THE RUBY WAY, Third Edition (2015)
Chapter 11. OOP and Dynamic Features in Ruby
Of his quick objects hath the mind no part, Nor his own vision holds what it doth catch...
—William Shakespeare, “Sonnet 113”
This is an unusual chapter. Whereas many of the chapters in this book deal with a specific problem subdomain such as strings or files, this one doesn’t. If the “problem space” is viewed as stretching out on one axis of a graph, this chapter extends out on the other axis, encompassing a slice of each of the other areas. This is because object-oriented programming and dynamicity aren’t problem domains themselves but are paradigms that can be applied to any problem, whether it be system administration, low-level networking, or web development.
For this reason, much of this chapter’s information should already be familiar to a programmer who knows Ruby. In fact, the rest of the book wouldn’t make sense without some of the fundamental knowledge here. Any Ruby programmer knows how to create a subclass, for instance.
This raises the question of what to include and what to exclude. Does every Ruby programmer know about the extend method? What about the instance_eval method? What is obvious to one person might be big news to another.
We have decided to err on the side of completeness. We include in this chapter some of the more esoteric tasks you might want to do with dynamic OOP in Ruby, but we also include the more routine tasks in case anyone is unfamiliar with them. We go right down to the simplest level because people won’t agree on where the “middle” level ends. And we have tried to offer a little extra information even on the most basic of topics to justify their inclusion here. On the other hand, topics that are fully covered elsewhere in the book are omitted here.
We’ll also make two other comments. First, there is nothing magical about dynamic OOP. Ruby’s object orientation and its dynamic nature do interact with each other, but they aren’t inherently interrelated; we put them in a single chapter largely for convenience. Second, some language features might be mentioned here that aren’t strictly related to either topic. Consider this to be cheating, if you will. We wanted to put them somewhere.
11.1 Everyday OOP Tasks
If you don’t already understand OOP, you won’t learn it here. And if you don’t already understand OOP in Ruby, you probably won’t learn it here either. If you’re rusty on those concepts, you can scan Chapter 1, “Ruby in Review,” where we cover it rapidly (or you can go to another book).
On the other hand, much of this current chapter is tutorial oriented and fairly elementary. Therefore, it will be of some value to the beginner and perhaps less value to the intermediate Ruby programmer. We maintain that a book is a random access storage device, so you can easily skip the parts that don’t interest you.
11.1.1 Using Multiple Constructors
There is no real “constructor” in Ruby as there is in C++ or Java. The concept is certainly there because objects have to be instantiated and initialized, but the behavior is somewhat different.
In Ruby, a class has a class method called new, which is used to instantiate new objects. The new method calls the user-defined special method initialize, which then initializes the attributes of the object appropriately, and new returns a reference to the new object.
But what if we want to have multiple constructors for an object? How should we handle that?
There is nothing to prevent the creation of additional class methods that return new objects. Listing 11.1 shows a contrived example in which a rectangle can have two side lengths and three color values. We create additional class methods that assume certain defaults for some of the parameters. (For example, a square is a rectangle with all sides the same length.)
Listing 11.1 Multiple Constructors
class ColoredRectangle
def initialize(r, g, b, s1, s2)
@r, @g, @b, @s1, @s2 = r, g, b, s1, s2
end
def self.white_rect(s1, s2)
new(0xff, 0xff, 0xff, s1, s2)
end
def self.gray_rect(s1, s2)
new(0x88, 0x88, 0x88, s1, s2)
end
def self.colored_square(r, g, b, s)
new(r, g, b, s, s)
end
def self.red_square(s)
new(0xff, 0, 0, s, s)
end
def inspect
"#@r #@g #@b #@s1 #@s2"
end
end
a = ColoredRectangle.new(0x88, 0xaa, 0xff, 20, 30)
b = ColoredRectangle.white_rect(15,25)
c = ColoredRectangle.red_square(40)
So, we can define any number of methods that create objects according to various specifications. Whether the term constructor is appropriate here is a question that we will leave to the language lawyers.
11.1.2 Creating Instance Attributes
An instance attribute in Ruby is always prefixed by an @ sign. It is like an ordinary variable in that it springs into existence when it is first assigned.
In OO languages, we frequently create methods that access attributes to avoid issues of data hiding. We want to have control over how the internals of an object are accessed from the outside. Typically we use setter and getter methods for this purpose (although in Ruby we don’t typically use these terms). These are simply methods used to assign (set) a value or retrieve (get) a value, respectively.
Of course, it is possible to create these functions “by hand,” as shown here:
class Person
def name
@name
end
def name=(x)
@name = x
end
def age
@age
end
# ...
end
However, Ruby gives us a shorthand for creating these methods. The attr method takes a symbol as a parameter and creates the associated attribute. It also creates a getter of the same name, and if the optional second parameter is true, it creates a setter as well:
class Person
attr :name, true # Create @name, name, name=
attr :age # Create @age, age
end
The related methods attr_reader, attr_writer, and attr_accessor take any number of symbols as parameters. The first creates only “read” methods (to get the value of an attribute); the second creates only “write” methods (to set values); the third creates both. Here is an example:
class SomeClass
attr_reader :a1, :a2 # Creates @a1, a1, @a2, a2
attr_writer :b1, :b2 # Creates @b1, b1=, @b2, b2=
attr_accessor :c1, :c2 # Creates @c1, c1, c1=, @c2, c2, c2=
# ...
def initialize
@a1 = 237
@a2 = nil
end
end
Recall that assignment to a writer of this form can only be done with a receiver, so within a method, the receiver self must be used:
def update_ones(a1, b1, c1)
self.a1 = a1
self.b1 = b1
self.c1 = c1
end
Without invoking the method on self, Ruby will instead simply create a local variable inside the method with that name, which is not at all what we want in this case.
There is a special method to determine whether an instance variable is already defined:
obj = SomeClass.new
obj.instance_variable_defined?(:b2) # true
obj.instance_variable_defined?(:d2) # true
In accordance with our desire to use eval only when necessary, Ruby also has methods that can retrieve or assign instance variable values given the variable name as a string:
class MyClass
attr_reader :alpha, :beta
def initialize(a, b, g)
@alpha, @beta, @gamma = a, b, g
end
end
x = MyClass.new(10, 11, 12)
x.instance_variable_set("@alpha", 234)
p x.alpha # 234
x.instance_variable_set("@gamma", 345) # 345
v = x.instance_variable_get("@gamma") # 345
Note first of all that we do have to use the at-sign on the variable name; not to do so is an error. If this is unintuitive, remember that methods such as attr_accessor actually take a symbol used to name the methods, which is why they omit the at-sign.
You may wonder whether the existence of these methods is a violation of encapsulation. The answer is no.
It’s true these methods are powerful and potentially dangerous. They should be used cautiously, not casually. But it’s impossible to say whether encapsulation is violated without looking at how these tools are used.
If they are used intentionally as part of a good design, then all is well. If they are used to violate the design, or to circumvent a bad design, then all is not well. Ruby intentionally grants access to the interiors of objects for people who really need it; the mark of the responsible programmer is not to abuse that freedom.
11.1.3 Using More Elaborate Constructors
As objects grow more complex, they accumulate more attributes that must be initialized when an object is created. The corresponding constructor can be long and cumbersome, forcing us to count parameters and wrap the line past the margin.
One way to deal with this complexity is to pass in a block that accepts the new object to the initialize method (see Listing 11.2). We can then evaluate the block to initialize the object.
Listing 11.2 A “Fancy” Constructor
class PersonalComputer
attr_accessor :manufacturer,
:model, :processor, :clock,
:ram, :disk, :monitor,
:colors, :vres, :hres, :net
def initialize
yield self if block_given?
end
# Other methods...
end
desktop = PersonalComputer.new do |pc|
pc.manufacturer = "Acme"
pc.model = "THX-1138"
pc.processor = "Z1"
pc.clock = 9.6 # GHz
pc.ram = 512 # Gb
pc.disk = 20 # Tb
pc.monitor = 30 # inches
pc.colors = 16777216
pc.vres = 1600
pc.hres = 2000
pc.net = "OC-768"
end
p desktop
Note that we’re using accessors for our attributes so that we can assign values to them. Additionally, we could perform any arbitrary logic we wanted inside the body of this block. For example, we could derive certain fields from others by computation.
What if you didn’t really want an object to have accessors for each of the attributes? In that case, we could use instance_eval instead and make the setter methods protected. This could prevent “accidental” assignment of an attribute from outside the object:
class Library
attr_reader :shelves
def initialize(&block)
instance_eval(&block)
end
protected
attr_writer :shelves
end
branch = Library.new do
self.shelves = 10
end
branch.shelves = 20
# NoMethodError: protected method 'shelves=' called
branch.shelves # 10
Even when you are using instance_eval, explicit calls to setters on self are still required. A setter method always takes an explicit receiver to distinguish the method call from an ordinary assignment to a local variable.
11.1.4 Creating Class-Level Attributes and Methods
A method or attribute isn’t always associated with a specific instance of a class; it can be associated with the class itself. The typical example of a class method is the new method; it is always invoked in this way because it is called to create a new instance (and therefore can’t belong to any particular instance).
We can define class methods of our own. You have already seen this in Section 11.1.1, “Using Multiple Constructors.” However, their functionality certainly isn’t limited to constructors; they can be used for any general-purpose task that makes sense at the class level.
In this next highly incomplete fragment, we assume that we are creating a class to play sound files. The play method can reasonably be implemented as an instance method; we can instantiate many objects referring to many different sound files. However, the detect_hardwaremethod has a larger context, and depending on our implementation, it might not even make sense to create new objects if this method fails. Its context is that of the whole sound-playing environment rather than any particular sound file:
class SoundPlayer
MAX_SAMPLE = 192
def self.detect_hardware
# ...
end
def play
# ...
end
end
Notice that there is another way to declare this class method. The following fragment is essentially the same:
class SoundPlayer
MAX_SAMPLE = 192
def play
# ...
end
end
def SoundPlayer.detect_hardware
# ...
end
The only difference relates to constants declared in the class. When the class method is declared outside its class declaration, these constants aren’t in scope. For example, detect_hardware in the first fragment can refer directly to MAX_SAMPLE if it needs to; in the second fragment, the notation SoundPlayer::MAX_SAMPLE would have to be used instead.
Not surprisingly, there are class variables as well as class methods. These begin with a double @ sign, and their scope is the class rather than any instance of the class.
The traditional example of using class variables is counting instances of the class as they are created. But they can actually be used for any purpose in which the information is meaningful in the context of the class rather than the object. For a different example, see Listing 11.3.
Listing 11.3 Class Variables and Methods
class Metal
@@current_temp = 70
attr_accessor :atomic_number
def self.current_temp=(x)
@@current_temp = x
end
def self.current_temp
@@current_temp
end
def liquid?
@@current_temp >= @melting
end
def initialize(atnum, melt)
@atomic_number = atnum
@melting = melt
end
end
aluminum = Metal.new(13, 1236)
copper = Metal.new(29, 1982)
gold = Metal.new(79, 1948)
Metal.current_temp = 1600
puts aluminum.liquid? # true
puts copper.liquid? # false
puts gold.liquid? # false
Metal.current_temp = 2100
puts aluminum.liquid? # true
puts copper.liquid? # true
puts gold.liquid? # true
Note here that the class variable is initialized at the class level before it is used in a class method. Note also that we can access a class variable from an instance method, but we can’t access an instance variable from a class method. After a moment of thought, this makes sense.
But what happens if we try? What if we try to print the attribute @atomic_number from within the Metal.current_temp method? We find that it seems to exist—it doesn’t cause an error—but it has the value nil. What is happening here?
The answer is that we’re not actually accessing the instance variable of class Metal at all. We’re accessing an instance variable of class Class instead. (Remember that in Ruby, Class is a class!)
Such a thing is called a class instance variable (a term that comes from Smalltalk). For more comments on this, see Section 11.2.4, “Creating Parametric Classes.”
Listing 11.4 summarizes the situation.
