Apache Hadoop YARN: Moving beyond MapReduce and Batch Processing with Apache Hadoop 2 (2014)
9. MapReduce with Apache Hadoop YARN
The introduction of Hadoop version 2 has changed much of how MapReduce applications run on a cluster. Unlike the monolithic MapReduce–Schedule in Hadoop Version 1, Hadoop YARN has generalized the cluster resources available to users. To keep compatibility with Hadoop version 1, the YARN team has written a MapReduce framework that works on top of YARN. The framework is highly compatible with Hadoop version 1, with only a small number of issues to consider. As with Hadoop version 1, Hadoop YARN comes with virtually the same MapReduce examples and benchmarks that help demonstrate how Hadoop YARN functions.
Running Hadoop YARN MapReduce Examples
Running the existing MapReduce examples is a straightforward process. The examples are located in hadoop-[VERSION]/share/hadoop/mapreduce. Depending on where you installed Hadoop, this path may vary. For the purposes of this example, let’s define this path:
export YARN_EXAMPLES=$YARN_HOME/share/hadoop/mapreduce
$YARN_HOME should be defined as part of your installation. Also, the examples given in this section have a version tag—in this case, “2.2.0.” Your installation may have a different version tag. The following discussion provides some examples of Hadoop YARN-based MapReduce programs and benchmarks.
Listing Available Examples
Using our $YARN_HOME environment variable, we can get a list of possible examples by running
$ yarn jar $YARN_EXAMPLES/hadoop-mapreduce-examples-2.2.0.jar
The possible examples are as follows:
An example program must be given as the first argument.
Valid program names are:
aggregatewordcount: An Aggregate based map/reduce program that counts
the words in the input files.
aggregatewordhist: An Aggregate based map/reduce program that computes
the histogram of the words in the input files.
bbp: A map/reduce program that uses Bailey-Borwein-Plouffe to compute
exact digits of Pi.
dbcount: An example job that counts the pageview counts from a database.
distbbp: A map/reduce program that uses a BBP-type formula to compute
exact bits of Pi.
grep: A map/reduce program that counts the matches of a regex in the
input.
join: A job that effects a join over sorted, equally partitioned
data sets
multifilewc: A job that counts words from several files.
pentomino: A map/reduce tile laying program to find solutions to
pentomino problems.
pi: A map/reduce program that estimates Pi using a quasi-Monte Carlo
method.
randomtextwriter: A map/reduce program that writes 10GB of random
textual data per node.
randomwriter: A map/reduce program that writes 10GB of random data per
node.
secondarysort: An example defining a secondary sort to the reduce.
sort: A map/reduce program that sorts the data written by the random
writer.
sudoku: A sudoku solver.
teragen: Generate data for the terasort.
terasort: Run the terasort.
teravalidate: Checking results of terasort
wordcount: A map/reduce program that counts the words in the input
files.
wordmean: A map/reduce program that counts the average length of the
words in the input files.
wordmedian: A map/reduce program that counts the median length of the
words in the input files.
wordstandarddeviation: A map/reduce program that counts the standard
deviation of the length of the words in the input files.
To illustrate several capabilities of Hadoop YARN, we will show how to run the pi benchmark, the terasort examples, and the TestDFSIO benchmark.
Running the Pi Example
To run the pi example with 16 maps and 100,000 samples, enter the following:
$ yarn jar $YARN_EXAMPLES/hadoop-mapreduce-examples-2.2.0.jar pi 16 100000
If the program runs correctly, you should see the following (after the log messages):
13/10/14 20:10:01 INFO mapreduce.Job: map 0% reduce 0%
13/10/14 20:10:08 INFO mapreduce.Job: map 25% reduce 0%
13/10/14 20:10:16 INFO mapreduce.Job: map 56% reduce 0%
13/10/14 20:10:17 INFO mapreduce.Job: map 100% reduce 0%
13/10/14 20:10:17 INFO mapreduce.Job: map 100% reduce 100%
13/10/14 20:10:17 INFO mapreduce.Job: Job job_1381790835497_0003 completed
successfully
13/10/14 20:10:17 INFO mapreduce.Job: Counters: 44
File System Counters
FILE: Number of bytes read=358
FILE: Number of bytes written=1365080
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=4214
HDFS: Number of bytes written=215
HDFS: Number of read operations=67
HDFS: Number of large read operations=0
HDFS: Number of write operations=3
Job Counters
Launched map tasks=16
Launched reduce tasks=1
Data-local map tasks=14
Rack-local map tasks=2
Total time spent by all maps in occupied slots (ms)=174725
Total time spent by all reduces in occupied slots
(ms)=7294
Map-Reduce Framework
Map input records=16
Map output records=32
Map output bytes=288
Map output materialized bytes=448
Input split bytes=2326
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=448
Reduce input records=32
Reduce output records=0
Spilled Records=64
Shuffled Maps =16
Failed Shuffles=0
Merged Map outputs=16
GC time elapsed (ms)=195
CPU time spent (ms)=7740
Physical memory (bytes) snapshot=6143696896
Virtual memory (bytes) snapshot=23140454400
Total committed heap usage (bytes)=4240769024
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=1888
File Output Format Counters
Bytes Written=97
Job Finished in 20.854 seconds
Estimated value of Pi is 3.14127500000000000000
Notice that the MapReduce progress is shown in the same way as in MapReduce version 1, but the application statistics are different. Most of the statistics are self-explanatory. The one important item to note is that the YARN “Map-Reduce Framework” is used to run the program. The use of this framework, which is designed to be compatible with Hadoop version 1, will be discussed further later in this chapter.
