The Well-Grounded Rubyist, Second Edition (2014)
Part 2. Built-in classes and modules
In part 2, we come to the heart of the Ruby language: built-in classes and modules.
A great deal of what you’ll do as a Rubyist will involve Ruby’s built-ins. You’ve already seen examples involving many of them: strings, arrays, files, and so forth. Ruby provides you with a rich toolset of out-of-the-box built-in data types that you can use and on which you can build.
That’s the thing: when you design your own classes and modules, you’ll often find that what you need is something similar to an existing Ruby class. If you’re writing a DeckOfCards class, for example, one of your first thoughts will probably be that a deck of cards is a lot like an array. Then you’d want to think about whether your cards class should be a subclass of Array—or perhaps each deck object could store an array in an instance variable and put the cards there—and so forth. The point is that Ruby’s built-in classes provide you with starting points for your own class and object designs as well as with a set of classes extremely useful in their own right.
We’ll start part 2 with a look at built-in essentials (chapter 7). The purpose of this chapter is to provide you with an array (so to speak!) of techniques and tools that you’ll find useful across the board in the chapters that follow. To study strings, arrays, and hashes, for example, it’s useful to know how Ruby handles the concepts of true and false—concepts that aren’t pegged to any single built-in class but that you need to understand generally.
Following the essentials, we’ll turn to specific classes, but grouped into higher-level categories: scalar objects first (chapter 8) and then collections (chapter 9). Scalars are atomic objects, like strings, numbers, and symbols. Each scalar object represents one value; scalars don’t contain other objects. (Strings contain characters, of course; but there’s no separate character class in Ruby, so strings are still scalar.) Collection objects contain other objects; the major collection classes in Ruby are arrays and hashes. The collection survey will also include ranges, which are hybrid objects that can (but don’t always) serve to represent collections of objects. Finally, we’ll look at sets, which are implemented in the standard library (rather than the Ruby core) but which merit an exception to the general rule that our focus is on the core itself.
Equal in importance to the specific collection classes are the facilities that all collections in Ruby share: facilities embodied in the Enumerable module. Enumerable endows collection objects with the knowledge of how to traverse and transform themselves in a great number of ways. Chapter 10 will be devoted to the Enumerable module and its ramifications for Ruby programming power.
Part 2 continues in chapter 11 with a look at regular expressions—a string-related topic that, nonetheless, deserves some space of its own—and concludes in chapter 12 with an exploration of file and I/O operations: reading from and writing to files and I/O streams, and related subtopics like error handling and file-status queries. Not surprisingly, Ruby treats all of these things, including regular expressions and I/O streams, as objects.
By the end of part 2, you’ll have a rich working knowledge of Ruby’s core classes, and your own Ruby horizons will have expanded dramatically.
Chapter 7. Built-in essentials
This chapter covers
· Literal object constructors
· Syntactic sugar
· “Dangerous” and/or destructive methods
· The to_* family of conversion methods
· Boolean states and objects, and nil
· Object-comparison techniques
· Runtime inspection of objects’ capabilities
The later chapters in this part of the book will cover specific built-in classes: what they are, what you can do with them, and what methods their instances have. This chapter will discuss a selection of topics that cut across a number of built-in classes.
It’s more than that, though: it’s also a kind of next-generation Ruby literacy guide, a deeper and wider version of chapter 1. Like chapter 1, this chapter has two goals: making it possible to take a certain amount of material for granted in later chapters, where it will arise in various places to varying degrees; and presenting you with information about Ruby that’s important and usable in its own right. Throughout this chapter, you’ll explore the richness that lies in every Ruby object, as well as some of the syntactic and semantic subsystems that make the language so interesting and versatile.
The chapter moves through a number of topics, so it’s probably worth having a look in advance at what you’re going to see. Here’s a lightly annotated summary:
· Literal constructors —Ways to create certain objects with syntax, rather than with a call to new
· Syntactic sugar —Things Ruby lets you do to make your code look nicer
· “Dangerous” and/or destructive methods —Methods that alter their receivers permanently, and other “danger” considerations
· The to_* family of conversion methods —Methods that produce a conversion from an object to an object of a different class, and the syntactic features that hook into those methods
· Boolean states and objects, and nil —A close look at true and false and related concepts in Ruby
· Object-comparison techniques —Ruby-wide techniques, both default and customizable, for object-to-object comparison
· Runtime inspection of objects’ capabilities —An important set of techniques for runtime reflection on the capabilities of an object
You’ll find all these topics useful as you read and/or write Ruby code in working through this book and beyond.
You may want to fire up an irb session for this chapter; it makes frequent use of the irb session format for the code examples, and you can often try the examples with small variations to get a feel for how Ruby behaves.
7.1. Ruby’s literal constructors
Ruby has a lot of built-in classes. Most of them can be instantiated using new:
str = String.new
arr = Array.new
Some can’t; for example, you can’t create a new instance of the class Integer. But for the most part, you can create new instances of the built-in classes.
In addition, a lucky, select few built-in classes enjoy the privilege of having literal constructors. That means you can use special notation, instead of a call to new, to create a new object of that class.
The classes with literal constructors are shown in table 7.1. When you use one of these literal constructors, you bring a new object into existence. (Although it’s not obvious from the table, it’s worth noting that there’s no new constructor for Symbol objects. The only way to generate a Symbolobject is with the literal constructor.)
Table 7.1. Built-in Ruby classes with literal constructors
|
Class |
Literal constructor |
Example(s) |
|
String |
Quotation marks |
"new string" |
|
Symbol |
Leading colon |
:symbol |
|
Array |
Square brackets |
[1,2,3,4,5] |
|
Hash |
Curly braces |
{"New York" => "NY", "Oregon" => "OR"} |
|
Range |
Two or three dots |
0..9 or 0...10 |
|
Regexp |
Forward slashes |
/([a-z]+)/ |
|
Proc (lambda) |
Dash, arrow, parentheses, braces |
->(x,y) { x * y } |
We’ll look in considerable detail at a great deal of functionality in all these classes. Meanwhile, begin getting used to the notation so you can recognize these data types on sight. Literal constructors are never the only way to instantiate an object of a given class, but they’re very commonly used.
We’ll look next at some of the syntactic sugar that Ruby makes available to you across the spectrum of objects.