Listing 11.4 Class and Instance Data
class MyClass
SOME_CONST = "alpha" # A class-level constant
@@var = "beta" # A class variable
@var = "gamma" # A class instance variable
def initialize
@var = "delta" # An instance variable
end
def mymethod
puts SOME_CONST # (the class constant)
puts @@var # (the class variable)
puts @var # (the instance variable)
end
def self.classmeth1
puts SOME_CONST # (the class constant)
puts @@var # (the class variable)
puts @var # (the class instance variable)
end
end
def MyClass.classmeth2
puts MyClass::SOME_CONST # (the class constant)
# puts @@var # error – out of scope
puts @var # (the class instance variable)
end
myobj = MyClass.new
MyClass.classmeth1 # alpha, beta, gamma
MyClass.classmeth2 # alpha, gamma
myobj.mymethod # alpha, beta, delta
We should mention that a class method can be made private with the method private_class_method. This works the same way private works at the instance level.
11.1.5 Inheriting from a Superclass
We can inherit from a class by using the < symbol:
class Boojum < Snark
# ...
end
Given this declaration, we can say that the class Boojum is a subclass of the class Snark, or in the same way, Snark is a superclass of Boojum. As we all know, every boojum is a snark, but not every snark is a boojum.
The purpose of inheritance, of course, is to add or enhance functionality. We are going from the more general to the more specific.
As an aside, many languages such as C++ implement multiple inheritance (MI). Ruby (like Java and some others) doesn’t allow MI, but the mixin facility can compensate for this; see Section 11.1.12, “Working with Modules.”
Let’s look at a (slightly) more realistic example. Suppose that we have a Person class and want to create a Student class that derives from it.
We’ll define Person this way:
class Person
attr_accessor :name, :age, :sex
def initialize(name, age, sex)
@name, @age, @sex = name, age, sex
end
# ...
end
And we’ll then define Student this way:
class Student < Person
attr_accessor :id_number, :hours
def initialize(name, age, sex, id_number, hours)
super(name, age, sex)
@id_number = id_number
@hours = hours
end
# ...
end
# Create two objects
a = Person.new("Dave Bowman", 37, "m")
b = Student.new("Franklin Poole", 36, "m", "000-13-5031", 24)
Now let’s look at what we’ve done here. What is this super that we see called from Student’s initialize method? It is simply a call to the corresponding method in the parent class. As such, we give it three parameters (whereas our own initialize method takes five).
It’s not always necessary to use super in such a way, but it is often convenient. After all, the attributes of a class form a superset of the attributes of the parent class, so why not use the parent’s constructor to initialize them?
Concerning what inheritance really means, it definitely represents the “is-a” relationship. A Student is a Person, just as we expect. Here are three other observations:
• Every attribute (and method) of the parent is reflected in the child. If Person had a height attribute, Student would inherit it, and if the parent had a method named say_hello, the child would inherit that, too.
• The child can have additional attributes and methods, as you have already seen. That is why the creation of a subclass is often referred to as “extending a superclass.”
• The child can override or redefine any of the attributes and methods of its parent.
This last point brings up the question of how a method call is resolved. How do you know whether you're calling the method of this particular class or its superclass?
The short answer is, you don’t know, and you don’t care. If we invoke a method on a Student object, the method for that class will be called if it exists. If it doesn’t, the method in the superclass will be called, and so on.
We say “and so on” because every class (except BasicObject) has a superclass. As an aside, BasicObject is a “blank slate” type of object that has even fewer methods than Object does.
What if we specifically want to call a superclass method, but we don’t happen to be in the corresponding method? We can always create an alias in the subclass before we do anything with it:
class Student # reopening class
# Assuming Person has a say_hello method...
alias :say_hi :say_hello
def say_hello
puts "Hi, there."
end
def formal_greeting
# Say hello the way my superclass would.
say_hi
end
end
There are various subtleties relating to inheritance that we don’t discuss here, but this is essentially how it works. Be sure to refer to the next section.
11.1.6 Testing Classes of Objects
Frequently we will want to know the answer to a question such as: What kind of object is this? Or how does it relate to this class? There are many ways of making this kind of determination.
First, the class method (that is, the instance method named class) always returns the class of an object:
s = "Hello"
n = 237
sc = s.class # String
nc = n.class # Fixnum
Don’t be misled into thinking that the thing returned by class or type is a string representing the class. It is an actual instance of the class Class! Therefore, if we wanted, we could call a class method of the target type as though it were an instance method of Class (which it is):
s2 = "some string"
var = s2.class # String
my_str = var.new("Hi...") # A new string
We could compare such a variable with a constant class name to see whether they are equal; we could even use a variable as the superclass from which to define a subclass! Confused? Just remember that in Ruby, Class is an object, and Object is a class.
Sometimes we want to compare an object with a class to see whether the object belongs to that class. The method instance_of? will accomplish this. Here is an example:
puts 5.instance_of?(Fixnum) # true
puts "XYZZY".instance_of?(Fixnum) # false
puts "PLUGH".instance_of?(String) # true
But what if we want to take inheritance relationships into account? The kind_of? method (similar to instance_of?) takes this issue into account. A synonym is is_a?, naturally enough, because what we are describing is the classic is-a relationship:
n = 9876543210
flag1 = n.instance_of? Bignum # true
flag2 = n.kind_of? Bignum # true
flag3 = n.is_a? Bignum # true
flag3 = n.is_a? Integer # true
flag4 = n.is_a? Numeric # true
flag5 = n.is_a? Object # true
flag6 = n.is_a? String # false
flag7 = n.is_a? Array # false
Obviously kind_of? or is_a? is more generalized than the instance_of? relationship. For an example from everyday life, every dog is a mammal, but not every mammal is a dog.
There is one surprise here for the Ruby neophyte. Any module that is mixed in by a class maintains the is-a relationship with the instances. For example, the Array class mixes in Enumerable; this means that any array is a kind of enumerable entity:
x = [1, 2, 3]
flag8 = x.kind_of? Enumerable # true
flag9 = x.is_a? Enumerable # true
We can also use the numeric relational operators in a fairly intuitive way to compare one class to another. We say “intuitive” because the less-than operator is used to denote inheritance from a superclass:
flag1 = Integer < Numeric # true
flag2 = Integer < Object # true
flag3 = Object == Array # false
flag4 = IO >= File # true
flag5 = Float < Integer # nil
Every class has the operator === (sometimes called the “threequal” operator) defined. The expression class === instance will be true if the instance belongs to the class. The relationship operator is usually known as the case equality operator because it is used implicitly in a casestatement. This is therefore a way to act on the class of an expression.
For more information on this operator, see Section 11.1.7, “Testing Equality of Objects.”
We should also mention the respond_to? method. This is used when we don’t really care what the class is but just want to know whether it implements a certain method. This, of course, is a rudimentary kind of type information. (In fact, we might say this is the most important type information of all.) The method is passed a symbol and an optional flag (indicating whether to include private methods in the search):
# Search public methods
if wumpus.respond_to?(:bite)
puts "It's got teeth!"
else
puts "Go ahead and taunt it."
end
# Optional second parameter will search
# private and protected methods as well.
if woozle.respond_to?(:bite, true)
puts "Woozles bite!"
else
puts "Ah, the non-biting woozle."
end
Sometimes we want to know what class is the immediate parent of an object or class. The instance method superclass of class Class can be used for this:
array_parent = Array.superclass # Object
fn_parent = 237.class.superclass # Integer
obj_parent = Object.superclass # BasicObject
basic_parent = BasicObject.superclass # nil
Every class except BasicObject will have a superclass.
11.1.7 Testing Equality of Objects
All animals are equal, but some are more equal than others.
—George Orwell, Animal Farm
When you write classes, it’s convenient if the semantics for common operations are the same as for Ruby’s built-in classes. For example, if your classes implement objects that may be ranked, it makes sense to implement the method <=> and mix in the Comparable module. Doing so means that all the normal comparison operators work with objects of your class.
However, the picture is less clear when it comes to dealing with object equality. Ruby objects implement five different methods that test for equality. Your classes might well end up implementing some of these, so let’s look at each in turn.
The most basic comparison is the equal? method (which comes from BasicObject). It returns true if its receiver and parameter have the same object ID. This is a fundamental part of the semantics of objects and shouldn’t be overridden in your classes.
The most common test for equality uses our old friend ==, which tests the values of its receiver with its argument. This is probably the most intuitive test for equality.
Next on the scale of abstraction is the method eql?, which is part of Object. (Actually, eql? is implemented in the Kernel module, which is mixed into Object.) Like the == operator, eql? compares its receiver and its argument, but it is slightly stricter. For example, different numeric objects will be coerced into a common type when compared using ==, but objects of different types will never test equal using eql?:
flag1 = (1 == 1.0) # true
flag2 = 1.eql?(1.0) # false
The eql? method exists for one reason: It is used to compare the values of hash keys. If you want to override Ruby’s default behavior when using your objects as hash keys, you’ll need to override the methods eql? and hash for those objects.
Two more equality tests are implemented by every object. The === method is used to compare the target in a case statement against each of the selectors, using selector === target. Although apparently complex, this rule allows Ruby case statements to be intuitive in practice. For example, you can switch based on the class of an object:
case an_object
when String
puts "It's a string."
when Numeric
puts "It's a number."
else
puts "It's something else entirely."
end
This works because class Module implements === to test whether its parameter is an instance of its receiver (or the receiver’s parents). Therefore, if an_object is the string “cat”, the expression String === an_object would be true, and the first clause in the case statement would fire.
Finally, Ruby implements the match operator =~. Conventionally, this is used by strings and regular expressions to implement pattern matching. However, if you find a use for it in other classes, you’re free to overload it.
The equality tests == and =~ also have negated forms, != and !~, respectively. These are implemented internally by reversing the sense of the non-negated form. This means that if you implement, say, the method ==, you also get the method != for free.
11.1.8 Controlling Access to Methods
In Ruby, an object is pretty much defined by the interface it provides: the methods it makes available to others. However, when writing a class, you often need to write other helper methods that are used within your class but dangerous if available externally. That is where the privatemethod of class Module comes in handy.
You can use private in two different ways. If in the body of a class or method definition you call private with no parameters, subsequent methods will be made private to that class or module. Alternatively, you can pass a list of method names (as symbols) to private, and these named methods will be made private. Listing 11.5 shows both forms.
Listing 11.5 Private Methods
class Bank
def open_safe
# ...
end
def close_safe
# ...
end
private :open_safe, :close_safe
def make_withdrawal(amount)
if access_allowed
open_safe
get_cash(amount)
close_safe
end
end
# make the rest private
private
def get_cash
# ...
end
def access_allowed
# ...
end
end
Because the attr family of statements effectively just defines methods, attributes are affected by access control statements such as private.
The implementation of private might seem strange but is actually clever. Private methods cannot be called with an explicit receiver: They are always called with an implicit receiver of self. This means that you can never invoke a private method in another object: There is no way to specify that other object as the receiver of the method call. It also means that private methods are available to subclasses of the class that defines them but again only in the same object.
The protected access modifier is less restrictive. Protected methods can be accessed only by instances of the defining class and its subclasses. As you saw in Section 11.1.3, “Using More Elaborate Constructors,” this allows calling setters on self (which is not allowed by private).
Protected methods can be invoked on other objects (as long as they are objects of the same class as the sender). A common use for protected methods is defining accessors to allow two objects of the same type to cooperate with each other. In the following example, objects of classPerson can be compared based on the person’s age, but that age is not accessible outside the Person class. The private attribute pay_scale may be read from inside the class, but not from outside the class, even by other objects of the same class:
class Person
attr_reader :name, :age, :pay_scale
protected :age
private :pay_scale
def initialize(name, age, pay_scale)
@name, @age, @pay_scale = name, age, pay_scale
end
def <=>(other)
age <=> other.age # allowed by protected
end
def same_rank?(other)
pay_scale == other.pay_scale # not allowed by private
end
def rank
case pay_scale
when 1..3
"lower"
when 4..6
"middle"
when 7..9
"high"
end
end
end
p1 = Person.new("Fred", 31, 5)
p2 = Person.new("Agnes", 43, 7)
x = p1.age # NoMethodError: protected method 'age'
compare = (p1 <=> p2) # -1
r = p1.rank # "middle"
x = p2.same_rank?(p1) # NoMethodError: private method 'pay_scale'
To complete the picture, the access modifier public is used to make methods public. This shouldn’t be a surprise.
As a final twist, normal methods defined outside a class or module definition (that is, the methods defined at the top level) are made private by default. Because they are defined in class Object, they are globally available, but they cannot be called with a receiver.
