Real-time Analytics with Storm and Cassandra (2015)
Chapter 6. Adding NoSQL Persistence to Storm
In this chapter, we will graduate to the next step in understanding Storm—we will add persistence to our topology. We have chosen Cassandra for very obvious reasons, which will be elaborated during this chapter. The intent is to make you understand how the Cassandra data store can be integrated with the Storm topology.
The following topics will be covered in this chapter:
· The advantages of Cassandra
· Introduction to columnar databases and column family design fundamentals
· Setting up a Cassandra cluster
· Introducing the CQLSH, CLI, and Connector APIs
· Storm topology wired to the Cassandra store
· Understanding the mechanism of persistence
· The best practices for Storm Cassandra applications
The advantages of Cassandra
This is the first and most obvious question anyone would ask, "Why are we using NoSQL?" Well, the very quick answer for looking at NoSQL instead of traditional data stores is the same as why the world is moving to big data—low cost, highly scalable, and reliable solutions that can store endless amounts of data.
Now, the next question is why Cassandra, and why not anything else out of the NoSQL stack. Here the answer lies in the kind of problem and solution approach we are trying to implement. Well, we are handling real-time analytics, and everything we need should be accurate, fail-safe, and lightning fast. Therefore, Cassandra is the best choice because:
· It has the fastest writes amongst its peers such as HBase and so on
· It is linearly scalable with peer-to-peer design
· No single point of failure
· Read and write requests can be handled without impacting each other's performance
· Handles search queries comprising millions of transactions and lightning-fast speeds
· Fail-safe and highly available with replication factors in place
· Guarantees eventual consistency with the CAP theorem on NoSQL DBs
· Column family design to handle a variety of formats
· No or low licensing cost
· Less development-ops or operational cost
· It can be extended for integration on a variety of other big data components
Columnar database fundamentals
One of the most important aspects of getting started with NoSQL data stores is getting to understand the fundamentals of columnar databases; or rather, let's use the actual term—column families.
This is a concept that has a variety of implementations in different NoSQL databases, for instance:
· Cassandra: This is a key-value-pair-based NoSQL DB
· Mongo DB: This is a document-based NoSQL DB
· Neo4J: This is a graph DB
They differ from conventional RDBMS systems that are row-oriented in terms of the following:
· Performance
· Storage extendibility
· Fault tolerance
· Low or no licensing cost
But having iterated all the differences and benefits of NoSQL DBs, you must clearly understand that the shift to NoSQL is a shift of the entire paradigm of data storage, availability, and access—they are not a replacement for RDBMS.
In the RDBMS world, we are all used to creating tables, but here in Cassandra, we create column families where we define the metadata of the columns, but the columns are actually stored as rows. Each row can have different sets of columns, thus making the whole column family relatively unstructured and extendible.
Types of column families
There are two types of column families:
· Static column family: As the name suggests, this has a static set of columns and is a very close surrogate of all well-known RDBMS tables, barring a few differences that are a result of its NoSQL heritage. Here is an example of a static column family:
|
Rowkey |
Columns |
|||
|
Raman |
Name |
|
Cell no. |
Age |
|
Raman Subramanian |
aa@yahoo.com |
9999999999 |
20 |
|
|
Edison |
Name |
|
Cell no. |
Age |
|
Edison Weasley |
bb@yahoo.com |
88888888888 |
30 |
|
|
Amey |
Name |
|
Cell no. |
Age |
|
Amey Marriot |
cc@yahoo.com |
7777777777 |
40 |
|
|
Sriman |
Name |
|
||
|
Sriman Mishra |
dd@yahoo.com |
|||
· Dynamic column family: This one gets the true essence of being unstructured and schema-less. Here, we don't use predefined columns associated with the column family, but the same can be dynamically generated and supplied by the client application at the time of inserting data into the column family. During the creation or definition of a dynamic column family, we get to define the information about the column names and values by defining the comparators and validators. Here is an example of a dynamic column family:
|
Rowkey |
Columns |
|||
|
Raman |
Name |
|
Cell no. |
Age |
|
Edison |
Address |
State |
Territory |
|
|
Amey |
Country |
Sex |
Cell no. |
Age |
|
Sriman |
Nationality |
|||
Types of columns
There are a variety of columns that Cassandra supports:
· Standard columns: These columns contain a name; this is either static or dynamic and set by the writing application. A value (this is actually the attribute that stores the data) and timestamp are shown here:
|
Column_name |
|
value |
|
timestamp |
· Cassandra makes use of the timestamp associated with the column to find out the last update to the column. When data is queried from Cassandra, it orders by this timestamp and always returns the most recent value.