Using the Web GUI to Monitor Examples
The Hadoop YARN web GUI differs from the web GUI found in Hadoop version 1. This section provides an illustration of how to use the web GUI to monitor and find information about YARN jobs. Figure 9.1 shows the main YARN web interface (http://hostname:8088). For this example, we use the pi application, which can run quickly and finish before you have explored the GUI. A longer-running application, like terasort, may be helpful when exploring all the various links in the GUI.
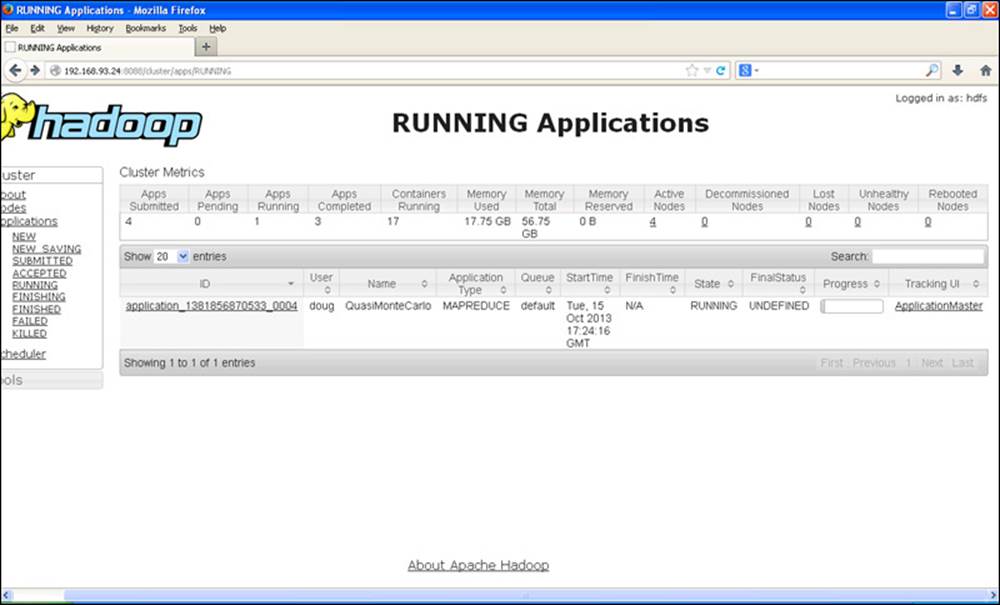
Figure 9.1 Hadoop YARN running applications web GUI for pi example
If you look at the Cluster Metrics table, you will see some new information. First, you will notice that rather than Hadoop version 1 “Map/Reduce Task Capacity,” there is now information on the number of running containers. If YARN is running a MapReduce job, these containers will be used for both map and reduce tasks. Unlike in Hadoop version 1, the number of mappers and reducers is not fixed. There are also memory metrics and links to node status. If you click on the nodes link, you can get a summary of the node activity. For example, Figure 9.2 is a snapshot of the node activity while the pi application is running. Note again the number of containers, which are used by the MapReduce framework as either mappers or reducers.
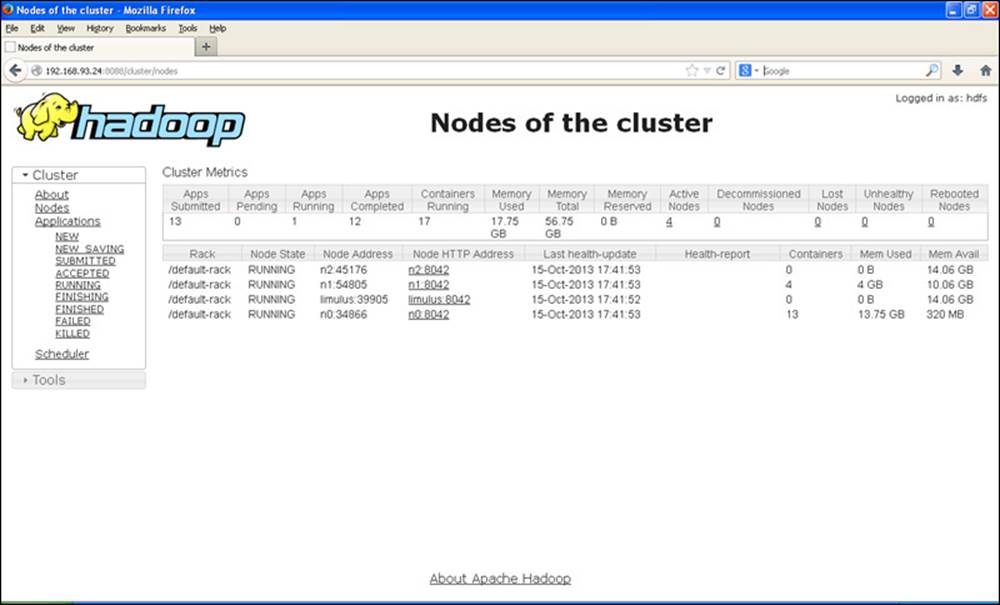
Figure 9.2 Hadoop YARN nodes status window
Going back to the main Applications/Running window, if you click on the application_138... link, the Application status window in Figure 9.3 will be presented. This window provides similar information as the Running Applications window, but only for the selected job.