11.1.9 Copying an Object
The Ruby built-in methods Object#clone and #dup produce copies of their receiver. They differ in the amount of context about the object that they copy. The dup method copies just the object’s content, whereas clone also preserves things such as singleton classes associated with the object:
s1 = "cat"
def s1.upcase
"CaT"
end
s1_dup = s1.dup
s1_clone = s1.clone
s1 #=> "cat"
s1_dup.upcase #=> "CAT" (singleton method not copied)
s1_clone.upcase #=> "CaT" (uses singleton method)
Both dup and clone are shallow copies: They copy the immediate contents of their receiver only. If the receiver contains references to other objects, those objects aren’t in turn copied; the duplicate simply holds references to them. The following example illustrates this. The object arr2is a copy of arr1, so changing entire elements such as arr2[2] has no effect on arr1. However, both the original array and the duplicate contain a reference to the same String object, so changing its contents via arr2 also affects the value referenced by arr1:
arr1 = [ 1, "flipper", 3 ]
arr2 = arr1.dup
arr2[2] = 99
arr2[1][2] = 'a'
arr1 # [1, "flapper", 3]
arr2 # [1, "flapper", 99]
Sometimes you want a deep copy, where the entire object tree rooted in one object is copied to create the second object. This way, there is guaranteed to be no interaction between the two. Ruby provides no built-in method to perform a deep copy, but there are a couple of techniques you can use to implement one.
The pure way to do it is to have your classes implement a deep_copy method. As part of its processing, this method calls deep_copy recursively on all the objects referenced by the receiver. You then add a deep_copy method to all the Ruby built-in classes that you use.
Fortunately, there’s a quicker (albeit hackier) way using the Marshal module. If you use marshaling to dump an object into a string and then load it back into a new object, that new object will be a deep copy of the original:
arr1 = [ 1, "flipper", 3 ]
arr2 = Marshal.load(Marshal.dump(arr1))
arr2[2] = 99
arr2[1][2] = 'a'
arr1 # [1, "flipper", 3]
arr2 # [1, "flapper", 99]
In this case, notice how changing the string via arr2 doesn’t affect the string referenced by arr1.
11.1.10 Using initialize_copy
When you copy an object with dup or clone, the constructor is bypassed. All the state information is copied.
But what if you don’t want this to happen? Consider this example:
class Document
attr_accessor :title, :text
attr_reader :timestamp
def initialize(title, text)
@title, @text = title, text
@timestamp = Time.now
end
end
doc1 = Document.new("Random Stuff",File.read("somefile"))
sleep 300 # Wait awhile...
doc2 = doc1.clone
doc1.timestamp == doc2.timestamp # true
# Oops... the timestamps are the same!
When a Document is created, it is given a timestamp. If we copy that object, we copy the timestamp also. But what if we wanted instead to capture the time that the copy operation happened?
Defining an initialize_copy makes this possible. This method is called when an object is copied. It is analogous to initialize, giving us complete control over the object’s state.
class Document # Reopen the class
def initialize_copy(other)
@timestamp = Time.now
end
end
doc3 = Document.new("More Stuff", File.read("otherfile"))
sleep 300 # Wait awhile...
doc4 = doc3.clone
doc3.timestamp == doc4.timestamp # false
# Timestamps are now accurate.
Note that the initialize_copy is called after the information is copied. That is why we omitted this line:
@title, @text = other.title, other.text
As a matter of fact, an empty initialize_copy would behave just as if the method were not there at all.
11.1.11 Understanding allocate
In rare circumstances, you might want to create an object without calling its constructor (bypassing initialize). For example, maybe you have an object whose state is determined entirely by its accessors; then it isn’t necessary to call new (which calls initialize) unless you really want to. Imagine you are gathering data a piece at a time to fill in the state of an object; you might want to start with an “empty” object rather than gathering all the data up front and calling the constructor.
The allocate makes this easier. It returns a “blank” object of the proper class, yet uninitialized:
class Person
attr_accessor :name, :age, :phone
def initialize(n, a, p)
@name, @age, @phone = n, a, p
end
end
p1 = Person.new("John Smith", 29, "555-1234")
p2 = Person.allocate
p p1.age # 29
p p2.age # nil
11.1.12 Working with Modules
There are two basic reasons to use modules in Ruby. The first is simply namespace management; we’ll have fewer name collisions if we store constants and methods in modules. A method stored in this way (a module method) is called with the module name, analogous to the way a class method is called. If we see calls such as File.ctime and FileTest.exist?, we can’t tell just from context that File is a class and FileTest is a module.
The second reason is more interesting: We can use a module as a mixin. A mixin is like a specialized implementation of multiple inheritance in which only the interface portion is inherited.
We’ve talked about module methods, but what about instance methods? A module isn’t a class, so it can’t have instances, and an instance method can’t be called without a receiver.
As it turns out, a module can have instance methods. These become part of whatever class does the include of the module:
module MyMod
def method_1
puts "This is method 1"
end
end
class MyClass
include MyMod
end
x = MyClass.new
x.method_1 # This is method 1
Here, MyMod is mixed into MyClass, and the instance method method_1 is inherited. You have also seen an include done at the top level; in that case, the module is mixed into Object as you might expect.
But what happens to our module methods, if there are any? You might think they would be included as class methods, but Ruby doesn’t behave that way. The module methods aren’t mixed in.
However, we have a trick we can use if we want that behavior. There is a hook called included that we can override. It is called with a parameter, which is the “destination” class or module (into which this module is being included). For an example of its use, see Listing 11.6.
Listing 11.6 Including a Module with included
module MyMod
def self.included(klass)
def klass.module_method
puts "Module (class) method"
end
end
def method_1
puts "Method 1"
end
end
class MyClass
include MyMod
def self.class_method
puts "Class method"
end
def method_2
puts "Method 2"
end
end
x = MyClass.new
# Output:
MyClass.class_method # Class method
x.method_1 # Method 1
MyClass.module_method # Module (class) method
x.method_2 # Method 2
This example is worth examining in detail. First, we should understand that included is a hook that is called when an include happens. If we really wanted to, we could implement our own include method by defining append_features, but that is far less common (if it is ever desired at all).
Also note that within the included method definition there is yet another definition. This looks unusual, but it works because the inner method definition is a singleton method (class level or module level). An attempt to define an instance method in the same way would result in aNested method error.
Conceivably a module might want to determine the initiator of a mixin. The included method can also be used for this because the class is passed in as a parameter.
It is also possible to mix in the instance methods of a module as class methods using include or extend. Listing 11.7 shows an example.
Listing 11.7 Module Instance Methods Becoming Class Methods
module MyMod
def meth3
puts "Module instance method meth3"
puts "can become a class method."
end
end
class MyClass
class << self # Here, self is MyClass
include MyMod
end
end
MyClass.meth3
# Output:
# Module instance method meth3
# can become a class method.
The extend method is useful here. This example simply becomes the following:
class MyClass
extend MyMod
end
We’ve been talking about methods. What about instance variables? Although it is certainly possible for modules to have their own instance data, it usually isn’t done. However, if you find a need for this capability, there is nothing stopping you from using it.
It is possible to mix a module into an object rather than a class (for example, with the extend method). See Section 11.2.2, “Specializing an Individual Object.”
It’s important to understand one more fact about modules. It is possible to define methods in your class that will be called by the mixin. This is a powerful technique that will seem familiar to those who have used Java interfaces.
The classic example is mixing in the Comparable module and defining a <=> method. Because the mixed-in methods can call the comparison method, we now have such operators as <, >, <=, and so on.
Another example is mixing in the Enumerable module and defining <=> and the iterator each. This gives us numerous useful methods such as collect, sort, min, max, and select.
You can also define modules of your own to be used in the same way. The principal limitation is the programmer’s imagination.
11.1.13 Transforming or Converting Objects
Sometimes an object comes in exactly the right form at the right time, but sometimes we need to convert it to something else or pretend it’s something it isn’t. A good example is the heavily used to_s method.
Every object can be converted to a string representation in some fashion. But not every object can successfully masquerade as a string. That in essence is the difference between the to_s and to_str methods. Let’s elaborate on that.
Methods such as puts and contexts such as #{...} interpolation in strings all expect to receive a String as a parameter. If they don’t, they ask the object they did receive to convert itself to a String by sending it a to_s message. This is where you can specify how your object will appear when displayed; simply implement a to_s method in your class that returns an appropriate String:
class Pet
def initialize(name)
@name = name
end
# ...
def to_s
"Pet: #@name"
end
end
Other methods (such as the String concatenation operator +) are more picky; they expect you to pass in something that is really pretty close to a String. In this case, Matz decided not to have the interpreter call to_s to convert non-string arguments because he felt this would lead to too many errors. Instead, the interpreter invokes a stricter method, to_str. Of the built-in classes, only String and Exception implement to_str, and only String, Regexp, and Marshal call it. Typically when you see the runtime error TypeError: Failed to convert xyz into String, you know that the interpreter tried to invoke to_str and failed.
You can implement to_str yourself. For example, you might want to allow numbers to be concatenated to strings:
class Numeric
def to_str
to_s
end
end
label = "Number " + 9 # "Number 9"
An analogous situation holds for arrays. The method to_a is called to convert an object to an array representation, and to_ary is called when an array is expected.
An example of when to_ary is called is with multiple assignment. Suppose we have a statement of this form:
a, b, c = x
Assuming that x is an array of three elements, this would behave in the expected way. But if it isn’t an array, the interpreter will try to call to_ary to convert it to one. For what it’s worth, the method we define can be a singleton (belonging to a specific object). The conversion can be completely arbitrary; here we show an (unrealistic) example in which a string is converted to an array of strings:
class String
def to_ary
return self.split("")
end
end
str = "UFO"
a, b, c = str # ["U", "F", "O"]
The inspect method implements another convention. Debuggers, utilities such as irb, and the debug print method p use the inspect method to convert an object to a printable representation. If you want classes to reveal internal details when being debugged, you should override inspect.
Numeric coercion is another example of transforming or converting an object. Refer to Section 5.16, “Coercing Numeric Values.”
11.1.14 Creating Data-Only Classes (Structs)
Sometimes you need to group together a bunch of related data. Initially, it can be easy to simply use an array or a hash. That approach is brittle, and makes changes or adding accessor methods difficult. You could solve the problem by defining a class:
class Address
attr_accessor :street, :city, :state
def initialize(street, city, state)
@street, @city, @state = street, city, state
end
end
books = Address.new("411 Elm St", "Dallas", "TX")
This works, but it’s tedious, and a fair amount of repetition is in there. That’s why the built-in class Struct comes in handy. In the same way that convenience methods such as attr_accessor define methods to access attributes, class Struct defines classes that contain attributes. These classes are structure templates:
Address = Struct.new("Address", :street, :city, :state)
books = Address.new("411 Elm St", "Dallas", "TX")
So, why do we pass the name of the structure to be created in as the first parameter of the constructor and also assign the result to a constant (Address in this case)?
When we create a new structure template by calling Struct.new, we may pass a string with the class name as the first argument. If we do, a new class is created within class Struct itself, with the name passed in as the first parameter and the attributes given as the rest of the parameters. This means that if we wanted, we could access this newly created class within the namespace of class Struct:
Struct.new("Address", :street, :city, :state)
books = Struct::Address.new("411 Elm St", "Dallas", "TX")
If the first argument to Struct.new is a symbol, all of the arguments are taken to be attribute names, and a class inside the Struct namespace will not be created.
When creating a Struct class, additional methods can be defined for the class by simply providing a block to Struct.new. The block will be evaluated as if it were the class body, much like any other class definition.
After you’ve created a structure template, you call its new method to create new instances of that particular structure. You don’t have to assign values to all the attributes in the constructor: Those that you omit will be initialized to nil. Once it is created, you can access the structure’s attributes using normal syntax or by indexing the structure object as if it were a Hash. For more information, look up class Struct in any reference (such as rdoc.info online).
By the way, we advise against the creation of a Struct named Tms. There is already a predefined Struct::Tms class.
11.1.15 Freezing Objects
Sometimes we want to prevent an object from being changed. The freeze method (in Object) allows us to do this, effectively turning an object into a constant.
After we freeze an object, an attempt to modify it results in a TypeError. Listing 11.8 shows a pair of examples.
