F# Deep Dives (2015)
Part 3. Developing complete systems
Chapter 10. Building social web applications
Yan Cui
Social media has seen a meteoric rise in the last couple of years and has drastically changed the way we use the web and how we communicate with one another. Riding this tide of change in the technology landscape is a whole new genre of gaming—social gaming—which has managed to break down the age and gender barriers that existed with traditional PC and console-based games. Many a social game counts its user base in the hundreds of millions; and such games are monetized at such a level that the traditional giants in the game industry have no choice but to sit up and take notice.[1]
1 As evident by the expensive acquisitions of Playfish and PopCap by Electronic Arts.
A primer on social gaming
Zynga’s FarmVille reached 1 million users in its first week, much to the surprise of its developers, and at its peak FarmVille had over 50 million daily unique users (daily active users [DAUs], a common way to measure the popularity of social games). There have been many similar success stories in this space, and as of this writing the top 10 games according to AppData (www.appdata.com) all have at least 20 million DAUs. Of course, not every game succeeds—some are even scrapped soon after going live—but let’s focus on the positives!
Scalability challenges go hand in hand with operating a successful social game. Having many players playing your game means there are many concurrent requests to deal with. Each action the player takes in the game is likely to alter their game state in one way or another, so there’s probably a 1:1 read-to-write ratio for game-state data. It’s not uncommon for a game to perform tens or hundreds of thousands of read and write operations against the database per second.
To gain insights into what the players are doing in the game and drive features and promotions to better retain existing players and attract new ones, you need to be able to record a vast amount of data related to players’ activities in the game, and analyze that data in as close to real time as possible. Zynga, for instance, generates tens of terabytes of analytical data every day!
For reasons such as these, cloud computing and NoSQL databases are particularly popular among social game operators. Later in this chapter, you’ll learn how they can help you create a highly distributed and scalable solution for your game.
In this chapter, you’ll design and implement a simple farming game in F#, called SharpVille. Although the solution will be far from complete, it will serve to outline the basic structure of a simple client-server setup that you can easily extend to add more features or adapt to create your own game (see figure 1).
Figure 1. The plan for the chapter. You first decide what features you’d like in the game and design a basic, functional UI (figure 2, in the next section). You’ll explore the client-server interaction required for the game and implement the contracts, server, and client components in turn. Finally, you’ll put together the various components for a working demo.
Designing a social game
Let’s start by defining the scope of the game, mocking up the UI, and defining the interaction between the client application and the server.
Features
Here’s a list of the basic features for the game:
· You (the player) have a farm to tend to.
· You have a set number of plots to plant seeds in. You can harvest for a profit after a set amount of time.
· Different seeds cost different amounts to buy and yield different profits.
· Different seeds take a different amount of time to yield profit.
· You can visit friends’ farms and help them.
· As you plant seeds and harvest, you also gain experience points (EXP).
· You level up as a farmer as you collect EXP.
· As you level up, you unlock more types of seeds you can plant.
· To drive healthy competition, there will be a leaderboard with you and your friends, sorted by EXP.
Based on this feature list, it’s easy to derive the data you need to track the player’s game state: EXP, level, gold balance, as well as what the player has planted and where.
The UI
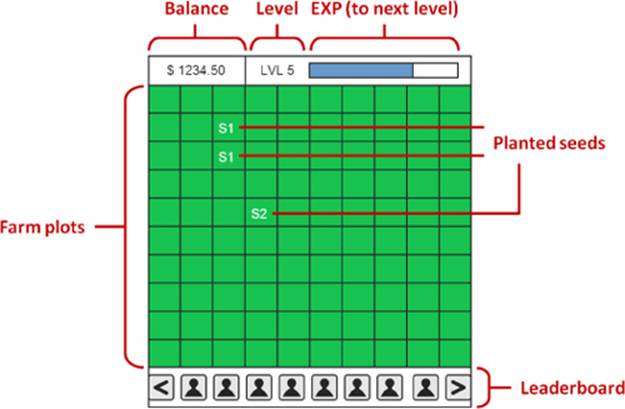
The UI should display the gameplay elements just described. Something simple but functional like figure 2 will do for the purpose of the demo.
Figure 2. A rough idea of how the UI should look. The farm plot area is a 10 × 10 grid where each cell represents a plot in which the player is able to plant seeds. S1 and S2 are the IDs of the seeds that have been planted in those cells.
Client-server interaction
In order for the game to work, the client needs to be able to communicate with the server to accomplish the following:
· Identify and authenticate the player
· Retrieve information related to the player’s current game state from the server at startup, and retrieve updates to stay in sync thereafter
· Inform the server that the player wishes to perform an action, so the server is able to
o Validate the action
o Update the player’s state if the action is valid
o Return incremental updates to the player state after each action
Table 1 shows the operations you need to support on the server, along with the information that needs to change hands.
Table 1. The operations the server should support, and the data that should be passed in via the request and returned via the response
|
Operation |
Input |
Output |
|
Handshake |
Player ID and hash |
Current EXP, level, gold balance, positions where seeds were planted, and the session ID to be used from here on |
|
GetLeaderboard |
Session ID and player IDs of the player’s friends |
Leaderboard profiles |
|
Plant |
Session ID, grid position, and seed ID |
New EXP, level, gold balance, and positions where seeds were planted |
|
Harvest |
Session ID and grid position |
New EXP, level, gold balance, and positions where seeds were planted |
|
Visit |
Session ID and friend’s player ID |
Grid positions where seeds were planted and the number of fertilizers left |
|
Fertilize |
Session ID, friend’s player ID, and grid position of where to fertilize |
The number of fertilizers left |
With these things in mind, you can now establish the contract between the server and client.
Thick server and thin server
The approach we’re taking here means the server is doing most of the heavy lifting, such as enforcing the rules of the game, applying the game logic with each request, and updating the game state accordingly. This isn’t to say that you shouldn’t do any validation on the client and allow invalid requests to make their way to the server and fail there (for example, a request to harvest a crop that’s not yet ready). Instead, you should enforce some of the game rules on the client and not allow invalid requests to be made against the server based on the knowledge you have of the player’s current game state on the client.
If the game state on the client is out of date (for instance, if the player is playing on multiple devices), then the server’s validation will serve as the last line of defense against invalid requests. For example, if players have spent all their gold planting seeds while playing on their iPad, the server validation will stop them from being able to plant additional seeds by switching to the web version where their local state on the client is out of date and still carries enough of a balance to plant additional seeds.
This approach has the benefit of making the game difficult to cheat. Because the rules are enforced by the server—which you control, at the cost of more work performed on the server—more servers are required to deal with a given number of concurrent players. Depending on how much code you’re able to share between client platforms, or how intensive the rendering task is on the client, sometimes it can also be advantageous to implement the bulk of the game logic on the server[2] for those reasons.
2 For instance, the Xbox One hit Titanfall uses a Microsoft Azure-hosted server solution to run all the battle simulation and enemy artificial intelligence, leaving the client to focus on rendering the intense combat scenes. As another example, the creator of EVE Online has used Amazon AppStream to stream the character creator from the server in order to get players through the door and invested in the game quickly without having to wait for a sizable download before they can even see the game.
THIN SERVER
Alternatively, you can do the heavy lifting on the client and let the server act as little more than custodian for the player’s game state. The client is responsible for making sure game rules aren’t broken and for manipulating and managing the game state, which must be updated on the server at some point by doing either of the following:
· Replacing the player’s current state with the latest snapshot on the client as a whole
· Aggregating all incremental changes on the client and applying the same changes on the latest state the server knows about
With this approach, the load on the server is minimal, but there’s also a huge opportunity for savvier players to cheat the game by capturing and modifying requests to the server using HTTP proxy tools (hence bypassing any client-side validation you have in place) or creating simple programs to mimic the real client application and submitting invalid changes to the game state.
More care is also required to deal with the case when the player is playing the game on multiple devices simultaneously and the resulting version conflicts that can occur as far as game state changes are concerned.
THICK VS. THIN SERVER
Given these two approaches, you might think it’s an obvious choice to go with the thick server approach (or something close to it), but it’s easy to underestimate the cost and performance implications of such decisions when you’ve successfully amassed a sizable user base in the tens of millions! It’s for these reasons that some of the biggest games on Facebook are doing much of the work on the client and have a thin server layer.
Ultimately it’s a decision you’ll likely make on a game-by-game basis depending on the particular needs of that game. Also, you’re not limited to these two approaches—there’s plenty of middle ground, and you have the opportunity for mix-and-matching depending on the actions you’re performing in the game.
Prerequisites
Before you start writing code, let’s make sure you have everything required to get this demo application up and running. Here’s a short list of the things you’ll need:
· Visual Studio 2012 or above
· F# XAML item templates (http://mng.bz/sR00)
Great! Now you’re ready to start implementing the awesome game, SharpVille!
Implementing the contracts
First, let’s create a new F# Library project for the contracts the client and server will share, including various types to represent the player’s state as well as the request/response types. Let’s call this project SharpVille.Contracts. This is a convenient time to create the solution too; name it SharpVille.
The model
Once you’ve created the project, delete the Library1.fs and Script.fsx files that are created by default. Then, right-click the project in the Solution Explorer to add a new F# source file called Model.fs (shown in the following listing).
Listing 1. Representing the model objects
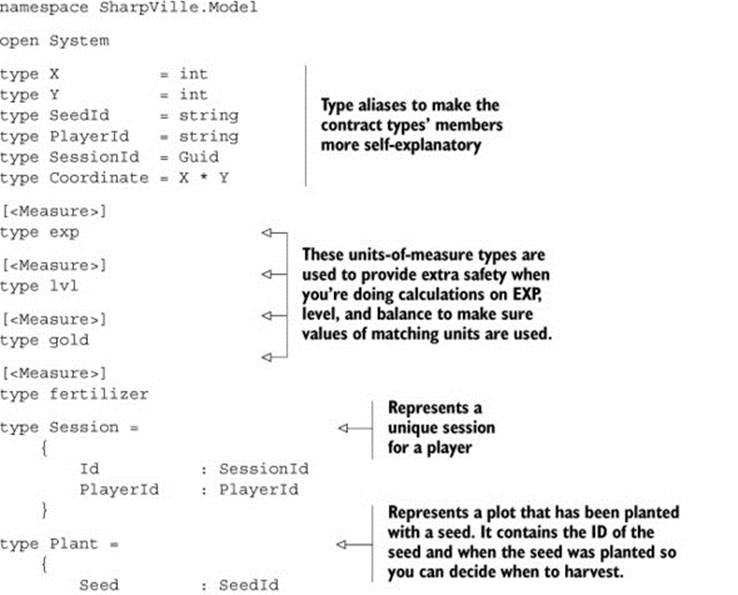