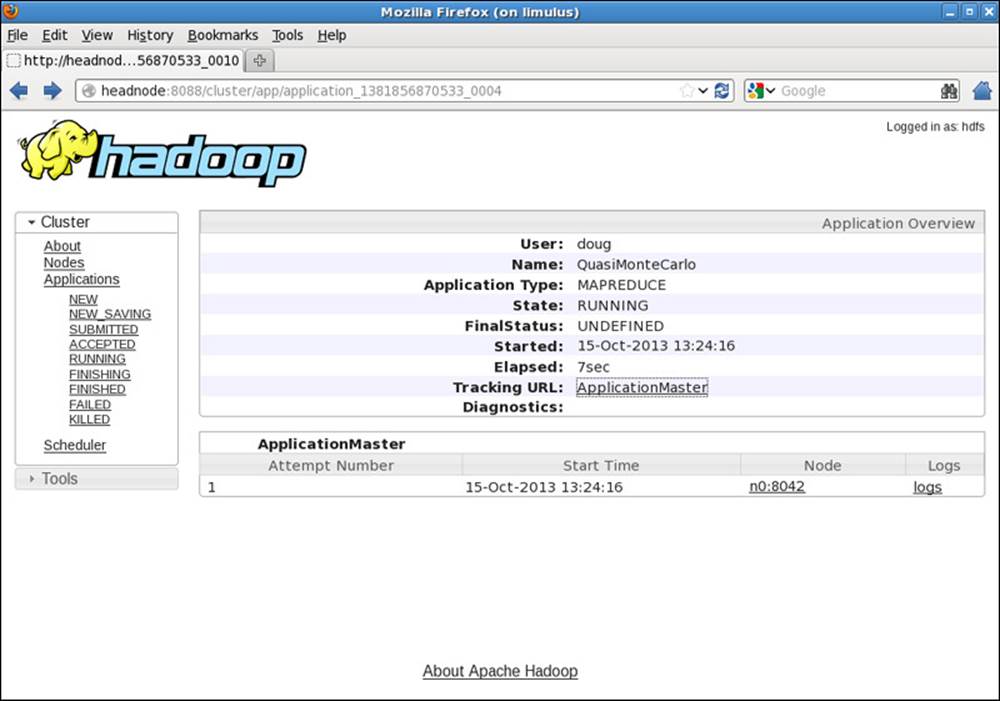
Figure 9.3 Hadoop YARN application status for pi example
Clicking on the ApplicationMaster link in Figure 9.3 takes us to the window shown in Figure 9.4. Note that the link to the application’s ApplicationMaster is also found on the main Running Applications screen in the last column.
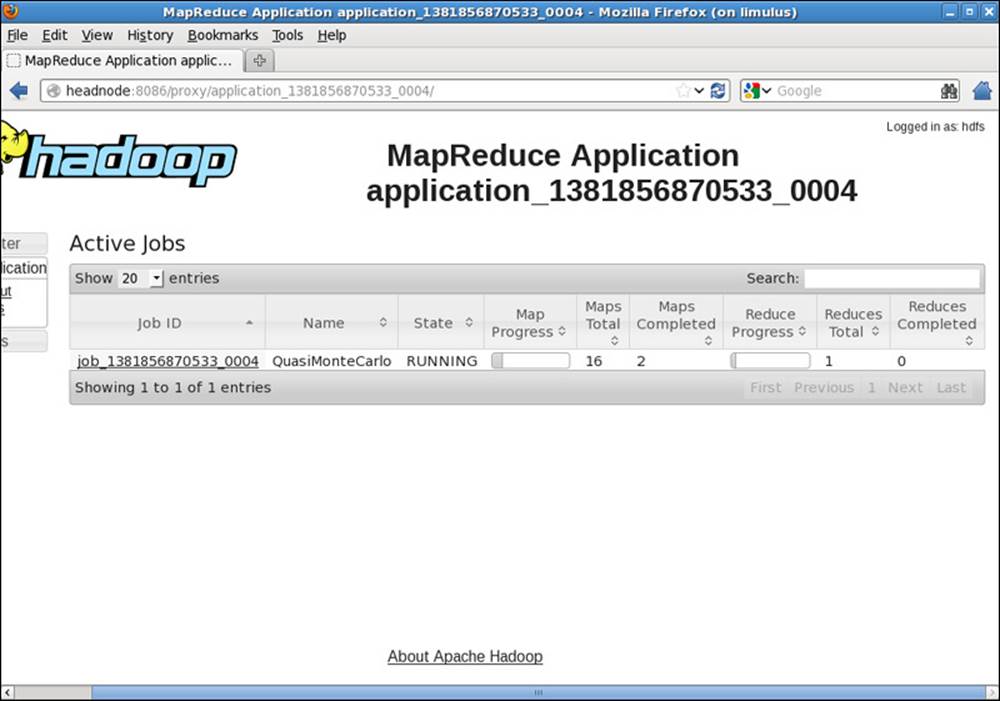
Figure 9.4 Hadoop YARN ApplicationMaster for MapReduce application
In the MapReduce Application window, the details of the MapReduce job can be observed. Clicking on the job_138... brings up the window shown in Figure 9.5. (Your job number will be different.)