Listing 11.8 Freezing an Object
str = "This is a test. "
str.freeze
begin
str << " Don't be alarmed." # Attempting to modify
rescue => err
puts "#{err.class} #{err}"
end
arr = [1, 2, 3]
arr.freeze
begin
arr << 4 # Attempting to modify
rescue => err
puts "#{err.class} #{err}"
end
# Output:
# TypeError: can't modify frozen string
# TypeError: can't modify frozen array
Freezing strings is handled as a special case: The interpreter will create a single frozen string object and return it for every instance of the frozen string. This can reduce memory usage if, for example, a particular string will be returned from a method that is called many times:
str1 = "Woozle".freeze
str2 = "Woozle".freeze
str1.object_id == str2.object_id # true
Although freezing prevents modification, bear in mind that freeze operates on an object reference, not on a variable! This means that any operation resulting in a new object will work. Sometimes this isn’t intuitive. In the following example, we might expect that the += operation would fail—but it acts normally. This is because assignment is not a method call. It acts on variables, not objects, and it creates a new object as needed. The old object is indeed still frozen, but it is no longer referenced by that variable name:
str = "counter-"
str.freeze
str += "intuitive" # "counter-intuitive"
arr = [8, 6, 7]
arr.freeze
arr += [5, 3, 0, 9] # [8, 6, 7, 5, 3, 0, 9]
Why does this happen? The statement a += x is semantically equivalent to a = a + x. The expression a + x is evaluated to a new object, which is then assigned to a! The object isn’t changed, but the variable now refers to a new object. All the reflexive assignment operators exhibit this behavior, as do some other methods. Always ask yourself whether you are creating a new object or modifying an existing one; then freeze will not surprise you.
There is a method called frozen? that will tell you whether an object is frozen:
hash = { 1 => 1, 2 => 4, 3 => 9 }
hash.freeze
arr = hash.to_a
puts hash.frozen? # true
puts arr.frozen? # false
hash2 = hash
puts hash2.frozen? # true
As you can see here (with hash2), the object, not the variable, is frozen.
11.1.16 Using tap in Method Chaining
The tap method runs a block with access to the value of an expression in the middle of other operations. (Think “tap” as in tapping a phone, or as in using the tap in the kitchen.)
One use of tap can be to print intermediate values while they are being processed, because the block is passed the object that tap is called on:
a = [1, 5, 1, 4, 2, 3, 4, 3, 2, 5, 2, 1]
p a.sort.uniq.tap{|x| p x }.map {|x| x**2 + 2*x + 7 }
# [1, 2, 3, 4, 5]
# [10, 15, 22, 31, 42]
Providing this sort of access can be helpful, but the real power of tap comes from its ability to change the object inside the block. This allows code to alter an object and still return the original object, rather than the result of the last operation:
def feed(woozle)
woozle.tap do |w|
w.stomach << Steak.new
end
end
Without tap, our feed method would return the stomach that now contains a steak. Instead, it returns the newly fed (and presumably happy) woozle.
This technique is highly useful inside class methods that construct an object, call methods on the object, and then return the object. It is also handy when implementing methods that are intended to be chained together.
11.2 More Advanced Techniques
Not everything in Ruby OOP is straightforward. Some techniques are more complex than others, and some are rarely used. The dividing line will be different for each programmer. We’ve tried to put items in this part of the chapter that were slightly more involved or slightly more rare in terms of usage.
From time to time, you might ask yourself whether it’s possible to do some task or other in Ruby. The short answer is that Ruby is a rich dynamic OOP language with a good set of reasonably orthogonal features, and if you want to do something that you’re used to in another language, you can probably do it in Ruby.
As a matter of fact, all Turing-complete languages are pretty much the same from a theoretical standpoint. The whole field of language design is the search for a meaningful, convenient notation. The reader who doubts the importance of a convenient notation should try writing a LISP interpreter in COBOL or doing long division with Roman numerals.
Of course, we won’t say that every language task is elegant or natural in Ruby. Someone would quickly prove us wrong if we made that assertion.
This section also touches on the use of Ruby in various advanced programming styles such as functional programming and aspect-oriented programming. We don’t claim expertise in these areas; we are only reporting what other people are saying. Take it all with a grain of salt.
11.2.1 Sending an Explicit Message to an Object
In a static language, you take it for granted that when you call a function, that function name is hard-coded into the program; it is part of the program source. In a dynamic language, we have more flexibility than that.
Every time you invoke a method, you’re sending a message to an object. Most of the time, these messages are hard-coded as in a static language, but they need not always be. We can write code that determines at runtime which method to call. The send method will allow us to use aSymbol to represent a method name.
For an example, suppose that we had an array of objects, and we wanted to get another array that contained an attribute on each object. That’s not a problem; we can easily write customized map blocks. But suppose that we wanted to be a little more elegant and write only a single routine that could return whatever attribute we specified. Listing 11.9 shows an example.
Listing 11.9 Using a Method Named by a Parameter
class Person
attr_reader :name, :age, :height
def initialize(name, age, height)
@name, @age, @height = name, age, height
end
def inspect
"#@name #@age #@height"
end
end
class Array
def map_by(sym)
self.map {|x| x.send(sym) }
end
end
people = []
people << Person.new("Hansel", 35, 69)
people << Person.new("Gretel", 32, 64)
people << Person.new("Ted", 36, 68)
people << Person.new("Alice", 33, 63)
p1 = people.map_by(:name) # Hansel, Gretel, Ted, Alice
p2 = people.map_by(:age) # 35, 32, 36, 33
p3 = people.map_by(:height) # 69, 64, 68, 63
This particular code is not really necessary because we can simply call map(&:name) and get the same result, but it illustrates the send method well. We’ll look at this option more carefully in Section 11.2.7, “Using Symbols as Blocks.”
We’ll also mention the alias __send__, which does exactly the same thing. It is given this peculiar name, of course, because send is a name that might be used (purposefully or accidentally) as a user-defined method name.
One issue that some coders have with send is that it allows circumvention of Ruby’s privacy model (in the sense that private methods may be called indirectly by sending the object a string or symbol). This was intended more as a feature than a design flaw; however, if you are more comfortable “protecting yourself” against doing this accidentally, you can use the public_send method instead.
11.2.2 Specializing an Individual Object
I’m a Solipsist, and I must say I’m surprised there aren’t more of us.
—Letter received by Bertrand Russell
In most object-oriented languages, all objects of a particular class share the same behavior. The class acts as a template, producing an object with the same interface each time the constructor is called.
Although Ruby acts the same way, that isn’t the end of the story. Once you have a Ruby object, you can change its behavior “on the fly.” Effectively, you’re giving that object a private, anonymous subclass: All the methods of the original class are available, but you’ve added additional behavior for just that object. Because this behavior is private to the associated object, it can only occur once. A thing occurring only once is called a “singleton,” so we sometimes refer to singleton methods and singleton classes (also called metaclasses).
The word “singleton” can be confusing because it is also used in a different sense—as the name of a well-known design pattern for a class that can only be instantiated once. For this usage, refer to the singleton library.
In the following example, we see a pair of objects, both of which are strings. For the second one, we will add a method called upcase that will override the existing method of that name:
a = "hello"
b = "goodbye"
def b.upcase # create single method
gsub(/(.)(.)/) { $1.upcase + $2 }
end
puts a.upcase # HELLO
puts b.upcase # GoOdBye
Adding a singleton method to an object creates a singleton class for that object if one doesn’t already exist. This singleton class’s parent will be the object’s original class. (This could be considered an anonymous subclass of the original class.) If you want to add multiple methods to an object, you can create the singleton class directly:
b = "goodbye"
class << b
def upcase # create single method
gsub(/(.)(.)/) { $1.upcase + $2 }
end
def upcase!
gsub!(/(.)(.)/) { $1.upcase + $2 }
end
end
puts b.upcase # GoOdBye
puts b # goodbye
b.upcase!
puts b # GoOdBye
As an aside, note that the more “primitive” objects (such as a Fixnum) cannot have singleton methods added. This is because an object of this nature is stored as an immediate value rather than as an object reference. However, this functionality is planned for a future revision of Ruby (though the values will still be immediate).
If you read some of the library code, you’re bound to come across an idiomatic use of singleton classes. Within class definitions, you might see something like this:
class SomeClass
# Stuff...
class << self
# more stuff...
end
# ... and so on.
end
Within the body of a class definition, self is the class you’re defining, so creating a singleton based on it modifies the class’s class. At the simplest level, this means that instance methods in the singleton class are class methods externally:
class TheClass
class << self
def hello
puts "hi"
end
end
end
# invoke a class method
TheClass.hello # hi
Another common use of this technique is to define class-level helper functions, which we can then access in the rest of the class definition. As an example, we want to define several accessor functions that always convert their results to a string. We could do this by coding each individually. A neater way might be to define a class-level function accessor_string that generates these functions for us (as shown in Listing 11.10).
Listing 11.10 A Class-Level Method accessor_string
class MyClass
class << self
def accessor_string(*names)
names.each do |name|
class_eval <<-EOF
def #{name}
@#{name}.to_s
end
EOF
end
end
end
def initialize
@a = [1, 2, 3]
@b = Time.now
end
accessor_string :a, :b
end
o = MyClass.new
puts o.a # 123
puts o.b # 2014-07-26 00:45:12 -0700
More imaginative examples are left up to you.
It is also possible to use the extend method to mix a module into a single object. The instance methods from the module become instance methods for the object. Let’s look at Listing 11.11.
Listing 11.11 Using extend
module Quantifier
def two?
2 == self.select { |x| yield x }.size
end
def four?
4 == self.select { |x| yield x }.size
end
end
list = [1, 2, 3, 4, 5]
list.extend(Quantifier)
flag1 = list.two? {|x| x > 3 } # => true
flag2 = list.two? {|x| x >= 3 } # => false
flag3 = list.four? {|x| x <= 4 } # => true
flag4 = list.four? {|x| x % 2 == 0 } # => false
In this example, the two? and four? methods are mixed into the list array.
11.2.3 Nesting Classes and Modules
It’s possible to nest classes and modules arbitrarily. The programmer new to Ruby might not know this.
Mostly this is for namespace management. Note that the File class has a Stat class embedded inside it. This helps to “encapsulate” the Stat class inside a class of related functionality and also allows for a future class named Stat, which won’t conflict with that one (perhaps a statistics class, for instance).
The Struct::Tms class is a similar example. Any new Struct is placed in this namespace so as not to pollute the one above it, and Tms is really just another Struct.
It’s also conceivable that you might want to create a nested class simply because the outside world doesn’t need that class or shouldn’t access it. In other words, you can create classes that are subject to the principle of “data hiding,” just as the instance variables and methods are subject to the same principle at a lower level.
class BugTrackingSystem
class Bug
#...
end
#...
end
# Nothing out here knows about Bug.
You can nest a class within a module, a module within a class, and so on.
11.2.4 Creating Parametric Classes
Learn the rules; then break them.
—Basho
Suppose we wanted to create multiple classes that differed only in the initial values of the class-level variables. Recall that a class variable is typically initialized as a part of the class definition:
class Terran
@@home_planet = "Earth"
def Terran.home_planet
@@home_planet
end
def Terran.home_planet=(x)
@@home_planet = x
end
#...
end
That is all fine, but suppose we had a number of similar classes to define. The novice will think, “Ah, I’ll just define a superclass” (see Listing 11.12).
Listing 11.12 Parametric Classes: The Wrong Way
class IntelligentLife # Wrong way to do this!
@@home_planet = nil
def IntelligentLife.home_planet
@@home_planet
end
def IntelligentLife.home_planet=(x)
@@home_planet = x
end
#...
end
class Terran < IntelligentLife
@@home_planet = "Earth"
#...
end
class Martian < IntelligentLife
@@home_planet = "Mars"
#...
end
However, this won’t work. If we call Terran.home_planet, we expect a result of “Earth”—but we get “Mars”!
Why would this happen? The answer is that class variables aren’t truly class variables; they belong not to the class but to the entire inheritance hierarchy. The class variables aren’t copied from the parent class but are shared with the parent (and thus with the “sibling” classes).
We could eliminate the definition of the class variable in the base class, but then the class methods we define no longer work!
We could fix this by moving these definitions to the child classes, but now we’ve defeated our whole purpose. We’re declaring separate classes without any “parameterization.”
