Programming Google App Engine with Python (2015)
Chapter 8. Datastore Transactions
With web applications, many users access and update data concurrently. Often, multiple users need to read or write to the same unit of data at the same time. This requires a data system that can give some assurances that simultaneous operations will not corrupt any user’s view of the data. Most data systems guarantee that a single operation on a single unit of data maintains the integrity of that unit, typically by scheduling operations that act on the unit to be performed in a sequence, one at a time.
Many applications need similar data integrity guarantees when performing a set of multiple operations, possibly over multiple units of data. Such a set of operations is called a transaction. A data system that supports transactions guarantees that if a transaction succeeds, all the operations in the transaction are executed completely. If any step of the transaction fails, then none of its effects are applied to the data. The data remains in a consistent and predictable state before and after the transaction, even if other processes are attempting to modify the data concurrently.
For example, say you want to post a message to the bulletin board in the town square inviting other players to join your guild. The bulletin board maintains a count of how many messages have been posted to the board, so readers can see how many messages there are without reading every message object in the system. Posting a message requires three datastore operations:
1. Read the old message count
2. Update the message count with an incremented value
3. Create the new message object
Without transactions, these operations may succeed or fail independently. The count may be updated but the message object may not be created. Or, if you create the message object first, the object may be created, but the count not updated. In either case, the resulting count is inaccurate. By performing these operations in a single transaction, if any step fails, none of the effects are applied, and the application can try the entire transaction again.
Also consider what happens when two players attempt to post to the message board at the same time. To increment the message count, each player process must read the old value, and then update it with a new value calculated from the old one. Without transactions, these operations may be interleaved:
1. Process A reads the original count (say, 10).
2. Process B reads the count (also 10).
3. Process A adds 1 and updates the count with the new value (11).
4. Process B adds 1 to its value and updates the count (11).
Because Process B doesn’t know that Process A updated the value, the final count is 1 less than it ought to be (12). With transactions, Process B knows right away that another process is updating the data and can do the right thing.
A scalable web application has several requirements that are at odds with transactions. For one, the application needs access to data to be fast, and to not be affected by how much data is in the system or how it is distributed across multiple servers. The longer it takes for a transaction to complete, the longer other processes have to wait to access the data reserved by the transaction. The combined effect on how many transactions can be completed in a period of time is called throughput. For web apps, high throughput is important.
A web app usually needs transactions to finish completely and consistently, so it knows that the effects of the transaction can be relied upon by other processes for further calculations. The transaction is complete when it is committed, replicated to multiple machines, and ready to be served to any process that asks for it. The promise that all processes can see the changes once a transaction is complete is known as strong consistency.
An alternative policy known as eventual consistency trades this promise for greater flexibility in how changes are applied. With strong consistency, if a process wants to read a value, but a change for that value has been committed to the datastore and not yet ready, the process waits until the save is complete, then reads the value. But if the process doesn’t need the latest value, it can read the older value without waiting. Consistency is eventual because the impatient processes are not guaranteed to see the latest value, but will see it after the value is ready.
Cloud Datastore provides transactions with strong consistency and low overhead. It does this by limiting the scope of transactions: a single transaction can only read or write to entities that belong to a single entity group. Every entity belongs to an entity group, by default a group of its own. The app assigns an entity to a group when the entity is created, and the assignment is permanent.
By having the app arrange entities into groups, Cloud Datastore can treat each group independently when applying concurrent transactions. Two transactions that use different groups can occur simultaneously without harm. With a bit of thought, an app can ensure that entities are arranged to minimize the likelihood that two processes will need to access the same group, and thereby maximize throughput.
Entity groups also come into play with queries and indexes. If a query only needs results from a single entity group, the query can return strongly consistent results, as the group’s local index data is updated transactionally with the group’s entities. The query requests this behavior by identifying the group as part of the query, using a part of the key path, or ancestor. (We’re finally going to explain what key paths are: they form entity groups by arranging keys in a hierarchy.)
Whereas ancestor queries are strongly consistent, queries across all entity groups are eventually consistent: global kind-based indexes are not guaranteed to be up-to-date by the time changes to entities are ready. This makes ancestor queries—and good entity group design in general—a powerful weapon in your datastore arsenal.
