Agile Data Science (2014)
Part II. Climbing the Pyramid
Chapter 8. Making Predictions
Now that we have interactive reports exposing different aspects of our data, we’re ready to make our first prediction. This forms our fourth agile sprint (Figure 8-1). When making predictions, we take what we know about the past and project what will happen in the future, simultaneously transitioning from batch processing of historical data to real-time classification of the present to predict the future. We’ll start simply, moving on to driving real actions in the next chapter.
Figure 8-1. Level 4: making predictions
Code examples for this chapter are available at https://github.com/rjurney/Agile_Data_Code/tree/master/ch08. Clone the repository and follow along!
git clone https://github.com/rjurney/Agile_Data_Code.git
Predicting Response Rates to Emails
When I click around in our application and look at the charts showing how often someone emails by hour of the day, I wonder if we can infer from this data when someone is most likely to reply. This is why we created charts and reports in the first place—to guide us as we climb the data-value pyramid.
In this chapter, we will predict whether a recipient will respond to a given email using some of the entities we’ve extracted from our inbox. In the next chapter, we’ll use this inference to enable a new kind of action.
We’re going to walk from simple frequencies to real insight one table at a time, just as we did in Chapter 2. This time, we’ll show you the code to accompany the logic.
We begin by calculating a simple overall sent count between pairs of emails (Figure 8-2). Check out ch08/p_reply.pig.
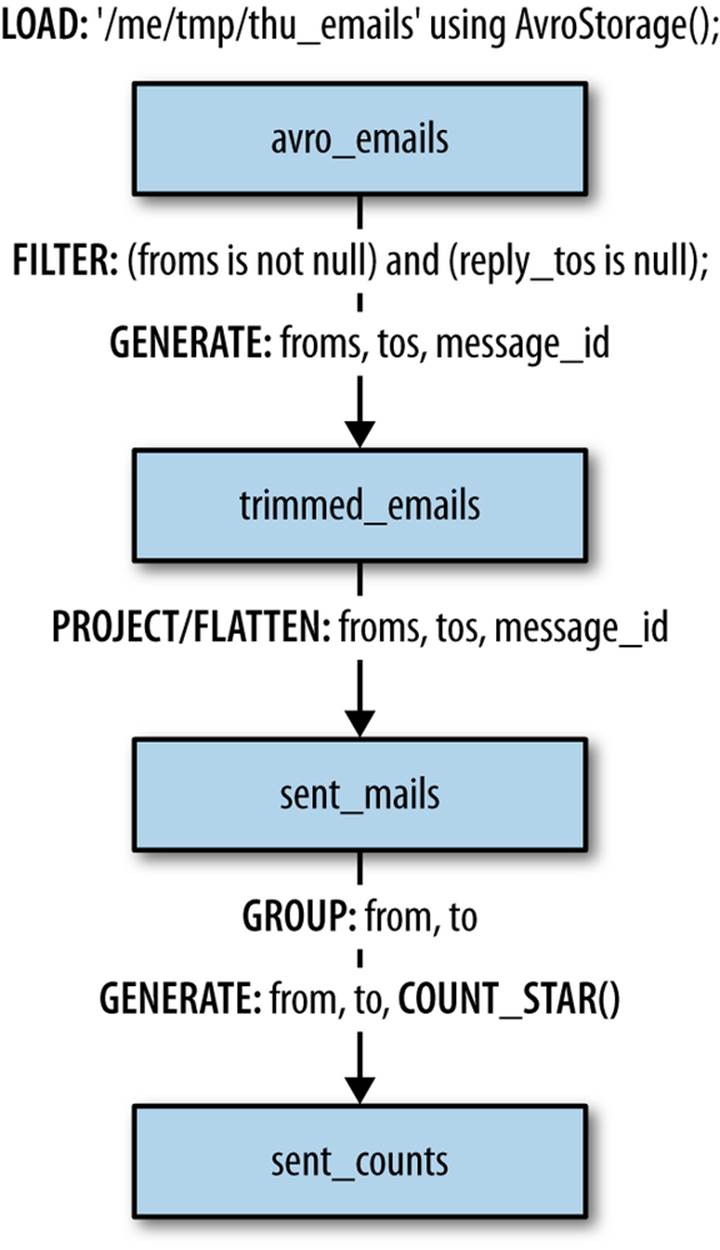
Figure 8-2. Calculating sent counts
/* Get rid of emails with reply_to; they confuse everything in mailing lists. */
avro_emails = load '/me/tmp/thu_emails' using AvroStorage();
clean_emails = filter avro_emails by (froms is not null) and (reply_tos is null);
