queue hierarchy is configured as follows:
![]() Property: yarn.scheduler.capacity.root.queues
Property: yarn.scheduler.capacity.root.queues
![]() Value: grumpy-engineers,finance-wizards,marketing-moguls
Value: grumpy-engineers,finance-wizards,marketing-moguls
Similarly, the children of the parent queue finance-wizards are defined as follows:
![]() Property: yarn.scheduler.capacity.finance-wizards.queues
Property: yarn.scheduler.capacity.finance-wizards.queues
![]() Value: meticulous-accountants,thrifty-treasurers
Value: meticulous-accountants,thrifty-treasurers
Leaf queues have no further children, so they should not have any corresponding configuration property that ends with the .queues suffix.
There are limitations on how one can name the queues. To avoid confusion, the Capacity scheduler doesn’t allow two leaf queues to have the same name across the whole hierarchy.
As of this book’s writing, queues could not be deleted completely at run time, but they could be stopped (as will be described later in this chapter). New queues can be added dynamically at run time by simply defining a new queue, attaching it to its parent, and refreshing the configuration using the yarn rmadmin utility mentioned earlier. Note that newly added queues cannot invalidate constraints, such as the constraint that queue capacity at each level be no more than 100%. Further, one cannot (for obvious reasons) change what was previously a leaf-level queue to be a parent queue by adding a new child queue to it.
Queue Access Control
The point of having queues is to enable sharing and at the same time to give control back to the organization, limiting who can submit applications to any given queue and who can administer a queue.
Queues can be configured to restrict submission to queues at various levels. Although application submission can really happen only at the leaf queue level, an ACL on a parent queue can be set to control admittance to all the descendant queues.
Access Control Lists in Hadoop are configured by specifying the list of users and/or groups as a string property. For specifying a list of users and groups, the format is “user1,user2 group1,group” (a comma-separated list of users, followed by a space separator, followed by a comma-separated list of groups). If it is set to “*” (asterisk), all users and groups are allowed to perform the operation guarded by the ACL in question. If it is set to “ ” (i.e., space), no users or groups are allowed to perform the operation. With that specification of ACLs, for example, to restrict access to any queue originating under the finance-wizards queue to only sherlock, pacioli, and a special group called cfo-group, one can make the following assignments:
![]() Property: yarn.scheduler.capacity.root.finance-wizards.acl_submit_applications
Property: yarn.scheduler.capacity.root.finance-wizards.acl_submit_applications
![]() Value: sherlock,pacioli cfo-group
Value: sherlock,pacioli cfo-group
A separate ACL can be used to control administration of queues at various levels. Queue administrators have permission to submit applications without an explicit submit ACL, kill any application in the queue, and obtain information about any application in the queue; by comparison, regular users are restricted from viewing all the details of other users’ applications. Administrators’ ACLs can be configured similar to submit ACLs, for example, to make the special group cfo-group the sole administrators of the finance-wizards queues:
![]() Property: yarn.scheduler.capacity.root.finance-wizards.acl_administer_queue
Property: yarn.scheduler.capacity.root.finance-wizards.acl_administer_queue
![]() Value: " cfo-group"
Value: " cfo-group"
![]() Description: A space character followed by cfo-group, unquoted
Description: A space character followed by cfo-group, unquoted
With YARN’s Capacity scheduler supporting a hierarchy of queues, delegation of the administration is possible. Queue administrators of a suborganization can take control of monitoring queues for irregularities. Ideally, administrators of suborganizations should be able to add new queues, stop queues, and perform other queue-related tasks; these abilities are expected to be available in future versions of YARN.
Capacity Management with Queues
The Capacity scheduler is designed to allow organizations to share compute clusters using the very familiar notion of first-in, first-out queues. YARN doesn’t assign whole nodes to queues. Instead, queues own a fraction of the capacity of the cluster, which can be fulfilled from any number of nodes in a dynamic fashion. Scheduling is the process of matching the resource requirements of multiple applications from various users, each submitted to different queues at multiple levels in the queue hierarchy, with free capacity available at any point in time on the nodes in the cluster.
