The Well-Grounded Rubyist, Second Edition (2014)
Part 1. Ruby foundations
Chapter 5. The default object (self), scope, and visibility
This chapter covers
· The role of the current or default object, self
· Scoping rules for local, global, and class variables
· Constant lookup and visibility
· Method-access rules
In describing and discussing computer programs, we often use spatial and, sometimes, human metaphors. We talk about being “in” a class definition or returning “from” a method call. We address objects in the second person, as in obj.respond_to?("x") (that is, “Hey obj, do you respond to'x'?”). As a program runs, the question of which objects are being addressed, and where in the imaginary space of the program they stand, constantly shifts.
And the shifts aren’t just metaphorical. The meanings of identifiers shift too. A few elements mean the same thing everywhere. Integers, for example, mean what they mean wherever you see them. The same is true for keywords: you can’t use keywords like def and class as variable names, so when you see them, you can easily glean what they’re doing. But most elements depend on context for their meaning. Most words and tokens—most identifiers—can mean different things at different places and times.
This chapter is about orienting yourself in Ruby code: knowing how the identifiers you’re using are going to resolve, following the shifts in context, and making sense of the use and reuse of identifiers and terms. If you understand what can change from one context to another, and also what triggers a change in context (for example, entering a method-definition block), you can always get your bearings in a Ruby program. And it’s not just a matter of passive Ruby literacy: you also need to know about contexts and how they affect the meaning of what you’re doing when you’re writing Ruby.
This chapter focuses initially on two topics: self and scope. Self is the “current” or “default” object, a role typically assigned to many objects in sequence (though only one at a time) as a program runs. The self object in Ruby is like the first person or I of the program. As in a book with multiple first-person narrators, the I role can get passed around. There’s always one self, but what object it is will vary. The rules of scope govern the visibility of variables (and other elements, but largely variables). It’s important to know what scope you’re in, so that you can tell what the variables refer to and not confuse them with variables from different scopes that have the same name, nor with similarly named methods.
Between them, self and scope are the master keys to orienting yourself in a Ruby program. If you know what scope you’re in and know what object is self, you’ll be able to tell what’s going on, and you’ll be able to analyze errors quickly.
The third main topic of this chapter is method access. Ruby provides mechanisms for making distinctions among access levels of methods. Basically, this means rules limiting the calling of methods depending on what self is. Method access is therefore a meta-topic, grounded in the study of self and scope.
Finally, we’ll also discuss a topic that pulls together several of these threads: top-level methods, which are written outside of any class or module definition.
Let’s start with self.
5.1. Understanding self, the current/default object
One of the cornerstones of Ruby programming—the backbone, in some respects—is the default object or current object, accessible to you in your program through the keyword self. At every point when your program is running, there’s one and only one self. Being self has certain privileges, as you’ll see. In this section, we’ll look at how Ruby determines which object is self at a given point and what privileges are granted to the object that is self.
5.1.1. Who gets to be self, and where
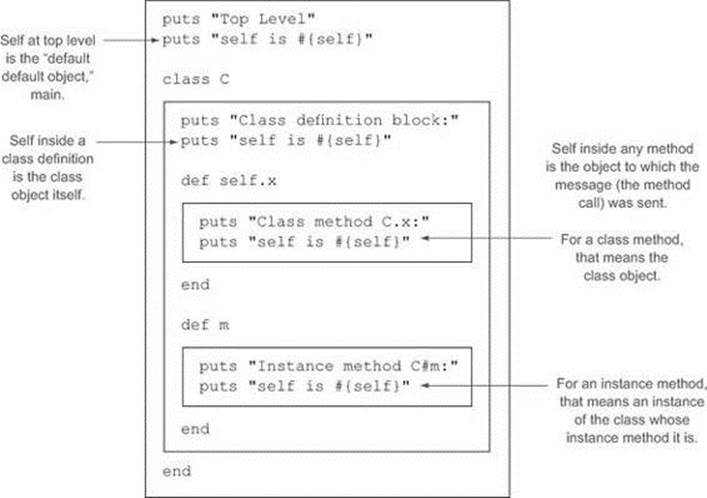
There’s always one (and only one) current object or self. You can tell which object it is by following the small set of rules summarized in table 5.1. The table’s contents will be explained and illustrated as we go along.
Table 5.1. How the current object (self) is determined
|
Context |
Example |
Which object is self? |
|
Top level of program |
Any code outside of other blocks |
main (built-in top-level default object) |
|
Class definition |
class C |
The class object C |
|
Module definition |
module M |
The module object M |
|
Method definitions |
1. Top level (outside any definition block): def method_name self |
Whatever object is self when the method is called; top-level methods are available as private methods to all objects |
|
1. Instance-method definition in a class: class C def method_name self |
An instance of C, responding to method_name |
|
|
1. Instance-method definition in a module: module M def method_name self |
· Individual object extended by M · Instance of class that mixes in M |
|
|
1. Singleton method on a specific object: def obj.method_name self |
Obj |
To know which object is self, you need to know what context you’re in. In practice, there aren’t many contexts to worry about. There’s the top level (before you’ve entered any other context, such as a class definition). There are class-definition blocks, module-definition blocks, and method-definition blocks. Aside from a few subtleties in the way these contexts interact, that’s about it. As shown in table 5.1, self is determined by which of these contexts you’re in (class and module definitions are similar and closely related).
Figure 5.1 gives you a diagrammatic view of most of the cases in table 5.1. Both show you that some object is always self and that which object is self depends on where you are in the program.
Figure 5.1. The determination of self in different contexts
The most basic program context, and in some respects a unique one, is the top level: the context of the program before any class or module definition has been opened, or after they’ve all been closed. We’ll look next at the top level’s ideas about self.
5.1.2. The top-level self object
The term top-level refers to program code written outside of any class- or module-definition block. If you open a brand-new text file and type
x = 1
you’ve created a top-level local variable x. If you type
def m
end
you’ve created a top-level method. (We’ll look at top-level methods in much more detail in section 5.4; they’re relevant here just as pointers to the existence of a top-level self.) A number of our examples, particularly in the early chapters (for example, those in chapter 2 demonstrating argument semantics) involved top-level code. Once we started writing class and module definitions, more of our code began to appear inside those definitions. The way self shifts in class, module, and method definitions is uniform: the keyword (class, module, or def) marks a switch to a new self. But what’s self when you haven’t yet entered any definition block?
The answer is that Ruby provides you with a start-up self at the top level. If you ask it to identify itself with
ruby -e 'puts self'
it will tell you that it’s called main.
main is a special term that the default self object uses to refer to itself. You can’t refer to it as main; Ruby will interpret your use of main as a regular variable or method name. If you want to grab main for any reason, you need to assign it to a variable at the top level:
m = self
It’s not likely that you’d need to do this, but that’s how it’s done. More commonly, you’ll feel the need for a fairly fine-grained sense of what self is in your class, module, and method definitions, where most of your programming will take place.
5.1.3. Self inside class, module, and method definitions
It pays to keep a close eye on self as you write classes, modules, and methods. There aren’t that many rules to learn, and they’re applied consistently. But they’re worth learning well up front, so you’re clear on why the various techniques you use that depend on the value of self play out the way they do.
It’s all about self switching from one object to another, which it does when you enter a class or module definition, an instance-method definition, or a singleton-method (including class-method) definition.
Self in class and module definitions
In a class or module definition, self is the class or module object. This innocent-sounding rule is important. If you master it, you’ll save yourself from several of the most common mistakes that people make when they’re learning Ruby.
You can see what self is at various levels of class and/or module definition by using puts explicitly, as shown in the following listing.
Listing 5.1. Examining self via calls to puts in class and module definitions