/* Treat emails without in_reply_to as sent emails */
trimmed_emails = foreach clean_emails generate froms, tos, message_id;
sent_mails = foreach trimmed_emails generate flatten(froms.address) as from,
flatten(tos.address) as to,
message_id;
store sent_counts into '/tmp/sent_counts';
Global sent counts between pairs of email addresses are easy enough to calculate, as this is roughly equivalent to a SQL group by: we use the flatten command to project all unique pairs of from/to in each email (remember: emails can have more than one to), along with the message_idof the email. See Table 8-1.
Table 8-1. Sent counts—simple frequencies
|
From |
To |
Total |
|
russell.jurney@gmail.com |
****@hotmail.com |
237 |
|
russell.jurney@gmail.com |
jurney@gmail.com |
122 |
|
russell.jurney@gmail.com |
****.jurney@gmail.com |
273 |
The next step is a little more complex. We need to separate replies. Since we will be using overall sent counts as the denominator in determining our reply ratios, we need to remove all mailing list emails from the analysis. Calculating the sent counts for the entire lurking population of a mailing list is daunting, to say the least!
Our calculation is the same as for total emails, except we filter so that all emails have a nonnull in_reply_to, and we project in_reply_to with our email pairs instead of message_id.
/* Remove in_reply_tos, as they are mailing lists which have incalculable total
sent_counts */
avro_emails2 = load '/me/tmp/thu_emails' using AvroStorage();
replies = filter avro_emails2 by (froms is not null) and (reply_tos is null)
and (in_reply_to is not null);
replies = foreach replies generate flatten(froms.address) as from,
flatten(tos.address) as to,
in_reply_to;
replies = filter replies by in_reply_to != 'None';
store replies into '/tmp/replies';
NOTE
Note that we have to load the emails twice to effect a self-join. As of Pig 0.10, Pig can’t join a relation to itself.