Queues are configured by the administrators to be allocated as a fraction of the capacity of the whole cluster. In our example, assuming that the administrators decide to share the cluster resources between the grumpy-engineers, finance-wizards, and marketing-moguls in a 6:1:3 ratio, the corresponding queue configuration will be as follows:
![]() Property: yarn.scheduler.capacity.root.grumpy-engineers.capacity
Property: yarn.scheduler.capacity.root.grumpy-engineers.capacity
![]() Value: 60
Value: 60
![]() Property: yarn.scheduler.capacity.root.finance-wizards.capacity
Property: yarn.scheduler.capacity.root.finance-wizards.capacity
![]() Value: 10
Value: 10
![]() Property: yarn.scheduler.capacity.root.marketing-moguls.capacity
Property: yarn.scheduler.capacity.root.marketing-moguls.capacity
![]() Value: 30
Value: 30
YARN is built around the fundamental requirements of fault tolerance and elasticity. In a YARN cluster built out of commodity hardware, subcomponents of a node like disks or even whole nodes can go down for any of several reasons. In addition, depending on workloads and historical cluster usage, administrators may choose to either add new physical machines or take away existing nodes to account for under-utilization. Any of these changes will cause corresponding variations in cluster capacity, as seen by the Capacity scheduler for the sake of scheduling. Queue capacity configuration is indicated in terms of percentages for this reason; this scheme ensures that organizations and suborganizations can reason well about their shares and guarantees irrespective of small variations in the total cluster capacity.
As discussed in the section dealing with hierarchical queues, there is a capacity planning problem at a suborganization level. Continuing with our example, let’s assume the grumpy-engineers decide to share their capacity between the infinite-monkeys and the pesky-testers in a 1:4 ratio (so that testing of YARN gets as much resources as possible). The corresponding configuration should be as follows, again given in terms of percentages:
![]() Property: yarn.scheduler.capacity.root.grumpy-engineers.infinite-monkeys.capacity
Property: yarn.scheduler.capacity.root.grumpy-engineers.infinite-monkeys.capacity
![]() Value: 20
Value: 20
![]() Property: yarn.scheduler.capacity.root.grumpy-engineers.pesky-testers.capacity
Property: yarn.scheduler.capacity.root.grumpy-engineers.pesky-testers.capacity
![]() Value: 80
Value: 80
Note that the sum of capacities at any level in the hierarchy should be no more than 100% (for obvious reasons).
As described earlier, during scheduling, queues at any level in the hierarchy are sorted in the order of their current used capacity and available resources are distributed among them, starting with those queues that are the most under-served at that point in time. With respect to just capacities, the resource scheduling has the following flow:
![]() The more under-served the queues, the higher the priority that is given to them during resource allocation. The most under-served queue is the queue with the smallest ratio of used capacity to the total cluster capacity.
The more under-served the queues, the higher the priority that is given to them during resource allocation. The most under-served queue is the queue with the smallest ratio of used capacity to the total cluster capacity.
![]() The used capacity of any parent queue is defined as the aggregate sum of used capacity of all the descendant queues recursively.
The used capacity of any parent queue is defined as the aggregate sum of used capacity of all the descendant queues recursively.
![]() The used capacity of a leaf queue is the amount of resources that is used by allocated containers of all applications running in that queue.
The used capacity of a leaf queue is the amount of resources that is used by allocated containers of all applications running in that queue.
![]() Once it is decided to give a parent queue the freely available resources, further similar scheduling is done to decide recursively as to which child queue gets to use the resources based on the same concept of used capacities.
Once it is decided to give a parent queue the freely available resources, further similar scheduling is done to decide recursively as to which child queue gets to use the resources based on the same concept of used capacities.
![]() Scheduling inside a leaf queue further happens to allocate resources to applications arriving in a FIFO order.
Scheduling inside a leaf queue further happens to allocate resources to applications arriving in a FIFO order.
![]() Such scheduling also depends on locality, user level limits, and application limits (to be described soon).
Such scheduling also depends on locality, user level limits, and application limits (to be described soon).
![]() Once an application within a leaf queue is chosen, scheduling happens within an application, too. Applications may have different resource requests at different priorities.
Once an application within a leaf queue is chosen, scheduling happens within an application, too. Applications may have different resource requests at different priorities.
![]() To ensure elasticity, capacity that is configured but not utilized by any queue due to lack of demand is automatically assigned to the queues that are in need of resources.
To ensure elasticity, capacity that is configured but not utilized by any queue due to lack of demand is automatically assigned to the queues that are in need of resources.
