How to Use Objects: Code and Concepts (2016)
Part I: Language Usage
Chapter 3. Abstraction and Hierarchy
The presentation so far has focused on objects and networks of objects. We![]() 1.1 have discussed how objects manage their internals and how they collaborate on larger tasks. We have also seen fundamental recurring structures and patterns one finds in practical applications. To achieve this focus on the runtime behavior, we have deliberately neglected classes and interfaces as the static, compile-time foundations of objects. When questions of inheritance did crop up in the context of method overriding, we have restricted the presentation to technical arguments. In the end, we were interested only in the result: No matter how objects were constructed, how they obtained
1.1 have discussed how objects manage their internals and how they collaborate on larger tasks. We have also seen fundamental recurring structures and patterns one finds in practical applications. To achieve this focus on the runtime behavior, we have deliberately neglected classes and interfaces as the static, compile-time foundations of objects. When questions of inheritance did crop up in the context of method overriding, we have restricted the presentation to technical arguments. In the end, we were interested only in the result: No matter how objects were constructed, how they obtained![]() 1.4.1 their methods and fields, we have asked only how they perform their tasks in the very end.
1.4.1 their methods and fields, we have asked only how they perform their tasks in the very end.
This chapter fills the remaining gap in the presentation of Java usage: How do professionals use classes, interfaces, inheritance, and subtyping to build the objects that do the work at runtime? This question adds a new dimension to objects: While previously we have looked at the final resulting objects, we now ask how the objects’ features are stacked one upon the other in their different superclasses of a hierarchy, and how the behavior of objects is classified by interfaces.
3.1 Inheritance
Many people consider inheritance the distinguishing feature of an object-oriented language, and the one on which a large part of the flexibility and reusability of objects rests. We have already seen a great deal of its![]() 1.4 mechanics in connection with method overriding. Now it is time to discuss the conceptual basis of inheritance itself. The challenge here lies in the very power of the mechanism, and in the creativity it inspires: Method overriding allows you to reuse code in intricate and sophisticated manners, but when applied without discipline, it becomes a maintenance nightmare, since later developers will have to untangle the web of calls between subclasses and superclasses. The goal must therefore be to find guidelines for a safe and predictable usage of inheritance.
1.4 mechanics in connection with method overriding. Now it is time to discuss the conceptual basis of inheritance itself. The challenge here lies in the very power of the mechanism, and in the creativity it inspires: Method overriding allows you to reuse code in intricate and sophisticated manners, but when applied without discipline, it becomes a maintenance nightmare, since later developers will have to untangle the web of calls between subclasses and superclasses. The goal must therefore be to find guidelines for a safe and predictable usage of inheritance.
Before we start, there’s one word on wording: We will be using “superclass” whenever we start an argument from the subclass’s (or derived class’s) perspective. We will prefer “base class” whenever the discussion starts from that class and talks about possible derived classes or class hierarchies. These are, however, only stylistic considerations; the technical meaning of both terms is the same.
3.1.1 The Liskov Substitution Principle
It is common folklore that inheritance is all about “is-a relationships.” This is also reflected in Java’s typing rules: The compiler will allow assignments from a class to any of its superclasses. However, there are several different notions of what precisely constitutes an “is-a relationship.” The possible confusion is exhibited in the classical circle/ellipse dilemma: On the one hand, a circle is-an ellipse, just one that happens to have two identical radii; on the other hand, an ellipse is-a circle, just one that happens to have an additional field “minor radius.” More confusing still, a circle is not an ellipse at all, because unlike an ellipse, it cannot be stretched in two directions independently. So which one is it to be?
After long and wide-ranging debate, it has turned out that it is best to![]() 1.1 start from the behavior of objects, according to the premise that objects
1.1 start from the behavior of objects, according to the premise that objects![]() 160,162 are active entities in a larger network. The focal point of this reasoning has been termed the Liskov Substitution Principle:
160,162 are active entities in a larger network. The focal point of this reasoning has been termed the Liskov Substitution Principle:
An object of a derived class must be usable wherever an object of a superclass is expected.
In other words, clients that can work with an instance of a superclass must work as well with instances of a subclass, because the behavior that they![]() 6.4 expect is still present. These expectations can be made precise in the form of contracts. For now, an intuition is sufficient.
6.4 expect is still present. These expectations can be made precise in the form of contracts. For now, an intuition is sufficient.
Suppose, for example, that a client wants to copy the content of an InputStream to disk. The client merely fetches bytes into a buffer through the method read declared in the following snippet. It does not matter where these bytes really come from—whether from the local disk, over the![]() 2.4.2 network, or even from a pipeline of encryption and encoding steps. The behavior is determined solely by the idea of a “stream of bytes” from which the client takes an initial chunk.
2.4.2 network, or even from a pipeline of encryption and encoding steps. The behavior is determined solely by the idea of a “stream of bytes” from which the client takes an initial chunk.
java.io.InputStream
public int read(byte b[], int off, int len) throws IOException {
...
for (; i < len; i++) {
c = read(); b[off + i] = (
byte) c;
}
...
}
The default implementation shown in this snippet reads single bytes one by one. This is actually inefficient in many situations. For local files, for![]() 238 instance, the operating system can fetch chunks of bytes directly (which is done in the native method readBytes in the next example). The File InputStream therefore overrides the method read. However, the client is
238 instance, the operating system can fetch chunks of bytes directly (which is done in the native method readBytes in the next example). The File InputStream therefore overrides the method read. However, the client is![]() 1.4.1 not aware of this special implementation, since the object still exhibits the behavior described in the superclass.
1.4.1 not aware of this special implementation, since the object still exhibits the behavior described in the superclass.
java.io.FileInputStream
public int read(byte b[], int off, int len) throws IOException {
...
bytesRead = readBytes(b, off, len);
...
}
![]() From a language perspective, the fact that a FileInputStream can be used where an InputStream is declared is called subtyping. For s a subtype of t, one writes s ≤ t. Then, the language decrees that if obj has type s and s ≤ t, then obj also has type t. We now look briefly at different notions of subtyping in object-oriented languages.
From a language perspective, the fact that a FileInputStream can be used where an InputStream is declared is called subtyping. For s a subtype of t, one writes s ≤ t. Then, the language decrees that if obj has type s and s ≤ t, then obj also has type t. We now look briefly at different notions of subtyping in object-oriented languages.
The central question is how the types of different objects are related. In Java this happens through extends and implements clauses: The subtyping between classes is simply declared. The compiler checks that all technical side-conditions, such as on the implementation of abstract methods, are fulfilled.
There is also a leaner and somewhat cleaner approach without explicit declarations. Structural subtyping starts with a language that builds objects from three elementary![]() 69,1,60,209 constructs: records, functions (as values), and fixed points. The question of how to do that is in itself interesting, but beyond the current discussion. The point relevant for now is that the subtyping rules on these elements are applied along the structure of objects. In the end, they combine to yield a notion of subtyping for objects that basically ensures that programs “can’t go wrong” at runtime—that is, that all invoked methods are found
69,1,60,209 constructs: records, functions (as values), and fixed points. The question of how to do that is in itself interesting, but beyond the current discussion. The point relevant for now is that the subtyping rules on these elements are applied along the structure of objects. In the end, they combine to yield a notion of subtyping for objects that basically ensures that programs “can’t go wrong” at runtime—that is, that all invoked methods are found![]() 186 and all data items are used according to their types. In fact, these are the technical side-conditions that the Java compiler must check as well.
186 and all data items are used according to their types. In fact, these are the technical side-conditions that the Java compiler must check as well.
In contrast, behavioral subtyping takes the view that structural subtyping must be![]() 232,160,5,162 complemented by assertions about the object’s reaction to method calls: The mere existence of a method does not guarantee that clients get the expected result from a call. The declaration of super-types in the extends and implements clauses of Java can therefore be seen as an explicit assertion by the programmer that the behavior of the resulting object will be adequate—that is, that the subclass’s instances will obey the rules set by the super-type.
232,160,5,162 complemented by assertions about the object’s reaction to method calls: The mere existence of a method does not guarantee that clients get the expected result from a call. The declaration of super-types in the extends and implements clauses of Java can therefore be seen as an explicit assertion by the programmer that the behavior of the resulting object will be adequate—that is, that the subclass’s instances will obey the rules set by the super-type.
3.1.2 Interface Between the Base Class and Subclasses
The Liskov Substitution Principle explains how inheritance interacts with the object’s interface available to clients. If we consider classes just as a tool for implementing objects, that’s all there is to say. Inheritance, however, introduces a further visibility level protected betweenprivate and public. It enables subclasses to be more intimate with their superclass, to share some of its secrets hidden from the world at large. Unconstrained access to the internals of the superclass will, unfortunately, quickly yield complex and unmaintainable code. Furthermore, relying on these internals too much means that the superclass can never change without destroying the existing subclasses, a phenomenon termed the fragile base class problem.![]() 185
185
![]() 232,160It has been noticed early on that a firm conceptual basis for using inheritance in a safe way can be obtained by considering that each class really has two interfaces (Fig. 3.1): one toward its clients and one toward its subclasses.
232,160It has been noticed early on that a firm conceptual basis for using inheritance in a safe way can be obtained by considering that each class really has two interfaces (Fig. 3.1): one toward its clients and one toward its subclasses.
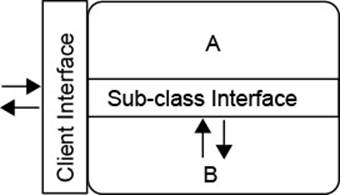
Figure 3.1 The Two Interfaces of a Class
Use protected to define and enforce an interface toward subclasses.
Developers of subclasses can be expected to be more familiar with the superclass’s mechanics than is the general client. They can therefore be allowed greater license, more access points, and more services offered to them. We![]() 1.4.8.2 have already seen examples of this: In the one direction, reusable functionality in protected methods is accessible throughout the hierarchy. In the other direction, the superclass can explicitly invite the collaboration in specific
1.4.8.2 have already seen examples of this: In the one direction, reusable functionality in protected methods is accessible throughout the hierarchy. In the other direction, the superclass can explicitly invite the collaboration in specific![]() 1.4.9 operations through protected abstract methods in the TEMPLATE METHOD pattern.
1.4.9 operations through protected abstract methods in the TEMPLATE METHOD pattern.
![]()
![]() 111(§6.6.2)In fact, the intention of the protected modifier is to allow access to any other classes that may be involved in implementing a specific functionality. In particular, classes in the same package and all derived classes are considered to belong to this group.
111(§6.6.2)In fact, the intention of the protected modifier is to allow access to any other classes that may be involved in implementing a specific functionality. In particular, classes in the same package and all derived classes are considered to belong to this group.
Design the interface toward subclasses with as much care as the interface toward other objects.
In the end, subclasses are still just consumers of the superclass’s abilities.![]() 232 They are really clients of a different sort. In this capacity, they have a right to their own interface, a right to be told explicitly how the superclass can be used. There are two motivations for defining a narrow interface. First, it facilitates subclassing, and therefore reuse of your work, since it limits the
232 They are really clients of a different sort. In this capacity, they have a right to their own interface, a right to be told explicitly how the superclass can be used. There are two motivations for defining a narrow interface. First, it facilitates subclassing, and therefore reuse of your work, since it limits the![]() 12.1 amount of detail other developers have to understand. Second, it broadens your possibilities of later adaptations, since anything you keep hidden from subclasses can still be changed. If you think back, both points are really the same for public methods for general clients.
12.1 amount of detail other developers have to understand. Second, it broadens your possibilities of later adaptations, since anything you keep hidden from subclasses can still be changed. If you think back, both points are really the same for public methods for general clients.
Make fields private and define protected access methods.
A good strategy in general is to make each class responsible for its own fields throughout the object’s lifetime, first during initialization, then in![]() 1.6.3 maintaining consistency. A class does not in general modify the fields it has
1.6.3 maintaining consistency. A class does not in general modify the fields it has![]() 6.4.2 inherited, because this might destroy assumptions implicit in the superclass’s code. A typical example is found in AbstractListViewer, whose field listMap is private, but can be accessed by dedicated protected service methods.
6.4.2 inherited, because this might destroy assumptions implicit in the superclass’s code. A typical example is found in AbstractListViewer, whose field listMap is private, but can be accessed by dedicated protected service methods.
In fact, fields should be private even if they are final and therefore cannot be modified by subclasses. Only if the fields are hidden completely can the superclass change its implementation decisions whenever it sees fit. Even read-only fields can break subclasses, when their content or interpretation changes unexpectedly—read-only fields, too, can lead to the fragile![]() 3.1.11 base class problem.
3.1.11 base class problem.
3.1.3 Factoring Out Common Behavior
If the essence of objects lies in their behavior, then the essence of base classes lies in the common behavior exhibited by all possible subclasses. The first and best reason for introducing a base class is therefore to capture that common behavior. There are really two kinds of behavior that could be relevant here, analogously to the two interfaces of classes: one toward clients![]() 3.1.2 and one toward subclasses. We will treat the first now, and the second in the next section.
3.1.2 and one toward subclasses. We will treat the first now, and the second in the next section.