Literal constructor characters with more than one meaning
Some of the notation used for literal constructors has more than one meaning in Ruby. Many objects have a method called [] that looks like a literal array constructor but isn’t. Code blocks, as you’ve seen, can be delimited with curly braces—but they’re still code blocks, not hash literals. This kind of overloading of notation is a consequence of the finite number of symbols on the keyboard. You can always tell what the notation means by its context, and there are few enough contexts that, with a little practice, it will be easy to differentiate.
7.2. Recurrent syntactic sugar
As you know, Ruby sometimes lets you use sugary notation in place of the usual object.method(args) method-calling syntax. This lets you do nice-looking things, such as using a plus sign between two numbers, like an operator
x = 1 + 2
instead of the odd-looking method-style equivalent:
x = 1.+(2)
As you delve more deeply into Ruby and its built-in methods, be aware that certain methods always get this treatment. The consequence is that you can define how your objects behave in code like this
my_object + my_other_object
simply by defining the + method. You’ve seen this process at work, particularly in connection with case equality and defining the === method. But now let’s look more extensively at this elegant technique.
7.2.1. Defining operators by defining methods
If you define a + method for your class, then objects of your class can use the sugared syntax for addition. Moreover, there’s no such thing as defining the meaning of that syntax separately from defining the method. The operator is the method. It just looks nicer as an operator.
Remember, too, that the semantics of methods like + are entirely based on convention. Ruby doesn’t know that + means addition. Nothing (other than good judgment) stops you from writing completely nonaddition-like + methods:

The plus sign in the puts statement is a call to the + method of obj, with the integer 100 as the single (ignored) argument.
Layered on top of the operator-style sugar is the shortcut sugar: x +=1 for x = x + 1. Once again, you automatically reap the sugar harvest if you define the relevant method(s). Here’s an example—a bank account class with + and – methods:

By defining the – instance method ![]() , we gain the -= shortcut, and can subtract from the account using that notation
, we gain the -= shortcut, and can subtract from the account using that notation ![]() . This is a simple but instructive example of the fact that Ruby encourages you to take advantage of the very same “wiring” that the language itself uses, so as to integrate your programs as smoothly as possible into the underlying technology.
. This is a simple but instructive example of the fact that Ruby encourages you to take advantage of the very same “wiring” that the language itself uses, so as to integrate your programs as smoothly as possible into the underlying technology.
The automatically sugared methods are collected in table 7.2.
Table 7.2. Methods with operator-style syntactic sugar–calling notation
|
Category |
Name |
Definition example |
Calling example |
Sugared notation |
|
Arithmetic method/operators |
+ |
def +(x) |
obj.+(x) |
obj + x |
|
- |
def -(x) |
obj.-(x) |
obj - x |
|
|
* |
def *(x) |
obj.*(x) |
obj * x |
|
|
/ |
def /(x) |
obj./(x) |
obj / x |
|
|
% (modulo) |
def %(x) |
obj.%(x) |
obj % x |
|
|
** (exponent) |
def **(x) |
obj.**(x) |
obj ** x |
|
|
Get/set/append data |
[] |
def [](x) |
obj.[](x) |
obj[x] |
|
[]= |
def []=(x,y) |
obj.[]=(x,y) |
obj[x] = y |
|
|
<< |
def <<(x) |
obj.<<(x) |
obj << x |
|
|
Comparison method/operators |
<=> |
def <=>(x) |
obj.<=>(x) |
obj <=> x |
|
== |
def ==(x) |
obj.==(x) |
obj == x |
|
|
> |
def >(x) |
obj.>(x) |
obj > x |
|
|
< |
def <(x) |
obj.<(x) |
obj < x |
|
|
>= |
def >=(x) |
obj.>=(x) |
obj >= x |
|
|
<= |
def <=(x) |
obj.<=(x) |
obj <= x |
|
|
Case equality operator |
=== |
def ===(x) |
obj.===(x) |
obj === x |
|
Bitwise operators |
| (OR) |
def |(x) |
obj.|(x) |
obj | x |
|
& (AND) |
def &(x) |
obj.&(x) |
obj & x |
|
|
^ (XOR) |
def ^(x) |
obj.^(x) |
obj ^ x |
Remembering which methods get the sugar treatment isn’t difficult. They fall into several distinct categories, as table 7.2 shows. These categories are for convenience of learning and reference only; Ruby doesn’t categorize the methods, and the responsibility for implementing meaningful semantics lies with you. The category names indicate how these method names are used in Ruby’s built-in classes and how they’re most often used, by convention, when programmers implement them in new classes.
(Don’t forget, too, the conditional assignment operator ||=, as well as its rarely spotted cousin &&=, both of which provide the same kind of shortcut as the pseudo-operator methods but are based on operators, namely || and &&, that you can’t override.)
The extensive use of this kind of syntactic sugar—where something looks like an operator but is a method call—tells you a lot about the philosophy behind Ruby as a programming language. The fact that you can define and even redefine elements like the plus sign, minus sign, and square brackets means that Ruby has a great deal of flexibility. But there are limits to what you can redefine in Ruby. You can’t redefine any of the literal object constructors: {} is always a hash literal (or a code block, if it appears in that context), "" will always delimit a string, and so forth.
But there’s plenty that you can do. You can even define some unary operators via method definitions.
7.2.2. Customizing unary operators
The unary operators + and - occur most frequently as signs for numbers, as in -1. But they can be defined; you can specify the behavior of the expressions +obj and -obj for your own objects and classes. You do so by defining the methods +@ and -@.
Let’s say that you want + and - to mean uppercase and lowercase for a stringlike object. Here’s how you define the appropriate unary operator behavior, using a Banner class as an example:

Now create a banner, and manipulate its case using the unary + and - operators:

The basic string output for the banner text, unchanged, is provided by the to_s conversion method ![]() , which you’ll see up close in section 7.4.1.
, which you’ll see up close in section 7.4.1.
You can also define the ! (logical not) operator, by defining the ! method. In fact, defining the ! method gives you both the unary ! and the keyword not. Let’s add a definition to Banner:
class Banner
def !
reverse
end
end
Now examine the banner, “negated.” We’ll need to use parentheses around the not version to clarify the precedence of expressions (otherwise puts thinks we’re trying to print not):

As it so often does, Ruby gives you an object-oriented, method-based way to customize what you might at first think are hardwired syntactic features—even unary operators like !.
Unary negation isn’t the only use Ruby makes of the exclamation point.
7.3. Bang (!) methods and “danger”
Ruby methods can end with an exclamation point (!), or bang. The bang has no significance to Ruby internally; bang methods are called and executed just like any other methods. But by convention, the bang labels a method as “dangerous”—specifically, as the dangerous equivalent of a method with the same name but without the bang.