We are now prepared to join the sent messages with the replies to see each email and whether it was replied to at all (Figure 8-3).
/* Now join a copy of the emails by message id to the in_reply_to of our emails */
with_reply = join sent_mails by message_id, replies by in_reply_to;
/* Filter out mailing lists - only direct replies where from/to match up */
direct_replies = filter with_reply by (sent_mails::from == replies::to) and
(sent_mails::to == replies::from);
store direct_replies into '/tmp/direct_replies';
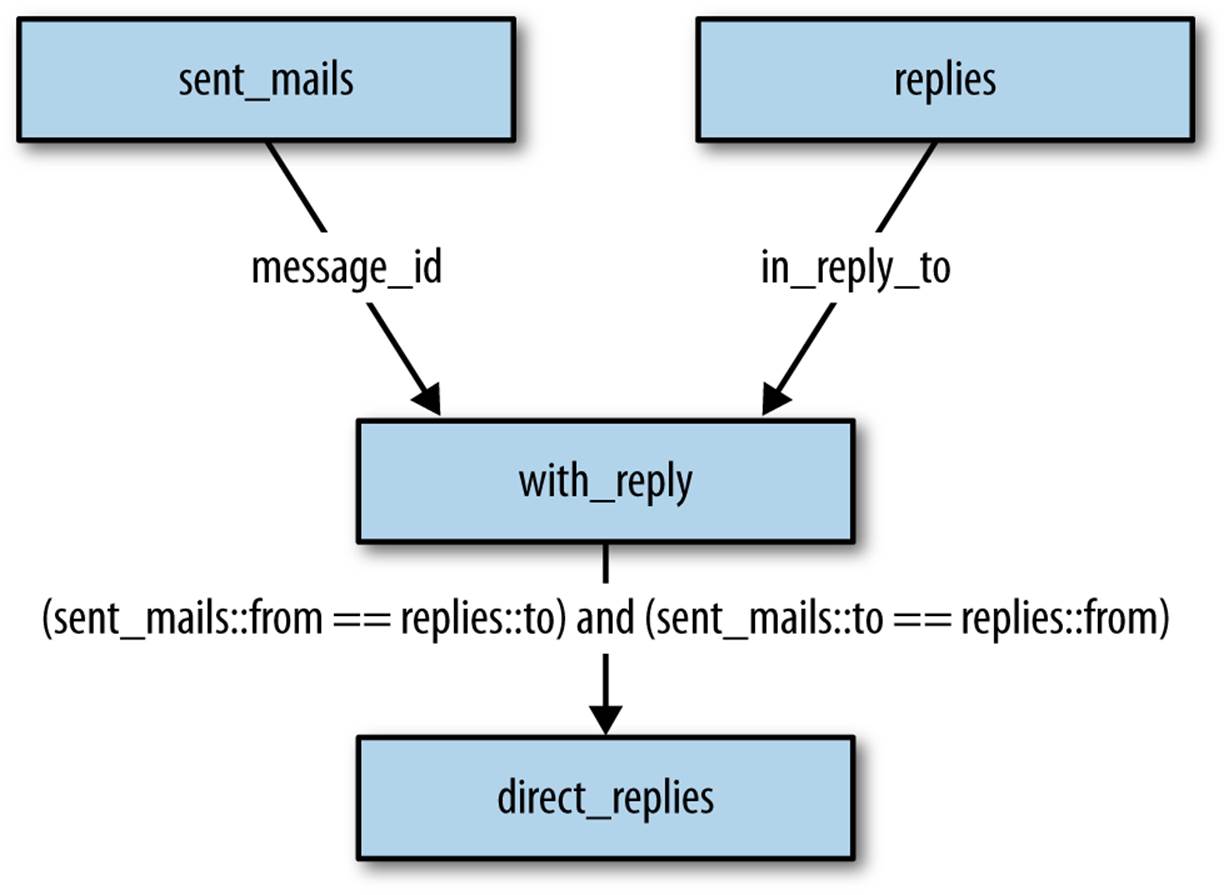
Figure 8-3. Self-join of emails with replies
The data at this point looks like the following. Notice how we’ve used a join (in this case, a self-join) to filter our data, which is a pattern in dataflow programming with Pig.
from to message_id from to in_reply_to
russell.jurney@gmail.com kate.jurney@gmail.com
CANSvDjrAR+ZHnxES3hBUZV+wJY_0ZbhzH0wjJEmiCTzBQGH1OQ@mail.gmail.com
kate.jurney@gmail.com russell.jurney@gmail.com
CANSvDjrAR+ZHnxES3hBUZV+wJY_0ZbhzH0wjJEmiCTzBQGH1OQ@mail.gmail.com
russell.jurney@gmail.com kate.jurney@gmail.com
CANSvDjrLdcnk7_bPk-pLK2dSDF9Hw_6YScespnEnrnAEY8hocw@mail.gmail.com
kate.jurney@gmail.com russell.jurney@gmail.com
CANSvDjrLdcnk7_bPk-pLK2dSDF9Hw_6YScespnEnrnAEY8hocw@mail.gmail.com
russell.jurney@gmail.com kate.jurney@gmail.com
CANSvDjrXO0pOC53j7B=sm4TMyTUVpG_GWxT-cUi=MtrGDDcs1Q@mail.gmail.com
kate.jurney@gmail.com russell.jurney@gmail.com
CANSvDjrXO0pOC53j7B=sm4TMyTUVpG_GWxT-cUi=MtrGDDcs1Q@mail.gmail.com
russell.jurney@gmail.com kate.jurney@gmail.com
CANSvDjrbuxc4ik3PPAy9OcRf3au9ww3ivkFKv8rwwdEsqvAAMw@mail.gmail.com
kate.jurney@gmail.com russell.jurney@gmail.com
CANSvDjrbuxc4ik3PPAy9OcRf3au9ww3ivkFKv8rwwdEsqvAAMw@mail.gmail.com
Since we have duplicate fields after the join, we can drop them:
direct_replies = foreach direct_replies generate sent_mails::from as from,
sent_mails::to as to;
The semantics of our data are now, “The message from A to B with ID C was replied to, from B to A.”