To get a better understanding of how the cluster is divided and how scheduling happens, consider how available memory in the cluster is scheduled. Assuming a cluster of 100 nodes, each with 10 GB of memory allocated for YARN containers, we have a total cluster capacity of 1000 GB (one 1 TB). Now according to the previously described configuration, the grumpy-engineers organization is assigned a capacity of 60% of cluster capacity (i.e., an absolute capacity of 600 GB). Similarly, the finance-wizards are assigned 100 GB and the marketing-moguls suborganization gets 300 GB.
Under the grumpy-engineers organization, capacity needs to be distributed between the infinite-monkeys team and the pesky-testers in the ratio 1:4. Thus the infinite-monkeys get 120 GB, and 480 GB is assigned to the pesky-testers.
Consider the following timeline of events happening in the cluster:
![]() In the beginning, the entire grumpy-engineers queue is free, with no application in any queues or from any users in a running state. Other queues at that level used by the finance-wizards and the marketing-moguls are completely utilizing their capacities.
In the beginning, the entire grumpy-engineers queue is free, with no application in any queues or from any users in a running state. Other queues at that level used by the finance-wizards and the marketing-moguls are completely utilizing their capacities.
![]() The users sid and hitesh first submit applications to the leaf queue infinite-monkeys. Their applications are elastic and can run with either all the resources available in the cluster or a subset depending on the state of the resource usage.
The users sid and hitesh first submit applications to the leaf queue infinite-monkeys. Their applications are elastic and can run with either all the resources available in the cluster or a subset depending on the state of the resource usage.
![]() As the first set of users in the system, even though each of them may be controlled to be within the queue (120 GB, because of user-limit factor described later), together they can occupy 240 GB (two users controlled to queue capacity each).
As the first set of users in the system, even though each of them may be controlled to be within the queue (120 GB, because of user-limit factor described later), together they can occupy 240 GB (two users controlled to queue capacity each).
![]() This situation can occur despite the fact that infinite-monkeys are configured to be run with only 120 GB. The Capacity scheduler lets this happen to ensure elastic sharing of cluster resources and for high utilization.
This situation can occur despite the fact that infinite-monkeys are configured to be run with only 120 GB. The Capacity scheduler lets this happen to ensure elastic sharing of cluster resources and for high utilization.
![]() Assume the users jian, zhijie, and xuan submit more applications to the leaf queue infinite-monkeys, such that even though each leaf queue is restricted to 120 GB, the overall used capacity in the queue becomes 600 GB—essentially taking over all the capacity to which the pesky-testers are entitled.
Assume the users jian, zhijie, and xuan submit more applications to the leaf queue infinite-monkeys, such that even though each leaf queue is restricted to 120 GB, the overall used capacity in the queue becomes 600 GB—essentially taking over all the capacity to which the pesky-testers are entitled.
![]() Next the user gupta submits his own application to the queue pesky-testers, so as to start running an analysis of historical testing of his software project. With no free resources in the cluster, his application will wait.
Next the user gupta submits his own application to the queue pesky-testers, so as to start running an analysis of historical testing of his software project. With no free resources in the cluster, his application will wait.
![]() Given that the infinite-monkeys queue has now taken over the whole cluster, the user gupta may or may not be able to get back the guaranteed capacity of his queue immediately depending on whether preemption is enabled.
Given that the infinite-monkeys queue has now taken over the whole cluster, the user gupta may or may not be able to get back the guaranteed capacity of his queue immediately depending on whether preemption is enabled.
![]() As resources start being freed up from the applications of sid, hitesh, jian, zhijie, and xuan in the infinite-monkeys queue, the freed-up containers will start being allocated to gupta’s applications. This will continue until the cluster stabilizes at the intended 1:4 ratio of resource allocation between the two queues.
As resources start being freed up from the applications of sid, hitesh, jian, zhijie, and xuan in the infinite-monkeys queue, the freed-up containers will start being allocated to gupta’s applications. This will continue until the cluster stabilizes at the intended 1:4 ratio of resource allocation between the two queues.