The SharpVille.Model namespace contains the domain objects for the game, including all the data you need in order to track a player’s progress in the game. Notice that all the types defined in this namespace contain data only and no behavior or logic. Any client- or server-specific logic will be implemented in the respective projects to prevent them from leaking through the abstraction layers via a shared assembly.
The GameSpecification type encapsulates the aspects of the game that are configurable, such as the seeds and levels. It allows the game to be data-driven and gives you the ability to tweak the game-play experience without making any code changes (which usually require more significant testing time) and the potential to run A/B testing[3] at a later date.
3 See “A/B Testing,” Wikipedia, http://en.wikipedia.org/wiki/A/B_testing.
Requests and response objects
For this demo application, you’ll follow the request-response pattern. For each of the server operations you’re going to support (shown earlier in table 1), you’ll create a matching pair of request and response types. Begin by adding a new F# source file, Requests.fs (shown in the next listing) just below Model.fs.
Listing 2. Request objects
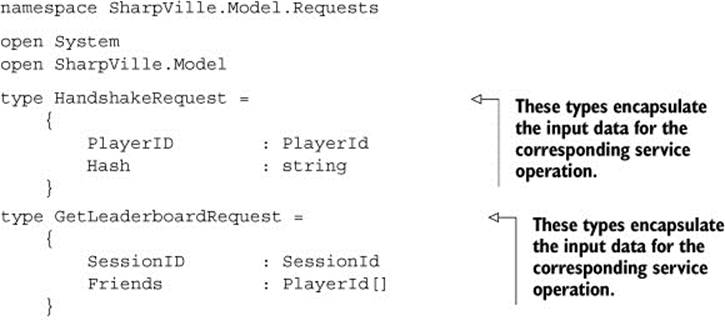
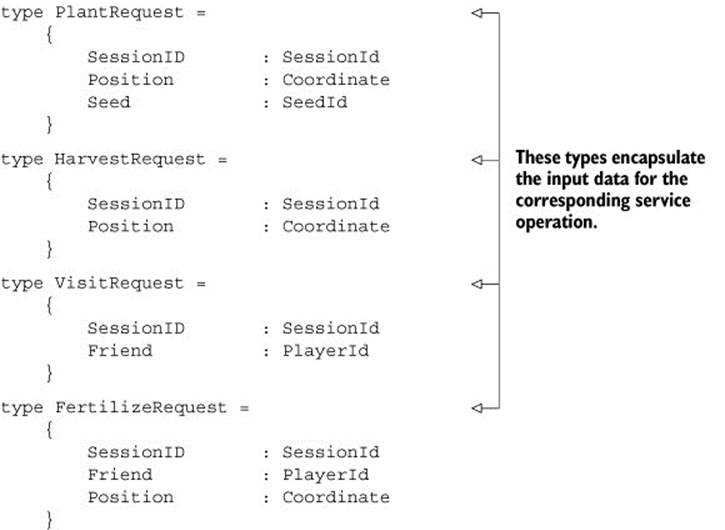
The code in listing 2 is pretty straightforward. You take the input information for each of the operations in table 1 and create a request type to encapsulate it.
Let’s do the same thing again and create the matching response types. Add a new F# source file, Responses.fs, just below Requests.fs.
Listing 3. Response objects