from to message_id
russell.jurney@gmail.com kate.jurney@gmail.com CANSvDjrAR+ZHnxE0Z…@mail.gmail.com
russell.jurney@gmail.com kate.jurney@gmail.com CANSvDjrL+2dSDF9Hw…@mail.gmail.com
russell.jurney@gmail.com kate.jurney@gmail.com CANSvDjrXO0p=sTUVp…@mail.gmail.com
russell.jurney@gmail.com kate.jurney@gmail.com CANSvDjrbuxc4iau9w…@mail.gmail.com
Now we’re ready to calculate reply counts between pairs of email addresses (Table 8-2).
reply_counts = foreach(group direct_replies by (from, to)) generate flatten(group)
as (from, to),
COUNT_STAR(direct_replies) as total;
store reply_counts into '/tmp/reply_counts';
Table 8-2. Reply counts
|
From |
To |
Total replies |
|
russell.jurney@gmail.com |
****@hotmail.com |
60 |
|
russell.jurney@gmail.com |
jurney@gmail.com |
31 |
|
russell.jurney@gmail.com |
****.jurney@gmail.com |
36 |
Having calculated total emails sent between email addresses, as well as the number of replies, we can calculate reply ratios: how often one email address replies to another (see Figure 8-4 and Table 8-3).
sent_replies = join sent_counts by (from, to), reply_counts by (from, to);
reply_ratios = foreach sent_replies generate sent_counts::from as from,
sent_counts::to as to,
(float)reply_counts::total/(float)
sent_counts::total as ratio;
reply_ratios = foreach reply_ratios generate from, to, (ratio > 1.0 ? 1.0 :