As an example, Eclipse’s user interface contains many different kinds of structured data displays, such as lists, trees, and tables. From a software design perspective, they have many commonalities: The user can select displayed![]() 70,71 items, the data may be filtered and sorted, and so on. Furthermore, one can observe changes in the selection and a viewer-specific “open” gesture,
70,71 items, the data may be filtered and sorted, and so on. Furthermore, one can observe changes in the selection and a viewer-specific “open” gesture,![]() 2.1 usually a double-click. It is therefore useful to introduce a common base class StructuredViewer that offers corresponding methods:
2.1 usually a double-click. It is therefore useful to introduce a common base class StructuredViewer that offers corresponding methods:
org.eclipse.jface.viewers.StructuredViewer
public ISelection getSelection()
public void setFilters(ViewerFilter[] filters)
public void setComparator(ViewerComparator comparator)
public void
addSelectionChangedListener(ISelectionChangedListener
listener)
public void addOpenListener(IOpenListener listener)
Now other elements of the user interface that rely only on the common behavior of structured viewers can work independently of the concrete viewer type. For instance, the OpenAndLinkWithEditorHelper opens the current selection of a structured viewer in an editor. In the Java tools, it is attached to the tree in the JavaOutlinePage as well as the table in the QuickFixPage. The helper works because it relies on only the common characteristics of structured viewers. First, it observes the selection and the “open” gesture:
org.eclipse.ui.OpenAndLinkWithEditorHelper.InternalListener
viewer.addPostSelectionChangedListener(listener);
viewer.addOpenListener(listener);
Then, when the selection actually changes, the helper can react correspondingly:
org.eclipse.ui.OpenAndLinkWithEditorHelper
public void selectionChanged(SelectionChangedEvent event) {
final ISelection selection = event.getSelection();
...
linkToEditor(selection);
...
}
It must be said, however, that factoring out common behavior for the![]() 3.2.1 benefit of clients is nowadays not usually done through inheritance, but
3.2.1 benefit of clients is nowadays not usually done through inheritance, but![]() 3.2.10 through interfaces. A more precise delineation will be given at the very end, after both language features have been discussed by themselves. We have nevertheless put this point up front because it underlines the importance of
3.2.10 through interfaces. A more precise delineation will be given at the very end, after both language features have been discussed by themselves. We have nevertheless put this point up front because it underlines the importance of![]() 3.1.1 the Liskov Substitution Principle: Inheritance is always about behavioral subtyping.
3.1.1 the Liskov Substitution Principle: Inheritance is always about behavioral subtyping.
3.1.4 Base Classes for Reusable Infrastructure
![]() 3.1.1Inheritance combines two aspects into one mechanism: that of subtyping, which enables clients to work uniformly over different subclasses, and that of a partial implementation, which enables subclasses get part of their own behavior for free. In the latter case, rather than working hard in the manner of self-made men, the subclasses just lay back and rely on their inheritance. Unlike real people, they can even choose a suitable parent.
3.1.1Inheritance combines two aspects into one mechanism: that of subtyping, which enables clients to work uniformly over different subclasses, and that of a partial implementation, which enables subclasses get part of their own behavior for free. In the latter case, rather than working hard in the manner of self-made men, the subclasses just lay back and rely on their inheritance. Unlike real people, they can even choose a suitable parent.
Base classes are, however, more than just pieces of behavior that one takes as given. Good, powerful base classes provide an infrastructure that interacts with subclasses in several ways.
• ![]() 3.1.3They offer basic functionality to clients that the subclasses then do not have to rebuild themselves.
3.1.3They offer basic functionality to clients that the subclasses then do not have to rebuild themselves.
• ![]() 3.1.2
3.1.2 ![]() 1.4.8They offer an extended protected interface to the expected subclasses that lets the subclasses manipulate the internals.
1.4.8They offer an extended protected interface to the expected subclasses that lets the subclasses manipulate the internals.
• ![]() 1.4.9
1.4.9 ![]() 132They offer generic mechanisms that can be adapted at specific points through the TEMPLATE METHOD pattern.
132They offer generic mechanisms that can be adapted at specific points through the TEMPLATE METHOD pattern.
Think of a base class as an infrastructure upon which concrete classes build.
You will note that we have studied all of these elements previously in isolation. We will now see that combining them in one class yields powerful abstractions. A second aspect of the guideline is that an infrastructure usually requires completion and cannot be used on its own. This is reflected in the fact that many base classes are abstract, or have Abstract as a prefix to their names. Others, such as LabelProvider, do implement all methods, but only with empty bodies and returning sensible default values.
Let’s go back to the StructuredViewer and check for these three points. We have already seen the contribution to the client interface in the previous section: The structure viewer manages the selection, listeners, filters, and sorter, and similar publicly visible aspects. In terms of the second point, it maintains internal helpers, such as a caching hash map from![]() 1.3.6 data items to display items that can speed up operations on large data sets.
1.3.6 data items to display items that can speed up operations on large data sets.
org.eclipse.jface.viewers.StructuredViewer
private CustomHashtable elementMap;
On these data structures, the structure viewer offers protected operations for use in the subclasses. In the case of the cache, for instance, it provides the following method (the omitted code deals with cases where one data item is associated with several display items):
org.eclipse.jface.viewers.StructuredViewer
protected void mapElement(Object element, Widget item) {
if (elementMap != null) {
Object widgetOrWidgets = elementMap.get(element);
if (widgetOrWidgets == null) {
elementMap.put(element, item);
} else
...
}
}
All of these elements are usually reused as they are; that is, with the client or subclasss simply calling them to make use of the functionality.
The third point of the infrastructure is somewhat more intricate. Using![]() 1.4.9 the TEMPLATEMETHOD, the base class specifies the general outline of some operation, but leaves those parts that are specific to the subclasses to be implemented later. A simple example of this was given in the presentation of the pattern. For a more extended example, you might want to trace the workings of the following method, which must be called whenever some
1.4.9 the TEMPLATEMETHOD, the base class specifies the general outline of some operation, but leaves those parts that are specific to the subclasses to be implemented later. A simple example of this was given in the presentation of the pattern. For a more extended example, you might want to trace the workings of the following method, which must be called whenever some![]() 9.3.2 properties of an element have changed locally, so that the display can be updated:
9.3.2 properties of an element have changed locally, so that the display can be updated:
org.eclipse.jface.viewers.StructuredViewer
public void update(Object element, String[] properties)
The method takes care of multiple display items for element, each of which is treated by internalUpdate. That method first checks for a possible interaction with the current filters, then delegates, through intermediate steps, to the concrete subclass by calling:
org.eclipse.jface.viewers.StructuredViewer
protected abstract void doUpdateItem(Widget item, Object element,
boolean fullMap);
Note that the infrastructure has taken care of the tedious details, caching, filtering, and so on, and has finally arrived at the conclusion that a specific display item needs to be refilled with the current data of a specific object. As a result, subclasses can concentrate on the essentials, on the task that they are really written for. Isn’t that a great kind of infrastructure?
If you are longing for a yet more intricate example, you might want to![]() 214 take a look at the Graphical Editing Framework. Its AbstractGraphical EditParts add the further indirection of delegating part of their behavior not only to subclasses, but also to helpers calledEditPolicys.
214 take a look at the Graphical Editing Framework. Its AbstractGraphical EditParts add the further indirection of delegating part of their behavior not only to subclasses, but also to helpers calledEditPolicys.
Finally, we point out that Eclipse actively supports the completion of an infrastructure base class by tools:
Tool: Create Completed Subclass
In the New/Class wizard, choose the desired base class and then check Inherited Abstract Methods in the selection of method stubs to be generated.
![]() This tool does not excuse you from studying the documentation of the base class in detail to understand the provided mechanisms. Not all methods that you have to override are really abstract. Very often, you will have to use Override Method manually for specific further methods.
This tool does not excuse you from studying the documentation of the base class in detail to understand the provided mechanisms. Not all methods that you have to override are really abstract. Very often, you will have to use Override Method manually for specific further methods.
3.1.5 Base Classes for Abstraction
![]() 48(Ch.4)A classic use of inheritance is to capture abstraction. Abstraction here means to construct a hierarchical case distinction, where superclasses are more general and comprise more concrete cases than their subclasses. Conversely, subclasses capture special cases of their superclasses. We can therefore also speak of a specialization hierarchy. Very often, the classes represent domain concepts, so that users see their own mental classification reflected in the software. The hierarchy then is an iterated refinement of concepts. The “is-a” relation has an intuitive meaning, both to users and to software engineers.
48(Ch.4)A classic use of inheritance is to capture abstraction. Abstraction here means to construct a hierarchical case distinction, where superclasses are more general and comprise more concrete cases than their subclasses. Conversely, subclasses capture special cases of their superclasses. We can therefore also speak of a specialization hierarchy. Very often, the classes represent domain concepts, so that users see their own mental classification reflected in the software. The hierarchy then is an iterated refinement of concepts. The “is-a” relation has an intuitive meaning, both to users and to software engineers.
To give an example, Eclipse’s Java Model classifies the different language concepts in a hierarchy below JavaElement. The hierarchy consists![]() 112,39 of 46 classes and has depth 7 (including the root). In comparison to usual hierarchies, it is rather detailed. For a detailed overview, useType Hierarchy. Let us now look at some of the classes to understand how abstraction by inheritance works.
112,39 of 46 classes and has depth 7 (including the root). In comparison to usual hierarchies, it is rather detailed. For a detailed overview, useType Hierarchy. Let us now look at some of the classes to understand how abstraction by inheritance works.
Some of the cases refer directly to language constructs, such as Source Field, SourceMethod, or ImportDeclaration. Furthermore, there are parts of the super-structure such as CompilationUnit (i.e., one source file), ClassFile (i.e., a compiled binary class file), orPackageFragment (where “fragment” indicates that the Java Virtual Machine merges different packages with the same name).
The hierarchy above these obvious types then captures their commonalities in a multistep case distinction. At the top, there are two kinds of Java Elements. First, SourceRefElements are elements that correspond directly to source code, either explicitly in source files or implicitly through the source information attached to binary class files. In contrast, Openable is a technical superclass of (largish) things that must be loaded into memory, or “opened,” before their parts can be analyzed. For instance, a JarPackage FragmentRoot holds the file system path to a JAR file. When that element is opened, the infrastructure of Openable handles the general process and![]() 3.1.4 finally calls back the method computeChildren in JarPackageFragment Root, which reads the JAR file from disk and creates the corresponding entries in the Java model.
3.1.4 finally calls back the method computeChildren in JarPackageFragment Root, which reads the JAR file from disk and creates the corresponding entries in the Java model.
Within the source files, which are below SourceRefElement, the classification follows the Java abstract syntax. For instance, a SourceField is-a![]() 111 NamedMember, which is a Member, which is-a SourceRefElement.
111 NamedMember, which is a Member, which is-a SourceRefElement.
Further examples of classification can found in the hierarchy below JFace’s Viewer and that below SWT’s Widget.![]() 9.3.2
9.3.2 ![]() 7.1
7.1
Classify by dynamic behavior, not by static data or format.
It is important to note that the Liskov Substitution Principle is not invalidated![]() 3.1.1 only because the intention is to create an abstraction hierarchy. As we have seen, Openable provides an infrastructure for its subclasses. Also, it is used (through the interface IOpenable) in many places in the JDT to access the underlying source code.
3.1.1 only because the intention is to create an abstraction hierarchy. As we have seen, Openable provides an infrastructure for its subclasses. Also, it is used (through the interface IOpenable) in many places in the JDT to access the underlying source code.
Beware of deep or intricate abstraction hierarchies.
Novices in object-oriented programming are often overenthusiastic about creating classification hierarchies. You should always keep in mind that![]() 92 every class you introduce costs—for development, testing, documentation, and maintenance. It must therefore justify its existence by making a significant contribution to the system’s functionality. Usually this means providing some facet of reusable infrastructure or a useful view on the object for
92 every class you introduce costs—for development, testing, documentation, and maintenance. It must therefore justify its existence by making a significant contribution to the system’s functionality. Usually this means providing some facet of reusable infrastructure or a useful view on the object for![]() 3.1.4
3.1.4 ![]() 3.1.3
3.1.3 ![]() 3.2.2 some concrete clients. However, a mere case of implementation inheritance
3.2.2 some concrete clients. However, a mere case of implementation inheritance![]() 3.1.10 does not justify the existence of a base class. All in all, these demands are
3.1.10 does not justify the existence of a base class. All in all, these demands are![]() 112 rather high and empirical studies suggest that hierarchies usually remain rather shallow and narrow.
112 rather high and empirical studies suggest that hierarchies usually remain rather shallow and narrow.
3.1.6 Reifying Case Distinctions
A developer’s life is full of cases—so much so that Alan Perlis concluded,![]() 208(No.32) “Programmers are not to be measured by their ingenuity and their logic but by the completeness of their case analysis.” Whenever the behavior of an object varies, whether because of external circumstances, parameters, or its internal state, the code must express corresponding case distinctions. Very often, the cases can even be made explicit by naming them.
208(No.32) “Programmers are not to be measured by their ingenuity and their logic but by the completeness of their case analysis.” Whenever the behavior of an object varies, whether because of external circumstances, parameters, or its internal state, the code must express corresponding case distinctions. Very often, the cases can even be made explicit by naming them.
A straightforward, if limited, approach is to use explicit enums to name the cases and then switch to perform the case distinctions. The limitation consists of two resulting problems. First, the code that treats each case is scattered throughout the sources, which makes it hard to grasp how the case is really handled. Second, adding new cases requires retouching all those case distinctions, so it usually cannot be done easily by arbitrary![]() 1.5.5 developers—they at least need access to the sources. If you neglected to throw an exception in the default case, you may also be in for lengthy debugging sessions.