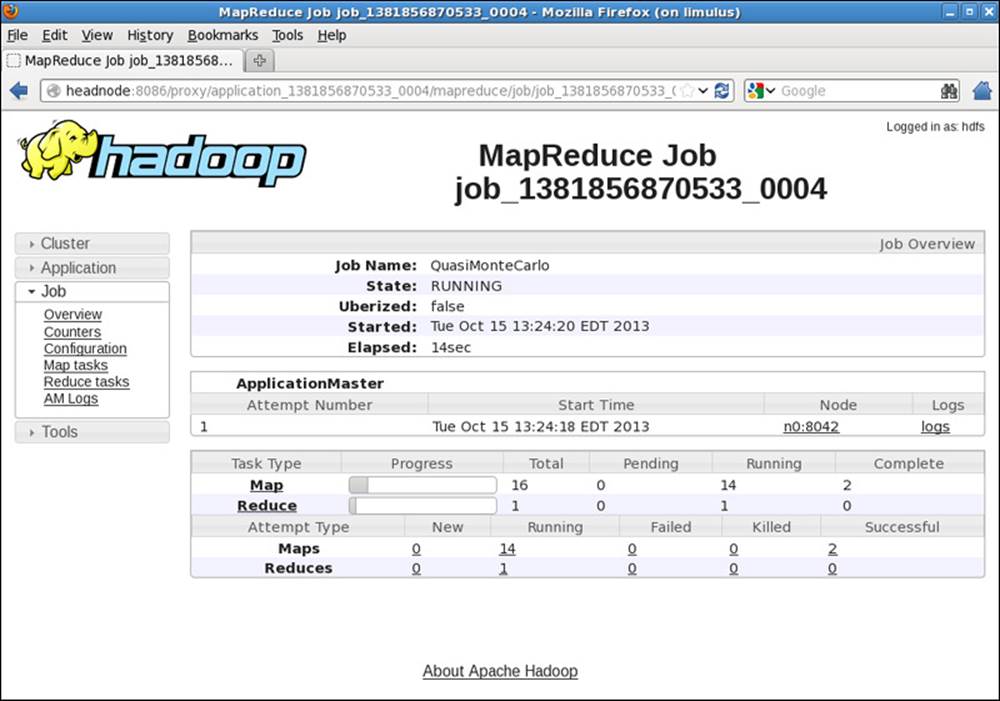
Figure 9.5 Hadoop YARN MapReduce job progress
The status of the job is now presented in more detail. When the job is finished, the window is updated to that shown in Figure 9.6.
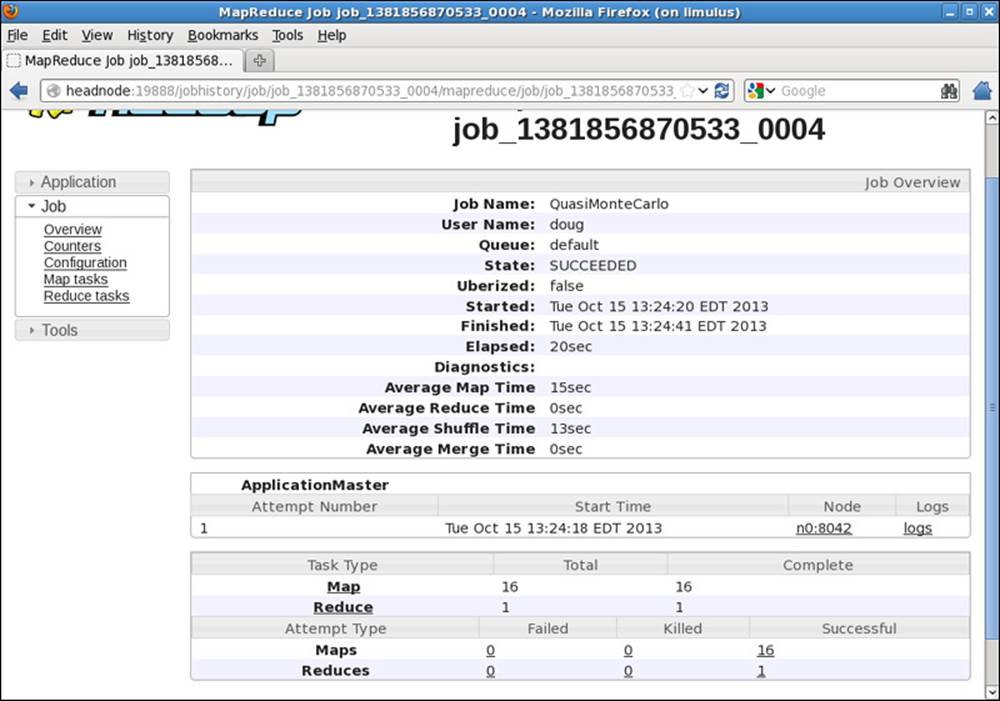
Figure 9.6 Hadoop YARN completed MapReduce job summary
If you click on the node used to run the ApplicationMaster (n0:8042 in our example), the window in Figure 9.7 opens and provides a summary from the NodeManager. Again, the NodeManager tracks only containers; the actual tasks that the containers run are determined by the ApplicationMaster.