As one can see, this setup leaves the door open for abusive users to submit applications continuously and lock out other queues from resource allocation until the abusive users’ containers finish or get preempted. To avoid this problem, the Capacity scheduler supports limits on the elastic growth of any queue. For example, to restrict the infinite-monkeys from monopolizing the queue capacity and to box them into their capacity, administrators can set the following limit:
![]() Property: yarn.scheduler.capacity.root.grumpy-engineers.infinite-monkeys.maximum-capacity
Property: yarn.scheduler.capacity.root.grumpy-engineers.infinite-monkeys.maximum-capacity
![]() Value: 40
Value: 40
Once this limit is set, the infinite-monkeys can still go beyond their capacity of 120 GB, but they cannot get resources allocated to them that exceed 40% of the parent queue grumpy-engineers’ capacity (i.e., 40% of 600 GB = 240 GB).
The capacity and maximum capacity configuration come together to provide the basic control over sharing and elasticity across organizations or suborganizations on a YARN cluster. Administrators need to balance the elasticity with the limits so that there isn’t a loss of utilization due to too-strict limits and, conversely, there isn’t any cross-organization impact due to excessive sharing.
Capacities and maximum capacities can be dynamically changed at run time using the rmadmin “refresh queues” functionality. It is a good practice for administrators to audit queue usage and grow or shrink user limits at various levels to find the desired balance.
User Limits
Leaf queues have the additional responsibility of ensuring fairness with regard to scheduling applications submitted by various users in that queue. The Capacity scheduler places various limits on users to enforce this fairness. Recall that applications can only be submitted to leaf queues in the Capacity scheduler; thus, parent queues do not have any role in enforcing user limits.
When configuring the user limits of a queue, administrators have to decide upfront the amount of user sharing that they would like to enable at run time. Let’s start with an example of an administrator who decides to configure user limits for the finance-wizards suborganization. As mentioned, user limits need to be set for every leaf queue. Let’s focus on the leaf queue called root.finance-wizards.thrifty-treasurers.
All user limits are based on the queue’s capacity. As mentioned earlier, queue capacity is a dynamically changing entity, so user limits are also dynamically adjusted in every scheduling cycle based on capacity changes.
Assume the queue capacity needs to be shared among not more than five users in the thrifty-treasurers queue. When you account for fairness, this results in each of those five users being given an equal share (20%) of the capacity of the root.finance-wizards.thrifty-treasurers queue. The following configuration for the finance-wizards queue applies this limit:
![]() Property: yarn.scheduler.capacity.root.finance-wizards.thrifty-treasurers.minimum-user-limit-percent
Property: yarn.scheduler.capacity.root.finance-wizards.thrifty-treasurers.minimum-user-limit-percent
![]() Value: 20
Value: 20
This configuration property is named minimum-user-limit-percent to reflect the fact that it determines only the minimum to which any user’s share of the queue capacity can shrink. In other words, irrespective of this limit, any user can come into the queue and take more than his or her fair share if there are idle resources. Let’s look at an example to see how this situation can occur.
![]() Assume the queue started out being empty. Only user hillegas submits an application, which occupies the entire queue’s capacity.
Assume the queue started out being empty. Only user hillegas submits an application, which occupies the entire queue’s capacity.
![]() Now when another user meredith submits an application, hillegas and meredith are both “assigned” 50% of the capacity of the queue. By “assigned,” we mean that from that point onward, all scheduling decisions are based on the assumption that each of those users deserves a 50% share of the queue.
Now when another user meredith submits an application, hillegas and meredith are both “assigned” 50% of the capacity of the queue. By “assigned,” we mean that from that point onward, all scheduling decisions are based on the assumption that each of those users deserves a 50% share of the queue.
![]() Whether the containers of user hillegas are immediately killed to satisfy the requests from user meredith is a function of whether preemption is enabled in the Capacity scheduler. If hillegas’s containers are preempted in due time, meredith’s application will start getting those containers until the 50% balance is reached. Otherwise, as containers from hillegas gradually finish in their usual manner after completing their work, they will be assigned to meredith.
Whether the containers of user hillegas are immediately killed to satisfy the requests from user meredith is a function of whether preemption is enabled in the Capacity scheduler. If hillegas’s containers are preempted in due time, meredith’s application will start getting those containers until the 50% balance is reached. Otherwise, as containers from hillegas gradually finish in their usual manner after completing their work, they will be assigned to meredith.
![]() Once the balance of 50% share for each user is reached, any freshly freed-up capacity is alternately allocated to the applications of each user.