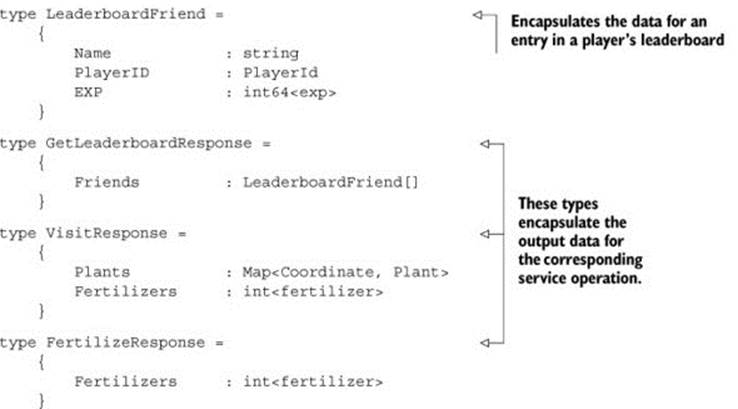
One of the things you may notice in listing 3 is that some of the response types are defined as record types, whereas others are defined as class types (although immutable). This is because HandshakeResponse, PlantResponse, and HarvestResponse are all identical (at least for now), so having them all inherit from the same base class means
· You don’t have to keep repeating yourself (DRY!).
· You can consolidate the response-handling code on the client to work directly against the base class.
You may wonder why you wouldn’t just return the same response type from the three different service methods, instead. The answer is future extensibility. If you choose to return the same response type from the three methods, it restricts your ability to modify the response (add a new property, perhaps) from each of the methods in isolation without introducing breaking API changes.
Being able to keep a consistent, backward-compatible API is important because it means you’re more likely to be able to release incremental changes to the server code without having to do a synchronized update to the client code. This type of synchronized updates usually means downtime, and downtime is extremely expensive, especially in this highly competitive business—players you lose during downtime might never come back.
Also, when your service starts to support both web and mobile clients, the ability to do incremental updates becomes increasingly important. You’ll soon discover that updating mobile clients can be a tricky business (as anyone who has had to deal with the Apple App Store would no doubt tell you!).
The request-response pattern
The request-response pattern is all over the web, and for good reasons. As time goes by, and your application evolves, the lists of parameters to your service methods are likely to grow, and you may even need to introduce overloads to provide more variety and support optional parameters. These types of API changes have a significant blast radius in terms of the number of code files you need to touch, and they also impact the backward compatibility of your service.
By wrapping the input and output values into request and response objects, you can do the following:
· Add input/output values incrementally
· Maintain a consistent, backward-compatible public API
· Solve the problem of growing parameters
· Have an easy way to provide multiple results
Implementing the server
We’re rather spoiled for choice when it comes to what technology to use to implement the server. For the purpose of demonstrating the versatility of F#, I’ll show you a simple HTTP server using F#’s asynchronous workflows.[4] You’ll use JSON as the wire format for the request and response objects because it’s human readable, which is helpful when it comes to debugging.
4 See “Asynchronous Workflows,” Microsoft Developer Network, http://mng.bz/y66m.
Embracing the cloud
More and more companies are moving their infrastructures to the cloud each day, and the trend is likely to continue for the foreseeable future. An in-depth discussion of the merits of cloud computing is beyond the scope of this chapter, but I’d like to outline some common reasons why so many companies have decided to make the move.
TRADING CAPITAL EXPENSE FOR VARIABLE EXPENSE
Although there are many eye-catching success stories in our industry, many games fall by the wayside.[5] In general, the industry is a highly competitive place where success has as much to do with luck as quality, and even the most successful titles can’t guarantee a sustained long-term future.[6]
5 Such as Tiny Speck’s experimental social game, Glitch, which despite being well executed and having a highly engaged player base, closed down only two months after its official launch; see “Glitch (Video Game)”, Wikipedia, http://en.wikipedia.org/wiki/Glitch_(video_game).
6 Zynga’s Empires & Allies, once the most popular social game on Facebook with over 100 million monthly active users, closed down less than 2 years after its initial launch, in June 2013. See “Empires & Allies,” Wikipedia, http://en.wikipedia.org/wiki/Empires_&_Allies.
In such a competitive market, being able to experiment and take risks is a massive business advantage and differentiator. The pay-as-you-go pricing model offered by cloud providers such as Amazon Web Services (AWS) allows you to take more risks and innovate as the cost of failure falls dramatically.
ELASTIC SCALABILITY
The amount of server capacity required for a game is as unpredictable as its chance of becoming a success, and even the best attempts to guess actual demand are likely to result in either wastage through overprovision or a bad user experience through underprovision. Unless your user base is well balanced geographically, you might even end up with a mixture of the two in a single day if your user base is highly concentrated around one time zone.
With AWS and most other cloud providers, you can scale elastically based on actual demand. This removes the need for guesswork and gives you an easy way to provision only what you need, when you need it.
INCREASED SPEED AND AGILITY
In the traditional self-hosted environment, acquiring and setting up a large number of servers to meet growing demands is a time-consuming process, not to mention the expertise and resources required to maintain a growing fleet of hardware on an ongoing basis.
In a cloud-hosted environment, you can go from having 1 to 1,000 servers in seconds with a few button clicks. Maintaining the infrastructure is the responsibility of the cloud provider and is not a distraction and expense for you. When you no longer require those capacities, it’s just as easy to scale down your infrastructure and stop paying for servers.
Because your developers don’t have to worry about the provisioning of the underlying infrastructure, they can better focus on the things that are important to you and your business. In return, you’ll reap the rewards of improved developer efficiency.
RELIABILITY
Because operating large data centers is a core part of the business for cloud providers, you can be sure they’re able and willing to hire the best engineers money can buy. Consequently, they’re likely able to provide a more reliable and efficient infrastructure for you than you can provide yourself.
There have been several high-profile outages by AWS, which generated much public criticism and doubt about the public cloud in general. One aspect of these outages that many overlooked was the speed of recovery and the extremely low frequency at which outages of such scale occur. They’re high-impact, infrequent events that don’t truly reflect the level of service and reliability provided by the likes of AWS.
FOCUSING ON WHAT’S IMPORTANT
It’s a huge advantage not to have to worry about managing the heavy lifting required to run a data center: buying and installing new hardware, setting up networks, negotiating with bandwidth providers, and so forth. These tasks aren’t difficult to do on their own, but doing them at scale, and doing them well, is challenging.
We all know that good software engineers are hard to come by, so you shouldn’t waste your scarce engineering resources on infrastructure, which is by all means important but hardly ever differentiates your business in any meaningful way. By leaving the infrastructure to cloud providers that specialize in it, you allow your engineers to focus on things that truly differentiate your business.