As soon as you cross a class or module keyword boundary, the class or module whose definition block you’ve entered—the Class or Module object—becomes self. Listing 5.1 shows two cases: entering C, and then entering C::M. When you leave C::M but are still in C, self is once again C.
Of course, class- and module-definition blocks do more than just begin and end. They also contain method definitions, which, for both instance methods and class methods, have rules determining self.
Self in instance-method definitions
The notion of self inside an instance-method definition is subtle, for the following reason: when the interpreter encounters a def/end block, it defines the method immediately. But the code inside the method definition isn’t executed until later, when an object capable of triggering its execution receives the appropriate message.
When you’re looking at a method definition on paper or on the screen, you can only know in principle that, when the method is called, self will be the object that called it (the receiver of the message). At the time the method gets defined, the most you can say is that self inside this method will be some future object that calls the method.
You can rig a method to show you self as it runs:
class C
def x
puts "Class C, method x:"
puts self
end
end
c = C.new
c.x
puts "That was a call to x by: #{c}"
This snippet outputs
Class C, method x:
#<C:0x00000101b381a0>
That was a call to x by: #<C:0x00000101b381a0>
The weird-looking item in the output (#<C:0x00000101b381a0>) is Ruby’s way of saying “an instance of C.” (The hexadecimal number after the colon is a memory-location reference. When you run the code on your system, you’ll probably get a different number.) As you can see, the receiver of the “x” message, namely c, takes on the role of self during execution of x.
Self in singleton-method and class-method definitions
As you might expect, when a singleton method is executed, self is the object that owns the method, as an object will readily tell you:
obj = Object.new
def obj.show_me
puts "Inside singleton method show_me of #{self}"
end
obj.show_me
puts "Back from call to show_me by #{obj}"
The output of this example is as follows:
Inside singleton method show_me of #<Object:0x00000101b19840>
Back from call to show_me by #<Object:0x00000101b19840>
It makes sense that if a method is written to be called by only one object, that object gets to be self. Moreover, this is a good time to remember class methods—which are, essentially, singleton methods attached to class objects. The following example reports on self from inside a class method of C:
class C
def C.x
puts "Class method of class C"
puts "self: #{self}"
end
end
C.x
Here’s what it reports:
Class method of class C
self: C
Sure enough, self inside a singleton method (a class method, in this case) is the object whose singleton method it is.
Using self instead of hard-coded class names
By way of a little programming tip, here’s a variation on the last example:

Note the use of self.x ![]() rather than C.x. This way of writing a class method takes advantage of the fact that in the class definition, self is C. So def self.x is the same as def C.x.
rather than C.x. This way of writing a class method takes advantage of the fact that in the class definition, self is C. So def self.x is the same as def C.x.
The self.x version offers a slight advantage: if you ever decide to rename the class, self.x will adjust automatically to the new name. If you hard-code C.x, you’ll have to change C to your class’s new name. But you do have to be careful. Remember that self inside a method is always the object on which the method was called. You can get into a situation where it feels like self should be one class object, but is actually another:
class D < C
end
D.x
D gets to call x, because subclasses get to call the class methods of their superclasses. As you’ll see if you run the code, the method C.x reports self—correctly—as being D, because it’s D on which the method is called.
Being self at a given point in the program comes with some privileges. The chief privilege enjoyed by self is that of serving as the default receiver of messages, as you’ll see next.
5.1.4. Self as the default receiver of messages
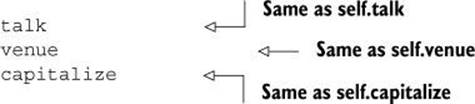
Calling methods (that is, sending messages to objects) usually involves the dot notation:
obj.talk
ticket.venue
"abc".capitalize
That’s the normal, full form of the method-calling syntax in Ruby. But a special rule governs method calls: if the receiver of the message is self, you can omit the receiver and the dot. Ruby will use self as the default receiver, meaning the message you send will be sent to self, as the following equivalencies show:
Warning
You can give a method and a local variable the same name, but it’s rarely if ever a good idea. If both a method and a variable of a given name exist, and you use the bare identifier (like talk), the variable takes precedence. To force Ruby to see the identifier as a method name, you’d have to use self.talk or call the method with an empty argument list: talk(). Because variables don’t take arguments, the parentheses establish that you mean the method rather than the variable. Again, it’s best to avoid these name clashes if you can.
Let’s see this concept in action by inducing a situation where we know what self is and then testing the dotless form of method calling. In the top level of a class-definition block, self is the class object. And we know how to add methods directly to class objects. So we have the ingredients to do a default receiver demo:

The first call to no_dot ![]() doesn’t have an explicit receiver; it’s a bareword. When Ruby sees this (and determines that it’s a method call rather than a variable or keyword), it figures that you mean it as shorthand for
doesn’t have an explicit receiver; it’s a bareword. When Ruby sees this (and determines that it’s a method call rather than a variable or keyword), it figures that you mean it as shorthand for
self.no_dot
and the message gets printed. In the case of our example, self.no_dot would be the same as C.no_dot, because we’re inside C’s definition block and, therefore, self is C. The result is that the method C.no_dot is called, and we see the output.
The second time we call the method ![]() we’re back outside the class-definition block, so C is no longer self. Therefore, to call no_dot, we need to specify the receiver: C. The result is a second call to no_dot (albeit with a dot) and another printing of the output from that method.
we’re back outside the class-definition block, so C is no longer self. Therefore, to call no_dot, we need to specify the receiver: C. The result is a second call to no_dot (albeit with a dot) and another printing of the output from that method.
The most common use of the dotless method call occurs when you’re calling one instance method from another. Here’s an example:
class C
def x
puts "This is method 'x'"
end
def y
puts "This is method 'y', about to call x without a dot."
x
end
end
c = C.new
c.y
The output is
This is method 'y', about to call x without a dot.
This is method 'x'.
Upon calling c.y, the method y is executed, with self set to c (which is an instance of C). Inside y, the bareword reference to x is interpreted as a message to be sent to self. That, in turn, means the method x is executed.
There’s one situation where you can’t omit the object-plus-dot part of a method call: when the method name ends with an equal sign—a setter method, in other words. You have to do self.venue = "Town Hall" rather than venue = "Town Hall" if you want to call the method venue= on self. The reason is that Ruby always interprets the sequence identifier = value as an assignment to a local variable. To call the method venue= on the current object, you need to include the explicit self. Otherwise, you end up with a variable called venue and no call to the setter method.
The default to self as receiver for dotless method invocations allows you to streamline your code nicely in cases where one method makes use of another. A common case is composing a whole name from its components: first, optional middle, and last. The following listing shows a technique for doing this, using attributes for the three name values and conditional logic to include the middle name, plus a trailing space, if and only if there’s a middle name.
Listing 5.2. Composing whole name from values, using method calls on implicit self