1.5.5 developers—they at least need access to the sources. If you neglected to throw an exception in the default case, you may also be in for lengthy debugging sessions.
Inheritance can capture cases as objects.
Inheritance enables an object-oriented solution to keep the code of the individual cases together. First, you introduce a base class that essentially has one (abstract) method for each piece of code that depends on the case. Then you pass around the correct case as an object and invoke the required code as necessary. From a different perspective, you are replacing the switch![]() 100 statement by dynamic dispatch. A further angle is obtained by seeing the different code fragments as short algorithms; with this perspective, we arrive
100 statement by dynamic dispatch. A further angle is obtained by seeing the different code fragments as short algorithms; with this perspective, we arrive![]() 1.3.4 at an instance of the STRATEGY pattern.
1.3.4 at an instance of the STRATEGY pattern.
![]() 82Let us start by looking at an example. EclipseLink provides an object
82Let us start by looking at an example. EclipseLink provides an object![]() 201 relational mapping (ORM)—that is, it implements persistent database storage for Java objects. Database systems do, however, differ in their exact SQL syntax and allowed language constructs. The classDatabasePlatform is the base of a corresponding case distinction. It has roughly 250 (!) methods representing the variabilities between database systems. For instance, every database system has the ability to generate unique primary keys, for instance by assigning increasing numbers to new rows. EclipseLink must later be able to determine the number assigned, a task for which it calls the method buildSelectQueryForIdentity. MySQL and PostgreSQL, for instance, use the following implementations:
201 relational mapping (ORM)—that is, it implements persistent database storage for Java objects. Database systems do, however, differ in their exact SQL syntax and allowed language constructs. The classDatabasePlatform is the base of a corresponding case distinction. It has roughly 250 (!) methods representing the variabilities between database systems. For instance, every database system has the ability to generate unique primary keys, for instance by assigning increasing numbers to new rows. EclipseLink must later be able to determine the number assigned, a task for which it calls the method buildSelectQueryForIdentity. MySQL and PostgreSQL, for instance, use the following implementations:
org.eclipse.persistence.platform.database.MySQLPlatform
public ValueReadQuery buildSelectQueryForIdentity() {
ValueReadQuery selectQuery = new ValueReadQuery();
selectQuery.setSQLString("SELECT LAST_INSERT_ID()");
return selectQuery;
}
org.eclipse.persistence.platform.database.PostgreSQLPlatform
public ValueReadQuery buildSelectQueryForIdentity() {
ValueReadQuery selectQuery = new ValueReadQuery();
selectQuery.setSQLString("select lastval()");
return selectQuery;
}
This example clearly shows the benefits of introducing cases as classes, compared to the solution by switch: The code for one database system remains together in one place, and it is possible to introduce new cases without touching existing code. Default implementations—in this case, along the SQL standard—can be placed into the base class and are then used across cases.
Of course, there are also some disadvantages: In smaller ad-hoc examples, the code infrastructure of base and derived classes, object creation and storage, and other supports can easily outweigh the actual case-specific code. Further, it becomes harder to grasp and exploit similarities between cases, because their code is scattered over different classes. The only remedy![]() 1.4.8.2
1.4.8.2 ![]() 3.1.4 is to introduce infrastructure base classes, which requires additional effort and planning. Finally, the code that calls the case methods is in danger of becoming less readable, because the human reader may have to follow the dynamic dispatch mentally.
3.1.4 is to introduce infrastructure base classes, which requires additional effort and planning. Finally, the code that calls the case methods is in danger of becoming less readable, because the human reader may have to follow the dynamic dispatch mentally.
In the end you have to make a decision: Is the potential extensibility worth the overhead and code scattering? There is certainly no injunction to express case distinctions by inheritance, although you should consider the approach whenever the code of individual cases gets bulky, such that it is unreadable when cases are put side by side in a switch. If you do, you should follow a few guidelines.
Aim at behavioral abstraction.
If you perceive case classes only as places to dump the corresponding code, you are likely to pay out more than you receive back. Nevertheless, you can see the case distinction as a prompt to define some abstract behavior![]() 3.1.3 that captures some common perspective on the different cases. Then, you have gained an additional insight. As a result, clients will be able to work at a more abstract level and their code becomes more readable through the
3.1.3 that captures some common perspective on the different cases. Then, you have gained an additional insight. As a result, clients will be able to work at a more abstract level and their code becomes more readable through the![]() 1.4.5 method calls, instead of becoming potentially less readable.
1.4.5 method calls, instead of becoming potentially less readable.
Aim at extensible case distinctions.
Ideally, the case distinction you introduce is open-ended: If other developers can identify and implement new cases even after your own code is complete, your software already caters to tomorrow’s needs.
You may well ask: If I have to obey these rules anyway, what is the difference from previous uses of inheritance? Although the final result may, in fact, look very similar, there are two crucial differences. First, you started from the low-key observation of requiring a case distinction, rather than from the ambitious goal of creating a useful abstraction. Such a gradual development is often more to the point in practice. Second, you may always stop along the way. In the EclipseLink example, some methods look like behavior, while others are only code snippets that needed to differ according to the database. The preceding example may be read as behavior, in the sense that the database can retrieve the last assigned primary key. In contrast, the method writeAddColumnClause, which creates the syntax to add a column to an existing table, is necessary only because one supported database system happens to require parentheses around the column specification.
3.1.7 Adapting Behavior
When object-oriented programming first became popular, one of its attractions was the ability to adapt existing functionality by subclassing and![]() 132 method overriding. The general approach of programming by difference was to choose a class from an existing application and adapt those methods that do not fit the context of reuse. At the same time, it was recognized that reuse does not happen by chance or with hindsight. Rather, it happens due to the foresight of the original developer and judicious application of what
132 method overriding. The general approach of programming by difference was to choose a class from an existing application and adapt those methods that do not fit the context of reuse. At the same time, it was recognized that reuse does not happen by chance or with hindsight. Rather, it happens due to the foresight of the original developer and judicious application of what![]() 3.1.4
3.1.4 ![]() 3.1.5 has since been termed refactoring. Accordingly, adapting behavior usually occurs within a context of explicitly identified common behavior.
3.1.5 has since been termed refactoring. Accordingly, adapting behavior usually occurs within a context of explicitly identified common behavior.
In some rare cases, the original idea of programming by difference can still be useful for internal classes that just need “a bit of extra functionality”![]() 12.3.3.5 beyond what is already there. For instance, the code assist system of Eclipse
12.3.3.5 beyond what is already there. For instance, the code assist system of Eclipse![]() 3.1.5 mainly deals in JavaElements extracted from the source. However, the original mechanism for unique identification of members seems to have been too slow so that caching needs to be added. Accordingly, AssistSourceField, AssistSourceMethod, and similar elements share a hash map that is consulted before recomputing identifiers. The fields mentioned in the following snippet are introduced for the purpose.
3.1.5 mainly deals in JavaElements extracted from the source. However, the original mechanism for unique identification of members seems to have been too slow so that caching needs to be added. Accordingly, AssistSourceField, AssistSourceMethod, and similar elements share a hash map that is consulted before recomputing identifiers. The fields mentioned in the following snippet are introduced for the purpose.
org.eclipse.jdt.internal.codeassist.impl.AssistSourceField
public String getKey() {
if (this.uniqueKey == null) {
Binding binding = this.bindingCache.get(this);
if (binding != null) {
this.isResolved = true;
this.uniqueKey = new String(binding.computeUniqueKey());
} else {
...
}
}
return this.uniqueKey;
}
![]() Whenever you feel like using inheritance in this way, you should be aware that you are really creating a hack: You are using a class—by subclassing—in a way that it was not specifically designed for. The chances that the class breaks with a change in
Whenever you feel like using inheritance in this way, you should be aware that you are really creating a hack: You are using a class—by subclassing—in a way that it was not specifically designed for. The chances that the class breaks with a change in![]() 3.1.11 the base class are therefore rather high. In fact, this use of inheritance is very near to implementation inheritance, to be discussed later.
3.1.11 the base class are therefore rather high. In fact, this use of inheritance is very near to implementation inheritance, to be discussed later.![]() 3.1.10
3.1.10
3.1.8 Inheritance Versus Delegation
Whenever you wish to reuse functionality given in a class A, you must make a choice: Either you instantiate A and delegate the relevant subtasks to that![]() 3.1.4 object, or you inherit from A and incorporate A’s functionality into your
3.1.4 object, or you inherit from A and incorporate A’s functionality into your![]() 1.8.5 own object. Both approaches have specific advantages and disadvantages that you must be aware of to make an informed decision. As a general rule of thumb:
1.8.5 own object. Both approaches have specific advantages and disadvantages that you must be aware of to make an informed decision. As a general rule of thumb:
Prefer delegation over inheritance, unless you need the extra expressive power.
The preference of delegation over inheritance can be widely seen in the Eclipse platform. For instance, the JFace SourceViewer incorporates over 70 aspects of its functionality through delegation. There are several rather obvious reasons for preferring delegation.
• There is only one inheritance slot anyway, so you have to choose carefully which class you inherit from.
• The inheritance relation is public knowledge, so you have to be wary![]() 232 of clients that seek to exploit the common base behavior.
232 of clients that seek to exploit the common base behavior.
• You always inherit the entire interface and cannot restrict the available![]() 1.4.14 methods.
1.4.14 methods.
• You cannot change the published choice of the base class later on, since it might break clients. At this point, encapsulation of implementation details is not achieved.
For all of those reasons, you can use inheritance only if you can argue that the Liskov Substitution Principle is obeyed—implementation inheritance is![]() 3.1.1
3.1.1 ![]() 3.1.10 undesirable.
3.1.10 undesirable.
Beyond these obvious reasons, inheritance makes reasoning about the code more complex, and poses corresponding challenges for understanding and maintenance. First, we have already seen that unlimited access to the![]() 3.1.2
3.1.2 ![]() 6.4.2 superclass’s fields is undesirable because it jeopardizes the object’s consistency. Instead, you should define an explicit interface towards subclasses.
6.4.2 superclass’s fields is undesirable because it jeopardizes the object’s consistency. Instead, you should define an explicit interface towards subclasses.![]() 232 Second, undisciplined use of method overriding can easily lead to the situation in Fig. 3.2(a), where arrows with solid heads represent explicit calls, while those with empty heads represent self-calls to an overridden method that are dynamically dispatched to the subclass. The only chance of taming
232 Second, undisciplined use of method overriding can easily lead to the situation in Fig. 3.2(a), where arrows with solid heads represent explicit calls, while those with empty heads represent self-calls to an overridden method that are dynamically dispatched to the subclass. The only chance of taming![]() 3.1.4
3.1.4 ![]() 1.4.9 this behavior is to designate explicit callbacks that subclasses can or must override.
1.4.9 this behavior is to designate explicit callbacks that subclasses can or must override.
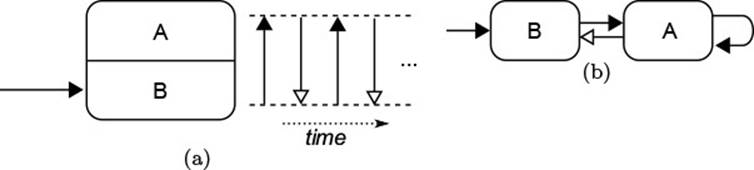
Figure 3.2 Coupling by Inheritance and Delegation
In contrast, delegation in Fig. 3.2(b) never incurs such inadvertent redirections of calls: The arrow with an empty head here represents explicit callbacks,![]() 2.1 such as notifications through an OBSERVER pattern. Furthermore,
2.1 such as notifications through an OBSERVER pattern. Furthermore,![]() 2.4.2 the DECORATOR pattern demonstrates that an incremental improvement akin to that achieved through inheritance can also be achieved through delegation.
2.4.2 the DECORATOR pattern demonstrates that an incremental improvement akin to that achieved through inheritance can also be achieved through delegation.
All of these arguments are sometimes summarized by saying that the![]() 12.1 subclass is coupled tightly to its superclass. In other words, the subclass necessarily makes many assumptions about the superclass’s mechanisms, its internal sequences of method calls, and the meaning of its fields. The more assumptions the subclass makes, the more likely it is to break when the superclass changes. Its implementation is tied to—is coupled to—that of the superclass.
12.1 subclass is coupled tightly to its superclass. In other words, the subclass necessarily makes many assumptions about the superclass’s mechanisms, its internal sequences of method calls, and the meaning of its fields. The more assumptions the subclass makes, the more likely it is to break when the superclass changes. Its implementation is tied to—is coupled to—that of the superclass.
Inheritance introduces tight coupling of the subclass to the superclass.
3.1.9 Downcasts and instanceof
Type hierarchies are introduced, whether through inheritance or interfaces, to group objects in a meaningful way and to enable clients to work with different kinds of objects interchangeably. The compiler will always cast an object to any of its super-types, so the methods of these super-types are available to clients. Downcasts and instanceof expressions therefore go against the grain of classification: Clients single out special cases and are thus less widely applicable themselves. Nevertheless, both downcasts and instanceof are often used and required.
Try to argue that a special subtype will always be present.
