Professional Microsoft SQL Server 2014 Integration Services (Wrox Programmer to Programmer), 1st Edition (2014)
Chapter 8. Creating an End-to-End Package
WHAT’S IN THIS CHAPTER?
· Walking through a basic transformation
· Performing mainframe ETL with data scrubbing
· Making packages dynamic
WROX.COM CODE DOWNLOADS FOR THIS CHAPTER
You can find the wrox.com code downloads for this chapter at www.wrox.com/go/prossis2014 on the Download Code tab.
Now that you’ve learned about all the basic tasks and transformations in SSIS, you can jump into some practical applications for SSIS. You’ll first start with a normal transformation of data from a series of flat files into SQL Server. Next you’ll add some complexity to a process by archiving the files automatically. The last example demonstrates how to make a package that handles basic errors and makes the package more dynamic. As you run through the tutorials, remember to save your package and your project on a regular basis to avoid any loss of work.
BASIC TRANSFORMATION TUTORIAL
As you can imagine, the primary reason people use SSIS is to read the data from a source and write it to a destination after it’s potentially transformed. This tutorial walks you through a common scenario: you want to copy data from a Flat File Source to a SQL Server table without altering the data. This may be a simple example, but the examples will get much more complex in later chapters.
Start the tutorial by going online to the website for this book and downloading the sample extract that contains zip code information about cities. The zip code extract was retrieved from public record data from the 1990 census and has been filtered to contain only Florida cities, in order to reduce download time. You’ll use this in the next tutorial as well, so it’s very important not to skip this first tutorial. You can download the sample extract file, called ZipCodeExtract.csv, from this book’s web page at www.wrox.com. Place the file into a directory called C:\ProSSIS\Data\Ch08.
Open SQL Server Data Tools (SSDT) and select File ⇒ New ⇒ Project. Then select Integration Services Project as your project type. Type ProSSISCh08 as the project name, and accept the rest of the defaults (as shown in Figure 8-1). You can place the project anywhere on your computer; the default location is under the users\"Your User Name"\Documents\Visual Studio 2012\Projects folder. In this example, the solution is created in c:\ProSSIS\Data\Ch08, but you may use the default location if you so desire.
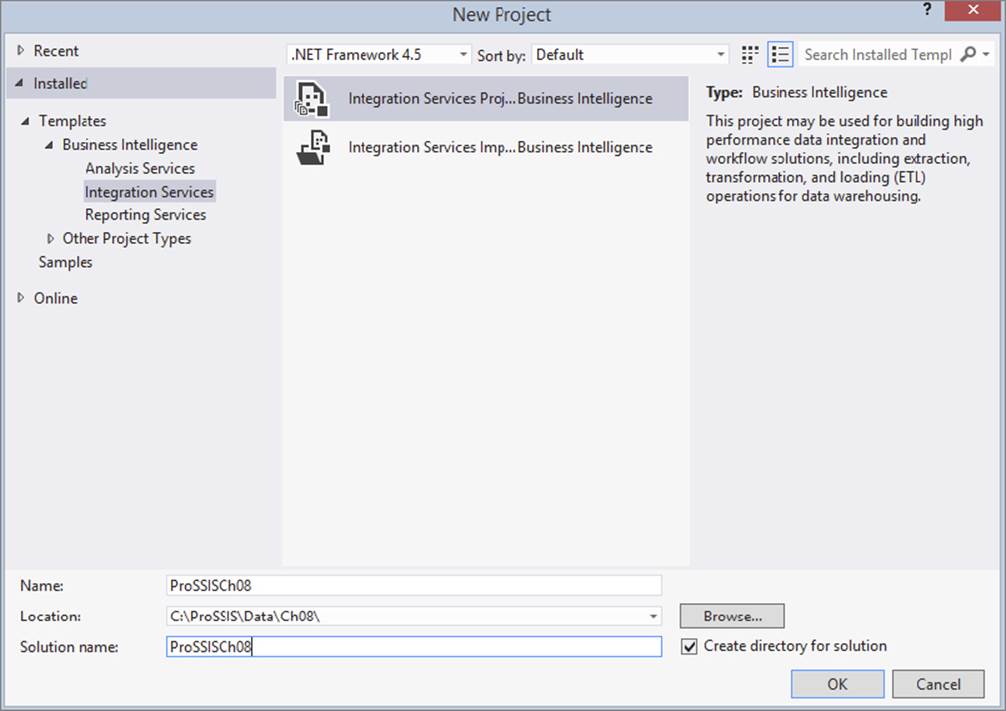
FIGURE 8-1
The project will be created, and you’ll see a default Package.dtsx package file in the Solution Explorer. Right-click the file, select Rename, and rename the file ZipLoad.dtsx. If the package isn’t open yet, double-click it to open it in the package designer.
Creating Connections
Now that you have the package created, you need to add a connection that can be used across multiple packages. In the Solution Explorer, right-click the Connection Managers folder and select New Connection Manager. This opens the Add SSIS Connection Manager window.
Select the OLEDB connection and click Add, which opens the Configure OLEDB Connection Manager window. If this is the first time you are creating a connection, then the Data Connection list in the left window will be empty.
NOTE There are many ways to create the connection. For example, you could create it as you’re creating each source and destination. You can also use the new Source and Destination Assistants when building a Data Flow. Once you’re more experienced with the tool, you’ll find what works best for you.
Click the New button at the bottom of the window. Your first Connection Manager for this example will be to SQL Server, so select Native OLE DB\SQL Native Client 11.0 as the Provider. For the Server Name option, type the name of your SQL Server and enter the authentication mode that is necessary for you to read and write to the database, as shown in Figure 8-2. If you are using a local instance of SQL Server, then you should be able to use Localhost as the server name and Windows authentication for the credentials. Lastly, select the AdventureWorks database. If you don’t have the AdventureWorks database, select any other available database on the server. You can optionally test the connection. Now click OK. You will now have a Data Source in the Data Source box that should be selected. Click OK. You will now see a Data Source under the Connection Manager folder in the Solution Explorer, and the same Data Source in the Connection Manager window in the ZipLoad Package you first created.
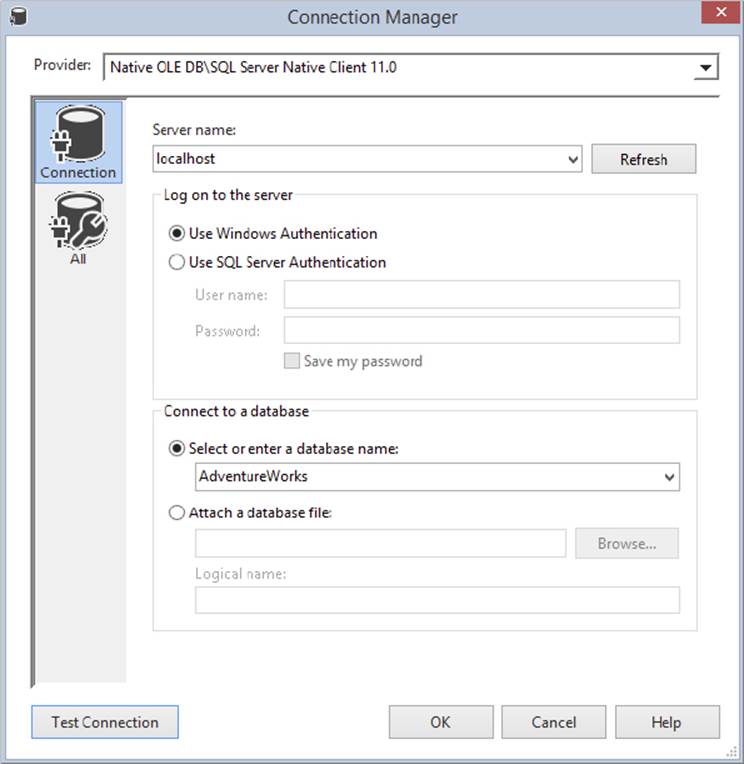
FIGURE 8-2
This new Data Source will start with “(project)”. The name of the connection automatically contains the server name and the database name. This is not a good naming convention because packages are almost always moved from server to server — for example, development, QA, and production servers. Therefore, a better naming convention would be the connection type and the database name. Right-click on the Connection Manager you just created in the Solution Explorer and rename it to OLEDB_AdventureWorks. You can create connections in the package and convert them to project connections also. Any project-level connections automatically appear in the Connection Manager window in all packages in that project. If a connection is needed only in one package in the project, then it can be created at the package level. To create a connection at the package level, right-click in the Connection Manager window in a package and follow the same steps used to create the project-level connection described previously.