· Composite columns: Cassandra makes use of this storage mechanism to handle clustered rows. This is a unique way of handling all the logical rows together that share the same partition key into a single physical wide row. This enables Cassandra to accomplish the legendary feat of storing 2 billion columns per row. For example, let's say I want to create a table where I capture live status updates from some social networking sites:
· CREATE TABLE statusUpdates(
· update_id uuid PRIMARY KEY,
· username varchar,
· mesage varchar
· );
·
· CREATE TABLE timeseriesTable (
· user_id varchar,
· udate_id uuid,
· username varchar,
· mesage varchar,
· PRIMARY KEY user_id , update_id )
);
The live updates are being recorded under the StatusUpdates table that has the username, message, and update_id (which is actually a UUID) property.
While designing a Cassandra column family, you should make extensive use of the functionality provided by UUIDs, which can be employed for sequencing data.
The combination of the user_id and update_id properties from timeseriesTable can uniquely identify a row in chronology.
Cassandra makes use of the first column defined in the primary key as the partition key; this is also known as the row key.
· Expiring columns: These are special types of Cassandra columns that have a time to live (TTL) associated with them; the values stored in these columns are automatically deleted or erased after the TTL has elapsed. These columns are used for use cases where we don't want to retain data older than a stated interval; for instance, if we don't need data older than 24 hours. In our column family, I would associate a TTL of 24 hours with every column that is being inserted, and this data will be automatically deleted by Cassandra after 24 hours of its insertion.
· Counter columns: These are again specialized function columns that store a number incrementally. They have a special implementation and a specialized usage for situations where we use counters; for instance, if I need to count the number of occurrences of an event.
Setting up the Cassandra cluster
Cassandra is a very scalable key-value store. It promises eventual consistency and its distributed ring-based architecture eliminates any single point of failure in the cluster, thus making it highly available. It's designed and developed to support very fast reads and writes over excessively large volumes of data .This fast write and read ability makes it a very strong contender to be used in an online transaction processing (OLTP) application to support large business intelligence systems.
Cassandra provides a column-family-based data model that is more flexible than typical key-value systems.
Installing Cassandra
Cassandra requires the most stable version of Java 1.6 that you can deploy, preferably the Oracle or Sun JVM. Perform the following steps to install Cassandra:
1. Download the most recent stable release (version 1.1.6 at the time of writing) from the Apache Cassandra site.
2. Create a Cassandra directory under /usr/local as follows:
3. sudo mkdir /usr/local/cassandra
3. Extract the downloaded TAR file to the /usr/local location. Use the following command:
4. sudo tar –xvf apache-cassandra-1.1.6-bin.tar.gz -C /usr/local/cassandra
4. Cassandra needs a directory to store its data, log files, and cache files. Create /usr/local/cassandra/tmp to store this data:
5. sudo mkdir –p /usr/local/cassandra/tmp
5. Update the Cassandra.yaml configuration file under /usr/local/Cassandra/apache-cassandra-1.1.6/conf.
The following properties will go into it:
cluster_name: 'MyClusterName'
seeds: <IP of Node-1><IP of Node-2>(IP address of each node go into it)
listen_address: <IP of Current Node>
6. Calculate a token for each node using the following script and update the initial_token property to each node by adding a unique token value in Cassandra.yaml:
7. #! /usr/bin/python
8. import sys
9. if (len(sys.argv) > 1):
10. num=int(sys.argv[1])
11.else:
12. num=int(raw_input("How many nodes are in your cluster? "))
13.for i in range(0, num):
print 'node %d: %d' % (i, (i*(2**127)/num))
7. Update the following property in the conf/log4j-server.properties file. Create the temp directory under cassandra:
8. Log4j.appender.R.File=/usr/local/cassandra/temp/system.log
8. Increase the rpc_timeout property in Cassandra.yaml (if this timeout is very small and the network latency is high, Cassandra might assume the nodes are dead without waiting long enough for a response to propagate).
9. Run the Cassandra server at /usr/local/Cassandra/apache-cassandra-1.1.6 using bin/Cassandra –f.
10.Run the Cassandra client at /usr/local/Cassandra/apache-cassandra-1.1.6 using bin/Cassandra-cli with a host and port.
11.Use the bin/nodetool ring utility at /usr/local/Cassandra/apache-cassandra-1.1.6 to verify a properly connected cluster:
12.bin/nodetool –host <ip-adress> -p <port number> ring
13.192.168.1.30 datacenter1 rack1 Up Normal 755.25 MB 25.00% 0
14.192.168.1.31 datacenter1 rack1 Up Normal 400.62 MB 25.00% 42535295865117307932921825928970
15.192.168.1.51 datacenter1 rack1 Up Normal 400.62 MB 25.00% 42535295865117307932921825928971
192.168.1.32 datacenter1 rack1 Up Normal 793.06 MB 25.00% 85070591730234615865843651857941
The preceding output displays a connected cluster. This configuration shows that it's correctly configured and connected.
Here is a screenshot of the output:

Multiple data centers
In practical scenarios, we would want to have Cassandra clusters distributed across different data centers so that the system is more reliable and resilient overall to localized network snags and physical disasters.
Prerequisites for setting up multiple data centers
The following are a set of prerequisites that should be used for setting up multiple data centers:
· Have Cassandra installed on each node
· Have the IP address of each node in the cluster
· Identify the cluster names
· Identify the seed nodes
· Identify the snitch that is to be used
Installing Cassandra data centers
The following are a set of steps to set up Cassandra data centers:
1. Let's start with an assumption that we have already installed Cassandra on the following nodes:
10.188.66.41 (seed1)
10.196.43.66
10.188.247.41
10.196.170.59 (seed2)
10.189.61.170
10.189.30.138
2. Assign tokens using the token generation Python script defined in the previous section to each of the preceding nodes.
3. Let's say we align to the following distribution of nodes and their tokens across the data centers:
|
Node |
IP Address |
Token |
Data Center |
|
node0 |
10.188.66.41 |
0 |
Dc1 |
|
node1 |
10.196.43.66 |
56713727820156410577229101238628035245 |
Dc1 |
|
node2 |
10.188.247.41 |
113427455640312821154458202477256070488 |
Dc1 |
|
node3 |
10.196.170.59 |
10 |
Dc2 |
|
node4 |
10.189.61.170 |
56713727820156410577229101238628035255 |
Dc2 |
|
node5 |
10.189.30.138 |
113427455640312821154458202477256070498 |
Dc2 |
4. Stop Cassandra on the nodes and clear the data from data_dir of Cassandra:
5. $ ps auwx | grep cassandra
This command finds the Cassandra Java process ID (PID):
$ sudo kill <pid>
This is the command to kill the process with the specified PID:
$ sudo rm -rf /var/lib/cassandra/*
The preceding command clears the data from the default directories of Cassandra.