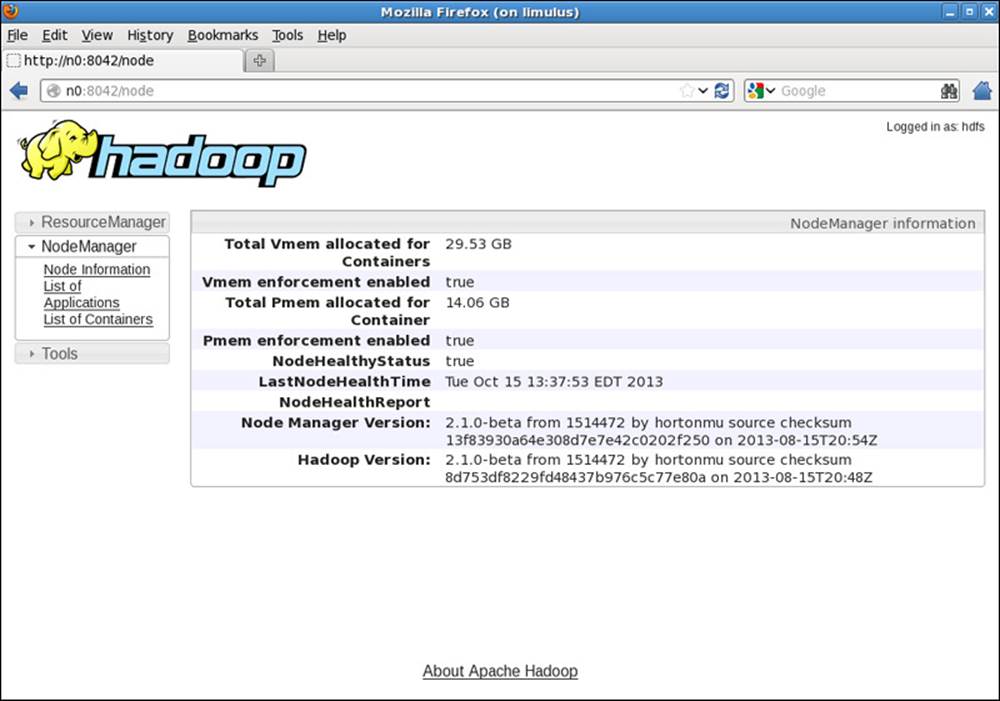
Figure 9.7 Hadoop YARN NodeManager job summary
Going back to the job summary page, you can also examine the logs for the ApplicationMaster by clicking the “logs” link. In the resulting window, shown in Figure 9.8, stdout, stderr, and the syslog can all be browsed.
Figure 9.8 Hadoop YARN NodeManager logs available for browsing
If we return to the main cluster window, choose Applications/Finished, and then select our job, we will see the summary page shown in Figure 9.9.
Figure 9.9 Hadoop YARN application summary page
There are a few things to notice as we moved through the windows as described previously. First, because YARN manages applications, all input from YARN refers to an application. YARN has no data about the actual application. Data from the MapReduce job are provided by the MapReduce framework. Thus there are two clearly different data streams that are combined in the web GUI: YARN applications and MapReduce framework jobs. If the framework does not provide job information, then certain parts of the web GUI will have nothing to display.
Another interesting aspect to note is the dynamic nature of the mapper and reducer tasks. These are executed as YARN containers, and their number will change as the application runs. This feature provides much better cluster utilization due to the absence of static slots.
Finally, other links in the windows can be explored (e.g., the History link in Figure 9.9). With the MapReduce framework, it is possible to drill down to the individual map and reduce tasks. If log aggregation is enabled (see Chapter 6, “Apache Hadoop YARN Administration”), then the individual logs for each map and reduce task can be viewed.
Running the Terasort Test
To run the terasort benchmark, three separate steps are required. In general, the rows are 100 bytes long; thus the total amount of data written is 100 times the number of rows (i.e., to write 100 GB of data, use 1,000,000,000 rows). You will also need to specify input and output directories in HDFS.
1. Run teragen to generate rows of random data to sort.
$ yarn jar $YARN_EXAMPLES/hadoop-mapreduce-examples-2.2.0.jar teragen <number of 100-byte rows> <output dir>
2. Run terasort to sort the database.
$ yarn jar $YARN_EXAMPLES/hadoop-mapreduce-examples-2.2.0.jar terasort <input dir> <output dir>
3. Run teravalidate to validate the sort teragen.
$ yarn jar $YARN_EXAMPLES/hadoop-mapreduce-examples-2.2.0.jar teravalidate <terasort output dir> <teravalidate output dir>
Run the TestDFSIO Benchmark
YARN also includes an HDFS benchmark application called TestDFSIO. Similar to terasort, it has several steps. We will write and read ten 1 GB files.
1. Run TestDFSIO in write mode and create data.
$ yarn jar $YARN_EXAMPLES/hadoop-mapreduce-client-jobclient-2.2.0-tests.jar TestDFSIO -write -nrFiles 10 -fileSize 1000
Example results are as follows (date and time removed):
fs.TestDFSIO: ----- TestDFSIO ----- : write
fs.TestDFSIO: Date & time: Wed Oct 16 10:58:20 EDT 2013
fs.TestDFSIO: Number of files: 10
fs.TestDFSIO: Total MBytes processed: 10000.0
fs.TestDFSIO: Throughput mb/sec: 10.124306231915458
fs.TestDFSIO: Average IO rate mb/sec: 10.125661849975586
fs.TestDFSIO: IO rate std deviation: 0.11729341192174683
fs.TestDFSIO: Test exec time sec: 120.45
fs.TestDFSIO:
2. Run TestDFSIO in read mode.
$ yarn jar $YARN_EXAMPLES/hadoop-mapreduce-client-jobclient-2.2.0-tests.jar TestDFSIO -read -nrFiles 10 -fileSize 1000
Example results are as follows (date and time removed):
fs.TestDFSIO: ----- TestDFSIO ----- : read
fs.TestDFSIO: Date & time: Wed Oct 16 11:09:00 EDT 2013
fs.TestDFSIO: Number of files: 10
fs.TestDFSIO: Total MBytes processed: 10000.0
fs.TestDFSIO: Throughput mb/sec: 40.946519750553804
fs.TestDFSIO: Average IO rate mb/sec: 45.240928649902344
fs.TestDFSIO: IO rate std deviation: 18.27387874605978
fs.TestDFSIO: Test exec time sec: 47.937
fs.TestDFSIO:
3. Clean up the TestDFSIO data.
$ yarn jar $YARN_EXAMPLES/hadoop-mapreduce-client-jobclient-2.2.0-tests.jar TestDFSIO -clean
MapReduce Compatibility
MapReduce was the original use-case for which Hadoop was developed. To graph the World Wide Web and illustrate how it changes over time, MapReduce was developed to process this graph and its billions of nodes and trillions of edges. Moving this technology to YARN made it a complex application to build due to the requirements for data locality, fault tolerance, and application priorities.
To provide data locality, the MapReduce ApplicationMaster is required to locate blocks for processing and then request containers on these blocks. To implement fault tolerance, the ability to handle failed map or reduce tasks and request them again on other nodes was needed. Fault tolerance moved hand-in-hand with the complex intra-application priorities.
The logic to handle complex intra-application priorities for map and reduce tasks had to be built into the ApplicationMaster. There is no need to start idle reducers before mappers finish processing enough data. Reducers are now under control of the ApplicationMaster and are not fixed, as they had been in Hadoop version 1.
One rather unique failure mode occurs when a node fails after all the maps have finished. When this happens, the map task must be repeated because the results are unavailable. In many cases, all available containers are being used by the reducer tasks, preventing the spawning of another mapper task to process the missing data. Logically, this would create a deadlock with reducers waiting for missing mapper data. The MapReduce ApplicationMaster has been designed to detect this situation and, while the solution is not ideal, will kill enough reducers to free up sufficient resources for mappers to finish processing the missing data. The killed reducer will then start again, allowing the job to complete.
The MapReduce ApplicationMaster
The MapReduce ApplicationMaster is implemented as a composition of loosely coupled services. The services interact with one another via events. Each component acts on the received events and sends out any required events to other components. This design keeps it highly concurrent, with no or minimal synchronization needs. The events are dispatched by a central Dispatch mechanism. All components register with the Dispatcher, and this information is shared across different components using AppContext.
In Hadoop version 1, the death of the JobTracker would result in the loss of all jobs, both running and queued. With YARN, the ApplicationMaster is a MapReduce job that serves as the equivalent to the JobTracker. The ApplicationMaster will now run on compute nodes, which can lead to an increase in failure scenarios. To combat the threat of MapReduce ApplicationMaster failures, YARN has the capability to restart the ApplicationMaster a specified number of times and the capability to recover completed tasks. Additionally, much like the JobTracker, the ApplicationMaster keeps metrics for jobs that are currently running. Typically, the ApplicationMaster tracking URL makes these metrics available and can be found as part of the YARN web GUI (discussed in the earlier pi example). The following setting can enable MapReduce recovery in YARN.
Enabling Application Master Restarts
To enable ApplicationMaster restarts, do the following:
1. Inside yarn-site.xml, you can tune the property yarn.resourcemanager.am.max-retries. The default is 2.
2. Inside mapred-site.xml, you can more directly tune how many times a MapReduce ApplicationMaster should restart with the property mapreduce.am.max-attempts. The default is 2.
Enabling Recovery of Completed Tasks
To enable recovery of completed tasks, look inside the mapred-site.xml file. The property yarn.app.mapreduce.am.job.recovery.enable enables the recovery of tasks. By default, it is true.
The JobHistory Server
With the ApplicationMaster now taking the place of the JobTracker, a centralized location for the history of all MapReduce jobs was required. The JobHistory server helps fill the void left by the transitory ApplicationMaster by hosting these completed job metrics and logs. This new history daemon is unrelated to the services provided by YARN and is directly tied to the MapReduce application framework.
Calculating the Capacity of a Node
Since YARN has now removed the hard-partitioned mapper and reducer slots of Hadoop version 1, new capacity calculations are required. There are eight important parameters for calculating a node’s capacity; they are found in the mapred-site.xml and yarn-site.xml files.
![]() mapred-site.xml
mapred-site.xml
![]() mapreduce.map.memory.mb
mapreduce.map.memory.mb
mapreduce.reduce.memory.mb
The hard limit enforced by Hadoop on the mapper or reducer task.
![]() mapreduce.map.java.opts
mapreduce.map.java.opts
mapreduce.reduce.java.opts
The heap size of the jvm –Xmx for the mapper or reducer task. Remember to leave room for the JVM Perm Gen and Native Libs used. This value should always be smaller than mapreduce.[map|reduce].memory.mb.
![]() yarn-site.xml
yarn-site.xml
![]() yarn.scheduler.minimum-allocation-mb
yarn.scheduler.minimum-allocation-mb
The smallest container YARN will allow.
![]() yarn.scheduler.maximum-allocation-mb
yarn.scheduler.maximum-allocation-mb
The largest container YARN will allow.
![]() yarn.nodemanager.resource.memory-mb
yarn.nodemanager.resource.memory-mb
The amount of physical memory (RAM) on the compute node for containers. It is important that this value isn’t the total RAM on the node, as other Hadoop services also require RAM.