Next, create a Flat File connection and point it to the ZipCodeextract.csv file in your C:\ProSSIS\Data\Ch08 directory. Right-click in the Connection Manager area of the package designer, and select New Flat File Connection. Name the connection FF_ZipCode_CSV, and add any description you like. Point the File Name option to C:\ProSSIS\Data\Ch08\ZipCodeExtract.csv or browse to the correct location by clicking Browse.
NOTE If you can’t find the file, ensure that the file type filter is adjusted so you’re not looking for just *.txt files, which is the default setting. Set the filter to All Files to ensure you can see the file.
Set the Format dropdown box to Delimited, with <none> set for the Text Qualifier option; these are both the default options. The Text Qualifier option enables you to specify that character data is wrapped in quotes or some type of qualifier. This is helpful when you have a file that is delimited by commas and you also have commas inside some of the text data that you do not wish to separate by. Setting a Text Qualifier will ignore any commas inside the text data. Lastly, check the “Column names in the first data row” option. This specifies that your first row contains the column names for the file.
Select the Columns tab from the left side of the editor to see a preview of the file data and to set the row and column delimiters. The defaults are generally fine for this screen. The Row Delimiter option should be set to {CR}{LF}, which means that a carriage return and line feed separates each row. The Column Delimiter option is carried over from the first page and is therefore set to “Comma {,}”. In some extracts that you may receive, the header record may be different from the data records, and the configurations won’t be exactly the same as in the example.
Now select the Advanced tab from the left side of the editor. Here, you can specify the data types for each of the three columns. The default for this type of data is a 50-character string, which is excessive in this case. Click Suggest Types to comb through the data and find the best data type fit for it. This will open the Suggest Column Types dialog, where you should accept the default options and click OK.
At this point, the data types in the Advanced tab have changed for each column. One column in particular was incorrectly changed. When combing through the first 100 records, the Suggest Column Types dialog selected a “four-byte signed integer [DT_I4]” for the zip code column, but your Suggest Types button may select a smaller data type based on the data. While this would work for the data extract you currently have, it won’t work for states that have zip codes that begin with a zero in the northeast United States. Change this column to a string by selecting “string [DT_STR]” from the DataType dropdown, and change the length of the column to 5 by changing the OutputColumnWidth option (see Figure 8-3). Finally, change the TextQualified option to False, and then click OK.
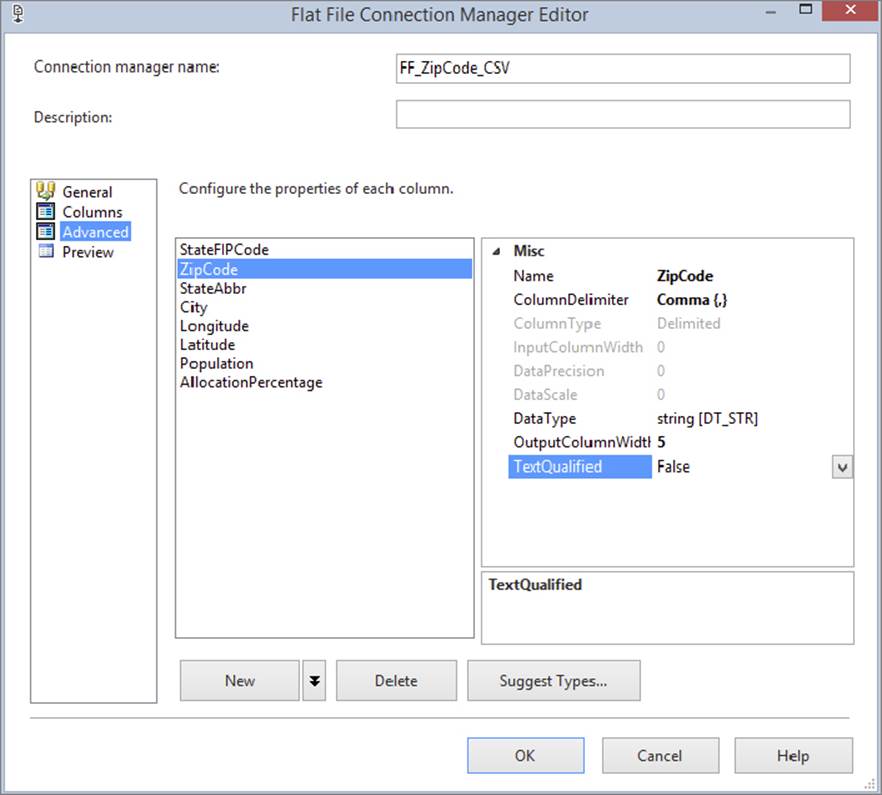
FIGURE 8-3
Creating the Control Flow
With the first two connections created, you can now define the package’s Control Flow. In this tutorial, you have only a single task, the Data Flow Task. In the Toolbox, drag the Data Flow Task over to the design pane in the Control Flow tab. Next, right-click the task and select Rename to rename the task Load ZipCode Data.
Creating the Data Flow
This section reflects the most detailed portion of almost all of your packages. The Data Flow is where you will generally spend 70 percent of your time as an SSIS developer. To begin, double-click the Data Flow Task to drill into the Data Flow.
NOTE When opening a task for editing, always double-click the icon on the left side of the task. Otherwise, you may start renaming the task instead of opening it. You can also right-click on the task and select Edit.
Double-clicking on the Data Flow Task will automatically take you to the Data Flow tab. Note that the name of the task — Load ZipCode Data — is displayed in the Data Flow Task dropdown. If you had more than one Data Flow Task, the names of each would appear as options in the dropdown.
Drag and drop a Source Assistant from the Toolbox onto the Data Flow design pane. Select Flat File in the left pane of the Source Assistant. Then select FF_ZipCode_CSV in the right pane and Click OK. Rename the source Florida ZipCode File in the Properties window.
NOTE All the rename instructions in these tutorials are optional, but they will keep you on the same page as the tutorials in this book. In a real-world situation, ensuring the package task names are descriptive will make your package self-documenting. This is due to the names of the tasks being logged by SSIS. Logging is discussed in Chapter 22.
Double-click on the source, and you will see it is pointing to the Connection Manager called FF_ZipCode_CSV. Select the Columns tab and note the columns that you’ll be outputting to the path. You’ve now configured the source, and you can click OK.
Next, drag and drop Destination Assistant onto the design pane. Select SQL Server in the left pane and OLEDB_AdventureWorks in the right pane in the Destination Assistant window and click OK. Rename the new destination AdventureWorks. Select the Florida ZipCode File Source and then connect the path (blue arrow) from the Florida ZipCode File Source to AdventureWorks. Double-click the destination, and AdventureWorks should already be selected in the Connection Manager dropdown box. For the Name of the Table or View option, click the New button next to the dropdown box. This is how you can create a table inside SSDT without having to go back to SQL Server Management Studio.
The default DDL for creating the table uses the destination’s name (AdventureWorks), and the data types may not be exactly what you’d like. You can edit this DDL, as shown here:
CREATE TABLE [AdventureWorks] (
[StateFIPCode] smallint,
[ZipCode] varchar(5),
[StateAbbr] varchar(2),
[City] varchar(16),
[Longitude] real,
[Latitude] real,
[Population] int,
[AllocationPercentage] real
)
However, suppose this won’t do for your picky DBA, who is concerned about performance. In this case, you should rename the table ZipCode (taking out the brackets) and change each column’s data type to a more suitable size and type, as shown in the ZipCode andStateAbbr columns (Ch08SQL.txt):
CREATE TABLE [ZipCode] (
[StateFIPCode] smallint,
[ZipCode] char(5),
[StateAbbr] char(2),
[City] varchar(16),
[Longitude] real,
[Latitude] real,
[Population] int,
[AllocationPercentage] real
)
When you are done changing the DDL, click OK. The table name will be transposed into the Table dropdown box. Finally, select the Mapping tab to ensure that the inputs are mapped to the outputs correctly. SSIS attempts to map the columns based on name; in this case, because you just created the table with the same column names, it should be a direct match, as shown in Figure 8-4.