5. Modify the following property settings in the cassandra.yaml file for each node:
6. endpoint_snitch <provide the name of snitch>
7. initial_token: <provide the value of token from previous step>
8. seeds: <provide internal IP_address of each seed node>
listen_address: <provide localhost IP address>
Here is what the updated configuration will look like:
node0:
end_point_snitch: org.apache.cassandra.locator.PropertyFileSnitch
initial_token: 0
seed_provider:
- class_name: org.apache.cassandra.locator.SimpleSeedProvider
parameters:
- seeds: "10.188.66.41,10.196.170.59"
listen_address: 10.196.43.66
node1 to node5
All the properties for these nodes are the same as those defined for the preceding node0 except for the initial_token and listen_address properties.
6. Next, we will have to assign names to each data center and their racks; for example, Dc1, Dc2 and Rc1, Rc2.
7. Go to the cassandra-topology.properties file and add an assignment for data center and rack names against the IP addresses of each node. For example:
8. # Cassandra Node IP=Data Center:Rack
9. 10.188.66.41=Dc1:Rc1
10.10.196.43.66=Dc2:Rc1
11.10.188.247.41=Dc1:Rc1
12.10.196.170.59=Dc2:Rc1
13.10.189.61.170=Dc1:Rc1
10.199.30.138=Dc2:Rc1
8. The next step is to start seed nodes one by one, followed by all the rest of the nodes.
9. Check that your ring is up and running.
Introduction to CQLSH
Now that we are through with the Cassandra setup, let's get acquainted with the shell and a few basic commands:
1. Run CQL at /usr/local/Cassandra/apache-cassandra-1.1.6 using bin/cqlsh with a host and port:
2. bin/cqlsh –host <ip-adress> -p <port number>
2. Create a keyspace either at the Cassandra client or at CQL, as follows:
3. create keyspace <keyspace_name>;
3. Create a column family at the Cassandra client or at CQL as follows:
4. use <keyspace_name>;
5. create column family <columnfamily name>;
For example, create the following table:
CREATE TABLE appUSers (
user_name varchar,
Dept varchar,
email varchar,
PRIMARY KEY (user_name));
4. Insert a few records into the column family from the command line:
5. INSERT INTO appUSers (user_name, Dept, email)
6. VALUES ('shilpi', 'bigdata, 'shilpisaxena@yahoo.com');
5. Retrieve the data from the column family:
6. SELECT * FROM appUSers LIMIT 10;
Introduction to CLI
This section gets you acquainted with another tool that is used for interaction with Cassandra processes—the CLI shell.
The following steps are used for interacting with Cassandra using the CLI shell:
1. The following is the command to connect to the Cassandra CLI:
2. Cd Cassandra-installation-dir/bin
3. cassandra-cli -host localhost -port 9160
2. Create a keyspace:
3. [default@unknown] CREATE KEYSPACE myKeySpace
4. with placement_strategy = 'SimpleStrategy'
5. and strategy_options = {replication_factor:1};
3. Verify the creation of the keyspace using the following command:
4. [default@unknown] SHOW KEYSPACES;
5. Durable Writes: true
6. Options: [replication_factor:3]
7. Column Families:
8. ColumnFamily: MyEntries
9. Key Validation Class: org.apache.cassandra.db.marshal.UTF8Type
10. Default column value validator: org.apache.cassandra.db.marshal.UTF8Type
11. Columns sorted by: org.apache.cassandra.db.marshal.ReversedType (org.apache.cassandra.db.marshal.TimeUUIDType)
12. GC grace seconds: 0
13. Compaction min/max thresholds: 4/32
14. Read repair chance: 0.1
15. DC Local Read repair chance: 0.0
16. Replicate on write: true
17. Caching: KEYS_ONLY
18. Bloom Filter FP chance: default
19. Built indexes: []
20. Compaction Strategy: org.apache.cassandra.db.compaction. SizeTieredCompactionStrategy
21. Compression Options:
22. sstable_compression: org.apache.cassandra.io.compress.SnappyCompressor
23. ColumnFamily: MYDevicesEntries
24. Key Validation Class: org.apache.cassandra.db.marshal.UUIDType
25. Default column value validator: org.apache.cassandra.db.marshal.UTF8Type
26. Columns sorted by: org.apache.cassandra.db.marshal.UTF8Type
27. GC grace seconds: 0
28. Compaction min/max thresholds: 4/32
29. Read repair chance: 0.1
30. DC Local Read repair chance: 0.0
31. Replicate on write: true
32. Caching: KEYS_ONLY
33. Bloom Filter FP chance: default
34. Built indexes: [sidelinedDevicesEntries. sidelinedDevicesEntries_date_created_idx, sidelinedDevicesEntries. sidelinedDevicesEntries_event_type_idx]
35. Column Metadata:
36. Column Name: event_type
37. Validation Class: org.apache.cassandra.db.marshal.UTF8Type
38. Index Name: sidelinedDevicesEntries_event_type_idx
39. Index Type: KEYS
40. Index Options: {}