GOING GLOBAL INSTANTLY
It wasn’t long ago when the cost of deploying applications to a global audience was prohibitive to all but established enterprises. Nowadays, even small startups can use the cloud to deploy their applications to a global audience. AWS, for instance, lets you deploy infrastructure in data centers around the globe and provides edge locations that let you quickly and efficiently deliver content to your customers in all corners of the world via its content-delivery network.
Common utility functions
Before you start implementing the server-side logic, you’ll add a new F# Library project to your solution and call it SharpVille.Common. You’ll put any shared utility functions and modules in this project. Once again, delete the default files and add a new F# source file called Utils.fs (see the following listing), where you’ll create two helper functions for reading and writing JSON data.
Listing 4. Helper functions for reading and writing JSON
namespace SharpVille.Common
open System.Text
[<AutoOpen>]
module Utils =
open System.IO
open System.Runtime.Serialization.Json
let readJson<'a> (stream : Stream) =
let serializer = new DataContractJsonSerializer(typedefof<'a>)
serializer.ReadObject(stream) :?> 'a
let writeJson (obj : 'a) (stream : Stream) =
let serializer = new DataContractJsonSerializer(typedefof<'a>)
serializer.WriteObject(stream, obj) |> ignore
In listing 4 you’re using the BCL’s built-in DataContractJsonSerializer (http://mng.bz/7nc8) because it works well[7] with F#’s types, so you don’t need to have third-party dependencies for the demo. Also available are a number of open source JSON serializers, including Json.Net(http://json.net) and ServiceStack.Text (https://github.com/ServiceStack/ServiceStack.Text), both of which offer a richer set of features and better performance for working with JSON from .NET.
7 See Yan Cui, “F# – Serializing F# Record and Discriminated Union Types,” theburningmonk.com, http://mng.bz/Oz10.
When you’re done, add another F# Library project and call it SharpVille.Server. This is where you’ll implement the server-side logic for the game.
Beware of serialization costs
For high-concurrency web applications, the cost of serialization and deserialization can be nontrivial and consume a significant portion of your CPU cycles as well as bandwidth, which ultimately translates to higher operational cost. For these reasons, the folks at Google created a fast and compact wire format called protocol buffers (https://developers.google.com/protocol-buffers) which, based on my benchmark[8] on a simple Plain Old CLR Object (POCO), is several times more efficient than the BCL’s BinaryFormatter.
8 Yan Cui, “Benchmarks,” http://theburningmonk.com/benchmarks.
In the specific context of building a backend for a social game, if you go down the stateless server route, it means for each call you also need to retrieve the player’s current game state from a database, update it, and save the change back to the database. This pair of read-write activities also requires serialization and deserialization and can be even more expensive, depending on the size of the game state.
From experience, I’ve found in some of my games that the cost of serialization and deserialization accounts for up to 90% of CPU cycles used. Moving to a more efficient serializer such as protocol buffers reduced the number of servers required by up to half.
Do your own benchmarks
Although there are many publicly available benchmarks on the relative performance of various serializers and serialization formats, none will be as representative of your payload as one that runs against the real data you’ll be working with. As a rule of thumb, run your own benchmarks against the actual data you’ll be working with whenever possible.
The data access layer
You must take many considerations into account when deciding what persistence technology to use for the various types of data you need to store for the game. With the ever-increasing popularity and maturity of NoSQL solutions, you have plenty of options available.
For the purpose of this demo, you won’t tie the implementation to any specific database. You’ll instead use a simple in-memory dictionary to store the player state and session data. Implementing the IStateRepository and ISessionStore interfaces with a key-value store such as Memcached or Redis is a trivial exercise.
For now, add a new F# source file in the SharpVille.Server project and call it DAL.fs (see listing 5). You’ll define the interfaces to abstract over your data access layers here and add two simple implementations using in-memory dictionaries.
Listing 5. Implementing the data access layer
module SharpVille.Server.DAL
open System
open System.Collections.Generic
open SharpVille.Model
type IStateRepository =
abstract member Get : PlayerId -> State option
abstract member Put : State -> unit
type ISessionStore =
abstract member Get : SessionId -> Session option
abstract member Put : Session -> unit
type InMemoryStateRepo () =
let states = new Dictionary<PlayerId, State>()
interface IStateRepository with
member this.Get(playerId) =
match states.TryGetValue playerId with
| true, x -> Some x
| _ -> None
member this.Put(state) = states.[state.PlayerId] <- state
type InMemorySessionStore () =
let sessions = new Dictionary<SessionId, Session>()
interface ISessionStore with
member this.Get(sessionId) =
match sessions.TryGetValue sessionId with
| true, x -> Some x
| _ -> None
member this.Put(session) = sessions.[session.Id] <- session
Exercise 1
A key-value store such as Memcached, Redis, Couchbase, or MongoDB would be a great fit for the simple get/put operations required for the IStateRepository and ISessionStore interfaces. Try implementing these two interfaces using the API of a key-value store of your choice.
NoSQL in social games
By now I assume you’ve heard the hype about NoSQL databases. Rather than a single technology, Not Only SQL (NoSQL) is better described as a movement away from the traditional relational model and the one-size-fits-all approach that’s often applied with relational databases.
What many came to realize was that although the relational approach to modeling data is capable of solving most problems, some data, such as the social graphs used by the likes of Facebook and Twitter, doesn’t translate naturally to the relational model. Moreover, for these types of data, the relational model doesn’t allow for an efficient way to answer the kind of typical questions that you’d want to ask, such as what common interests you share with your friends. This is one area where the graph database, a category of NoSQL databases, really shines;[9] you’ll learn more about this later in this chapter.
9 For a more in-depth look at how graph databases can help you work efficiently with highly connected data, see Ian Robinson’s talk “Tackling Complex Data with Neo4j,” InfoQ, http://mng.bz/BHSx.
The ACID[10] (Atomicity, Consistency, Isolation, Durability) guarantees provided by modern relational databases are powerful, but you don’t often need all those guarantees, which come at a cost of performance and scalability. Many NoSQL databases allow you to trade the ACID guarantees for horizontal scalability and speed.
10 See “ACID,” Wikipedia, http://en.wikipedia.org/wiki/ACID.
KEY-VALUE STORES