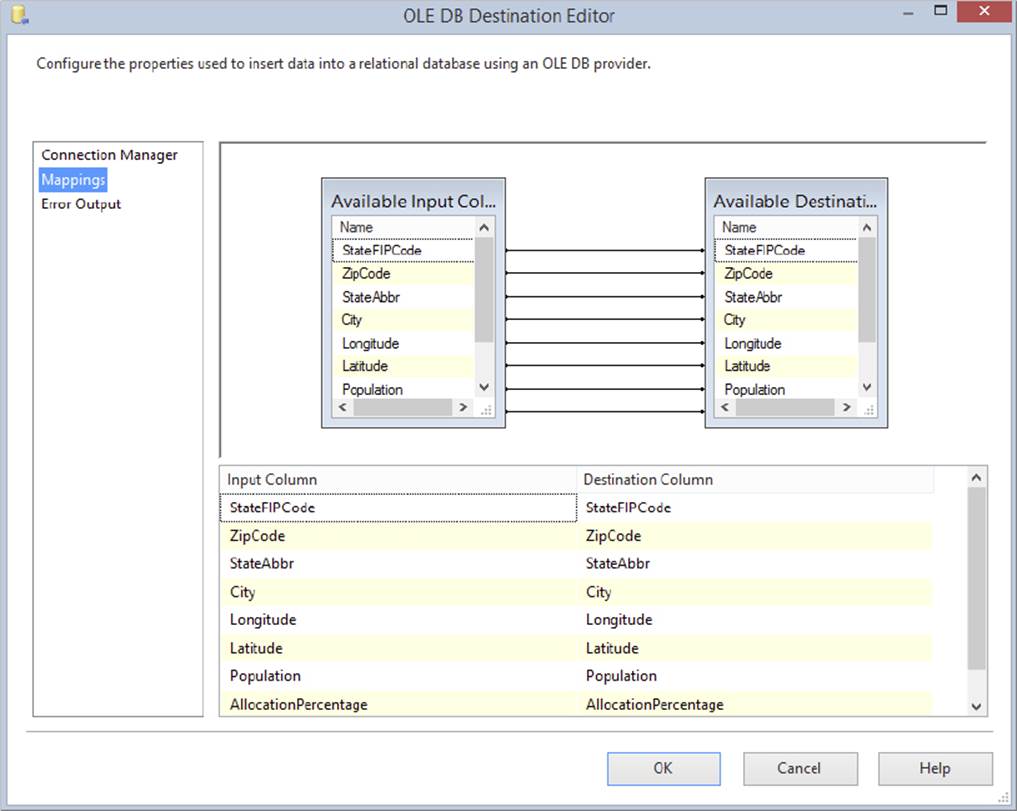
FIGURE 8-4
After confirming that the mappings look like Figure 8-4, click OK.
Completing the Package
With the basic framework of the package now constructed, you need to add one more task to the Control Flow tab to ensure that you can run this package multiple times. To do this, click the Control Flow tab and drag an Execute SQL task over to the design pane. Rename the task Purge ZipCode Table. Double-click the task and select OLEDB_AdventureWorks from the Connection dropdown. Finally, type the following query for the SQLStatement option (you can also click the ellipsis button and enter the query):
TRUNCATE TABLE ZipCode
Click OK to complete the task configuration. To connect the task as a parent to the Load ZipCode Info Task, click the Purge ZipCode Table Task and drag the green arrow onto the Load ZipCode Info Task.
Saving the Package
Your first package is now complete. To save the package, click the Save icon in the top menu or select File ⇒ Save Selected Items. Note here that by clicking Save, you’re saving the .DTSX file to the project, but you have not saved it to the server yet. To do that, you have to deploy the project. Also, SSIS does not version control your packages independently. To version control your packages, you need to integrate a solution like Subversion (SVN) into SSIS, as described in Chapter 17.
Executing the Package
With the package complete, you can attempt to execute it by right-clicking on the package name in the solution explorer and selecting Execute Package. This is a good habit to get into when executing, because other methods, like using the green debug arrow at the top, can cause more to execute than just the package. The package will take a few moments to validate, and then it will execute.
You can see the progress under the Progress tab or in the Output window. In the Control Flow tab, the two tasks display a small yellow circle that begins to spin (in the top right of the task). If all goes well, they will change to green circles with a check. If both get green checks, then the package execution was successful. If your package failed, you can check the Output window to see why. The Output window should be open by default, but in case it isn’t, you can open it by clicking View ⇒ Output. You can also see a graphical version of the Output window in the Progress tab (it is called the Execution Results tab if your package stops). The Execution Results tab will always show the results from the latest package run in the current SSDT session.
You can go to the Data Flow tab, shown in Figure 8-5, to see how many records were copied over. Notice the number of records displayed in the path as SSIS moves from source to destination.
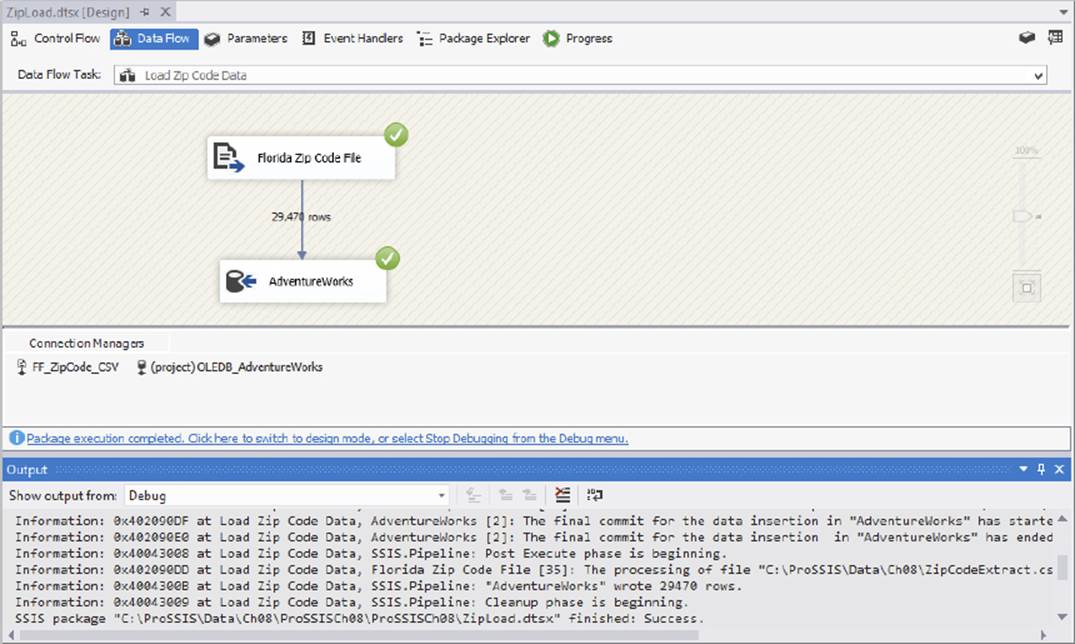
FIGURE 8-5
By default, when you execute a package, you are placed in debug mode. Changes you make in this mode are not made available until you run the package again, and you cannot add new tasks or enter some editors. To break out of this mode, click the square Stop icon or click Debug ⇒ Stop Debugging.
TYPICAL MAINFRAME ETL WITH DATA SCRUBBING
With the basic ETL out of the way, you will now jump into a more complex SSIS package that attempts to scrub data. You can start this scenario by downloading the 010305c.dat public data file from the website for this book into a directory called C:\ProSSIS\Data\Ch08. This file contains public record data from the Department of State of Florida.
In this scenario, you run a credit card company that’s interested in marketing to newly formed domestic corporations in Florida. You want to prepare a data extract each day for the marketing department to perform a mail merge and perform a bulk mailing. Yes, your company is an old-fashioned, snail-mail spammer. Luckily, the Florida Department of State has an interesting extract you can use to empower your marketing department.
The business goals of this package are as follows:
· Create a package that finds the files in the C:\ProSSIS\Data\Ch08 directory and loads the file into your relational database.
· Archive the file after you load it to prevent it from being loaded twice.
· The package must self-heal. If a column is missing data, the data should be added automatically.
· If the package encounters an error in its attempt to self-heal, output the row to an error queue.
· You must audit the fact that you loaded the file and how many rows you loaded.
Start a new package in your existing ProSSISCh08 SSDT project from the first tutorial. Right-click the SSIS Packages folder in the Solution Explorer and select New SSIS Package. This will create Package1.dtsx, or some numeric variation on that name. Rename the fileCorporationLoad.dtsx. Double-click the package to open it if it is not already open.
Since the OLEDB_AdventureWorks connection you created earlier was a project-level connection, it should automatically appear in the Connection Manager window of the package. You now have two packages using the same project-level connection. If you were to change the database or server name in this connection, it would change for both packages.