41. Column Name: date_created
42. Validation Class: org.apache.cassandra.db.marshal.DateType
43. Index Name: sidelinedDevicesEntries_date_created_idx
44. Index Type: KEYS
45. Index Options: {}
46. Column Name: event
47. Validation Class: org.apache.cassandra.db.marshal.UTF8Type
48. Compaction Strategy: org.apache.cassandra.db.compaction. SizeTieredCompactionStrategy
49. Compression Options:
50. sstable_compression: org.apache.cassandra.io.compress.SnappyCompressor
4. Create a column family:
5. [default@unknown] USE myKeySpace;
6. [default@demo] CREATE COLUMN FAMILY appUsers
7. WITH comparator = UTF8Type
8. AND key_validation_class=UTF8Type
9. AND column_metadata = [
10. {column_name:user_name, validation_class: UTF8Type}
11. {column_name: Dept, validation_class: UTF8Type}
12. {column_name: email, validation_class: UTF8Type}
13.];
5. Insert data into the column family:
6. [default@demo] SET appUsers['SS'][user_name']='shilpi';
7. [default@demo] SET appUsers['ss'][Dept]='BigData';
8. [default@demo] SET appUsers['ss']['email']=shilpisaxena@yahoo.com';
Note
In this example, the code ss is my row key.
6. Retrieve data from the Cassandra column family:
7. GET appUsers[utf8('ss')][utf8('user_name')];
8. List appUsers;
Using different client APIs to access Cassandra
Now that we are acquainted with Cassandra, let's move on to the next step where we will access (insert or update) data into the cluster programmatically. In general, the APIs we are talking about are wrappers written over the core Thrift API, which offers various CRUD operations over the Cassandra cluster using programmer-friendly packages.
The client APIs that are used to access Cassandra are as follows:
· Thrift protocol: The most basic of all APIs to access Cassandra is the Remote Procedure Call (RPC) protocol, which provides a language-neutral interface and thus exposes flexibility to communicate using Python, Java, and so on. Please note that almost all other APIs we'll discuss use Thrift under the hood. It is simple to use and it provides basic functionality out of the box like ring discovery and native access. Complex features such as retry, connection pooling, and so on are not supported out of the box. However, there are a variety of libraries that have extended Thrift and added these much required features, and we will touch upon a few widely used ones in this chapter.
· Hector: This has the privilege of being one of the most stable and extensively used APIs for Java-based client applications to access Cassandra. As mentioned earlier, it uses Thrift under the hood, so it essentially can't offer any feature or functionality not supported by the Thrift protocol. The reason for its widespread use is that it has a number of essential features ready to use and available out of the box:
o It has implementation for connection pooling
o It has a ring discovery feature with an add-on of automatic failover support
o It has a retry option for downed hosts in the Cassandra ring
· Datastax Java driver: This is, again, a recent addition to the stack of client access options to Cassandra, and hence goes well with the newer version of Cassandra. Here are its salient features:
o Connection pooling
o Reconnection policies
o Load balancing
o Cursor support
· Astyanax: This is a very recent addition to the bouquet of Cassandra client APIs and has been developed by Netflix, which definitely makes it more fabled than others. Let's have a look at its credentials to see where it qualifies:
o It supports all of the functions of Hector and is much easier to use
o It promises better connection pooling than Hector
o It is better at handling failovers than Hector
o It provides some out-of-the-box, database-like features (now that's big news). At the API level, it provides functionality called Recipes in its terms, which provides:
Parallel row query execution
Messaging queue functionality
Object storage
Pagination
o It has numerous frequently required utilities like JSON Writer and CSV Importer
Storm topology wired to the Cassandra store
Now you have been educated and informed about why you should use Cassandra. You have been walked through setting up Cassandra and column family creation, and have even covered the various client/protocol options available to access the Cassandra data store programmatically. As mentioned earlier, Hector has so far been the most widely used API for accessing Cassandra, though the Datastax and Astyanax drivers are fast catching up. For our exercise, we'll use the Hector API.