Dangerous can mean whatever the person writing the method wants it to mean. In the case of the built-in classes, it usually means this method, unlike its nonbang equivalent, permanently modifies its receiver. It doesn’t always, though: exit! is a dangerous alternative to exit, in the sense that it doesn’t run any finalizers on the way out of the program. The danger in sub! (a method that substitutes a replacement string for a matched pattern in a string) is partly that it changes its receiver and partly that it returns nil if no change has taken place—unlike sub, which always returns a copy of the original string with the replacement (or no replacement) made.
If “danger” is too melodramatic for you, you can think of the ! in method names as a kind of “Heads up!” And, with very few, very specialized exceptions, every bang method should occur in a pair with a nonbang equivalent. We’ll return to questions of best method-naming practice after we’ve looked at some bang methods in action.
7.3.1. Destructive (receiver-changing) effects as danger
No doubt most of the bang methods you’ll come across in the core Ruby language have the bang on them because they’re destructive: they change the object on which they’re called. Calling upcase on a string gives you a new string consisting of the original string in uppercase; but upcase!turns the original string into its own uppercase equivalent, in place:
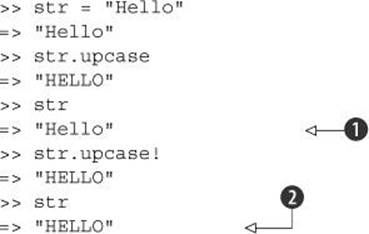
Examining the original string after converting it to uppercase shows that the uppercase version was a copy; the original string is unchanged ![]() . But the bang operation has changed the content of str itself
. But the bang operation has changed the content of str itself ![]() .
.
Ruby’s core classes are full of destructive (receiver-changing) bang methods paired with their nondestructive counterparts: sort/sort! for arrays, strip/strip! (strip leading and trailing whitespace) for strings, reverse/reverse! for strings and arrays, and many more. In each case, if you call the nonbang version of the method on the object, you get a new object. If you call the bang version, you operate in-place on the same object to which you sent the message.
You should always be aware of whether the method you’re calling changes its receiver. Neither option is always right or wrong; which is best depends on what you’re doing. One consideration, weighing in on the side of modifying objects instead of creating new ones, is efficiency: creating new objects (like a second string that’s identical to the first except for one letter) is expensive in terms of memory and processing. This doesn’t matter if you’re dealing with a small number of objects. But when you get into, say, handling data from large files and using loops and iterators to do so, creating new objects can be a drain on resources.
On the other hand, you need to be cautious about modifying objects in place, because other parts of the program may depend on those objects not to change. For example, let’s say you have a database of names. You read the names out of the database into an array. At some point, you need to process the names for printed output—all in capital letters. You may do something like this:
names.each do |name|
capped = name.upcase
# ...code that does something with capped...
end
In this example, capped is a new object—an uppercase duplicate of name. When you go through the same array later, in a situation where you do not want the names in uppercase, such as saving them back to the database, the names will be the way they were originally.
By creating a new string (capped) to represent the uppercase version of each name, you avoid the side effect of changing the names permanently. The operation you perform on the names achieves its goals without changing the basic state of the data. Sometimes you’ll want to change an object permanently, and sometimes you won’t want to. There’s nothing wrong with that, as long as you know which you’re doing and why.
Furthermore, don’t assume a direct correlation between bang methods and destructive methods. They often coincide, but they’re not the same thing.
7.3.2. Destructiveness and “danger” vary independently
What follows here is some commentary on conventions and best practices. Ruby doesn’t care; Ruby is happy to execute methods whose names end in ! whether they’re dangerous, safe, paired with a nonbang method, not paired—whatever. The value of the ! notation as a token of communication between a method author and a user of that method resides entirely in conventions. It’s worth gaining a solid understanding of those conventions and why they make sense.
The best advice on when to use bang-terminated method names is...
Don’t use ! except in m/m! method pairs
The ! notation for a method name should only be used when there’s a method of the same name without the !, when the relation between those two methods is that they both do substantially the same thing, and when the bang version also has side effects, a different return value, or some other behavior that diverges from its nonbang counterpart.
Don’t use the ! just because you think your method is dangerous in some vague, abstract way. All methods do something; that in itself isn’t dangerous. The ! is a warning that there may be more going on than the name suggests—and that, in turn, makes sense only if the name is in use for a method that doesn’t have the dangerous behavior.
Don’t name a method save! just because it writes to a file. Call that method save, and then, if you have another method that writes to a file but (say) doesn’t back up the original file (assuming that save does so), go ahead and call that one save!.
If you find yourself writing one method to write to the file, and you put a ! at the end because you’re worried the method is too powerful or too unsafe, you should reconsider your method naming. Any experienced Rubyist who sees a save! method documented is going to want to know how it differs from save. The exclamation point doesn’t mean anything in isolation; it only makes sense at the end of one of a pair of otherwise identical method names.
Don’t equate ! notation with destructive behavior, or vice versa
Danger in the bang sense usually means object-changing or “destructive” behavior. It’s therefore not uncommon to hear people assert that the ! means destructive. From there, it’s not much of a leap to start wondering why some destructive methods’ names don’t end with !.
This line of thinking is problematic from the start. The bang doesn’t mean destructive; it means dangerous, possibly unexpected behavior. If you have a method called upcase and you want to write a destructive version of it, you’re free to call it destructive_upcase; no rule says you have to add a ! to the original name. It’s just a convention, but it’s an expressive one.
Destructive methods do not always end with !, nor would that make sense. Many nonbang methods have names that lead you to expect the receiver to change. These methods have no nondestructive counterparts. (What would it mean to have a nondestructive version of String#clear, which removes all characters from a string and leaves it equal to ""? If you’re not changing the string in place, why wouldn’t you just write "" in the first place?) If a method name without a bang already suggests in-place modification or any other kind of “dangerous behavior,” then it’s not a dangerous method.
You’ll almost certainly find that the conventional usage of the ! notation is the most elegant and logical usage. It’s best not to slap bangs on names unless you’re playing along with those conventions.
Leaving danger behind us, we’ll look next at the facilities Ruby provides for converting one object to another.
7.4. Built-in and custom to_* (conversion) methods
Ruby offers a number of built-in methods whose names consist of to_ plus an indicator of a class to which the method converts an object: to_s (to string), to_sym (to symbol), to_a (to array), to_i (to integer), and to_f (to float). Not all objects respond to all of these methods. But many objects respond to a lot of them, and the principle is consistent enough to warrant looking at them collectively.
