The Well-Grounded Rubyist, Second Edition (2014)
Part 2. Built-in classes and modules
Chapter 8. Strings, symbols, and other scalar objects
This chapter covers
· String object creation and manipulation
· Methods for transforming strings
· Symbol semantics
· String/symbol comparison
· Integers and floats
· Time and date objects
The term scalar means one-dimensional. Here, it refers to objects that represent single values, as opposed to collection or container objects that hold multiple values. There are some shades of gray: strings, for example, can be viewed as collections of characters in addition to being single units of text. Scalar is to some extent in the eye of the beholder. Still, as a good first approximation, you can look at the classes discussed in this chapter as classes of one-dimensional, bite-sized objects, in contrast to the collection objects that will be the focus of the next chapter.
The built-in objects we’ll look at in this chapter include the following:
· Strings, which are Ruby’s standard way of handling textual material of any length
· Symbols, which are (among other things) another way of representing text in Ruby
· Integers
· Floating-point numbers
· Time, Date, and DateTime objects
All of these otherwise rather disparate objects are scalar—they’re one-dimensional, noncontainer objects with no further objects lurking inside them the way arrays have. This isn’t to say scalars aren’t complex and rich in their semantics; as you’ll see, they are.
8.1. Working with strings
Ruby provides two built-in classes that, between them, provide all the functionality of text representation and manipulation: the String class and the Symbol class. Strings and symbols are deeply different from each other, but they’re similar enough in their shared capacity to represent text that they merit being discussed in the same chapter. We’ll start with strings, which are the standard way to represent bodies of text of arbitrary content and length. You’ve seen strings in many contexts already; here, we’ll get more deeply into some of their semantics and abilities. We’ll look first at how you write strings, after which we’ll discuss a number of ways in which you can manipulate strings, query them (for example, as to their length), compare them with each other, and transform them (from lowercase to uppercase, and so on). We’ll also examine some further details of the process of converting strings with to_i and related methods.
8.1.1. String notation
A string literal is generally enclosed in quotation marks:
"This is a string."
Single quotes can also be used:
'This is also a string.'
But a single-quoted string behaves differently, in some circumstances, than a double-quoted string. The main difference is that string interpolation doesn’t work with single-quoted strings. Try these two snippets, and you’ll see the difference:
puts "Two plus two is #{2 + 2}."
puts 'Two plus two is #{2 + 2}.'
As you’ll see if you paste these lines into irb, you get two very different results:
Two plus two is 4.
Two plus two is #{2 + 2}.
Single quotes disable the #{...} interpolation mechanism. If you need that mechanism, you can’t use single quotes. Conversely, you can, if necessary, escape (and thereby disable) the string interpolation mechanism in a double-quoted string, using backslashes:
puts "Escaped interpolation: \"\#{2 + 2}\"."
Single- and double-quoted strings also behave differently with respect to the need to escape certain characters. The following statements document and demonstrate the differences. Look closely at which are single-quoted and which are double-quoted, and at how the backslash is used:
puts "Backslashes (\\) have to be escaped in double quotes."
puts 'You can just type \ once in a single quoted string.'
puts "But whichever type of quotation mark you use..."
puts "...you have to escape its quotation symbol, such as \"."
puts 'That applies to \' in single-quoted strings too.'
puts 'Backslash-n just looks like \n between single quotes.'
puts "But it means newline\nin a double-quoted string."
puts 'Same with \t, which comes out as \t with single quotes...'
puts "...but inserts a tab character:\tinside double quotes."
puts "You can escape the backslash to get \\n and \\t with double quotes."
Here’s the output from this barrage of quotations. It doesn’t line up line-for-line with the code, but you can see why if you look at the statement that outputs a newline character:
Backslashes (\) have to be escaped in double quotes.
You can just type \ once in a single quoted string.
But whichever type of quotation mark you use...
...you have to escape its quotation symbol, such as ".
That applies to ' in single-quoted strings too.
Backslash-n just looks like \n between single quotes.
But it means newline
in a double-quoted string.
Same with \t, which comes out as \t with single quotes...
...but inserts a tab character: inside double quotes.
You can escape the backslash to get \n and \t with double quotes.
You’ll see other cases of string interpolation and character escaping as we proceed. Meanwhile, by far the best way to get a feel for these behaviors firsthand is to experiment with strings in irb.
Ruby gives you several ways to write strings in addition to single and double quotation marks.
Other quoting mechanisms
The alternate quoting mechanisms take the form %char{text}, where char is one of several special characters and the curly braces stand in for a delimiter of your choosing. Here’s an example of one of these mechanisms: %q, which produces a single-quoted string:
puts %q{You needn't escape apostrophes when using %q.}
As the sample sentence points out, because you’re not using the single-quote character as a quote character, you can use it unescaped inside the string.
Also available to you are %Q{}, which generates a double-quoted string, and plain %{} (percent sign and delimiter), which also generates a double-quoted string. Naturally, you don’t need to escape the double-quote character inside strings that are represented with either of these notations.
The delimiter for the %-style notations can be just about anything you want, as long as the opening delimiter matches the closing one. Matching in this case means either making up a left/right pair of braces (curly, curved, or square) or being two of the same character. Thus all of the following are acceptable:
%q-A string-
%Q/Another string/
%[Yet another string]
You can’t use alphanumeric characters as your delimiters, but if you feel like being obscure, you can use a space. It’s hard to see in an example, so the entire following example is surrounded by square brackets that you shouldn’t type if you’re entering the example in an irb session or Ruby program file:
[%q Hello! ]
The space-delimited example, aside from being silly (although instructive), brings to mind the question of what happens if you use the delimiter inside the string (because many strings have spaces inside them). If the delimiter is a single character, you have to escape it:
[%q Hello\ there! ]
%q-Better escape the \- inside this string!-
If you’re using left/right matching braces and Ruby sees a left-hand one inside the string, it assumes that the brace is part of the string and looks for a matching right-hand one. If you want to include an unmatched brace of the same type as the ones you’re using for delimiters, you have to escape it:
%Q[I can put [] in here unescaped.]
%q(I have to escape \( if I use it alone in here.)
%Q(And the same goes for \).)
irb doesn’t play well with some of this syntax
irb has its own Ruby parser, which has to contend with the fact that as it parses one line, it has no way of knowing what the next line will be. The result is that irb does things a little differently from the Ruby interpreter. In the case of quote mechanisms, you may find that in irb, escaping unmatched square and other brackets produces odd results. Generally, you’re better off plugging these examples into the command-line format ruby –e 'puts %q[ Example: \[ ]' and similar.
Each of the %char-style quoting mechanisms generates either a single- or double-quoted string. That distinction pervades stringdom; every string is one or the other, no matter which notation you use—including the next one we’ll look at, the “here” document syntax.
“Here” documents
A “here” document, or here-doc, is a string, usually a multiline string, that often takes the form of a template or a set of data lines. It’s said to be “here” because it’s physically present in the program file, not read in from a separate text file.
Here-docs come into being through the << operator, as shown in this irb excerpt:
>> text = <<EOM
This is the first line of text.
This is the second line.
Now we're done.
EOM
=> "This is the first line of text.\nThis is the second line.\n![]() Now we're done.\n"
Now we're done.\n"
The expression <<EOM means the text that follows, up to but not including the next occurrence of “EOM.” The delimiter can be any string; EOM (end of message) is a common choice. It has to be flush-left, and it has to be the only thing on the line where it occurs. You can switch off the flush-left requirement by putting a hyphen before the << operator:
>> text = <<-EOM
The EOM doesn't have to be flush left!
EOM
=> "The EOM doesn't have to be flush left!\n"
The EOM that stops the reading of this here-doc (only a one-line document this time) is in the middle of the line.
