CoffeeScript in Action (2014)
Part 3. Applications
Learning how to use CoffeeScript and how to use it well is not enough. It’s necessary, but it’s not sufficient. Why? Because the applications you write using CoffeeScript exist in a real world with practical considerations beyond the language itself. This part of the book prepares you for writing robust and maintainable applications in CoffeeScript both today and in the future.
Because this part explores topics that are ancillary to CoffeeScript, it takes the time to also teach the underlying concepts in those topics. Depending on your familiarity with the focus of each chapter, you should adapt your reading style accordingly.
Chapter 10. Driving with tests
This chapter covers
· Understanding unit tests
· Dealing effectively with dependencies inside tests
· How to test asynchronous programs
· How to test behavior
· Test suites and how to automate your test suite
I saw the best minds of my generation destroyed by madness.
From Howl by Allen Ginsberg
You have to solve harder problems in CoffeeScript today than most people had to solve in JavaScript in the early days. Back then, JavaScript was used to enhance browser applications. Today you’re writing entire applications in CoffeeScript. Writing more of the program means dealing with more of the problems. Writing tests for your programs can help with these problems and save you from losing your mind. Writing the tests first, before writing the programs, is a technique referred to as test-driven development.
If you’ve never done it before, test-driven development can feel uncomfortable, like having your pants on backwards. Be patient and give it some time, though; it might take a while to adjust. If you’ve done test-driven development before but not in CoffeeScript, you’ll be pleasantly surprised at how easy some of the techniques are.
This chapter presents and encourages a test-driven approach to development and leads you through the creation of your own tiny test framework. In practice, it’s more likely you’d use an existing test framework, but your understanding will be deeper if you go through the steps to build a tiny framework. The techniques for writing unit tests, dealing with dependencies, testing asynchronous callback-driven code, and structuring tests can be applied in other ways. First of all, why are tests important and why do you need automated tests? Why can’t you just test manually?
10.1. No tests? Disaster awaits
One time-honored approach to testing JavaScript applications is to test everything manually. Manual tests are important, but a testing strategy that uses only manual tests doesn’t work. You’ve seen it many times before. It’s not sufficient, it doesn’t scale, and it’s expensive because you need the real application and real humans to do all of it. Humans are really expensive, and you don’t need to spend all their valuable time doing something the computer can do.
Manual testing is more difficult in the long run. If it’s too difficult, you’ll decide not to do the tests, and before you know it, there are no tests.
What happens when you don’t write tests?
Imagine you’ve written all of the tracking code for Agtron’s site. It tells him how many visitors his shop gets. Yesterday he had more than 100,000 visitors. You have no idea how he managed to get that much traffic to his website, but it’s awesome nonetheless. Even better, your application and the accompanying tracking application, both written entirely in CoffeeScript, are performing nicely. No hiccups. As the sun sets before the weekend, you get a phone call from Agtron asking you to change the tracking program to add tracking of mouse movements for every user. Beer in hand on a Friday evening, you deftly implement a solution. On your way out the door, you go live to the production servers. Job done.
You awake in the night to the sound of your phone ringing. Something is wrong. The tracking program isn’t tracking any users. It occurs to you to debug the client-side program on the live server to see if you can find the problem there. When you load it up, though, you remember that the code on the production server has been compressed to make it download faster. It’s a big sea of unreadable code similar to this:
((function(){var a,b,c=function(a,b){return function(){return
a.apply(b,arguments)}};b=require("http"),a=function(){function
a(a,b){this.options=a,this.http=b,this.controller=c(this.controller,this),thi
s.pages=[]}return a.prototype.start=function(a){return
this.server=this.http.createServer(this.controller),this.server.listen(this.o
ptions.port,a)},a.prototype.stop=function(){return
this.server.close()},a.prototype.controller=function(a,b){return
this.increment(a.url),b.writeHead(200,{"Content-Type":"text/
html"}),b.write(""),b.end()},a.prototype.increment=function(a){var
b,c;return(c=(b=this.pages)[a])==null&&(b[a]=0),this.pages[a]=this.pages[a]+1
},a.prototype.total=function(){var a,b,c,d;c=0,d=this.pages;for(b in
d)a=d[b],c+=a;return c},a}(),exports.Tracking=a})).call(this);
You have no chance of debugging it. In a panic, your brain compiles a knee-jerk list of inappropriate reactions:
· Buy a one-way ticket to Tibet and live in a monastery on a mountaintop collecting sticks for the rest of your life.
· Give up on programming and move into management.
· Stop using CoffeeScript and go back to using only JavaScript.
Settle yourself. Instead, you decide to roll back the changes and deploy the last-known working version of the tracking program. There will be time to figure out what was wrong with the changes first thing in the morning.
The next morning, sitting at your desk and clutching your morning coffee, you’re on the phone with Agtron discussing what went wrong.
“How come the tests didn’t catch this problem?”
“The thing about the tests,” you reply, “is that there are no tests.”
Silence.
This story might have a happy ending. More likely it doesn’t. Instead of following it through, imagine a world where you have tests for everything the program does. Tests that you can run every time you make a change (or even when you don’t make a change) to make sure that the program is working as it should. That sounds better than a late-night panic when things go wrong. To live in that world, you need to learn how to write tests.
10.2. How to write tests
Ask your dentist which teeth you should brush. The answer will be “only the ones you want to keep.” It’s the same with tests—test only the parts of the program that you want to work. There are three basic steps:
1. Write a test.
2. Watch it fail.
3. Change the program to make the test pass.
This sequence begins with writing a test. How do you write a test?
Frameworks
Although it’s common to use a kitchen-sink-included testing framework to write tests, these frameworks aren’t necessary to learn how to test. By learning to write tests without a testing framework, you’ll understand the principles behind testing frameworks.
A test can be just a stated requirement for what the program should do. A simple requirement for something the tracking application should do is this:
It should record each product the user clicks on.
If this test is translated into something that can be executed (a test program), then it can be run automatically against the real program every time a change is made. Tests that are run automatically provide frequent feedback that the program does what it should. Without tests, there’s only hopethat the program will do what it should. The broken tracking application showed you that hope isn’t an effective long-term testing strategy. How do you write a test for the requirement?
To learn how to test effectively, you need to learn about assertions, how to write them for the smallest parts (units) of your program, how to repeatedly write them as you develop your program, and how to get reliable feedback to tell you whether your assertions hold or not. The first step is understanding assertions.
10.2.1. Assertions
For a moment, forget about how you’ll implement the tracking application. Imagine that it’s already written and that as part of your work you have a totalVisits variable that tells you how many visits have been recorded. The test would follow along these lines:
initial = totalVisits
# Somehow visit the homepage
# Assert that the totalVisits has increased by one
There are two parts of this that you don’t yet know how to write in CoffeeScript: write a program that visits the homepage (like a real user), and assert that the number of visits has increased afterward. You’ll learn assertions first.
An assertion is a statement about the value of an expression. It either passes or fails. CoffeeScript doesn’t have assertions built-in, but Node.js has a built-in assert module that you can use. To use the assert module you require it:
assert = require 'assert'
# { [Function: ok] ...
Then you invoke one of the assert methods, such as assert.ok, which tests whether an expression is truthy. If the assertion succeeds, it evaluates to undefined:
assert.ok 4 is 4
# undefined
If the assertion fails, an exception is thrown:
assert.ok 4 == 5
# AssertionError: false == true
Tests describe something the program does. The description is an important part of the test. One way to put a description in a test is by wrapping it in a function assigned to a variable named after the description:
![]()
Another useful assertion method is assert.equal, which takes two arguments and throws an exception if the arguments aren’t equal:
do assert4Equals4 = ->
assert.equal 4, 4
Although obviously fake, this small test demonstrates a very basic unit test. A test to see if a small unit of your program does what it should do is a unit test.
10.2.2. How to unit test
In order to understand the mechanics of writing tests, it’s worthwhile to take only a small part of an application and implement it using a test-driven approach. Suppose that as part of the dashboard for Agtron’s tracking application, you need to highlight the most popular product. To highlight it you must add a class attribute to a DOM element in a web page. Consider the following HTML fragment:
<html>
<div class="product special">X12</div>
The <div> has two classes: product and special. You want some way to add a third class of popular so that it becomes
<html>
<div class="product special popular">X12</div>
Putting aside manipulation of HTML elements for a moment, this problem is about adding words to a string. When you’re writing this individual unit of code, the requirement is this:
It should add a word to a space-separated string of words.
Follow the steps. Write a test; watch it fail; make it pass.
Write a test
Create a file called word_utils.spec.coffee and put the following failing test inside:
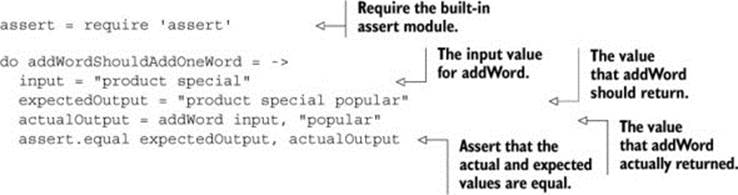
Watch it fail
There’s no addWord function yet, so this test should throw an error, and throwing an error counts as a failure. It does throw an error:
> coffee word_utils.spec.coffee
ReferenceError: addWord is not defined
Create a file called word_utils.coffee and require it in the test file:

Make it pass
Implement the addWord function to make the test pass. The word_utils.coffee file initially exports an empty addWord function:
addWord = (existing, addition) -> # not implemented
exports.addWord = addWord
In practice you’d now continue to implement a working solution. This time, though, pause for a moment and think, what would happen if you ran the test now? It should fail because the addWord function returns undefined. To make sure the program is currently working how you think it’s working, you run the test:
> coffee word_utils.spec.coffee
AssertionError: "ultra mega ok" == "undefined"
It fails exactly as you expected it to. That’s good. You now implement a working addWord function:
addWord = (text, word) ->
"#{text} #{word}"
You run the test and it passes:
> coffee word_utils.spec.coffee
# No output
The common.js assertions return undefined when there’s no failure, so there’s no console output when this test passes.
You’ve just done test-driven development. You wrote the test; you watched it fail; you implemented the solution to make it pass. By writing the test first, you know that you have a test for that specific part of your program. Yes, it’s possible that the test is wrong. No, having tests isn’t a guarantee that the program never does anything wrong. What you can guarantee, though, is that if you don’t write tests you’ll have much less confidence that your program does what it should.
You repeat the process as you write the program. Like the cliché, you lather, rinse, repeat. If you have a new requirement, write a new test.
10.2.3. Rinse and repeat
The most popular product doesn’t stay the most popular forever. You need to be able to remove the highlight from an element once it’s no longer the most popular. Removing the class popular from
<html>
<div class="product special popular"></div>
results in
<html>
<div class="product special"></div>
This requirement can be written like this:
It should remove a word from a space-separated string of words.
Same thing again. Write a test; watch it fail; make it pass.
Write a test
A test for a function that removes a word is as follows:
assert = require 'assert'
{addWord, removeWord} = require './word_utils'
do removeWordShouldRemoveOneWord = ->
input = "product special"
expectedOutput = "product"
actualOutput = removeWord input, "special"
assert.equal expectedOutput, actualOutput
Before you’ve implemented any solution, the test fails as expected. The first implementation of removeWords uses the replace method on a string to replace the word with an empty string:
removeWord = (text, word) ->
text.replace word, ''
Remember to export the new function from the word_utils file:
exports.removeWord = removeWord
You now have an implementation. Does the test now pass or does it still fail?
Watch it fail
Run the test:

The test fails because the whitespace is different.
Make it pass
To make the test pass, you try again with another solution using a regular expression to remove any whitespace left behind:

Now the test passes:
> coffee word_utils.spec.coffee
# No output
Agtron, peering over your shoulder, asks if he can try something. Agreeing, you hand him the keyboard. You anticipate that Agtron is going to show you how to improve your test. He changes the test to run against multiple input values:

The test fails:
> coffee word_utils.spec.coffee
#AssertionError: "product ial" == "product special"
Agtron hasn’t just shown you how to improve the test; he’s shown you that the test was insufficient. You need a better removeWord function. In chapter 3 you learned to split a string of words into an array of words. With this technique, you have a new solution:
removeWord = (text, toRemove) ->
words = text.split /\s/
(word for word in words when word isnt toRemove).join ' '
You now have a passing test:
> coffee word_utils.spec.coffee
# No output
This example is trivial and only tests a very small simple function. The process is important, though, and it’s always the same, as you’ve just seen.
Until now you’ve used a three-step process that included watching the test fail. You might consider this step as implied, making the process two steps:
1. Write a failing test for a single unit of code.
2. Write code that passes the test.
The important thing is that the test is written first. It’s also very different from how you wrote the broken tracking application, which was solution first, test second. Actually, the tracking application never got to the second part, so there was no feedback about whether the application worked as it should. Test feedback matters.
10.2.4. Feedback
Currently, when a test passes you’re blandly greeted with empty console output:
![]()
It would be useful to see feedback for each test stating whether it passed or failed. The following listing contains the tests for addWord and removeWord and a fact function that runs a test wrapped inside a try...catch.
Listing 10.1. Add and remove word


Running this file outputs the description of each fact along with the result:
> coffee word_utils.spec.coffee
addWord adds a word: OK
removeWord removes a word and surrounding whitespace: OK
The addWord and removeWord functions are general solutions to part of a more specific problem of adding a class to a <div>. What would have happened had you dove straight in and written an addWord implementation like this?
addClass = (selector, newClass) ->
element = document.querySelector selector
if element.className?
element.className = "#{element.className} #{newClass}"
else
element.className = newClass
Try to write a test for it:

Notice that the test asserts something on the document. This is only indirectly testing the addClass function. Worse, if the document ever changes the way it works, you’ll need to update both the function and the test. No thanks.
The addClass function depends on the presence of a document to work. In other words, document is a dependency. How do you deal effectively with dependencies in a test?
10.3. Dependencies
When you write a test, the part of the program you’re testing is the system under test. Anything that you’re not testing but that the system under tests uses is a dependency.
Imagine a car. To test if the battery is working, a device called an ammeter, which tests if the battery is producing electricity, is used. The car needs electricity to start and to power accessories such as the radio. A battery that’s removed from the car can still be tested with an ammeter. Not the radio, though; if the battery is removed, then the radio won’t turn on, preventing it from being tested. How do you test the radio without the battery? Well, the radio doesn’t need the battery specifically but only some equivalent source of electricity.
The same principle applies to components in a program. When you test part of a program, the dependencies don’t need to be the real thing, just something that’s equivalent as far as the test is concerned. In this section you’ll learn why testing programs with dependencies is a challenge, how you can isolate those dependencies, and how to deal with them by using test doubles.
10.3.1. Why dependencies make testing difficult
Remember the task at hand: rewrite the tracking application using a test-driven approach. One part of the application is a dashboard that Agtron uses to see what’s happening on his web shop: how many visitors there are, what they’re looking at, and things like that. Imagine you’re writing a test for part of the dashboard that extracts some data obtained via an HTTP service that returns JSON:
fact "data is parsed correctly", ->
extractData 'support', (res) ->
assert.equals res.status, 'online'
A simplified example of data from the HTTP service contains just one property and value:
{ status: 'online' }
You implement extractData to take a callback and pass it as the callback to http.get:
http = require 'http'
extractData = (topic, callback) ->
options =
host: 'www.agtronsemporium.com'
port: 80
path: "/service/#{topic}"
http.get(options, (res) ->
callback res.something
).on 'error', (e) ->
console.log e
This works well until the day you crash the website. When www.agtronsemporium.com crashes, you’re no longer able to get data from it. This causes the extractData function to fail because http.get doesn’t work.
Imagine you’re working on the program during this time when the HTTP service is down:
> AssertionError: "undefined" == "online"
This is a problem. Whenever the external site is down, you have no way to verify that the program is working correctly, even at the unit level. Unit tests shouldn’t break when a dependency (in this case the external site) is unavailable. To make sure that unit tests work all the time, you need something that does the job of an HTTP service that isn’t an HTTP service. You need something that won’t break like an egg on your face. A thing that does the job during a test is a test double.
10.3.2. Test doubles
There are many terms for things that replace dependencies during a test (such as spies, mocks, and stubs). In this chapter test double or just double is used as a general term for something that replaces a dependency in a test. A double is like the stunt double for an actor or the friend who brought their jumper cables around that time your car battery was dead. When the real thing isn’t suitable, you use a double.
In a minute you’ll see how to create a double, but suppose for now you already have one; how do you get it into the program during the tests? By injecting it.
Injection
Picking up the actor metaphor again, consider a scene where an actor has to do a stunt:

