Apache Hadoop YARN: Moving beyond MapReduce and Batch Processing with Apache Hadoop 2 (2014)
7. Apache Hadoop YARN Architecture Guide
Chapter 4 provided a functional overview of YARN components and a brief description of how a YARN application flows through the system. In this chapter, we will delve deeper into the inner workings of YARN and describe how the system is implemented from the ground up.
YARN separates all of its functionality into two layers: a platform layer responsible for resource management and what is called first-level scheduling, and a framework layer that coordinates application execution and second-level scheduling. Specifically, a per-cluster ResourceManagertracks usage of resources, monitors the health of various nodes in the cluster, enforces resource-allocation invariants, and arbitrates conflicts among users. By separating these multiple duties that were previously shouldered by a single daemon, the JobTracker, in Hadoop version 1, the ResourceManager can simply allocate resources centrally based on a specification of an application’s requirements, but ignore how the application makes use of those resources. That responsibility is delegated to an ApplicationMaster, which coordinates the logical execution of a single application by requesting resources from the ResourceManager, generating a physical plan of its work, making use of the resources it receives, and coordinating the execution of such a physical plan.
Overview
The ResourceManager and NodeManagers running on individual nodes come together to form the core of YARN and constitute the platform. ApplicationMasters and the corresponding containers come together to form a YARN application. This separation of concerns is shown in Figure 7.1. From YARN’s point of view, all users interact with it by submitting applications that then make use of the resources offered by the platform. From end-users’ perspective, they may either (1) directly interact with YARN by running applications directly on the platform or (2) interact with aframework, which in turn runs as an application on top of YARN. Frameworks may expose a higher-level functionality to the end-users. As an example, the MapReduce code that comes bundled with Apache Hadoop can be looked at as a framework running on top of YARN. On the one hand, MapReduce gives to the users a map and reduce abstraction that they can code against, with the framework taking care of the gritty details of running smoothly on a distributed system—failure handling, reliability, resource allocation, and so. On the other hand, MapReduce uses the underlying platform’s APIs to implement such functionality.
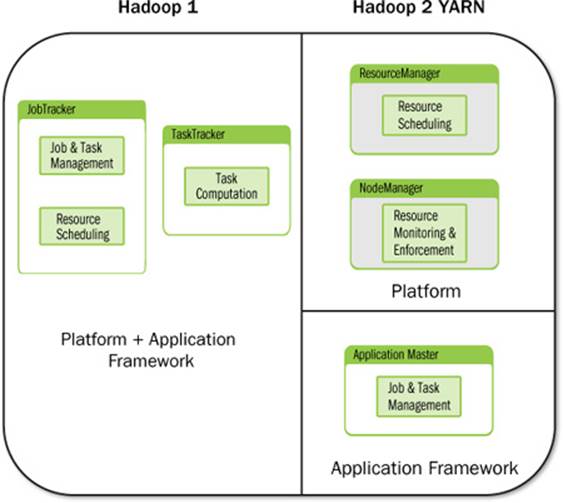
Figure 7.1 Hadoop version 1 with integrated platform and applications framework versus Hadoop version 2 with separate platform and application framework
The overall architecture is described in Figure 7.2. The ResourceManager provides scheduling of applications. Each application is managed by an ApplicationMaster (per-task manager) that requests per-task computation resources in the form of containers. Containers are scheduled by the ResourceManager and locally managed by the per-node NodeManager.
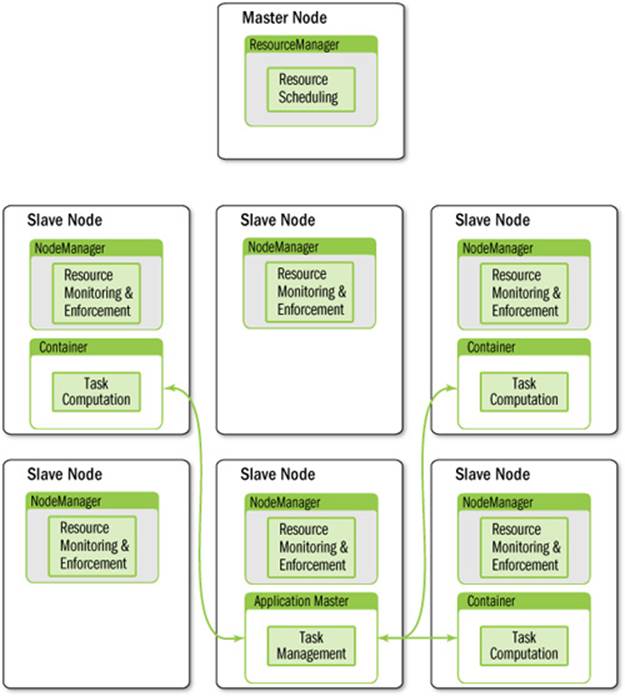
Figure 7.2 YARN architectural overview
A detailed description of the responsibilities and components of the ResourceManager, NodeManager, and ApplicationMaster follows.
ResourceManager
As previously described, the ResourceManager is the master that arbitrates all the available cluster resources, thereby helping manage the distributed applications running on the YARN platform. It works together with the following components:
![]() The per-node NodeManagers, which take instructions from the ResourceManager, manage resources available on a single node, and accept container requests from ApplicationMasters
The per-node NodeManagers, which take instructions from the ResourceManager, manage resources available on a single node, and accept container requests from ApplicationMasters
![]() The per-application ApplicationMasters, which are responsible for negotiating resources with the ResourceManager and for working with the NodeManagers to start, monitor, and stop the containers
The per-application ApplicationMasters, which are responsible for negotiating resources with the ResourceManager and for working with the NodeManagers to start, monitor, and stop the containers
Overview of the ResourceManager Components
The ResourceManager components are illustrated in Figure 7.3. To better describe the workings of each component, they will be introduced separately by grouping them corresponding to each external entity for which they provide services: clients, the NodeManagers, the ApplicationMasters, or other internal core components.
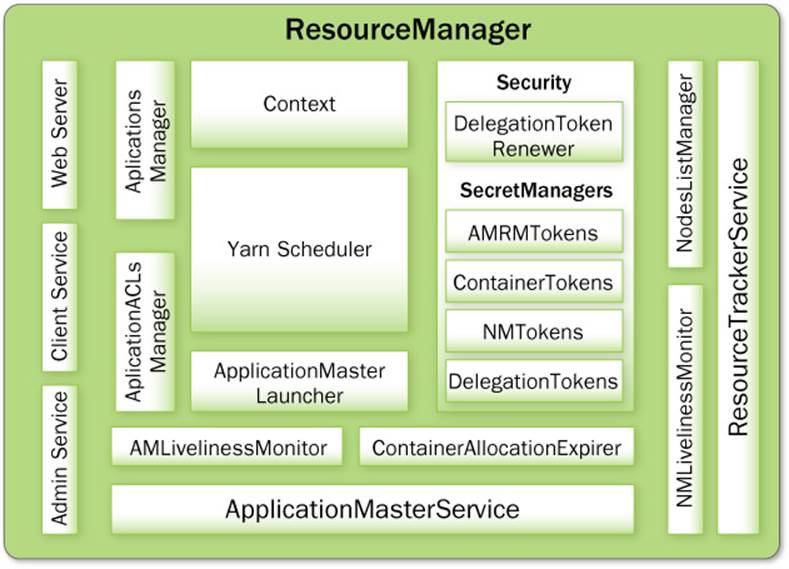
Figure 7.3 ResourceManager components
Client Interaction with the ResourceManager
The first interaction point of a user with the platform comes in the form of a client to the ResourceManager. The following components in ResourceManager interact with the client.
Client Service
This service implements ApplicationClientProtocol, the basic client interface to the ResourceManager. This component handles all the remote procedure call (RPC) communications to the ResourceManager from the clients, including operations such as the following:
![]() Application submission
Application submission
![]() Application termination
Application termination
![]() Exposing information about applications, queues, cluster statistics, user ACLs, and more
Exposing information about applications, queues, cluster statistics, user ACLs, and more
Client Service provides additional protection to the ResourceManager depending on whether the administrator configured YARN to run in secure or nonsecure mode. In secure mode, the Client Service makes sure that all incoming requests from users are authenticated (for example, by Kerberos) and then authorizes each user by looking up application-level Access Control Lists (ACLs) and subsequently queue-level ALCs. For all clients that cannot be authenticated with Kerberos directly, this service also exposes APIs to obtain what are known as the ResourceManager delegation tokens. Delegation tokens are special objects that a Kerberos-authenticated client can first obtain by securely communicating with the ResourceManager and then pass along to its nonauthenticated processes. Any client process that has a handle to these delegation tokens can communicate with ResourceManager securely without separately authenticating with Kerberos first.
Administration Service
While Client Service is responsible for typical user invocations like application submission and termination, there is a list of activities that administrators of a YARN cluster have to perform from time to time. To make sure that administration requests don’t get starved by the regular users’ requests and to give the operators’ commands a higher priority, all of the administrative operations are served via a separate interface called Administration Service. ResourceManagerAdministrationProtocol is the communication protocol that is implemented by this component. Some of the important administrative operations are highlighted here:
![]() Refreshing queues: for example, adding new queues, stopping existing queues, and reconfiguring queues to change some of their properties like capacities, limits, and more
Refreshing queues: for example, adding new queues, stopping existing queues, and reconfiguring queues to change some of their properties like capacities, limits, and more
![]() Refreshing the list of nodes handled by the ResourceManager: for example, adding newly installed nodes or decommissioning existing nodes for various reasons
Refreshing the list of nodes handled by the ResourceManager: for example, adding newly installed nodes or decommissioning existing nodes for various reasons
![]() Adding new user-to-group mappings, adding/updating administrator ACLs, modifying the list of superusers, and so on
Adding new user-to-group mappings, adding/updating administrator ACLs, modifying the list of superusers, and so on
Both Client Service and Administration Service work closely with ApplicationManager for ACL enforcement.
Application ACLs Manager
The ResourceManager needs to gate the user-facing APIs like the client and administrative requests so that they are accessible only to authorized users. This component maintains the ACLs per application and enforces them. Application ACLs are enabled on the ResourceManager by setting to true the configuration property yarn.acl.enable. There are two types of application accesses: (1) viewing and (2) modifying an application. ACLs against the view access determine who can “view” some or all of the application-related details on the RPC interfaces, web UI, and web services. The modify-application ACLs determine who can “modify” the application (e.g., kill the application).
An ACL is a list of users and groups who can perform a specific operation. Users can specify the ACLs for their submitted application as part of the ApplicationSubmissionContext. These ACLs are tracked per application by the ACLsManager and used for access control whenever a request comes in. Note that irrespective of the ACLs, all administrators (determined by the configuration property yarn.admin.acl) can perform any operation.
The same ACLs are transferred over to the ApplicationMaster so that the ApplicationMaster itself can use them for users accessing various services running inside the ApplicationMaster. The NodeManager also receives the same ACLs as part of ContainerLaunchContext (discussed later in this chapter) when a container is launched which then uses them for access control to serve requests about the applications/containers, mainly about their status, application logs, etc.