![]() yarn.nodemanager.vmem-pmem-ratio
yarn.nodemanager.vmem-pmem-ratio
The amount of virtual memory each container is allowed. This is calculated by the following formula: containerMemoryRequest*vmem-pmem-ratio.
As an example, consider a configuration with the settings in Table 9.1. Using these settings, we have given each map and reduce task a generous 512 MB of overhead for the container, as seen with the difference between the mapreduce.[map|reduce].memory.mb and themapreduce.[map|reduce].java.opts.

Table 9.1 Example YARN MapReduce Settings
Next YARN has been configured to allow a container no smaller than 512 MB and no larger than 4 GB; the compute nodes have 36 GB of RAM available for containers. With a virtual memory ratio of 2.1 (the default value), each map can have as much as 3225.6 MB and a reducer can have 5376 MB of virtual memory. Thus our compute node configured for 36 GB of container space can support up to 24 maps or 14 reducers, or any combination of mappers and reducers allowed by the available resources on the node.
Changes to the Shuffle Service
As in Hadoop version 1, the shuffle functionality is required for parallel MapReduce job operation. Reducers fetch the outputs from all the maps by “shuffling” map output data from the corresponding nodes where map tasks have run. The MapReduce shuffle functionality is implemented as an auxiliary service in the NodeManager. This service starts up a Netty web server in the NodeManager address space and knows how to handle MapReduce-specific shuffle requests from reduce tasks. The MapReduce ApplicationMaster specifies the service ID for the shuffle service, along with security tokens that may be required when the ApplicationMaster starts any container. In the returning response, the NodeManager provides the ApplicationMaster with the port on which the shuffle service is running, which is then passed on to the reduce tasks.
Hadoop version 2 also provides the option for encrypted shuffle. With encrypted shuffle functionality, the ability to use HTTPS with optional client authentication is possible. The feature is implemented with a toggle for HTTP or HTTPS, keystore/truststore properties, and the distribution of these stores to new and existing nodes. For details of the multistep configuration of encrypted shuffle, it is recommended that users read the most current documentation for this feature on the Apache Hadoop website.
Running Existing Hadoop Version 1 Applications
To ease the transition from Hadoop version 1 to YARN, a major goal of YARN and the MapReduce framework implementation on top of YARN is to ensure that existing MapReduce applications that were programmed and compiled against previous MapReduce APIs (we’ll call these MRv1 applications) can continue to run with little work on top of YARN (we’ll call these MRv2 applications).
Binary Compatibility of org.apache.hadoop.mapred APIs
For the vast majority of users who use the org.apache.hadoop.mapred APIs, MapReduce on YARN ensures full binary compatibility. These existing applications can run on YARN directly without recompilation. You can use jar files of your existing application that code against MapReduce APIs, and use bin/hadoop to submit them directly to YARN.
Source Compatibility of org.apache.hadoop.mapreduce APIs
Unfortunately, it has proved difficult to ensure full binary compatibility of applications that were originally compiled against MRv1 org.apache.hadoop.mapreduce APIs. These APIs have gone through lots of changes. For example, a bunch of classes stopped being abstract classes and changed to interfaces. The YARN community eventually reached a compromise on this issue, supporting source compatibility only for org.apache.hadoop.mapreduce APIs. Existing applications using MapReduce APIs are source compatible and can run on YARN either with no changes, with simple recompilation against MRv2 jar files that are shipped with Hadoop version 2, or with minor updates.
Compatibility of Command-line Scripts
Most of the command-line scripts from Hadoop 1.x should just work, without any tweaking. The only exception is MRAdmin, whose functionality was removed from MRv2 because JobTracker and TaskTracker no longer exist. The MRAdmin functionality has been replaced with RMAdmin. The suggested method to invoke MRAdmin (as well as RMAdmin) is through the command line, even though one can directly invoke the APIs. In YARN, when mradmin commands are executed, warning messages will appear, reminding users to use YARN commands (i.e., rmadmincommands). Conversely, if the user’s applications programmatically invoke MRAdmin, those applications will break when running on top of YARN. There is no support for either binary or source compatibility under YARN.
Compatibility Tradeoff Between MRv1 and Early MRv2 (0.23.x) Applications
Unfortunately, there are some APIs that may be compatible either with MRv1 applications or with early MRv2 applications (in particular, the applications compiled against Hadoop 0.23), but not both. Some of these APIs were exactly the same in both MRv1 and MRv2, except for the return type change in their method signatures. Therefore, we were forced to trade off the compatibility between the two.
![]() We decided to make MapReduce APIs be compatible with MRv1 applications, which have a larger user base.
We decided to make MapReduce APIs be compatible with MRv1 applications, which have a larger user base.
![]() If MapReduce APIs don’t significantly break Hadoop 0.23 applications, we made the same decision of making them compatible with version 0.23 but only source compatible with 1.x versions.
If MapReduce APIs don’t significantly break Hadoop 0.23 applications, we made the same decision of making them compatible with version 0.23 but only source compatible with 1.x versions.
Table 9.2 lists the APIs that are incompatible with Hadoop 0.23. If early Hadoop 2 adopters using 0.23.x versions included the following methods in their custom routines, they must modify the code accordingly. For some problematic methods, we provided an alternative method with the same functionality and similar method signature to MRv2 applications.