A test for this scene asserts that it returns the value 'Scene completed':
fact 'The scene is completed', ->
assert.equals scene(), 'Scene completed'
The scene itself obtains the actor, so a test for this scene has no way to replace the actor with a double. If instead the scene is provided with the actor, then replacing the actor with a double becomes possible:
scene = (actor) ->
actor.soliloquy()
actor.stunt()
'Scene completed'
Now you can replace the actor with a double by passing it in as an argument. The double will need to be convincing, though. It’s no good having a double that doesn’t know how to soliloquy because the scene won’t work if it doesn’t. So how do you create a test double that works?
Frameworks
If you use a test framework, it will likely provide some standard ways to create test doubles. But as with assertions, you don’t need a testing framework to learn how to use doubles. In some languages it’s very difficult to create a double without a framework, but in CoffeeScript it’s quite easy. This is because objects are like an all-night café—always open.
Creating a double from scratch
During the scene, the actor does a soliloquy and a stunt—both methods of the actor object. A double that takes the place of the actor during the scene without ruining it needs to know how to do (or pretend to do) things that the actor has to do. Create a double that can soliloquy andstunt using an object literal:
actorDouble =
soliloquy: ->
stunt: ->
The scene completes successfully with this actorDouble in place of the actor:
scene = (actor) ->
actor.soliloquy()
actor.stunt()
'Scene completed'
fact 'The scene is completed', ->
actorDouble =
soliloquy: ->
stunt: ->
assert.equal scene(actorDouble), 'Scene completed'
# The scene is completed: OK
This technique of providing dependencies to part of a program is called dependency injection. Creating doubles in this way to pass them in as arguments is straightforward, if at times a little inconvenient, in CoffeeScript.
Consider the extractData function that contains a dependency on http. Any tests against it will suffer the same difficulties that the tests for scene had:

As you can see, the http dependency makes testing very difficult because it breaks all the tests any time the external site is offline. You can solve this with an http double. The double must know how to act like the real thing, so by looking at extractData you can see that the double must have a get method and an on method:

To the extractData function, this http double will look just like a real http. In duck-typing terms (chapter 7), it walks like an http and quacks like an http, so it’s an http.
Having the double is only half the story; it also needs to be injected during the test. In order to allow this, the extractData function must be changed to allow the dependency to be injected:
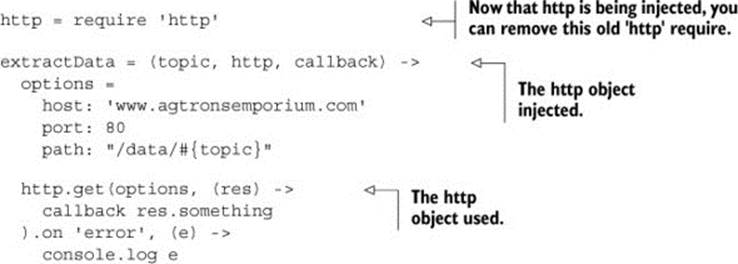
Now the tests can be written such that they don’t break every time something goes wrong in the real world.
Injecting dependencies in this way isn’t the only option; dependencies can be isolated to specific locations in the program so that they can be avoided as much as possible in other, easily testable units of the program.
Creating a double with prototypes
Sometimes you need a double for an object with lots of properties, but only one of those properties needs to be replaced inside the test. Consider this Form class, which has a dependency on the global window object present in all web browsers:
class Form
reloader = ->
window.location.reload()
A real window object in a web browser has many properties:

A real window object in a web browser has more than 200 properties. It would take a very long time to create a suitable double to use inside the test. Instead of writing a double from scratch, you can use Object.create to create a double with the real thing as a prototype and then override just the parts you need to. For the Form class you need to override the reload method:
windowDouble = Object.create window
windowDouble.location.reload = ->
This saves some time in creating a double to inject during testing. Change the Form class to accept an injected window in the constructor:
class Form
constructor: (@window) ->
reloader: ->
@window.location.reload()
Isolation
The extractData function does too much. It fetches and extracts the data when really it should just extract the data. Breaking out the fetching of data into a separate function removes the dependency that extractData has on http. This means that tests for extractData don’t need to even know about http, let alone create a double:
fetchData (http, callback) ->
options =
host: 'www.agtronscameras.com'
port: 80
path: "/data/#{topic}"
http.get(options, (res) ->
callback res
).on 'error', (e) ->
console.log e
extractData = (data) ->
console.log data
fetchAndExtractData = ->
fetchData http, extractData
The next listing shows the final version of the tests with dependencies avoided where possible and injected where necessary.
Listing 10.2. Testing with a double