Next, create a new Flat File Connection Manager just as you did in the last tutorial. When the configuration screen opens, call the connection FF_Corporation_DAT in the General tab.
Note Using naming conventions like this are a best practice in SSIS. The name tells you the type of file and the type of connection.
Enter any description you like. For this Connection Manager, you’re going to configure the file slightly differently. Click Browse and point to the C:\ProSSIS\Data\Ch08\010305c.dat file (keep in mind that the default file filter is *.txt so you will have to change the filter to All Files in order to see the file). You should also change the Text Qualifier option to a single double-quote (“). Check the “Column names in the first data row” option. The final configuration should resemble Figure 8-6. Go to the Columns tab to confirm that the column delimiter is Comma Delimited.
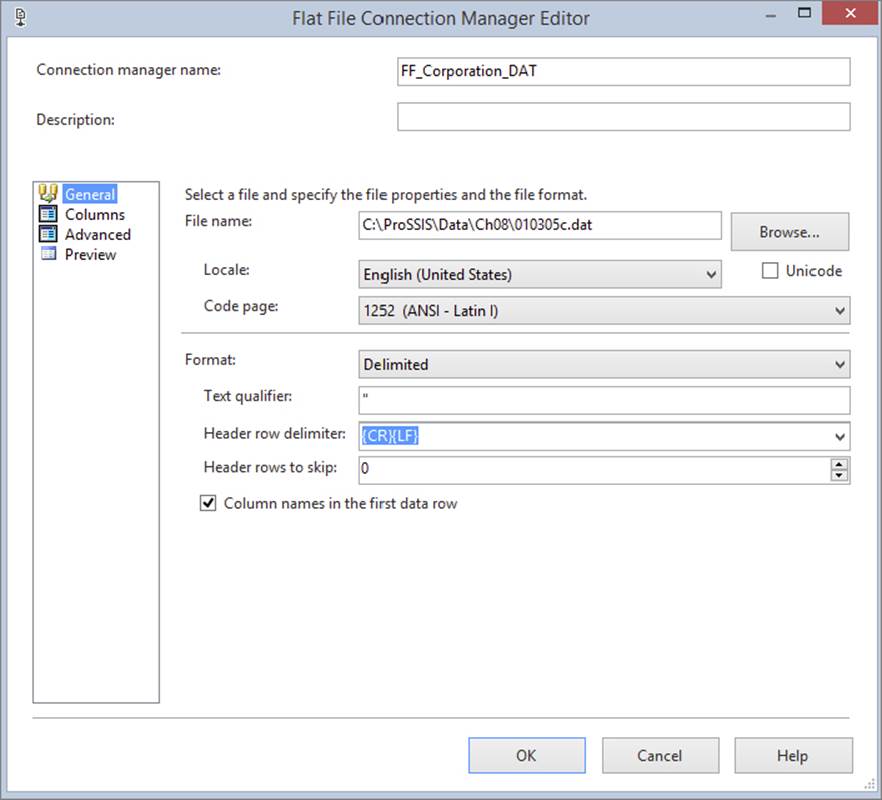
FIGURE 8-6
Next, go to the Advanced tab. By default, each of the columns is set to a 50-character [DT_STR] column. However, this will cause issues with this file, because several columns contain more than 100 characters of data, which would result in a truncation error. Therefore, change the AddressLine1 and AddressLine2 columns to String [DT_STR], which is 150 characters wide, as shown in Figure 8-7. After you’ve properly set these two columns, click OK to save the Connection Manager.
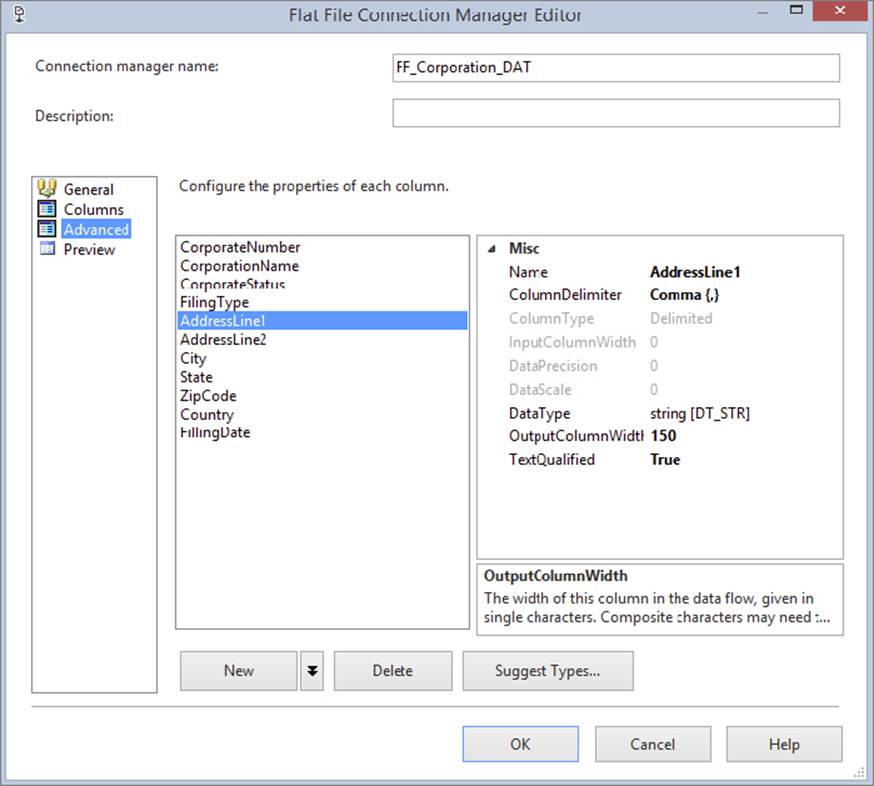
FIGURE 8-7
Creating the Data Flow
With the mundane work of creating the connections now out of the way, you can create the transformations. As you did in the last package, you must first create a Data Flow Task by dragging it from the Toolbox. Name this task Load Corporate Data. Double-click the task to go to the Data Flow tab.
Drag and drop a Flat File Source onto the design pane and rename it Uncleansed Corporate Data. (You could also use the Source Assistant as shown previously; you are being shown a different method here intentionally.) Double-click the source and select FF_Corporation_DAT as the Connection Manager you’ll be using. Click OK to close the screen. You’ll add the destination and transformation in a moment after the scenario is expanded a bit.
Handling Dirty Data
Before you go deeper into this scenario, take a moment to look more closely at this data. As you were creating the connection, if you are a very observant person (I did not notice this until it was too late), you may have noticed that some of the important data that you’ll need is missing. For example, the city and state are missing from some of the records.
NOTE The Data Profiling Task can also help with this situation; it is covered in Chapter 12.
To fix this for the marketing department, you’ll use some of the transformations that were discussed in the last few chapters to send the good records down one path and the bad records down a different path. You will then attempt to cleanse the bad records and then send those back through the main path. There may be some records you can’t cleanse (such as corporations with foreign postal codes), which you’ll have to write to an error log and deal with another time.
First, standardize the postal code to a five-digit format. Currently, some have five digits and some have the full nine-digit zip code with a dash (five digits, a dash, and four more digits). Some are nine-digit zip codes without the dash. To standardize the zip code, you use the Derived Column Transformation. Drag it from the Toolbox and rename it Standardize Zip Code.
Connect the source to the transformation and double-click the Standardize Zip Code Transformation to configure it. Expand the Columns tree in the upper-left corner, find [ZipCode], and drag it onto the Expression column in the grid below. This will prefill some of the information for you in the derived column’s grid area. You now need to create an expression that will take the various zip code formats in the [ZipCode] output column and output only the first five characters. An easy way to do this is with the SUBSTRING function. The SUBSTRING function code would look like this:
SUBSTRING ([ZipCode],1,5)
This code should be typed into the Expression column in the grid. Next, specify that the derived column will replace the existing ZipCode output by selecting that option from the Derived Column dropdown box. Figure 8-8 shows the completed options. When you are done with the transformation, click OK.