ResourceManager Web Application and Web Services
The ResourceManager has a web application that exposes information about the state of the cluster; metrics; lists of active, healthy, and unhealthy nodes; lists of applications, their state and status; hyper-references to the ApplicationMaster web interfaces; and a scheduler-specific interface.
Application Interaction with the ResourceManager
Once an application goes past the client-facing services in the ResourceManager and is accepted into the system, it travels through the internal machinery of the ResourceManager that is responsible for launching the ApplicationMaster. The following describes how the ApplicationMasters interact with the ResourceManager once they have started.
ApplicationMasters Service
This component responds to requests from all the ApplicationMasters. It implements ApplicationMasterProtocol, which is the one and only protocol that ApplicationMasters use to communicate with the ResourceManager. It is responsible for the following tasks:
![]() Registration of new ApplicationMasters
Registration of new ApplicationMasters
![]() Termination/unregistering of requests from any finishing ApplicationMasters
Termination/unregistering of requests from any finishing ApplicationMasters
![]() Authorizing all requests from various ApplicationMasters to make sure that only valid ApplicationMasters are sending requests to the corresponding Application entity residing in the ResourceManager
Authorizing all requests from various ApplicationMasters to make sure that only valid ApplicationMasters are sending requests to the corresponding Application entity residing in the ResourceManager
![]() Obtaining container allocation and deallocation requests from all running ApplicationMasters and forwarding them asynchronously to the YarnScheduler
Obtaining container allocation and deallocation requests from all running ApplicationMasters and forwarding them asynchronously to the YarnScheduler
The ApplicationMasterService has additional logic to make sure that—at any point in time—only one thread in any ApplicationMaster can send requests to the ResourceManager. All the RPCs from ApplicationMasters are serialized on the ResourceManager, so it is expected that only one thread in the ApplicationMaster will make these requests.
This component works closely with ApplicationMaster liveliness monitor described next.
ApplicationMaster Liveliness Monitor
To help manage the list of live ApplicationMasters and dead/non-responding ApplicationMasters, this monitor keeps track of each ApplicationMaster and its last heartbeat time. Any ApplicationMaster that does not produce a heartbeat within a configured interval of time—by default, 10 minutes—is deemed dead and is expired by the ResourceManager. All containers currently running/allocated to an expired ApplicationMaster are marked as dead. The ResourceManager reschedules the same application to run a new Application Attempt on a new container, allowing up to a maximum of two such attempts by default.
Interaction of Nodes with the ResourceManager
The following components in the ResourceManager interact with the NodeManagers running on cluster nodes.
Resource Tracker Service
NodeManagers periodically send heartbeats to the ResourceManager, and this component of the ResourceManager is responsible for responding to such RPCs from all the nodes. It implements the ResourceTracker interface to which all NodeManagers communicate. Specifically, it is responsible for the following tasks:
![]() Registering new nodes
Registering new nodes
![]() Accepting node heartbeats from previously registered nodes
Accepting node heartbeats from previously registered nodes
![]() Ensuring that only “valid” nodes can interact with the ResourceManager and rejecting any other nodes
Ensuring that only “valid” nodes can interact with the ResourceManager and rejecting any other nodes
Before and during the registration of a new node to the system, lots of things happen. The administrators are supposed to install YARN on the node along with any other dependencies, and configure the node to communicate to its ResourceManager by setting up configuration similar to other existing nodes. If needed, this node should be removed from the excluded nodes list of the ResourceManager.
The ResourceManager will reject requests from any invalid or decommissioned nodes. Nodes that don’t respect the ResourceManager’s configuration for minimum resource requirements will also be rejected.
Following a successful registration, in its registration response the ResourceManager will send security-related master keys needed by NodeManagers to authenticate container-related requests from the ApplicationMasters. NodeManagers need to be able to validate NodeManager tokens and container tokens that are submitted by ApplicationMasters as part of container-launch requests. The underlying master keys are rolled over every so often for security purposes; thus, on further heartbeats, NodeManagers will be notified of such updates whenever they happen.
The Resource Tracker Service forwards a valid node-heartbeat to the YarnScheduler, which then makes scheduling decisions based on freely available resources on that node and the resource requirements from various applications.
In addition, the Resource Tracker Service works closely with the NodeManager liveliness monitor and nodes-list manager, described next.
NodeManagers Liveliness Monitor
To keep track of live nodes and specifically identify any dead nodes, this component keeps track of each node’s identifier (ID) and its last heartbeat time. Any node that doesn’t send a heartbeat within a configured interval of time—by default, 10 minutes—is deemed dead and is expired by the ResourceManager. All the containers currently running on an expired node are marked as dead, and no new containers are scheduled on such node. Once such a node restarts (either automatically or by administrators’ intervention) and reregisters, it will again be considered for scheduling.
Nodes-List Manager
The nodes-list manager is a collection in the ResourceManager’s memory of both valid and excluded nodes. It is responsible for reading the host configuration files specified via the yarn.resourcemanager.nodes.include-path andyarn.resourcemanager.nodes.exclude-path configuration properties and seeding the initial list of nodes based on those files. It also keeps track of nodes that are explicitly decommissioned by administrators as time progresses.
Core ResourceManager Components
So far, we have described various components of the ResourceManager that interact with the outside world—namely, clients, ApplicationMasters, and NodeManagers. In this section, we’ll present the core ResourceManager components that bind all of them together.
ApplicationsManager
The ApplicationsManager is responsible for maintaining a collection of submitted applications. After application submission, it first validates the application’s specifications and rejects any application that requests unsatisfiable resources for its ApplicationMaster (i.e., there is no node in the cluster that has enough resources to run the ApplicationMaster itself). It then ensures that no other application was already submitted with the same application ID—a scenario that can be caused by an erroneous or a malicious client. Finally, it forwards the admitted application to the scheduler.
This component is also responsible for recording and managing finished applications for a while before they are completely evacuated from the ResourceManager’s memory. When an application finishes, it places an ApplicationSummary in the daemon’s log file. The ApplicationSummaryis a compact representation of application information at the time of completion.
Finally, the ApplicationsManager keeps a cache of completed applications long after applications finish to support users’ requests for application data (via web UI or command line). The configuration property yarn.resourcemanager.max-completed-applications controls the maximum number of such finished applications that the ResourceManager remembers at any point of time. The cache is a first-in, first-out list, with the oldest applications being moved out to accommodate freshly finished applications.
ApplicationMaster Launcher
In YARN, while every other container’s launch is initiated by an ApplicationMaster, the ApplicationMaster itself is allocated and prepared for launch on a NodeManager by the ResourceManager itself. The ApplicationMaster Launcher is responsible for this job. This component maintains a thread pool to set up the environment and to communicate with NodeManagers so as to launch ApplicationMasters of newly submitted applications as well as applications for which previous ApplicationMaster attempts failed for some reason. It is also responsible for talking to NodeManagers about cleaning up the ApplicationMaster—mainly killing the process by signaling the corresponding NodeManager when an application finishes normally or is forcefully terminated.
YarnScheduler
The YarnScheduler is responsible for allocating resources to the various running applications subject to constraints of capacities, queues, and so on. It performs its scheduling function based on the resource requirements of the applications, such as memory, CPU, disk, and network needs. Currently, memory and CPU cores are supported resources. We already gave a brief coverage of various YARN scheduling options in Chapter 4, “Functional Overview of YARN Components.” The default scheduler that is packaged with YARN, the Capacity scheduler, is discussed in Chapter 8.
ContainerAllocationExpirer
This component is in charge of ensuring that all allocated containers are eventually used by ApplicationMasters and subsequently launched on the corresponding NodeManagers. ApplicationMasters run as untrusted user code and may potentially hold on to allocations without using them; as such, they can lead to under-utilization and abuse of a cluster’s resources. To address this, the ContainerAllocationExpirer maintains a list of containers that are allocated but still not used on the corresponding NodeManagers. For any container, if the corresponding NodeManager doesn’t report to the ResourceManager that the container has started running within a configured interval of time (by default, 10 minutes), the container is deemed dead and is expired by the ResourceManager.
In addition, independently NodeManagers look at this expiry time, which is encoded in the ContainerToken tied to a container, and reject containers that are submitted for launch after the expiry time elapses. Obviously, this feature depends on the system clocks being synchronized across the ResourceManager and all NodeManagers in the system.
Security-related Components in the ResourceManager
The ResourceManager has a collection of components called SecretManagers that are charged with managing the tokens and secret keys that are used to authenticate/authorize requests on various RPC interfaces. A brief summary of the tokens, secret keys, and the secret managers follows.
ContainerToken SecretManager
This SecretManager is responsible for managing ContainerTokens—a special set of tokens issued by the ResourceManager to an ApplicationMaster so that it can use an allocated container on a specific node. This ResourceManager-specific component keeps track of the underlying secret keys and rolls the keys over every so often.
ContainerTokens are a security tool used by the ResourceManager to send vital information related to starting a container to NodeManagers through the ApplicationMaster. This information cannot be sent directly to a NodeManager without causing significant latencies. The ResourceManager can construct ContainerTokens only after a container is allocated, and the information to be encoded in a ContainerToken is available only after this allocation. Waiting for NodeManagers to acknowledge the token before ApplicationMasters can get the allocated container is a nonstarter. For this reason, they are routed to the NodeManagers through the ApplicationMasters.
From a security point of view, we cannot trust the ApplicationMaster to pass along correct information to the NodeManagers before starting a container. For example, it may just fabricate the amount of memory or cores before passing along this information to the NodeManager. To avoid this problem, the ResourceManager encrypts vital container-related information into a container token before sending it to the ApplicationMaster. A container token consists of the following fields:
![]() Container ID: This uniquely identifies a container. The NodeManager uses this information to bind it to a specific application or application attempt. This binding is important because any user may have multiple applications running concurrently and one ApplicationMaster should not start containers for another application.
Container ID: This uniquely identifies a container. The NodeManager uses this information to bind it to a specific application or application attempt. This binding is important because any user may have multiple applications running concurrently and one ApplicationMaster should not start containers for another application.
![]() NodeManager address: The container token encodes the target Node-Manager’s address so as to avoid abusive ApplicationMasters using container tokens corresponding to containers allocated on one NodeManager to start containers on another unrelated NodeManager.
NodeManager address: The container token encodes the target Node-Manager’s address so as to avoid abusive ApplicationMasters using container tokens corresponding to containers allocated on one NodeManager to start containers on another unrelated NodeManager.
![]() Application submitter: This is the name of the user who submitted the application to the ResourceManager. It is important because the NodeManager needs to perform all container-related activities, such as localizing resources, starting a process for the container, and creating log directories, as the user for security reasons.
Application submitter: This is the name of the user who submitted the application to the ResourceManager. It is important because the NodeManager needs to perform all container-related activities, such as localizing resources, starting a process for the container, and creating log directories, as the user for security reasons.
![]() Resource: This informs the NodeManager about the amount of each resource (e.g., memory, virtual cores) that the ResourceManager has authorized an ApplicationMaster to start. The NodeManager uses this information both to account for used resources and to monitor containers to not use resources beyond the corresponding limits.