When you isolate dependencies and inject them only into places where you absolutely need them, the program is easier to reason about and easier to test. Dependency injection can lead to a particular problem, though. In a world where everything is injected, all you see is things being injected. What does this mean and how can you avoid it?
10.3.3. Avoiding dependency injection hell
Imagine you’re writing part of the dashboard for Agtron’s tracking application that displays the number of visits for a particular user. As part of this, you have a visits function with three dependencies: a database, an HTTP service, and a user.
Suppose this visits function looks up the user in the database and then uses that information to get the number of hits for the user from the HTTP service:
visits = (database, http, user) ->
http.hitsFor database.userIdFor(user.name)
Suppose you then find out that some users have requested their data be kept private and that information be available only in a permissions file. You add another argument:
visits = (database, http, user, permissions) ->
if permissions.allowDataFor user
http.hitsFor database.userIdFor(user.name)
else
'private'
With more and more dependencies, you can see that this will get more and more unwieldy. An options object passed in as an argument (see chapter 4) is a common solution to the problem of having too many arguments:
visits = (dependencies) ->
if dependencies.permissions.allowDataFor user
dependencies.http.hitsFor dependencies.database.userIdFor(user.name)
else
'private'
That’s different . . . and worse! The function is now harder to understand.
Think about it; most of the time you don’t need all of those options. If you partially apply the function (discussed in chapter 6) and create a new function that has fewer arguments, then you can make it more manageable. Instead of having lots of dependencies,
visits = (database, http, user, permissions) ->
if permissions.allowDataFor user
http.hitsFor database.userIdFor(user.name)
else
'private
make a makeVisits function that fixes the user and permissions arguments to visits:
makeVisitsForUser = (database, http) ->
(user, permissions) ->
visits database, http, user, permissions
This function would typically be used dynamically, but an example of using it for a single known user, by explicitly passing in a user and permissions, is as follows:

The resulting visitsForBob function can then be used:

Cute, you think, but how is it useful in a test? Imagine you have two tests that use the visits function. Each of them creates doubles for database, http, user, and permissions:
fact 'Visits not shown when permissions are private', ->
database = databaseDouble
http = httpDouble
user = userDouble
permissions = new Permissions
assert.equal visits(database, http, user, permissions), 'private'
fact 'Returns visits for user', ->
database = databaseDouble
http = httpDouble
user = userDouble
permissions = new Permissions
assert.equal visits(database, http, user, permissions), 'private'
Notice that the dependencies are essentially the same in both cases. If the program has already been structured to have the makeVisitsForUser function, then dealing with the dependencies in the test is easier:
database = databaseDouble
http = httpDouble
visitsForUser = makeVisitsForUser database, http
fact 'Visits not returned when permissions are private', ->
user = new User
privatePermissions = new Permissions private: true
assert.equal visitsForUser(user, privatePermissions), 'private'
fact 'Visits returned for user', ->
user = new User
privatePermissions = new Permissions private: true
assert.equal visitsForBob(database, http), 'private'
This change looks minor at a small scale (and it is), but as a program grows, if it has been composed with functions, then you can avoid some messy dependency situations that are otherwise difficult to solve.
In this section you’ve learned to deal with program dependencies when writing unit tests. The general approach is to create a test double that takes the place of the dependency during the test. You’ve also seen the different ways to get doubles where you need them during tests. By forcing yourself to write programs that allow dependencies to be replaced by doubles during tests, your programs will be easier to maintain. That’s an added benefit that you’ll appreciate on another day.
What else do you need to know about testing? This is CoffeeScript, so your applications almost always run in an event-driven environment. One of the things you’ll have to deal with in an event-driven environment is the tension between asynchronous code and the desire to structure tests synchronously.
10.4. Testing the asynchronous
CoffeeScript programs, usually run in the browser or on Node.js, are usually event driven, and I/O is almost always asynchronous. Why is this a problem? Well, consider the following test structure:
fact 'the tracking application tracks a user mouse click', ->
options = {}
tracking = new Tracking options, http
tracking.start ->
fred.visit '/page/1'
assert.equal tracking.total(), 1
The start method of the tracking object expects a callback function that will be invoked when it’s finished. But the test invokes the visit method of the fred object and asserts the result of invoking the total method on the tracking object immediately, without bothering to wait for the start method to finish. If the start method hasn’t finished by the time the assertion occurs, the test will fail.
There are three related techniques for dealing with asynchronous I/O in tests: live with it, remove it, or expect it.
10.4.1. Live with it
One technique for testing asynchronous programs is to just reflect the asynchronous nature in your tests. To do this, add assertions as part of a callback to the function you’re testing:

Leaving the callback in the test for the start method works well for a while. But what if the start method has some external dependency? What if the start method performs some potentially error-prone network I/O?
10.4.2. Remove it
There are two types of functions that accept callbacks. One uses I/O and the other one doesn’t. Don’t do any I/O in a unit test. Remember the http double?
http =
get: (options, callback) ->
callback()
@
on: (event, callback) ->
# do nothing
The get method takes a callback as an argument but it isn’t asynchronous; it’s invoked immediately. It’s unlike a real http where the callback is invoked only after a network request has successfully returned. This means the http double has removed the dependency on the external HTTP service whenever it’s used in place of the real http. If you pass in an http double as a dependency to the tracking object, then you’re removing the external dependency from the test:
fact 'the tracking application tracks a user mouse click', ->
options = {}
http =
get: (options, callback) ->
callback()
@
on: (event, callback) ->
# do nothing
tracking = new Tracking options, http
tracking.start ->
fred.visit '/page/1'
assert.equal tracking.total(), 1
Perhaps you don’t really need an http double at all. Instead, you can create a double of a method that uses it. Replace the start method with a double:
fact 'the tracking application tracks a user mouse click', ->
tracking = new Tracking options, http
tracking.start = (callback) ->
callback()
fred.visit '/page/1'
assert.equal tracking.total(), 1
This example oversimplifies the scenario, but you can clearly see that instead of a double for an object, you essentially have a double for a function. This is often referred to as a method stub, but you can think of it like any other double.
10.4.3. Expect it
Suppose you’re testing a program that talks to a database via this http object. You don’t really care about the response you get back asynchronously from the database. What you do care about is that you made the correct call to it. If the correct call was made, you trust the database to do the right thing. After all, a database that doesn’t store things when you tell it to is probably not a database worth having.
Consider the http module; you might expect a particular method to be called with specific parameters. A simple way to test that the call happened is to remember it in the test, using a variable:

Using lexical scope, you can store information about whether the get method has been invoked on http. It’s a simple technique for testing whether a dependency has been called.
The full unit tests for the Tracking class are shown in listing 10.3. This listing makes use of the fact function from listing 10.1 extracted into a separate file as follows:
exports.fact = (description, fn) ->
try
fn()
console.log "#{description}: OK"
catch e
console.error "#{description}: "
throw e
Also note that the module being tested (listing 10.4) is also required at the top of the test.
Listing 10.3. Test for the Tracking class

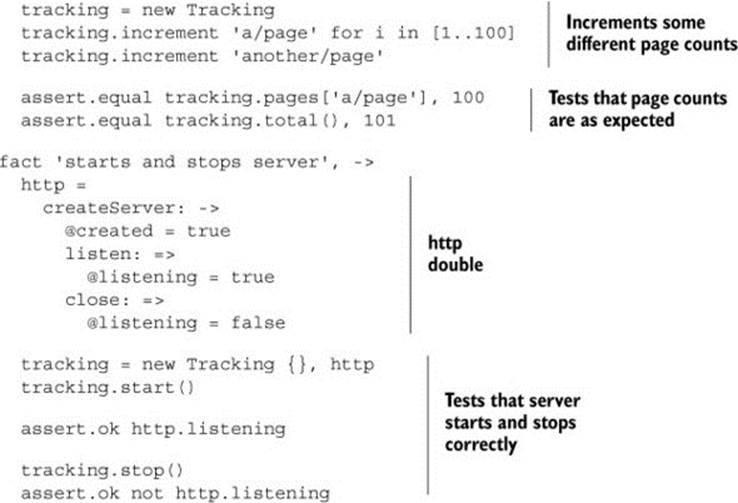
The Tracking class is shown in the next listing.
Listing 10.4. The Tracking class
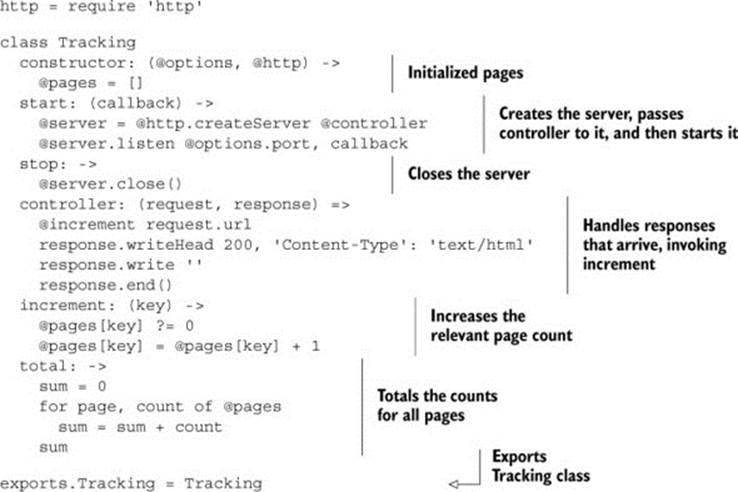
10.4.4. Exercise
Write a small expectation library that makes the following possible:
fact 'http service should be accessed', ->
httpDouble = double http
tracking = new Tracking {}, httpDouble
assert.ok httpDouble.listen.called == true
Assertions, unit tests, dependencies, expectations, and dealing with the asynchronous are important, but remember why you started down this path in the first place. You want to write real programs with evidence that they do what they’re supposed to do. This means you started with a test for what the program does.
10.5. System tests
You started with a requirement:
It should record each product the user clicks on.
This is a system requirement. System tests are often functional tests because they test the functionality of the whole system. Functional tests are not related to functional programming, so you might find the term system test less confusing.
To learn how to test-drive the development of a program, you looked only at small components of the overall tracking system. This was necessary for you to understand how things work but was somewhat artificial. In practice you’d implement only the components required to get a passing test for a single system requirement.
The good news is that you now have the pieces of the test-driven development puzzle you need to start with a system requirement, write a test for it, and continue to write the code to meet that requirement:
fact 'the tracking application tracks a single mouse click', ->
tracking.start ->
assert.equals tracking.total, 0
userVisitsPageAndClicks()
assert.equals tracking.total, 1
You know that the asynchronous part of the tracking program has been reflected in the test, with the remainder of the test being passed to the start method. You also know that userVisitsPageAndClicks is going to create a double for a user because having a real user for your test isn’t practical; you’d need to kidnap one and keep them locked in your basement. The following listing demonstrates this slightly differently as a full working example.
Listing 10.5. System test for tracking application
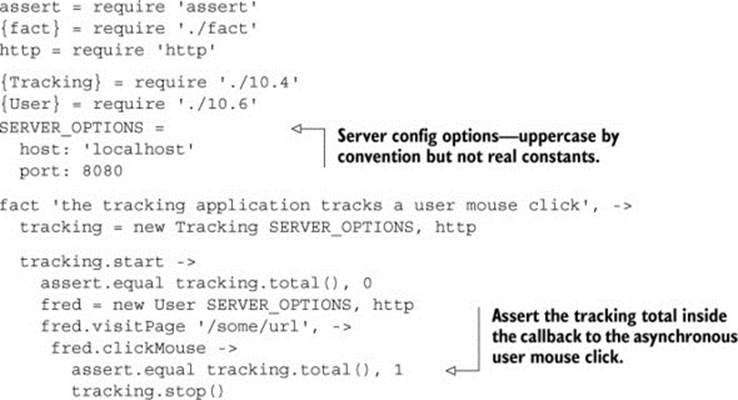
The User class used in listing 10.5 is shown in the next listing. This class provides a user that can interact inside the tests. Think of it like a test double for a real person. It simulates what happens when a real person visits the site.
Listing 10.6. The User class