We’ll offer a different solution. We’ll defer the evaluation of the class variable until runtime by using the class_eval method. Listing 11.13 shows a complete solution.
Listing 11.13 Parametric Classes: A Better Way
class IntelligentLife
def IntelligentLife.home_planet
class_eval("@@home_planet")
end
def IntelligentLife.home_planet=(x)
class_eval("@@home_planet = #{x}")
end
#...
end
class Terran < IntelligentLife
@@home_planet = "Earth"
#...
end
class Martian < IntelligentLife
@@home_planet = "Mars"
#...
end
puts Terran.home_planet # Earth
puts Martian.home_planet # Mars
It goes without saying that inheritance still operates normally here. Any instance methods or instance variables defined within IntelligentLife will be inherited by Terran and Martian, just as you would expect.
Listing 11.14 is perhaps the best solution. In this case, we don’t use class variables at all but class instance variables.
Listing 11.14 Parametric Classes: The Best Way
class IntelligentLife
class << self
attr_accessor :home_planet
end
#...
end
class Terran < IntelligentLife
self.home_planet = "Earth"
#...
end
class Martian < IntelligentLife
self.home_planet = "Mars"
#...
end
puts Terran.home_planet # Earth
puts Martian.home_planet # Mars
Here, we open up the singleton class and define an accessor called home_planet. The two child classes call their own accessors and set the variable. These accessors work strictly on a per-class basis now.
As a small enhancement, let’s also add a private call in the singleton class:
private :home_planet=
Making the writer private will prevent any code outside the hierarchy from changing this value. As always, using private is an “advisory” protection and is easily bypassed by the programmer who wants to. Making a method private at least tells us we are not meant to call that method in this particular context.
I should mention that there are other ways of implementing these techniques. Use your creativity.
11.2.5 Storing Code as Proc Objects
Not surprisingly, Ruby gives you several alternatives when it comes to storing a chunk of code in the form of an object. We’ll take a look at Proc objects and lambdas here.
The built-in class Proc represents a Ruby block as an object. Proc objects, like blocks, are closures and therefore carry around the context where they were defined. The proc method is a shorthand alias for Proc.new.
local = 12
myproc = Proc.new {|a| puts "Param is #{a}, local is #{local}" }
myproc.call(99) # Param is 99, local is 12
Proc objects are also created automatically by Ruby when a method defined with a trailing & parameter is called with a block:
def take_block(x, &block)
puts block.class
x.times {|i| block[i, i*i] }
end
take_block(3) { |n,s| puts "#{n} squared is #{s}" }
This example also shows the use of brackets ([]) as an alias for the call method. The output is shown here:
Proc
0 squared is 0
1 squared is 1
2 squared is 4
If you have a Proc object, you can pass it to a method that’s expecting a block, preceding its name with an &, as shown here:
myproc = proc { |n| print n, "... " }
(1..3).each(&myproc) # 1... 2... 3...
Although it can certainly be useful to pass a Proc to a method, calling return from inside the Proc returns from the entire method. A special type of Proc object, called a lamdba, returns only from the block:
def greet(&block)
block.call
"Good morning, everyone."
end
philippe_proc = Proc.new { return "Too soon, Philippe!" }
philippe_lambda = lambda { return "Too soon, Philippe!" }
p greet(philippe_proc) # Too soon, Philippe!
p greet(philippe_lambda) # Good morning, everyone.
In addition to the keyword lambda, the -> notation also creates lambdas. Just keep in mind that -> (sometimes called “stabby proc” or “stabby lambda”) puts block arguments outside the curly braces:
non_stabby_lambda = lambda {|king| greet(king) }
stabby_lambda = -> (king) { stab(king) }
11.2.6 Storing Code as Method Objects
Ruby also lets you turn a method into an object directly using Object#method. The method method returns a Method object, which is a closure that is bound to the object it was created from:
str = "cat"
meth = str.method(:length)
a = meth.call # 3 (length of "cat")
str << "erpillar"
b = meth.call # 11 (length of "caterpillar")
str = "dog"
c = meth.call # 11 (length of "caterpillar")
Note the final call! The variable str refers to a new object ("dog") now, but meth is still bound to the old object.
A call to public_method works the same way, but as the name implies, it only searches public methods on the receiver.
To get a method that can be used with any instance of a particular class, you can use instance_method to create UnboundMethod objects. Before calling an UnboundMethod object, you must first bind it to a particular object. This act of binding produces a Method object, which you call normally:
umeth = String.instance_method(:length)
m1 = umeth.bind("cat")
m1.call # 3
m2 = umeth.bind("caterpillar")
m2.call # 11
Binding a method to the wrong class can cause an error, but allowing binding to other objects makes UnboundMethod a little more intuitive than Method.
11.2.7 Using Symbols as Blocks
When a parameter is prefixed with an ampersand, it is treated by Ruby as a block parameter. As shown earlier, it is possible to create a Proc object, assign it to a variable, and then use that Proc as the block for a method that takes a block.
However, as mentioned in Section 11.2.1, “Sending an Explicit Message to an Object,” it is possible to call methods that require blocks but only pass them a symbol prefixed by an ampersand. Why is that possible? The answer lies in the to_proc method.
A non-obvious side effect of providing a block parameter as an argument is that if the argument is not a Proc, Ruby will attempt to convert it into one by calling to_proc on it.
Some clever Ruby developers realized that this could be leveraged to simplify their calls to map, and they defined the to_proc method on the Symbol class. The implementation looks something like this:
class Symbol
def to_proc
Proc.new {|obj| obj.send(self) }
end
end
# Which allows map to be invoked like this:
%w[A B C].map(&:chr) # [65, 66, 67]
This shortcut proved to be so popular that it was added to Ruby itself, and can now be used anywhere.
11.2.8 How Module Inclusion Works
When a module is included into a class, Ruby in effect creates a proxy class as the immediate ancestor of that class. You may or may not find this intuitive. Any methods in an included module are “masked” by any methods that appear in the class:
module MyMod
def meth
"from module"
end
end
class ParentClass
def meth
"from parent"
end
end
class ChildClass < ParentClass
def meth
"from child"
end
include MyMod
end
x = ChildClass.new
p x.meth # from child
This is just like a regular inheritance relationship: Anything the child redefines is the new current definition. This is true regardless of whether the include is done before or after the redefinition.
Here’s a similar example, where the child method invokes super instead of returning a simple string. What do you expect it to return?
# MyMod and ParentClass unchanged
class ChildClass < ParentClass
include MyMod
def meth
"from child: super = " + super
end
end
x = ChildClass.new
p x.meth # from child: super = from module
As you can see, MyMod is really the new parent of ChildClass. What if we also let the module invoke super in the same way?
module MyMod
def meth
"from module: super " + super
end
end
# ParentClass is unchanged
class ChildClass < ParentClass
include MyMod
def meth
"from child: super " + super
end
end
x = ChildClass.new
p x.meth # from child: super from module: super from parent
Modules have one more trick up their sleeve, though, in the form of the prepend method. It allows a module method to be inserted beneath the method of the including class:
# MyMod and ParentClass unchanged
class ChildClass < ParentClass
prepend MyMod
def meth
"from child: super " + super
end
end
x = ChildClass.new
p x.meth # from module: super from child: super from parent
This feature of Ruby allows modules to alter the behavior of methods even when the method in the child class does not call super.
Whether included or prepended, the meth from MyMod can call super only because there actually is a meth in the superclass (that is, in at least one ancestor). What would happen if we called this in another circumstance?
module MyMod
def meth
"from module: super = " + super
end
end
class Foo
include MyMod
end
x = Foo.new
x.meth
This code would result in a NoMethodError (or a call to method_missing, if it had been defined).
11.2.9 Detecting Default Parameters
The following question was once asked by Ian Macdonald on the Ruby mailing list: “How can I detect whether a parameter was specified by the caller, or the default was taken?” This is an interesting question; not something you would use every day, but still interesting.
At least three solutions were suggested. By far the simplest and best was by Nobu Nakada, which is shown in the following code:
def meth(a, b=(flag=true; 345))
puts "b is #{b} and flag is #{flag.inspect}"
end
meth(123) # b is 345 and flag is true
meth(123,345) # b is 345 and flag is nil
meth(123,456) # b is 456 and flag is nil
As the preceding example shows, this trick works even if the caller explicitly supplies what happens to be the default value. The trick is obvious when you see it: The parenthesized expression sets a local variable called flag but then returns the default value 345. This solution is a tribute to the power of Ruby.
11.2.10 Delegating or Forwarding
Ruby has two libraries that offer solutions for delegating or forwarding method calls from the receiver to another object. These are delegate and forwardable; we’ll look at them in that order.
The delegate library gives you three ways of solving this problem.
The SimpleDelegator class can be useful when the object delegated to can change over the lifespan of the receiving object. The __setobj__ method is used to select the object to which you’re delegating.
However, I find the SimpleDelegator technique to be a little too simple. Because I am not convinced it offers a significant improvement over doing the same thing by hand, I won’t cover it here.
The DelegateClass top-level method takes a class (to be delegated to) as a parameter. It then creates a new class from which we can inherit. Here’s an example of creating our own Queue class that delegates to an Array object:
require 'delegate'
class MyQueue < DelegateClass(Array)
def initialize(arg=[])
super(arg)
end
alias_method :enqueue, :push
alias_method :dequeue, :shift
end
mq = MyQueue.new
mq.enqueue(123)
mq.enqueue(234)
p mq.dequeue # 123
p mq.dequeue # 234
It’s also possible to inherit from Delegator and implement a __getobj__ method; this is the way SimpleDelegator is implemented, and it offers more control over the delegation.
However, if you want more control, you should probably be doing per-method delegation rather than per-class anyway. The forwardable library enables you to do this. Let’s revisit the queue example:
require 'forwardable'
class MyQueue
extend Forwardable
def initialize(obj=[])
@queue = obj # delegate to this object
end
def_delegator :@queue, :push, :enqueue
def_delegator :@queue, :shift, :dequeue
def_delegators :@queue, :clear, :empty?, :length, :size, :<<
# Any additional stuff...
end
This example shows that the def_delegator method associates a method call (for example, enqueue) with a delegated object @queue and the correct method to call on that object (push). In other words, when we call enqueue on a MyQueue object, we delegate that by making apush call on our object @queue (which is usually an array).
Notice that we say :@queue rather than :queue or @queue; this is simply because of the way the Forwardable class is written. It could have been done differently.
Sometimes we want to pass methods through to the delegate object by using the same method name. The def_delegators method allows us to specify an unlimited number of these. For example, as shown in the preceding code example, invoking length on a MyQueue object will in turn call length on @queue.
Unlike the first example in this chapter, the other methods on the delegate object are simply not supported. This can be a good thing. For example, you don’t want to invoke [] or []= on a queue; if you do, you’re not using it as a queue anymore.
Also notice that the previous code allows the caller to pass an object into the constructor (to be used as the delegate object). In the spirit of duck-typing, this means that we can choose the kind of object we want to delegate to—as long as it supports the set of methods that we reference in the code.
For example, the following calls are all valid (note that the last two assume that we’ve done a require 'thread' previously):
q1 = MyQueue.new # use an array
q2 = MyQueue.new(my_array) # use one specific array
q3 = MyQueue.new(Queue.new) # use a Queue (thread.rb)
q4 = MyQueue.new(SizedQueue.new) # use a SizedQueue (thread.rb)
So, for example, q3 and q4 in the preceding examples are now magically thread-safe because they delegate to an object that is thread-safe. (That’s unless any customized code not shown here violates that.)
There is also a SingleForwardable class that operates on an instance rather than on an entire class. This is useful if you want just one instance of a class to delegate to another object, while all other instances continue to not delegate, as before.
One final option is manual delegation. Ruby makes it extremely straightforward to simply wrap one object in another, which is another way to implement our queue:
class MyQueue
def initialize(obj=[])
@queue = obj # delegate to this object
end
def enqueue(arg)
@queue.push(arg)
end
def dequeue(arg)
@queue.shift(arg)
end
%i[clear empty? length size <<].each do |name|
define_method(name){|*args| @queue.send(name, *args) }
end
# Any additional stuff...
end
As you can see, in some cases, it may not be a noticeable advantage to use a library for delegation instead of writing some simple code.