The use case we want to implement here is to use Cassandra to support real-time, adhoc reporting for telecom data that is being collated, parsed, and enriched using a Storm topology.
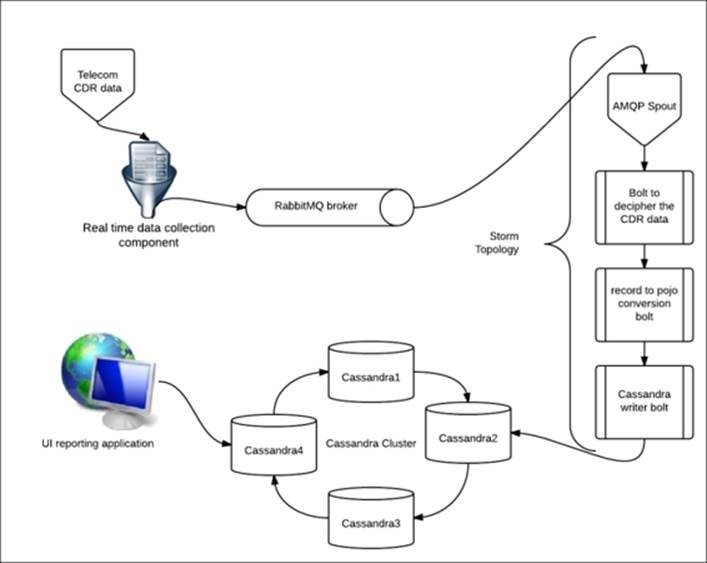
As depicted in the preceding figure, the use case requires live telecom Call Detail Record (CDR) capture using the data collection components (for practice, we can use sample records and a simulator shell script to mimic the live CDR feeds). The collated live feed is pushed into the RabbitMQ broker and then consumed by the Storm topology.
For the topology, we have an AMQP spout as the consumer, which reads the data of the queue and pushes it downstream to the topology bolts; here, we have wired in bolts to parse the message and convert it to Plain Old Java Objects (POJO's). Then, we have a new entry in our topology, the Cassandra bolt, which actually stores the data in the Cassandra cluster.
From the Cassandra cluster, a UI-based consumer retrieves the data based on a search query defined by the user, thus providing the adhoc, real-time reporting over live data.
For the sake of our implementation, we will query the data from CLI/CQLSH as shown here:
1. Create a keyspace:
2. create keyspace my_keyspace with placement_strategy = 'SimpleStrategy' and strategy_options = {replication_factor : 3} and durable_writes = true;
3. use my_keyspace;
2. Create the column family:
3. create column family my_columnfamily
4. with column_type = 'Standard'
5. and comparator = 'UTF8Type'
6. and default_validation_class = 'BytesType'
7. and key_validation_class = 'TimeUUIDType'
8. and read_repair_chance = 0.1
9. and dclocal_read_repair_chance = 0.0
10. and gc_grace = 0
11. and min_compaction_threshold = 4
12. and max_compaction_threshold = 32
13. and replicate_on_write = true
14. and compaction_strategy = 'org.apache.cassandra.db.compaction. SizeTieredCompactionStrategy'
15. and caching = 'KEYS_ONLY'
16. and bloom_filter_fp_chance = 0.5
17. and column_metadata = [
18.{column_name : 'cellnumber',
19. validation_class : Int32Type },
20. {column_name : 'tollchrg',
21. validation_class : UTF8Type},
22.{column_name : 'msgres',
23. validation_class : UTF8Type},
24.