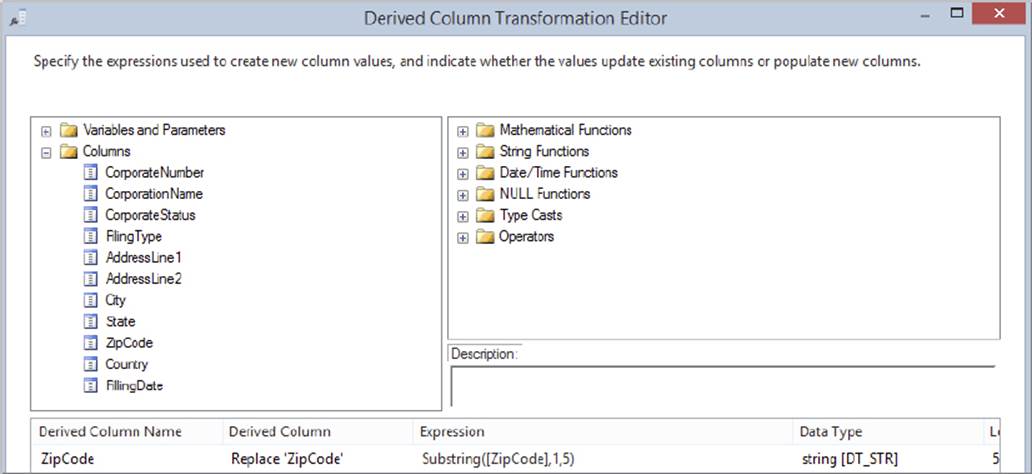
FIGURE 8-8
The Conditional Split Transformation
Now that you have standardized the data slightly, drag and drop the Conditional Split Transformation onto the design pane and connect the blue arrow from the Derived Column Transformation called Standardize Zip Code to the Conditional Split. Rename the Conditional Split Transformation Find Bad Records. The Conditional Split Transformation enables you to push bad records into a data-cleansing process.
To cleanse the data that lacks city or state, you’ll write a condition specifying that any row missing a city or state should be moved to a cleansing path in the Data Flow. Double-click the Conditional Split Transformation after you have connected it from the Derived Column Transformation in order to edit it.
Create a condition called Missing State or City by typing its name in the Output Name column. You now need to write an expression that looks for empty records. One way to do this is to use the LTRIM function. The two vertical bars (||) in the following code are the same as a logical OR in your code. Two & operators would represent a logical AND condition. (You can read much more about the expression language in Chapter 5.) The following code will check for a blank Column 6 or Column 7:
LTRIM([State]) == "" || LTRIM([City]) == ""
The last thing you need to do is give a name to the default output if the coded condition is not met. Call that output Good Data, as shown in Figure 8-9. The default output contains the data that did not meet your conditions. Click OK to close the editor.
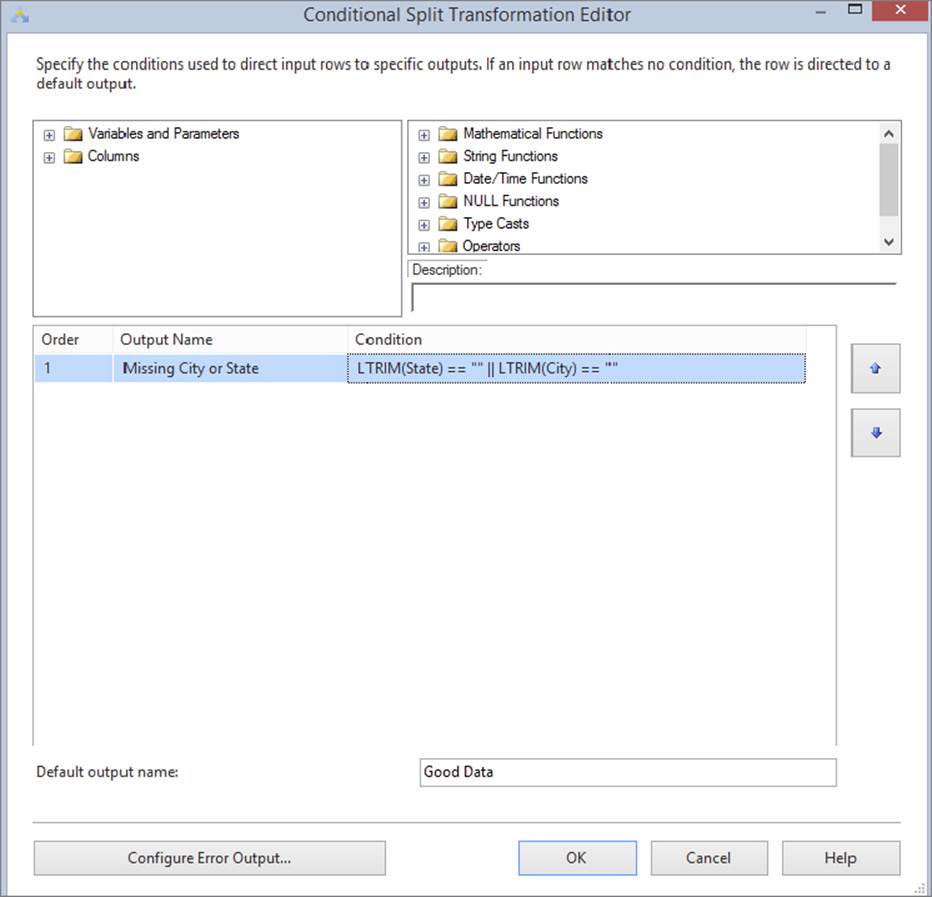
FIGURE 8-9
NOTE If you have multiple cases, always place the conditions that you think will capture most of the records at the top of the list, because at runtime the list is evaluated from top to bottom, and you don’t want to evaluate records more times than needed.
The Lookup Transformation
Next, drag and drop the Lookup Transformation onto the design pane. When you connect to it from the Conditional Split Transformation, you’ll see the Input Output Selection dialog (shown in Figure 8-10). Select Missing State or City and click OK. This will send any bad records to the Lookup Transformation from the Conditional Split. Rename the Lookup Transformation Fix Bad Records.
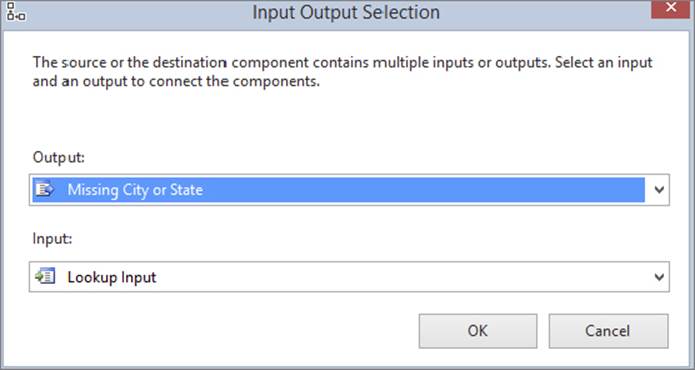
FIGURE 8-10
The Lookup Transformation enables you to map a city and state to the rows that are missing that information by looking the record up in the ZipCode table you loaded earlier. Open the transformation editor for the Lookup Transformation. Then, in the General tab, ensure that the Full Cache property is set and that you have the OLE DB Connection Manager property set for the Connection Type. Change the No Matching Entries dropdown box to “Redirect rows to no match output,” as shown in Figure 8-11.