An app can request more flexible behaviors, with their corresponding trade-offs. Cross-group transactions (sometimes called “XG transactions”) can act on up to five entity groups, in exchange for added latency and a greater risk of contention with other processes. An app can specify a read policy when reading data, which can request a faster eventually consistent read instead of a strongly consistent read that may have to wait on pending updates.
In this chapter, we discuss what happens when you update an entity group, how to create entities in entity groups, how to perform ancestor queries, and how to perform multiple operations on an entity group, using a transaction. We also discuss batch operations, how query indexes are built, and the consistency guarantees of Cloud Datastore.
Entities and Entity Groups
When you create, update, or delete a single entity, the change occurs in a transaction: either all your changes to the entity succeed, or none of them do. If you change two properties of an entity and save it, every request handler process that fetches the entity will see both changes. At no point during the save will a process see the new value for one property and the old value for the other. And if the update fails, the entity stays as it was before the save. In database terms, the act of updating an entity is atomic.
It is often useful to update multiple entities atomically, such that any process’s view of the data is consistent across the entities. In the bulletin board example, the message count and each of the messages may be stored as separate entities, but the combined act of creating a new message entity and updating the count ought to be atomic. We need a way to combine multiple actions into a single transaction, so they all succeed or all fail.
To do this in a scalable way, Cloud Datastore must know in advance which entities may be involved in a single transaction. These entities are stored and updated together, so the datastore can keep them consistent and still access them quickly. You tell Cloud Datastore which entities may be involved in the same transaction by using entity groups.
Every entity belongs to an entity group, possibly a group containing just itself. An entity can only belong to one group. You assign an entity to a group when the entity is created. Group membership is permanent; an entity cannot be moved to another group once it has been created.
The datastore uses entity groups to determine what happens when two processes attempt to update data in the entity group at the same time. When this happens, the first update that completes “wins,” and the other update is canceled. App Engine notifies the process whose update is canceled by raising an exception. In most cases, the process can just try the update again and succeed. But the app must decide for itself how to go about retrying, as important data may have changed between attempts.
This style of managing concurrent access is known as optimistic concurrency control. It’s “optimistic” in the sense that the database tries to perform the operations without checking whether another process is working with the same data (such as with a “locking” mechanism), and only checks for collisions at the end, optimistic that the operations will succeed. The update is not guaranteed to succeed, and the app must reattempt the operations or take some other course of action if the data changes during the update.
Multiple processes vying for the opportunity to write to an entity group at the same time is known as contention. Two processes are contending for the write; the first to commit wins. A high rate of contention slows down your app, because it means many processes are getting their writes canceled and have to retry, possibly multiple times. In egregious cases, contention for a group may exclude a process to the point of the failure of that process. You can avoid high rates of contention with careful design of your entity groups.
Optimistic concurrency control is a good choice for web applications because reading data is fast—a typical reader never waits for updates—and almost always succeeds. If an update fails due to contention, it’s usually easy to try again, or return an error message to the user. Most web applications have only a small number of users updating the same piece of data, so contention failures are rare.
TIP
Updating an entity in a group can potentially cancel updates to any other entity in the group by another process. You should design your data model so that entity groups do not need to be updated by many users simultaneously.
Be especially careful if the number of simultaneous updates to a single group grows as your application gets more users. In this case, you usually want to spread the load across multiple entity groups, and increase the number of entity groups automatically as the user base grows. Scalable division of a data resource like this is known as sharding.
Also be aware that some data modeling tasks may not be practical on a large scale. Incrementing a value in a single datastore entity every time any user visits the site’s home page is not likely to work well with a distributed strong consistency data system.
Keys, Paths, and Ancestors
To create an entity in a group with other entities, you associate it with the key of another entity from that group. One way to do this is to make the existing entity’s key the parent of the new entity. The key of the parent becomes part of the key of the child. These parent–child relationships form a path of ancestors down to a root entity that does not have a parent. Every entity whose key begins with the same root is in the same group, including the root entity itself.