7.4.1. String conversion: to_s
The most commonly used to_ method is probably to_s. Every Ruby object—except instances of BasicObject—responds to to_s, and thus has a way of displaying itself as a string. What to_s does, as the following irb excerpts show, ranges from nothing more than return its own receiver, when the object is already a string
>> "I am already a string!".to_s
=> "I am already a string!"
to returning a string containing a codelike representation of an object
>> ["one", "two", "three", 4, 5, 6].to_s
=> "[\"one\", \"two\", \"three\", 4, 5, 6]"
(where the backslash-escaped quotation marks mean there’s a literal quotation mark inside the string) to returning an informative, if cryptic, descriptive string about an object:
>> Object.new.to_s
=> "#<Object:0x000001030389b0>"
The salient point about to_s is that it’s used by certain methods and in certain syntactic contexts to provide a canonical string representation of an object. The puts method, for example, calls to_s on its arguments. If you write your own to_s for a class or override it on an object, your to_swill surface when you give your object to puts. You can see this clearly, if a bit nonsensically, using a generic object:
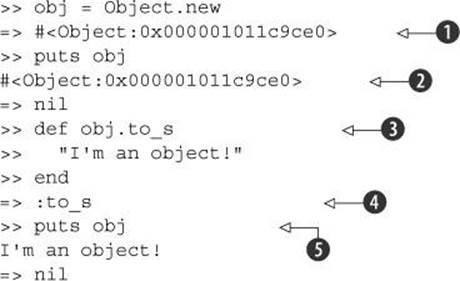
The object’s default string representation is the usual class and memory-location screen dump ![]() . When you call puts on the object, that’s what you see
. When you call puts on the object, that’s what you see ![]() . But if you define a custom to_s method on the object
. But if you define a custom to_s method on the object ![]() , subsequent calls to puts reflect the new definition
, subsequent calls to puts reflect the new definition ![]() . (Note that the method definition itself evaluates to a symbol, :to_s, representing the name of the method
. (Note that the method definition itself evaluates to a symbol, :to_s, representing the name of the method ![]() .)
.)
You also get the output of to_s when you use an object in string interpolation:
>> "My object says: #{obj}"
=> "My object says: I'm an object!"
Don’t forget, too, that you can call to_s explicitly. You don’t have to wait for Ruby to go looking for it. But a large percentage of calls to to_s are automatic, behind-the-scenes calls on behalf of puts or the interpolation mechanism.
Note
When it comes to generating string representations of their instances, arrays do things a little differently from the norm. If you call puts on an array, you get a cyclical representation based on calling to_s on each of the elements in the array and outputting one per line. That’s a special behavior; it doesn’t correspond to what you get when you call to_s on an array—namely, a string representation of the array in square brackets.
While we’re looking at string representations of objects, let’s examine a few related methods. We’re drifting a bit from the to_* category, perhaps, but these are all methods that generate strings from objects, and a consideration of them is therefore timely.
Born to be overridden: inspect
Every Ruby object—once again, with the exception of instances of BasicObject—has an inspect method. By default—unless a given class overrides inspect—the inspect string is a mini-screen-dump of the object’s memory location:
>> Object.new.inspect
=> "#<Object:0x007fe24a292b68>"
Actually, irb uses inspect on every value it prints out, so you can see the inspect strings of various objects without even explicitly calling inspect:
>> Object.new
=> #<Object:0x007f91c2a8d1e8>
>> "abc"
=> "abc"
>> [1,2,3]
=> [1, 2, 3]
>> /a regular expression/
=> /a regular expression/
If you want a useful inspect string for your classes, you need to define inspect explicitly:
class Person
def initialize(name)
@name = name
end
def inspect
@name
end
end
david = Person.new("David")
puts david.inspect # Output: David
(Note that overriding to_s and overriding inspect are two different things. Prior to Ruby 2, inspect piggybacked on to_s, so you could override both by overriding one. That’s no longer the case.)
Another, less frequently used, method generates and displays a string representation of an object: display.
Using display
You won’t see display much. It occurs only once, at last count, in all the Ruby program files in the entire standard library. (inspect occurs 160 times.) It’s a specialized output method.
display takes an argument: a writable output stream, in the form of a Ruby I/O object. By default, it uses STDOUT, the standard output stream:
>> "Hello".display
Hello=> nil
Note that display, unlike puts but like print, doesn’t automatically insert a newline character. That’s why => nil is run together on one line with the output.
You can redirect the output of display by providing, for example, an open file handle as an argument:

The string "Hello" is “displayed” directly to the file ![]() , as we confirm by reading the contents of the file in and printing them out
, as we confirm by reading the contents of the file in and printing them out ![]() .
.
Let’s leave string territory at this point and look at how conversion techniques play out in the case of the Array class.
7.4.2. Array conversion with to_a and the * operator
The to_a (to array) method, if defined, provides an array-like representation of objects. One of to_a’s most striking features is that it automatically ties in with the * operator. The * operator (pronounced “star,” “unarray,” or, among the whimsically inclined, “splat”) does a kind of unwrapping of its operand into its components, those components being the elements of its array representation.
You’ve already seen the star operator used in method parameter lists, where it denotes a parameter that sponges up the optional arguments into an array. In the more general case, the star turns any array, or any object that responds to to_a, into the equivalent of a bare list.
The term bare list means several identifiers or literal objects separated by commas. Bare lists are valid syntax only in certain contexts. For example, you can put a bare list inside the literal array constructor brackets:
[1,2,3,4,5]
It’s a subtle distinction, but the notation lying between the brackets isn’t an array; it’s a list, and the array is constructed from the list, thanks to the brackets.
The star has a kind of bracket-removing or unarraying effect. What starts as an array becomes a list. You can see this if you construct an array from a starred array:
>> array = [1,2,3,4,5]
=> [1, 2, 3, 4, 5]
>> [*array]
=> [1, 2, 3, 4, 5]
The array in array has been demoted, so to speak, from an array to a bare list, courtesy of the star. Compare this with what happens if you don’t use the star:
>> [array]
=> [[1, 2, 3, 4, 5]]
Here, the list from which the new array gets constructed contains one item: the object array. That object hasn’t been mined for its inner elements, as it was in the example with the star.
One implication is that you can use the star in front of a method argument to turn it from an array into a list. You do this in cases where you have objects in an array that you need to send to a method that’s expecting a broken-out list of arguments:

If you don’t use the unarraying star, you’ll send just one argument—an array—to the method, and the method won’t be happy.