By default, here-docs are read in as double-quoted strings. Thus they can include string interpolation and use of escape characters like \n and \t. If you want a single-quoted here-doc, put the closing delimiter in single quotes when you start the document. To make the difference clearer, this example includes a puts of the here-doc:
>> text = <<-'EOM'
Single-quoted!
Note the literal \n.
And the literal #{2+2}.
EOM
=> "Single-quoted!\nNote the literal \\n.\nAnd the literal \#{2+2}.\n"
>> puts text
Single-quoted!
Note the literal \n.
And the literal #{2+2}.
The <<EOM (or equivalent) doesn’t have to be the last thing on its line. Wherever it occurs, it serves as a placeholder for the upcoming here-doc. Here’s one that gets converted to an integer and multiplied by 10:
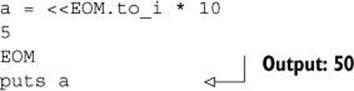
You can even use a here-doc in a literal object constructor. Here’s an example where a string gets put into an array, creating the string as a here-doc:
array = [1,2,3, <<EOM, 4]
This is the here-doc!
It becomes array[3].
EOM
p array
The output is
[1, 2, 3, "This is the here-doc!\nIt becomes array[3].\n", 4]
And you can use the <<EOM notation as a method argument; the argument becomes the here-doc that follows the line on which the method call occurs. This can be useful if you want to avoid cramming too much text into your argument list:
do_something_with_args(a, b, <<EOM)
http://some_very_long_url_or_other_text_best_put_on_its_own_line
EOM
In addition to creating strings, you need to know what you can do with them. You can do a lot, and we’ll look at much of it in detail, starting with the basics of string manipulation.
8.1.2. Basic string manipulation
Basic in this context means manipulating the object at the lowest levels: retrieving and setting substrings, and combining strings with each other. From Ruby’s perspective, these techniques aren’t any more basic than those that come later in our survey of strings; but conceptually, they’re closer to the string metal, so to speak.
Getting and setting substrings
To retrieve the nth character in a string, you use the [] operator/method, giving it the index, on a zero-origin basis, for the character you want. Negative numbers index from the end of the string:
>> string = "Ruby is a cool language."
=> "Ruby is a cool language."
>> string[5]
=> "i"
>> string[-12]
=> "o"
If you provide a second integer argument, m, you’ll get a substring of m characters, starting at the index you’ve specified:
>> string[5,10]
=> "is a cool "
You can also provide a single range object as the argument. We’ll look at ranges in more depth later; for now, you can think of n..m as all of the values between n and m, inclusive (or exclusive of m, if you use three dots instead of two). The range can use negative numbers, which count from the end of the string backward, but the second index always has to be closer to the end of the string than the first index; the index logic only goes from left to right:
>> string[7..14]
=> " a cool "
>> string[-12..-3]
=> "ol languag"
>> string[-12..20]
=> "ol langua"
>> string[15..-1]
=> "language."
You can also grab substrings based on an explicit substring search. If the substring is found, it’s returned; if not, the return value is nil:
>> string["cool lang"]
=> "cool lang"
>> string["very cool lang"]
=> nil
It’s also possible to search for a pattern match using the [] technique with a regular expression—[] is a method, and what’s inside it are the arguments, so it can do whatever it’s programmed to do:
>> string[/c[ol ]+/]
=> "cool l"
We’ll look at regular expressions separately in chapter 11, at which point you’ll get a sense of the possibilities of this way of looking for substrings.
The [] method is also available under the name slice. Furthermore, a receiver-changing version of slice, namely slice!, removes the character(s) from the string permanently:
>> string.slice!("cool ")
=> "cool "
>> string
=> "Ruby is a language."
To set part of a string to a new value, you use the []= method. It takes the same kinds of indexing arguments as [] but changes the values to what you specify. Putting the preceding little string through its paces, here are some substring-setting examples, with an examination of the changed string after each one:
>> string = "Ruby is a cool language."
=> "Ruby is a cool language."
>> string["cool"] = "great"
=> "great"
>> string
=> "Ruby is a great language."
>> string[-1] = "!"
=> "!"
>> string
=> "Ruby is a great language!"
>> string[-9..-1] = "thing to learn!"
=> "thing to learn!"
>> string
=> "Ruby is a great thing to learn!"
Integers, ranges, strings, and regular expressions can thus all work as index or substring specifiers. If you try to set part of the string that doesn’t exist—that is, a too-high or too-low numerical index, or a string or regular expression that doesn’t match the string—you get a fatal error.
In addition to changing individual strings, you can also combine strings with each other.
Combining strings
There are several techniques for combining strings. These techniques differ as to whether the second string is permanently added to the first or whether a new, third string is created out of the first two—in other words, whether the operation changes the receiver.
To create a new string consisting of two or more strings, you can use the + method/operator to run the original strings together. Here’s what irb has to say about adding strings:
>> "a" + "b"
=> "ab"
>> "a" + "b" + "c"
=> "abc"
The string you get back from + is always a new string. You can test this by assigning a string to a variable, using it in a + operation, and checking to see what its value is after the operation:

The expression str + "there." (which is syntactic sugar for the method call str.+ ("there")) evaluates to the new string "Hi there." ![]() but leaves str unchanged
but leaves str unchanged ![]() .
.
To add (append) a second string permanently to an existing string, use the << method, which also has a syntactic sugar, pseudo-operator form:

In this example, the original string str has had the new string appended to it, as you can see from the evaluation of str at the end ![]() .
.
String interpolation is (among other things) another way to combine strings. You’ve seen it in action already, but let’s take the opportunity to look at a couple of details of how it works.
String combination via interpolation
At its simplest, string interpolation involves dropping one existing string into another:
>> str = "Hi "
=> "Hi "
>> "#{str} there."
=> "Hi there."
The result is a new string: "Hi there." However, it’s good to keep in mind that the interpolation can involve any Ruby expression:
>> "The sum is #{2 + 2}."
=> "The sum is 4."
The code inside the curly braces can be anything. (They do have to be curly braces; it’s not like %q{}, where you can choose your own delimiter.) It’s unusual to make the code terribly complex, because that detracts from the structure and readability of the program—but Ruby is happy with any interpolated code and will obligingly place a string representation of the value of the code in your string:
>> "My name is #{class Person
attr_accessor :name
end
d = Person.new
d.name = "David"
d.name
}."
=> "My name is David."
You really, really don’t want to do this, but it’s important to understand that you can interpolate any code you want. Ruby patiently waits for it all to run and then snags the final value of the whole thing (d.name, in this case, because that’s the last expression inside the interpolation block) and interpolates it.
There’s a much nicer way to accomplish something similar. Ruby interpolates by calling to_s on the object to which the interpolation code evaluates. You can take advantage of this to streamline string construction, by defining your own to_s methods appropriately:
>> class Person
>> attr_accessor :name
>> def to_s
>> name
>> end
>> end
=> :to_s
>> david = Person.new
=> #<Person:0x00000101a73cb0>
>> david.name = "David"
=> "David"
>> "Hello, #{david}!"
=> "Hello, David!"
Here the object david serves as the interpolated code, and produces the result of its to_s operation, which is defined as a wrapper around the name getter method. Using the to_s hook is a useful way to control your objects’ behavior in interpolated strings. Remember, though, that you can also say (in the preceding example) david.name. So if you have a broader use for a class’s to_s than a very specific interpolation scenario, you can usually accommodate it.
After you’ve created and possibly altered a string, you can ask it for a considerable amount of information about itself. We’ll look now at how to query strings.