ratio) as ratio;
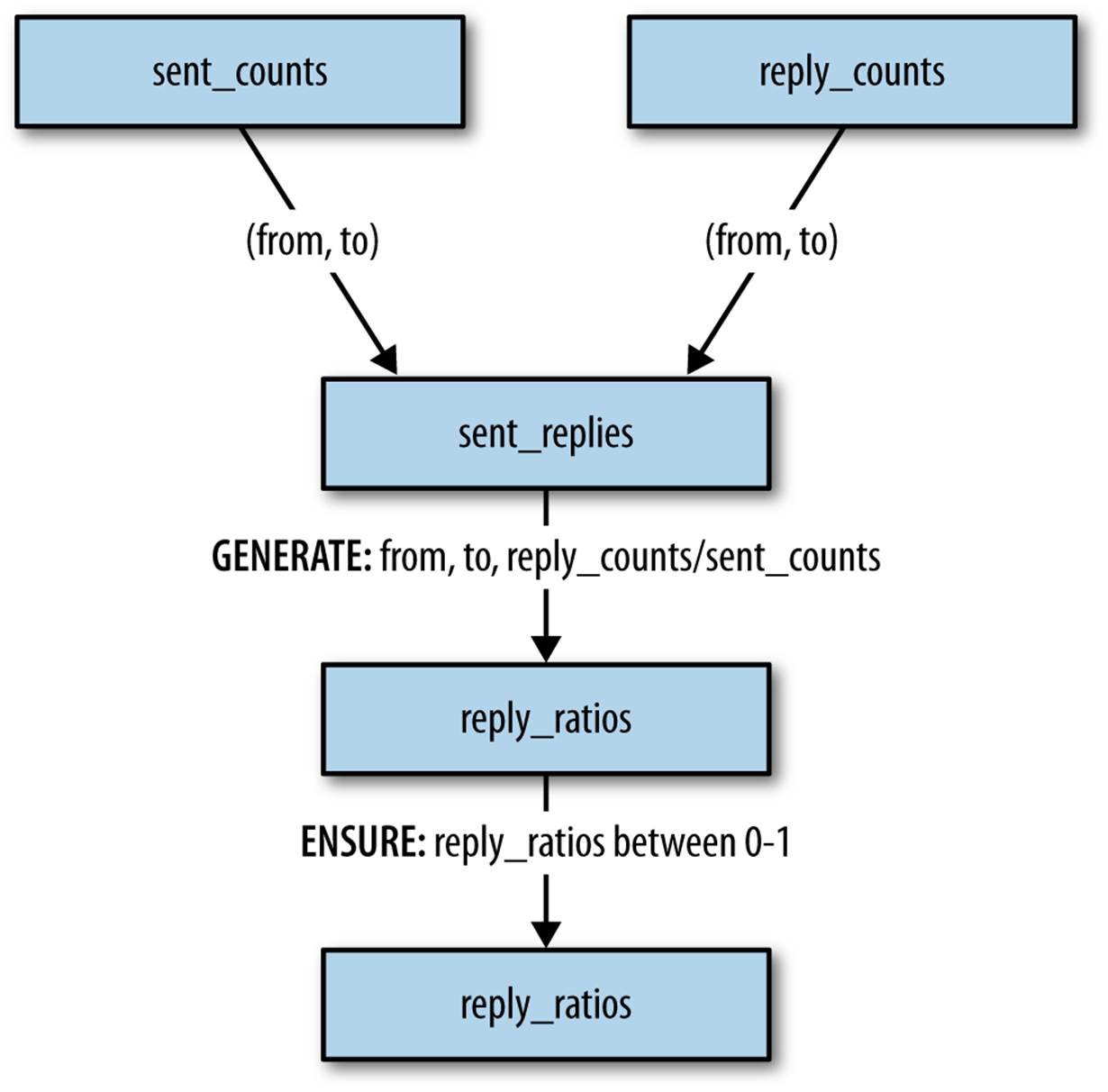
Figure 8-4. Calculating reply ratios
Table 8-3. P(response|email)
|
From |
To |
P(response|email) |
|
russell.jurney@gmail.com |
****@hotmail.com |
0.25316456 |
|
russell.jurney@gmail.com |
jurney@gmail.com |
0.25409836 |
|
russell.jurney@gmail.com |
****.jurney@gmail.com |
0.13186814 |
What this means is that given an email from russel.jurney@gmail.com to ****@gmail.com, we can expect 0.25 replies. Another way of saying this is that there is a reply about 25% of the time.
Finally, we publish this data to MongoDB and verify that it arrived.
store reply_ratios into 'mongodb://localhost/agile_data.reply_ratios'
using MongoStorage();
> db.reply_ratios.findOne({"from": "russell.jurney@gmail.com", "to":
"kate.jurney@gmail.com"})
{
"_id" : ObjectId("5010f7df0364e16aa73da639"),
"from" : "russell.jurney@gmail.com",
"to" : "kate.jurney@gmail.com",
"ratio" : 0.1318681389093399
}
Now let’s add this feature to our email address page.
Personalization
Up to now we’ve made no assumptions about the user of our application. That is about to change. In this section we will assume the user is me: russell.jurney@gmail.com. In practice, we would authorize and log in a user and then import and present data from his perspective via a unique session. To simplify the examples, we’ll just assume we’re me.