When you create an entity and do not specify a parent, the entity is created in a new group by itself. The new entity is the root of the new group.
We alluded to paths earlier when we discussed keys, so let’s complete the picture. An entity’s key consists of the path of ancestors in the entity’s group, starting from the group’s root. Each entity in the path is represented by the entity’s kind followed by either the system-assigned numeric ID or the app-assigned string ID. The full path is a sequence of kind and ID pairs.
The following keys represent entities in the same group, because they all have the same root ancestor:
MessageBoard, "The_Archonville_Times"
MessageBoard, "The_Archonville_Times" / Message, "first!"
MessageBoard, "The_Archonville_Times" / Message, "pk_fest_aug_21"
MessageBoard, "The_Archonville_Times" / Message, "first!" / Message, "keep_clean"
With Python and ndb, there are two ways to make keys with ancestors. The first is to provide the parent argument to the ndb.Key constructor, whose value is another ndb.Key:
board_key = ndb.Key(MessageBoard, 'The_Archonville_Times')
board = board_key.get()
msg1_key = ndb.Key(Message, 'first!', parent=board_key)
msg1 = Message(key=msg1_key)
msg1.put()
Alternatively, the ndb.Key constructor can take positional arguments representing the kinds and IDs along the path:
msg2_key = ndb.Key(MessageBoard, 'The_Archonville_Times',
Message, 'pk_fest_aug_21')
msg2 = Message(key=msg2_key)
msg2.put()
The final kind in the ancestor path is the kind of the entity. In ndb, this must match the model class name. You can use the class object directly (as we’ve done here) or the string name of the class ('Message').
As a shortcut, the model class constructor can accept a parent key and an id instead of a complete key:
msg3 = Message(parent=msg1.key(), id='keep_clean')
msg3.put()
GQL supports key literals with ancestors, as follows:
SELECT * FROM MessageAttachment
WHERE message = KEY(MessageBoard, 'The_Archonville_Times',
Message, 'first!',
Message, 'keep_clean')
Notice that entities of different kinds can be in the same entity group. In the datastore, there is no relationship between kinds and entity groups. (You can enforce such a relationship in your app’s code, if you like.)
Ancestors do not have to exist for a key to be valid. If you create an entity with a parent and then delete the parent, the key for the child is still valid and can still be assembled from its parts (such as with strings in the ndb.Key constructor). This is true even for a group’s root entity: the root can be deleted and other entities in the group remain in the group.
You can even use a made-up key for an entity that doesn’t exist as the parent for a new entity. Neither the kind nor the ID of an ancestor needs to represent an actual entity. Group membership is defined by the first key part in the ancestor path, regardless of whether that part corresponds to an entity. Here is Python code that creates two entities in the same group without a root entity:
root = ndb.Key('MessageBoard', 'The_Baskinville_Post')
msg1 = Message(parent=root)
msg1.put()
msg2 = Message(parent=root)
msg2.put()
After being saved with put(), the datastore assigns numeric IDs to these Message entities, and their complete keys resemble the following:
MessageBoard, "The_Baskinville_Post" / Message, 1
MessageBoard, "The_Baskinville_Post" / Message, 2
Ancestor Queries
The root ancestor in a key path determines group membership. Intermediate ancestors have no affect on group membership, which poses the question, what good are ancestor paths? One possible answer to that question: ancestor queries.
A datastore query can include a filter that limits the results to just those entities with a given ancestor. This can match any ancestor, not just the immediate parent. In other words, a query can match a sequence of key parts starting from the root.
Continuing the town square bulletin board example, where each MessageBoard is the root of an entity group containing things attached to the board, the following GQL query returns the 10 most recent Message entities attached to a specific board:
SELECT * FROM Message
WHERE ANCESTOR IS KEY(MessageBoard,
'The_Archonville_Times')
ORDER BY post_date DESC
LIMIT 10
Most queries that use an ancestor filter need custom indexes. There is one unusual exception: a query does not need a custom index if the query also contains equality filters on properties (and no inequality filters or sort orders). In this exceptional case, the “merge join” algorithm can use a built-in index of keys along with the built-in property indexes. In cases where the query would need a custom index anyway, the query can match the ancestor to the keys in the custom index.