8.1.3. Querying strings
String queries come in a couple of flavors. Some give you a Boolean (true or false) response, and some give you a kind of status report on the current state of the string. We’ll organize our exploration of string query methods along these lines.
Boolean string queries
You can ask a string whether it includes a given substring, using include?. Given the string used earlier ("Ruby is a cool language."), inclusion queries might look like this:
>> string.include?("Ruby")
=> true
>> string.include?("English")
=> false
You can test for a given start or end to a string with start_with? and end_with?:
>> string.start_with?("Ruby")
=> true
>> string.end_with?("!!!")
=> false
And you can test for the absence of content—that is, for the presence of any characters at all—with the empty? method:
>> string.empty?
=> false
>> "".empty?
=> true
Keep in mind that whitespace counts as characters; the string " " isn’t empty.
Content queries
The size and length methods (they’re synonyms for the same method) do what their names suggest they do:
>> string.size
=> 24
If you want to know how many times a given letter or set of letters occurs in a string, use count. To count occurrences of one letter, provide that one letter as the argument. Still using the string "Ruby is a cool language.", there are three occurrences of "a":
>> string.count("a")
=> 3
To count how many of a range of letters there are, you can use a hyphen-separated range:
>> string.count("g-m")
=> 5
Character specifications are case-sensitive:
>> string.count("A-Z")
=> 1
You can also provide a written-out set of characters you want to count:
![]()
To negate the search—that is, to count the number of characters that don’t match the ones you specify—put a ^ (caret) at the beginning of your specification:
>> string.count("^aey. ")
=> 14
>> string.count("^g-m")
=> 19
(If you’re familiar with regular expressions, you’ll recognize the caret technique as a close cousin of regular expression character class negation.) You can combine the specification syntaxes and even provide more than one argument:
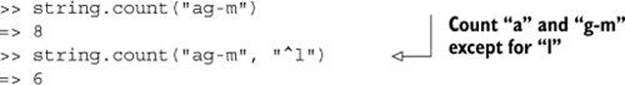
Another way to query strings as to their content is with the index method. index is sort of the inverse of using [] with a numerical index: instead of looking up a substring at a particular index, it returns the index at which a given substring occurs. The first occurrence from the left is returned. If you want the first occurrence from the right, use rindex:
>> string.index("cool")
=> 10
>> string.index("l")
=> 13
>> string.rindex("l")
=> 15
Although strings are made up of characters, Ruby has no separate character class. One-character strings can tell you their ordinal code, courtesy of the ord method:
>> "a".ord
=> 97
If you take the ord of a longer string, you get the code for the first character:
>> "abc".ord
=> 97
The reverse operation is available as the chr method on integers:
>> 97.chr
=> "a"
Asking a number that doesn’t correspond to any character for its chr equivalent causes a fatal error.
In addition to providing information about themselves, strings can compare themselves with other strings, to test for equality and order.
8.1.4. String comparison and ordering
The String class mixes in the Comparable module and defines a <=> method. Strings are therefore good to go when it comes to comparisons based on character code (ASCII or otherwise) order:
>> "a" <=> "b"
=> -1
>> "b" > "a"
=> true
>> "a" > "A"
=> true
>> "." > ","
=> true
Remember that the spaceship method/operator returns -1 if the right object is greater, 1 if the left object is greater, and 0 if the two objects are equal. In the first case in the previous sequence, it returns -1 because the string "b" is greater than the string "a". But "a" is greater than "A", because the order is done by character value and the character values for "a" and "A" are 97 and 65, respectively, in Ruby’s default encoding of UTF-8. Similarly, the string "." is greater than "," because the value for a period is 46 and that for a comma is 44. (See section 8.1.7 for more on encoding.)
Like Ruby objects in general, strings have several methods for testing equality.
Comparing two strings for equality
The most common string comparison method is ==,which tests for equality of string content:
>> "string" == "string"
=> true
>> "string" == "house"
=> false
The two literal "string" objects are different objects, but they have the same content. Therefore, they pass the == test. The string "house" has different content and is therefore not considered equal, based on ==, with "string".
Another equality-test method, String#eql?, tests two strings for identical content. In practice, it usually returns the same result as ==. (There are subtle differences in the implementations of these two methods, but you can use either. You’ll find that == is more common.) A third method,String#equal?, behaves like equal? usually does: it tests whether two strings are the same object—or for that matter, whether a string and any other object are the same object:
>> "a" == "a"
=> true
>> "a".equal?("a")
=> false
>> "a".equal?(100)
=> false
The first test succeeds because the two strings have the same contents. The second test fails because the first string isn’t the same object as the second string. (And of course no string is the same object as the integer 100, so that test fails too.) This is a good reminder of the fact that strings that appear identical to the eye may, to Ruby, have different object identities.
The next two sections will present string transformations and conversions, in that order. The difference between the two is that a transformation involves applying some kind of algorithm or procedure to the content of a string, whereas a conversion means deriving a second, unrelated object—usually not even a string—from the string.
8.1.5. String transformation
String transformations in Ruby fall informally into three categories: case, formatting, and content transformations. We’ll look at each in turn.
Case transformations
Strings let you raise, lower, and swap their case. All of the case-changing methods have receiver-modifying bang equivalents:
>> string = "David A. Black"
=> "David A. Black"
>> string.upcase
=> "DAVID A. BLACK"
>> string.downcase
=> "david a. black"
>> string.swapcase
=> "dAVID a. bLACK"
There’s also a nice refinement that lets you capitalize the string:
>> string = "david"
=> "david"
>> string.capitalize
=> "David"
Like the other case transformers, capitalize has an in-place equivalent, capitalize!.
You can perform a number of transformations on the format of a string, most of which are designed to help you make your strings look nicer.
Formatting transformations
Strictly speaking, format transformations are a subset of content transformations; if the sequence of characters represented by the string didn’t change, it wouldn’t be much of a transformation. We’ll group under the formatting heading some transformations whose main purpose is to enhance the presentation of strings.
The rjust and ljust methods expand the size of your string to the length you provide in the first argument, padding with blank spaces as necessary:
>> string = "David A. Black"
=> "David A. Black"
>> string.rjust(25)
=> " David A. Black"
>> string.ljust(25)
=> "David A. Black "
If you supply a second argument, it’s used as padding. This second argument can be more than one character long:
>> string.rjust(25,'.')
=> "...........David A. Black"
>> string.rjust(25,'><')
=> "><><><><><>David A. Black"
The padding pattern is repeated as many times as it will fit, truncating the last placement if necessary.
And to round things out in the justification realm, there’s a center method, which behaves like rjust and ljust but puts the characters of the string in the center:
>> "The middle".center(20, "*")
=> "*****The middle*****"
Odd-numbered padding spots are rendered right-heavy:
>> "The middle".center(21, "*")
=> "*****The middle******"
Finally, you can prettify your strings by stripping whitespace from either or both sides, using the strip, lstrip, and rstrip methods:
>> string = " David A. Black "
=> " David A. Black "
>> string.strip
=> "David A. Black"
>> string.lstrip
=> "David A. Black "
>> string.rstrip
=> " David A. Black"
All three of the string-stripping methods have ! versions that change the string permanently in place.
Content transformations
We’ll look at some, though not all, of the ways you can transform a string by changing its contents.
The chop and chomp methods are both in the business of removing characters from the ends of strings—but they go about it differently. The main difference is that chop removes a character unconditionally, whereas chomp removes a target substring if it finds that substring at the end of the string. By default, chomp’s target substring is the newline character, \n. You can override the target by providing chomp with an argument:
>> "David A. Black".chop
=> "David A. Blac"
>> "David A. Black\n".chomp
=> "David A. Black"
>> "David A. Black".chomp('ck')
=> "David A. Bla"
By far the most common use of either chop or chomp is the use of chomp to remove newlines from the ends of strings, usually strings that come to the program in the form of lines of a file or keyboard input.