25.{column_name : 'servicetype',
26. validation_class : UTF8Type}]
27. and compression_options = {'sstable_compression' : 'org.apache.cassandra.io.compress.SnappyCompressor'
};
3. The following changes need to be made to pom.xml in the project. The Hector dependency should be added to the pom.xml file so that it is fetched at the time of build and added to the m2 repository, as shown:
4. <dependency>
5. <groupId>me.prettyprint</groupId>
6. <artifactId>hector-core</artifactId>
7. <version>0.8.0-2</version>
</dependency>
If you are working with a non-Maven project, follow the usual protocol—download the Hector core JAR file and add it to the project build path so that all the required dependencies are satisfied.
4. Next, we'll need to get the components in place in our Storm topology. We will start by creating a CassandraController Java component that will hold all Cassandra-related functionality, and it will be called from the CassandraBolt class in the topology to persist the data into Cassandra:
5. public class CassandraController {
6.
7. private static final Logger logger = LogUtils.getLogger(CassandraManager.class);
8. //various serializers are declared in here
9. UUIDSerializer timeUUIDSerializer = UUIDSerializer.get();
10. StringSerializer stringSerializer = StringSerializer.get();
11. DateSerializer dateSerializer = DateSerializer.get();
12. LongSerializer longSerializer = LongSerializer.get();
13.
14. public CassandraController() {
15. //list of IPs of Cassandra node in ring
16. String nodes = "10.3.1.41,10.3.1.42,10.3.1.44,10.3.1.45";
17. String clusterName = "mycluster";
18. //creating a new configurator
19. CassandraHostConfigurator hostConfigurator = new CassandraHostConfigurator(nodes);
20. hostConfigurator.setCassandraThriftSocketTimeout(0);
21. cluster = HFactory.getOrCreateCluster(clusterName, hostConfigurator);
22.
23. String[] nodeList = nodes.split(",");
24. if (nodeList != null && nodeList.length == cluster.getConnectionManager(). getDownedHosts().size()) {
25. logger.error("All cassandra nodes are down. " + nodes);
26. }
27.
28. //setting up read and write consistencies
29. ConfigurableConsistencyLevel consistency = new ConfigurableConsistencyLevel();
30. consistency.setDefaultWriteConsistencyLevel (HConsistencyLevel.ONE);
31. consistency.setDefaultReadConsistencyLevel (HConsistencyLevel.ONE);
32. keySpaceObj = HFactory.createKeyspace ("my_keyspace", cluster, consistency);
33. stringMutator = HFactory.createMutator(keySpaceObj, stringSerializer);
34. uuidMutator = HFactory.createMutator (keySpaceObj, timeUUIDSerializer);
35.
36. logger.info("Cassandra data store initialized, Nodes=" + nodes + ", " + "cluster name=" + clusterName + ", " + "keyspace=" + keyspace + ", " + "consistency=" + writeConsistency);
37. }
38. //defining the mutator
39. public Mutator < Composite > getCompositeMutator() {
40. return compositeMutator;
41. }
42.
43. public void setCompositeMutator(Mutator < Composite > compositeMutator) {
44. this.compositeMutator = compositeMutator;
45. }
46. //getter and setters for all mutators and serializers
47.
48. public StringSerializer getStringSerializer() {
49. return stringSerializer;
50. }
51.
52. public Keyspace getKeyspace() {
53. return keySpaceObj;
54. }
}
5. Last but not least in our topology is actually the component that will write into Cassandra, the Storm bolt that will make use of CassandraController created earlier to write the real-time data into Cassandra:
6. public class CassandraBolt extends BaseBasicBolt {
7. private static final Logger logger = LogUtils.getLogger(CassandraBolt.class);
8.