With ndb, you can set the ancestor for a query by passing an ndb.Key value as the ancestor parameter to the ndb.Query() constructor or the query() model class method:
q = Message.query(
ancestor=ndb.Key(MessageBoard, 'The_Archonville_Times'))
q = q.order('-post_date')
# ...
As we mentioned in Chapter 7, the datastore supports queries over entities of all kinds. Kindless queries are limited to key filters and ancestor filters. Because ancestors can have children of disparate kinds, kindless queries are useful for getting every child of a given ancestor, regardless of kind:
SELECT * WHERE ANCESTOR IS KEY('MessageBoard', 'The_Archonville_Times')
A kindless ancestor query in Python:
q = ndb.Query(
ancestor=ndb.Key('MessageBoard', 'The_Archonville_Times'))
TIP
Although ancestor queries can be useful, don’t get carried away building large ancestor trees. Remember that every entity with the same root belongs to the same entity group, and more simultaneous users that need to write to a group mean a greater likelihood of concurrency failures.
If you want to model hierarchical relationships between entities without the consequences of entity groups, consider using multivalued properties to store paths. For example, if there’s an entity whose path in your hierarchy can be represented as /A/B/C/D, you can store this path as e.parents = ['/A', '/A/B', '/A/B/C']. Then you can perform a query similar to an ancestor query on this property: … WHERE parents = '/A/B'.
What Can Happen in a Transaction
Entity groups ensure that the operations performed within a transaction see a consistent view of the entities in a group. For this to work, a single transaction must limit its operations to entities in a single group. The entity group determines the scope of the transaction.
Within a transaction, you can fetch, update, or delete an entity by using the entity’s key. You can create a new entity that either is a root entity of a new group that becomes the subject of the transaction, or that has a member of the transaction’s entity group as its parent. You can also create other entities in the same group.
You can perform queries over the entities of a single entity group in a transaction. A query in a transaction must have an ancestor filter that matches the transaction’s entity group. The results of the query, including both the indexes that provide the results as well as the entities themselves, are guaranteed to be consistent with the rest of the transaction.
You do not need to declare the entity group for a transaction explicitly. You simply perform datastore actions on entities of the same group. If you attempt to perform actions that involve different entity groups within a transaction, the API raises an exception. The API also raises an exception if you attempt to perform a query in a transaction that does not have an ancestor filter.
Transactions have a maximum size. A single transaction can write up to 10 megabytes of data.
Transactional Reads
Sometimes it is useful to fetch entities in a transaction even if the transaction does not update any data. Reading multiple entities in a transaction ensures that the entities are consistent with one another. As with updates, entities fetched in a transaction must be members of the same entity group.
A transaction that only reads entities never fails due to contention. As with reading a single entity, a read-only transaction sees the data as it appears at the beginning of the transaction, even if other processes make changes after the transaction starts and before it completes.
The same is true for ancestor-only queries within a transaction. If the transaction does not create, update, or delete data from the entity group, it will not fail due to contention.
The datastore can do this because it remembers previous versions of entities, using timestamps associated with the entity groups. The datastore notes the current time at the beginning of every operation and transaction, and this determines which version of the data the operation or transaction sees. This is known as multiversion concurrency control, a form of optimistic concurrency control. This mechanism is internal to the datastore; the application cannot access previous versions of data, nor can it see the timestamps.
This timestamp mechanism has a minor implication for reading data within transactions. When you read an entity in a transaction, the datastore returns the version of the entity most recent to the beginning of the transaction. If you update an entity and then refetch the same entity within the same transaction, the datastore returns the entity as it appeared before the update. In most cases, you can just reuse the in-memory object you modified (which has your changes) instead of refetching the entity.
Eventually Consistent Reads
As described in the previous section, transactional reads are strongly consistent. When the app fetches an entity by key, the datastore ensures that all changes committed prior to the beginning of the current transaction are complete—and are therefore returned by the read—before continuing. Occasionally, this can involve a slight delay as the datastore catches up with a backlog of committed changes. In a transaction, a strongly consistent read can only read entities within the transaction’s entity group.