Resource: This informs the NodeManager about the amount of each resource (e.g., memory, virtual cores) that the ResourceManager has authorized an ApplicationMaster to start. The NodeManager uses this information both to account for used resources and to monitor containers to not use resources beyond the corresponding limits.
![]() Expiry timestamp: NodeManagers look at this timestamp to determine if the container token passed is still valid. Any containers that are not used by the ApplicationMasters until after this expiry time is reached will be automatically cancelled by YARN.
Expiry timestamp: NodeManagers look at this timestamp to determine if the container token passed is still valid. Any containers that are not used by the ApplicationMasters until after this expiry time is reached will be automatically cancelled by YARN.
![]() For this feature to work, the clocks on the nodes running the ResourceManager and the NodeManagers must be in sync.
For this feature to work, the clocks on the nodes running the ResourceManager and the NodeManagers must be in sync.
![]() When the ResourceManager allocates a container, it also determines and sets its expiry time based on a cluster configuration, defaulting to 10 minutes.
When the ResourceManager allocates a container, it also determines and sets its expiry time based on a cluster configuration, defaulting to 10 minutes.
![]() When administrators set the expiry interval configuration, it should not be set (1) to a very low value, because ApplicationMasters may not have enough time to start containers before they are expired, or (2) to a very high value, because doing so permits rogue ApplicationMasters to allocate containers but not use them, which hurts cluster utilization.
When administrators set the expiry interval configuration, it should not be set (1) to a very low value, because ApplicationMasters may not have enough time to start containers before they are expired, or (2) to a very high value, because doing so permits rogue ApplicationMasters to allocate containers but not use them, which hurts cluster utilization.
![]() If a container is not used before it expires, then the NodeManager will simply reject any start-container requests using this token. The NodeManager also has a cache of recently started containers to prevent ApplicationMasters from using the same token in a rapid manner on very short-lived containers.
If a container is not used before it expires, then the NodeManager will simply reject any start-container requests using this token. The NodeManager also has a cache of recently started containers to prevent ApplicationMasters from using the same token in a rapid manner on very short-lived containers.
![]() Master key identifier: This is used by NodeManagers to validate container tokens that are sent across them.
Master key identifier: This is used by NodeManagers to validate container tokens that are sent across them.
![]() The ResourceManager generates a secret key and assigns a key ID to uniquely identify this key. This secret key, along with its ID, is shared with every NodeManager, first as a part of each node’s registration and then during subsequent heartbeats whenever the ResourceManager rolls over the keys for security reasons. The key rollover period is a ResourceManager configurable value, but defaults to a day.
The ResourceManager generates a secret key and assigns a key ID to uniquely identify this key. This secret key, along with its ID, is shared with every NodeManager, first as a part of each node’s registration and then during subsequent heartbeats whenever the ResourceManager rolls over the keys for security reasons. The key rollover period is a ResourceManager configurable value, but defaults to a day.
![]() Whenever the ResourceManager rolls over the underlying keys, they aren’t immediately used to generate new tokens; thus there is enough time for all the NodeManagers in the cluster to learn about the rollover. As NodeManagers emit heartbeats and learn about the new key, or once the activation period expires, the ResourceManager replaces its older key with a newly created key. Thereafter, it uses the new key only for generating container tokens. This activation period is set to be 1.5 times the node-expiry interval.
Whenever the ResourceManager rolls over the underlying keys, they aren’t immediately used to generate new tokens; thus there is enough time for all the NodeManagers in the cluster to learn about the rollover. As NodeManagers emit heartbeats and learn about the new key, or once the activation period expires, the ResourceManager replaces its older key with a newly created key. Thereafter, it uses the new key only for generating container tokens. This activation period is set to be 1.5 times the node-expiry interval.
![]() As you can see, there will be times before key activation when NodeManagers may receive tokens generated using different keys. In such a case, even when the ResourceManager instructs NodeManagers that a key has rolled over, NodeManagers continue to remember both the current (new) key and the previous (old) key, and use the correct key based on the master key ID present in the token.
As you can see, there will be times before key activation when NodeManagers may receive tokens generated using different keys. In such a case, even when the ResourceManager instructs NodeManagers that a key has rolled over, NodeManagers continue to remember both the current (new) key and the previous (old) key, and use the correct key based on the master key ID present in the token.
![]() ResourceManager identifier: It is possible that the ResourceManager might restart after allocating a container but before the ApplicationMaster can reach the NodeManager to start the container. To ensure both the new ResourceManager and the NodeManagers are able to recognize containers from the old instance of ResourceManager separately from the ones allocated by the new instance, the ResourceManager identifier is encoded into the container token. At the time of this writing, the ResourceManager on restart will kill all of the previously running containers; in a similar vein, NodeManagers simply reject containers issued by the older ResourceManager.
ResourceManager identifier: It is possible that the ResourceManager might restart after allocating a container but before the ApplicationMaster can reach the NodeManager to start the container. To ensure both the new ResourceManager and the NodeManagers are able to recognize containers from the old instance of ResourceManager separately from the ones allocated by the new instance, the ResourceManager identifier is encoded into the container token. At the time of this writing, the ResourceManager on restart will kill all of the previously running containers; in a similar vein, NodeManagers simply reject containers issued by the older ResourceManager.
AMRMToken SecretManager
Only ApplicationMasters can initiate requests for resources in the form of containers. To avoid the possibility of arbitrary processes maliciously imitating a real ApplicationMaster and sending scheduling requests to the ResourceManager, the ResourceManager uses per-ApplicationAttempt tokens called AMRMTokens. This secret manager saves each token locally in memory until an ApplicationMaster finishes and uses it to authenticate any request coming from a valid ApplicationMaster process.
ApplicationMasters can obtain this token by loading a credentials file localized by YARN. The location of this file is determined by the public constant ApplicationConstants.CONTAINER_TOKEN_FILE_ENV_NAME.
Unlike the container tokens, the underlying master key for AMRMTokens doesn’t need to be shared with any other entity in the system. Like the container tokens, the keys are rolled every so often for security reasons, but there are no corresponding activation periods.
NMToken SecretManager
Container tokens are in a way used for authorization of start-container requests from the ApplicationMasters. They are valid only during the connection to the NodeManager that is created for starting the container. Further, if there is no other authentication mechanism, a connection created using a container token cannot be used to start other containers. The whole point of a container token is to prevent resource abuse, which would be possible with shared connections.
Besides starting a container, NodeManagers allow ApplicationMasters to stop a container or get the status of a container. These requests can be submitted long after containers are allocated, so mandating the ApplicationMasters to create a persistent but separate connection per container with each NodeManager is not practical.
NMTokens serve this purpose. ApplicationMasters use NMTokens to manage one connection per NodeManager and use it to send all requests to that node.
![]() The ResourceManager generates one NMToken per application attempt per NodeManager.
The ResourceManager generates one NMToken per application attempt per NodeManager.
![]() Whenever a new container is created, ResourceManager issues the ApplicationMaster an NMToken corresponding to that node. ApplicationMasters will get NMTokens only for those NodeManagers on which they started containers.
Whenever a new container is created, ResourceManager issues the ApplicationMaster an NMToken corresponding to that node. ApplicationMasters will get NMTokens only for those NodeManagers on which they started containers.
![]() As a network optimization, NMTokens are not sent to the ApplicationMasters for each and every allocated container, but only for the first time or if NMTokens have to be invalidated due to the rollover of the underlying master key.
As a network optimization, NMTokens are not sent to the ApplicationMasters for each and every allocated container, but only for the first time or if NMTokens have to be invalidated due to the rollover of the underlying master key.
![]() Whenever an ApplicationMaster receives a new NMToken, it should replace the existing token, if present, for that NodeManager with the newer token. A library, NMTokenCache, is available for the token management.
Whenever an ApplicationMaster receives a new NMToken, it should replace the existing token, if present, for that NodeManager with the newer token. A library, NMTokenCache, is available for the token management.
![]() ApplicationMasters are always expected to use the latest NMToken, and each NodeManager accepts only one NMToken from any ApplicationMaster. If a new NMToken is received from the ResourceManager, then older connections for corresponding NodeManagers should be closed and a new connection should be created with the latest NMToken. If connections created with older NMTokens are then used for launching newly assigned containers, the NodeManagers simply reject them.
ApplicationMasters are always expected to use the latest NMToken, and each NodeManager accepts only one NMToken from any ApplicationMaster. If a new NMToken is received from the ResourceManager, then older connections for corresponding NodeManagers should be closed and a new connection should be created with the latest NMToken. If connections created with older NMTokens are then used for launching newly assigned containers, the NodeManagers simply reject them.
![]() As with container tokens, NMTokens issued for one ApplicationMaster cannot be used by another. To make this happen, the application attempt ID is encoded into the NMTokens.
As with container tokens, NMTokens issued for one ApplicationMaster cannot be used by another. To make this happen, the application attempt ID is encoded into the NMTokens.
RMDelegationToken SecretManager
This component is a ResourceManager-specific delegation token secret manager. It is responsible for generating delegation tokens to clients, which can be passed on to processes that wish to be able to talk to the ResourceManager but are not Kerberos authenticated.
DelegationToken Renewer
In secure mode, the ResourceManager is Kerberos authenticated and so provides the service of renewing file system tokens on behalf of the applications. This component renews tokens of submitted applications as long as the application runs and until the tokens can no longer be renewed.
NodeManager
A NodeManager is YARN’s per-node agent that takes care of the individual compute nodes in a Hadoop YARN cluster and uses the physical resources on the nodes to run containers as requested by YARN applications. It is essentially the “worker” daemon in YARN. Its responsibilities include the following tasks:
![]() Keeping up-to-date with the ResourceManager
Keeping up-to-date with the ResourceManager
![]() Tracking node health
Tracking node health
![]() Overseeing containers’ life-cycle management; monitoring resource usage (e.g., memory, CPU) of individual containers
Overseeing containers’ life-cycle management; monitoring resource usage (e.g., memory, CPU) of individual containers
![]() Managing the distributed cache (a local file system cache of files such as jars and libraries that are used by containers)
Managing the distributed cache (a local file system cache of files such as jars and libraries that are used by containers)
![]() Managing the logs generated by containers
Managing the logs generated by containers
![]() Auxiliary services that may be exploited by different YARN applications
Auxiliary services that may be exploited by different YARN applications
We’ll now give a brief overview of NodeManagers’ functionality before describing the components in more detail.
Overview of the NodeManager Components
Among the previously listed responsibilities, container management is the core responsibility of a NodeManager. From this point of view, the NodeManager accepts requests from ApplicationMasters to start and stop containers, authenticates container tokens (a security mechanism to make sure applications can appropriately use resources as given out by the ResourceManager), manages libraries that containers depend on for execution, and monitors containers’ execution. Operators configure each NodeManager with a certain amount of memory, number of CPUs, and other resources available at the node by way of configuration files (yarn-default.xml and/or yarn-site.xml). After registering with the ResourceManager, the NodeManager periodically sends a heartbeat with its current status and receives instructions, if any, from the ResourceManager. When the scheduler gets to process the node’s heartbeat (which can happen after a delay follows a node’s heartbeat), containers are allocated against that NodeManager and then are subsequently returned to the ApplicationMasters when the ApplicationMasters themselves send a heartbeat to the ResourceManager.