For many social games, such as SharpVille, the majority of the database interactions involve a key lookup into a hash to fetch a player’s game state, which is by far the most important use case. Even a modestly successful social game has to deal with a sizable number of concurrent players, often performing hundreds of thousands of database operations per second with a likely 1:1 read-to-write ratio. The most important criteria for the database are the following:
· The ability to handle a large number of concurrent transactions
· The ability to scale horizontally to maintain a linear relationship between cost and scale
· Low-latency access to data
Key-value stores such as Couchbase (www.couchbase.com), Riak (http://basho.com/riak), and Amazon DynamoDB (http://aws.amazon.com/dynamodb) are great matches for these criteria. They essentially store your data in a huge distributed hash table while providing mechanisms to seamlessly replicate the data behind the scenes, to provide greater availability and fault tolerance against network partitions and hardware failures.
Many of these databases (such as Couchbase and Redis [http://redis.io]) use a memory-first storage model to provide ultra-low-latency access to data (usually in the 2–4 ms range) while giving you the option to persist data to disk for durability as well. Document stores such as MongoDB (www.mongodb.org) and RavenDB (http://ravendb.net) that store data in self-contained documents are also popular choices for player states.
COLUMN DATABASES
Column databases are also referred to as Bigtable clones because they’re inspired by Google’s 2006 paper on Bigtable,[11] a proprietary technology that’s today powering many of the data-storage services provided by Google’s cloud offerings. Databases in this category, such as popular open source solutions Cassandra (http://cassandra.apache.org) and HBase (http://hbase.apache.org), store data in columns rather than rows, typically scale well with size, and are most used in data warehousing and analytics applications.
11 Fay Chang, Jeffrey Dean, et al. (Google, Inc.), “Bigtable: A Distributed Storage System for Structured Data,” Seventh Symposium on Operating System Design and Implementation, November, 2006, http://bit.ly/1hGHDX9.
As far as commercial solutions go, Vertica (www.vertica.com) has been the preferred solution among the big social game operators[12] to provide a platform for analyzing their large amounts of in-game events so they can understand the performance of their games and drive features and changes forward. Zynga, for instance, operates one of the largest data warehouses in the world and generates over 15 TB of new data every day from its estimated 60 million daily active users.
12 Vertica Social Gaming Panel, San Francisco, CA, April 26, 2011 (video), http://mng.bz/1K81.
GRAPH DATABASE
Graph databases are unique in the sense that they’re based on graph theory and store data using nodes and edges instead of rows and columns. The nodes represent the entities stored in the database, and the edges the relationship between the nodes. Both nodes and edges can be associated with an arbitrary set of properties, and edges can be one way or bidirectional.
Graph databases allow you to query data by traversing the graph. They’re great for building social features. My employer, Gamesys (www.gamesyscorporate.com), for instance, uses Neo4j (www.neo4j.org), a popular open source graph database (which is also fully ACID compliant), to power high-value social features in our cash gaming business. In our MMORPG title Here Be Monsters, we’re also using Neo4j to help us automate the process of balancing the in-game economy.[13]
13 Yan Cui, “Modelling a Large Scale Social Game with Neo4j,” Skills Matter, April 30, 2014 (video), http://mng.bz/9OLl.
POLYGLOT PERSISTENCE
A complex application often has to deal with many types of data and may have different requirements for that data. Different databases are designed to solve different problems, which is especially true in the case of NoSQL databases. Using the same database for all your data needs usually leads to nonperformant solutions.
Increasingly, companies are realizing this and have opted for a polyglot approach by using multiple database systems that are chosen based on how the data is being used. For instance, using polyglot persistence you might end up
· Using an in-memory key-value store for session and other transient data
· Using a key-value or document store for player state
· Using a column database for analytics data and business intelligence (BI) applications
· Using a graph database to store data for social features
· Using an RDBMS to store financial and other data that requires transactional support
You face a number of challenges with polyglot persistence, including the following:
· You need to decide which database system to use for each type of data and application.
· Many NoSQL databases are still young and have rough edges.
· You may lack experience with and knowledge of operating NoSQL databases.
· You need to deal with consistency with some NoSQL databases.
· You have to work with many different APIs.
The game engine
Now that we’ve got some of the plumbing out of the way, let’s move on to the server-side game engine. This is where you’ll put all the game logic as well as validation to enforce the game rules.
In the SharpVille.Server project, add another F# source file called GameEngine.fs below DAL.fs (see listing 6). For the purpose of the demo, you’ll only implement the Handshake, Plant, and Harvest calls, to demonstrate how these features would work end to end; but by the time you finish this chapter, you should be able to easily extend the existing implementation to support additional features.
Listing 6. Defining the game engine interface
module SharpVille.Server.GameEngine
open System
open SharpVille.Model
open SharpVille.Model.Requests
open SharpVille.Model.Responses
open SharpVille.Server.DAL
type IGameEngine =
abstract member Handshake : HandshakeRequest -> HandshakeResponse
abstract member Plant : PlantRequest -> PlantResponse
abstract member Harvest : HarvestRequest -> HarvestResponse
This listing uses matching request/response types for each operation. If you need to modify the input/output parameters for one of the operations in the future, you should be able to modify just the corresponding request or response type without impacting others.
Now, in the same GameEngine.fs file, you can begin implementing the IGame-Engine interface one step at a time, starting with a skeleton (see listing 7). The game engine will need to return the game specification in the HandshakeResponse, so for simplicity’s sake you’ll pass the current game specification into the game engine as a constructor parameter. In practice, though, you’ll want to be able to update the game specification (or the entire game engine if possible!) on the fly without requiring a restart, to reduce downtime.
Listing 7. implementing the IGameEngine interface
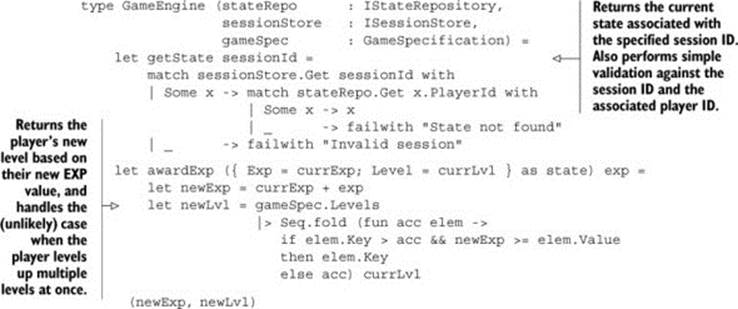
So far, you’ve added only two helper functions that will be required by pretty much every operation you support. The awardExp function takes the player’s current state (which is fetched by calling the getState function with a valid sessionId) and returns the player’s new EXP and level so you can update their state at the end of the operation.
In the following listing, you’ll implement the handler for the Handshake operation, which is responsible for creating a new session and initializing default states for new players.
Listing 8. The Handshake handler