Similarly, when the app performs an ancestor query in a transaction, the query uses the group’s local indexes in a strongly consistent fashion. The results of the index scans are guaranteed to be consistent with the contents of the entities returned by the query.
You can opt out of this protection by specifying a read policy that requests eventual consistency. With an eventually consistent read of an entity, your app gets the current known state of the entity being read, regardless of whether there are still committed changes to be applied. With an eventually consistent ancestor query, the indexes used for the query are consistent with the time the indexes are read.
In other words, an eventual consistency read policy causes gets and queries to behave as if they are not a part of the current transaction. This may be faster in some cases, as the operations do not have to wait for committed changes to be written before returning a result.
Perhaps more importantly: an eventually consistent get operation can get an entity outside of the current transaction’s entity group.
Transactions in Python
The Python API uses function objects to handle transactions. To perform multiple operations in a transaction, you define a function that executes the operations by using the @db.transactional() decorator. When you call your function outside of a transaction, the function starts a new transaction, and all datastore operations that occur within the function are expected to comply with the transaction’s requirements:
import datetime
from google.appengine.api import datastore_errors
from google.appengine.ext import ndb
class MessageBoard(ndb.Expando):
pass
class Message(ndb.Expando):
pass
@ndb.transactional()
def create_message_txn(board_name, message_name, message_title, message_text):
board = ndb.Key('MessageBoard', board_name).get()
if notboard:
board = MessageBoard(id=board_name)
board.count = 0
message = Message(id=message_name, parent=board.key)
message.title = message_title
message.text = message_text
message.post_date = datetime.datetime.now()
board.count += 1
ndb.put_multi([board, message])
# ...
try:
create_message_txn(
board_name=board_name,
message_name=message_title,
message_title=message_title,
message_text=message_text)
except datastore_errors.TransactionFailedError, e:
# Report an error to the user.
# ...
All calls to the datastore to create, update, or delete entities within the transaction function take effect when the transaction is committed. Typically, you would update an entity by fetching or creating the model object, modifying it, then saving it, and continue to use the local object to represent the entity. In the rare case where the transaction function fetches an entity after saving it, the fetch will see the entity as it was before the update, because the update has not yet been committed.
If the transaction function raises an exception, the transaction is aborted, and the exception is reraised to the caller. If you need to abort the transaction but do not want the exception raised to the caller (just the function exited), raise the ndb.Rollback exception in the transaction function. This causes the function to abort the transaction, then return None.
If the transaction cannot be completed due to a concurrency failure, the function call is retried automatically. By default, it is retried three times. If all three of these retries fail, the function raises a datastore_errors.TransactionFailedError (from thegoogle.appengine.api.datastore_errors module). You can configure the number of retries by providing the retries argument to the @ndb.transactional decorator:
@ndb.transactional(retries=10)
def create_message_txn(board_name, message_name, message_title, message_text):
# ...
TIP
Make sure your transaction function can be called multiple times safely without undesirable side effects. If this is not possible, you can set retries=0, but know that the transaction will fail on the first incident of contention.
The default behavior of @ndb.transactional functions is to start a new transaction if one isn’t already started, and join the started transaction otherwise. This behavior is controlled by the propagation argument to the decorator, whose value is one of the following:
ndb.TransactionOptions.ALLOWED
This is the default.
ndb.TransactionOptions.MANDATORY
The function expects to be called during an already-started transaction, and throws datastore_errors.BadRequestError if called outside a transaction.
ndb.TransactionOptions.INDEPENDENT
The function always starts a new transaction, pausing an already-started transaction, if any.
If a function should not be run in a transaction, you can isolate it by using the @ndb.non_transactional decorator. By default, calling a nontransactional function within a transaction pauses the transaction and does not start a new one, so datastore operations in the function do not participate in the transaction. If you specify allow_existing=False to the decorator, calling the nontransactional function during a transaction raises datastore_errors.BadRequestError.