All containers in YARN—including ApplicationMasters—are described by a Container Launch Context (CLC). This request object includes environment variables, library dependencies (which may be present on remotely accessible storage), security tokens that are needed both for downloading libraries required to start a container and for usage by the container itself, container-specific payloads for NodeManager auxiliary services, and the command necessary to create the process. After validating the authenticity of a start-container request, the NodeManager configures the environment for the container, forcing any administrator-provided settings that may be configured.
Before actually launching a container, the NodeManager copies all the necessary libraries—data files, executables, tarballs, jar files, shell scripts, and so on—to the local file system. The downloaded libraries may be shared between containers of a specific application via a local application-level cache, between containers launched by the same user via a local user-level cache, and even between users via a public cache, as can be specified in the CLC. The NodeManager eventually garbage-collects libraries that are not in use by any running containers.
The NodeManager may also kill containers as directed by the ResourceManager. Containers may be killed in the following situations:
![]() The ResourceManager sends a signal that an application has completed.
The ResourceManager sends a signal that an application has completed.
![]() The scheduler decides to preempt it for another application or user.
The scheduler decides to preempt it for another application or user.
![]() The NodeManager detects that the container exceeded the resource limits as specified by its ContainerToken.
The NodeManager detects that the container exceeded the resource limits as specified by its ContainerToken.
Whenever a container exits, the NodeManager will clean up its working directory in local storage. When an application completes, all resources owned by its containers are cleaned up.
In addition to starting and stopping containers, cleaning up after exited containers, and managing local resources, the NodeManager offers other local services to containers running on the node. For example, the log aggregation service uploads all the logs written by the application’s containers to stdout and stderr to a file system once the application completes.
As described in the ResourceManager section, when any NodeManager fails (which may occur for various reasons), the ResourceManager detects this failure using a timeout, and reports the failure to all running applications. If the fault or condition causing the timeout is transient, the NodeManager will resynchronize with the ResourceManager, clean up its local state, and continue. Similarly, when a new NodeManager joins the cluster, the ResourceManager notifies all ApplicationMasters about the availability of new resources for spawning containers.
NodeManager Components
Similar to the ResourceManager, the NodeManager is divided internally into a host of nested components, each of which has a clear responsibility. Figure 7.4 gives an overview of the NodeManager components.
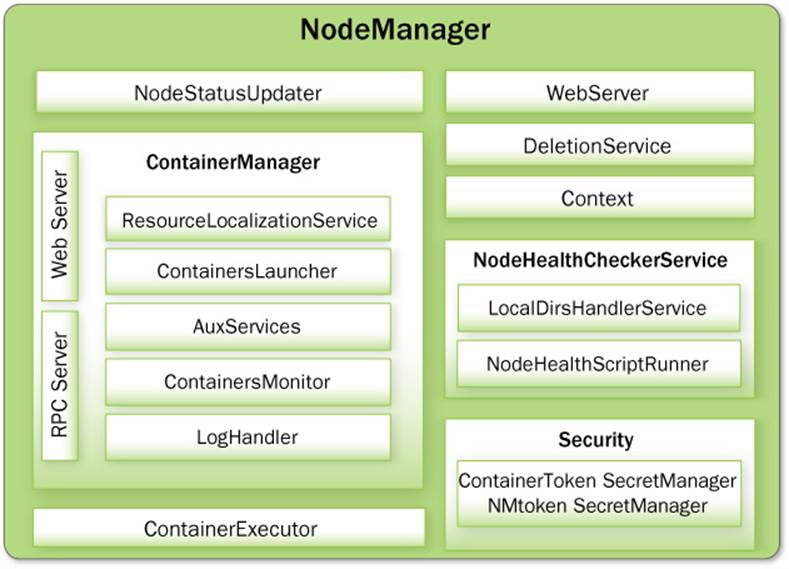
Figure 7.4 NodeManager components
NodeStatusUpdater
On start-up, this component registers with the ResourceManager, sends information about the resources available on this node, and identifies the ports at which the NodeManager’s web server and the RPC server are listening. As part of the registration, the ResourceManager sends the NodeManager security-related keys needed by the NodeManager to authenticate future container requests from the ApplicationMasters. Subsequent NodeManager–ResourceManager communication provides the ResourceManager with any updates on existing containers’ status, new containers started on the node by the ApplicationMasters, containers that have completed, and so on.
In addition, the ResourceManager may signal the NodeManager via this component to potentially kill currently running containers because of, say, a scheduling policy that shuts down the NodeManager in situations such as explicit decommissioning by the operator or resynchronizing of the NodeManager in case of network issues. Finally, when any application finishes on the ResourceManager, the ResourceManager signals the NodeManager to clean up various application-specific entities on the NodeManager—for example, internal per-application data structures and application-level local resources—and then initiate and finish the per-application logs’ aggregation onto a file system.
ContainerManager
This component is the core of the NodeManager. It is composed of the following subcomponents, each of which performs a subset of the functionality that is needed to manage the containers running on the node.
RPC Server
ContainerManager accepts requests from ApplicationMasters to start new containers, or to stop running ones. It works with NMToken SecretManager and ContainerToken SecretManager (described later) to authenticate and authorize all requests. All the operations performed on containers running on this node are recorded in an audit log, which can be postprocessed by security tools.
Resource Localization Service
Resource localization is one of the important services offered by NodeManagers to user applications. Overall, the resource localization service is responsible for securely downloading and organizing various file resources needed by containers. It tries its best to distribute the files across all the available disks. It also enforces access control restrictions on the downloaded files and puts appropriate usage limits on them. To understand how localization happens inside NodeManager, a brief recap of some definitions related to resource localization from Chapter 4, “Functional Overview of YARN Components,” follows.
![]() Localization: Localization is the process of copying/downloading remote resources onto the local file system. Instead of always accessing a resource remotely, that resource is copied to the local machine, which can then be accessed locally.
Localization: Localization is the process of copying/downloading remote resources onto the local file system. Instead of always accessing a resource remotely, that resource is copied to the local machine, which can then be accessed locally.
![]() LocalResource: LocalResource represents a file/library required to run a container. The localization service is responsible for localizing the resource prior to launching the container. For each LocalResource, applications can specify the following information:
LocalResource: LocalResource represents a file/library required to run a container. The localization service is responsible for localizing the resource prior to launching the container. For each LocalResource, applications can specify the following information:
![]() URL: Remote location from where a LocalResource has to be downloaded.
URL: Remote location from where a LocalResource has to be downloaded.
![]() Size: Size in bytes of the LocalResource.
Size: Size in bytes of the LocalResource.
![]() Creation timestamp: Resource creation time on the remote file system.
Creation timestamp: Resource creation time on the remote file system.
![]() LocalResourceType: The type of a resource localized by the NodeManager—FILE, ARCHIVE, or PATTERN.
LocalResourceType: The type of a resource localized by the NodeManager—FILE, ARCHIVE, or PATTERN.
![]() Pattern: The pattern that should be used to extract entries from the archive (used only when the type is PATTERN).
Pattern: The pattern that should be used to extract entries from the archive (used only when the type is PATTERN).
![]() LocalResourceVisibility: Specifies the visibility of a resource localized by the NodeManager. The visibility can be either PUBLIC, PRIVATE, or APPLICATION.
LocalResourceVisibility: Specifies the visibility of a resource localized by the NodeManager. The visibility can be either PUBLIC, PRIVATE, or APPLICATION.
![]() DeletionService: A service that runs inside the NodeManager and deletes local paths as and when instructed to do so.
DeletionService: A service that runs inside the NodeManager and deletes local paths as and when instructed to do so.
![]() Localizer: The actual thread or process that does localization. There are two types of localizers: PublicLocalizer for PUBLIC resources and ContainerLocalizers for PRIVATE and APPLICATION resources.
Localizer: The actual thread or process that does localization. There are two types of localizers: PublicLocalizer for PUBLIC resources and ContainerLocalizers for PRIVATE and APPLICATION resources.
![]() LocalCache: NodeManager maintains and manages several local caches of all the files downloaded. The resources are uniquely identified based on the remote URL originally used while copying that file.
LocalCache: NodeManager maintains and manages several local caches of all the files downloaded. The resources are uniquely identified based on the remote URL originally used while copying that file.
The Localization Process
As you will recall from Chapter 4, “Functional Overview of YARN Components,” there are three types of LocalResources: PUBLIC, PRIVATE, and APPLICATION. For security reasons, the NodeManager localizes PRIVATE/APPLICATION LocalResources in a completely different manner than PUBLIC LocalResources. Figure 7.5 gives an overview of where and how resource localization happens.
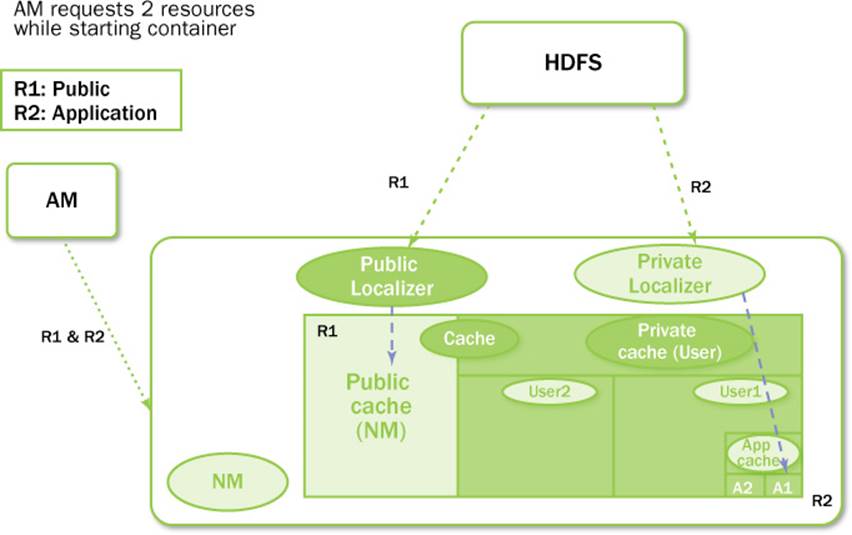
Figure 7.5 Resource-localization process inside the NodeManager
Localization of PUBLIC Resources
Localization of PUBLIC resources is taken care of by a pool of threads called Public-Localizers. PublicLocalizers run inside the address space of the NodeManager itself. The number of PublicLocalizer threads is controlled by the configuration propertyyarn.nodemanager.localizer.fetch.thread-count, which sets the maximum parallelism during downloading of PUBLIC resources to this thread count. While localizing PUBLIC resources, the localizer validates that all the requested resources are, indeed, PUBLIC by checking their permissions on the remote file system. Any LocalResource that doesn’t match that condition is rejected for localization. Each PublicLocalizer uses credentials passed as part of ContainerLaunchContext (discussed later) to securely copy the resources from the remote file system.