You might ask, “Is delegation better than inheritance?” But that’s the wrong question in a sense. Sometimes the situation calls for delegation rather than inheritance; for example, suppose that a class already has a parent class. We can still use delegation (in some form), but we can’t inherit from an additional parent (because Ruby doesn’t allow multiple inheritance).
11.2.11 Defining Class-Level Readers and Writers
We have seen the methods attr_reader, attr_writer, and attr_accessor, which make it a little easier to define readers and writers (getters and setters) for instance attributes. But what about class-level attributes?
Ruby has no similar facility for creating these automatically. However, we could create something similar on our own very simply. Just open the singleton class and use the ordinary attr family of methods.
The resulting instance variables in the singleton class will be class instance variables. These are often better for our purposes than class variables because they are strictly “per class” and are not shared up and down the hierarchy.
class MyClass
@alpha = 123 # Initialize @alpha
class << self
attr_reader :alpha # MyClass.alpha()
attr_writer :beta # MyClass.beta=()
attr_accessor :gamma # MyClass.gamma() and MyClass.gamma=()
end
def MyClass.look
puts "#@alpha, #@beta, #@gamma"
end
#...
end
puts MyClass.alpha # 123
MyClass.beta = 456
MyClass.gamma = 789
puts MyClass.gamma # 789
MyClass.look # 123, 456, 789
Most classes are no good without instance level data as well, but we’ve omitted it here for clarity.
11.2.12 Working in Advanced Programming Disciplines
Brother, can you paradigm?
—Graffiti seen at IBM Austin, 1989
Many philosophies of programming are popular in various circles. These are often difficult to characterize in relation to object-oriented or dynamic techniques, and some of these styles can actually be independent of whether a language is dynamic or object oriented.
Because we are far from experts in these matters, we are relying mostly on hearsay. So take these next paragraphs with a grain of sodium chloride.
Some programmers prefer a flavor of OOP known as prototype-based OOP (or classless OOP). In this world, an object isn’t described as a member of a class; it is built from the ground up, and other objects are created based on the prototype. Ruby has at least rudimentary support for this programming style because it allows singleton methods for individual objects, and the clone method will clone these singletons. Interested readers should also look at the simple OpenStruct class for building Python-like objects; you should also be aware of how method_missingworks.
One or two limitations in Ruby hamper classless OOP. Certain objects such as Fixnums are stored not as references but as immediate values so that they can’t have singleton methods. This is supposed to change in the future, but at the time of this writing, it’s impossible to project when it will happen.
In functional programming (FP), emphasis is placed on the evaluation of expressions rather than the execution of commands. An FP language is one that encourages and supports functional programming, and as such, there is a natural gray area. Nearly all would agree that Haskell is a pure functional language, whereas Ruby certainly isn’t one.
But Ruby has at least some minimal support for FP; it has a fairly rich set of methods for operating on arrays (lists), and it has Proc objects so that code can be encapsulated and called over and over. Ruby allows the method chaining that is so common in FP. There have been some initial efforts at creating a library that would serve as a kind of FP “compatibility layer,” borrowing certain ideas from Haskell. At the time of this writing, these efforts aren’t complete.
The concept of aspect-oriented programming (AOP) is an interesting one. In AOP, programmers to deal with programming issues that crosscut the modular structure of the program. In other words, some activities or features of a system will be scattered across the system in code fragments here and there, rather than being gathered into one tidy location. AOP can modularize things that are difficult to modularize using traditional OOP or procedural techniques. It works at right angles to the usual way of thinking.
Ruby certainly wasn’t created specifically with AOP in mind. However, it was designed to be a flexible and dynamic language, and it is conceivable that these techniques can be facilitated by a library. The Module#prepend method and the aspector gem both provide some amount of AOP within Ruby.
The concept of design by contract (DBC) is well known to Eiffel devotees, although it is certainly known outside those circles also. The general idea is that a piece of code (a method or class) implements a contract; certain preconditions must be true if the code is going to do its job, and the code guarantees that certain post-conditions are true afterward. The robustness of a system can be greatly enhanced by the ability to specify this contract explicitly and have it automatically checked at runtime. The usefulness of the technique is expanded by the inheritance of contract information as classes are extended.
The Eiffel language had DBC explicitly built in; Ruby does not. There are usable implementations of DBC libraries, however, and they are worth investigating.
Design patterns have inspired much discussion over the last few years. These, of course, are highly language independent and can be implemented well in many languages. But again, Ruby’s unusual flexibility makes them perhaps more practical than in some other environments. Well-known examples of these are given elsewhere; the Visitor pattern is essentially implemented in Ruby’s default iterator each, and other patterns are part of Ruby’s standard distribution (such as the standard libraries delegator and singleton).
We don’t use the term “Extreme Programming” (XP) anymore, but many of its principles are ingrained in our culture by now. This methodology encourages (among other things) early testing and refactoring on the fly.
The “culture of testing” isn’t language specific, although it might be easier in some languages than others. Certainly we maintain that Ruby makes (manual) refactoring easier than many languages would, although that is a highly subjective claim. However, the existence of the RSpeclibrary (and others) makes for a real blending of Ruby and XP. This library facilitates unit testing; it is powerful, easy to use, and has proven useful in developing much other Ruby software in current use. We highly recommend the practice of testing early and often, and we recommendRSpec for those who want to do this in Ruby. (Minitest is another excellent gem, for those who prefer the Test::Unit style.)
By the time you read this, many of the issues we talk about in this section will have been fleshed out more. As always, your best resources for the latest information are online. It’s difficult to list online resources in print because they are in constant flux. In this case, the search engine is your friend.
11.3 Working with Dynamic Features
Skynet became self-aware at 2:14 a.m. EDT August 29, 1997.
—Terminator 2: Judgment Day
Some of you may come from the background of a static language such as C. To those readers, we will address this rhetorical question: Can you imagine writing a C function that will take a string, treat it as a variable name, and return the value of the variable? No? Then can you imagine removing or replacing the definition of a function? Can you imagine trapping calls to nonexistent functions?
Ruby makes this sort of thing possible. These capabilities take getting used to, and they are easy to abuse. However, the concepts have been around for many years (they are at least as old as LISP) and are regarded as “tried and true” in the Scheme and Smalltalk communities as well. Python has many dynamic features, and even Java has some dynamic features, so we expect this way of thinking to continue to increase in popularity over time.
11.3.1 Evaluating Code Dynamically
The global function eval compiles and executes a string that contains a fragment of Ruby code. This is a powerful (albeit extremely dangerous) mechanism, because it allows you to build up code to be executed at runtime. For example, the following code reads in lines of the form “name = expression.” It then evaluates each expression and stores the result in a hash indexed by the corresponding variable name:
parameters = {}
ARGF.each do |line|
name, expr = line.split(/\s*=\s*/, 2)
parameters[name] = eval expr
end
Suppose the input contained these lines:
a = 1
b = 2 + 3
c = 'date'
Then the hash parameters would end up with the value {"a"=>1, "b"=>5, "c"=>"Sat Jul 26 00:51:48 PDT 2014\n"}. This example also illustrates the danger of evaling strings when you don’t control their contents; a malicious user could put d=`rm *` in the input and ruin your day.
Ruby has three other methods that evaluate code “on the fly”: class_eval, module_eval, and instance_eval. The first two are synonyms, and all three do effectively the same thing; they evaluate a string or a block, but while doing so they change the value of self to their own receiver. Perhaps the most common use of class_eval allows you to add methods to a class when all you have is a reference to that class.
We use this in the hook_method code in the Trace example in Section 11.4.3, “Tracking Changes to a Class or Object Definition.” You’ll find other examples in the more dynamic library modules, such as the standard library delegate.rb.
The eval method also makes it possible to evaluate local variables in a context outside their scope. We don’t advise doing this lightly, but it’s nice to have the capability.
Ruby associates local variables with blocks, with high-level definition constructs (class, module, and method definitions), and with the top-level of your program (the code outside any definition constructs). Associated with each of these scopes is the binding of variables, along with other housekeeping details.
Probably the ultimate user of bindings is pry, an interactive Ruby console. It not only uses bindings to keep the variables in the program that you type in separate from its own, but adds the Binding#pry method to open a new interactive console within that binding. We’ll look more closely at pry in Chapter 16, “Testing and Debugging.”
You can encapsulate the current binding in an object using the method Kernel#binding. Having done that, you can pass the binding as the second parameter to eval, setting the execution context for the code being evaluated.
def some_method
a = "local variable"
return binding
end
the_binding = some_method
eval "a", the_binding # "local variable"
Interestingly, the presence of a block associated with a method is stored as part of the binding, enabling tricks such as this:
def some_method
return binding
end
the_binding = some_method { puts "hello" }
eval "yield", the_binding # hello
11.3.2 Retrieving a Constant by Name
The const_get method retrieves the value of a constant (by name) from the module or class to which it belongs:
str = "PI"
Math.const_get(str) # Evaluates to Math::PI
This is a way of avoiding the use of eval, which is both dangerous and considered inelegant. This type of solution is better code, it’s computationally cheaper, and it’s safer. Other similar methods are instance_variable_set, instance_variable_get, anddefine_method.
It’s true that const_get is faster than eval. In informal tests, const_get was roughly 350% as fast; your results will vary. But is this really significant? The fact is, the test code ran a loop 10 million times to get good results and still finished in under 30 seconds.
The usefulness of const_get is that it is easier to read, more specific, and more self-documenting. This is the real reason to use it. In fact, even if it did not exist, to make it a synonym for eval might still be a step forward.
See also the next section (11.3.3, “Retrieving a Class by Name”) for another trick.
11.3.3 Retrieving a Class by Name
We have seen this question more than once. Given a string containing the name of a class, how can we create an instance of that class?
Classes in Ruby are normally named as constants in the “global” namespace—that is, members of Object. That means the proper way is with const_get, which we just saw:
classname = "Array"
klass = Object.const_get(classname)
x = klass.new(4, 1) # [1, 1, 1, 1]
If the constant is inside a namespace, just provide a string that with namespaces delimited by two colons (as if you were writing Ruby directly):
class Alpha
class Beta
class Gamma
FOOBAR = 237
end
end
end
str = "Alpha::Beta::Gamma::FOOBAR"
val = Object.const_get(str) # 237
11.3.4 Using define_method
Other than def, define_method is the only normal way to add a method to a class or object; the latter, however, enables you to do it at runtime.
Of course, essentially everything in Ruby happens at runtime. If you surround a method definition with puts calls, as in the following example, you can see that:
class MyClass
puts "before"
def meth
#...
end
puts "after"
end
However, within a method body or similar place, we can’t just reopen a class (unless it’s a singleton class). In such a case, we use define_method. It takes a symbol (for the name of the method) and a block (for the body of the method):
if today =~ /Saturday|Sunday/
define_method(:activity) { puts "Playing!" }
else
define_method(:activity) { puts "Working!" }
end
activity
Note, however, that define_method is private. This means that calling it from inside a class definition or method will work just fine, as shown here:
class MyClass
define_method(:body_method) { puts "The class body." }
def self.new_method(name, &block)
define_method(name, &block)
end
end
MyClass.new_method(:class_method) { puts "A class method." }
x = MyClass.new
x.body_method # Prints "The class body."
x.class_method # Prints "A class method."
We can even create an instance method that dynamically defines other instance methods:
class MyClass
def new_method(name, &block)
self.class.send(:define_method, name, &block)
end
end
x = MyClass.new
x.new_method(:instance_method) { puts "An instance method." }
x.mymeth # Prints "An instance method."
Here, we’re still defining an instance method dynamically. Only the means of invoking new_method has changed. Note the send trick that we use to circumvent the privacy of define_method. This works because send always allows you to call private methods. (This is another “loophole,” as some would call it, that has to be used responsibly.)
It’s important to realize another fact about define_method: It takes a block, and a block in Ruby is a closure. This means that, unlike an ordinary method definition, we are capturing context when we define the method. The following example is useless, but it illustrates the point:
class MyClass
def self.new_method(name, &block)
define_method(name, &block)
end
end
a, b = 3, 79
MyClass.new_method(:compute) { a*b }
x = MyClass.new
puts x.compute # 237
a, b = 23, 24
puts x.compute # 552
The point is that the new method can access variables in the original scope of the block, even if that scope “goes away” and is otherwise inaccessible. This will be useful at times, perhaps in a metaprogramming situation or with a GUI toolkit that allows defining methods for event callbacks.