Once the balance of 50% share for each user is reached, any freshly freed-up capacity is alternately allocated to the applications of each user.
![]() If either of the users doesn’t require the entire queue capacity to run his or her application(s), the Capacity scheduler will automatically assign the extra idle capacity to the other user who needs it, all in an elastic manner—even if the current capacity assignments are 50% each. Thus, the sharing is based on both the number of existing users and the outstanding demands of a specific user. If a user has a 50% share but doesn’t have enough resource requirements to make use of that share, the idle capacity is automatically allocated to the other user, even if the other user is already meeting his or her 50% minimum requirement.
If either of the users doesn’t require the entire queue capacity to run his or her application(s), the Capacity scheduler will automatically assign the extra idle capacity to the other user who needs it, all in an elastic manner—even if the current capacity assignments are 50% each. Thus, the sharing is based on both the number of existing users and the outstanding demands of a specific user. If a user has a 50% share but doesn’t have enough resource requirements to make use of that share, the idle capacity is automatically allocated to the other user, even if the other user is already meeting his or her 50% minimum requirement.
![]() As long as there are outstanding resource requests from existing as well as newly submitted applications from the same set of users, the capacity assignments to these users will not change.
As long as there are outstanding resource requests from existing as well as newly submitted applications from the same set of users, the capacity assignments to these users will not change.
![]() Now if user tucker begins to submit applications to the same queue, the share of each and every user currently present in the queue—that is, hillegas, meredith, and tucker—becomes 33.3% of the queue capacity (again, assuming there is sufficient demand from each user’s applications). The same rules of allocation and reassignment apply as before.
Now if user tucker begins to submit applications to the same queue, the share of each and every user currently present in the queue—that is, hillegas, meredith, and tucker—becomes 33.3% of the queue capacity (again, assuming there is sufficient demand from each user’s applications). The same rules of allocation and reassignment apply as before.
![]() This trend continues until five users are admitted into the queue and each of them is assigned a 20% share as dictated by the minimum-user-limit-percent configuration property for this queue.
This trend continues until five users are admitted into the queue and each of them is assigned a 20% share as dictated by the minimum-user-limit-percent configuration property for this queue.
![]() If a sixth user selden now enters the queue, the behavior changes to respect the administrator’s desire set via the configuration. Instead of continuing to further divide the capacity among six users, the Capacity scheduler halts the sharing to satisfy the minimum user limit percentage for each of the existing five users (i.e., 20%). User selden will be put on a wait list until the applications of one or more of the existing users finish.
If a sixth user selden now enters the queue, the behavior changes to respect the administrator’s desire set via the configuration. Instead of continuing to further divide the capacity among six users, the Capacity scheduler halts the sharing to satisfy the minimum user limit percentage for each of the existing five users (i.e., 20%). User selden will be put on a wait list until the applications of one or more of the existing users finish.
![]() Just as a growing number of users is managed, so a shrinking number of users is also handled. As any users’ applications finish, other existing users with outstanding requirements begin to reclaim the share. For example, in an alternative scenario, if hillegas, meredith, and tucker are each using 33% of the queue capacity and user meredith’s applications complete, hillegas and tucker can now each get 50% of the queue capacity, reflecting the fact that there are only two users in the queue now.
Just as a growing number of users is managed, so a shrinking number of users is also handled. As any users’ applications finish, other existing users with outstanding requirements begin to reclaim the share. For example, in an alternative scenario, if hillegas, meredith, and tucker are each using 33% of the queue capacity and user meredith’s applications complete, hillegas and tucker can now each get 50% of the queue capacity, reflecting the fact that there are only two users in the queue now.
![]() Despite this sharing among users, the fundamental nature of the Capacity scheduler to schedule applications based on a FIFO order doesn’t change! This guarantees that users cannot monopolize queues by submitting new applications continuously: Applications (and thus the corresponding users) that are submitted earlier always get a higher priority than applications that are submitted later.
Despite this sharing among users, the fundamental nature of the Capacity scheduler to schedule applications based on a FIFO order doesn’t change! This guarantees that users cannot monopolize queues by submitting new applications continuously: Applications (and thus the corresponding users) that are submitted earlier always get a higher priority than applications that are submitted later.