Localization of PRIVATE/APPLICATON Resources
Localization of PRIVATE/APPLICATION resources is not done inside the NodeManager and, therefore, is not centralized. The process is a little involved and is outlined here.
![]() Localization of these resources happen in a separate process called ContainerLocalizer.
Localization of these resources happen in a separate process called ContainerLocalizer.
![]() Every ContainerLocalizer process is managed by a single thread in NodeManager called LocalizerRunner. Every container will trigger one LocalizerRunner if it has any resources that are not yet downloaded.
Every ContainerLocalizer process is managed by a single thread in NodeManager called LocalizerRunner. Every container will trigger one LocalizerRunner if it has any resources that are not yet downloaded.
![]() LocalResourcesTracker is a per-user or per-application object that tracks all the LocalResources for a given user or an application.
LocalResourcesTracker is a per-user or per-application object that tracks all the LocalResources for a given user or an application.
![]() When a container first requests a PRIVATE/APPLICATION LocalResource, if it is not found in LocalResourcesTracker (or is found but is in the INITIALIZED state), it is added to pending resources list.
When a container first requests a PRIVATE/APPLICATION LocalResource, if it is not found in LocalResourcesTracker (or is found but is in the INITIALIZED state), it is added to pending resources list.
![]() A LocalizerRunner may (or may not) be created depending on the need for downloading something new.
A LocalizerRunner may (or may not) be created depending on the need for downloading something new.
![]() The LocalResource is added to its LocalizerRunner’s pending resources list.
The LocalResource is added to its LocalizerRunner’s pending resources list.
![]() One requirement for the NodeManager in secure mode is to download/copy these resources as the application submitter, rather than as a yarn-user (privileged user). Therefore, the LocalizerRunner starts a LinuxContainerExecutor (LCE). The LCE is a process running as application submitter, which then executes a ContainerLocalizer. The ContainerLocalizer works as follows:
One requirement for the NodeManager in secure mode is to download/copy these resources as the application submitter, rather than as a yarn-user (privileged user). Therefore, the LocalizerRunner starts a LinuxContainerExecutor (LCE). The LCE is a process running as application submitter, which then executes a ContainerLocalizer. The ContainerLocalizer works as follows:
![]() Once started, the ContainerLocalizer starts a heartbeat with the NodeManager process.
Once started, the ContainerLocalizer starts a heartbeat with the NodeManager process.
![]() On each heartbeat, the LocalizerRunner either assigns one resource at a time to a ContainerLocalizer or asks it to die. The ContainerLocalizer informs the LocalizerRunner about the status of the download.
On each heartbeat, the LocalizerRunner either assigns one resource at a time to a ContainerLocalizer or asks it to die. The ContainerLocalizer informs the LocalizerRunner about the status of the download.
![]() If it fails to download a resource, then that particular resource is removed from LocalResourcesTracker and the container eventually is marked as failed. When this happens, the LocalizerRunner stops the running ContainerLocalizers and exits.
If it fails to download a resource, then that particular resource is removed from LocalResourcesTracker and the container eventually is marked as failed. When this happens, the LocalizerRunner stops the running ContainerLocalizers and exits.
![]() If it is a successful download, then the LocalizerRunner gives a Container-Localizer another resource again and again, continuing to do so until all pending resources are successfully downloaded.
If it is a successful download, then the LocalizerRunner gives a Container-Localizer another resource again and again, continuing to do so until all pending resources are successfully downloaded.
![]() As of this writing, each ContainerLocalizer doesn’t support parallel downloading of multiple PRIVATE/APPLICATION resources. In addition, the maximum parallelism is the number of containers requested for the same user on the same NodeManager at that point of time. The worst case for this process occurs when an ApplicationMaster itself is starting. If the ApplicationMaster needs any resources to be localized then, they will be downloaded serially before its container starts.
As of this writing, each ContainerLocalizer doesn’t support parallel downloading of multiple PRIVATE/APPLICATION resources. In addition, the maximum parallelism is the number of containers requested for the same user on the same NodeManager at that point of time. The worst case for this process occurs when an ApplicationMaster itself is starting. If the ApplicationMaster needs any resources to be localized then, they will be downloaded serially before its container starts.
Target Locations of LocalResources
On each of the NodeManager machines, LocalResources are ultimately localized in the following target directories, under each local directory:
![]() PUBLIC: <local-dir>/filecache
PUBLIC: <local-dir>/filecache
![]() PRIVATE: <local-dir>/usercache/<username>/filecache
PRIVATE: <local-dir>/usercache/<username>/filecache
![]() APPLICATION: <local-dir>/usercache/<username>/appcache/<app-id>/
APPLICATION: <local-dir>/usercache/<username>/appcache/<app-id>/
Irrespective of the application type, once the resources are downloaded and the containers are running, the containers can access these resources locally by making use of the symbolic links created by the NodeManager in each container’s working directory.
Resource Localization Configuration
Administrators can control various aspects of resource localization by setting or changing certain configuration parameters in yarn-site.xml when starting a NodeManager:
![]() yarn.nodemanager.local-dirs: A comma-separated list of local directories that one can configure to be used for copying files during localization. The idea behind allowing multiple directories is to use multiple disks for localization so as to provide both fail-over (one or a few disks going bad doesn’t affect all containers) and load balancing (no single disk is bottlenecked with writes) capabilities. Thus, individual directories should be configured if possible on different local disks.
yarn.nodemanager.local-dirs: A comma-separated list of local directories that one can configure to be used for copying files during localization. The idea behind allowing multiple directories is to use multiple disks for localization so as to provide both fail-over (one or a few disks going bad doesn’t affect all containers) and load balancing (no single disk is bottlenecked with writes) capabilities. Thus, individual directories should be configured if possible on different local disks.
![]() yarn.nodemanager.local-cache.max-files-per-directory: Limits the maximum number of files that will be localized in each of the localization directories (separately for PUBLIC, PRIVATE, and APPLICATION resources). The default value is 8192 and this parameter should, in general, not be assigned a large value (configure a value that is sufficiently less than the per-directory maximum file limit of the underlying file system, such as ext3).
yarn.nodemanager.local-cache.max-files-per-directory: Limits the maximum number of files that will be localized in each of the localization directories (separately for PUBLIC, PRIVATE, and APPLICATION resources). The default value is 8192 and this parameter should, in general, not be assigned a large value (configure a value that is sufficiently less than the per-directory maximum file limit of the underlying file system, such as ext3).
![]() yarn.nodemanager.localizer.address: The network address where ResourceLocalizationService listens for requests from various localizers.
yarn.nodemanager.localizer.address: The network address where ResourceLocalizationService listens for requests from various localizers.
![]() yarn.nodemanager.localizer.client.thread-count: Limits the number of RPC threads in ResourceLocalizationService that are used for handling localization requests from localizers. The default is 5, which means that at any point of time, only five localizers will be processed while others wait in the RPC queues.
yarn.nodemanager.localizer.client.thread-count: Limits the number of RPC threads in ResourceLocalizationService that are used for handling localization requests from localizers. The default is 5, which means that at any point of time, only five localizers will be processed while others wait in the RPC queues.
![]() yarn.nodemanager.localizer.fetch.thread-count: Configures the number of threads used for localizing PUBLIC resources. Recall that localization of PUBLIC resources happens inside the NodeManager address space; thus this property limits how many threads will be spawned inside the NodeManager for localization of PUBLIC resources. The default is 4.
yarn.nodemanager.localizer.fetch.thread-count: Configures the number of threads used for localizing PUBLIC resources. Recall that localization of PUBLIC resources happens inside the NodeManager address space; thus this property limits how many threads will be spawned inside the NodeManager for localization of PUBLIC resources. The default is 4.
![]() yarn.nodemanager.delete.thread-count: Controls the number of threads used by DeletionService for deleting files. This DeletionService is used all over the NodeManager for deleting log files as well as local cache files. The default is 4.
yarn.nodemanager.delete.thread-count: Controls the number of threads used by DeletionService for deleting files. This DeletionService is used all over the NodeManager for deleting log files as well as local cache files. The default is 4.
![]() yarn.nodemanager.localizer.cache.target-size-mb: This property decides the maximum disk space to be used for localizing resources. (As of this book’s writing, there was no individual limit for PRIVATE, APPLICATION, or PUBLIC caches.) Once the total disk size of the cache exceeds this value, the DeletionService will try to remove files that are not used by any running containers. This limit is applicable to all the disks and is not used on a per-disk basis.
yarn.nodemanager.localizer.cache.target-size-mb: This property decides the maximum disk space to be used for localizing resources. (As of this book’s writing, there was no individual limit for PRIVATE, APPLICATION, or PUBLIC caches.) Once the total disk size of the cache exceeds this value, the DeletionService will try to remove files that are not used by any running containers. This limit is applicable to all the disks and is not used on a per-disk basis.
![]() yarn.nodemanager.localizer.cache.cleanup.interval-ms: After the interval specified by this configuration property elapses, ResourceLocalizationService will try to delete any unused resources if the total cache size exceeds the configured maximum cache size. Unused resources are those resources that are not referred to by any running container. Every time a container requests a resource, that container is added to the resource’s reference list. It will remain there until the container finishes, thereby preventing accidental deletion of this resource. As a part of container resource cleanup (when the container finishes), the container will be removed from the resource’s reference list. When the reference count drops to zero, it is an ideal candidate for deletion. The resources will be deleted on a least recently used (LRU) basis until the current cache size drops below the target size.
yarn.nodemanager.localizer.cache.cleanup.interval-ms: After the interval specified by this configuration property elapses, ResourceLocalizationService will try to delete any unused resources if the total cache size exceeds the configured maximum cache size. Unused resources are those resources that are not referred to by any running container. Every time a container requests a resource, that container is added to the resource’s reference list. It will remain there until the container finishes, thereby preventing accidental deletion of this resource. As a part of container resource cleanup (when the container finishes), the container will be removed from the resource’s reference list. When the reference count drops to zero, it is an ideal candidate for deletion. The resources will be deleted on a least recently used (LRU) basis until the current cache size drops below the target size.
Containers Launcher
The Containers Launcher maintains a pool of threads to prepare and launch containers as quickly as possible. It also cleans up the containers’ processes when the Resource-Manager sends such a request through the NodeStatusUpdater or when the ApplicationMasters send requests via the RPC server. The launch or cleanup of a container happens in one thread of the thread pool, which will return only when the corresponding operation finishes. Consequently, launch or cleanup of one container doesn’t affect any other operations and all container operations are isolated inside the NodeManager process.
Auxiliary Services
An administrator may configure the NodeManager with a set of pluggable, auxiliary services. The NodeManager provides a framework for extending its functionality by configuring these services. This feature allows per-node custom services that specific frameworks may require, yet places them in a local “sandbox” separate from the rest of the NodeManager. These services must be configured before the NodeManager starts. Auxiliary services are notified when an application’s first container starts on the node, whenever a container starts or finishes, and finally when the application is considered to be complete.