Let’s turn to numbers.
7.4.3. Numerical conversion with to_i and to_f
Unlike some programming languages, such as Perl, Ruby doesn’t automatically convert from strings to numbers or numbers to strings. You can’t do this
![]()
because Ruby doesn’t know how to add a string and an integer together. And you’ll get a surprise if you do this:
print "Enter a number: "
n = gets.chomp
puts n * 100
You’ll see the string version of the number printed out 100 times. (This result also tells you that Ruby lets you multiply a string—but it’s always treated as a string, even if it consists of digits.) If you want the number, you have to turn it into a number explicitly:
n = gets.to_i
As you’ll see if you experiment with converting strings to integers (which you can do easily in irb with expressions like "hello".to_i), the to_i conversion value of strings that have no reasonable integer equivalent (including "Hello") is always 0. If your string starts with digits but isn’t made up entirely of digits ("123hello"), the nondigit parts are ignored and the conversion is performed only on the leading digits.
The to_f (to float) conversion gives you, predictably, a floating-point equivalent of any integer. The rules pertaining to nonconforming characters are similar to those governing string-to-integer conversions: "hello".to_f is 0.0, whereas "1.23hello".to_f is 1.23. If you call to_f on a float, you get the same float back. Similarly, calling to_i on an integer returns that integer.
If the conversion rules for strings seem a little lax to you—if you don’t want strings like "-5xyz" to succeed in converting themselves to integers or floats—you have a couple of stricter conversion techniques available to you.
Stricter conversions with Integer and Float
Ruby provides methods called Integer and Float (and yes, they look like constants, but they’re methods with names that coincide with those of the classes to which they convert). These methods are similar to to_i and to_f, respectively, but a little stricter: if you feed them anything that doesn’t conform to the conversion target type, they raise an exception:
>> "123abc".to_i
=> 123
>> Integer("123abc")
ArgumentError: invalid value for Integer(): "123abc"
>> Float("3")
=> 3.0
>> Float("-3")
=> -3.0
>> Float("-3xyz")
ArgumentError: invalid value for Float(): "-3xyz"
(Note that converting from an integer to a float is acceptable. It’s the letters that cause the problem.)
If you want to be strict about what gets converted and what gets rejected, Integer and Float can help you out.
Conversion vs. typecasting
When you call methods like to_s, to_i, and to_f, the result is a new object (or the receiver, if you’re converting it to its own class). It’s not quite the same as typecasting in C and other languages. You’re not using the object as a string or an integer; you’re asking the object to provide a second object that corresponds to its idea of itself (so to speak) in one of those forms.
The distinction between conversion and typecasting touches on some important aspects of the heart of Ruby. In a sense, all objects are typecasting themselves constantly. Every time you call a method on an object, you’re asking the object to behave as a particular type. Correspondingly, an object’s “type” is really the aggregate of everything it can do at a particular time.
The closest Ruby gets to traditional typecasting (and it isn’t very close) is the role-playing conversion methods, described in section 7.4.4.
Getting back to the to_* family of converters: in addition to the straightforward object-conversion methods, Ruby gives you a couple of to_* methods that have a little extra intelligence about what their value is expected to do.
7.4.4. Role-playing to_* methods
It’s somewhat against the grain in Ruby programming to worry much about what class an object belongs to. All that matters is what the object can do—what methods it can execute.
But in a few cases involving the core classes, strict attention is paid to the class of objects. Don’t think of this as a blueprint for “the Ruby way” of thinking about objects. It’s more like an expediency that bootstraps you into the world of the core objects in such a way that once you get going, you can devote less thought to your objects’ class memberships.
String role-playing with to_str
If you want to print an object, you can define a to_s method for it or use whatever to_s behavior it’s been endowed with by its class. But what if you need an object to be a string?
The answer is that you define a to_str method for the object. An object’s to_str representation enters the picture when you call a core method that requires that its argument be a string.
The classic example is string addition. Ruby lets you add two strings together, producing a third string:
>> "Hello " + "there."
=> "Hello there."
If you try to add a nonstring to a string, you get an error:
>> "Hello " + 10
TypeError: no implicit conversion of Float into String
This is where to_str comes in. If an object responds to to_str, its to_str representation will be used when the object is used as the argument to String#+.
Here’s an example involving a simple Person class. The to_str method is a wrapper around the name method:
class Person
attr_accessor :name
def to_str
name
end
end
If you create a Person object and add it to a string, to_str kicks in with the name string:

The to_str conversion is also used on arguments to the << (append to string) method. And arrays, like strings, have a role-playing conversion method.
Array role-playing with to_ary
Objects can masquerade as arrays if they have a to_ary method. If such a method is present, it’s called on the object in cases where an array, and only an array, will do—for example, in an array-concatenation operation.
Here’s another Person implementation, where the array role is played by an array containing three person attributes:
class Person
attr_accessor :name, :age, :email
def to_ary
[name, age, email]
end
end
Concatenating a Person object to an array has the effect of adding the name, age, and email values to the target array:

Like to_str, to_ary provides a way for an object to step into the role of an object of a particular core class. As is usual in Ruby, sensible usage of conventions is left up to you. It’s possible to write a to_ary method, for example, that does something other than return an array—but you’ll almost certainly get an error message when you try to use it, as Ruby looks to to_ary for an array. So if you’re going to use the role-playing to_* methods, be sure to play in Ruby’s ballpark.
We’ll turn now to the subject of Boolean states and objects in Ruby, a topic we’ve dipped into already, but one that merits closer inquiry.
7.5. Boolean states, Boolean objects, and nil
Every expression in Ruby evaluates to an object, and every object has a Boolean value of either true or false. Furthermore, true and false are objects. This idea isn’t as convoluted as it sounds. If true and false weren’t objects, then a pure Boolean expression like
100 > 80
would have no object to evaluate to. (And > is a method and therefore has to return an object.)
In many cases where you want to get at a truth/falsehood value, such as an if statement or a comparison between two numbers, you don’t have to manipulate these special objects directly. In such situations, you can think of truth and falsehood as states, rather than objects.
We’ll look at true and false both as states and as special objects, along with the special object nil.
7.5.1. True and false as states
Every expression in Ruby is either true or false, in a logical or Boolean sense. The best way to get a handle on this is to think in terms of conditional statements. For every expression e in Ruby, you can do this
if e
and Ruby can make sense of it.