The best situation is one where you actually know that an object must have a more specific type. Very often, this is the case because of basic consistency conditions (i.e., invariants). When you only ever put objects of a specific![]() 4.1 type into some list, as in this snippet:
4.1 type into some list, as in this snippet:
org.eclipse.jface.viewers.Viewer
public void addSelectionChangedListener(ISelectionChangedListener
listener) {
selectionChangedListeners.add(listener);
}
then you will always get those types of objects out afterward:
org.eclipse.jface.viewers.Viewer.fireSelectionChanged
Object[] listeners = selectionChangedListeners.getListeners();
for (int i = 0; i < listeners.length; ++i) {
ISelectionChangedListener l = (ISelectionChangedListener)
listeners[i];
...
}
You might feel that you are relying on some insubstantial reasoning here. In fact, no instanceof checks are necessary because the program’s logic already dictates their outcome: This use of downcasts is completely safe. Bugs aside, the cast will always succeed.
Do not check with instanceof where the outcome is clear.
The reason why we advocate omitting the check is one of readability: If![]() 4.5 you write the check, the reader will start wondering what else can happen, and whether the other cases are handled correctly. Without the check, your code clearly states that no other cases can legally arise.
4.5 you write the check, the reader will start wondering what else can happen, and whether the other cases are handled correctly. Without the check, your code clearly states that no other cases can legally arise.
In fact, this is how generics work under the hood: Java’s type system![]() 53,52 keeps track of the list elements’ type—in other words, the invariant over the list content.
53,52 keeps track of the list elements’ type—in other words, the invariant over the list content.
downcasts.GenericsAndInvariants
1 private ArrayList<Integer> data = new ArrayList<Integer>();
2 public void useData() {
3 Integer d = data.get(0);
4 }
When one extracts an element (line 3), the compiler inserts a corresponding cast into the byte-code (at offset 8 in the following javap -c listing):
0: aload_0
1: getfield #17 // Field data:Ljava/util/ArrayList;
4: iconst_0
5: invokevirtual #24 // Method java/util/ArrayList.get;
8: checkcast #28 // class java/lang/Integer
Another reliable source of information about specialized types comprises![]() 9.3.2 framework mechanisms. For instance, JFace viewers display application data on the screen. The viewer invokes setInput on the viewer to target it to the desired data structure. To access the data, the viewer employs a content provider. For instance, the classpath tab folder in a Java run configuration (go to Run/Run configurations to see it) displays a data structure called ClasspathModel. The viewer, in this case a tree viewer, is set up accordingly:
9.3.2 framework mechanisms. For instance, JFace viewers display application data on the screen. The viewer invokes setInput on the viewer to target it to the desired data structure. To access the data, the viewer employs a content provider. For instance, the classpath tab folder in a Java run configuration (go to Run/Run configurations to see it) displays a data structure called ClasspathModel. The viewer, in this case a tree viewer, is set up accordingly:
org.eclipse.jdt.debug.ui.launchConfigurations.JavaClasspathTab.refresh
fClasspathViewer.setContentProvider(
new ClasspathContentProvider(this));
fClasspathViewer.setInput(fModel);
Viewers promise to call back the content provider’s inputChanged method first thing, with themselves as the viewer and the data structure supplied by the application. The casts in the following snippet are therefore completely safe, and no instanceof check should be done.
org.eclipse.jdt.internal.debug.ui.classpath.ClasspathContentProvider
public void inputChanged(Viewer viewer, Object oldInput,
Object newInput) {
treeViewer = (TreeViewer) viewer;
if (newInput != null) {
model = (ClasspathModel) newInput;
}
...
}
Use instanceof whenever different subtypes may potentially be accessed.
Finally, we reach the realm of uncertainty, where the concrete type may or![]() 1.5.2
1.5.2 ![]() 4.6 may not be a subtype of some expected class or interface. One important source of uncertainty is the system boundary: One simply can never be sure that the user invokes some menu entry only at the appropriate point.
4.6 may not be a subtype of some expected class or interface. One important source of uncertainty is the system boundary: One simply can never be sure that the user invokes some menu entry only at the appropriate point.![]() 2.1.3 Consider, for instance, the refactoring Introduce Parameter Object. It can be invoked only on methods, and the corresponding Action object should really be enabled only if a method is currently selected. Nevertheless, the run code checks that the restriction is indeed obeyed (line 3), before downcasting the selected object and proceeding (line 5).
2.1.3 Consider, for instance, the refactoring Introduce Parameter Object. It can be invoked only on methods, and the corresponding Action object should really be enabled only if a method is currently selected. Nevertheless, the run code checks that the restriction is indeed obeyed (line 3), before downcasting the selected object and proceeding (line 5).
org.eclipse.jdt.internal.ui.actions.IntroduceParameterObjectAction
1 public void run(JavaTextSelection selection) {
2 IJavaElement[] elements = selection.resolveElementAtOffset();
3 if (elements.length != 1 || !(elements[0] instanceof IMethod))
4 return;
5 run((IMethod) elements[0]);
6 }
Tool: Create instanceof Case
To create code for the idiom “if instanceof then downcast,” type instanceof, auto-complete the code (Ctrl-Space), and choose Dynamic type test and cast. Use the linked positions, cycling them by tab, to fill in the details.
Finally, instanceof and downcasts may be necessitated by architectural![]() 12.1 considerations. Fig. 3.3 depicts a common situation. Some client in one module works with a hierarchy in a different module.
12.1 considerations. Fig. 3.3 depicts a common situation. Some client in one module works with a hierarchy in a different module.
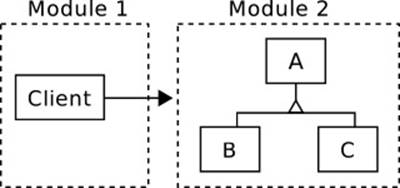
Figure 3.3 Downcasts for Architectural Reasons
Naturally, the client may wish to carry out operations that depend on the concrete class of an object. There are several different approaches.
1. Put an abstract operation into the base class and let dynamic dispatch![]() 3.1.6 handle the case distinction.
3.1.6 handle the case distinction.
2. Include combinations of instanceof and downcast into the client.
3. If available, a VISITOR might be sufficient to implement the operation.![]() 2.3.2
2.3.2
The last possibility really applies only to special case of recursive structures that happen to implement the VISITOR pattern. Since that pattern precludes extensibility of the hierarchy, it is rather uncommon. The first possibility applies only if your team controls the sources of the hierarchy. Furthermore, it incurs the grave danger of bloated classes: If A, B, and C are part of a central structure, then abstract operations will flow in from all parts of the system. Over time, these classes are heaped with more and more responsibilities. A very compelling reason for downcasts arises if the new responsibilities are fundamentally inconsistent with the purposes of the classes.
As an example, the Eclipse data structure of IJavaElements keeps track of the structure of the sources you are editing—that is, packages, classes, methods, and fields are all represented as objects within Eclipse so that you can easily access them. Even so, the visual appearance is a rather special![]() 9 need that is confined to special UI modules. The following code in Eclipse’s UI layer therefore looks at the data structure, switches based on the node type, and then performs a downcast according to the case at hand. In the omitted code, the icons that you see, such as in the package explorer and outline view, get chosen.
9 need that is confined to special UI modules. The following code in Eclipse’s UI layer therefore looks at the data structure, switches based on the node type, and then performs a downcast according to the case at hand. In the omitted code, the icons that you see, such as in the package explorer and outline view, get chosen.
org.eclipse.jdt.internal.ui.viewsupport.JavaElementImageProvider
public ImageDescriptor getBaseImageDescriptor(IJavaElement element,
int renderFlags) {
switch (element.getElementType()) {
case IJavaElement.METHOD: {
IMethod method = (IMethod) element;
...
}
case IJavaElement.FIELD: {
IMember member = (IMember) element;
...
}
...
}
}
Try to avoid instanceof and downcasts.
We started this subsection by undertaking an analysis of situations requiring and at least suggesting case analysis and downcasts. It must be clear, however, that in general it is better to solve case distinctions in operations![]() 1.4.1
1.4.1 ![]() 3.1.6
3.1.6 ![]() 2.3.1 by polymorphism and dynamic dispatch, since these mechanisms enable you to extend hierarchies later on; that is, when a new case surfaces, you can always create yet another class in the hierarchy. In contrast, explicit case distinctions limit the opportunities of evolving the software gracefully, since each and every case distinction needs to be touched on changes, something
2.3.1 by polymorphism and dynamic dispatch, since these mechanisms enable you to extend hierarchies later on; that is, when a new case surfaces, you can always create yet another class in the hierarchy. In contrast, explicit case distinctions limit the opportunities of evolving the software gracefully, since each and every case distinction needs to be touched on changes, something![]() 92 that in refactoring is very aptly called “shotgun surgery.”
92 that in refactoring is very aptly called “shotgun surgery.”
Ad-hoc case distinctions do occur in practice. One common situation is that of special functionality associated with special cases. For instance, the![]() 214 Graphical Editing Framework (GEF) introduces the concept of connections, which are lines attached automatically to other elements of a drawing. It is then useful to allow special elements to determine the exact attachment point, while in general the lines just continue to the bounding box of the element. The special case is captured in an interface NodeEditPart, which provides just the required support. The following snippet then determines the attachment of the line’s start point:
214 Graphical Editing Framework (GEF) introduces the concept of connections, which are lines attached automatically to other elements of a drawing. It is then useful to allow special elements to determine the exact attachment point, while in general the lines just continue to the bounding box of the element. The special case is captured in an interface NodeEditPart, which provides just the required support. The following snippet then determines the attachment of the line’s start point:
org.eclipse.gef.editparts.AbstractConnectionEditPart
protected ConnectionAnchor getSourceConnectionAnchor() {
if (getSource() instanceof NodeEditPart) {
NodeEditPart editPart = (NodeEditPart) getSource();
return editPart.getSourceConnectionAnchor(this);
}
IFigure f = ((GraphicalEditPart) getSource()).getFigure();
return new ChopboxAnchor(f);
}
A similar situation occurs in connection with the extension interfaces.![]() 3.2.5
3.2.5
Encapsulating downcasts in methods leaves the client type-safe.
It is a common idiom to encapsulate the type test and downcast into a method that returns null if the test fails. In this way, the caller remains type-correct: It checks for null, but otherwise can assume it is working with an object of an expected type. The offending type checks are confined to a dedicated method.
For instance, many objects in the Eclipse platform offer a getAdapter() method that returns an adapter with a given interface, or null if such an adapter does not exist. Sometimes the result is the target this itself, if it happens to be a subtype of the given interface.
org.eclipse.core.runtime.IAdaptable
public interface IAdaptable {
public Object getAdapter(Class adapter);
}
Conceptually, the method has the signature of the following dummy implementation, which follows that of JavaEditor. The interface IAdaptable does not use generics only for the historical reason that it was defined prior to Java 1.5.
downcasts.AdapterIdiom
public <T> T getAdapter(Class<T> adapter) {
if (IContentOutlinePage.class == adapter) {
// create the outline page if necessary
return (T) fOutlinePage;
}
...
return null;
}
Consider client-specific interfaces when downcasts become necessary.
The deeper reason for having the method getAdapter() is that the client![]() 3.2.2 requires some functionality that was not envisaged in the object’s original interface. Perhaps it is really specific for the client, or perhaps it was a simple oversight in the original design. In any case, understanding the new need as a stand-alone piece of functionality often helps to structure the design more clearly.
3.2.2 requires some functionality that was not envisaged in the object’s original interface. Perhaps it is really specific for the client, or perhaps it was a simple oversight in the original design. In any case, understanding the new need as a stand-alone piece of functionality often helps to structure the design more clearly.
3.1.10 Implementation Inheritance
The term implementation inheritance captures situations where a subclass is interested in the fields and methods of an existing class, but does not![]() 6.4.1 plan to honor the inherited behavior of that class.
6.4.1 plan to honor the inherited behavior of that class.
Let us start with a typical example. A junior programmer wishes to implement the mathematical notion of a “valuation,” referring to a mapping from variables to values. The programmer is supposed to provide get() and put() methods, so he decides he can finish the job quickly by just inheriting from HashMap:
implinh.Valuation
public class Valuation extends HashMap<VarName, Double> {
}
![]() 3.1.1However, this class violates the Liskov Substitution Principle: A valuation is not meant to be a hash map, but merely uses the hash map’s data structure. As a negation of the Liskov Substitution Principle, we get:
3.1.1However, this class violates the Liskov Substitution Principle: A valuation is not meant to be a hash map, but merely uses the hash map’s data structure. As a negation of the Liskov Substitution Principle, we get:
Avoid implementation inheritance.
The drawbacks of implementation inheritance have long been known.
• ![]() 232Implementation inheritance exposes too much information. The inheritance
232Implementation inheritance exposes too much information. The inheritance![]() 1.1 hierarchy is public knowledge, while encapsulation requires that, the implementation of an object must be hidden. Implementation inheritance therefore exposes too much of the class’s internals. In particular, clients of the class may upcast a reference to the subclass and use that reference with algorithms working directly on the implementation.
1.1 hierarchy is public knowledge, while encapsulation requires that, the implementation of an object must be hidden. Implementation inheritance therefore exposes too much of the class’s internals. In particular, clients of the class may upcast a reference to the subclass and use that reference with algorithms working directly on the implementation.
• The inherited interface is usually too large. In the example, iteration through the values is not part of a mathematical valuation. The subclass![]() 1.4.14 conceptually has a large number of refused bequests—that is, methods that it does not want but exposes for technical reasons.
1.4.14 conceptually has a large number of refused bequests—that is, methods that it does not want but exposes for technical reasons.