The output from the calling code in this listing is as follows:
David's whole name: David Black
David's new whole name: David Alan Black
The definition of whole_name depends on the bareword method calls to first_name, middle_name, and last_name being sent to self—self being the Person instance (david in the example). The variable n serves as a string accumulator, with the components of the name added to it one by one. The return value of the entire method is n, because the expression n << last_name ![]() has the effect of appending last_name to n and returning the result of that operation.
has the effect of appending last_name to n and returning the result of that operation.
In addition to serving automatically as the receiver for bareword messages, self also enjoys the privilege of being the owner of instance variables.
5.1.5. Resolving instance variables through self
A simple rule governs instance variables and their resolution: every instance variable you’ll ever see in a Ruby program belongs to whatever object is the current object (self) at that point in the program.
Here’s a classic case where this knowledge comes in handy. See if you can figure out what this code will print, before you run it:

The code prints the following:
I am an instance variable initialized to a string.
The trap is that you may think it will print "Instance variables can appear anywhere...." The code prints what it does because the @v in the method definition ![]() and the @v outside it
and the @v outside it ![]() are completely unrelated to each other. They’re both instance variables, and both are named @v, but they aren’t the same variable. They belong to different objects.
are completely unrelated to each other. They’re both instance variables, and both are named @v, but they aren’t the same variable. They belong to different objects.
Whose are they?
The first @v ![]() lies inside the definition block of an instance method of C. That fact has implications not for a single object, but for instances of C in general: each instance of C that calls this method will have its own instance variable @v.
lies inside the definition block of an instance method of C. That fact has implications not for a single object, but for instances of C in general: each instance of C that calls this method will have its own instance variable @v.
The second @v ![]() belongs to the class object C. This is one of the many occasions where it pays to remember that classes are objects. Any object may have its own instance variables—its own private stash of information and object state. Class objects enjoy this privilege as much as any other object.
belongs to the class object C. This is one of the many occasions where it pays to remember that classes are objects. Any object may have its own instance variables—its own private stash of information and object state. Class objects enjoy this privilege as much as any other object.
Again, the logic required to figure out what object owns a given instance variable is simple and consistent: every instance variable belongs to whatever object is playing the role of self at the moment the code containing the instance variable is executed.
Let’s do a quick rewrite of the example, this time making it a little chattier about what’s going on. The following listing shows the rewrite.
Listing 5.3. Demonstrating the relationship between instance variables and self
class C
puts "Just inside class definition block. Here's self:"
p self
@v = "I am an instance variable at the top level of a class body."
puts "And here's the instance variable @v, belonging to #{self}:"
p @v
def show_var
puts "Inside an instance method definition block. Here's self:"
p self
puts "And here's the instance variable @v, belonging to #{self}:"
p @v
end
end
c = C.new
c.show_var
The output from this version is as follows:
Just inside class definition block. Here's self:
C
And here's the instance variable @v, belonging to C:
"I am an instance variable at the top level of a class body."
Inside an instance method definition block. Here's self:
#<C:0x00000101a77338>
And here's the instance variable @v, belonging to #<C:0x00000101a77338>:
nil
Sure enough, each of these two different objects (the class object C and the instance of C, c) has its own instance variable @v. The fact that the instance’s @v is nil demonstrates that the assignment to the class’s @v had nothing to do with the instance’s @v.
Understanding self—both the basic fact that such a role is being played by some object at every point in a program and knowing how to tell which object is self—is one of the most vital aspects of understanding Ruby. Another equally vital aspect is understanding scope, to which we’ll turn now.
5.2. Determining scope
Scope refers to the reach or visibility of identifiers, specifically variables and constants. Different types of identifiers have different scoping rules; using, say, the identifier x for a local variable in each of two method definitions has a different effect than using the global variable $x in the same two places, because local and global variables differ as to scope. In this section, we’ll consider three types of variables: global, local, and class variables. (As you’ve just seen, instance variables are self-bound, rather than scope-bound.) We’ll also look at the rules for resolving constants.
Self and scope are similar in that they both change over the course of a program, and in that you can deduce what’s going on with them by reading the program as well as running it. But scope and self aren’t the same thing. You can start a new local scope without self changing—but sometimes scope and self change together. They have in common the fact that they’re both necessary to make sense of what your code is going to do. Like knowing which object self is, knowing what scope you’re in tells you the significance of the code.
Let’s start with global variables—not the most commonly used construct, but an important one to grasp.
5.2.1. Global scope and global variables
Global scope is scope that covers the entire program. Global scope is enjoyed by global variables, which are recognizable by their initial dollar-sign ($) character. They’re available everywhere. They walk through walls: even if you start a new class or method definition, even if the identity of self changes, the global variables you’ve initialized are still available to you.
In other words, global variables never go out of scope. (An exception to this is “thread-local globals,” which you’ll meet in chapter 14.) In this example, a method defined inside a class-definition body (two scopes removed from the outer- or top-level scope of the program) has access to a global variable initialized at the top:

You’ll be told by $gvar, in no uncertain terms, “I’m a global!” If you change all the occurrences of $gvar to a non-global variable, such as local_var, you’ll see that the top-level local_var isn’t in scope inside the method-definition block.
Built-in global variables
The Ruby interpreter starts up with a fairly large number of global variables already initialized. These variables store information that’s of potential use anywhere and everywhere in your program. For example, the global variable $0 contains the name of the startup file for the currently running program. The global $: (dollar sign followed by a colon) contains the directories that make up the path Ruby searches when you load an external file. $$ contains the process ID of the Ruby process. And there are more.
Tip
A good place to see descriptions of all the built-in global variables you’re likely to need—and then some—is the file English.rb in your Ruby installation. This file provides less-cryptic names for the notoriously cryptic global variable set. (Don’t blame Ruby for the names—most of them come from shell languages and/or Perl and awk.) If you want to use the slightly friendlier names in your programs, you can do require "English", after which you can refer to $IGNORECASE instead of $=, $PID instead of $$, and so forth. A few globals have their English-language names preloaded; you can say $LOAD_PATH instead of $: even without loading English.rb.
Creating your own global variables can be tempting, especially for beginning programmers and people learning a new language (not just Ruby, either). But that’s rarely a good or appropriate choice.
Pros and cons of global variables
Globals appear to solve lots of design problems: you don’t have to worry about scope, and multiple classes can share information by stashing it in globals rather than designing objects that have to be queried with method calls. Without doubt, global variables have a certain allure.
But they’re used very little by experienced programmers. The reasons for avoiding them are similar to the reasons they’re tempting. Using global variables tends to end up being a substitute for solid, flexible program design, rather than contributing to it. One of the main points of object-oriented programming is that data and actions are encapsulated in objects. You’re supposed to have to query objects for information and to request that they perform actions.
And objects are supposed to have a certain privacy. When you ask an object to do something, you’re not supposed to care what the object does internally to get the job done. Even if you yourself wrote the code for the object’s methods, when you send the object a message, you treat the object as a black box that works behind the scenes and provides a response.
Global variables distort the landscape by providing a layer of information shared by every object in every context. The result is that objects stop talking to each other and, instead, share information by setting global variables.
Here’s a small example—a rewrite of our earlier Person class (the one with the first, optional middle, and last names). This time, instead of attributes on the object, we’ll generate the whole name from globals:
class Person
def whole_name
n = $first_name + " "
n << "#{$middle_name} " if $middle_name
n << $last_name
end
end
To use this class and to get a whole name from an instance of it, you’d have to do this:

This version still derives the whole name, from outside, by querying the object. But the components of the name are handed around over the heads of the objects, so to speak, in a separate network of global variables. It’s concise and easy, but it’s also drastically limited. What would happen if you had lots of Person objects, or if you wanted to save a Person object, including its various names, to a database? Your code would quickly become tangled, to say the least.
Globally scoped data is fundamentally in conflict with the object-oriented philosophy of endowing objects with abilities and then getting things done by sending requests to those objects. Some Ruby programmers work for years and never use a single global variable (except perhaps a few of the built-in ones). That may or may not end up being your experience, but it’s not a bad target to aim for.
Now that we’ve finished with the “try not to do this” part, let’s move on to a detailed consideration of local scope.
5.2.2. Local scope
Local scope is a basic layer of the fabric of every Ruby program. At any given moment, your program is in a particular local scope. The main thing that changes from one local scope to another is your supply of local variables. When you leave a local scope—by returning from a method call, or by doing something that triggers a new local scope—you get a new supply. Even if you’ve assigned to a local variable x in one scope, you can assign to a new x in a new scope, and the two x’s won’t interfere with each other.
You can tell by looking at a Ruby program where the local scopes begin and end, based on a few rules:
· The top level (outside of all definition blocks) has its own local scope.
· Every class or module-definition block (class, module) has its own local scope, even nested class-/module-definition blocks.
· Every method definition (def) has its own local scope; more precisely, every call to a method generates a new local scope, with all local variables reset to an undefined state.
Exceptions and additions to these rules exist, but they’re fairly few and don’t concern us right now.
Figure 5.2 illustrates the creation of a number of local scopes.
Figure 5.2. Schematic view of local scopes at the top level, the class-definition level, and the methoddefinition level
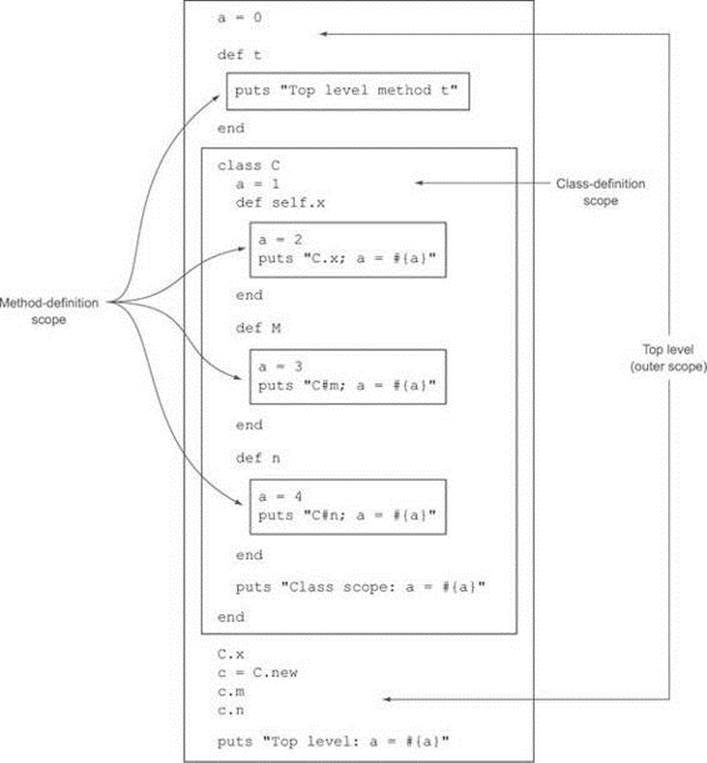
Every time you cross into a class-, module-, or method-definition block—every time you step over a class, module, or def keyword—you start a new local scope. Local variables that lie very close to each other physically may in fact have nothing whatsoever to do with each other, as this example shows:
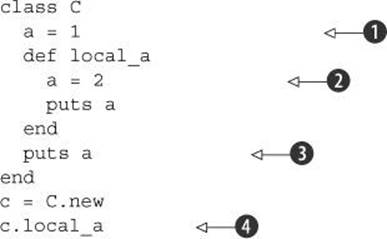
This code produces the following output:
1
2
The variable a that gets initialized in the local scope of the class definition ![]() is in a different scope than the variable a inside the method definition
is in a different scope than the variable a inside the method definition ![]() . When you get to the puts a statement after the method definition
. When you get to the puts a statement after the method definition ![]() , you’re back in the class-definition local scope; the a that gets printed is the a you initialized back at the top
, you’re back in the class-definition local scope; the a that gets printed is the a you initialized back at the top ![]() , not the a that’s in scope in the method definition
, not the a that’s in scope in the method definition ![]() . Meanwhile, the second a isn’t printed until later, when you’ve created the instance c and sent the message local_a to it
. Meanwhile, the second a isn’t printed until later, when you’ve created the instance c and sent the message local_a to it ![]() .
.
When you nest classes and modules, every crossing into a new definition block creates a new local scope. The following listing shows some deep nesting of classes and modules, with a number of variables called a being initialized and printed out along the way.
Listing 5.4. Reusing a variable name in nested local scopes
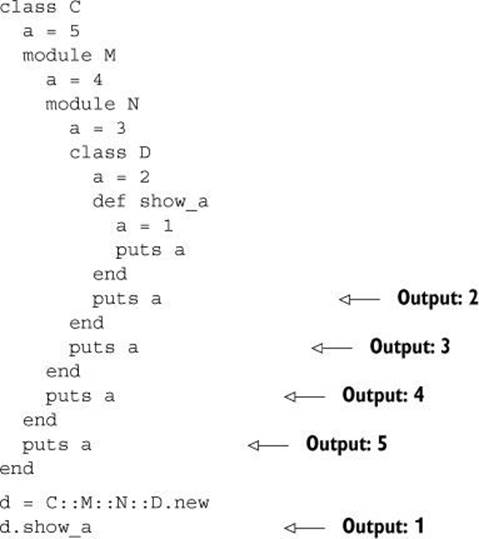
Every definition block—whether for a class, a module, or a method—starts a new local scope—a new local-variable scratchpad—and gets its own variable a. This example also illustrates the fact that all the code in class- and module-definition blocks gets executed when it’s first encountered, whereas methods aren’t executed until an object is sent the appropriate message. That’s why the value of a that’s set inside the show_a method is displayed last among the five values that the program prints; the other four are executed as they’re encountered in the class or module definitions, but the last one isn’t executed until show_a is executed by the object d.
Local scope changes often, as you can see. So does the identity of self. Sometimes, but only sometimes, they vary together. Let’s look a little closer at the relationship between scope and self.
5.2.3. The interaction between local scope and self
When you start a definition block (method, class, module), you start a new local scope, and you also create a block of code with a particular self. But local scope and self don’t operate entirely in parallel, not only because they’re not the same thing, but also because they’re not the same kindof thing.
Consider the following listing. This program uses recursion: the instance method x calls itself. The point is to demonstrate that every time a method is called—even if a previous call to the method is still in the process of running—a new local scope is generated.
Listing 5.5. Demonstrating the generation of a new local scope per method call