9. public void prepare(Map stormConf, TopologyContext context) {
10.
11. logger.debug("Cassandra bolt, prepare()");
12. try {
13. cassandraMngr = new CassandraController();
14. myCf = "my_columnfamily";
15. );
16.
17. } catch (Exception e) {
18. logger.error("Error while instantiating CassandraBolt", e);
19. throw new RuntimeException(e);
20. }
21. }
22.
23. @Override
24. public void execute(Tuple input, BasicOutputCollector collector) {
25. logger.debug("execute method :: Start ");
26. Calendar tCalendar = null;
27. long eventts = eventObj.getEventTimestampMillis();
28. com.eaio.uuid.UUID uuid = new com.eaio.uuid.UUID(getTimeForUUID(eventts), clockSeqAndNode);
29.
30. java.util.UUID keyUUID = java.util.UUID.fromString(uuid.toString());
31.
32. /*
33. * Persisting to my CF
34. */
35.
36. try {
37. if (keyUUID != null) {
38. cassandraMngrTDR.getUUIDMutator().addInsertion(
39. keyUUID,
40. myCf,
41. HFactory.createColumn("eventts",
42. new Timestamp(tCalendar.getTimeInMillis()), -1, cassandraMngr.getStringSerializer(),
43. cassandraMngr.getDateSerializer()));
44. }
45.
46. cassandraMngrTDR.getUUIDMutator().addInsertion(
47. keyUUID,
48. myCf,
49. HFactory.createColumn("cellnumber", eventObj.getCellnumber(), -1, cassandraMngr.getStringSerializer(),
50. cassandraMngr.getLongSerializer()));
51. cassandraMngr.getUUIDMutator().execute();
52. logger.debug("CDR event with key = " + keyUUID + " inserted into Cassandra cf " + myCf);
53.
54. } else {
55. logger.error("Record not saved. Error while parsing date to generate KEY for cassandra data store, column family - " + myCf);
56. }
57. }
58.
59. catch (Exception excep) {
60. logger.error("Record not saved. Error while saving data to cassandra data store, column family - " + myCf, excep);
61. }
62.
63. logger.debug("execute method :: End ");
64. }
}
So here we complete the last piece of the puzzle; we can now stream data into Cassandra using Storm in real time. Once you execute the topology end to end, you can verify the data in Cassandra by using the select or list commands on CLI/CQLSH.
The best practices for Storm/Cassandra applications
When working with distributed applications that have SLAs operating 24/7 with a very high velocity and a miniscule average processing time, certain aspects become extremely crucial to be taken care of:
· Network latency plays a big role in real-time applications and can make or break products, so make a very informed and conscious decision on the placement of various nodes in a data center or across data centers. In such situations, it's generally advisable to keep ping latency at a minimum.
· The replication factor should be around three for Cassandra.
· Compaction should be part of routine Cassandra maintenance.
Quiz time
Q.1. State whether the following statements are true or false:
1. Cassandra is a document-based NoSQL.
2. Cassandra has a single point of failure.
3. Cassandra uses consistent hashing for key distribution.
4. Cassandra works on master-slave architecture.
Q.2. Fill in the blanks:
1. _______________attributes of the CAP theorem are adhered to by Cassandra.
2. _______________ is the salient feature that makes Cassandra a contender to be used in conjunction with Storm.
3. The ____________ is an API to access Cassandra using a Java client, and is a Greek mythological character—brother of Cassandra.
Q.3. Complete the use case mentioned in the chapter and demonstrate end-to-end execution to populate data into Cassandra.
Summary
In this chapter, you have covered the fundamentals of NoSQL in general and specifically Cassandra. You got hands-on experience in setting up the Cassandra cluster as well as got to know about varied APIs, drivers, and protocols that provide programmatic access to Cassandra. We also integrated Cassandra as a data store to our Storm topology for data insertion.
In the next chapter, we will touch upon some integral aspects of Cassandra, specifically consistency and availability.