Both chop and chomp have bang equivalents that change the string in place.
On the more radical end of character removal stands the clear method, which empties a string of all its characters, leaving the empty string:
>> string = "David A. Black"
=> "David A. Black"
>> string.clear
=> ""
>> string
=> ""
String#clear is a great example of a method that changes its receiver but doesn’t end with the ! character. The name clear makes it clear, so to speak, that something is happening to the string. There would be no point in having a clear method that didn’t change the string in place; it would just be a long-winded way to say "" (the empty string).
If you want to swap out all your characters without necessarily leaving your string bereft of content, you can use replace, which takes a string argument and replaces the current content of the string with the content of that argument:
>> string = "(to be named later)"
=> "(to be named later)"
>> string.replace("David A. Black")
=> "David A. Black"
As with clear, the replace method permanently changes the string—as suggested, once again, by the name.
You can target certain characters for removal from a string with delete. The arguments to delete follow the same rules as the arguments to count (see section 8.1.3):
>> "David A. Black".delete("abc")
=> "Dvid A. Blk"
>> "David A. Black".delete("^abc")
=> "aac"
>> "David A. Black".delete("a-e","^c")
=> "Dvi A. Blck"
Another specialized string transformation is crypt, which performs a Data Encryption Standard (DES) encryption on the string, similar to the Unix crypt(3) library function. The single argument to crypt is a two-character salt string:
>> "David A. Black".crypt("34")
=> "347OEY.7YRmio"
Make sure you read up on the robustness of any encryption techniques you use, including crypt.
The last transformation technique we’ll look at is string incrementation. You can get the next-highest string with the succ method (also available under the name next). The ordering of strings is engineered to make sense, even at the expense of strict character-code order: "a" comes after "`"(the backtick character) as it does in ASCII, but after "z" comes "aa", not "{". Incrementation continues, odometer-style, throughout the alphabet:
>> "a".succ
=> "b"
>> "abc".succ
=> "abd"
>> "azz".succ
=> "baa"
The ability to increment strings comes in handy in cases where you need batch-generated unique strings, perhaps to use as filenames.
As you’ve already seen, strings (like other objects) can convert themselves with methods in the to_* family. We’ll look next at some further details of string conversion.
8.1.6. String conversions
The to_i method you saw in the last chapter is one of the conversion methods available to strings. This method offers an additional feature: if you give it a positive integer argument in the range 2–36, the string you’re converting is interpreted as representing a number in the base corresponding to the argument.
For example, if you want to interpret 100 as a base 17 number, you can do so like this:
>> "100".to_i(17)
=> 289
The output is the decimal equivalent of 100, base 17.
Base 8 and base 16 are considered special cases and have dedicated methods so you don’t have to go the to_i route. These methods are oct and hex, respectively:
>> "100".oct
=> 64
>> "100".hex
=> 256
Other conversion methods available to strings include to_f (to float), to_s (to string; it returns its receiver), and to_sym or intern, which converts the string to a Symbol object. None of these hold any particular surprises:
>> "1.2345".to_f
=> 1.2345
>> "Hello".to_s
=> "Hello"
>> "abcde".to_sym
=> :abcde
>> "1.2345and some words".to_f
=> 1.2345
>> "just some words".to_i
=> 0
Every string consists of a sequence of bytes. The bytes map to characters. Exactly how they map to characters—how many bytes make up a character, and what those characters are—is a matter of encoding, which we’ll now take a brief look at.
8.1.7. String encoding: A brief introduction
The subject of character encoding is interesting but vast. Encodings are many, and there’s far from a global consensus on a single best one. Ruby 1.9 added a great deal of encoding intelligence and functionality to strings. The big change in Ruby 2 was the use of UTF-8, rather than US-ASCII, as the default encoding for Ruby scripts. Encoding in Ruby continues to be an area of ongoing discussion and development. We won’t explore it deeply here, but we’ll put it on our radar and look at some important encoding-related techniques.
Setting the encoding of the source file
To start with, your source code uses a certain encoding. By default, Ruby source files use UTF-8 encoding. You can determine this by asking Ruby to display the value __ENCODING__. Put this line in a file, and run it:
![]()
You need to put the line in a file because you may get different results if you run the command directly from the command line. The reason for the difference is that a fileless Ruby run takes its encoding from the current locale setting. You can verify this by observing the effect of running the same command with the LANG environment variable set to a different value:
![]()
To change the encoding of a source file, you need to use a magic comment at the top of the file. The magic comment takes the form
# encoding: encoding
where encoding is an identifier for an encoding. For example, to encode a source file in US-ASCII, you put this line at the top of the file:
# encoding: ASCII
This line (which can use the word coding rather than the word encoding, if you prefer) is sometimes referred to as a “magic comment.”
In addition to your source file, you can also query and set the encoding of individual strings.
Encoding of individual strings
Strings will tell you their encoding:
>> str = "Test string"
=> "Test string"
>> str.encoding
=> #<Encoding:UTF-8>
You can encode a string with a different encoding, as long as the conversion from the original encoding to the new one—the transcoding—is permitted (which depends on the capability of the string with the new encoding):
>> str.encode("US-ASCII")
=> "Test string"
If you need to, you can force an encoding with the force_encoding method, which bypasses the table of “permitted” encodings and encodes the bytes of the string with the encoding you specify, unconditionally.
The bang version of encode changes the encoding of the string permanently:
>> str.encode!("US-ASCII")
=> "Test string"
>> str.encoding
=> #<Encoding:US-ASCII>
The encoding of a string is also affected by the presence of certain characters in a string and/or by the amending of the string with certain characters. You can represent arbitrary characters in a string using either the \x escape sequence, for a two-digit hexadecimal number representing a byte, or the \u escape sequence, which is followed by a UTF-8 code, and inserts the corresponding character.
The effect on the string’s encoding depends on the character. Given an encoding of US-ASCII, adding an escaped character in the range 0–127 (0x00-0x7F in hexadecimal) leaves the encoding unchanged. If the character is in the range 128–255 (0xA0-0xFF), the encoding switches to UTF-8. If you add a UTF-8 character in the range 0x0000–0x007F, the ASCII string’s encoding is unaffected. UTF-8 codes higher than 0x007F cause the string’s encoding to switch to UTF-8. Here’s an example:

The \u escape sequence ![]() lets you insert any UTF-8 character, whether you can type it directly or not.
lets you insert any UTF-8 character, whether you can type it directly or not.
There’s a great deal more to the topic of character and string encoding, but you’ve seen enough at this point to know the kinds of operations that are available. How deeply you end up exploring encoding will depend on your needs as a Ruby developer. Again, be aware that encoding has tended to be the focus of particularly intense discussion and development in Ruby (and elsewhere).
At this point, we’ll wrap up our survey of string methods and turn to a class with some strong affinities with the String class but also some interesting differences: the Symbol class.
8.2. Symbols and their uses
Symbols are instances of the built-in Ruby class Symbol. They have a literal constructor: the leading colon. You can always recognize a symbol literal (and distinguish it from a string, a variable name, a method name, or anything else) by this token:
:a
:book
:"Here's how to make a symbol with spaces in it."
You can also create a symbol programmatically by calling the to_sym method (also known by the synonym intern) on a string, as you saw in the last section:
>> "a".to_sym
=> :a
>> "Converting string to symbol with intern....".intern
=> :"Converting string to symbol with intern...."
Note the telltale leading colons on the evaluation results returned by irb.
You can easily convert a symbol to a string:
>> :a.to_s
=> "a"
That’s just the beginning, though. Symbols differ from strings in important ways. Let’s look at symbols on their own terms and then come back to a comparative look at symbols and strings.