The instance method C#x takes two arguments: a value to assign to the variable a and a flag telling the method whether to call itself ![]() . (The use of the flag provides a way to prevent infinite recursion.) The first line of the method initializes a
. (The use of the flag provides a way to prevent infinite recursion.) The first line of the method initializes a ![]() , and the next several lines of the method print out the string representation of self and the value of a
, and the next several lines of the method print out the string representation of self and the value of a ![]() .
.
Now comes the decision: to recurse, or not to recurse. It depends on the value of the recurse variable ![]() . If the recursion happens, it calls x without specifying a value for the recurse parameter
. If the recursion happens, it calls x without specifying a value for the recurse parameter ![]() ; that parameter will default to false, and recursion won’t happen the second time through.
; that parameter will default to false, and recursion won’t happen the second time through.
The recursive call uses a different value for the value_for_a argument; therefore, different information will be printed out during that call. But upon returning from the recursive call, we find that the value of a in this run of x hasn’t changed ![]() . In short, every call to x generates a new local scope, even though self doesn’t change.
. In short, every call to x generates a new local scope, even though self doesn’t change.
The output from calling x on an instance of C and setting the recurse flag to true ![]() looks like this:
looks like this:
Here's the inspect-string for 'self': #<C:0x00000101b25be0>
And here's a:
First value for a
Calling myself (recursion)...
Here's the inspect-string for 'self': #<C:0x00000101b25be0>
And here's a:
Second value for a
Back after recursion; here's a:
First value for a
There’s no change to self, but the local variables are reset.
Tip
Instead of printing out the default string representation of an object, you can also use the object_id method to identify the object uniquely. Try changing p self to puts self.object_id, and puts a to puts a.object_id in the previous example.
If this listing seems like the long way around to making the point that every method call has its own local scope, think of it as a template or model for the kinds of demonstrations you might try yourself as you develop an increasingly fine-grained sense of how scope and self work, separately and together.
Note
It’s also possible to do the opposite of what listing 5.5 demonstrates—namely, to change self without entering a new local scope. This is accomplished with the instance_eval and instance_exec methods, which we’ll look at later.
Like variables, constants are governed by rules of scope. We’ll look next at how those rules work.
5.2.4. Scope and resolution of constants
As you’ve seen, constants can be defined inside class- and method-definition blocks. If you know the chain of nested definitions, you can access a constant from anywhere. Consider this nest:
module M
class C
class D
module N
X = 1
end
end
end
end
You can refer to the module M, the class M::C, and so forth, down to the simple constant M::C::D::N::X (which is equal to 1).
Constants have a kind of global visibility or reachability: as long as you know the path to a constant through the classes and/or modules in which it’s nested, you can get to that constant. Stripped of their nesting, however, constants definitely aren’t globals. The constant X in one scope isn’t the constant X in another:
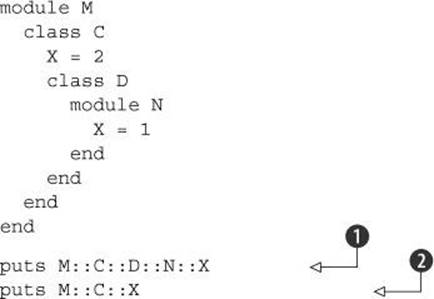
As per the nesting, the first puts ![]() gives you 1; the second
gives you 1; the second ![]() gives you 2. A particular constant identifier (like X) doesn’t have an absolute meaning the way a global variable (like $x) does.
gives you 2. A particular constant identifier (like X) doesn’t have an absolute meaning the way a global variable (like $x) does.
Constant lookup—the process of resolving a constant identifier, or finding the right match for it—bears a close resemblance to searching a file system for a file in a particular directory. For one thing, constants are identified relative to the point of execution. Another variant of our example illustrates this:

Here the identifier D::N::X is interpreted relative to where it occurs: inside the definition block of the class M::C. From M::C’s perspective, D is just one level away. There’s no need to do M::C::D::N::X, when just D::N::X points the way down the path to the right constant. Sure enough, we get what we want: a printout of the number 1.
Forcing an absolute constant path
Sometimes you don’t want a relative path. Sometimes you really want to start the constant-lookup process at the top level—just as you sometimes need to use an absolute path for a file.
This may happen if you create a class or module with a name that’s similar to the name of a Ruby built-in class or module. For example, Ruby comes with a String class. But if you create a Violin class, you may also have Strings:

The constant String in this context ![]() resolves to Violin::String, as defined. Now let’s say that elsewhere in the overall Violin class definition, you need to refer to Ruby’s built-in String class. If you have a plain reference to String, it resolves to Violin::String. To make sure you’re referring to the built-in, original String class, you need to put the constant path separator :: (double colon) at the beginning of the class name:
resolves to Violin::String, as defined. Now let’s say that elsewhere in the overall Violin class definition, you need to refer to Ruby’s built-in String class. If you have a plain reference to String, it resolves to Violin::String. To make sure you’re referring to the built-in, original String class, you need to put the constant path separator :: (double colon) at the beginning of the class name:
def history
::String.new(maker + ", " + date)
end
This way, you get a Ruby String object instead of a Violin::String object. Like the slash at the beginning of a pathname, the :: in front of a constant means “start the search for this at the top level.” (Yes, you could just piece the string together inside double quotes, using interpolation, and bypass String.new. But then we wouldn’t have such a vivid name-clash example!)
In addition to constants and local, instance, and global variables, Ruby also features class variables, a category of identifier with some idiosyncratic scoping rules.
5.2.5. Class variable syntax, scope, and visibility
Class variables begin with two at signs—for example, @@var. Despite their name, class variables aren’t class scoped. Rather, they’re class-hierarchy scoped, except...sometimes. Don’t worry; we’ll go through the details. After a look at how class variables work, we’ll evaluate how well they fill the role of maintaining state for a class.
Class variables across classes and instances
At its simplest, the idea behind a class variable is that it provides a storage mechanism that’s shared between a class and instances of that class, and that’s not visible to any other objects. No other entity can fill this role. Local variables don’t survive the scope change between class definitions and their inner method definitions. Globals do, but they’re also visible and mutable everywhere else in the program, not just in one class. Constants likewise: instance methods can see the constants defined in the class in which they’re defined, but the rest of the program can see those constants, too. Instance variables, of course, are visible strictly per object. A class isn’t the same object as any of its instances, and no two of its instances are the same as each other. Therefore it’s impossible, by definition, for a class to share instance variables with its instances.
So class variables have a niche to fill: visibility to a class and its instances, and to no one else. Typically, this means being visible in class-method definitions and instance-method definitions, and sometimes at the top level of the class definition.
Here’s an example: a little tracker for cars. Let’s start with a trial run and the output; then, we’ll look at how the program works. Let’s say we want to register the makes (manufacturer names) of cars, which we’ll do using the class method Car.add_make(make). Once a make has been registered, we can create cars of that make, using Car.new(make). We’ll register Honda and Ford, and create two Hondas and one Ford:
Car.add_make("Honda")
Car.add_make("Ford")
h = Car.new("Honda")
f = Car.new("Ford")
h2 = Car.new("Honda")
The program tells us which cars are being created:
Creating a new Honda!
Creating a new Ford!
Creating a new Honda!
At this point, we can get back some information. How many cars are there of the same make as h2? We’ll use the instance method make_mates to find out, interpolating the result into a string:
puts "Counting cars of same make as h2..."
puts "There are #{h2.make_mates}."
As expected, there are two cars of the same make as h2 (namely, Honda).
How many cars are there altogether? Knowledge of this kind resides in the class, not in the individual cars, so we ask the class:
puts "Counting total cars..."
puts "There are #{Car.total_count}."
The output is
Counting total cars...
There are 3.
Finally, we try to create a car of a nonexistent make:
x = Car.new("Brand X")
The program doesn’t like it, and we get a fatal error:
car.rb:21:in `initialize': No such make: Brand X. (RuntimeError)
The main action here is in the creation of cars and the ability of both individual cars and the Car class to store and return statistics about the cars that have been created. The next listing shows the program. If you save this listing and then add the previous sample code to the end of the file, you can run the whole file and see the output of the code.
Listing 5.6. Keeping track of car manufacturing statistics with class variables