Finally, if you have a function that should be called within a transaction by some callers and without a transaction by others, you can use the ndb.transaction() wrapper function. It takes the function to call as its first argument, and optional subsequent arguments like those you would pass to the @ndb.transactional decorator. It calls the function with no arguments, so if you want to call a function that accepts arguments, use a Python lambda expression:
def process_message_text(message_text):
# ... datastore calls ...
# result = ...
return result
@ndb.transactional
def create_message_txn(board_name, message_name, message_title, message_text):
# ...
new_message_text = ndb.transaction(
lambda: process_message_text(message_text))
As an added convenience, you can test whether the code is currently being executed within a transaction by calling ndb.in_transaction().
Within a transaction, reading entities and fetching results from an ancestor query uses a read policy of strong consistency. There’s no reason (or ability) to use another read policy in this case: a transactional read either sees the latest committed state (as with strong consistency) or the transaction fails because the entity group has been updated since the transaction was started.
How Entities Are Updated
To fully understand how the datastore guarantees that your data stays consistent, it’s worth discussing how transactions are performed behind the scenes. To do so, we must mention BigTable, Google’s distributed data system that is the basis of the App Engine datastore. We won’t go into the details of how entities, entity groups, and indexes are stored in BigTable, but we will refer to BigTable’s own notion of atomic transactions in our explanation.
Figure 8-1 shows the phases of a successful transaction.
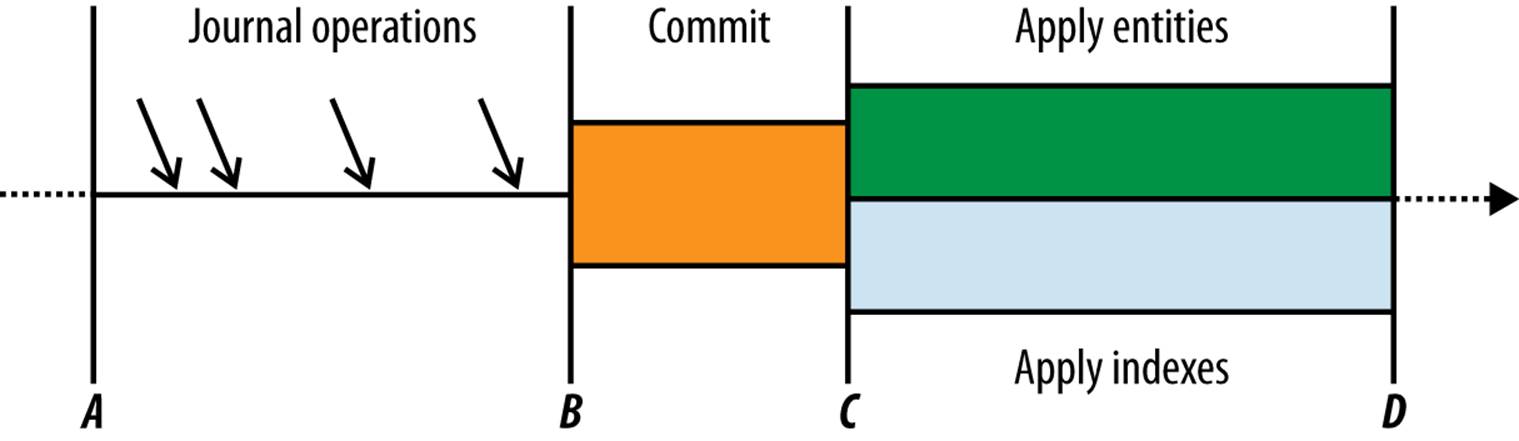
Figure 8-1. The timeline of a transaction: the operations, the commit phase, and the apply phase
The datastore uses a “journal” to keep track of changes that need to be applied to entities in an entity group. Each journal entry has a unique timestamp that indicates the order in which the changes were made. The datastore remembers the timestamp of the most recent change that has been committed, and guarantees that attempts to read the data will see all changes up to that point.
When an app begins a transaction for an entity group, the datastore makes a note of the current last-committed timestamp for the group (point A in Figure 8-1). As the app calls the datastore to update entities, the datastore writes the requested changes to the journal. Each change is marked as “uncommitted.”