Insert a fetch for reply_ratio into our Flask app:
reply_ratio = db.reply_ratios.find_one({'from': 'russell.jurney@gmail.com',
'to': email_address})
return render_template('partials/address.html', reply_ratio=reply_ratio, ...
Edit our template for the address page to display the value (Figure 8-5). Note that we’ve skipped displaying each step in our calculation. As you become more comfortable with your dataset, you can chunk in larger batches. Still, it is a good idea to publish frequently to keep everyone on the team on the same page, and to give everyone access to building blocks to create new features from.
<div class="span6" style="margin-top: 25px">
<h3>Probability of Reply</h3>
<p style="white-space:nowrap;">{{ reply_ratio['from']}} -> {{
reply_ratio['to']}}: {{
reply_ratio['ratio']|round(2) }}</p>
</div>
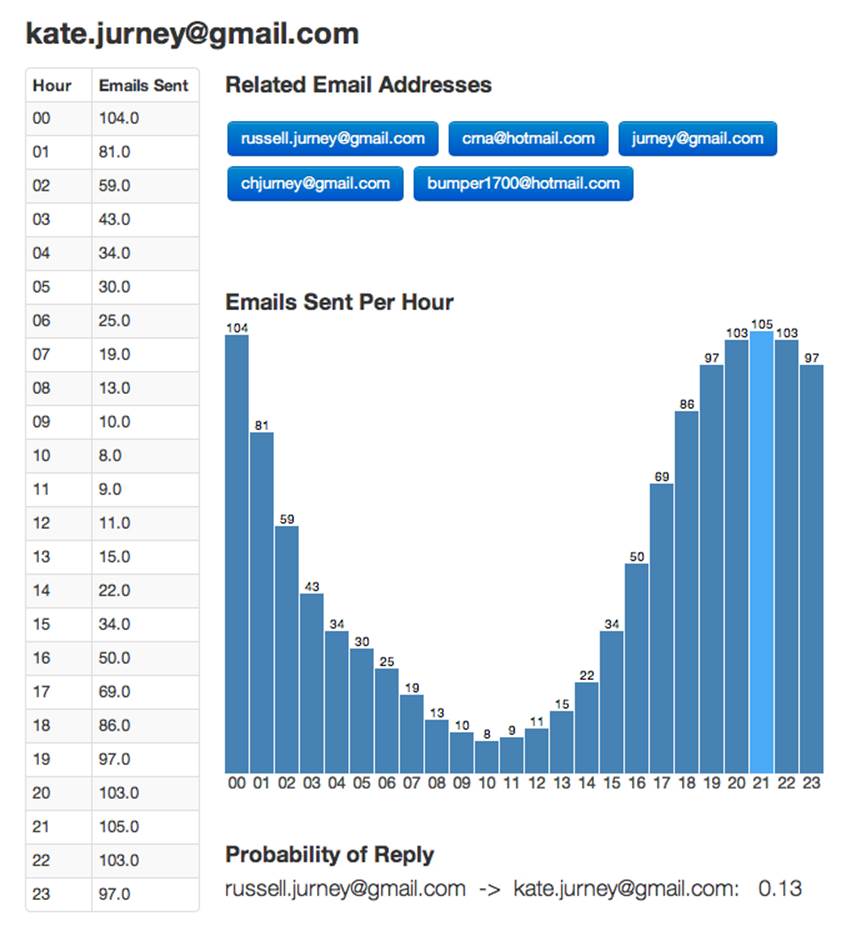
Figure 8-5. Displaying reply ratio
Conclusion
In this chapter we’ve taken what we know about the past to predict the future. We now know the odds that an email we are sending will be replied to. This can guide us in whom we email—after all, if we are expecting a response, we might not bother to email someone who doesn’t reply!
In the next chapter, we’ll drill down into this prediction to drive a new action that can take advantage of it.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.