Table 9.2 MRv2 Incompatible APIs
Running MapReduce Version 1 Existing Code
Most of the MRv1 examples continue to work on YARN, except that they are now present in a newly versioned jar file. One exception worth mentioning is that the sleep example, which was originally found in hadoop-examples-1.x.x.jar, is no longer in hadoop-mapreduce-examples-2.x.x.jar but rather was moved into the test jar hadoop-mapreduce-client-jobclient-2.x.x-tests.jar.
That exception aside, users may want to directly try hadoop-examples-1.x.x.jar on YARN. Running hadoop -jar hadoop-examples-1.x.x.jar will still pick the classes in hadoop-mapreduce-examples-2.x.x.jar. This behavior is due to Java first searching the desired class in the system jar files; if the class is not found there, it will go on to search in the user jar files in classpath.hadoop-mapreduce-examples-2.x.x.jar, which is installed together with other MRv2 jar files in the Hadoop class path. Thus the desired class (e.g., WordCount) will be picked from this 2.x.x jar file instead of the 1.x.x jar file. However, it is possible to let Java pick the classes from the jar file that is specified after -jar option. Users have two options:
![]() Add HADOOP\_USER\_CLASSPATH\_FIRST=true and HADOOP\_CLASSPATH=...:hadoop-examples-1.x.x.jar as environment variables, and add mapreduce.job.user.classpath.first = true in mapred-site.xml.
Add HADOOP\_USER\_CLASSPATH\_FIRST=true and HADOOP\_CLASSPATH=...:hadoop-examples-1.x.x.jar as environment variables, and add mapreduce.job.user.classpath.first = true in mapred-site.xml.
![]() Remove the 2.x.x jar from the class path. If it is a multiple-node cluster, the jar file needs to be removed from the class path on all the nodes.
Remove the 2.x.x jar from the class path. If it is a multiple-node cluster, the jar file needs to be removed from the class path on all the nodes.
Running Apache Pig Scripts on YARN
Pig is one of the two major data process applications in the Hadoop ecosystem, with the other being Hive. Because of significant efforts from the Pig community, Pig scripts of existing users don’t need any modifications. Pig on YARN in Hadoop 0.23 has been supported since version 0.10.0 and Pig working with Hadoop 2.x has been supported since version 0.10.1.
Existing Pig scripts that work with Pig 0.10.1 and beyond will work just fine on top of YARN. In contrast, versions earlier than Pig 0.10.x may not run directly on YARN due to some of the incompatible MapReduce APIs and configuration.
Running Apache Hive Queries on YARN
Hive queries of existing users don’t need any change to work on top of YARN, starting with Hive 0.10.0, thanks to the work done by Hive community. Support for Hive to work on YARN in the Hadoop 0.23 and 2.x releases has been in place since version 0.10.0. Queries that work in Hive 0.10.0 and beyond will work without changes on top of YARN. However, as with Pig, earlier versions of Hive may not run directly on YARN, as those Hive releases don’t support Hadoop 0.23 and 2.x.
Running Apache Oozie Workflows on YARN
Like the Pig and Hive communities, the Apache Oozie community worked to make sure existing Oozie workflows would run in a completely backward-compatible manner on Hadoop version 2. Support for Hadoop 0.23 and 2.x is available starting with Oozie release 3.2.0. Existing Oozie workflows can start taking advantage of YARN in versions 0.23 and 2.x with Oozie 3.2.0 and above.
Advanced Features
The following features are included in Hadoop version 2 but have not been extensively tested. The user community is encouraged to play with these features and provide feedback to the Apache Hadoop community.
Uber Jobs
An Uber Job occurs when multiple mapper and reducers are combined to use a single container. There are four core settings around the configuration of Uber Jobs found in the mapred-site.xml options presented in Table 9.3.

Table 9.3 Configuration Options for Uber Jobs
Pluggable Shuffle and Sort
This plug-in allows users to replace built-in shuffle and sort logic with alternative paradigms but is currently considered unstable. These properties can be set on a per-job basis, as shown in Table 9.4, or as a site-wide property, as shown in Table 9.5. The properties identified in Table 9.4 can also be set in mapred-site.xml to change the default values for all jobs. Use-cases include protocol changes between mappers and reducers as well as the use of custom algorithms enabling new types of sorting. While the NodeManagers handle all shuffle services for the default shuffle, any pluggable shuffle and sort configurations will run in the job tasks themselves.

Table 9.4 Job Configuration Properties (on a Per-Job Basis)

Table 9.5 NodeManager Configuration Properties (yarn-site.xml on All Nodes)
Important
If you are setting an auxiliary service in addition to the default mapreduce_shuffle service, then you should add a new service key to the yarn.nodemanager.aux-services property—for example, mapreduce_shufflex. Then the property defining the corresponding class must be yarn.nodemanager.aux-services.mapreduce_shufflex.class.
Wrap-up
Running Hadoop version 1 MapReduce applications on Hadoop YARN has been made as simple and as compatible as possible. Because MapReduce is now a YARN framework, the execution life cycle is different than that found in Hadoop version 1. The results are the same, however.
The shift from discrete mappers and reducers to containers can be seen by running and monitoring the example MapReduce programs with the web GUI. The distinction between YARN containers and MapReduce mappers and reducers is clearly evident in these examples.
In most cases, Hadoop YARN version 2 provides source code compatibility with all Hadoop version 1 MapReduce code. There is also a fair amount of binary compatibility with many applications, such as Pig and Hive.