• ![]() 12.1The larger interface can increase coupling. In the example, the inherited method putAll(Collection c) ties the implementation to the Java collections framework, which might cause problems with porting later on.
12.1The larger interface can increase coupling. In the example, the inherited method putAll(Collection c) ties the implementation to the Java collections framework, which might cause problems with porting later on.
• ![]() 3.1.11Relying on the superclass’s internals makes the fragile base class problem more likely. When choosing a class for its implementation, one usually takes a look also at the internals to determine whether all required
3.1.11Relying on the superclass’s internals makes the fragile base class problem more likely. When choosing a class for its implementation, one usually takes a look also at the internals to determine whether all required![]() 3.1.7 quired mechanisms are actually there. Also, one adapts those methods that are not entirely as needed. This close link between subclass and base class makes it more likely that the subclass will break when the base class changes.
3.1.7 quired mechanisms are actually there. Also, one adapts those methods that are not entirely as needed. This close link between subclass and base class makes it more likely that the subclass will break when the base class changes.
Hide the implementation object by delegation.
A better solution in the example is to move the implementation object to a field inside the Valuation class. Now only the specified methods are exposed; the implementation could be replaced later on. Furthermore, the behavior of the methods can be modified. For instance, they may throw an UndefinedVariableException if get is called with a nonexistent variable.
implinh.Valuation2
public class Valuation2 {
private HashMap<VarName, Double> rep =
new HashMap<VarName, Double>();
public Double get(Object key) {
return rep.get(key);
}
public Double put(VarName key, Double value) {
return rep.put(key, value);
}
}
Tool: Generate Delegate Methods
To expose selected methods of a collaborator stored in a field, invoke Source/Generate Delegate Methods and choose the desired methods in the dialog.
![]() C++ tackles the problem of implementation inheritance at its root: If clients of
C++ tackles the problem of implementation inheritance at its root: If clients of![]() 239 the subclass cannot “see” the superclass, then all of the previously given objections are resolved. The language therefore extends the usual concept of access privileges to inheritance. If the superclass is declared private, then its fields and methods are inherited as usual, but only the class itself (and its friends) can make use of the fact; they alone can access the inherited members and can upcast a pointer. If inheritance is protected, then only the class itself and its subclasses see the relation.
239 the subclass cannot “see” the superclass, then all of the previously given objections are resolved. The language therefore extends the usual concept of access privileges to inheritance. If the superclass is declared private, then its fields and methods are inherited as usual, but only the class itself (and its friends) can make use of the fact; they alone can access the inherited members and can upcast a pointer. If inheritance is protected, then only the class itself and its subclasses see the relation.
In C++, one can express an “is-implemented-as” relation between subclass and superclass. The advantage over delegation is, of course, that the two involved objects are merged into one, such that the overhead of managing a separate object is avoided. Experts![]() 183(Item 39) in C++ usage nevertheless advise that this feature be used only in special situations.
183(Item 39) in C++ usage nevertheless advise that this feature be used only in special situations.
(It also has to be said that the overhead of delegation is minimal. Since objects in C++ have value semantics by default, adding a field rep as in this solution would actually embed the hash map into the outer valuation object. Also, objects without virtual methods do not have a header, so the overhead consists of only the additional method call during delegation.)
3.1.11 The Fragile Base Class Problem
The discussion of inheritance so far has pointed out common usage that works well in practice. However, we must not ignore the reality that in using inheritance extensively, one always walks a narrow path, where Bad Things can happen if one takes a wrong step into uncharted territory. We have already seen some examples, when we discussed the need to introduce![]() 3.1.2 explicit interfaces of protected methods for subclasses and the guideline
3.1.2 explicit interfaces of protected methods for subclasses and the guideline![]() 3.1.8 to prefer delegation over inheritance.
3.1.8 to prefer delegation over inheritance.
Development folklore has come to use the term fragile base class problem to summarize the undesirable phenomena related to inheritance: Developers find that a base class with many subclasses becomes “fragile,” in the sense that changing the base class in seemingly minor ways that appear to concern only the class’s internals nevertheless breaks many of the subclasses.![]() 7.3.3 This is, of course, an issue with extensible systems and (white-box) frameworks—that is, with software that is specifically intended to be reused in many applications. The same findings are also summarized by saying that
7.3.3 This is, of course, an issue with extensible systems and (white-box) frameworks—that is, with software that is specifically intended to be reused in many applications. The same findings are also summarized by saying that![]() 12.1 inheritance results in tight coupling between subclass and base class: The subclass usually makes so many, often implicit, assumptions about the base class’s behavior that even innocent changes to the base class will invalidate these assumptions. The problem can be recast in yet another way by saying
12.1 inheritance results in tight coupling between subclass and base class: The subclass usually makes so many, often implicit, assumptions about the base class’s behavior that even innocent changes to the base class will invalidate these assumptions. The problem can be recast in yet another way by saying![]() 136 that specifying the outside behavior of the base class is insufficient, because defining the allowed collaborations between the base class and its subclass clients requires talking about the internal mechanisms of the base class.
136 that specifying the outside behavior of the base class is insufficient, because defining the allowed collaborations between the base class and its subclass clients requires talking about the internal mechanisms of the base class.
The plethora of reasons why a class can be “fragile” makes it hard to define the term “fragile base class problem” precisely and comprehensively.![]() 185 Mikhajlov and Sekerinski have given an extensive and formalized analysis
185 Mikhajlov and Sekerinski have given an extensive and formalized analysis![]() 185(§3.6,§5.2) of the problems involved. They derive and justify a number of rules that exclude the problematic cases and achieve a desirable goal, which they call the flexibility property. Expressed in the terms introduced here, this property yields the following strategic goal:1
185(§3.6,§5.2) of the problems involved. They derive and justify a number of rules that exclude the problematic cases and achieve a desirable goal, which they call the flexibility property. Expressed in the terms introduced here, this property yields the following strategic goal:1
1. The original formulation is “If C is refined by C′ and C is refined by (M mod C), then C is refined by (M mod C′).” In this definition, “refines” is used in the sense of [18] and means “fulfills all expectations,” similar to the substitution principle. M mod C expresses subclassing by viewing the subclass’s definition as a modifier that is applied to the superclass’s definition.
Allow only changes to the base class that do not break the Liskov Substitution Principle for subclasses.
This goal can be justified from the previous discussions: A subclass is introduced to modify or concretize the behavior of its base class, with the aim of implementing the application’s functionality. Such a modification is![]() 3.1.1 restricted by the Liskov Substitution Principle, which guarantees that the subclass will work smoothly within the existing context. If a modification of the base class were to break the substitution principle for the subclass, that smooth integration would be destroyed and the overall application would be broken.
3.1.1 restricted by the Liskov Substitution Principle, which guarantees that the subclass will work smoothly within the existing context. If a modification of the base class were to break the substitution principle for the subclass, that smooth integration would be destroyed and the overall application would be broken.
The question is how such a general goal can be achieved. The insight is![]() 185(§3.6) that it is sufficient to follow a few rules in the code; given that this is the case, one can prove that the flexibility property is satisfied.
185(§3.6) that it is sufficient to follow a few rules in the code; given that this is the case, one can prove that the flexibility property is satisfied.
“No direct access to the base class state.”
This first rule has already been explored extensively in Section3.1.2 and does not need further discussion. If subclasses freely access the base class’s state, then the base class internals can never be changed in any way without endangering the subclasses.
“No cycles requirement.”
The fundamental challenge to the stability of base classes stems from the fact that (almost) all methods can be overridden, which can lead to undesirable interactions between the base class and the subclass. Each of the two classes can in principle make arbitrary self-calls, and these can get dispatched dynamically to either one of them.
One particular case is that overriding actually introduces an infinite recursion and nontermination of the program: If method f in the base class![]() 185 calls method g, and now the subclass overrides g to call f, the cycle is there. The immediate idea is, of course:
185 calls method g, and now the subclass overrides g to call f, the cycle is there. The immediate idea is, of course:
Be cautious about additional self-calls in overridden methods.
The deeper insight is that such cycles can be avoided only if there is a fixed![]() 185(§5.1) linear order on methods so that methods always call “smaller” ones. (In the rare cases where mutual recursion is necessary for algorithmic reasons, the methods can be private or one can specify that they must be overridden
185(§5.1) linear order on methods so that methods always call “smaller” ones. (In the rare cases where mutual recursion is necessary for algorithmic reasons, the methods can be private or one can specify that they must be overridden![]() 136 together.) If “fixed linear order” seems rather abstract, then think of the call graph of the methods and perform a depth-first traversal: If you don’t hit any cycles, you can number the methods as needed when finishing the visit. (In other words, you perform a topological sort of the call graph to
136 together.) If “fixed linear order” seems rather abstract, then think of the call graph of the methods and perform a depth-first traversal: If you don’t hit any cycles, you can number the methods as needed when finishing the visit. (In other words, you perform a topological sort of the call graph to![]() 72 obtain the numbers. The point is that a suitable numbering exists if and only if there are no cycles.)
72 obtain the numbers. The point is that a suitable numbering exists if and only if there are no cycles.)
Document the dependencies and call relationships between methods.
In practice, one does not number methods. However, the documentation of reusable classes usually excludes cycles by mentioning the intended call chains. For instance, the method paint() in Swing’s JComponent makes a very explicit statement of this kind:
This method actually delegates the work of painting to three protected methods: paintComponent, paintBorder, paint Children. They’re called in the order listed to ensure that children appear on top of the component itself.
Since clients will certainly refrain from calling paint() from within the three mentioned methods, cycles are avoided.
Specify the replaceable methods and the infrastructure mechanisms.
![]() 136Another way of approaching the goal is to specify explicitly which methods
136Another way of approaching the goal is to specify explicitly which methods![]() 232 should be replaceable. It was recognized early on that undisciplined overriding will lead to chaos, so the logical consequence is to allow overriding only at specific points. The implicit goal is, of course, to make sure that the mechanisms calling the overridable methods are cycle-free, and that the
232 should be replaceable. It was recognized early on that undisciplined overriding will lead to chaos, so the logical consequence is to allow overriding only at specific points. The implicit goal is, of course, to make sure that the mechanisms calling the overridable methods are cycle-free, and that the![]() 1.4.9 replacements will not call back into the generic mechanisms. The TEMPLATE METHOD pattern makes this very explicit; further conceptual foundations
1.4.9 replacements will not call back into the generic mechanisms. The TEMPLATE METHOD pattern makes this very explicit; further conceptual foundations![]() 12.3.2 will be discussed in the context of frameworks.
12.3.2 will be discussed in the context of frameworks.
Note also that this approach clearly prevents certain forms of implementation inheritance: If the designer decides and states which methods should be overridden, then the client cannot override methods just because they![]() 3.1.7 happen to implement something akin to their own requirements.
3.1.7 happen to implement something akin to their own requirements.
“No revision self-calling assumptions.”
“No base class down-calling assumptions.”
![]() 6.4.1The last two rules touch the realm of contracts, in that the actual behavior of overridden methods must be discussed. However, they can also be understood from a technical perspective.
6.4.1The last two rules touch the realm of contracts, in that the actual behavior of overridden methods must be discussed. However, they can also be understood from a technical perspective.
Fig. 3.4 illustrates the problematic cases underlying the two rules (following the code in [185, §3]). The levels B for the base class and S for the subclass are clear. We inject the revision B′ of the base class in between, because it is able to intercept and redirect some of the method calls by dynamic dispatch. Also, B′ is supposed to “behave essentially the same as![]() 3.1.1 B”—although technically there is no inheritance relationship, behavioral subtyping should hold.
3.1.1 B”—although technically there is no inheritance relationship, behavioral subtyping should hold.
Figure 3.4 Self-Calls in Fragile Base Classes
Let us start with the situation in Fig. 3.4(a). The revision B′ has a method f that at some point, either directly or indirectly through other methods, invokes g. Now the revision can make the mistake of expecting that dynamic dispatch will actually result in executing its own method g, whose behavior it knows exactly. But of course, the subclass S is not aware of that g and may override that method for its own purposes, probably with quite a different behavior. The revision B′ breaks the application, because method f does not work as expected with the different g.
An analogous situation is shown in Fig. 3.4(b). The subclass has a method f that calls a method h, which probably implements some generic![]() 3.1.4 mechanism or infrastructure. From looking at the code of B, the subclass knows that h will eventually delegate to g and expects that dynamic dispatch selects it own method g, whose behavior it knows exactly. The method f therefore relies on the exact behavior of the final g, an assumption that gets broken when the revision B′ overrides h and modifies the self-calling structure, for instance by inlining the code of g.
3.1.4 mechanism or infrastructure. From looking at the code of B, the subclass knows that h will eventually delegate to g and expects that dynamic dispatch selects it own method g, whose behavior it knows exactly. The method f therefore relies on the exact behavior of the final g, an assumption that gets broken when the revision B′ overrides h and modifies the self-calling structure, for instance by inlining the code of g.
Even in self-calls, methods must expect only the behavior of the base class.
In both cases, the problem arises from the additional and unjustified assumption that a particular method will be executed by dynamic dispatch. In both cases, special knowledge about the expected target method is exploited. The base class is fragile because revisions that invalidate this assumption break the overall application, even though the revision itself may be well within its rights: It overrides existing methods without changing their specified behavior.