For lots of expressions, a conditional test is a stretch; but it can be instructive to try it on a variety of expressions, as the following listing shows.
Listing 7.1. Testing the Boolean value of expressions using if constructs

Here’s the output from this listing (minus a warning about using a string literal in a conditional):
Empty class definition is false!
Class definition with the number 1 in it is true!
Method definition is true!
Strings appear to be true!
100 is greater than 50!
As you can see, empty class definitions ![]() are false; nonempty class definitions evaluate to the same value as the last value they contain
are false; nonempty class definitions evaluate to the same value as the last value they contain ![]() (in this example, the number 1); method definitions are true
(in this example, the number 1); method definitions are true ![]() (even if a call to the method would return false); strings are true
(even if a call to the method would return false); strings are true ![]() (don’t worry about the string literal in condition warning); and 100 is greater than 50
(don’t worry about the string literal in condition warning); and 100 is greater than 50 ![]() . You can use this simple if technique to explore the Boolean value of any Ruby expression.
. You can use this simple if technique to explore the Boolean value of any Ruby expression.
The if examples show that every expression in Ruby is either true or false in the sense of either passing or not passing an if test. But these examples don’t show what the expressions evaluate to. That’s what the if test is testing: it evaluates an expression (such as class MyClass; end) and proceeds on the basis of whether the value produced by that evaluation is true.
To see what values are returned by the expressions whose truth value we’ve been testing, you can derive those values in irb:

The empty class definition ![]() evaluates to nil, which is a special object (discussed in section 7.5.3). All you need to know for the moment about nil is that it has a Boolean value of false (as you can detect from the behavior of the if clauses that dealt with it in listing 7.1).
evaluates to nil, which is a special object (discussed in section 7.5.3). All you need to know for the moment about nil is that it has a Boolean value of false (as you can detect from the behavior of the if clauses that dealt with it in listing 7.1).
The class definition with the number 1 in it ![]() evaluates to the number 1, because every class-definition block evaluates to the last expression contained inside it, or nil if the block is empty.
evaluates to the number 1, because every class-definition block evaluates to the last expression contained inside it, or nil if the block is empty.
The method definition evaluates to the symbol :m ![]() , representing the name of the method that’s just been defined.
, representing the name of the method that’s just been defined.
The string literal ![]() evaluates to itself; it’s a literal object and doesn’t have to be calculated or processed into some other form when evaluated. Its value as an expression is itself.
evaluates to itself; it’s a literal object and doesn’t have to be calculated or processed into some other form when evaluated. Its value as an expression is itself.
Finally, the comparison expression 100 > 50 ![]() evaluates to true—not just to something that has the Boolean value true, but to the object true. The object true does have the Boolean value true. But along with false, it has a special role to play in the realm of truth and falsehood and how they’re represented in Ruby.
evaluates to true—not just to something that has the Boolean value true, but to the object true. The object true does have the Boolean value true. But along with false, it has a special role to play in the realm of truth and falsehood and how they’re represented in Ruby.
7.5.2. true and false as objects
The Boolean objects true and false are special objects, each being the only instance of a class especially created for it: TrueClass and FalseClass, respectively. You can ask true and false to tell you their classes’ names, and they will:

The terms true and false are keywords. You can’t use them as variable or method names; they’re reserved for Ruby’s exclusive use.
You can pass the objects true and false around, assign them to variables, and examine them like any other object. Here’s an irb session that puts true through its paces in its capacity as a Ruby object:
>> a = true
=> true
>> a = 1 unless a
=> nil
>> a
=> true
>> b = a
=> true
You’ll sometimes see true and false used as method arguments. For example, if you want a class to show you all of its instance methods but to exclude those defined in ancestral classes, you can provide the argument false to your request:
>> String.instance_methods(false)
The problem with Boolean arguments is that it’s very hard to remember what they do. They’re rather cryptic. Therefore, it’s best to avoid them in your own code, unless there’s a case where the true/false distinction is very clear.
Let’s summarize the true/false situation in Ruby with a look at Boolean states versus Boolean values.
True/false: States vs. values
As you now know, every Ruby expression is true or false in a Boolean sense (as indicated by the if test), and there are also objects called true and false. This double usage of the true/false terminology is sometimes a source of confusion: when you say that something is true, it’s not always clear whether you mean it has a Boolean truth value or that it’s the object true.
Remember that every expression has a Boolean value—including the expression true and the expression false. It may seem awkward to have to say, “The object true is true.” But that extra step makes it possible for the model to work consistently.
Building on this point, and on some of the cases you saw in slightly different form in table 7.1, table 7.3 shows a mapping of some sample expressions to both the outcome of their evaluation and their Boolean value.
Table 7.3. Mapping sample expressions to their evaluation results and Boolean values
|
Expression |
Object to which expression evaluates |
Boolean value of expression |
|
1 |
1 |
True |
|
0 |
0 |
True |
|
1+1 |
2 |
True |
|
true |
true |
True |
|
false |
false |
False |
|
nil |
nil |
False |
|
"string" |
"string" |
True |
|
"" |
"" |
True |
|
puts "string" |
nil |
False |
|
100 > 50 |
true |
True |
|
x = 10 |
10 |
True |
|
def x; end |
:x |
True |
|
class C; end |
nil |
False |
|
class C; 1; end |
1 |
True |
Note in particular that zero and empty strings (as well as empty arrays and hashes) have a Boolean value of true. The only objects that have a Boolean value of false are false and nil.
And on the subject of nil: it’s time for us to look more closely at this unique object.
7.5.3. The special object nil
The special object nil is, indeed, an object (it’s the only instance of a class called NilClass). But in practice, it’s also a kind of nonobject. The Boolean value of nil is false, but that’s just the start of its nonobjectness.
nil denotes an absence of anything. You can see this graphically when you inquire into the value of, for example, an instance variable you haven’t initialized:
puts @x
This command prints nil. (If you try this with a local variable, you’ll get an error; local variables aren’t automatically initialized to anything, not even nil.) nil is also the default value for nonexistent elements of container and collection objects. For example, if you create an array with three elements, and then you try to access the tenth element (at index 9, because array indexing starts at 0), you’ll find that it’s nil:
>> ["one","two","three"][9]
=> nil
nil is sometimes a difficult object to understand. It’s all about absence and nonexistence; but nil does exist, and it responds to method calls like other objects:
>> nil.to_s
=> ""
>> nil.to_i
=> 0
>> nil.object_id
=> 8
The to_s conversion of nil is an empty string (""); the integer representation of nil is 0; and nil’s object ID is 8. (nil has no special relationship to 8; that just happens to be the number designated as its ID.)