The key to the program is the presence of the three class variables defined at the top of the class definition ![]() . @@makes is an array and stores the names of makes. @@cars is a hash: a keyed structure whose keys are makes of cars and whose corresponding values are counts of how many of each make there are. Finally, @@total_count is a running tally of how many cars have been created overall.
. @@makes is an array and stores the names of makes. @@cars is a hash: a keyed structure whose keys are makes of cars and whose corresponding values are counts of how many of each make there are. Finally, @@total_count is a running tally of how many cars have been created overall.
The Car class also has a make reader attribute ![]() , which enables us to ask every car what its make is. The value of the make attribute must be set when the car is created. There’s no writer attribute for makes of cars, because we don’t want code outside the class changing the makes of cars that already exist.
, which enables us to ask every car what its make is. The value of the make attribute must be set when the car is created. There’s no writer attribute for makes of cars, because we don’t want code outside the class changing the makes of cars that already exist.
To provide access to the @@total_count class variable, the Car class defines a total_count method ![]() , which returns the current value of the class variable. There’s also a class method called add_make
, which returns the current value of the class variable. There’s also a class method called add_make ![]() ; this method takes a single argument and adds it to the array of known makes of cars, using the << array-append operator. It first takes the precaution of making sure the array of makes doesn’t already include this particular make. Assuming all is well, it adds the make and also sets the counter for this make’s car tally to zero. Thus when we register the make Honda, we also establish the fact that zero Hondas exist.
; this method takes a single argument and adds it to the array of known makes of cars, using the << array-append operator. It first takes the precaution of making sure the array of makes doesn’t already include this particular make. Assuming all is well, it adds the make and also sets the counter for this make’s car tally to zero. Thus when we register the make Honda, we also establish the fact that zero Hondas exist.
Now we get to the initialize method, where new cars are created. Each new car needs a make. If the make doesn’t exist (that is, if it isn’t in the @@makes array), then we raise a fatal error ![]() . If the make does exist, then we set this car’s make attribute to the appropriate value
. If the make does exist, then we set this car’s make attribute to the appropriate value ![]() , increment by one the number of cars of this make that are recorded in the @@cars hash
, increment by one the number of cars of this make that are recorded in the @@cars hash ![]() , and also increment by one the total number of existing cars stored in @@total_count. (You may have surmised that @@total_count represents the total of all the values in @@cars. Storing the total separately saves us the trouble of adding up all the values every time we want to see the total.) There’s also an implementation of the instance method make_mates
, and also increment by one the total number of existing cars stored in @@total_count. (You may have surmised that @@total_count represents the total of all the values in @@cars. Storing the total separately saves us the trouble of adding up all the values every time we want to see the total.) There’s also an implementation of the instance method make_mates ![]() , which returns a list of all cars of a given car’s make.
, which returns a list of all cars of a given car’s make.
The initialize method makes heavy use of the class variables defined at the top, outer level of the class definition—a totally different local scope from the inside of initialize, but not different for purposes of class-variable visibility. Those class variables were also used in the class methodsCar.total_count and Car.add_make—each of which also has its own local scope. You can see that class variables follow their own rules: their visibility and scope don’t line up with those of local variables, and they cut across multiple values of self. (Remember that at the outer level of a class definition and inside the class methods, self is the class object—Car—whereas in the instance methods, self is the instance of Car that’s calling the method.)
So far, you’ve seen the simplest aspects of class variables. Even at this level, opinions differ as to whether, or at least how often, it’s a good idea to create variables that cut this path across multiple self objects. Does the fact that a car is an instance of Car really mean that the car object and theCar class object need to share data? Or should they be treated throughout like the two separate objects they are?
There’s no single (or simple) answer. But there’s a little more to how class variables work; and at the very least, you’ll probably conclude that they should be handled with care.
Class variables and the class hierarchy
As noted earlier, class variables aren’t class-scoped variables. They’re class-hierarchy-scoped variables.
Here’s an example. What would you expect the following code to print?
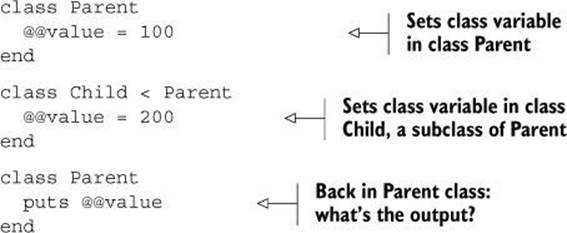
What gets printed is 200. The Child class is a subclass of Parent, and that means Parent and Child share the same class variables—not different class variables with the same names, but the same actual variables. When you assign to @@value in Child, you’re setting the one and only @@valuevariable that’s shared throughout the hierarchy—that is, by Parent and Child and any other descendant classes of either of them. The term class variable becomes a bit difficult to reconcile with the fact that two (and potentially a lot more) classes share exactly the same ones.
As promised, we’ll end this section with a consideration of the pros and cons of using class variables as a way to maintain state in a class.
Evaluating the pros and cons of class variables
The bread-and-butter way to maintain state in an object is the instance variable. Class variables come in handy because they break down the dam between a class object and instances of that class. But by so doing, and especially because of their hierarchy-based scope, they take on a kind of quasi-global quality: a class variable isn’t global, but it sure is visible to a lot of objects, once you add up all the subclasses and all the instances of those subclasses.
The issue at hand is that it’s useful to have a way to maintain state in a class. You saw this even in the simple Car class example. We wanted somewhere to stash class-relevant information, like the makes of cars and the total number of cars manufactured. We also wanted to get at that information, both from class methods and from instance methods. Class variables are popular because they’re the easiest way to distribute data in that configuration.
But they’re also leaky. Too many objects can get hold of them. Let’s say we wanted to create a subclass of Car called Hybrid to keep a count of manufactured (partly) electric vehicles. We couldn’t do this:
class Hybrid < Car
end
hy = Hybrid.new("Honda")
puts "There are #{Hybrid.total_count} hybrids in existence!"
because Hybrid.total_count is the same method as Car.total_count, and it wraps the same variable. Class variables aren’t reissued freshly for every subclass, the way instance variables are for every object.
To track hybrids separately, we’d have to do something like this:
class Hybrid < Car
@@total_hybrid_count = 0
# etc.
end
Although there are ways to abstract and semi-automate this kind of splitting out of code by class namespace, it’s not the easiest or most transparent technique in the world.
What’s the alternative?
Maintaining per-class state with instance variables of class objects
The alternative is to go back to basics. We need a slot where we can put a value (the total count), and it should be a different slot for every class. In other words, we need to maintain state on a per-class basis; and because classes are objects, that means on a per-object basis (for a certain group of objects, namely, class objects). And per-object state, whether the object in question is a class or something else, suggests instance variables.
The following listing shows a rewrite of the Car class in listing 5.6. Two of the class variables are still there, but @@total_count has been transformed into an instance variable.
Listing 5.7. Car with @@total_count replaced by instance variable @total_count