But how can the inheritance hierarchy be made stable under such possible revisions? The core idea in both cases is simply this: Because it is uncertain which method will actually be executed in the end, all code must be written to work with the documentation stated in the base class, because then it will work with any possible overriding. In the case of Fig. 3.4(a), the method f in B′ works with the overridden g in S if it assumes the behavior documented for g in B. In Fig. 3.4(b), f in S will not be derailed just because B′ happens to change the call structure by inlining.
This reasoning will later be linked easily to the idea of contract inheritance,![]() 6.4.1 which states that methods must obey the contract of the method that they override, while all callers, including self-calls, always work with the contract specified for the overridden method.
6.4.1 which states that methods must obey the contract of the method that they override, while all callers, including self-calls, always work with the contract specified for the overridden method.
3.2 Interfaces
While inheritance is an attractive mechanism for both code reuse and classification of objects, it creates an unfortunate link between implementation![]() 232,69,160 and classification. The accepted goal of behavioral subtyping sometimes
232,69,160 and classification. The accepted goal of behavioral subtyping sometimes![]() 3.1.3 suggests several different views on the same object, which cannot be achieved
3.1.3 suggests several different views on the same object, which cannot be achieved![]() 2.4.2 using a single available inheritance slot. Multiple inheritance, by comparison, introduces further complexities into the language.
2.4.2 using a single available inheritance slot. Multiple inheritance, by comparison, introduces further complexities into the language.
Java’s way out is its interfaces mechanism. Interfaces merely specify which methods will be present in an object, but do not provide an implementation.2
2. Java 8 features default implementations for interface methods that can be given directly in the interface. Their purpose is to enable extensions to interfaces, in particular in the Collections API, without breaking existing code (see also Section 3.2.5).
Interfaces completely decouple the existence of methods from their implementation.
The compiler merely checks that the concrete class has all the required methods. This point is actually central, because it establishes the freedom associated with interfaces: The interfaces can be seen as behavioral “tags” attached to objects for the benefit of their clients.
To illustrate the degree of independence, consider a base class with a method work:
interfaces.Bases
public class Base {
public void work() {
...
}
}
Suppose later on it is decided that “working” is a common behavior and should be captured in an interface:
interfaces.Behavior
public interface Behavior {
void work();
}
Then, it is possible to tag the Base implementation in retrospect. In the following class, the compiler just checks that the required method is present:
interfaces.Derived
public class Derived extends Base implements Behavior {}
Similarly, an abstract class can promise to implement an interface and defer the actual method implementations to its subclasses.
Tool: Create Completed Implementation Class
Implementing interfaces in a class is so common that there are several ways to generate stubs for the necessary methods. In the New/Class wizard, you can select the interfaces and check Create stubs for ... Inherited Abstract Methods. Next, you can simply list the interface in theimplements clause and Quick-Fix (Ctrl-1). Then, you can override the methods through Source/Override or implement methods or by writing the method name and auto-completing the code (Ctrl-Space).
![]() Those readers who are familiar with the internals of the efficient virtual method dispatch in C++ and the problems in extending it to multiple inheritance may wonder
Those readers who are familiar with the internals of the efficient virtual method dispatch in C++ and the problems in extending it to multiple inheritance may wonder![]() 239 whether interfaces are sufficiently efficient for large-scale use. It turns out that with
239 whether interfaces are sufficiently efficient for large-scale use. It turns out that with![]() 3,4 suitable engineering precautions, method invocations through interfaces require roughly one memory indirection more than method dispatch in single inheritance hierarchies. With the size of caches available today, this will hardly matter. The implementation effort saved through the clarified structure is always worth the very small runtime penalty.
3,4 suitable engineering precautions, method invocations through interfaces require roughly one memory indirection more than method dispatch in single inheritance hierarchies. With the size of caches available today, this will hardly matter. The implementation effort saved through the clarified structure is always worth the very small runtime penalty.
Don’t over-engineer your interfaces.
Before we embark on an investigation of interface usage, we point out that interfaces involve the danger of over-engineering a design. Because interfaces can be defined independently of an eventual implementation, there is the temptation to capture any facet of behavior that might seem important as an interface. Although this gives you the good feeling of writing down some actual code, it usually does not lead to the “simplest thing that could work.” As a rule of thumb, any interface must be justified by some client object that uses the interface and that could not work with the concrete class directly. If you can eliminate an interface from your design, you will help your team members and the maintenance programmers, because they will have to understand one thing less and because they can work with calls to concrete methods whose code they can inspect without debugging.
3.2.1 Behavioral Abstraction
The central point of interfaces is that they can capture pieces of behavior that are exhibited by different objects throughout the system. It is not important how the individual objects are constructed; it only matters that in the end they show some expected behavior. In the context of design, we![]() 11.3.3.7 will speak of roles that are taken on by different objects.
11.3.3.7 will speak of roles that are taken on by different objects.
Interfaces capture common behavior exhibited by kinds of different objects.
A typical example is the concept of a “selection” in editing. Whether in text editors, in the outline view, in the package explorer, or in the problems view, the user can always pick some part of the data and manipulate it. The corresponding objects all give access to a “selection” of some sort (lines 2–3 in the next example). Of course, clients will usually be interested in changes to the selection as well. For instance, they may want to enable or disable menu entries or buttons depending on the current selection. The common behavior![]() 2.1 therefore includes the OBSERVER pattern (lines 4–7), so that clients can register and de-register for change notifications. The converse also holds: The clients themselves are classified as ISelectionChangedListeners—that is, as objects capable of receiving the generated notifications.
2.1 therefore includes the OBSERVER pattern (lines 4–7), so that clients can register and de-register for change notifications. The converse also holds: The clients themselves are classified as ISelectionChangedListeners—that is, as objects capable of receiving the generated notifications.
org.eclipse.jface.viewers.ISelectionProvider
1 public interface ISelectionProvider {
2 public ISelection getSelection();
3 public void setSelection(ISelection selection);
4 public void addSelectionChangedListener
5 (ISelectionChangedListener listener);
6 public void removeSelectionChangedListener
7 (ISelectionChangedListener listener);
8 }
Here is a second example. There are many different kinds of editors and views in the Eclipse workbench. Some of them enable editing of files or other resources, so that they can become “dirty” and need to be “saved.” Furthermore, Eclipse takes care of saving the changes to avoid data loss. Together, these common aspects of behavior are captured by the following interface:
org.eclipse.ui.ISaveablePart
public interface ISaveablePart {
public boolean isDirty();
public void doSave(IProgressMonitor monitor);
public boolean isSaveOnCloseNeeded();
...
}
Design interfaces to match a concept, not the first implementing class.
In the preceding examples, the interfaces could be explained and understood from an abstract description of a conceptual behavior. It was not necessary to even look at concrete implementing classes to understand what the interfaces demand. This observation constitutes a good general guideline: The more you keep the definition of an interface independent of its eventual implementations, the higher the chances of reuse. Clients that work with the interface will work with any object implementing the interface, and the more objects that are able to implement the interface, the more objects that the client will work with.
![]()
![]() 3.2.7Eclipse offers a tool Extract Interface, which we will discuss later. Merely introducing an interface for an existing class does not enhance reusability. Instead, it clutters the source code with a useless abstraction that is, and in all probability will be, implemented only by a single class. Maintenance developers will see the interface and must take into account the potential of several implementors, rather than working with their knowledge of a single concrete class.
3.2.7Eclipse offers a tool Extract Interface, which we will discuss later. Merely introducing an interface for an existing class does not enhance reusability. Instead, it clutters the source code with a useless abstraction that is, and in all probability will be, implemented only by a single class. Maintenance developers will see the interface and must take into account the potential of several implementors, rather than working with their knowledge of a single concrete class.
Interfaces, like classes, must justify their existence by an added value.
3.2.2 Client-Specific Classification and Abstraction
The previous section advocated defining interfaces from some abstract concept that characterizes the behavior of several different objects. To find such concepts, it is sometimes useful to start from one particular client and its expectations on the objects it will work with. The Eclipse workbench contains several such examples.
• The Properties view shows the detailed settings on the current selection. Toward that end, it requests an IPropertySheetPage from the current editor.
• A marker is an annotation, such as a warning or an error, attached to some file. The interface IGotoMarker is then a behavior of an editor that allows outside clients to scroll the editor to a given marker without knowing anything about the editor’s content. The interface is (essentially) used only in the following IDE facade method:![]() 1.7.2
1.7.2
org.eclipse.ui.ide.IDE
public static void gotoMarker(IEditorPart editor,
IMarker marker) {
IGotoMarker gotoMarker = null;
gotoMarker =
(IGotoMarker) editor.getAdapter(IGotoMarker.class);
if (gotoMarker != null) {
gotoMarker.gotoMarker(marker);
}
}
• The auto-completion pop-up in the Java editor is a generic component that internally delegates the choice of possible completions to any object implementing the following interface, which allows implementors to compute a list of proposals on demand.
org.eclipse.jdt.ui.text.java.IJavaCompletionProposalComputer
public interface IJavaCompletionProposalComputer {
List<ICompletionProposal> computeCompletionProposals(
ContentAssistInvocationContext context,
IProgressMonitor monitor);
...
}
This example is prototypical of a client-specific interface: There is a single call site for this method, and that caller is, again, called from only one point, and this continues four levels up the call hierarchy.
The first observation to be made from these examples is a special case of an earlier guideline:![]() 1.1
1.1
Define interfaces from the clients’ perspective.
Since the goal of interfaces is to enable clients to work with different kinds of objects, it is a good idea to start from the clients’ expectations and to consider how the interface must be defined to make the clients’ code look elegant and natural.
Client-specific interfaces enable generic, reusable clients.
We have previously stated that defining an interface from its first implementation can be harmful. In contrast, defining an interface from its first and perhaps only client’s perspective usually enhances flexibility, since the client will work with different objects that may not even exist in the system as yet.
One possible pitfall is the inadvertent creation of an interface that can be implemented usefully in only one class. Thus, whenever you define an interface, make sure that there can be different useful implementations in the system.
Client-specific interfaces help tame change.
A complementary result of client-specific interfaces is that each client will depend on only those aspects of a concrete object that are accessible through its special interface. Any other methods and services not available here can then be changed without affecting the client. Especially for larger objects![]() 170,169 with many different sorts of clients, this is a distinct advantage. Martin
170,169 with many different sorts of clients, this is a distinct advantage. Martin![]() 11.5.6 terms this insight the Interface Segregation Principle (ISP): “Many client-specific interfaces are better than one general-purpose interface.”
11.5.6 terms this insight the Interface Segregation Principle (ISP): “Many client-specific interfaces are better than one general-purpose interface.”
Use EXTENSION OBJECTS to provide extended views on an object.
In practice, it happens very often that a new client finds that its target object![]() 3.2.5 does not yet expose the functionality that the client requires. Extending an existing interface or superclass by new methods is problematic, because it breaks existing subclasses, since they do not yet provide these methods. Also, interfaces expressing key abstractions of the application will quickly become bloated.
3.2.5 does not yet expose the functionality that the client requires. Extending an existing interface or superclass by new methods is problematic, because it breaks existing subclasses, since they do not yet provide these methods. Also, interfaces expressing key abstractions of the application will quickly become bloated.
The solution is to see such extensions as specific views on the target![]() 98 object and to materialize them as extension objects, as the following pattern explains:
98 object and to materialize them as extension objects, as the following pattern explains:
Pattern: Extension Objects
To anticipate the need to extend an object’s interface in the future, define a method getExtension(type) that returns an adapter implementing a newly introduced interface, or null if the interface is not supported. The type parameter identifies the view requested by the client.
![]() This pattern is also known as EXTENSION INTERFACE, because you receive interfaces for extensions. This choice of name conflicts with the pattern of introducing extensions
This pattern is also known as EXTENSION INTERFACE, because you receive interfaces for extensions. This choice of name conflicts with the pattern of introducing extensions![]() 3.2.5 to interfaces described later on. The two patterns are entirely distinct and serve completely different purposes.
3.2.5 to interfaces described later on. The two patterns are entirely distinct and serve completely different purposes.
As a result, objects can expose new functionality without breaking existing subclasses.
Because it avoids extending existing interfaces by using separate interfaces![]() 3.2.5 for the extensions instead, this pattern is also known as EXTENSION INTERFACE.
3.2.5 for the extensions instead, this pattern is also known as EXTENSION INTERFACE.![]() 99,218 Furthermore, client-specific views can be defined by client-specific interfaces, which avoids bloating the object’s main interface with specialized functionality. Likewise, the implementation hierarchy remains independent of the abstraction hierarchies, which helps to build flexible systems. Finally, the different clients remain independent, since a change to one interface does not affect clients accessing the object through other interfaces.
99,218 Furthermore, client-specific views can be defined by client-specific interfaces, which avoids bloating the object’s main interface with specialized functionality. Likewise, the implementation hierarchy remains independent of the abstraction hierarchies, which helps to build flexible systems. Finally, the different clients remain independent, since a change to one interface does not affect clients accessing the object through other interfaces.
The Eclipse platform uses this approach in many places. It dubs the pattern’s getExtension() method getAdapter(), which emphasizes the point that the returned object is in many cases really an adapter for the![]() 2.4.1 target object. For the pattern’s type, Eclipse uses the class of the expected interface. The method must return an object implementing the requested interface, or null if the requested view is not available.