It’s time to put all of these tests together and create a test suite.
10.6. Test suites
You have tests. Some of them are unit tests. Some of them are system tests. The total set of all the tests for the application belong together in a test suite.
All of the tests you have are executable, but to execute them you have to run each of them individually. Suppose you have your tests in three files. To test if the program is working correctly, you’ll need to execute all three files from the command line:
> coffee test1.coffee
# OK
> coffee test2.coffee
# OK
> coffee test3.coffee
# Fail
If you have to run all of the tests individually, then the chances that you actually will run them all the time is rather small. To get the full value of the tests, they need to be easy to run—all at once. In this section you’ll learn how to create a test suite for your tests that makes it easy to run them all at once. This involves removing some repetition with test setups and teardowns, making it easier to run the tests with a single command, and making the tests run for you, automatically. First up, setups and teardowns.
10.6.1. Setups and teardowns
It’s very likely that you have several tests that require a “bunch of the same stuff” to be in place before they run. Suppose you have three that all require an http double. You might start writing the first test like this:
fact 'this test uses a http double', ->
http =
get: (options, callback) ->
callback()
@
on: (event, callback) ->
# do nothing
When you write the second test, you don’t want to replicate the code for http double, so you move it outside the fact:
httpPrototype =
get: (options, callback) ->
callback()
@
on: (event, callback) ->
# do nothing
fact 'this test uses a http double', ->
http = Object.create httpPrototype
fact 'this test also uses a http double', ->
http = Object.create httpPrototype
Even that is tedious. What you really want is to define some setup that’s done either before all of your tests or before each of your tests. By now you know that functions are good for this sort of thing. For example, you can extract the double creation into a createHttp function to run before each test:
createHttp = ->
http =
get: (options, callback) ->
callback()
@
on: (event, callback) ->
# do nothing
http
fact 'this test uses a http double' ->
http = createHttp()
# the rest of the test goes here
If you have to create 10 doubles, you’ll have to call 10 different setup functions. No thanks. The simplest way to handle setup for groups of tests is to take advantage of function scope. If you have three tests that use an http double, put them in a single scope:

Similarly, when each test is finished, you might need to clean up after yourself by extracting the cleanup work to a teardown function that’s invoked after each test.
With setups and teardowns, you’ve tidied things up inside test files. How about multiple test files—how do you deal with those?
10.6.2. Test helpers and runners
You still have to run your test files individually. To test three modules, you must invoke three test files:
> coffee word_utils.spec.coffee
# OK
> coffee tracking.spec.coffee
# OK
> coffee another.spec.coffee
# OK
This is annoying. When there’s only one file to test, it’s almost bearable, but what about when there are 10, 100, or 1,000 test files? To be confident that you’ll actually go to the bother of running the tests, they need to all be invoked with a single command.
Test helpers
You have a new dependency problem in your tests. Everywhere you look, there are require statements that grab different parts of the program and do scaffolding in order to get a sufficient environment in place so that your tests will run. This is annoying to do multiple times. Don’t let the machines mock you.
A test helper provides a single place to put all of the things that the tests need to run. The test helper for the tracking application tests is in the listing that follows.
Listing 10.7. The test helper

To run the test files together, you can write another test runner file that finds all of the tests and runs them.
Test runners
You want all your tests to run with a single command, a test command reminiscent of the ring of power in The Lord of The Rings:
One command to rule them all, one command to find them, one command to bring them all and in the darkness bind them.
You get the idea.
A simple test runner just finds test files in a specific directory based on their filenames and executes their contents as CoffeeScript. This test runner can also inject require dependencies into a file by munging the file source to put additional require expressions at the top of the file before they’re run. This is a somewhat unsophisticated and brutish approach, but in the absence of a test framework or a more elegant solution, it works. The following listing shows such a test runner.
Listing 10.8. The test runner