While a container’s local storage will be cleaned up after it exits, it can promote some output so that it will be preserved until the application finishes. In this way, a container may produce data that persists beyond the life of the container, to be managed by the node. This property of output persistence, together with auxiliary services, enables a powerful feature. One important use-case that takes advantage of this feature is Hadoop MapReduce. For Hadoop MapReduce applications, the intermediate data are transferred between the map and reduce tasks using an auxiliary service called ShuffleHandler. As mentioned earlier, the CLC allows ApplicationMasters to address a payload to auxiliary services. MapReduce applications use this channel to pass tokens that authenticate reduce tasks to the shuffle service.
When a container starts, the service information for auxiliary services is returned to the ApplicationMaster so that the ApplicationMaster can use this information to take advantage of any available auxiliary services. As an example, the MapReduce framework gets the ShuffleHandler’s port information, which it then passes on to the reduce tasks for shuffling map outputs.
Containers Monitor
After a container is launched, this component starts observing its resource utilization while the container is running. To enforce isolation and fair sharing of resources like memory, each container is allocated some amount of such a resource by the ResourceManager. The ContainersMonitor monitors each container’s usage continuously. If a container exceeds its allocation, this component signals the container to be killed. This check is done to prevent any runaway container from adversely affecting other well-behaved containers running on the same node.
Log Handler
The LogHandler is a pluggable component that offers the option of either keeping the containers’ logs on the local disks or zipping them together and uploading them onto a file system. We describe this feature in Chapter 6 under the heading “User Log Management.”
Container Executor
This NodeManager component interacts with the underlying operating system to securely place files and directories needed by containers and subsequently to launch and clean up processes corresponding to containers in a secure manner.
Node Health Checker Service
The NodeHealthCheckerService provides for checking the health of a node by running a configured script frequently. It also monitors the health of the disks by creating temporary files on the disks every so often. Any changes in the health of the system are sent to NodeStatusUpdater (described earlier), which in turn passes the information to the ResourceManager.
NodeManager Security Components
This section outlines the NodeManager security components.
Application ACLs Manager in the NodeManager
The NodeManager needs to gate the user-facing APIs to allow specific users to access them. For instance, container logs can be displayed on the web interface. This component maintains the ACL for each application and enforces the access permissions whenever such a request is received.
ContainerToken SecretManager in the NodeManager
In the NodeManager, this component mirrors the corresponding functionality in the ResourceManager. It verifies various incoming requests to ensure that all of the start-container requests are properly authorized by the ResourceManager.
NMToken SecretManager in the NodeManager
This component also mirrors the corresponding functionality in the ResourceManager. It verifies all incoming API calls to ensure that the requests are properly authenticated using NMTokens.
Web Server
This component exposes the list of applications, containers running on the node at a given point of time, node-health-related information, and the logs produced by the containers.
Important NodeManager Functions
The flow of a few important NodeManager functions with respect to running a YARN application are summarized next.
Container Launch
To facilitate container launch, the NodeManager expects to receive detailed information about a container’s run time, as part of the total container specification. This includes the container’s command line, environment variables, a list of (file) resources required by the container, and any security tokens.
On receiving a container-launch request, the NodeManager first verifies this request and determines if security is enabled, so as to authorize the user, correct resources assignment, and other aspects of the request. The NodeManager then performs the following set of steps to launch the container.
1. A local copy of all the specified resources is created (distributed cache).
2. Isolated work directories are created for the container, and the local resources are made available in these directories by way of symbolic links to the downloaded resources.
3. The launch environment and command line are used to start the actual container.
User Log Management and Aggregation
Hadoop version 2 has much improved user log management, including log aggregation in HDFS. A full discussion of user log management can be found in Chapter 6, “Apache Hadoop YARN Administration.”
MapReduce Shuffle Auxiliary Service
The shuffle functionality required to run a MapReduce application is implemented as an auxiliary service. This service starts up a Netty web server, and knows how to handle MapReduce-specific shuffle requests from reduce tasks. The MapReduce ApplicationMaster specifies the service ID for the shuffle service, along with security tokens that may be required. The NodeManager provides the ApplicationMaster with the port on which the shuffle service is running; this information is then passed to the reduce tasks.
In YARN, the NodeManager is primarily limited to managing abstract containers (i.e., only processes corresponding to a container) and does not concern itself with per-application state management like MapReduce tasks. It also does away with the notion of named slots, such as map and reduce slots. Because of this clear separation of responsibilities coupled with the modular architecture described previously, the NodeManager can scale much more easily and its code is much more maintainable.
ApplicationMaster
The per-application ApplicationMaster is the bootstrap process that kicks off everything for a YARN application once it gets past the application submission and achieves its own launch. If one compares this approach to the Hadoop 1 architecture, the ApplicationMaster is in essence the per-application JobTracker. We start with a brief overview of the ApplicationMaster and then describe each of its chief responsibilities in detail.
Overview
Once an application is submitted, the application’s representation in the ResourceManager negotiates for a container to spawn this bootstrap process. Once such a container is allocated, as described in the ResourceManager section, the ApplicationMaster’s launcher directly communicates with the ApplicationMaster container’s NodeManager to set up and launch the container. Thus begins the life of an ApplicationMaster. A brief overview of its overall interaction with the rest of YARN is shown in Figure 7.6.
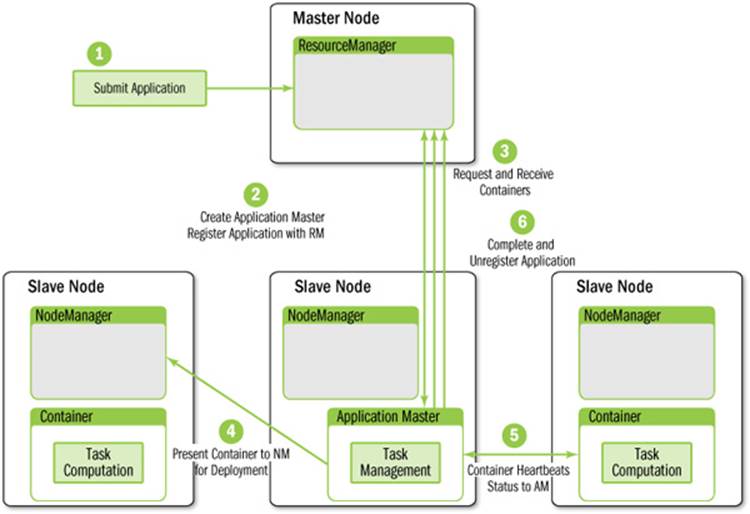
Figure 7.6 Application Master interactions with YARN
The process starts when (1) an application submits a request to the ResourceManager. Next, the ApplicationMaster is started and registers with the ResourceManager (2). The ApplicationMaster then requests containers (3) from the ResourceManager to perform actual work. The assigned containers are presented to the NodeManager for use by the ApplicationMaster (4). Computation takes place in the containers, which keep in contact (5) with the ApplicationMaster (not the ResourceManager) as the job progresses. When the application is complete, containers are stopped and the ApplicationMaster is unregistered (6) from the ResourceManager.
Once successfully launched, the ApplicationMaster is responsible for the following tasks:
![]() Initializing the process of reporting liveliness to the ResourceManager
Initializing the process of reporting liveliness to the ResourceManager
![]() Computing the resource requirements of the application
Computing the resource requirements of the application
![]() Translating the requirements into ResourceRequests that are understood by the YARN scheduler
Translating the requirements into ResourceRequests that are understood by the YARN scheduler
![]() Negotiating those resource requests with the scheduler
Negotiating those resource requests with the scheduler
![]() Using allocated containers by working with the NodeManagers
Using allocated containers by working with the NodeManagers
![]() Tracking the status of running containers and monitoring their progress
Tracking the status of running containers and monitoring their progress
![]() Reacting to container or node failures by requesting alternative resources from the scheduler if needed
Reacting to container or node failures by requesting alternative resources from the scheduler if needed
In the remainder of this section, we’ll describe these individual responsibilities in greater detail.
Liveliness
The first operation that any ApplicationMaster has to perform is to register with the ResourceManager. As part of the registration, ApplicationMasters can inform the ResourceManager about an IPC address and/or a web URL. The IPC address refers to a client-facing service address—a location that the application’s client can visit to obtain nongeneric information about the running application. The communication on the IPC server is application specific: It can be RPC, a simple socket connection, or something else. ApplicationMasters can also report an HTTP tracking URL that points to either an embedded web application running inside the ApplicationMaster’s address space or an external web server. This feature enables the clients to obtain application status and information via HTTP.
In the registration response, the ResourceManager returns information that the ApplicationMaster can use, such as the minimum and maximum sizes of resources that YARN accepts, and the ACLs associated with the application that are set by the user during application submission. The ApplicationMaster can use these ACLs for authorizing user requests on its own client-facing service.
Once registered, an ApplicationMaster periodically needs to send heartbeats to the ResourceManager to affirm its liveliness and health. Any ApplicationMaster that fails to report the status for the yarn.am.liveness-monitor.expiry-interval-ms property (a configuration property of the ResourceManager, whose default is 10 minutes) will be deemed to be a dead ApplicationMaster and will be killed by the platform. This configuration is controlled by administrators and should always be less than the value of the nodes’ expiry interval governed by theyarn.nm.liveness-monitor.expiry-interval-ms property. Otherwise, in situations involving network partitions, nodes may be marked as dead long before ApplicationMasters are marked as such, which may lead to correctness issues on the ResourceManager.
Resource Requirements
Once the liveliness reports with the ResourceManager are taken care of, the application/framework needs to figure out its own resource requirements. It may need either a static definition of resources or a dynamic one.
Resource requirements are referred to as static when they are decided at the time of application submission (in most cases, by the client) and when, once the ApplicationMaster starts running, there is no change in that specification. For example, in the case of Hadoop MapReduce, the number of maps is based on the input splits for MapReduce applications and the number of reducers on user input; thus this number depends on a static set of resources selected before the application’s submission.
Even if the requirements are static, there is another differentiating characteristic in terms of how the scheduling of those resources happens:
![]() All of the allocated containers may be required to run together—a kind of gang scheduling where resource usage follows a static all-or-nothing model.
All of the allocated containers may be required to run together—a kind of gang scheduling where resource usage follows a static all-or-nothing model.
![]() Alternatively, resource usage may change elastically, such that containers can proceed with their work as they are allocated independently of the availability of resources for the remaining containers.
Alternatively, resource usage may change elastically, such that containers can proceed with their work as they are allocated independently of the availability of resources for the remaining containers.
When dynamic resource requirements are applied, the ApplicationMaster may choose how many resources to request at run time based on criteria such as user hints, availability of cluster resources, and business logic.
In either case, once a set of resource requirements is clearly defined, the ApplicationMaster can begin sending the requests across to the scheduler and then schedule the allocated containers to do the desired work.
Scheduling
When an ApplicationMaster accumulates enough resource requests or a timer expires, it can send the requests in a heartbeat message, via the allocate API, to the ResourceManager. The allocate call is the single most important API between the ApplicationMaster and the scheduler. It is used by the ApplicationMaster to inform the ResourceManager about its requests; it is also used as the liveliness signal. At any point in time, only one thread in the ApplicationMaster can invoke the allocate API; all such calls are serialized on the ResourceManager per ApplicationAttempt. Because of this, if multiple threads ask for resources via the allocate API, each thread may get an inconsistent view of the overall resource requests.