2.4.1 target object. For the pattern’s type, Eclipse uses the class of the expected interface. The method must return an object implementing the requested interface, or null if the requested view is not available.
org.eclipse.core.runtime.IAdaptable
public interface IAdaptable {
public Object getAdapter(Class adapter);
}
For instance, editors offer their document’s structure to the Outline view you are familiar with through an IContentOutlinePage. Each editor provides its own implementation of the interface to represent the structure of the edited content. Here is the example of the JavaEditor.
org.eclipse.jdt.internal.ui.javaeditor.JavaEditor
public Object getAdapter(Class required) {
if (IContentOutlinePage.class.equals(required)) {
if (fOutlinePage == null)
fOutlinePage = createOutlinePage();
return fOutlinePage;
}
...
return super.getAdapter(required);
}
protected JavaOutlinePage createOutlinePage() {
JavaOutlinePage page=
new JavaOutlinePage(fOutlinerContextMenuId, this);
setOutlinePageInput(page, getEditorInput());
return page;
}
![]()
![]() 50(Ch.5)The Netbeans Rich Client Platform employs the similar concept of Lookups. Lookups are conceptually bags of adapters, which are accessed through the method lookup(). Analogously to getAdapter(), clients can discover an object’s capabilities, or can, at a global level, retrieve dependencies and service implementations from the default lookup.
50(Ch.5)The Netbeans Rich Client Platform employs the similar concept of Lookups. Lookups are conceptually bags of adapters, which are accessed through the method lookup(). Analogously to getAdapter(), clients can discover an object’s capabilities, or can, at a global level, retrieve dependencies and service implementations from the default lookup.
3.2.3 Abstraction Hierarchies
Interfaces, like inheritance, can be used to create fine-grained abstraction or specialization hierarchies. In contrast to inheritance, one can define behavioral distinctions freely, without worrying about the implementation for the moment. Interfaces can capture specializations from the clients’ perspective, without restricting at the same time the choices of the later implementors. For this reason, interfaces are nowadays preferred over inheritance for that purpose.
As an example, different kinds of “selections” naturally occur when editing in Eclipse: The user may select parts of text, or single or multiple elements in a table or tree. Correspondingly, the base interface ISelection has a single method isEmpty that determines whether anything has been selected. Buttons and menu items can use this, for instance, to determine whether they are enabled. Next, an IStructuredSelection deals with lists of data items that can be selected. It is used by tables and trees in the user interface and enables clients to access one or all selected elements.
org.eclipse.jface.viewers.IStructuredSelection
public interface IStructuredSelection extends ISelection {
public Object getFirstElement();
public Iterator iterator();
public int size();
public Object[] toArray();
public List toList();
}
Tree-like displays explicitly allow the same data item to be shown at different tree nodes—for instance, when the data structure itself involves structure sharing. Selections in trees therefore can be described more precisely by capturing the entire path to the selected elements.
org.eclipse.jface.viewers.ITreeSelection
public interface ITreeSelection extends IStructuredSelection {
public TreePath[] getPaths();
public TreePath[] getPathsFor(Object element);
}
Text-based selections in ITextSelection, in contrast, are characterized by their offset and length, and the text itself.
A second example is seen in an interface hierarchy paralleling that below JavaElement, the representation of Java language constructs inside the![]() 3.1.5 Eclipse IDE. This parallel construction is suggested by the BRIDGE pattern.
3.1.5 Eclipse IDE. This parallel construction is suggested by the BRIDGE pattern.![]() 12.2.1.5
12.2.1.5 ![]() 100 The interfaces derive fromIJavaElement. For instance, an IMethod is-an IMember, which is-an IJavaElement; similarly, an IField is-an IMember. It is interesting to note here that the interface hierarchy is much cleaner than the class hierarchy, because it is not cluttered with considerations about data storage and resource accesses. For instance, the interface IMethod is implemented by BinaryMethod and SourceMethod, depending on whether the method is found in a JAR archive or in a source file. These classes are located below BinaryMember and SourceMember, respectively, because they require different access paths to the details such as the annotations and parameters. From a client’s perspective, however, all that matters is that these details can be obtained. We conclude:
100 The interfaces derive fromIJavaElement. For instance, an IMethod is-an IMember, which is-an IJavaElement; similarly, an IField is-an IMember. It is interesting to note here that the interface hierarchy is much cleaner than the class hierarchy, because it is not cluttered with considerations about data storage and resource accesses. For instance, the interface IMethod is implemented by BinaryMethod and SourceMethod, depending on whether the method is found in a JAR archive or in a source file. These classes are located below BinaryMember and SourceMember, respectively, because they require different access paths to the details such as the annotations and parameters. From a client’s perspective, however, all that matters is that these details can be obtained. We conclude:
Abstraction by interfaces can concentrate on the clients’ perspective.
3.2.4 Multiple Classification
One of the drawbacks of inheritance hierarchies is that one must decide on a single way of classifying objects that must, furthermore, be aligned with the objects’ implementation. The latter point has already been discussed in the previous section. Now we will exhibit the utility of implementing multiple interfaces in one class.
Multiple classification can represent facets of behavior for different clients.
We have pointed out previously that it is useful to design interfaces based on![]() 3.2.1 particular clients’ expectations. With respect to classification and abstraction, this guideline induces the idea of taking apart an object’s behavior according to multiple possible views, and choosing corresponding abstraction hierarchies.
3.2.1 particular clients’ expectations. With respect to classification and abstraction, this guideline induces the idea of taking apart an object’s behavior according to multiple possible views, and choosing corresponding abstraction hierarchies.
Consider again an IMember in Eclipse’s Java model, which is the super-type of methods and fields. That interface extends four super-interfaces to capture different aspects of working with methods and fields: (1) As an IJavaElement, it is part of the tree structure extracted from the sources![]() 2.3.1 and compiled classes. (2) As an IParent, it is actually an inner node of that tree structure that exposes its children as generic IJavaElements. This can be used for displaying and browsing the structure in the user interface.
2.3.1 and compiled classes. (2) As an IParent, it is actually an inner node of that tree structure that exposes its children as generic IJavaElements. This can be used for displaying and browsing the structure in the user interface.
org.eclipse.jdt.core.IParent
public interface IParent {
IJavaElement[] getChildren() throws JavaModelException;
boolean hasChildren() throws JavaModelException;
}
(3) As an ISourceReference, it can be asked about its original location. For compiled classes in JAR archives, the information is taken from the class file and can be used to link to a separate source tree that you attach in the JAR’s properties.
org.eclipse.jdt.core.ISourceReference
public interface ISourceReference {
boolean exists();
String getSource() throws JavaModelException;
ISourceRange getSourceRange() throws JavaModelException;
ISourceRange getNameRange() throws JavaModelException;
}
(4) As an ISourceManipulation, the member can be copied, deleted, moved, and renamed. Those methods are geared toward the corresponding refactoring operations.
3.2.5 Extension Interface
One strategic problem with interfaces is that they cannot be changed easily: Once they are published, you must assume that some classes out there implement them, so any change to the interface breaks all of those implementors, since they suddenly no longer match the interface. At the very least, it forces all implementing classes to be adapted accordingly. The first conclusion to be drawn is this:
Design interfaces carefully when you introduce and publish them.
From a practical perspective, the challenge is often one of API versioning. Clients prefer backward compatibility in APIs, but sometimes this just cannot be achieved because the initial API design is known to be unstable. For instance, some of the expected uses of the API may not have been implemented, so that their requirements have not yet been integrated fully. In such cases, it is customary to make the status of the API explicit:
Publish provisional APIs until you are sure of the design decisions.
One important change is the extension of interfaces. Even if you think broadly about the possible clients using the interface, you can never be sure that the next client will not need further support for its operations. Sometimes, you may also learn about better ways of collaboration, simply by writing more client code that accesses the interface.
Pattern: Extension Interface
To extend an interface, introduce a derived interface and use downcasts.
Naming convention: For the new interface choose the original name and append a number to document the various extensions, starting with 2.
As an example, we have seen the behavioral abstraction ISaveablePart,![]() 3.2.1 which should be sufficient for editor-like implementors. When the editor is closed in some way and its content has been modified, the workbench will ask the user whether it should save the changes and then invokes doSave() on the editor. Only later was it realized that some parts might profit from an extended collaboration, where the saveable part itself prompts the user in a specialized manner. This new collaboration is enabled by the following extension interface (the interface defines constants for the return value):
3.2.1 which should be sufficient for editor-like implementors. When the editor is closed in some way and its content has been modified, the workbench will ask the user whether it should save the changes and then invokes doSave() on the editor. Only later was it realized that some parts might profit from an extended collaboration, where the saveable part itself prompts the user in a specialized manner. This new collaboration is enabled by the following extension interface (the interface defines constants for the return value):
org.eclipse.ui.ISaveablePart2
public interface ISaveablePart2 extends ISaveablePart {
...
public int promptToSaveOnClose();
}
For instance, the Variables view, which you are familiar with from debugging in Eclipse, just decides that it will always have its current state saved to disk.
org.eclipse.debug.internal.ui.views.variables.VariablesView
public int promptToSaveOnClose() {
return ISaveablePart2.YES;
}
When it comes to working with the saveable parts, the extension interface must be taken into account by dynamic type checking and downcasts. First, the logic in SaveableHelper checks whether the saveable happens to implement the extension interface, and if so, gives it the chance of an extended collaboration. If the interface is not implemented, or the saveable answers that the old-style prompt is sufficient, the logic falls back to that prompt.
org.eclipse.ui.internal.SaveableHelper.savePart
int choice = USER_RESPONSE;
if (saveable instanceof ISaveablePart2) {
choice = ((ISaveablePart2) saveable).promptToSaveOnClose();
}
if (choice == USER_RESPONSE || choice == ISaveablePart2.DEFAULT) {
// Standard Eclipse prompt
...
}
This example shows that extension interfaces come at the cost of making clients more complex. Furthermore, the implementors of the interface must make sure that they continue to work with old-style clients that are not aware of the extension.
Consider EXTENSION OBJECTS as an alternative.
![]() 3.2.2The EXTENSION OBJECTS pattern offers a partial remedy to the problems outlined previously: If the extension to an interface is done on behalf of specific clients, then it might be better to introduce a completely separate interface and have the object hand out an adapter implementing the interface.
3.2.2The EXTENSION OBJECTS pattern offers a partial remedy to the problems outlined previously: If the extension to an interface is done on behalf of specific clients, then it might be better to introduce a completely separate interface and have the object hand out an adapter implementing the interface.
3.2.6 Specifying Callbacks
The examples of behavioral abstraction seen so far have involved quite specific assumptions on the appropriate reaction of the implementing object. In short, the client expected the object to perform some specified service.![]() 7.11 In many cases, however, the situation is reversed. When the client calls a method through an interface, this is really a service to the object: The client
7.11 In many cases, however, the situation is reversed. When the client calls a method through an interface, this is really a service to the object: The client![]() 10
10 ![]() 7.3.2 notifies the object that something interesting has happened, but leaves the decision about an appropriate reaction entirely to the target object. The interface merely captures the technical necessity that some method exists.
7.3.2 notifies the object that something interesting has happened, but leaves the decision about an appropriate reaction entirely to the target object. The interface merely captures the technical necessity that some method exists.
![]() 2.1This situation occurs in particular with the OBSERVER pattern, where the caller notifies the target object about a state change. It also occurs
2.1This situation occurs in particular with the OBSERVER pattern, where the caller notifies the target object about a state change. It also occurs![]() 7.1 prototypically in connection with user interfaces, where the application is notified about user interactions. For instance, to receive information about mouse clicks, the application implements the following interface:
7.1 prototypically in connection with user interfaces, where the application is notified about user interactions. For instance, to receive information about mouse clicks, the application implements the following interface:
org.eclipse.swt.events.MouseListener
public interface MouseListener extends SWTEventListener {
public void mouseDown(MouseEvent e);
public void mouseUp(MouseEvent e);
public void mouseDoubleClick(MouseEvent e);
}
3.2.7 Decoupling Subsystems
Interfaces have the most wonderful property of purging concrete classes from client code: Clients can work with the interface alone; the concrete class is irrelevant. This property can be used to make subsystems less dependent![]() 12.1 on one another, a phenomenon known as decoupling. Fig. 3.5 gives the main idea. In this figure, Module B implements some functionality in a class Target. However, the developers are not sure about some of its aspects—whether it is the name, the inheritance hierarchy, or part of the class’s API. They decide to publish only just enough information for the Client to start operating—that’s API design on a need-to-know basis. Accordingly, the developers define an interface I that captures just those parts that they are sure about. If necessary, they also define an interface N that captures notifications issued by the Target. The final result is as desired: The developers remain free to change all the aspects of Target that are not yet published in either I or N. They can even make such far-reaching modifications as changing the inheritance hierarchy above Target. The interfaces on the module’s boundary effectively form a shell around its internals.
12.1 on one another, a phenomenon known as decoupling. Fig. 3.5 gives the main idea. In this figure, Module B implements some functionality in a class Target. However, the developers are not sure about some of its aspects—whether it is the name, the inheritance hierarchy, or part of the class’s API. They decide to publish only just enough information for the Client to start operating—that’s API design on a need-to-know basis. Accordingly, the developers define an interface I that captures just those parts that they are sure about. If necessary, they also define an interface N that captures notifications issued by the Target. The final result is as desired: The developers remain free to change all the aspects of Target that are not yet published in either I or N. They can even make such far-reaching modifications as changing the inheritance hierarchy above Target. The interfaces on the module’s boundary effectively form a shell around its internals.