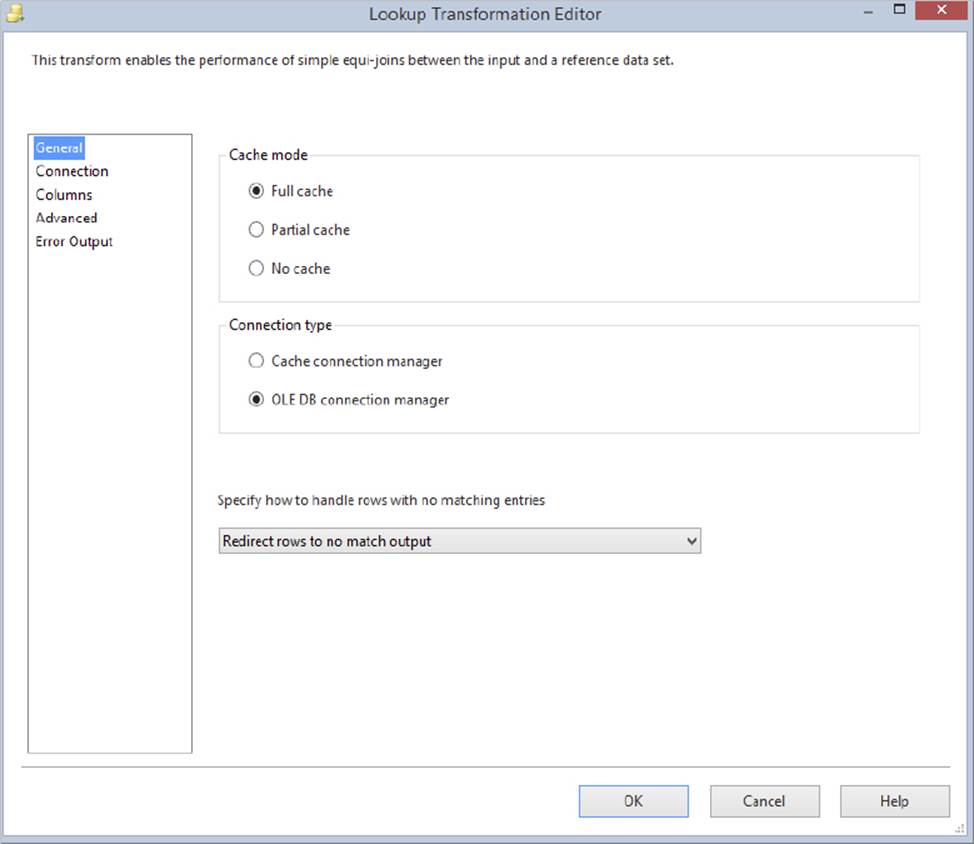
FIGURE 8-11
In the Connection tab, select OLEDB_AdventureWorks as the Connection Manager that contains your Lookup table. Select ZipCode from the “Use a Table or View” dropdown menu. For simplicity, you are just selecting the table, but the best practice is always to type in a SQL command and select only the needed columns.
Next, go to the Columns tab and drag ZipCode from the left Available Input Columns to the right ZipCode column in the Available Lookup Columns table. This will create an arrow between the two tables, as shown in Figure 8-12. Then, check the StateAbbr and City columns that you wish to output. This will transfer their information to the bottom grid. Change the Add as New Column option to Replace for the given column name as well. Specify that you want these columns to replace the existing City and State. Refer to Figure 8-12 to see the final configuration. Click OK to exit the transformation editor. There are many more options available here, but you should stick with the basics for the time being. With the configuration you just did, the potentially blank or bad city and state columns will be populated from the ZipCode table.
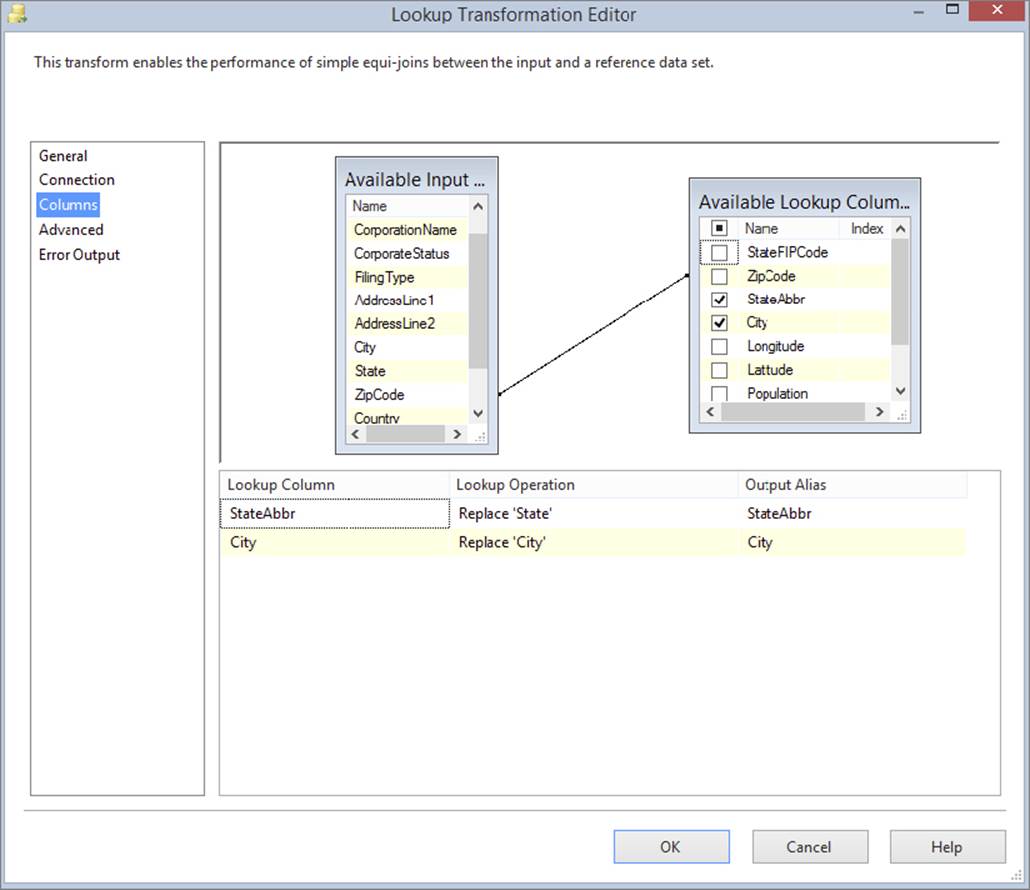
FIGURE 8-12
The Union All Transformation
Now that your dirty data is cleansed, send the sanitized data back into the main data path by using a Union All Transformation. Drag and drop the Union All Transformation onto the design pane and connect the Fix Bad Records Lookup Transformation and the Find Bad Records Conditional Split Transformation to the Union All Transformation. When you drag the blue line from the Lookup Transformation, you are prompted to define which output you want to send to the Union All Transformation. Select the Lookup Match Output. There is nothing more to configure with the Union All Transformation.
Finalizing
The last step in the Data Flow is to send the data to an OLE DB Destination. Drag the OLE DB Destination to the design pane and rename it Mail Merge Table. Connect the Union All Transformation to the destination. Double-click the destination and select OLEDB_AdventureWorks from the Connection Manager dropdown. For the Use a Table or View option, select the New button next to the dropdown. The default DDL for creating the table uses the destination’s name (AdventureWorks), and the data types may not be exactly what you want, as shown here:
CREATE TABLE [Mail Merge Table] (
[CorporateNumber] varchar(50),
[CorporationName] varchar(50),
[CorporateStatus] varchar(50),
[FilingType] varchar(50),
[AddressLine1] varchar(150),
[AddressLine2] varchar(150),
[City] varchar(50),
[State] varchar(50),
[ZipCode] varchar(50),
[Country] varchar(50),
[FilingDate] varchar(50)
)
Go ahead and change the schema to something a bit more useful. Change the table name and each column to something more meaningful, as shown in the following example (Ch08SQL.txt). These changes may cause the destination to show warnings about truncation after you click OK. If so, these warnings can be ignored for the purpose of this example.
NOTE Warnings in a package do not indicate the package will fail. In this case the zip code is trimmed to 5 characters so you know the data is not going to be truncated as indicated by the warning. It is acceptable to run packages with warning, especially in cases where unnecessary tasks would need to be added to remove the warning.
CREATE TABLE MarketingCorporation(
CorporateNumber varchar(12),
CorporationName varchar(48),
FilingStatus char(1),
FilingType char(4),
AddressLine1 varchar(150),
AddressLine2 varchar(50),
City varchar(28),
State char(2),
ZipCode varchar(10),
Country char(2),
FilingDate varchar(10) NULL
)
You may have to manually map some of the columns this time because the column names are different. Go to the Mappings tab and map each column to its new name. Click OK to close the editor.
Handling More Bad Data
The unpolished package is essentially complete, but it has one fatal flaw that you’re about to discover. Execute the package. As shown in Figure 8-13, when you do this, you can see, for example, that in the 010305c.dat file, four records were sent to be cleansed by the Lookup Transformation. Of those, only two had the potential to be cleansed. The other two records were for companies outside the country, so they could not be located in the Lookup Transformation that contained only Florida zip codes. These two records were essentially lost because you specified in the Lookup Transformation to redirect the rows without a match to a “no match output” (refer to Figure 8-11), but you have not set up a destination for this output. Recall that the business requirement was to send marketing a list of domestic addresses for their mail merge product. They didn’t care about the international addresses because they didn’t have a business presence in other countries.