Although the logic in the other handlers varies, they share a similar flow:
1. Fetch the current state (which also validates the request’s session ID).
2. Confirm that the request is valid given the player’s state.
3. Create a new player state.
4. Save the new state.
5. Return a response with the new state.
With this in mind, in the next listing you’ll add a method to handle the Plant operation right below the Handshake method.
Listing 9. The Plant handler

In the case of planting a seed, you need to ensure the following:
· The player has a valid session.
· The seed specified in the request is valid.
· The player is at the required level to use this seed.
· The player can afford the seed.
· The player is not trying to plant on a farm plot that’s already occupied.
If all the validations pass, you can proceed to charge the player for the seed and plant it in the requested farm plot. Note that you need to remember when the seed is planted, so that you can do the following:
· When the player resumes play (for example, after restarting the game), show them how much time is left before they can harvest the seed.
· When the player attempts to harvest the seed, validate that the required amount of time has passed since the seed was planted.
The player is rewarded with a small amount of EXP based on the seed they’ve planted and can potentially level up as a result. Fortunately, the aforementioned awardExp function takes care of all the heavy lifting here, so you just need to use the returned values to create an updated state for the player.
Similarly, the following listing adds another method to handle the Harvest operation right below the Plant method.
Listing 10. The Harvest handler

To harvest a previously planted seed, you need to validate the following:
· The player has a valid session.
· The farm plot that the player is trying to harvest isn’t empty.
· The seed is fully grown and ready to be harvested.
Note that you don’t validate the seed ID in this case. This is because in order for the seed ID to be in the player state, you must have validated against it when the player tried to plant the seed initially, so there’s no need to do the same work twice.
Exercise 2
You probably noticed that although the validation rules are different for the Plant and Harvest methods, there’s a fair amount of duplicated code in these two methods. As an exercise, try refactoring the common code out into a higher-order function that does the following in two functions:
· Performs the validation
· Creates a new player state based on the current state
Then rewrite the Plant and Harvest methods to make use of these new functions.
Stateless vs. stateful server
The approach you’re taking with SharpVille is a stateless approach where the game servers don’t hold any player states. That way, upon each request, the server needs to retrieve the player’s state from the database, modify it, and save the changes back to the database.
On the other hand, with a stateful approach, the game servers hold onto the player’s state for some period of time, commonly the duration of one game session.
The stateless approach has the advantage of allowing your cluster of game servers to be easily scaled up and down using AWS’s Auto Scaling service (http://aws.amazon.com/autoscaling), for instance, because they don’t hold any states. This approach has several drawbacks:
· A heavy load is placed against the database, because every request requires two database operations.
· Serialization and deserialization of the user state are heavy on the CPU.
· High latency results from the database operations.
· Bandwidth usage is high.
· You have to run more game servers and database nodes, which means higher operational costs.
By comparison, the stateful approach addresses these inefficiencies but in turn creates a number of complexities of its own. You must do the following:
· Ensure that the player always talks to the same server that holds their state.
· Avoid hot spots by balancing the load; you can no longer rely on the load-balancer alone.
· Avoid players hogging a server, so the server can be terminated when scaling down the cluster of game servers.
· Ensure that all state changes are persisted before the server can be terminated.
Which approach should you choose? That again is a decision you need to make on a game-by-game basis. Generally I find the simplicity offered by the stateless model most attractive; but for certain games, such as our MMORPG title Here Be Monsters (https://apps.facebook.com/herebemonsters), the player state is big and will continue to grow as more contents are introduced into the game. Thus the cost of the stateless approach becomes infeasible.
For Here Be Monsters, when we moved to the stateful server approach, we observed a 500% improvement in efficiency (that is, the same server can handle five times the number of concurrent requests) as well as a 60% reduction in average latency. With fewer game servers and database nodes to manage, it also eases day-to-day monitoring and maintenance of our production environment.
The HTTP server
To tie everything together for the server implementation, add another F# source file called HttpServer.fs just below GameEngine.fs.
Listing 11. HttpServer.fs
module SharpVille.Server.Http
open System
open System.IO
open System.Net
open SharpVille.Common.Utils
open SharpVille.Model
open SharpVille.Server.DAL
open SharpVille.Server.GameEngine
let inline handleReq (f : 'req -> 'resp) =
(fun (req : HttpListenerRequest) (resp : HttpListenerResponse) ->
async {
let inputStream = req.InputStream
let request = inputStream |> readJson<'req>
try
let response = f request
writeJson response resp.OutputStream
resp.OutputStream.Close()
with
| _ -> resp.StatusCode <- 500
resp.Close()
})
Listing 11 contains a helper function, handleReq, that encapsulates the common plumbing code required for handling a web request:
1. Read the input stream as JSON.
2. Dispatch the request object to the specified handler function.
3. Write the response object as JSON to the output stream.
4. Handle exceptions.
For the JSON serialization, it uses the readJson and writeJson functions created earlier in listing 4. It uses an async workflow to perform these operations asynchronously.
Next, let’s create a simple HttpListener (http://mng.bz/Y9a6) for each service endpoint to listen for incoming HTTP requests, handle the plumbing, and route the request to the corresponding method on the game engine. Just below the handleReq function, add the followingHttpListener extension method and the startServer function.
Listing 12. Implementing the HttpListener