Injecting modules into the source code of a test before passing it to the runtime makes you slightly uneasy, but it works and can make writing tests a bit easier. Making it easier to write tests means you’ll be more likely to actually write them, keeping the rest of the program cleaner. Although different test frameworks will have other ways to provide these conveniences for you, the reasons behind them are the same.
What does the setup of the program look like after all this is done? The file and directory structure for the tracking application should now be rearranged to look like this:
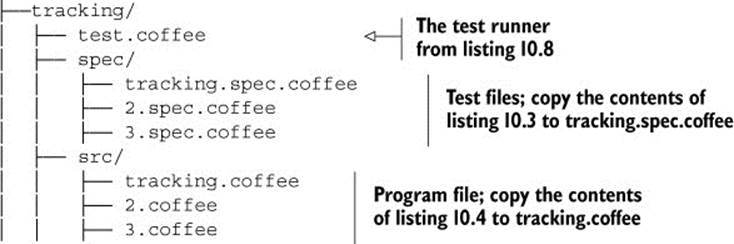
Move the test (or spec) files to a spec folder and the program source files to an src folder, keeping them clearly separated. When you do this, you’ll also need to update any require paths.
When the test.coffee file is executed, all of the tests in the test directory run and report the result:
> coffee test.coffee
Instead of invoking it using the coffee command, you can change test.coffee into an executable script, allowing the tests to be run without invoking coffee directly on the command line:
> ./test
An executable script is easier to integrate with other programs. Be sure to make the script executable. The exact method of doing this depends on the platform you’re running on. Here is a simple shell script for *nix-based systems that assumes CoffeeScript is installed:

It’s nice that you can run all the tests with a single command. What would be even nicer, though, is if you didn’t have to remember to run them at all.
10.6.3. Watchers
The final piece of the test suite puzzle is getting tests to run automatically when a file is changed. This way, you wouldn’t even need to run the single command that executes the tests. Instead, you can start the watcher. The watcher script here is called autotest because it runs the tests automatically:
> ./autotest
Then start writing tests. If you write a failing test in the file test1.spec.coffee,
fact 'True should equal false', ->
assert.equal true, false
then you’ll see a message on the command line:
> True should equal false
> Assertion Error: true != false
> at spec/1.spec.coffee
An example autotest script is shown in the next listing. This file needs to be executable.
Listing 10.9. The watcher
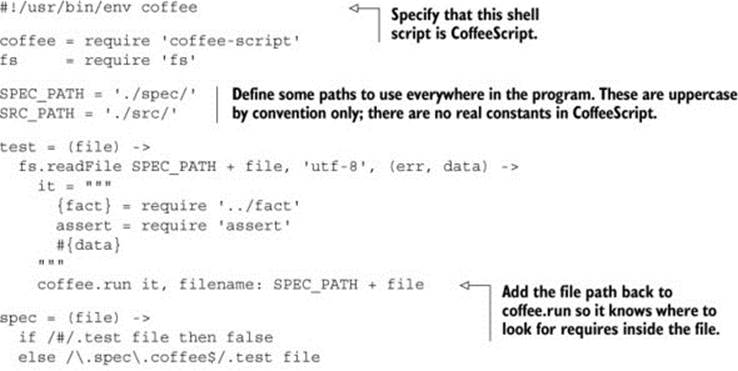

This autotest runs as a script in a *nix environment (such as your MacBook or your Linux or BSD server). Consult a local expert for how to create a version for your operating system.
The test script and watch script provided here read only a single directory. In practice you might need to monitor all of the subdirectories as well. But it’s just as likely that you’ll be using an existing testing framework. Having seen how the testing stack goes together, though, you’re in a better position to work with an existing testing framework. You know how to use a test framework because you’ve written one. That’s right: in this chapter you’ve written your own test framework. It wasn’t that difficult!
By writing (or using) a test framework, you’ve made it easier to write tests. If it’s easier to write tests, it’s more likely that you actually will write tests and, as a result, actually have evidence that your program behaves the way it’s supposed to. Evidence is good. Scruffy and Agtron wouldn’t trust your untested software any more than they would trust the untested medicine in figure 10.1.
Figure 10.1. Tests are evidence that your program works.

You get the message. Write tests.
10.7. Summary
You’ve learned how to test programs. Actually, by writing tests without a test framework, you’ve written your own tiny test framework. That was surprisingly easy to do in CoffeeScript, wasn’t it? This was valuable in showing you how the fundamental principles work. When you have to use a testing framework, you’ll understand the basic principles behind it. A testing framework provides easier ways to do some of the tasks outlined in this chapter. Although which test framework you use often comes down to personal choice, popular test frameworks worth exploring are Jasmine, Mocha, and node-unit, all of which can be found in the Node.js package manager, npm.
Why go to all this trouble writing tests? Surely this program is small enough that it doesn’t need any tests. You’re familiar with the phrase, “famous last words”? If you don’t have any tests, then there’s a very good chance that one day you’ll become unglued. It’s quite possible that when you do become unglued, you will do some heroics and save the day all by yourself. Or perhaps by sheer brilliance or determination you don’t need the tests. The tests are boring—until one day they fail. Then they’re priceless.
The next chapter is about creating user interfaces for web browsers: what the rules are, when to break them, and how the strengths of CoffeeScript can help with some of the challenges unique to user interfaces.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.