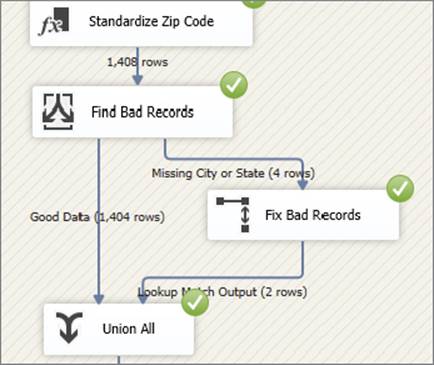
FIGURE 8-13
In this example, you want to send those two rows to an error queue for further investigation by a business analyst and to be cleaned manually. To do this properly, you need to audit each record that fails the match and create an ErrorQueue table on the SQL Server. Drag over the Audit Transformation found under the Other Transformations section of the SSIS Toolbox. Rename the Audit Transformation Add Auditing Info and connect the remaining blue arrow from the Fix Bad Records Transformation to the Audit Transformation.
With the Lookup problems now being handled, double-click the Audit Transformation to configure it. Add two additional columns to the output. Select Task Name and Package Name from the dropdown boxes in the Audit Type column. Remove the spaces in each default output column name, as shown in Figure 8-14, to make it easier to query later. You should output this auditing information because you may have multiple packages and tasks loading data into the corporation table, and you’ll want to track from which package the error actually originated. Click OK when you are done.
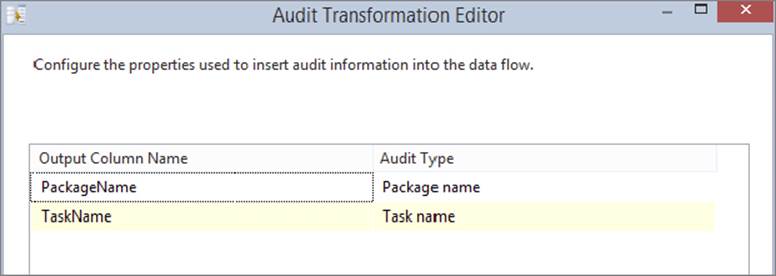
FIGURE 8-14
The last thing you need to do to polish up the package is send the bad rows to the SQL Server ErrorQueue table. Drag another OLE DB Destination over to the design pane and connect the Audit Transformation to it. Rename the destination Error Queue. Double-click the destination and select OLEDB_AdventureWorks as the Connection Manager, and click New to add the ErrorQueue table. Name the table ErrorQueue and follow a schema similar to the one shown here (Ch08SQL.txt):
CREATE TABLE [ErrorQueue] (
[CorporateNumber] varchar(50),
[CorporationName] varchar(50),
[CorporateStatus] varchar(50),
[FilingType] varchar(50),
[AddressLine1] varchar(150),
[AddressLine2] varchar(150),
[City] varchar(50),
[StateAbbr] varchar(50),
[ZipCode] varchar(50),
[Country] varchar(50),
[FilingDate] varchar(50),
[TaskName] nvarchar(19),
[PackageName] nvarchar(15)
)
NOTE In error queue tables like the one just illustrated, be very generous when defining the schema. In other words, you don’t want to create another transformation error trying to write into the error queue table. Instead, consider defining everything as a varchar column, providing more space than actually needed.
You may have to map some of the columns this time because of the column names being different. Go to the Mappings tab and map each column to its new name. Click OK to close the editor.
You are now ready to re-execute the package. This time, my data file contained four records that need to be fixed, and two of those were sent to the error queue. The final package would look something like the one shown in Figure 8-15 when executed.
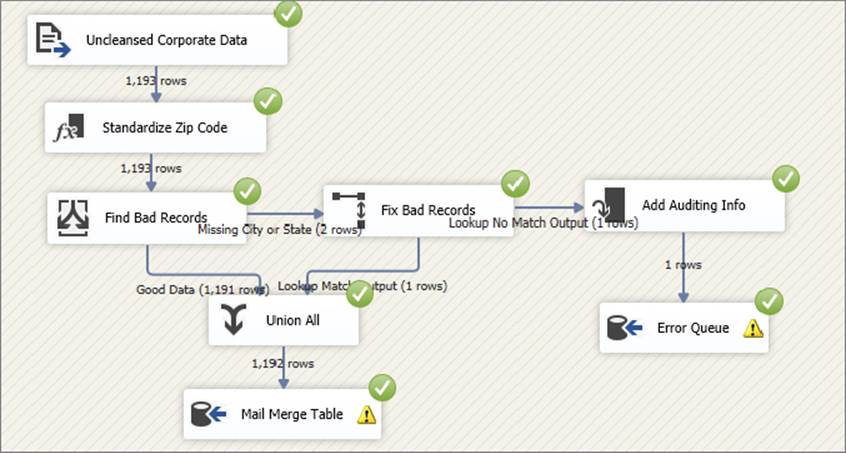
FIGURE 8-15
Looping and the Dynamic Tasks
You’ve gone a long way in this chapter toward creating a self-healing package, but it’s not very reusable yet. Your next task in the business requirements is to configure the package so that it reads a directory for any .DAT file and performs the preceding tasks on that collection of files. To simulate this example, copy the rest of the *.DAT files from the Chapter 8 download content for this book available at www.wrox.com into C:\ProSSIS\Data\Ch08.
Looping
Your first task is to loop through any set of .DAT files in the C:\ProSSIS\Data\Ch08 folder and load them into your database just as you did with the single file. To meet this business requirement, you need to use the Foreach Loop Container. Go to the Control Flow tab in the same package that you’ve been working in, and drag the container onto the design pane. Then, drag the “Load Corporate Data” Data Flow Task onto the container. Rename the container Loop Through Files.
Double-click the container to configure it. Go to the Collection tab and select Foreach File Enumerator from the Enumerator dropdown box. Next, specify that the folder will be C:\ProSSIS\Data\Ch08 and that the files will have the *.DAT extension, as shown in Figure 8-16.
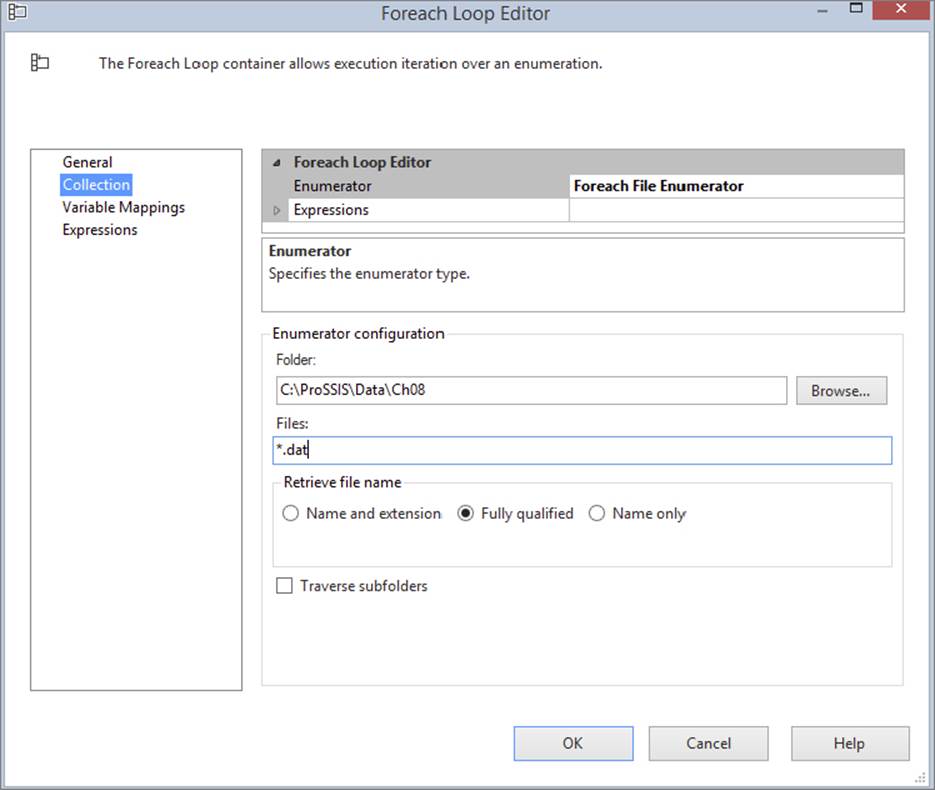
FIGURE 8-16
You need to now map the variables to the results of the Foreach File enumeration. Go to the Variable Mappings tab inside the Foreach Loop Editor and select <New Variable...> from the Variable column dropdown box. This will open the Add Variable dialog. For the container, you’ll remain at the package level. You could assign the scope of the variable to the container, but keep things simple for this example. Name the variable strExtractFileName and click OK, leaving the rest of the options at their default settings.