The key here is storing the counter in an instance variable belonging to the class object Car, and wrapping that instance variable in accessor methods—manually written ones, but accessor methods nonetheless. The accessor methods are Car.total_count and Car.total_count=. The first of these performs the task of initializing @total_count to zero ![]() . It does the initialization conditionally, using the or-equals operator, so that on the second and subsequent calls to total_count, the value of the instance variable is simply returned.
. It does the initialization conditionally, using the or-equals operator, so that on the second and subsequent calls to total_count, the value of the instance variable is simply returned.
The total_count= method is an attribute-writer method, likewise written as a class method so that the object whose instance variable is in use is the class object ![]() . With these methods in place, we can now increment the total count from inside the instance method initialize by callingself.class.total_count=
. With these methods in place, we can now increment the total count from inside the instance method initialize by callingself.class.total_count= ![]() .
.
The payoff comes when we subclass Car. Let’s have another look at Hybrid and some sample code that uses it:
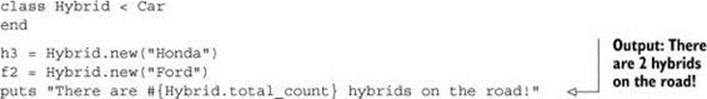
Hybrid is a new class object. It isn’t the same object as Car. Therefore, it has its own instance variables. When we create a new Hybrid instance, the initialize method from Car is executed. But this time, the expression
self.class.total_count += 1
has a different meaning. The receiver of the “total_count=” message is Hybrid, not Car. That means when the total_count= class method is executed, the instance variable @total_count belongs to Hybrid. (Instance variables always belong to self.) Adding to Hybrid’s total count therefore won’t affect Car’s total count.
We’ve made it so that a subclass of Car can maintain its own state, because we’ve shifted from a class variable to an instance variable. Every time total_count or total_count= is called, the @total_count to which it refers is the one belonging to self at that point in execution. Once again, we’re back in business using instance variables to maintain state per object (class objects, in this case).
The biggest obstacle to understanding these examples is understanding the fact that classes are objects—and that every object, whether it’s a car, a person, or a class, gets to have its own stash of instance variables. Car and Hybrid can keep track of manufacturing numbers separately, thanks to the way instance variables are quarantined per object.
We’ve reached the limit of our identifier scope journey. You’ve seen much of what variables and constants can do (and what they can’t do) and how these abilities are pegged to the rules governing scope and self. In the interest of fulfilling the chapter’s goal of showing you how to orient yourself regarding who gets to do what, and where, in Ruby code, we’ll look at one more major subtopic: Ruby’s system of method-access rules.
5.3. Deploying method-access rules
As you’ve seen, the main business of a Ruby program is to send messages to objects. And the main business of an object is to respond to messages. Sometimes, an object wants to be able to send itself messages that it doesn’t want anyone else to be able to send it. For this scenario, Ruby provides the ability to make a method private.
There are two access levels other than private: protected, which is a slight variation on private, and public. Public is the default access level; if you don’t specify that a method is protected or private, it’s public. Public instance methods are the common currency of Ruby programming. Most of the messages you send to objects are calling public methods.
We’ll focus here on methods that aren’t public, starting with private methods.
5.3.1. Private methods
Think of an object as someone you ask to perform a task for you. Let’s say you ask someone to bake you a cake. In the course of baking you a cake, the baker will presumably perform a lot of small tasks: measure sugar, crack an egg, stir batter, and so forth.
The baker does all these things, but not all of them have equal status when it comes to what the baker is willing to do in response to requests from other people. It would be weird if you called a baker and said, “Please stir some batter” or “Please crack an egg.” What you say is “Please bake me a cake,” and you let the baker deal with the details.
Let’s model the baking scenario. We’ll use minimal, placeholder classes for some of the objects in our domain, but we’ll develop the Baker class in more detail.
Save the code in the following listing to a file called baker.rb.
Listing 5.8. Baker and other baking-domain classes

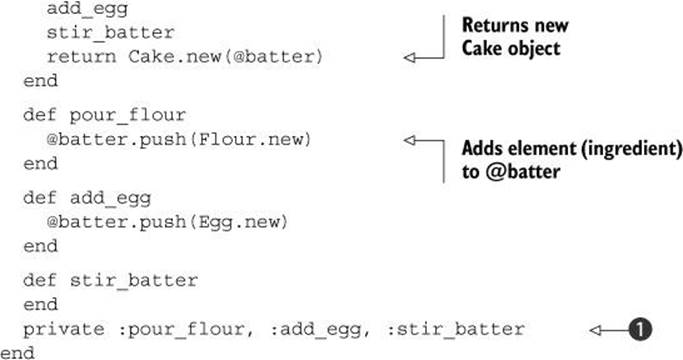
There’s something new in this code: the private method ![]() , which takes as arguments a list of the methods you want to make private. (If you don’t supply any arguments, the call to private acts like an on switch: all the instance methods you define below it, until you reverse the effect by calling public or protected, will be private.)
, which takes as arguments a list of the methods you want to make private. (If you don’t supply any arguments, the call to private acts like an on switch: all the instance methods you define below it, until you reverse the effect by calling public or protected, will be private.)
Private means that the method can’t be called with an explicit receiver. You can’t say
b = Baker.new
b.add_egg
As you’ll see if you try it, calling add_egg this way results in a fatal error:
`<main>': private method `add_egg' called for #<Baker:0x00000002aeae50> (NoMethodError)
add_egg is a private method, but you’ve specified the receiving object, b, explicitly. That’s not allowed.
Okay; let’s go along with the rules. We won’t specify a receiver. We’ll just say
add_egg
But wait. Can we call add_egg in isolation? Where will the message go? How can a method be called if there’s no object handling the message?
A little detective work will answer this question.
If you don’t use an explicit receiver for a method call, Ruby assumes that you want to send the message to the current object, self. Thinking logically, you can conclude that the message add_egg has an object to go to only if self is an object that responds to add_egg. In other words, you can only call the add_egg instance method of Baker when self is an instance of Baker.
And when is self an instance of Baker?
When any instance method of Baker is being executed. Inside the definition of bake_cake, for example, you can call add_egg, and Ruby will know what to do. Whenever Ruby hits that call to add_egg inside that method definition, it sends the message add_egg to self, and self is a Baker object.
Private and singleton are different
It’s important to note the difference between a private method and a singleton method. A singleton method is “private” in the loose, informal sense that it belongs to only one object, but it isn’t private in the technical sense. (You can make a singleton method private, but by default it isn’t.) A private, non-singleton instance method, on the other hand, may be shared by any number of objects but can only be called under the right circumstances. What determines whether you can call a private method isn’t the object you’re sending the message to, but which object is self at the time you send the message.
It comes down to this: by tagging add_egg as private, you’re saying the Baker object gets to send this message to itself (the baker can tell himself or herself to add an egg to the batter), but no one else can send the message to the baker (you, as an outsider, can’t tell the baker to add an egg to the batter). Ruby enforces this privacy through the mechanism of forbidding an explicit receiver. And the only circumstances under which you can omit the receiver are precisely the circumstances in which it’s okay to call a private method.
It’s all elegantly engineered. There’s one small fly in the ointment, though.
Private setter (=) methods
The implementation of private access through the “no explicit receiver” rule runs into a hitch when it comes to methods that end with equal signs. As you’ll recall, when you call a setter method, you have to specify the receiver. You can’t do this
dog_years = age * 7
because Ruby will think that dog_years is a local variable. You have to do this:
self.dog_years = age * 7
But the need for an explicit receiver makes it hard to declare the method dog_years= private, at least by the logic of the “no explicit receiver” requirement for calling private methods.
The way out of this conundrum is that Ruby doesn’t apply the rule to setter methods. If you declare dog_years= private, you can call it with a receiver—as long as the receiver is self. It can’t be another reference to self; it has to be the keyword self.
Here’s an implementation of a dog-years-aware Dog:
class Dog
attr_reader :age, :dog_years
def dog_years=(years)
@dog_years = years
end
def age=(years)
@age = years
self.dog_years = years * 7
end
private :dog_years=
end
You indicate how old a dog is, and the dog automatically knows its age in dog years:
![]()
The setter method age= performs the service of setting the dog years, which it does by calling the private method dog_years=. In doing so, it uses the explicit receiver self. If you do it any other way, it won’t work. With no receiver, you’d be setting a local variable. And if you use the same object, but under a different name, like this
def age=(years)
@age = years
dog = self
dog.dog_years = years * 7
end
execution is halted by a fatal error:
NoMethodError: private method 'dog_years=' called for
#<Dog:0x00000101b0d1a8 @age=10>
Ruby’s policy is that it’s okay to use an explicit receiver for private setter methods, but you have to thread the needle by making sure the receiver is exactly self.
The third method-access level, along with public and private, is protected.
5.3.2. Protected methods
A protected method is like a slightly kinder, gentler private method. The rule for protected methods is as follows: you can call a protected method on an object x, as long as the default object (self) is an instance of the same class as x or of an ancestor or descendant class of x’s class.
This rule sounds convoluted. But it’s generally used for a particular reason: you want one instance of a certain class to do something with another instance of its class. The following listing shows such a case.
Listing 5.9. Example of a protected method and its use