Note that the closure only has access to variables with the same names. On rare occasions, this can be tricky. Here, we use define to expose a class variable (not really the way we should do it, but it illustrates the point):
class SomeClass
@@var = 999
define_method(:peek) { @@var }
end
x = SomeClass.new
p x.peek # 999
Now let’s try this with a class instance variable:
class SomeClass
@var = 999
define_method(:peek) { @var }
end
x = SomeClass.new
p x.peek # prints nil
We expect 999 but get nil instead. Observe, on the other hand, that the following works fine:
class SomeClass
@var = 999
x = @var
define_method(:peek) { x }
end
x = SomeClass.new
p x.peek # 999
So what is happening? Well, it is true that a closure captures the variables from its context. But even though a closure knows the variables from its scope, the method context is the context of the instance, not the class itself.
Because @var in the instance context would refer to an instance variable of the object, the class instance variable is hidden by the object’s instance variable—even though it has never been used and technically doesn’t exist.
When working with individual objects, define_singleton_method is a convenient alternative to opening the singleton class and defining a method. It works analogously to define_method.
Although you can define methods at runtime by calling eval, avoid doing this. Instead, define_method can and should be used in all these circumstances. Minor subtleties like those just mentioned shouldn’t deter you.
11.3.5 Obtaining Lists of Defined Entities
The reflection API of Ruby enables us to examine the classes and objects in our environment at runtime. We’ll look at methods defined in Module, Class, and Object.
The Module module has a method named constants that returns an array of all the constants in the system (including class and module names). The nesting method returns an array of all the modules nested at the current location in the code.
The instance method Module#ancestors returns an array of all the ancestors of the specified class or module:
list = Array.ancestors # [Array, Enumerable, Object,
Kernel, BasicObject]
The constants method lists all the constants accessible in the specified module. Any ancestor modules are included:
list = Math.constants # [:DomainError, :PI, :E]
The class_variables method returns a list of all class variables in the given class and its superclasses. The included_modules method lists the modules included in a class:
class Parent
@@var1 = nil
end
class Child < Parent
@@var2 = nil
end
list1 = Parent.class_variables # [:@@var1]
list2 = Array.included_modules # [Enumerable, Kernel]
The Class methods instance_methods and public_instance_methods are synonyms; they return a list of the public instance methods for a class. The methods private_instance_methods and protected_instance_methods behave as expected. Any of these can take a Boolean parameter, which defaults to true; if it is set to false, superclasses will not be searched, thus resulting in a smaller list:
n1 = Array.instance_methods.size # 174
n2 = Array.public_instance_methods.size # 174
n3 = Array.public_instance_methods(false).size # 90
n4 = Array.private_instance_methods.size # 84
n5 = Array.protected_instance_methods.size # 0
The Object class has a number of similar methods that operate on instances (see Listing 11.15). Calling methods will return a list of all methods that can be invoked on that object. Calling public_methods will return a list of publicly accessible methods; this takes a parameter, defaulting to true, to choose whether methods from superclasses are included. The methods private_methods, protected_methods, and singleton_methods all take a similar parameter, and they return the methods you would expect them to return.
Listing 11.15 Reflection and Instance Variables
class SomeClass
def initialize
@a = 1
@b = 2
end
def mymeth
#...
end
protected :mymeth
end
x = SomeClass.new
def x.newmeth
# ...
end
iv = x.instance_variables # [:@a, :@b]
x.methods.size # 61
x.public_methods.size # 60
x.public_methods(false).size # 1
x.private_methods.size # 85
x.private_methods(false).size # 1
x.protected_methods.size # 1
x.singleton_methods.size # 1
11.3.6 Removing Definitions
The dynamic nature of Ruby means that pretty much anything that can be defined can also be undefined. One conceivable reason to do this is to decouple pieces of code that are in the same scope by getting rid of variables after they have been used; another reason might be to specifically disallow certain dangerous method calls. Whatever your reason for removing a definition, it should naturally be done with caution because it can conceivably lead to debugging problems.
The radical way to undefine something is with the undef keyword (not surprisingly the opposite of def). You can undef methods, local variables, and constants at the top level. Although a class name is a constant, you cannot remove a class definition this way:
def asbestos
puts "Now fireproof"
end
tax = 0.08
PI = 3
asbestos
puts "PI=#{PI}, tax=#{tax}"
undef asbestos
undef tax
undef PI
# Any reference to the above three
# would now give an error.
Within a class definition, a method or constant can be undefined in the same context in which it was defined. You can’t undef within a method definition or undef an instance variable.
The remove_method and undef_method methods also are available (defined in Module). The difference is subtle: remove_method will remove the current (or nearest) definition of the method; undef_method will literally cause the method to be undefined (removing it from superclasses as well). Listing 11.16 is an illustration of this.
Listing 11.16 Removing and Undefining Methods
class Parent
def alpha
puts "parent alpha"
end
def beta
puts "parent beta"
end
end
class Child < Parent
def alpha
puts "child alpha"
end
def beta
puts "child beta"
end
remove_method :alpha # Remove "this" alpha
undef_method :beta # Remove every beta
end
x = Child.new
x.alpha # parent alpha
x.beta # Error!
The remove_const method will remove a constant:
module Math
remove_const :PI
end
# No PI anymore!
Note that it is possible to remove access to a class definition in this way (because a class identifier is simply a constant). The following code demonstrates this:
class BriefCandle
#...
end
out_out = BriefCandle.new
class Object
remove_const :BriefCandle
end
BriefCandle.new # NameError: uninitialized constant BriefCandle
out_out.class.new # Another BriefCandle instance
Note that methods such as remove_const and remove_method are (naturally enough) private methods. That is why we show these being called from inside a class or module definition rather than outside.
11.3.7 Handling References to Nonexistent Constants
The const_missing method is called when you try to reference a constant that isn’t known. A symbol referring to the constant is passed in. It is analogous to the method_missing method, which we will examine in Section 11.3.8, “Handling Calls to Nonexistent Methods.”
To capture a constant globally, define this method within Module itself. (Remember that Module is the parent of Class.)
class Module
def const_missing(x)
"from Module"
end
end
class X
end
p X::BAR # "from Module"
p BAR # "from Module"
p Array::BAR # "from Module"
You can, of course, do anything you want to give the constant a fake value, compute its value, or whatever. Remember the Roman class from Chapter 6, “Symbols and Ranges”? Here we use it to ensure that arbitrary uppercase Roman numeral constants are treated as such:
class Module
def const_missing(name)
Roman.decode(name)
end
end
year1 = MCMLCCIV # 1974
year2 = MMXIV # 2014
If you want something less global, define the method as a class method on a class. That class and all its children will call that version of the method as needed:
class Alpha
def self.const_missing(sym)
"Alpha has no #{sym}"
end
end
class Beta
def self.const_missing(sym)
"Beta has no #{sym}"
end
end
class A < Alpha
end
class B < Beta
end
p Alpha::FOO # "Alpha has no FOO"
p Beta::FOO # "Beta has no FOO"
p A::FOO # "Alpha has no FOO"
p B::FOO # "Beta has no FOO"
11.3.8 Handling Calls to Nonexistent Methods
Sometimes it’s useful to be able to write classes that respond to arbitrary method calls. For example, you might want to wrap calls to external programs in a class, providing access to each program as a method call. You can’t know ahead of time the names of all these programs, so you can’t create the methods as you write the class.
That’s okay, though. Here come Object#method_missing and respond_to_ missing? to the rescue. Whenever a Ruby object receives a message for a method that isn’t implemented in the receiver, it invokes the method_missing method instead. You can use that to catch what would otherwise be an error, treating it as a normal method call. Let’s implement an operating system command wrapper class:
class CommandWrapper
def method_missing(method, *args)
system(method.to_s, *args)
end
end
cw = CommandWrapper.new
cw.date # Sat Jul 26 02:08:06 PDT 2014
cw.du '-s', '/tmp' # 166749 /tmp
The first parameter to method_missing is the name of the method that was called (and that couldn’t be found). Whatever was passed in that method call is then given as the remaining parameters.
If your method_missing handler decides that it doesn’t want to handle a particular call, it should call super rather than raising an exception. That allows method_missing handlers in superclasses to have a shot at dealing with the situation. Eventually, the method_missingmethod defined in class Object will be invoked, and that will raise an exception.
In order to safely use method_missing, always also define the respond_to_missing? method. By doing this, it is possible for Ruby to provide results for both the respond_to? method and method method. Here is an example of this technique:
class CommandWrapper # reopen previous class
def respond_to_missing?(method, include_all)
system("which #{method} > /dev/null")
end
end
cw = CommandWrapper.new
cw.respond_to?(:foo) # false
cw.method(:echo) # #<Method: CommandWrapper#echo>
cw.respond_to?(:echo) # true
The second parameter (include_all) allows the method definition to know whether to include private and protected methods in the respond check. In this example, we do not add any private or protected methods, and can ignore it.
Although the respond_to_missing? method is complementary to method_missing, there is no enforcement of this. Each method can be written alone, albeit with highly confusing behavior unless the other is also present.
11.3.9 Improved Security with taint
The dynamic nature of Ruby means that there are potential “security holes” in some Ruby code. As a trivial example, consider the eval method; if the string it is passed originates in the outside world, it is possible for a malicious user to cause arbitrary code to be executed—such as the ever-popular system("nohup rm -rf / &") string. Even without malice, it’s possible for an outside input to cause significant problems.
The first feature of Ruby that defends against these kinds of attacks is the safe level. The safe level is stored in a thread-local global variable and defaults to 0. Assigning a number to $SAFE sets the safe level, which can never be decreased.
When the safe level is 1 or higher, Ruby starts blocking certain dangerous actions using tainted objects. Every object has a tainted or non-tainted status flag. If an object has its origin in the “outside world” (for example, a string on the command line or a URL parameter), it is automatically tainted. This taint is passed on to objects that are derived from such an object.
Many core methods (notably eval) behave differently or raise an exception when passed tainted data as the safe level increases. Let’s look at this using strings:
str1 = "puts 'The answer is: '"
str2 = ARGV.first.dup # "3*79" (duped to unfreeze)
str1.tainted? # false
str2.tainted? # true
str1.taint # If we want to, we can
str2.untaint # change the taint status
eval(str1) # Prints: The answer is:
puts eval(str2) # Prints: 237
$SAFE = 1
eval(str1) # Raises SecurityError: Insecure operation
puts eval(str2) # Prints: 237
For a full summary of the interaction between taint levels and $SAFE values, see Table 11.1.
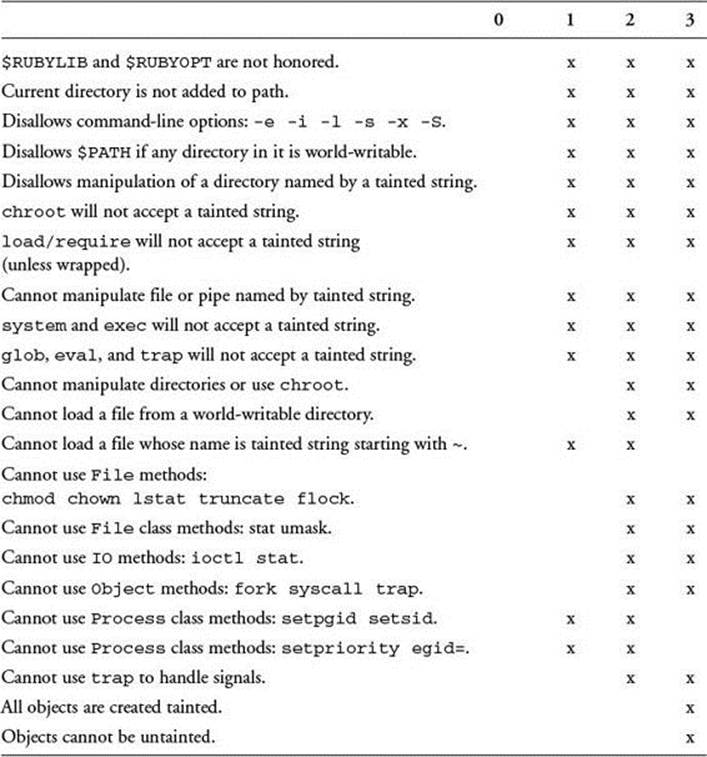
Table 11.1 Understanding $SAFE Levels
11.3.10 Defining Finalizers for Objects
Ruby classes have constructors (the methods new and initialize) but don’t have destructors (methods that delete objects). That’s because Ruby uses garbage collection to remove unreferenced objects; a destructor would make no sense.