The startServer function configures the routing for all the service endpoints, using an implementation of the IGameEngine interface. If you need to add new service endpoints to support new features in the future, you can amend this function to add the new routing.
Exercise 3
One feature of SharpVille is the ability to visit a friend’s farm. Now that the basic structure of the server implementation is in place, your task is to extend the game engine and the HTTP server to add support for this feature by adding a new Visit method to the game engine, which handles all calls to the HTTP endpoint http://*:80/SharpVille/Visit/.
Implementing the client
Next, you’ll add a project for the WPF client, using the project type F# Empty Windows Application (WPF). You should have access to this if you’ve followed along and installed the F# XAML Item Templates extension. Call this new project SharpVille .Client.WPF.
The XAML
The newly created project will have the basic skeleton for your simple WPF client. Open and modify the MainWindow.xaml file as shown next.
Listing 13. Implementing the UI in XAML


Listing 13 creates a simple UI in XAML, based on the original mockup (shown earlier in figure 2). There are two things to note from this XAML.
First, you bind the Content of some labels to the Balance and Level properties of a yet-to-be-defined data type, which you’ll use as the DataContext for this piece of the UI. This way, whenever the local player state is updated by the response from the server, the UI will automatically be updated to show the player’s latest balance and level.
Second, you have two Rectangle objects—NextLevel and Exp—where the Exp rectangle is placed on top of the NextLevel rectangle but is invisible initially because its Width is set to 0. As you adjust the Width of the Exp rectangle based on the player’s EXP and its relative distance to the next level, you can create a progress bar. The UI generated by the XAML code should resemble figure 3.
Figure 3. This is how the UI should look once you’ve finished updating MainWindow.xaml.

Representing the game state
Now that the basic UI is in place, you’ll create a type to use as its DataContext. As mentioned earlier, the player state defined in the model doesn’t define any behavior, and any server- or client-specific behavior will be implemented in the relevant projects.
For the client application, you want the player state to support data binding to make it easy for you to update the UI when the server responds with an updated state. In addition, other data is associated with the current state of the game but isn’t part of the player state, such as the current session and game specification, which the client application requires to function and communicate with the server.
So, add an F# source file called GameState.fs (listing 14) to the top of the project. This file will contain all the data you need to represent the current state of the game from the client’s perspective, including all the data you require to represent the player’s state.
Listing 14. Representing the game state for the client


In order to use this GameState type as the DataContext for the XAML UI and enable two-way binding on the Balance and Level properties, you need to implement the INotifyPropertyChanged interface (http://mng.bz/x07t). Unfortunately, this also means you can’t implement theGameState type as an F# record, and you’ll end up with something fairly verbose.
In practice, you can resort to using a library like Castle DynamicProxy, as demonstrated in chapter 7, to do the heavy lifting for you. Another alternative is to use C# here and use a weaver such as PostSharp (http://mng.bz/WbxL). But given that this is the only place where you’ve had to write verbose OO code so far, that hardly seems necessary.
Utility functions
Given the client-server nature of the game, it’s reasonable to assume that you’ll be making regular server calls from the client and, based on the response, updating the UI accordingly. To prevent your UI code from being convoluted due to server calls, you’ll create a couple of helper functions for making these calls asynchronously. Add the following new F# source file called Utils.fs right below GameState.fs.
Listing 15. Utility.fs
module Utils
open System
open System.IO
open System.Net.Http
open System.Windows.Media
open SharpVille.Common
open SharpVille.Model
open SharpVille.Model.Requests
open SharpVille.Model.Responses
open GameState
let makeWebRequest<'req, 'res> action (req : 'req) =
async {
let url = sprintf "http://localhost:80/SharpVille/%s" action
use clt = new HttpClient()
use requestStream = new MemoryStream()
writeJson req requestStream |> ignore
requestStream.Position <- 0L
let! response =
clt.PostAsync(url, new StreamContent(requestStream))
|> Async.AwaitTask
response.EnsureSuccessStatusCode() |> ignore
let! responseStream = response.Content.ReadAsStreamAsync()
|> Async.AwaitTask
return readJson<'res> responseStream
}
The makeWebRequest helper function is responsible for making the HTTP request to the server and deserializing the response into the desired type. To serialize and deserialize data to and from JSON, you’re using the readJson and writeJson utility functions you created earlier in the chapter (listing 4).
From here, you can reuse the makeWebRequest function to build operation-specific helpers to make Handshake (listing 16), Plant (listing 17), and Harvest (listing 18) requests against the server.
Listing 16. Handshake helper
let doHandshake playerId onSuccess =
async {
let req = { PlayerID = playerId; Hash = "" }
let! response = makeWebRequest<HandshakeRequest, HandshakeResponse>
"Handshake" req
do! onSuccess response
}
For the doHandshake helper function, you may have noticed that you deliberately set the Hash field in HandshakeRequest to an empty string. This is because you haven’t yet implemented any authentication logic on the server to validate against the provided Hash value.
Listing 17. Plant helper
let doPlant x y sessionId seedId onSuccess =
async {
let req = {
SessionID = sessionId
Position = (x, y)
Seed = seedId
}
let! response = makeWebRequest<PlantRequest, PlantResponse>
"Plant" req
do! onSuccess response
}
Listing 18. Harvest helper
let doHarvest x y sessionId onSuccess =
async {
let req : HarvestRequest = {
SessionID = sessionId
Position = (x, y)
}
let! response = makeWebRequest<HarvestRequest, HarvestResponse>
"Harvest" req
do! onSuccess response
}
Exercise 4: Adding support for failures
The example shown here handles only the success case, but in the real world things can go wrong at any moment—database operations can fail, the server could be terminated unexpectedly, or you could make an invalid request that fails server validation.
To ensure a smooth experience for the player, you must handle the errors gracefully. Your task is to modify the makeWebRequest function to handle error-response codes and display a message box with a user-friendly message.
The app
Finally, you’ll create the client application that will hook up all the various pieces you’ve created thus far. In the SharpVille.Client.WPF project, modify the App.fs F# source file that was created as part of the template, as follows.
Listing 19. App.fs[14]
14 https://github.com/fsprojects/FsXaml.
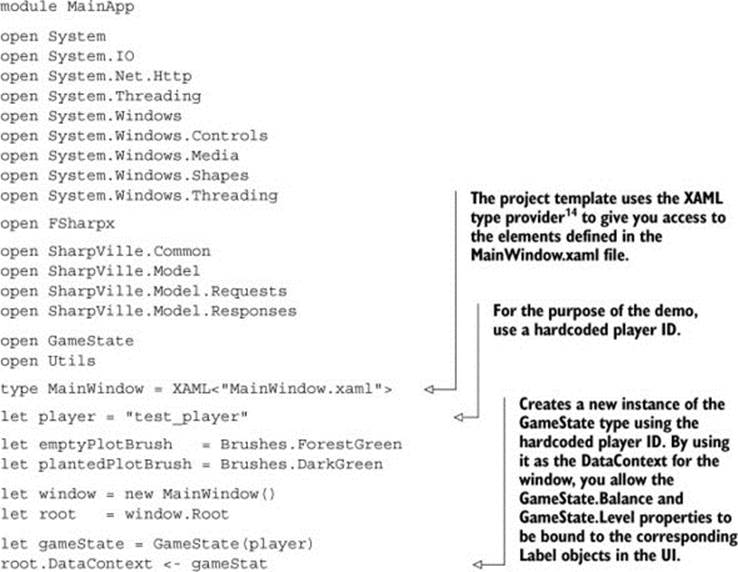
Most of the interesting operations you’ll perform from here on will involve updating the current game state based on the response from the server. Remember the State-Response base type you created earlier in the chapter (listing 3)? We decided early on that any operation that will update the player state (Plant and Harvest so far) will return a response object that derives from the StateResponse. This means you can centralize the client-side handling of state updates in one place, and whenever you receive a StateResponse you should do the following:
· Mutate the existing GameState, which will automatically update the balance and level in the UI thanks to the two-way bindings you have in place.
· Recalculate the percentage progress toward the next level, and update the EXP progress bar accordingly.
With this in mind, add the following updateState function to App.fs.
Listing 20. updateState helper