8.2.1. Chief characteristics of symbols
Symbols are a hard nut to crack for many people learning Ruby. They’re not quite like anything else, and they don’t correspond exactly to data types most people have come across previously. In some respects they’re rather stringlike, but at the same time, they have a lot in common with integers. It’s definitely worth a close look at their chief characteristics: immutability and uniqueness.
Immutability
Symbols are immutable. There’s no such thing as appending characters to a symbol; once the symbol exists, that’s it. You’ll never see :abc << :d or anything of that kind.
That’s not to say that there’s no symbol :abcd. There is, but it’s a completely different symbol from :abc. You can’t change :abc itself. Like an integer, a symbol can’t be changed. When you want to refer to 5, you don’t change the object 4 by adding 1 to it. You can add 1 to 4 by calling 4.+(1)(or 4 + 1), but you can’t cause the object 4 to be the object 5. Similarly, although you can use a symbol as a hint to Ruby for the generation of another symbol, you can’t alter a given symbol.
Uniqueness
Symbols are unique. Whenever you see :abc, you’re seeing a representation of the same object. Again, symbols are more like integers than strings in this respect. When you see the notation "abc" in two places, you’re looking at representations of two different string objects; the literal string constructor "" creates a new string. But :abc is always the same Symbol object, just as 100 is always the same object.
You can see the difference between strings and symbols in the matter of uniqueness by querying objects as to their object_id, which is unique for every separate object:
>> "abc".object_id
=> 2707250
>> "abc".object_id
=> 2704780
>> :abc.object_id
=> 160488
>> :abc.object_id
=> 160488
The "abc" notation creates a new string each time, as you can see from the fact that each such string has a different object ID. But the :abc notation always represents the same object; :abc identifies itself with the same ID number no matter how many times you ask it.
Because symbols are unique, there’s no point having a constructor for them; Ruby has no Symbol#new method. You can’t create a symbol any more than you can create a new integer. In both cases, you can only refer to them.
The word symbol has broad connotations; it sounds like it might refer to any identifier or token. It’s important to get a handle on the relation between symbol objects and symbols in a more generic sense.
8.2.2. Symbols and identifiers
This code includes one Symbol object (:x) and one local variable identifier (s):
s = :x
But it’s not unusual to refer to the s as a symbol. And it is a symbol, in the sense that it represents something other than itself. In fact, one of the potential causes of confusion surrounding the Symbol class and symbol objects is the fact that symbol objects don’t represent anything other than themselves. In a sense, a variable name is more “symbolic” than a symbol.
And a connection exists between symbol objects and symbolic identifiers. Internally, Ruby uses symbols to keep track of all the names it’s created for variables, methods, and constants. You can see a list of them, using the Symbol.all_symbols class method. Be warned; there are a lot of them! Here’s the tip of the iceberg:
>> Symbol.all_symbols
=> [:inspect, :intern, :object_id, :const_missing, :method_missing,
:method_added, :singleton_method_added, :method_removed,
:singleton_method_removed,
And on it goes, listing more than 3,000 symbols.
When you assign a value to a variable or constant, or create a class or write a method, the identifier you choose goes into Ruby’s internal symbol table. You can check for evidence of this with some array-probing techniques:
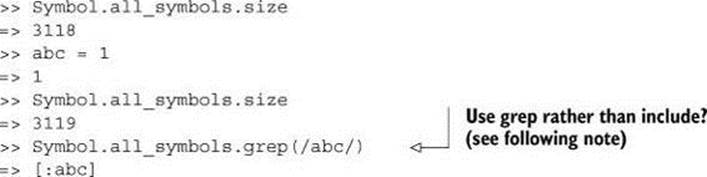
You can see from the measurement of the size of the array returned by all_symbols that it grows by 1 when you make an assignment to abc. In addition, the symbol :abc is now present in the array, as demonstrated by the grep operation.
Tests for symbol inclusion are always true
grep is a regular expression–based way of looking for matching elements in an array. Why not just say this?
>> Symbol.all_symbols.include?(:abc)
Because it will always be true! The very act of writing :abc in the include? test puts the symbol :abc into the symbol table, so the test passes even if there was no previous assignment to the identifier abc.
The symbol table is just that: a symbol table. It’s not an object table. If you use an identifier for more than one purpose—say, as a local variable and also as a method name—the corresponding symbol will still only appear once in the symbol table:

Ruby keeps track of what symbols it’s supposed to know about so it can look them up quickly. The inclusion of a symbol in the symbol table doesn’t tell you anything about what the symbol is for.
Coming full circle, you can also see that when you assign a symbol to a variable, that symbol gets added to the table:
>> abc = :my_symbol
=> :my_symbol
>> Symbol.all_symbols.size
=> 3020
>> Symbol.all_symbols.grep(/my_symbol/)
=> [:my_symbol]
Not only symbols matching variable and method names are put in the table; any symbol Ruby sees anywhere in the program is added. The fact that :my_symbol gets stored in the symbol table by virtue of your having used it means that the next time you use it, Ruby will be able to look it up quickly. And unlike a symbol that corresponds to an identifier to which you’ve assigned a more complex object, like a string or array, a symbol that you’re using purely as a symbol, like :my_symbol, doesn’t require any further lookup. It’s just itself: the symbol :my_symbol.
Ruby is letting you, the programmer, use the same symbol-storage mechanism that Ruby uses to track identifiers. Only you’re not tracking identifiers; you’re using symbols for your own purposes. But you still get the benefits of Ruby exposing the whole symbol mechanism for programmer-side use.
What do you do with symbols?
8.2.3. Symbols in practice
Symbols have a number of uses, but most appearances fall into one of two categories: method arguments and hash keys.
Symbols as method arguments
A number of core Ruby methods take symbols as arguments. Many such methods can also take strings. You’ve already seen a couple of examples from the attr_* method family:
attr_accessor :name
attr_reader :age
The send method, which sends a message to an object without the dot, can take a symbol:
"abc".send(:upcase)
You don’t normally need send if you know the whole method name in advance. But the lesson here is that send can take a symbol, which remains true even if the symbol is stored in a variable, rather than written out, and/or determined dynamically at runtime.
At the same time, most methods that take symbols can also take strings. You can replace :upcase with "upcase" in the previous send example, and it will work. The difference is that by supplying :upcase, you’re saving Ruby the trouble of translating the string upcase to a symbol internally on its way to locating the method.
It’s possible to go overboard. You’ll occasionally see code like this:
some_object.send(method_name.to_sym)
An extra step is taken (the to_sym conversion) on the way to passing an argument to send. There’s no point in doing this unless the method being called can only handle symbols. If it can handle strings and you’ve got a string, pass the string. Let the method handle the conversion if one is needed.
Consider allowing symbols or strings as method arguments
When you’re writing a method that will take an argument that could conceivably be a string or a symbol, it’s often nice to allow both. It’s not necessary in cases where you’re dealing with user-generated, arbitrary strings, or where text read in from a file is involved; those won’t be in symbol form anyway. But if you have a method that expects, say, a method name, or perhaps a value from a finite table of tags or labels, it’s polite to allow either strings or symbols. That means avoiding doing anything to the object that requires it to be one or the other and that will cause an error if it’s the wrong one. You can normalize the argument with a call to to_sym (or to_s, if you want to normalize to strings) so that whatever gets passed in fits into the operations you need to perform.
Next up: symbols as hash keys. We won’t look in depth at hashes until chapter 9, but the use of symbols as hash keys is extremely widespread and worth putting on our radar now.