You will then see the User::strExtractFileName variable in the Variable column and the number 0 in the Index option. Because the Foreach File Enumerator option has only one column, you’ll see only an index of 0 for this column. If you used a different enumerator option, you could enter a number for each column that was returned from the enumerator. Click OK to leave the Foreach Loop editor.
Making the Package Dynamic
Now that the loop is created, you need to set the filename in the Corporation Extract Connection Manager to be equal to the filename that the enumerator retrieves dynamically. To meet this business requirement, right-click the Corporation Extract Connection Manager and select Properties (note that you’re clicking Properties, not Edit as you’ve done previously). In the Properties pane for this Connection Manager, click the ellipsis button next to the Expressions option. By clicking the ellipsis button, you open the Property Expressions Editor. Select ConnectionString from the Property dropdown box and then click the ellipsis under the Expression column next to the connection string property you just selected, this will open the Expression Builder window, as shown in Figure 8-17. You can either type @[User::strExtractFileName] in the Expression column or click the ellipsis button, and then drag and drop the variable into the expression window. By entering @[User::strExtractFileName], you are setting the filename in the Connection Manager to be equal to the current value of the strExtractFileName variable that you set in the Foreach Loop earlier. Click OK to exit the open windows. Note in the Property window that there is a single expression by clicking the plus sign next to Expressions.
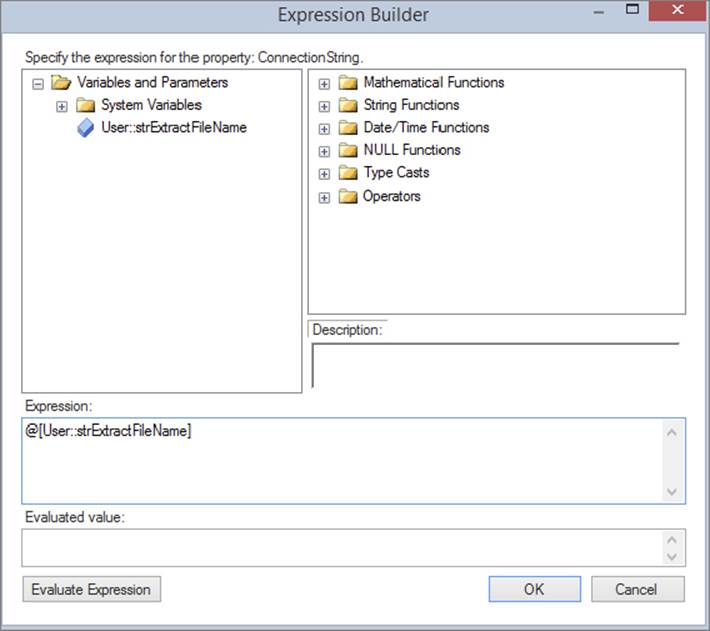
FIGURE 8-17
As it stands right now, each time the loop finds a .DAT file in the C:\ProSSIS\Data\Ch08 directory, it will set the strExtractFileName variable to that path and filename. Then, the Connection Manager will use that variable as its filename and run the Data Flow Task one time for each file it finds. You now have a reusable package that can be run against any file in the format you designated earlier.
The only missing technical solution to complete is the archiving of the files after you load them. Before you begin solving that problem, manually create an archive directory under C:\ProSSIS\Data\Ch08 called C:\ProSSIS\Data\Ch08\Archive. Right-click in the Connection Manager window and select New File Connection. Select Existing Folder for the Usage Type, and point the file to the C:\ProSSIS\Data\Ch08\Archive directory. Click OK and rename the newly created Connection Manager Archive.
Next, drag a File System Task into the Loop Through Files Container and connect the container to the “Load Corporate Data” Data Flow Task with an On Success constraint (the green arrow should be attached to the File System Task). Rename that task Archive File.
Double-click the “Archive File” File System Task to open the editor (shown in Figure 8-18). Set the Operation dropdown box to Move file. Next, change the Destination Connection from a variable to the archive Connection Manager that you just created. Also, select True for the OverwriteDestination option, which overwrites a file if it already exists in the archive folder. The SourceConnection dropdown box should be set to the FF_Corporation_DAT Connection Manager that you created earlier in this chapter. You have now configured the task to move the file currently in the Foreach Loop to the directory in the Archive File Connection Manager. Click OK to close the editor.
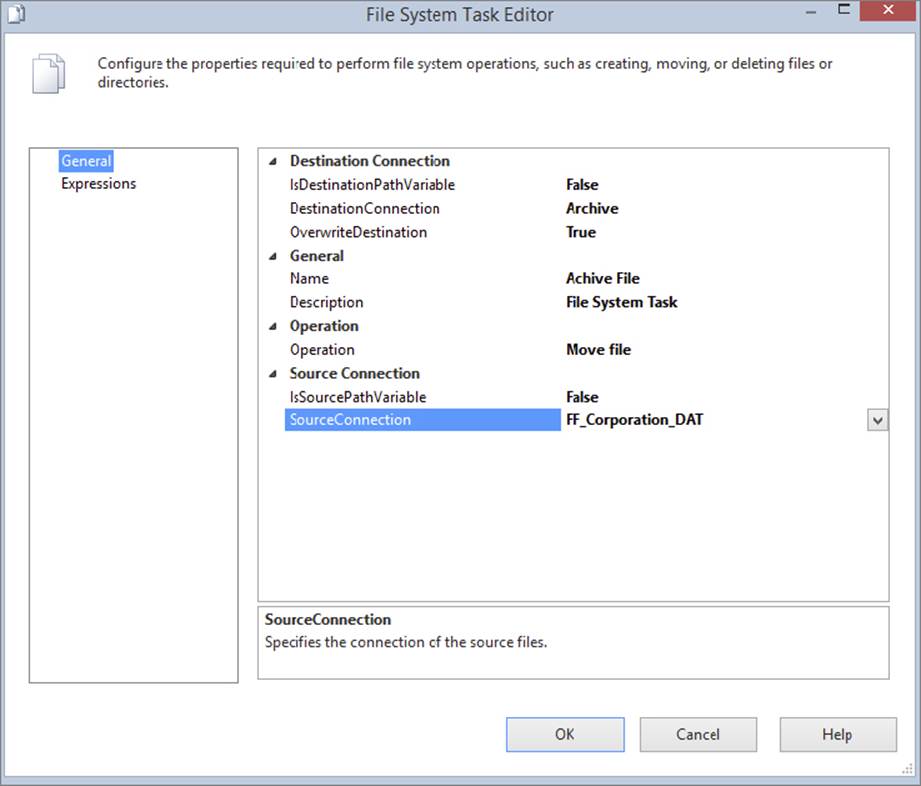
FIGURE 8-18
Your complete package should now be ready to execute. Save the package before you execute it. If you successfully implemented the solution, your Control Flow should look something like Figure 8-19 when executed. When you execute the package, you’ll see the Control Flow items flash green once for each .DAT file in the directory. To run the package again, you must copy the files back into the working directory from the archive folder.
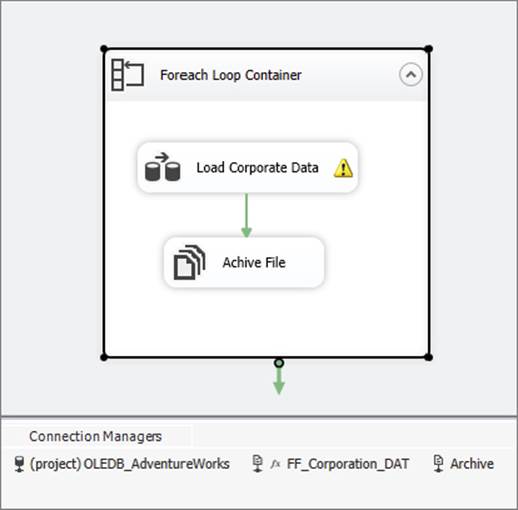
FIGURE 8-19
SUMMARY
This chapter focused on driving home the basic SSIS transformations, tasks, and containers. You performed a basic ETL procedure, and then expanded the ETL to self-heal when bad data arrived from your data supplier. You then set the package to loop through a directory, find each .DAT file, and load it into the database. The finale was archiving the file automatically after it was loaded. With this type of package now complete, you could use any .DAT file that matched the format you configured, and it will load with reasonable certainty. In the upcoming chapters, you’ll dive deeply into Script Tasks and Components.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.