It’s not accurate to say that nil is empty, because doing so would imply that it has characteristics and dimension, like a number or a collection, which it isn’t supposed to. Trying to grasp nil can take you into some thorny philosophical territory. You can think of nil as an object that exists and that comes equipped with a survival kit of methods but that serves the purpose of representing absence and a state of being undetermined.
Coming full circle, remember that nil has a Boolean value of false. nil and false are the only two objects that do. They’re not the only two expressions that do; 100 < 50 has a Boolean value of false, because it evaluates to the object false. But nil and false are the only two objects in Ruby with a Boolean value of false. All other Ruby objects—numbers, strings, instances of MyCoolClass—have a Boolean value of true. Tested directly, they all pass the if test.
Boolean values and testing provide a segue into the next topic: comparisons between objects. We’ll look at tests involving two objects and ways of determining whether they’re equal—and, if they aren’t, whether they can be ranked as greater/lesser, and based on what criteria.
7.6. Comparing two objects
Ruby objects are created with the capacity to compare themselves to other objects for equality and/or order, using any of several methods. Tests for equality are the most common comparison tests, and we’ll start with them. We’ll then look at a built-in Ruby module called Comparable, which gives you a quick way to impart knowledge of comparison operations to your classes and objects, and that is used for that purpose by a number of built-in Ruby classes.
7.6.1. Equality tests
Inside the Object class, all equality-test methods do the same thing: they tell you whether two objects are exactly the same object. Here they are in action:
>> a = Object.new
=> #<Object:0x00000101258af8>
>> b = Object.new
=> #<Object:0x00000101251d70>
>> a == a
=> true
>> a == b
=> false
>> a != b
=> true
>> a.eql?(a)
=> true
>> a.eql?(b)
=> false
>> a.equal?(a)
=> true
>> a.equal?(b)
=> false
All three of the positive equality-test methods (==, eql?, and equal?) give the same results in these examples: when you test a against a, the result is true, and when you test a against b, the result is false. (The not-equal or negative equality test method != is the inverse of the == method; in fact, if you define ==, your objects will automatically have the != method.) We have plenty of ways to establish that a is a but not b.
But there isn’t much point in having three tests that do the same thing. Further down the road, in classes other than Object, == and/or eql? are typically redefined to do meaningful work for different objects. The equal? method is usually left alone so that you can always use it to check whether two objects are exactly the same object.
Here’s an example involving strings. Note that they are == and eql?, but not equal?:
>> string1 = "text"
=> "text"
>> string2 = "text"
=> "text"
>> string1 == string2
=> true
>> string1.eql?(string2)
=> true
>> string1.equal?(string2)
=> false
Furthermore, Ruby gives you a suite of tools for object comparisons, and not always just comparison for equality. We’ll look next at how equality tests and their redefinitions fit into the overall comparison picture.
7.6.2. Comparisons and the Comparable module
The most commonly redefined equality-test method, and the one you’ll see used most often, is ==. It’s part of the larger family of equality-test methods, and it’s also part of a family of comparison methods that includes ==, !=, >, <, >=, and <=.
Not every class of object needs, or should have, all these methods. (It’s hard to imagine what it would mean for one Bicycle to be greater than or equal to another. Gears?) But for classes that do need full comparison functionality, Ruby provides a convenient way to get it. If you want objects of class MyClass to have the full suite of comparison methods, all you have to do is the following:
1. Mix a module called Comparable (which comes with Ruby) into MyClass.
2. Define a comparison method with the name <=> as an instance method in MyClass.
The comparison method <=> (usually called the spaceship operator or spaceship method) is the heart of the matter. Inside this method, you define what you mean by less than, equal to, and greater than. Once you’ve done that, Ruby has all it needs to provide the corresponding comparison methods.
For example, let’s say you’re taking bids on a job and using a Ruby script to help you keep track of what bids have come in. You decide it would be handy to be able to compare any two Bid objects, based on an estimate attribute, using simple comparison operators like > and <. Greater thanmeans asking for more money, and less than means asking for less money.
A simple first version of the Bid class might look like the following listing.
Listing 7.2. Example of a class that mixes in the Comparable module

The spaceship method ![]() consists of a cascading if/elsif/else statement. Depending on which branch is executed, the method returns a negative number (by convention, –1), a positive number (by convention, 1), or 0. Those three return values are predefined, prearranged signals to Ruby. Your <=> method must return one of those three values every time it’s called—and they always mean less than, equal to, and greater than, respectively.
consists of a cascading if/elsif/else statement. Depending on which branch is executed, the method returns a negative number (by convention, –1), a positive number (by convention, 1), or 0. Those three return values are predefined, prearranged signals to Ruby. Your <=> method must return one of those three values every time it’s called—and they always mean less than, equal to, and greater than, respectively.
You can shorten this method. Bid estimates are either floating-point numbers or integers (the latter, if you don’t bother with the cents parts of the figure or if you store the amounts as cents rather than dollars). Numbers already know how to compare themselves to each other, including integers to floats. Bid’s <=> method can therefore piggyback on the existing <=> methods of the Integer and Float classes, like this:
def <=>(other_bid)
self.estimate <=> other_bid.estimate
end
In this version of the spaceship method, we’re punting; we’re saying that if you want to know how two bids compare to each other, bump the question to the estimate values for the two bids and use that comparison as the basis for the bid-to-bid comparison.
The payoff for defining the spaceship operator and including Comparable is that you can from then on use the whole set of comparison methods on pairs of your objects. In this example, bid1 wins the contract; it’s less than (as determined by <) bid2:
>> bid1 = Bid.new
=> #<Bid:0x000001011d5d60>
>> bid2 = Bid.new
=> #<Bid:0x000001011d4320>
>> bid1.estimate = 100
=> 100
>> bid2.estimate = 105
=> 105
>> bid1 < bid2
=> true
The < method (along with >, >=, <=, ==, !=, and between?) is defined in terms of <=>, inside the Comparable module. (b.between?(a,c) tells you whether b > a and b < c.)
All Ruby numerical classes include Comparable and have a definition for <=>. The same is true of the String class; you can compare strings using the full assortment of Comparable method/operators. Comparable is a handy tool, giving you a lot of functionality in return for, essentially, one method definition.