Symbols as hash keys
A hash is a keyed data structure: you insert values into it by assigning the value to a key, and you retrieve a value by providing a reference to a key. Ruby puts no constraints on hash keys. You can use an array, a class, another hash, a string, or any object you like as a hash key. But in most cases you’re likely to use strings or symbols.
Here’s the creation of a hash with symbols as keys, followed by the retrieval of one of the values:
>> d_hash = { :name => "David", :age => 55 }
=> {:name=>"David", :age=>55}
>> d_hash[:age]
=> 55
And here’s a similar hash with string keys:
>> d_hash = { "name" => "David", "age" => 55 }
=> {"name"=>"David", "age"=>55}
>> d_hash["name"]
=> "David"
There’s nothing terrible about using strings as hash keys, especially if you already have a collection of strings on hand and need to incorporate them into a hash. But symbols have a few advantages in the hash-key department.
First, Ruby can process symbols faster, so if you’re doing a lot of hash lookups, you’ll save a little time. You won’t notice a difference if you’re only processing small amounts of data, but if you need to tweak for efficiency, symbol hash keys are probably a good idea.
Second, symbols look good as hash keys. Looking good is, of course, not a technical characteristic, and opinion about what looks good varies widely. But symbols do have a kind of frozen, label-like look that lends itself well to cases where your hash keys are meant to be static identifiers (like :name and :age), whereas strings have a malleability that’s a good fit for the representation of arbitrary values (like someone’s name). Perhaps this is a case of projecting the technical basis of the two objects—strings being mutable, symbols not—onto the aesthetic plane. Be that as it may, Ruby programmers tend to use symbols more than strings as hash keys.
The third reason to use symbols rather than strings as hash keys, when possible, is that Ruby allows a special form of symbol representation in the hash-key position, with the colon after the symbol instead of before it and the hash separator arrow removed. In other words,
hash = { :name => "David", :age => 55 }
can also be written as
hash = { name: "David", age: 55 }
As it so often does, Ruby goes out of its way to let you write things in an uncluttered, simple way. Of course, if you prefer the version with the standard symbol notation and the hash arrows, you can still use that form.
So far, and by design, we’ve looked at symbols mainly by the light of how they differ from strings. But you’ll have noticed that strings enter the discussion regularly, no matter how much we try to separate the two. It’s worth having centered the spotlight on symbols, but now let’s widen it and look at some specific points of comparison between symbols and strings.
8.2.4. Strings and symbols in comparison
Symbols have become increasingly stringlike in successive versions of Ruby. That’s not to say that they’ve shed their salient features; they’re still immutable and unique. But they present a considerably more stringlike interface than they used to.
By way of a rough demonstration of the changes, here are two lists of methods. The first comes from Ruby 1.8.6:
>> Symbol.instance_methods(false).sort
=> ["===", "id2name", "inspect", "to_i", "to_int", "to_s", "to_sym"]
The second is from Ruby 2:
>> Symbol.instance_methods(false).sort
=> [:<=>, :==, :===, :=~, :[], :capitalize, :casecmp, :downcase, :empty?,
:encoding, :id2name, :inspect, :intern, :length, :match, :next, :size,
:slice, :succ, :swapcase, :to_proc, :to_s, :to_sym, :upcase]
Somewhere along the line, symbols have learned to do lots of new things, mostly from the string domain. But note that there are no bang versions of the various case-changing and incrementation methods. For strings, upcase! means upcase yourself in place. Symbols, on the other hand, are immutable; the symbol :a can show you the symbol :A, but it can’t be the symbol :A.
In general, the semantics of the stringlike symbol methods are the same as the string equivalents, including incrementation:

Note that indexing into a symbol returns a substring ![]() , not a symbol. From the programmer’s perspective, symbols acknowledge the fact that they’re representations of text by giving you a number of ways to manipulate their content. But it isn’t really content; :david doesn’t contain “david” any more than 100 contains “100.” It’s a matter of the interface and of a characteristically Ruby-like confluence of object theory and programming practicality.
, not a symbol. From the programmer’s perspective, symbols acknowledge the fact that they’re representations of text by giving you a number of ways to manipulate their content. But it isn’t really content; :david doesn’t contain “david” any more than 100 contains “100.” It’s a matter of the interface and of a characteristically Ruby-like confluence of object theory and programming practicality.
Underneath, symbols are more like integers than strings. (The symbol table is basically an integer-based hash.) They share with integers not only immutability and uniqueness, but also immediacy: a variable to which a symbol is bound provides the actual symbol value, not a reference to it. If you’re puzzled over exactly how symbols work, or over why both strings and symbols exist when they seem to be duplicating each other’s efforts in representing text, think of symbols as integer-like entities dressed up in characters. It sounds odd, but it explains a lot.
The integer-like qualities of symbols also provide a nice transition to the topic of numerical objects.
8.3. Numerical objects
In Ruby, numbers are objects. You can send messages to them, just as you can to any object:
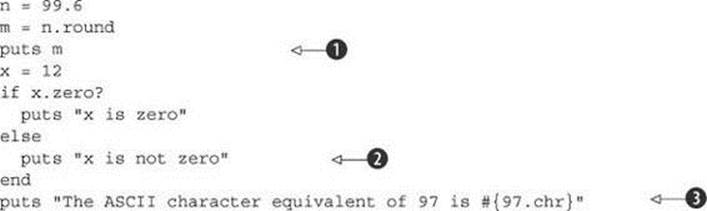
As you’ll see if you run this code, floating-point numbers know how to round themselves ![]() (up or down). Numbers in general know
(up or down). Numbers in general know ![]() whether they’re zero. And integers can convert themselves to the character that corresponds to their ASCII value
whether they’re zero. And integers can convert themselves to the character that corresponds to their ASCII value ![]() .
.
Numbers are objects; therefore, they have classes—a whole family tree of them.
8.3.1. Numerical classes
Several classes make up the numerical landscape. Figure 8.1 shows a slightly simplified view (mixed-in modules aren’t shown) of those classes, illustrating the inheritance relations among them.
Figure 8.1. Numerical class hierarchy
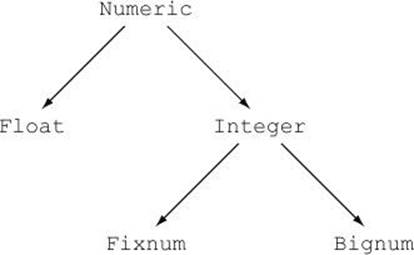
The top class in the hierarchy of numerical classes is Numeric; all the others descend from it. The first branch in the tree is between floating-point and integral numbers: the Float and Integer classes. Integers are broken into two classes: Fixnum and Bignum. Bignums, as you may surmise, are large integers. When you use or calculate an integer that’s big enough to be a Bignum rather than a Fixnum, Ruby handles the conversion automatically for you; you don’t have to worry about it.
8.3.2. Performing arithmetic operations
For the most part, numbers in Ruby behave as the rules of arithmetic and the usual conventions of arithmetic notation lead you to expect. The examples in table 8.1 should be reassuring in their boringness.
Table 8.1. Common arithmetic expressions and their evaluative results
|
Expression |
Result |
Comments |
|
1 + 1 |
2 |
Addition |
|
10/5 |
2 |
Integer division |
|
16/5 |
3 |
Integer division (no automatic floating-point conversion) |
|
10/3.3 |
3.3333333333 |
Floating-point division |
|
1.2 + 3.4 |
4.6 |
Floating-point addition |
|
-12 - -7 |
–5 |
Subtraction |
|
10 % 3 |
1 |
Modulo (remainder) |
Note that when you divide integers, the result is always an integer. If you want floating-point division, you have to feed Ruby floating-point numbers (even if all you’re doing is adding .0 to the end of an integer).