The ApplicationMaster asks for specific resources via a list of ResourceRequests of resourceAsks, and a list of container IDs or containersToBeReleased. The containers-ToBeReleased are any containers that were allocated by the scheduler in earlier cycles but are no longer needed. The response contains a list of newly allocated containers, the statuses of application-specific containers that completed since the previous interaction between the ApplicationMaster and the ResourceManager, and an indicator (availResources) to the application about available headroom for cluster resources. The ApplicationMaster can use the container statuses to glean information about completed containers and, for example, react to failure. The headroom can be used by the ApplicationMaster to tune its future requests for resources. For example, the MapReduce ApplicationMaster can use this information to schedule map and reduce tasks appropriately so as to avoid deadlocks (e.g., to prevent using up all its headroom for reduce tasks).
After the initial request, in response to subsequent heartbeats, the ApplicationMaster will receive allocated resources at a particular node in the cluster in the form of a container. Based on the containers it receives from the ResourceManager, the ApplicationMaster can do a second level of scheduling and assign its container to whichever task that is part of its execution plan. Note that, depending on the availability of resources, the timing of node heartbeats, and the scheduling algorithm, some of the subsequent calls may not return any containers even though there are outstanding requests. ApplicationMasters are supposed to keep making more allocate calls with unchanged requests until they get the containers that they need. If the requests set needs to change, the next allocate API can send the modified set of requests, and can potentially get containers for previous requests that were already submitted. The ApplicationMaster will also need to update its resource requests to the ResourceManager as the containers it receives start fulfilling requirements.
In contrast to other resource management systems, resource allocations in YARN to an application are late binding; that is, the ApplicationMaster is obligated only to use resources as provided by the container; it does not have to apply them to the logical task for which it originally requested the resources. There are two ways the ApplicationMaster can request and schedule resources:
![]() Inform ResourceManager of all the resource requests upfront and let the global scheduler make all the decisions.
Inform ResourceManager of all the resource requests upfront and let the global scheduler make all the decisions.
![]() Interact dynamically with ResourceManager to let the scheduler take care of the global scheduling and, depending on the availability of resources and the application’s business logic, do a second scheduling pass on the allocated containers.
Interact dynamically with ResourceManager to let the scheduler take care of the global scheduling and, depending on the availability of resources and the application’s business logic, do a second scheduling pass on the allocated containers.
As an example, the MapReduce ApplicationMaster takes advantage of the dynamic two-level scheduling. When the MapReduce ApplicationMaster receives a container, it matches that container against the set of pending map tasks, selecting a task with input data closest to the container, first trying data local tasks, and then falling back to rack locality. If the ApplicationMaster decides to run a map task in the container, the ApplicationMaster will update its request so that the requests on other nodes where this map task was originally needed are adjusted accordingly.
Scheduling Protocol and Locality
In YARN, an application (via the ApplicationMaster) can ask for containers of varying sizes, ranging from a minimum size all the way to the maximum size stipulated by the scheduler. It can also ask for different numbers of container types.
Resource Requests
The ResourceRequest object is used by the ApplicationMaster for resource requests. As use-cases evolve, this API is expected to change. At this time, it includes the following elements:
![]() Priority of the request.
Priority of the request.
![]() The name of the resource location on which the allocation is desired. It currently accepts a machine or a rack name. A special value of “*” (asterisk) signifies that any host/rack is acceptable to the application.
The name of the resource location on which the allocation is desired. It currently accepts a machine or a rack name. A special value of “*” (asterisk) signifies that any host/rack is acceptable to the application.
![]() Resource capability, which is the amount or size of each container required for that request.
Resource capability, which is the amount or size of each container required for that request.
![]() Number of containers, with respect to the specifications of priority and resource location, that are required by the application.
Number of containers, with respect to the specifications of priority and resource location, that are required by the application.
![]() A Boolean relaxLocality flag (defaults to true), which tells the ResourceManager if the application wants locality to be loose (i.e., allow fall-through to rack or “*” in case of no local containers) or strict (i.e., specify hard constraints on container placement).
A Boolean relaxLocality flag (defaults to true), which tells the ResourceManager if the application wants locality to be loose (i.e., allow fall-through to rack or “*” in case of no local containers) or strict (i.e., specify hard constraints on container placement).
The ApplicationMaster is responsible for computing the resource requirements of the application (e.g., input splits for MapReduce applications) and translating them into the ResourceRequest objects understood by the scheduler.
The main advantage of such a specification for the ResourceRequest is that it is extremely compact in terms of the amount of state necessary per application. It is also not stressful on the ResourceManager in terms of scheduling demands, and it lessens the amount of information exchanged between the ApplicationMaster and the ResourceManager. This design is crucial for scaling the ResourceManager. The size of the requests per application in this model is bounded by the cluster size (number of nodes + number of racks) and by the number of priorities and resource capabilities that are acceptable.
There is an apparent limitation to this model because there is a loss of information in the translation from the application’s affinity to the hosts/racks. This translation is one-way and irreversible; hence the ResourceManager has no concept of relationships in between the resource requests. For example, an application might need only one container on a specific rack, but specify that it wants one container each on the two hosts on the rack. The moment a container is allocated on one of the nodes, the request on the other node can be automatically cancelled. Currently, the existing grammar doesn’t let applications specify such complex relationships. YARN stipulates that the second-level scheduling pass that happens in the ApplicationMaster handles such relationships, which may be very specific to the application in question.
Scheduling Example
Assume there are four racks—rackA, rackB, rackC, and rackD—in the cluster. Also assume that each rack has only four machines each, named host-rackName-12[3-6].domain.com. Imagine an application whose data consists of a total of four files, which are physically located on host-A-123.domain.com, host-A-124.domain.com, host-B-123.domain.com, and host-B-124.domain.com, respectively. For efficient operation, this application expects YARN to allocate containers of 1 GB memory, one container each on each node. But depending on the cluster status and other users’ applications, YARN may or may not be able to allocate containers exactly in that manner. The application decides that it can live with rack-local containers in case node-local resources are not available, so it specifies a requirement of two containers each on the racks rackA and rackB. It doesn’t care about containers being allocated on the remaining hosts or racks, so it doesn’t specify anything for them. Overall, it has a requirement of getting four containers, so it specifies that “*” matches to a total of four containers. The entire ResourceRequest can be expressed as shown in Table 7.1.

Table 7.1 Example ResourceRequest
Note that the number of required containers at a rack doesn’t necessarily need to be the aggregate across all nodes on that rack. For example, if the application definitely prefers one container each on host-A-123 and host-A-124 for doing a specific piece of computation and needs one more container on rackA in addition to do some kind of rack-level aggregation, it can make the request shown in Table 7.2.

Table 7.2 Example Resource Request for Two Specific Hosts and Rack
Similarly, the sum total of requirements across all racks doesn’t necessarily need to match the value against “*”. Unlike the host- and rack-level specifications, the number of containers specified against “*” denotes the total number of containers absolutely required by the application.
Now assume that the application no longer needs the container on host-A-124 anymore. It then needs to update the ResourceRequest as shown in Table 7.3.

Table 7.3 Example Change in Resource Request
By the time this newly updated request is sent out, the ResourceManager may have already allocated a container on host-A-124. When such conditions arise, the ApplicationMaster is responsible for resolving any allocations in flight, with the local changes taking place in its resource requirements.
Locality Constraints
All the locality constraints for the application can be specified using the resource locations as described in the preceding example. In addition, the application can specify whether locality should be loose or strict using the relaxLocality flag against each request. If it is set to true, which is the default, the ResourceManager will wait for a while to allocate local containers; if this effort fails, it will fall through to the next level of resource location, from node to rack or from rack to “*”. In the case where the relaxLocality flag is set to false, the ResourceManager will not serve such request until such a resource-location has enough free capacity to satisfy the request.
Priorities
Priorities are used for ordering the importance of resource requests. Higher-priority requests of an application are served first by the ResourceManager before the lower-priority requests of the same application are handled. There is no cross-application implication of priorities. Potentially, resources of different capabilities can be requested at the same priority, in which case the ResourceManager may order them arbitrarily.
Launching Containers
Once the ApplicationMaster obtains containers from the ResourceManager, it can then proceed to actual launch of the containers. Before launching a container, it first has to construct the ContainerLaunchContext object according to its needs, which can include allocated resource capability, security tokens (if enabled), the command to be executed to start the container, an environment for the process, necessary binaries/jar/shared objects, and more. It can either launch containers one by one by communicating to a NodeManager, or it can batch all containers on a single node together and launch them in a single call by providing a list of StartContainerRequests to the NodeManager.
The NodeManager sends a response via StartContainerResponse that includes a list of successfully launched containers, a container ID-to-exception map for each failed StartContainerRequest in which the exception indicates errors per container, and an allServicesMetaData map from the names of auxiliary services and their corresponding metadata.
The ApplicationMaster can also get updated statuses for submitted but still to be launched containers as well as already launched containers.
Figure 7.7 illustrates the interaction of the ApplicationMaster with the NodeManagers to start/stop containers and get container status. Note that the ApplicationMaster does not communicate with the ResourceManager at this point.
Figure 7.7 ApplicationMaster interacting with NodeManager
The ApplicationMaster can also request a NodeManager to stop a list of containers running on that node by sending a StopContainersRequest that includes the container IDs of the containers that should be stopped. The NodeManager sends a response via StopContainersResponse, which includes a list of container IDs of successfully stopped containers as well as a container ID-to-exception map for each failed request in which the exception indicates errors from the particular container.
When an ApplicationMaster exits, depending on its submission context, the ResourceManager may choose to kill all the running containers that are not explicitly terminated by the ApplicationMaster itself.
Completed Containers
As previously described, when containers finish, the ApplicationMasters are informed by the ResourceManager about the event. Because the ResourceManager does not interpret (or care about) the container status, the ApplicationMaster determines the semantics of the success or failure of the container exit status reported through the ResourceManager.
Handling of container failures is the responsibility of the applications/frameworks. YARN is responsible only for providing information to the applications/framework. The ResourceManager collects information about all the finished containers as part of the allocate API’s response, and it returns this information to the corresponding ApplicationMaster. It is up to the ApplicationMaster to look at information such as the container status, exit code, and diagnostics information and act on it appropriately. For example, when the MapReduce ApplicationMaster learns about container failures, it retries map or reduce tasks by requesting new containers from the ResourceManager until a configured number of attempts fail for a single task.
ApplicationMaster Failures and Recovery
The ApplicationMaster is also tasked with recovering the application after a restart that was due to the ApplicationMaster’s own failure. When an ApplicationMaster fails, the ResourceManager simply restarts an application by launching a new ApplicationMaster (or, more precisely, the container running the ApplicationMaster) for a new ApplicationAttempt; it is the responsibility of the new ApplicationMaster to recover the application’s previous state This goal can be achieved by having the current ApplicationAttempts persist their current state to external storage for use by future attempts. Any ApplicationMaster can obviously just run the application from scratch all over again instead of recovering the past state. For example, as of this book’s writing, the Hadoop MapReduce framework’s ApplicationMaster recovered its completed tasks, but running tasks as well as the tasks that completed during ApplicationMaster recovery would be killed and rerun.