The goal in this listing is to compare one C instance with another C instance. The comparison depends on the result of a call to the method n. The object doing the comparing (c1, in the example) has to ask the other object (c2) to execute its n method. Therefore, n can’t be private.
That’s where the protected level comes in. With n protected rather than private, c1 can ask c2 to execute n, because c1 and c2 are both instances of the same class. But if you try to call the n method of a C object when self is anything other than an instance of C (or of one of C’s ancestors or descendants), the method fails.
A protected method is thus like a private method, but with an exemption for cases where the class of self (c1) and the class of the object having the method called on it (c2) are the same or related by inheritance.
Inheritance and method access
Subclasses inherit the method-access rules of their superclasses. Given a class C with a set of access rules, and a class D that’s a subclass of C, instances of D exhibit the same access behavior as instances of C. But you can set up new rules inside the class definition of D, in which case the new rules take precedence for instances of D over the rules inherited from C.
The last topic we’ll cover in this chapter is top-level methods. As you’ll see, top-level methods enjoy a special case status. But even this status meshes logically with the aspects of Ruby’s design you’ve encountered in this chapter.
5.4. Writing and using top-level methods
The most natural thing to do with Ruby is to design classes and modules and instantiate your classes. But sometimes you just want to write a quick script—a few commands stuffed in a file and executed. It’s sometimes more convenient to write method definitions at the top level of your script and then call them on top-level objects than to wrap everything in class definitions. When you do this, you’re coding in the context of the top-level default object, main, which is an instance of Object brought into being automatically for the sole reason that something has to be self, even at the top level.
But you’re not inside a class or module definition, so what exactly happens when you define a method?
5.4.1. Defining a top-level method
Suppose you define a method at the top level:
def talk
puts "Hello"
end
It’s not inside a class- or module-definition block, so it doesn’t appear to be an instance method of a class or module. So what is it?
A method that you define at the top level is stored as a private instance method of the Object class. The previous code is equivalent to this:
class Object
private
def talk
puts "Hello"
end
end
Defining private instance methods of Object has some interesting implications.
First, these methods not only can but must be called in bareword style. Why? Because they’re private. You can only call them on self, and only without an explicit receiver (with the usual exemption of private setter methods, which must be called with self as the receiver).
Second, private instance methods of Object can be called from anywhere in your code, because Object lies in the method lookup path of every class (except Basic-Object, but that’s too special a case to worry about). So a top-level method is always available. No matter what self is, it will be able to recognize the message you send it if that message resolves to a private instance method of Object.
To illustrate, let’s extend the talk example. Here it is again, with some code that exercises it:

The first call to talk succeeds ![]() ; the second fails with a fatal error
; the second fails with a fatal error ![]() , because it tries to call a private method with an explicit receiver.
, because it tries to call a private method with an explicit receiver.
What’s nice about the way top-level methods work is that they provide a useful functionality (simple, script-friendly, procedural-style bareword commands), but they do so in complete conformity with the rules of Ruby: private methods have to default to self as the receiver, and methods defined in Object are visible to all objects. No extra language-level constructs are involved, just an elegant and powerful combination of the ones that already exist.
The rules concerning definition and use of top-level methods bring us all the way back to some of the bareword methods we’ve been using since as early as chapter 1. You’re now in a position to understand how those methods work.
5.4.2. Predefined (built-in) top-level methods
From our earliest examples onward, we’ve been making bareword-style calls to puts and print, like this one:
puts "Hello"
puts and print are built-in private instance methods of Kernel—not, like the ones you write, of Object, but of Kernel. The upshot is similar, though (because Object mixes in Kernel): you can call such methods at any time, and you must call them without a receiver. The Kernel module thus provides a substantial toolkit of imperative methods, like puts and print, that increases the power of Ruby as a scripting language. You can get a lot done with Ruby scripts that don’t have any class, module, or method definitions, because you can do so much (read and write, run system commands, exit your program, and so on) with Ruby’s top-level methods.
If you want to see all of the private instance methods that Kernel provides, try this:
$ ruby -e 'p Kernel.private_instance_methods.sort'
The private_instance_methods method gives you an array of all the relevant methods, and sort sorts the array of method names for easier reading. As you can see, these methods, although often useful in imperative, script-style programming, aren’t restricted in their usefulness to that style; they include commands like require, load, raise (raise an exception), and others, that are among the most common techniques in all Ruby programs, whatever style of program design they exhibit.
5.5. Summary
This chapter covered
· The rotating role of self (the current or default object)
· Self as the receiver for method calls with no explicit receiver
· Self as the owner of instance variables
· Implications of the “classes are objects too” rule
· Variable scope and visibility for local, global, and class variables
· The rules for looking up and referencing constants
· Ruby’s method-access levels (public, private, protected)
· Writing and working with top-level method definitions
The techniques in this chapter are of great importance to Ruby. Concepts like the difference between instance variables in a class definition and instance variables in an instance-method definition are crucial. It’s easy to look at a Ruby program and get a general sense of what’s going on. But to understand a program in depth—and to write well-organized, robust programs—you need to know how to detect where the various local scopes begin and end; how constants, instance variables, and other identifiers are resolved; and how to evaluate the impact of the ever-shifting role of self.
This chapter has shown you how to get your bearings in a Ruby program. It’s also shown you some techniques you can use more accurately and effectively in your code by virtue of having your bearings. But there’s more to explore, relating to what you can do in the landscape of a program, beyond understanding it. The next chapter, on the subject of control flow, will address some of these techniques.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.