However, people coming to Ruby from languages such as C++ seem to miss the facility and often ask how they can write code to handle the finalization of objects. The simple answer is that there is no real way to do it reliably. However, you can arrange to have code called when an object is garbage collected:
a = "hello"
puts "The string 'hello' has an object id #{a.object_id}"
ObjectSpace.define_finalizer(a) { |id| puts "Destroying #{id}" }
puts "Nothing to tidy"
GC.start
a = nil
puts "The original string is now a candidate for collection"
GC.start
This produces the following output:
The string 'hello' has an object id 537684890
Nothing to tidy
The original string is now a candidate for collection
Destroying 537684890
Note that by the time the finalizer is called, the object has basically been destroyed already. An attempt to convert the ID you receive back into an object reference using ObjectSpace._id2ref will raise a RangeError, complaining that you are attempting to use a recycled object.
Also, be aware that Ruby uses a “conservative” GC mechanism. There is no guarantee that an object will undergo garbage collection before the program terminates.
However, all this might be moot. There’s a style of programming in Ruby that uses blocks to encapsulate the use of a resource. At the end of the block, the resource is deleted, and life carries on merrily, all without the use of finalizers. For example, consider the block form of File.open:
File.open("myfile.txt") do |file|
line = file.gets
# ...
end
Here, the File object is passed into the block, and when the block exits, the file is closed, all under control of the open method. Whereas File.open is written in C for efficiency, writing it in Ruby might look something like this:
def File.open(name, mode = "r")
f = os_file_open(name, mode)
if block_given?
begin
yield f
ensure
f.close
end
return nil
else
return f
end
end
First, check for the presence of a block. If found, invoke that block, passing in the open file. The block is called inside a begin-ensure-end section, ensuring that the file will be closed after the block terminates, even if an exception is thrown.
11.4 Program Introspection
The runtime flexibility of Ruby extends even beyond the dynamic features we have seen so far. Code in Ruby is able to accomplish things during program execution that are astonishing when compared to programs in C.
Among other things, it is possible to determine the name of the calling function and automatically list every user-defined element (objects, classes, or functions). This runtime flexibility, by allowing the programmer to examine and change program elements at runtime, makes many problems easier.
In this section, we’ll look at a few runtime tricks Ruby allows. We’ll look at some of the libraries built on top of these tricks later, in Chapter 16.
11.4.1 Traversing the Object Space
The Ruby runtime system needs to keep track of all known objects (if for no other reason than to be able to garbage collect those that are no longer referenced). This information is made accessible via the ObjectSpace.each_object method. If you specify a class or module as a parameter to each_object, only objects of that type will be returned:
ObjectSpace.each_object(Bignum) do |obj|
printf "%20s: %s\n", obj.class, obj.inspect
end
# Prints:
# Bignum: 134168290416582806546366068851909766153
# Bignum: 9223372036854775807
If all you’re after is a count of each type of object that has been created, the count_objects method will return a hash with object types and counts:
require 'pp'
p ObjectSpace.count_objects
# {:TOTAL=>33013, :FREE=>284, :T_OBJECT=>2145, :T_CLASS=>901,
:T_MODULE=>32, :T_FLOAT=>4, :T_STRING=>18999, :T_REGEXP=>167,
:T_ARRAY=>4715, :T_HASH=>325, :T_STRUCT=>2, :T_BIGNUM=>4,
:T_FILE=>8, :T_DATA=>1518, :T_MATCH=>205, :T_COMPLEX=>1,
:T_NODE=>3663, :T_ICLASS=>40}
The ObjectSpace module is also useful in defining object finalizers (see Section 11.3.10, “Defining Finalizers for Objects”).
11.4.2 Examining the Call Stack
And you may ask yourself: Well, how did I get here?
—Talking Heads, “Once in a Lifetime”
Sometimes we want to know who our caller was. This could be useful information if, for example, we had a fatal exception. The caller method, defined in Kernel, makes this possible. It returns an array of strings in which the first element represents the caller, the next element represents the caller’s caller, and so on:
def func1
puts caller[0]
end
def func2
func1
end
func2 # somefile.rb:6:in 'func2'
Each string in the caller array takes the form file:line: in method.
11.4.3 Tracking Changes to a Class or Object Definition
Perhaps we should start this section by asking: Who cares? Why are we interested in tracking changes to classes?
One possible reason is that we’re trying to keep track of the state of the Ruby program being run. Perhaps we’re implementing some kind of GUI-based debugger, and we need to refresh a list of methods if our user adds one on the fly.
Another reason might be that we’re doing clever things to other classes. For example, say that we wanted to write a module that could be included in any class. From then on, any changes in that class would be traced. We could implement this module as shown in Listing 11.17.
Listing 11.17 Tracing Module
module Tracing
def self.hook_method(const, meth)
const.class_eval do
alias_method "untraced_#{meth}", "#{meth}"
define_method(meth) do |*args|
puts "#{meth} called with params (#{args.join(', ')})"
send("untraced_#{meth}",*args)
end
end
end
def self.included(const)
const.instance_methods(false).each do |m|
hook_method(const, m)
end
def const.method_added(name)
return if @disable_method_added
puts "The method #{name} was added to class #{self}"
@disable_method_added = true
Tracing.hook_method(self, name)
@disable_method_added = false
end
if const.is_a?(Class)
def const.inherited(name)
puts "The class #{name} inherited from #{self}"
end
end
if const.is_a?(Module)
def const.extended(name)
puts "The class #{name} extended itself with #{self}"
end
def const.included(name)
puts "The class #{name} included #{self} into itself"
end
end
def const.singleton_method_added(name, *args)
return if @disable_singleton_method_added
return if name == :singleton_method_added
puts "The class method #{name} was added to class #{self}"
@disable_singleton_method_added = true
singleton_class = (class << self; self; end)
Tracing.hook_method(singleton_class, name)
@disable_singleton_method_added = false
end
end
end
This module has two main methods. The first, trace_method, is pretty straightforward: When a method is added, it is immediately aliased to the name untraced_name. The original method is then replaced by our tracing code, which dumps out the method name and parameters before invoking the original method.
Note the use of alias_method here. It works much like alias, except that it works only on methods (and it itself is a method, not a keyword). It can accept method names as symbols or strings.
The second method, included, is the callback invoked when our module is inserted into a class. It does a few things to track method calls and changes to the class that happen in the future.
First, it calls trace_method for every method that already exists the target class. That lets us trace methods that were defined before the Tracing module was even included. Then it defines a method_added class method, so any subsequently added method will both be logged and traced:
class MyClass
def first_meth
end
end
class MyClass
include Tracing
def second_meth(x, y)
end
# Output: The method second_meth was added to class MyClass
end
m = MyClass.new
m.first_meth
# Output: first_meth called with params ()
m.second_meth(1, 'cat')
# Output: second_meth called with params (1, 'cat')
Next, it does some conditional things we’ll come back to in a moment. Finally, it detects the addition of new singleton methods by defining the singleton_method_ added hook on the tracing target. (Recall that a singleton method in this sense is what we usually refer to as a class method—because Class is an object.)
class MyClass
def self.a_class_method(options)
end
end
MyClass.a_class_method(green: "super")
# Output:
# The class method a_class_method was added to class MyClass
# a_class_method called with params ({:green=>"super"})
The singleton_method_added callback is defined last so that the other class methods added by the Tracing module will not be printed. Also, note that (perhaps contrary to expectation) it can track its own addition to the class; therefore, we must explicitly exclude it from tracing.
Inside the first conditional, the inherited method is defined for every Class target. It is then called whenever our target class is subclassed by another:
class MySubClass < MyClass
end
# Output: The class MySubClass inherited from MyClass
Finally, in the conditional for Module targets, we define the included and extended callbacks, so we can trace when a class includes or extends the target:
module MyModule
include Tracing
end
class MyClass
include MyModule
extend MyModule
end
# Output:
# The class MyClass included MyModule into itself
# The class MyClass extended itself with MyModule
11.4.4 Monitoring Program Execution
A Ruby program can introspect or examine its own execution. There are many applications for such a capability; most provide some type of profiling or debugging functionality, and will be examined in Chapter 16.
In some cases, those libraries may not be needed at all, because it is possible to do any amount of introspection purely in Ruby. It has a significant performance penalty (making it unsuitable for production), but the TracePoint class allows us to invoke our own code whenever an event that interests us occurs. Here is an example that traces method calls and returns, indenting the output to show nested function calls:
def factorial(n)
(1..n).inject(:*) || 1
end
@call_depth = 0
TracePoint.trace(:a_call) do |tp|
@call_depth += 1
print "#{tp.path}:#{sprintf("%-4d", tp.lineno)} #{" " * @depth}"
puts "#{tp.defined_class}##{tp.method_id}"
end
TracePoint.trace(:a_return) do |tp|
print "#{tp.path}:#{sprintf("%-4d", tp.lineno)} #{" " * @depth}"
puts "#{tp.defined_class}##{tp.method_id} => #{tp.return_value}"
@call_depth -= 1
end
factorial(4)
Here, we use TracePoint.trace, which is a shorthand for calling new and then enable. It is also possible to trace a single block of code by passing the block to TracePoint#enable. Executing our code produces the following output:
factorial.rb:12 #<Class:TracePoint>#trace
factorial.rb:12 #<Class:TracePoint>#trace =>
#<TracePoint:0x007ffe8a893f10>
factorial.rb:1 Object#factorial
factorial.rb:2 Enumerable#inject
factorial.rb:2 Range#each
factorial.rb:2 Fixnum#*
factorial.rb:2 Fixnum#* => 2
factorial.rb:2 Fixnum#*
factorial.rb:2 Fixnum#* => 6
factorial.rb:2 Fixnum#*
factorial.rb:2 Fixnum#* => 24
factorial.rb:2 Range#each => 1..4
factorial.rb:2 Enumerable#inject => 24
factorial.rb:3 Object#factorial => 24
Another related method is Kernel#trace_var, which invokes a block whenever a global variable is assigned a value.
If you simply want to trace everything, rather than write your own specific tracers, you can just require the tracer standard library. Here is a program called factorial.rb:
def factorial(n)
(1..n).inject(:*) || 1
end
factorial(4)
Given this program, you can simply load tracer from the command line:
$ ruby —disable-gems —r tracer factorial.rb
#0:factorial.rb:1::-: def factorial(n)
#0:factorial.rb:5::-: factorial(4)
#0:factorial.rb:1:Object:>: def factorial(n)
#0:factorial.rb:2:Object:-: (1..n).inject(:*) || 1
#0:factorial.rb:2:Object:-: (1..n).inject(:*) || 1
#0:factorial.rb:3:Object:<: end
The lines output by tracer show the thread number, the filename and line number, the class being used, the event type, and the line from the source file being executed. The event types include '-' when a source line is executed, '>' for a call, '<' for a return, 'C' for a class, and'E' for an end. (If you do not disable Rubygems, or if you require some other library, you will see many other lines of output as well.)
These techniques can be used to build quite sophisticated debugging and instrumentation tools. We’ll examine how to use some tools that have already been written, such as pry, rbtrace, and ruby-prof, in Chapter 16. In the meantime, we encourage reading documentation, experimentation, and investigation as an excellent way to learn more.
11.5 Conclusion
In this chapter, we’ve seen a few of the more esoteric or advanced techniques in OOP, as well as some of the more everyday usages. We’ve seen some of the design patterns implemented (and some that don’t need to be). We’ve also looked at Ruby’s reflection API, some interesting consequences of Ruby’s dynamic nature, and various neat tricks that can be done in a dynamic language.
It’s time now to rejoin the real world. After all, OOP is not an end in itself but rather a means to an end; the end is to write applications that are effective, bug free, and maintainable.
In modern computing, these applications sometimes need a graphical interface. In Chapter 12, “Graphical Interfaces for Ruby,” we discuss creating graphical interfaces in Ruby.