Ruby also lets you manipulate numbers in nondecimal bases. Hexadecimal integers are indicated by a leading 0x. Here are some irb evaluations of hexadecimal integer expressions:
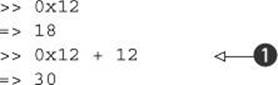
The second 12 in the last expression ![]() is a decimal 12; the 0x prefix applies only to the numbers it appears on.
is a decimal 12; the 0x prefix applies only to the numbers it appears on.
Integers beginning with 0 are interpreted as octal (base 8):
>> 012
=> 10
>> 012 + 12
=> 22
>> 012 + 0x12
=> 28
As you saw in section 8.1.6, you can also use the to_i method of strings to convert numbers in any base to decimal. To perform such a conversion, you need to supply the base you want to convert from as an argument to to_i. The string is then interpreted as an integer in that base, and the whole expression returns the decimal equivalent. You can use any base from 2 to 36, inclusive. Here are some examples:
>> "10".to_i(17)
=> 17
>> "12345".to_i(13)
=> 33519
>> "ruby".to_i(35)
=> 1194794
Keep in mind that most of the arithmetic operators you see in Ruby are methods. They don’t look that way because of the operator-like syntactic sugar that Ruby gives them. But they are methods, and they can be called as methods:
>> 1.+(1)
=> 2
>> 12./(3)
=> 4
>> -12.-(-7)
=> -5
In practice, no one writes arithmetic operations that way; you’ll always see the syntactic sugar equivalents (1 + 1 and so forth). But seeing examples of the method-call form is a good reminder of the fact that they’re methods—and also of the fact that if you define, say, a method called + in a class of your own, you can use the operator’s syntactic sugar. (And if you see arithmetic operators behaving weirdly, it may be that someone has redefined their underlying methods.)
We’ll turn now to the next and last category of scalar objects we’ll discuss in this chapter: time and date objects.
8.4. Times and dates
Ruby gives you lots of ways to manipulate times and dates. In fact, the extent and variety of the classes that represent times and/or dates, and the class and instance methods available through those classes, can be bewildering. So can the different ways in which instances of the various classes represent themselves. Want to know what the day we call April 24, 1705, would have been called in England prior to the calendar reform of 1752? Load the date package, and then ask
>> require 'date'
=> true
>> Date.parse("April 24 1705").england.strftime("%B %d %Y")
=> "April 13 1705"
On the less exotic side, you can perform a number of useful and convenient manipulations on time and date objects.
Times and dates are manipulated through three classes: Time, Date, and DateTime. (For convenience, the instances of all of these classes can be referred to collectively as date/time objects.) To reap their full benefits, you have to pull one or both of the date and time libraries into your program or irb session:
require 'date'
require 'time'
Here, the first line provides the Date and DateTime classes, and the second line enhances the Time class. (Actually, even if you don’t require 'date' you’ll be able to see the Date class. But it can’t do anything yet.) At some point in the future, all the available date- and time-related functionality may be unified into one library and made available to programs by default. But for the moment, you have to do the require operations if you want the full functionality.
In what follows, we’ll examine a large handful of date/time operations—not all of them, but most of the common ones and enough to give you a grounding for further development. Specifically, we’ll look at how to instantiate date/time objects, how to query them, and how to convert them from one form or format to another.
8.4.1. Instantiating date/time objects
How you instantiate a date/time object depends on exactly which object is involved. We’ll look at the Date, Time, and DateTime classes, in that order.
Creating date objects
You can get today’s date with the Date.today constructor:
>> Date.today
=> #<Date: 2013-11-02 ((2456599j,0s,0n),+0s,2299161j)
You can get a simpler string by running to_s on the date, or by putsing it:
>> puts Date.today
2013-11-02
You can also create date objects with Date.new (also available as Date.civil). Send along a year, month, and day:
>> puts Date.new(1959,2,1)
1959-02-01
If not provided, the month and day (or just day) default to 1. If you provide no arguments, the year defaults to –4712—probably not the most useful value.
Finally, you can create a new date with the parse constructor, which expects a string representing a date:
![]()
By default, Ruby expands the century for you if you provide a one- or two-digit number. If the number is 69 or greater, then the offset added is 1900; if it’s between 0 and 68, the offset is 2000. (This distinction has to do with the beginning of the Unix “epoch” at the start of 1970.)
>> puts Date.parse("03/6/9")
2003-06-09
>> puts Date.parse("33/6/9")
2033-06-09
>> puts Date.parse("77/6/9")
1977-06-09
Date.parse makes an effort to make sense of whatever you throw at it, and it’s pretty good at its job:
>> puts Date.parse("November 2 2013")
2013-11-02
>> puts Date.parse("Nov 2 2013")
2013-11-02
>> puts Date.parse("2 Nov 2013")
2013-11-02
>> puts Date.parse("2013/11/2")
2013-11-02
You can create Julian and commercial (Monday-based rather than Sunday-based day-of-week counting) Date objects with the methods jd and commercial, respectively. You can also scan a string against a format specification, generating a Date object, with strptime. These constructor techniques are more specialized than the others, and we won’t go into them in detail here; but if your needs are similarly specialized, the Date class can address them.
The Time class, like the Date class, has multiple constructors.
Creating time objects
You can create a time object using any of several constructors: new (a.k.a. now), at, local (a.k.a. mktime), and parse. This plethora of constructors, excessive though it may seem at first, does provide a variety of functionalities, all of them useful. Here are some examples, irb-style:

Time.new (or Time.now) creates a time object representing the current time ![]() . Time.at(seconds) gives you a time object for the number of seconds since the epoch (midnight on January 1, 1970, GMT) represented by the seconds argument
. Time.at(seconds) gives you a time object for the number of seconds since the epoch (midnight on January 1, 1970, GMT) represented by the seconds argument ![]() . Time.mktime (or Time.local) expects year, month, day, hour, minute, and second arguments. You don’t have to provide all of them; as you drop arguments off from the right, Time.mktime fills in with reasonable defaults (1 for month and day; 0 for hour, minute, and second)
. Time.mktime (or Time.local) expects year, month, day, hour, minute, and second arguments. You don’t have to provide all of them; as you drop arguments off from the right, Time.mktime fills in with reasonable defaults (1 for month and day; 0 for hour, minute, and second) ![]() .
.
To use Time.parse, you have to load the time library ![]() . Once you do, Time.parse makes as much sense as it can of the arguments you give it, much like Date.parse
. Once you do, Time.parse makes as much sense as it can of the arguments you give it, much like Date.parse ![]() .
.
Creating date/time objects
DateTime is a subclass of Date, but its constructors are a little different thanks to some overrides. The most common constructors are new (also available as civil), now, and parse:
>> puts DateTime.new(2009, 1, 2, 3, 4, 5)
2009-01-02T03:04:05+00:00
=> nil
>> puts DateTime.now
2013-11-03T04:44:52-08:00
=> nil
>> puts DateTime.parse("October 23, 1973, 10:34 AM")
1973-10-23T10:34:00+00:00
DateTime also features the specialized jd (Julian date), commercial, and strptime constructors mentioned earlier in connection with the Date class.
Let’s turn now to the various ways in which you can query date/time objects.
8.4.2. Date/time query methods
In general, the time and date objects have the query methods you’d expect them to have. Time objects can be queried as to their year, month, day, hour, minute, and second, as can date/time objects. Date objects can be queried as to their year, month, and day:
>> dt = DateTime.now
=> #<DateTime: 2014-02-21T06:33:38-05:00
((2456710j,41618s,552942000n),-18000s,2299161j)>
>> dt.year
=> 2014
>> dt.hour
=> 6
>> dt.minute
=> 33
>> dt.second
=> 38
>> t = Time.now
=> 2014-02-21 06:33:50 -0500
>> t.month
=> 2
>> t.sec
=> 50
>> d = Date.today
=> #<Date: 2014-02-21 ((2456710j,0s,0n),+0s,2299161j)>
>> d.day
=> 21
Note that date/time objects have a second method, as well as sec. Time objects have only sec.