One important thing to understand about the updateState function is that it returns an async workflow that will be executed asynchronously.
Because WPF’s UI elements can be updated only from the UI thread, you need to capture the SynchronizationContext[15] when the application starts and use it to switch back to the UI thread whenever you have to execute code to update any of the UI elements. The updateStatefunction shown in listing 20 accepts the captured UI SynchronizationContext as input. It will perform its calculations on a background thread and only when ready use the Async.SwitchToContext (http://mng.bz/Jr0E) method to switch back to the UI thread to update the length of the EXP progress bar.
15 See Stephen Cleary, “It’s All About the SynchronizationContext,” MSDN Magazine, February 2011, http://mng.bz/5cDw.
In the next listing, you’ll add a couple of functions to perform the handshake, plant, and harvest operations. Because their response objects all inherit from State-Response (listing 3), your new updateState helper function will come in handy here.
Listing 21. Function that performs the handshake, plant, and harvest operations

Remember the helper functions you added to Utils.fs in listing 16? They’re doing most of the heavy lifting for you, and all you need to do here is give them continuations to call when a response has come back from the server.
Once the game has been initialized after a successful handshake, the player should be able to click anywhere on the grid to click farm plots to plant or harvest. If a farm plot is empty and the player has sufficient funds, then clicking the farm plot should create a server request to plant a seed there. Clicking a planted farm plot should create a server request to harvest the produce, if and only if the required growth time for that seed has passed.
Next you’ll add an onClick function to handle what happens when the player clicks a farm plot (each represented as a Border UI element; see figure 4).
Figure 4. The WPF application running against the server code running locally
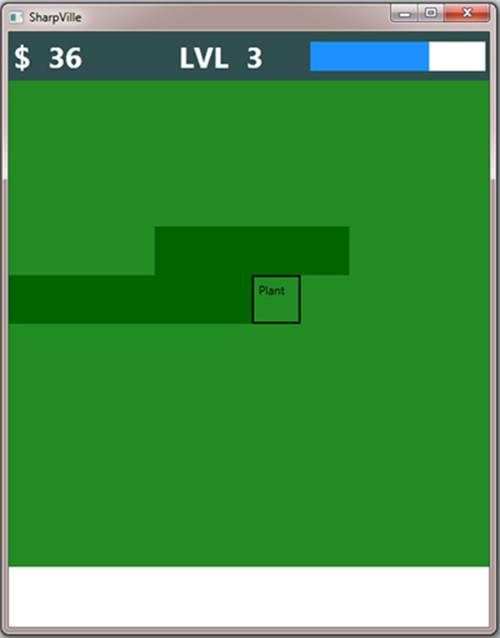
Listing 22. onClick handler

Finally, in the following listing, you add the finishing touches and initialize your WPF client.
Listing 23. Initializing the WPF application


Exercise 5
In the onClick function in listing 22, you hardcoded 30 seconds as the time it takes a planted seed to become harvestable. But the amount of time required for a seed to grow is dependent on the type of seed planted, and that information is available in the game specification.
Your task is to modify the onClick function so that it uses the seed ID associated with the Plant instance to determine the growth time for the seed by looking into the current game state’s GameSpec property. The GameSpecification type contains a Map of Seed objects keyed to their respective seed ID.
Exercise 6
In the plant function in listing 22, you hardcoded the seed ID to be S1 rather than letting players decide which seed to plant. Your task is to show a pop-up window that allows players to choose a seed from all the seeds their current level allows.
You can find all the available seeds in the current game specification. Each seed also specifies a RequiredLevel property that tells you what level players need to reach before they can use the seed.
If you’re feeling courageous, try taking it a step further and remember the player’s choice for all subsequent plant actions (so you don’t interpret the playing experience with unnecessary pop-up windows) until the sequence is broken by a different action, such as harvesting.
Putting it together
At long last, you have a working prototype for both the server and the client! To get the server component up and running, you’ll add a new F# application to the solution. Call the project SharpVille.Server.Console. You’ll use it to host your game server. Replace the default content of Program.fs so that it resembles the following listing.
Listing 24. Program.fs


Starting the console application starts the game server, which listens for requests on http://localhost:80/SharpVille/*. You can now start an instance of the WPF client to begin playing your very own SharpVille!
Summary
In this chapter, you designed and implemented a simple but nontrivial farming game that involves both client and server components. You designed the client-server interactions to enable the game features you desire, and you followed the request-response pattern for its extensibility.
This chapter focused on some of the implications of architectural decisions such as whether to store player states on the game servers or to shift the bulk of the processing onto the client. Along the way, you also explored current technology trends in the social gaming space, including the use of NoSQL databases and cloud computing and how they change the way you build large, web-scale applications.
Finally, you implemented a functional prototype of the farming game with a WPF client talking to a self-hosted game server over HTTP. Although the solution isn’t feature complete, it has the basic structures in place, and you can easily extend it to incorporate additional features.
About the author

Yan Cui is a senior server-side developer at the social gaming division of Gamesys, where he focuses on building the infrastructure as well as server-side logic for the company’s social games, which are played by nearly a million active players each day.
In his spare time, Yan enjoys researching and learning other technologies, and he’s a big fan of functional programming, cloud computing, and NoSQL databases. Yan writes a programming blog at http://theburningmonk.com. He’s also a PostSharp MVP and has been actively promoting the use of functional programming and aspect-oriented programming to developers in the United Kingdom.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.