Coordination and Output Commit
The ApplicationMaster is also tasked with any coordination needed by containers. If a framework supports multiple containers contending for a resource or an output commit, ApplicationMaster should provide synchronization primitives for them, so that only one of those containers can access the shared resource, or it should promote the output of one while the other is ordered to wait or abort. The MapReduce ApplicationMaster defines the number of multiple attempts per task that can potentially run concurrently; it also provides APIs for tasks so that the output-commit operation demonstrates consistency.
There is another dimension of application-level coordination or output commit with YARN. Even though one can control the number of application attempts, for any given application the platform will try its best to make sure that there is only one valid ApplicationMaster running in the cluster at any point in time. However, YARN cannot guarantee this. Thus there may be a presently running valid ApplicationMaster and another ApplicationMaster from a previous attempt that is marked as either failed or killed but is actually still running. There are several situations where this can happen. One of the most common cases involves a network partition: The node running the ApplicationMaster may be cut off from ResourceManager, so YARN cannot really enforce the one-ApplicationMaster-at-a-time restriction. Application writers must be aware of this possibility, and should code their applications and frameworks to handle the potential multiple-writer problems. Such a multiple-writer problem has the biggest impact on the application-level commit, when two ApplicationAttempts of the same application race to a shared resource, and the output commit, where one may run into issues like data corruption.
Information for Clients
Some services previously offered by the Hadoop JobTracker—such as returning job progress over RPC, a web interface to find job status, and tracking finished jobs via JobHistory—are no longer part of YARN. They are provided either by the ApplicationMasters or by custom-built framework daemons. At the time of this writing, a generic solution to server framework-specific data with reasonable abstractions was a work in progress.
Security
If the application exposes a web service or an HTTP/socket/RPC interface, it is also responsible for all aspects of its secure operation. YARN merely secures its deployment.
Cleanup on ApplicationMaster Exit
When an ApplicationMaster is done with all its work, it should explicitly unregister with the ResourceManager by sending a FinishApplicationRequest. Similar to registration, as part of this request ApplicationMasters can report IPC and web URLs where clients can go once the application finishes and the ApplicationMaster is no longer running.
Once an ApplicationMaster’s finish API causes the application to finish, the ApplicationMaster (i.e., the ApplicationMaster’s container) will not immediately be killed until either the ApplicationMaster exits on its own or the ApplicationMaster liveliness interval is reached. This is done so as to enable ApplicationMasters to do some cleanup after the finish API is successfully recorded on the ResourceManager.
YARN Containers
As described earlier, a container in YARN represents a unit of work in an application. A container runs on a node, managed by a NodeManager; makes use of some resources on a node (e.g., memory, disk, CPU); depends on some libraries that are represented as local resources; and performs the needed work. While we have discussed most of how a container comes into existence, we have not talked about what constitutes the running responsibilities of a container. Note that because containers in YARN are directly mapped to a process in the underlying operation system, we may be using these terms interchangeably.
Container Environment
Once a container starts, for it to be able to perform its duties, it may depend on the availability of various pieces of information. Some of this information may be static, and some may be dynamic—that is, resolvable only at run time.
Static information may include libraries, input and output paths, and specifications of external systems like database or file system URLs. The following list highlights some of this information and explains how a container can obtain it:
![]() The ApplicationMaster should describe all libraries and other dependencies needed by a container for its start-up as part of its ContainerLaunchContext. That way, at the time of the container launch, such dependencies will already be downloaded by the localization in the NodeManager and be ready for linking directly.
The ApplicationMaster should describe all libraries and other dependencies needed by a container for its start-up as part of its ContainerLaunchContext. That way, at the time of the container launch, such dependencies will already be downloaded by the localization in the NodeManager and be ready for linking directly.
![]() Input/output paths and file-system URLs are a part of the configuration that is beyond the control of YARN. Applications are required to propagate this information themselves. There are multiple ways one can do this:
Input/output paths and file-system URLs are a part of the configuration that is beyond the control of YARN. Applications are required to propagate this information themselves. There are multiple ways one can do this:
![]() Environment variables
Environment variables
![]() Command-line parameters
Command-line parameters
![]() Separate configuration files that are themselves passed as local resources
Separate configuration files that are themselves passed as local resources
![]() Local directories where containers can write some outputs are determined by the environment variable ApplicationConstants.Environment.LOCAL_DIRS.
Local directories where containers can write some outputs are determined by the environment variable ApplicationConstants.Environment.LOCAL_DIRS.
![]() Containers that need to log output or error statements to files need to make use of the log directory functionality. The NodeManager decide the location of log directories at run time. Because of this, a container’s command line or its environment variables should point to the log directory by using a specialized marker defined by ApplicationConstants.LOG_DIR_EXPANSION_VAR (i.e., <LOG_DIR>). This marker will be automatically replaced with the correct log directory on the local file system when a container is launched.
Containers that need to log output or error statements to files need to make use of the log directory functionality. The NodeManager decide the location of log directories at run time. Because of this, a container’s command line or its environment variables should point to the log directory by using a specialized marker defined by ApplicationConstants.LOG_DIR_EXPANSION_VAR (i.e., <LOG_DIR>). This marker will be automatically replaced with the correct log directory on the local file system when a container is launched.
![]() The user name, home directory, container ID, and some other environment-specific information are exposed as environment variables by the NodeManager; containers can simply look them up in their environment. All such environment variables are documented by theApplicationConstants.Environment API.
The user name, home directory, container ID, and some other environment-specific information are exposed as environment variables by the NodeManager; containers can simply look them up in their environment. All such environment variables are documented by theApplicationConstants.Environment API.
![]() Security-related tokens are all available on the local file system in a file whose name is provided in the container’s environment, keyed by the name ApplicationConstants.CONTAINER_TOKEN_FILE_ENV_NAME. Containers can simply read this file and load all the credentials into memory.
Security-related tokens are all available on the local file system in a file whose name is provided in the container’s environment, keyed by the name ApplicationConstants.CONTAINER_TOKEN_FILE_ENV_NAME. Containers can simply read this file and load all the credentials into memory.
Dynamic information includes settings that can potentially change during the lifetime of a container. It is composed of things like the location of the parent ApplicationMaster and the location of map outputs for a reduce task. Most of this information is the responsibility of the application-specific implementation. Some of the options include the following:
![]() The ApplicationMaster’s URL can be passed to the container via environment variables, a command-line argument, or the configuration, but any dynamic changes to it during fail-over can be found by directly communicating to the ResourceManager as a client.
The ApplicationMaster’s URL can be passed to the container via environment variables, a command-line argument, or the configuration, but any dynamic changes to it during fail-over can be found by directly communicating to the ResourceManager as a client.
![]() The ApplicationMaster can coordinate the locations of the container’s output and the corresponding auxiliary services, making this information available to other containers.
The ApplicationMaster can coordinate the locations of the container’s output and the corresponding auxiliary services, making this information available to other containers.
![]() The location of the HDFS NameNode (in case of a fail-over scenario) may be obtained from a dynamic plug-in that performs a configuration-based lookup of where an active NameNode is running.
The location of the HDFS NameNode (in case of a fail-over scenario) may be obtained from a dynamic plug-in that performs a configuration-based lookup of where an active NameNode is running.
Communication with the ApplicationMaster
Unlike with Hadoop version 1 MapReduce, there is no communication from a container to the parent NodeManager in YARN. Once a container starts, it is not required to report anything to the NodeManager. The code that runs the container is completely user written and, as such, all the NodeManager really enforces is the proper utilization of resources so that container runs within its limits.
It is also not required that containers report to their parent ApplicationMasters. In many cases, containers may just run in isolation, perform their work, and go away. On their exit, ApplicationMasters will eventually learn about their completion status, either directly from the NodeManager or via the NodeManager–ResourceManager–ApplicationMaster channel for status of completed containers. If an application needs its container to be in communication with its ApplicationMaster, however, it is entirely up to the application/framework to implement such a protocol. YARN neither enforces this type of communication nor supports it. Consequently, an application that needs to monitor the application-specific progress, counters, or status should have its container configured to report such status directly to the ApplicationMaster via some interprocess communication. Figure 7.8 shows an overview of the interaction of containers with the NodeManager and the ApplicationMaster.
Figure 7.8 Container’s interaction with ApplicationMaster and NodeManager
Summary for Application-writers
The following is a quick summary of the responsibilities for application writers. Consult Chapter 10, “Apache Hadoop YARN Application Example,” and Chapter 11, “Using Apache Hadoop YARN Distributed-Shell,” for actual application examples.
![]() Submit the application by passing a ContainerLaunchContext for the ApplicationMaster to the ResourceManager.
Submit the application by passing a ContainerLaunchContext for the ApplicationMaster to the ResourceManager.
![]() After the ResourceManager starts the ApplicationMaster, the ApplicationMaster should register with the ResourceManager and periodically report its liveliness and resource requirements over the wire.
After the ResourceManager starts the ApplicationMaster, the ApplicationMaster should register with the ResourceManager and periodically report its liveliness and resource requirements over the wire.
![]() Once the ResourceManager allocates a container, the ApplicationMaster can construct a ContainerLaunchContext to launch the container on the corresponding NodeManager. It may also monitor the status of the running container and stop it when the work is done. Monitoring the progress of work done inside the container is strictly the ApplicationMaster’s responsibility.
Once the ResourceManager allocates a container, the ApplicationMaster can construct a ContainerLaunchContext to launch the container on the corresponding NodeManager. It may also monitor the status of the running container and stop it when the work is done. Monitoring the progress of work done inside the container is strictly the ApplicationMaster’s responsibility.
![]() Once the ApplicationMaster is done with its overall work, it should unregister from the ResourceManager and exit cleanly.
Once the ApplicationMaster is done with its overall work, it should unregister from the ResourceManager and exit cleanly.
![]() Optionally, frameworks may add control flow between their containers and the ApplicationMaster as well as between their own clients and the ApplicationMaster to report status information.
Optionally, frameworks may add control flow between their containers and the ApplicationMaster as well as between their own clients and the ApplicationMaster to report status information.
In general, an ApplicationMaster that is hardened against faults, including its own, is nontrivial. The client libraries that ship with YARN—YarnClient, NMClient, and AMRMClient—expose a higher-level API and are strongly recommended over using low-level protocols.
Wrap-up
In YARN, the ResourceManager is fundamentally limited to scheduling and does not manage user applications. This design addresses the issues of better scalability and support for alternative (non-MapReduce) programming paradigms.
The YARN NodeManager has more responsibility than the Hadoop version 1 TaskTracker and is designed to tightly manage node resources in the form of application containers. It also supports better log management and provides a flexible method for multiple-container interaction by providing the auxiliary services capability.
Finally, some of the responsibility for managing resources has been pushed to the user with the introduction of the ApplicationMaster. This responsibility also offers great flexibility, such that applications can now manage their containers and application resources requirements dynamically at run time.