Some convenient day-of-week methods work equally for all three classes. Through them, you can determine whether the given date/time is or isn’t a particular day of the week:
>> d.monday?
=> false
>> dt.friday?
=> true
Other available queries include Boolean ones for leap year (leap?) and daylight saving time (dst?, for time objects only).
As you’ve seen, the string representations of date/time objects differ considerably, depending on exactly what you’ve asked for and which of the three classes you’re dealing with. In practice, the default string representations aren’t used much. Instead, the objects are typically formatted using methods designed for that purpose.
8.4.3. Date/time formatting methods
All date/time objects have the strftime method, which allows you to format their fields in a flexible way using format strings, in the style of the Unix strftime(3) system library:
>> t = Time.now
=> 2014-02-21 06:37:59 -0500
>> t.strftime("%m-%d-%y")
=> "02-21-14"
In the example, the format specifiers used are %m (two-digit month), %d (two-digit day), and %Y (four-digit year). The hyphens between the fields are reproduced in the output as literal hyphens.
Some useful format specifiers for strftime are shown in table 8.2.
Table 8.2. Common time and date format specifiers
|
Specifier |
Description |
|
%Y |
Year (four digits) |
|
%y |
Year (last two digits) |
|
%b, %B |
Short month, full month |
|
%m |
Month (number) |
|
%d |
Day of month (left-padded with zeros) |
|
%e |
Day of month (left-padded with blanks) |
|
%a, %A |
Short day name, full day name |
|
%H, %I |
Hour (24-hour clock), hour (12-hour clock) |
|
%M |
Minute |
|
%S |
Second |
|
%c |
Equivalent to "%a %b %d %H:%M:%S %Y" |
|
%x |
Equivalent to "%m/%d/%y" |
Warning
The %c and %x specifiers, which involve convenience combinations of other specifiers, may differ from one locale to another; for instance, some systems put the day before the month in the %x format. This is good, because it means a particular country’s style isn’t hard-coded into these formats. But you do need to be aware of it, so you don’t count on specific behavior that you may not always get. When in doubt, you can use a format string made up of smaller specifiers.
Here are some more examples of the format specifiers in action:
>> t.strftime("Today is %x")
=> "Today is 11/03/13"
>> t.strftime("Otherwise known as %d-%b-%y")
=> "Otherwise known as 03-Nov-13"
>> t.strftime("Or even day %e of %B, %Y.")
=> "Or even day 3 of November, 2013."
>> t.strftime("The time is %H:%m.")
=> "The time is 04:11."
In addition to the facilities provided by strftime, the Date and DateTime classes give you a handful of precooked output formats for specialized cases like RFC 2822 (email) compliance and the HTTP format specified in RFC 2616:
>> Date.today.rfc2822
=> "Sun, 3 Nov 2013 00:00:00 +0000"
>> DateTime.now.httpdate
=> "Sun, 03 Nov 2013 12:49:48 GMT"
One way or another, you can get your times and dates to look the way you want them to. Date/time objects also allow for conversions of various kinds, from one class of object to another.
8.4.4. Date/time conversion methods
All of the date/time classes allow for conversion to each other; that is, Time has to_date and to_datetime methods, Date has to_time and to_datetime, and DateTime has to_time and to_date. In all cases where the target class has more information than the source class, the missing fields are set to 0—essentially, midnight, because all three classes have date information but only two have time information.
You can also move around the calendar with certain time-arithmetic methods and operators.
Date/time arithmetic
Time objects let you add and subtract seconds from them, returning a new time object:
>> t = Time.now
=> 2013-11-03 04:50:49 -0800
>> t - 20
=> 2013-11-03 04:50:29 -0800
>> t + 20
=> 2013-11-03 04:51:09 -0800
Date and date/time objects interpret + and – as day-wise operations, and they allow for month-wise conversions with << and >>:
>> dt = DateTime.now
=> #<DateTime: 2013-11-03T04:51:05-08:00 ... >
>> puts dt + 100
2014-02-11T04:51:05-08:00
>> puts dt >> 3
2014-02-03T04:51:05-08:00
>> puts dt << 10
2013-01-03T04:51:05-08:00
You can also move ahead one using the next (a.k.a. succ) method. A whole family of next_unit and prev_unit methods lets you move back and forth by day(s), month(s), or year(s):
>> d = Date.today
=> #<Date: 2013-11-03 ((2456600j,0s,0n),+0s,2299161j)>
>> puts d.next
2013-11-04
>> puts d.next_year
2014-11-03
>> puts d.next_month(3)
2014-02-03
>> puts d.prev_day(10)
2013-10-24
Furthermore, date and date/time objects allow you to iterate over a range of them, using the upto and downto methods, each of which takes a time, date, or date/time object. Here’s an upto example:
>> d = Date.today
=> #<Date: 2013-11-03 ((2456600j,0s,0n),+0s,2299161j)>
>> next_week = d + 7
=> #<Date: 2013-11-10 ((2456607j,0s,0n),+0s,2299161j)>
>> d.upto(next_week) {|date| puts "#{date} is a #{date.strftime("%A")}" }
2013-11-03 is a Sunday
2013-11-04 is a Monday
2013-11-05 is a Tuesday
2013-11-06 is a Wednesday
2013-11-07 is a Thursday
2013-11-08 is a Friday
2013-11-09 is a Saturday
2013-11-10 is a Sunday
The date/time classes offer much more than what you’ve seen here. But the features we’ve covered are the most common and, in all likelihood, most useful. Don’t forget that you can always use the command-line tool ri to get information about methods! If you try ri Date, for example, you’ll get information about the class as well as a list of available class and instance methods—any of which you can run ri on separately.
We’ve reached the end of our survey of scalar objects in Ruby. Next, in chapter 9, we’ll look at collections and container objects.
8.5. Summary
In this chapter you’ve seen
· String creation and manipulation
· The workings of symbols
· Numerical objects, including floats and integers
· Date, time, and date/time objects and how to query and manipulate them
In short, we’ve covered the basics of the most common and important scalar objects in Ruby. Some of these topics involved consolidating points made earlier in the book; others were new in this chapter. At each point, we’ve examined a selection of important, common methods. We’ve also looked at how some of the scalar-object classes relate to each other. Strings and symbols both represent text, and although they’re different kinds of objects, conversions from one to the other are easy and common. Numbers and strings interact, too. Conversions aren’t automatic, as they are (for example) in Perl; but Ruby supplies conversion methods to go from string to numerical object and back, as well as ways to convert strings to integers in as many bases as 10 digits and the 26 letters of the English alphabet can accommodate.
Time and date objects have a foot in both the string and numerical camps. You can perform calculations on them, such as adding n months to a given date, and you can also put them through their paces as strings, using techniques like the Time#strftime method in conjunction with output format specifiers.
The world of scalar objects in Ruby is rich and dynamic. Most of what you do with both Ruby and Rails will spring from what you’ve learned here about scalar objects: direct manipulation of these objects, manipulation of objects that share some of their traits (for example, CGI parameters whose contents are strings), or collections of multiple objects in these categories. Scalar objects aren’t everything, but they lie at the root of virtually everything else. The tour we’ve taken of important scalar classes and methods in this chapter will stand you in good stead as we proceed next to look at collections and containers—the two- (and sometimes more) dimensional citizens of Ruby’s object world.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.