Overall, user limits are put in place to enable fair sharing of queue resources, but only up to a certain amount. A balance is sought between not spreading resources too thin among users and avoiding the case in which one or a few users overwhelm the queue with a continuous barrage of resource requests.
In addition to being governed by the configuration that controls sharing among users, the Capacity scheduler’s leaf queues have the ability to restrict or expand a user’s share within and beyond the queue’s capacity through the per-leaf-queue user-limit-factor configuration. It denotes the fraction of queue capacity that any single user can grow, up to a maximum, irrespective of whether there are idle resources in the cluster. This same configuration also dictates various other application limits, as we will see later.
![]() Property: yarn.scheduler.capacity.root.finance-wizards.user-limit-factor
Property: yarn.scheduler.capacity.root.finance-wizards.user-limit-factor
![]() Value: 1
Value: 1
The default value of 1 means that any single user in that queue can, at a maximum, occupy only the queue’s configured capacity. This value avoids the case in which users in a single queue monopolize resources across all queues in a cluster. By extension, setting the value to 2 allows the queue to grow to a maximum of twice the size of the queue’s configured capacity. Similarly, setting it to 0.5 restricts any user from growing his or her share beyond half of the queue capacity.
Note that, like everything else, these limits can be dynamically changed at run time using the refresh-queues functionality.
Reservations
The Capacity scheduler’s responsibility is to match free resources in the cluster with the resource requirements of an application. Many times, however, a scheduling cycle occurs in such a way that even though there are free resources on a node, they are not large enough in size to satisfy the application that is at the head of the queue. This situation typically happens with large-memory applications whose resource demand for each of their containers is much larger than the typical application running in the cluster. When such applications run in the cluster, anytime a regular application’s containers finish, thereby releasing previously used resources for new cycles of scheduling, nodes will have freely available resources but the large-memory applications cannot take advantage of them because the resources are still too small. If left unchecked, this mismatch can cause starving of resource-intensive applications.
The Capacity scheduler solves this problem with a feature called reservations. The scheduling flow for reservations resembles the following:
![]() When a node reports in with a finished container and thus a certain amount of freely available resources, the scheduler chooses the right queue based on capacities and maximum capacities.
When a node reports in with a finished container and thus a certain amount of freely available resources, the scheduler chooses the right queue based on capacities and maximum capacities.
![]() Within that queue, the scheduler looks at the application in a FIFO order together with the user limits. Once a needy application is found, it tries to see if the requirements of that application can be met by this node’s free capacity.
Within that queue, the scheduler looks at the application in a FIFO order together with the user limits. Once a needy application is found, it tries to see if the requirements of that application can be met by this node’s free capacity.
![]() If there is a size mismatch, the Capacity scheduler immediately creates a reservation for this application’s container on this node.
If there is a size mismatch, the Capacity scheduler immediately creates a reservation for this application’s container on this node.
![]() Once a reservation is made for an application on a node, those resources are not used by the scheduler for any other queue, application, or container until the original application for which the reservation was made is served.
Once a reservation is made for an application on a node, those resources are not used by the scheduler for any other queue, application, or container until the original application for which the reservation was made is served.
![]() The node on which a reservation was made can eventually report back that enough containers have finished such that the total free capacity on the node now matches the reservation size. When that happens, the Capacity scheduler marks the reservation as fulfilled, removes it, and allocates a container on that node.
The node on which a reservation was made can eventually report back that enough containers have finished such that the total free capacity on the node now matches the reservation size. When that happens, the Capacity scheduler marks the reservation as fulfilled, removes it, and allocates a container on that node.
![]() Meanwhile, some other node may fulfill the resource needs of the application such that the application no longer needs the reserved capacity. In such a situation, when the reserved node eventually comes back, the reservation is simply cancelled.
Meanwhile, some other node may fulfill the resource needs of the application such that the application no longer needs the reserved capacity. In such a situation, when the reserved node eventually comes back, the reservation is simply cancelled.
To limit the number of reservations from growing in an unbounded manner, and to prevent any potential scheduling deadlocks, the Capacity scheduler simplifies the problem drastically by maintaining only one active reservation per node.
State of the Queues
Queues in YARN can be in one of two states: RUNNING and STOPPED. These states are not specific to the Capacity scheduler. As should already be obvious, the RUNNING state indicates that a queue can accept application submissions, while a STOPPED queue doesn’t accept any such requests. The default state of any configured queue is RUNNING.