We’ll now turn to the subject of runtime object inspection. In keeping with the spirit of this chapter, we’ll look at enough techniques to sustain you through most of the rest of the book. Keep in mind, though, that chapter 15, the last in the book, will come back to the topic of runtime inspection (among others). So you can take this as the first, but not the last, substantial look at the topic.
7.7. Inspecting object capabilities
Inspection and reflection refer, collectively, to the various ways in which you can get Ruby objects to tell you about themselves during their lifetimes. Much of what you learned earlier about getting objects to show string representations of themselves could be described as inspection. In this section, we’ll look at a different kind of runtime reflection: techniques for asking objects about the methods they can execute.
How you do this depends on the object and on exactly what you’re looking for. Every object can tell you what methods you can call on it, at least as of the moment you ask it. In addition, class and module objects can give you a breakdown of the methods they provide for the objects that have use of those methods (as instances or via module inclusion).
7.7.1. Listing an object’s methods
The simplest and most common case is when you want to know what messages an object understands—that is, what methods you can call on it. Ruby gives you a typically simple way to do this. Enter this into irb:
>> "I am a String object".methods
You’ll see a large array of method names. At the least, you’ll want to sort them so you can find what you’re looking for:
>> "I am a String object".methods.sort
The methods method works with class and module objects, too. But remember, it shows you what the object (the class or module) responds to, not what instances of the class or objects that use the module respond to. For example, asking irb for
>> String.methods.sort
shows a list of methods that the Class object String responds to. If you see an item in this list, you know you can send it directly to String.
The methods you see when you call methods on an object include its singleton methods—those that you’ve written just for this object—as well as any methods it can call by virtue of the inclusion of one or more modules anywhere in its ancestry. All these methods are presented as equals: the listing of methods flattens the method lookup path and only reports on what methods the object knows about, regardless of where they’re defined.
You can verify this in irb. Here’s an example where a singleton method is added to a string. If you include the call to str.methods.sort at the end, you’ll see that shout is now among the string’s methods:
>> str = "A plain old string"
=> "A plain old string"
>> def str.shout
>> self.upcase + "!!!"
>> end
=> nil
>> str.shout
=> "A PLAIN OLD STRING!!!"
>> str.methods.sort
Conveniently, you can ask just for an object’s singleton methods:
>> str.singleton_methods
=> [:shout]
Similarly, if you mix a module into a class with include, instances of that class will report themselves as being able to call the instance methods from that module. Interestingly, you’ll get the same result even if you include the module after the instance already exists. Start a new irb session (to clear the memory of the previous example), and try this code. Instead of printing out all the methods, we’ll use a couple of less messy techniques to find out whether str has the shout method:

Including the module affects strings that already exist because when you ask a string to shout, it searches its method lookup path for a shout method and finds it in the module. The string really doesn’t care when or how the module got inserted into the lookup path.
Any object can tell you what methods it knows. In addition, class and module objects can give you information about the methods they provide.
7.7.2. Querying class and module objects
One of the methods you’ll find in the list generated by the irb command String. methods.sort is instance_methods. It tells you all the instance methods that instances of String are endowed with:
>> String.instance_methods.sort
The resulting list is the same as the list of methods, as shown by methods, for any given string (unless you’ve added singleton methods to that string).
You can make a similar request of a module:
>> Enumerable.instance_methods.sort
In addition to straightforward method and instance-method lists, Ruby provides a certain number of tweaks to help you make more fine-grained queries.
7.7.3. Filtered and selected method lists
Sometimes you’ll want to see the instance methods defined in a particular class without bothering with the methods every object has. After all, you already know that your object has those methods. You can view a class’s instance methods without those of the class’s ancestors by using the slightly arcane technique, introduced earlier, of providing the argument false to the instance_methods method:
String.instance_methods(false).sort
You’ll see many fewer methods this way, because you’re looking at a list of only those defined in the String class, without those defined in any of String’s ancestral classes or modules. This approach gives you a restricted picture of the methods available to string objects, but it’s useful for looking in a more fine-grained way at how and where the method definitions behind a given object are positioned.
Other method-listing methods include the following (of which you’ve seen singleton_methods already):
· obj.private_methods
· obj.public_methods
· obj.protected_methods
· obj.singleton_methods
In addition, classes and modules let you examine their instance methods:
· MyClass.private_instance_methods
· MyClass.protected_instance_methods
· MyClass.public_instance_methods
The last of these, public_instance_methods, is a synonym for instance_methods.
The mechanisms for examining objects’ methods are extensive. As always, be clear in your own mind what the object is (in particular, class/module or “regular” object) that you’re querying and what you’re asking it to tell you.
We’ve reached the end of our midbook bootstrap session, survival kit, literacy guide.... Whatever you call it (even “chapter 7”!), it puts us in a good position to look closely at a number of important core classes, which we’ll do over the next several chapters.
7.8. Summary
In this chapter you’ve seen
· Ruby’s literal constructors
· Syntactic sugar converting methods into operators
· “Destructive” methods and bang methods
· Conversion methods (to_s and friends)
· The inspect and display methods
· Boolean values and Boolean objects
· The special object nil
· Comparing objects and the Comparable module
· Examining an object’s methods
This chapter covered several topics that pertain to multiple built-in classes and modules. You’ve seen Ruby’s literal constructors, which provide a concise alternative to calling new on certain built-in classes. You’ve also seen how Ruby provides syntactic sugar for particular method names, including a large number of methods with names that correspond to arithmetic operators.
We looked at the significance of methods that change their own receivers, which many built-in methods do (many of them bang methods, which end with !). We also examined the to_* methods: built-in methods for performing conversions from one core class to another.
You’ve also learned a number of important points and techniques concerning Boolean (true/false) values and comparison between objects. You’ve seen that every object in Ruby has a Boolean value and that Ruby also has special Boolean objects (true and false) that represent those values in their simplest form. A third special object, nil, represents a state of undefinedness or absence. We also discussed techniques for comparing objects using the standard comparison operator (<=>) and the Comparable module.
Finally, we looked at ways to get Ruby objects to tell you what methods they respond to—a kind of reflection technique that can help you see and understand what’s going on at a given point in your program. We’ll look more deeply at introspection and reflection in chapter 15.
The material in this chapter will put you in a strong position to absorb what you encounter later, in the rest of this book and beyond. When you read statements like “This method has a bang alternative,” you’ll know what they mean. When you see documentation that tells you a particular method argument defaults to nil, you’ll know what that means. And the fact that you’ve learned about these recurrent topics will help us economize on repetition in the upcoming chapters about built-in Ruby classes and modules and concentrate instead on moving ahead.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.