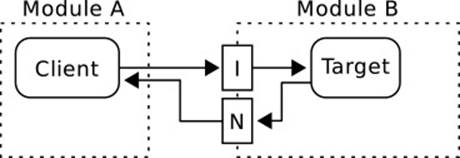
Figure 3.5 Decoupling Subsystems Through Interfaces
We have already seen an example of such decoupling, in the Eclipse![]() 3.1.5
3.1.5 ![]() 3.2.3
3.2.3 ![]() 3.2.4 Java model. That central module represents the structure of the projects and source code you are editing. It also updates the structure as you edit; the outline view and package explorer are adapted a few hundred milliseconds after you stop typing. Furthermore, memory consumption is kept acceptable by only caching the computed information on a most recently
3.2.4 Java model. That central module represents the structure of the projects and source code you are editing. It also updates the structure as you edit; the outline view and package explorer are adapted a few hundred milliseconds after you stop typing. Furthermore, memory consumption is kept acceptable by only caching the computed information on a most recently![]() 99(Ch.33) used basis and throwing it away when your focus of editing activities moves elsewhere. Surely, this behavior requires some rather nifty and probably complex internal logic, which is implemented in the package org.eclipse.jdt.internal.core. Of these classes, we have already looked at the inheritance hierarchy below JavaElement.
99(Ch.33) used basis and throwing it away when your focus of editing activities moves elsewhere. Surely, this behavior requires some rather nifty and probably complex internal logic, which is implemented in the package org.eclipse.jdt.internal.core. Of these classes, we have already looked at the inheritance hierarchy below JavaElement.![]() 3.1.5
3.1.5
Decoupling through interfaces protects clients from a module’s intricacies.
Clients, however, are not interested in these internals. Their expectation is quite simply the same as yours as a user: The data structure should roughly resemble the graphical display in the package explorer, where you start from projects, then dig down through packages, to individual classes, and further down to the class’s methods and fields. The Java model presents this nice outside view through interfaces in the package org.eclipse.jdt.core. At the top of the abstraction hierarchy, IJava Element![]() 2.3.1 is just one node in the nested structure. More specifically, an IJavaProject is clearly a project, an ICompilationUnit is a source file, an IType is a class or an interface, and so on. When you browse this hierarchy in Eclipse and look at the interfaces’ methods, you will find that they correspond closely to the information displayed in the explorer views.
2.3.1 is just one node in the nested structure. More specifically, an IJavaProject is clearly a project, an ICompilationUnit is a source file, an IType is a class or an interface, and so on. When you browse this hierarchy in Eclipse and look at the interfaces’ methods, you will find that they correspond closely to the information displayed in the explorer views.
Tool: Extract Interface
If you have the concrete implementation ready and have decided which aspects of the class’s API should be public, you can use Refactor/Extract Interface (Alt-Shift-T E) to create a corresponding interface.
Applying this tool results in a major inconvenience in the daily work with Eclipse: You can no longer jump from a method call to the method’s definition with Open Declaration (F3), because that simply takes you to the interface. The Eclipse developers have seen this problem and have provided the solution in a separate tool:
Tool: Open Implementation
To find the concrete method implementation hidden behind an interface, use the menu item Navigate/Open Implementation. This is also accessible in a pop-up menu by pressing Ctrl while hovering over a method call.
Provide abstract factories or facades to create objects.
One technical detail of decoupling by interfaces is that clients cannot create objects from the published interfaces alone. The module must offer![]() 1.4.12 other objects to perform those creations. We have already seen the relevant techniques: An ABSTRACT FACTORY is an object that creates objects conforming to some abstract type, in this case an interface. In the current
1.4.12 other objects to perform those creations. We have already seen the relevant techniques: An ABSTRACT FACTORY is an object that creates objects conforming to some abstract type, in this case an interface. In the current![]() 1.7.2 context, this pattern can be combined with a FACADE to define a simple entry point and hide the internals of the module completely.
1.7.2 context, this pattern can be combined with a FACADE to define a simple entry point and hide the internals of the module completely.
The Java model offers a facade JavaCore, whose static methods can create the desired objects. For instance, you can get the structure of a Java source file through the method:
org.eclipse.jdt.core.JavaCore
public static ICompilationUnit createCompilationUnitFrom(IFile file)
Make the insulation complete.
Hiding a few classes behind interfaces is certainly worthwhile if these are focal points of expected changes. However, the decoupling technique can be used to shield the client completely from the concrete types of a module. For instance, once you have a IJavaProject, you can manipulate its class path used for compilation:
org.eclipse.jdt.core.IJavaProject
void setRawClasspath(IClasspathEntry[] entries,
IProgressMonitor monitor)
throws JavaModelException;
The necessary class path entries are obtained from JavaCore—for instance, by using the following methods:
org.eclipse.jdt.core.JavaCore
public static IClasspathEntry newSourceEntry(IPath path)
public static IClasspathEntry newLibraryEntry(IPath path,
IPath sourceAttachmentPath, IPath sourceAttachmentRootPath)
In the end, the interfaces that define the module’s boundary form a complete capsule or shell around the concrete implementation classes. As a result, the entire implementation could be changed for the next release. Furthermore, clients can be sure that they do not need to understand the internals at all.
Use OSGi to enforce your restrictions.
The standard JVM class loader treats all JARs, packages, and classes on the class path the same: They all belong to a large, global pool of available types. OSGi (Open Services Gateway initiative) is a platform for building![]() A.1 modular Java software. The OSGi class loader, in contrast, honors the declaration of exported packages from each module’s self-description in its MANIFEST.MF file. The Java model, for instance, exports the package org.eclipse.jdt.core, but not org.eclipse.jdt.core.internal. By putting all concrete types into hidden packages, clients cannot even work around the intended barrier by downcasting, because they cannot access the concrete types at all.
A.1 modular Java software. The OSGi class loader, in contrast, honors the declaration of exported packages from each module’s self-description in its MANIFEST.MF file. The Java model, for instance, exports the package org.eclipse.jdt.core, but not org.eclipse.jdt.core.internal. By putting all concrete types into hidden packages, clients cannot even work around the intended barrier by downcasting, because they cannot access the concrete types at all.
Interfaces for decoupling introduce an overhead that needs justification.
The preceding examples have shown not only the power, but also the drawbacks of introducing interfaces for decoupling:
• Clients cannot simply create objects, but must go through factory methods. Besides the notational overhead, clients can never argue about concrete types, but only about abstract behavior.
• Clients cannot subclass to adapt behavior according to their needs.![]() 1.4.11
1.4.11 ![]() 3.1.7 This invalidates a major advantage of object-oriented programming.
3.1.7 This invalidates a major advantage of object-oriented programming.
• In consequence, the developers of the decoupled module must spend![]() 3.1.4
3.1.4 ![]() 7.3.3 more effort to make explicit all possible points of adaptation, usually through notification interfaces (Fig. 3.5). That is, whenever an
7.3.3 more effort to make explicit all possible points of adaptation, usually through notification interfaces (Fig. 3.5). That is, whenever an![]() 12.3.2 adaptation point is reached, the client gets a callback to execute application-specific code.
12.3.2 adaptation point is reached, the client gets a callback to execute application-specific code.
This overhead needs to be justified and balanced by corresponding benefits to the concrete architecture: Do clients get simpler because they are shielded from the module’s intricacies? Are the expected future changes actually likely to happen, and to the envisaged extent?
In the case of the Java model, the decision is clear. The Eclipse platform![]() 12.3.3 is meant to be extended by many clients through the plugin mechanism. Making the details of one of its core modules public would mean that almost any change to that module would break at least some existing clients. At the same time, the Java model is so complex that subclassing by clients is not likely to be beneficial or even possible anyway.
12.3.3 is meant to be extended by many clients through the plugin mechanism. Making the details of one of its core modules public would mean that almost any change to that module would break at least some existing clients. At the same time, the Java model is so complex that subclassing by clients is not likely to be beneficial or even possible anyway.
3.2.8 Tagging Interfaces
The interfaces that an object implements can be determined at runtime using the instanceof operator, or the reflection mechanism starting with getClass(). It is therefore possible to use them as simple static “tags” attached to objects. For instance, neither Cloneable norSerializable declares any methods. Their sole purpose is to act as flags that the generic field-wise object copy and object serialization by ObjectOutputStream, respectively, are applicable.
Similarly, empty interfaces can be used as bounds to type variables to introduce compile-time checks. For instance, an EventListener (in java.util) is an empty interface that ensures that one does not abuse Swing’s EventListenerList for storing arbitrary objects. The addmethod of that class specifies that only objects tagged as EventListeners can be entered:
javax.swing.event.EventListenerList
public synchronized <T extends EventListener>
void add(Class<T> t, T l)
Similar guards are added at other places in the library.
3.2.9 Management of Constants
![]() 1.3.8Interfaces can define not only methods, but also constants. These constants become available in all classes implementing the interface. Mostly, this feature is used in connection with methods, such as to define cases for return or parameter values for these methods. Sometimes, however, the interface is used for the sole purpose of gathering constants. For instance,
1.3.8Interfaces can define not only methods, but also constants. These constants become available in all classes implementing the interface. Mostly, this feature is used in connection with methods, such as to define cases for return or parameter values for these methods. Sometimes, however, the interface is used for the sole purpose of gathering constants. For instance,![]() 214 ColorConstants from the Graphical Editing Framework provides standard colors; the IContextMenuConstants from the Java tooling declares constants that enable other plugins to place menu contributions at specific points; and so on.
214 ColorConstants from the Graphical Editing Framework provides standard colors; the IContextMenuConstants from the Java tooling declares constants that enable other plugins to place menu contributions at specific points; and so on.
3.2.10 Inheritance Versus Interfaces
We have seen established usage of both inheritance and interfaces, and in particular their ability to introduce classifications and abstractions. When you have to decide between the two mechanisms, it is necessary to gain a vantage point from which the differences can be judged and weighed in the particular situation.
Prefer interfaces for capturing and classifying behavior.
Both mechanisms are equally capable of capturing some abstract behavior.![]() 3.1.3
3.1.3 ![]() 3.2.1 While traditionally class hierarchies were intended for this purpose, interfaces have nowadays taken over: They separate strictly behavioral subtyping from implementation issues, thereby avoiding the well-known problems
3.2.1 While traditionally class hierarchies were intended for this purpose, interfaces have nowadays taken over: They separate strictly behavioral subtyping from implementation issues, thereby avoiding the well-known problems![]() 232,162,160 with linking the two. The ability of multiple classification, up to the point
232,162,160 with linking the two. The ability of multiple classification, up to the point![]() 3.2.4 of client-specific interfaces, gives you the expressiveness and freedom to differentiate
3.2.4 of client-specific interfaces, gives you the expressiveness and freedom to differentiate![]() 3.2.2 views on an object in detail, without being restricted to a single classification scheme. Finally, the advances in efficient implementation of
3.2.2 views on an object in detail, without being restricted to a single classification scheme. Finally, the advances in efficient implementation of![]() 3 method dispatch for interfaces, together with the generally available computing power, have invalidated the need to optimize runtime or memory consumption by using single inheritance.
3 method dispatch for interfaces, together with the generally available computing power, have invalidated the need to optimize runtime or memory consumption by using single inheritance.
Prefer class hierarchies if common infrastructure can be created.
The ability to define common functionality, and to enable clients to contribute![]() 3.1.4
3.1.4 ![]() 3.1.3 through template methods, sets inheritance apart from interfaces.
3.1.3 through template methods, sets inheritance apart from interfaces.![]() 1.4.9 When creating such an infrastructure, be sure to obey the Liskov Substitution
1.4.9 When creating such an infrastructure, be sure to obey the Liskov Substitution![]() 3.1.1 Principle and to give a well-defined interface toward subclasses.
3.1.1 Principle and to give a well-defined interface toward subclasses.![]() 3.1.2 Also, be aware that subclassing is a rather heavyweight task, which often involves understanding the superclass’s mechanisms, if not its implementation, in some detail. Sometimes, it is better to move reusable functionality outside the class hierarchy altogether, or even force clients to reimplement
3.1.2 Also, be aware that subclassing is a rather heavyweight task, which often involves understanding the superclass’s mechanisms, if not its implementation, in some detail. Sometimes, it is better to move reusable functionality outside the class hierarchy altogether, or even force clients to reimplement![]() 1.4.8
1.4.8 ![]() 1.8.5 some small pieces of code.
1.8.5 some small pieces of code.
Use inheritance for fixed or limited case distinctions.
The introduction of an interface gives a signal to the human reader: At this point, clients can define their own, often arbitrary behavior and can add it to the system. For case distinctions, this is often not the intention at![]() 3.1.6 all. There, new cases cannot be defined freely, but should be tied closely to the existing cases and the common abstraction. This can be expressed by inheritance: Since there is a single inheritance slot, clients cannot “link in” arbitrary implementations, but must fit their contribution into the existing hierarchy.
3.1.6 all. There, new cases cannot be defined freely, but should be tied closely to the existing cases and the common abstraction. This can be expressed by inheritance: Since there is a single inheritance slot, clients cannot “link in” arbitrary implementations, but must fit their contribution into the existing hierarchy.
These few and rough guidelines on a very broad topic are certainly insufficient to decide whether to prefer inheritance or interfaces in specific cases. Even so, we hope that they have given you the general directions of the possible alternatives. At the same time, we would like to encourage you to find your own style and strategies: by reconsidering the different aspects in concrete situations you encounter in your daily work, and by studying existing code that you admire or find to be engineered soundly.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.