In the Capacity scheduler, both leaf queues and parent queues can be stopped. This state includes the root queue as well. For an application to be accepted at any leaf queue, all of the queues in the ancestry—all the way to the root queue—need to be running. This requirement means that once a parent queue is stopped, all the descendant queues in that hierarchy are inactive even if their own state is RUNNING.
In our example, the following configuration dictates the state of the finance-wizards queue:
![]() Property: yarn.scheduler.capacity.root.finance-wizards.state
Property: yarn.scheduler.capacity.root.finance-wizards.state
![]() Value: RUNNING
Value: RUNNING
The rationale for enabling the ability to stop queues is that in various scenarios, administrators wish to drain applications in a queue for many reasons. Decommissioning a queue to migrate users to other queues is one such example. Administrators can stop queues at run time so that while currently present applications run to completion, no new applications are admitted. Existing applications can continue until they complete, allowing the queue to be drained gracefully without any end-user impact. Administrators can also restart the stopped queues by modifying the same configuration property and refreshing the queue using the rmadmin utility as described earlier.
Limits on Applications
To avoid system thrash due to an unmanageable load, created either by accident or by malicious users, the Capacity scheduler puts a static configurable limit on the total number of concurrently active (both running and pending) applications at any single point in time. The default is 10,000. The following configuration property controls this value.
![]() Property: yarn.scheduler.capacity.maximum-applications
Property: yarn.scheduler.capacity.maximum-applications
![]() Value: 10000
Value: 10000
The limit on any specific queue is a fraction of this total limit proportional to its capacity. This setting is a hard limit, which means that once this limit is reached for a queue, any new applications to that queue will be rejected and clients will have to retry their requests after a while.
This limit can be explicitly overridden on a per-queue basis by the following configuration property:
![]() Property: yarn.scheduler.capacity.<queue-path>.maximum-applications
Property: yarn.scheduler.capacity.<queue-path>.maximum-applications
![]() Value: absolute-capacity * yarn.scheduler.capacity.maximum-applications
Value: absolute-capacity * yarn.scheduler.capacity.maximum-applications
There is also a limit on the maximum percentage of resources in the cluster that can be used by the ApplicationMasters. This limit defaults to 10%. It exists to avoid cross-application deadlocks where significant resources in the cluster are occupied entirely by the containers running ApplicationMasters that are waiting for other applications to release containers to proceed with their own work. This configuration indirectly controls the number of concurrent running applications in the cluster, with each queue limited to a number of applications proportional to its capacity.
![]() Property: yarn.scheduler.capacity.maximum-am-resource-percent
Property: yarn.scheduler.capacity.maximum-am-resource-percent
![]() Value: 0.1
Value: 0.1
Similar to the maximum number of applications, this limit can be overridden on a per-queue basis as follows.
![]() Property: yarn.scheduler.capacity.<queue-path>.maximum-am-resource-percent
Property: yarn.scheduler.capacity.<queue-path>.maximum-am-resource-percent
![]() Value: 0.1
Value: 0.1
All of these limits ensure that a single application, user, or queue cannot cause catastrophic failures or monopolize the cluster and cause unreasonable degradation of cluster performance or utilization.
User Interface
When the ResourceManager is started with Capacity scheduler, a scheduler webpage is available on the main YARN web interface (http://localhost:8080). The scheduler webpage is available by clicking the scheduler link in the left-hand column. As shown in Figure 8.2, the interface shows the queue hierarchy and information about individual queues.
Figure 8.2 Example YARN scheduler GUI
Wrap-up
The Capacity scheduler has been successfully managing large-scale systems for several years. Many of its concepts are directly inherited from the incarnation of CapacityTask-Scheduler in Hadoop version 1. Thanks to knowledge garnered from the YARN community’s experience of running the Capacity scheduler on very large, shared clusters, it has been continuously enhanced to improve upon its original design goals of providing elasticity in computing, a flexible resource model, isolation using appropriate limits, support for multitenancy, and the ability to manage new scheduling policies.
The continuous growth of Hadoop clusters and new users has helped refine the Capacity scheduler to its present form. It has become a useful tool to help manage the operational complexity (at run time) of hierarchical queues, Access Control Lists, and user and application limits; to set reservations; and to manage queue states.