When the app finishes the transaction (point B), the datastore checks the group’s last-committed timestamp again. If the timestamp hasn’t changed since the transaction began, it marks all the transaction’s changes as “committed” and then advances the group’s timestamp. Otherwise, the timestamp was advanced by another request handler since the beginning of the transaction, so the datastore aborts the current transaction and reports a concurrency failure to the app.
Verifying the timestamp, committing the journal entries, and updating the timestamp all occur in an atomic BigTable operation. If another process attempts to commit a transaction to the same entity group while the first transaction’s commit is in progress, the other process waits for the first commit to complete. This guarantees that if the first commit succeeds, the second process sees the updated timestamp and reports a concurrency failure. This is illustrated in Figure 8-2.
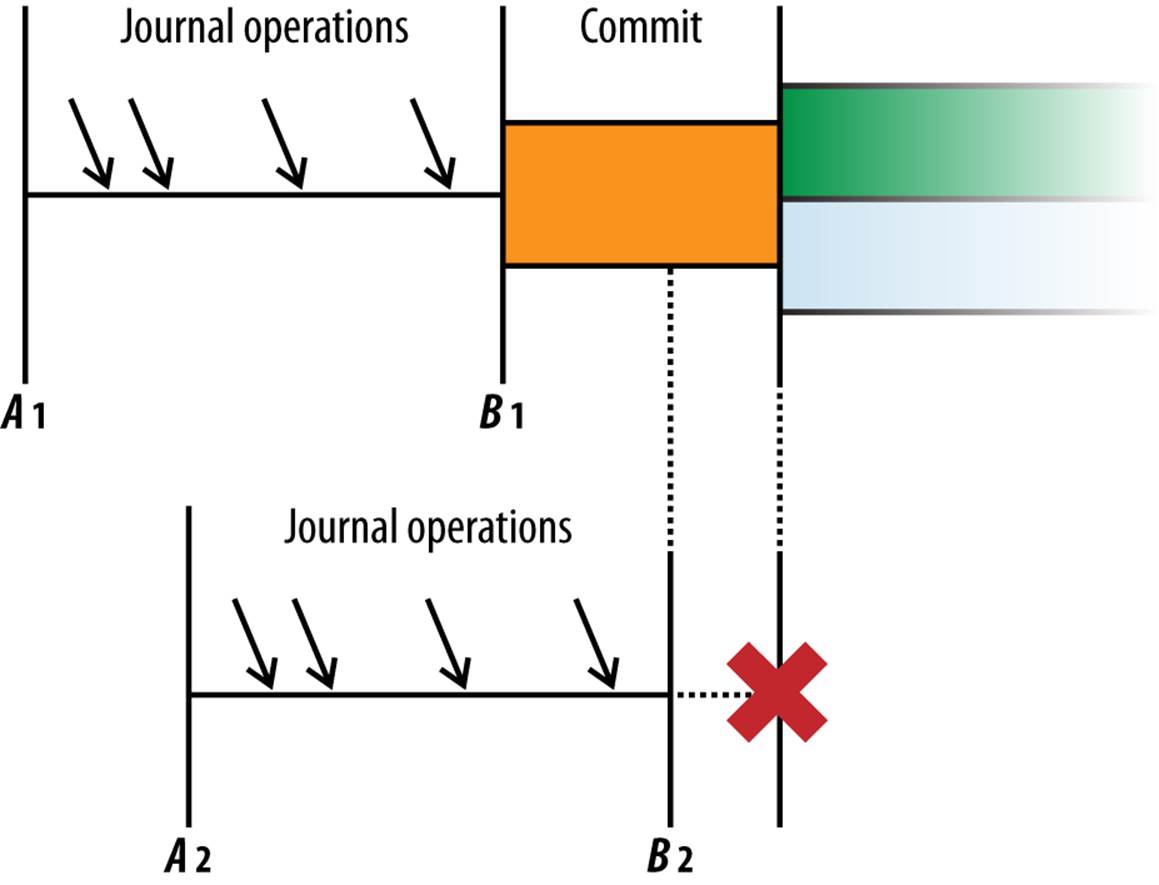
Figure 8-2. A timeline of two concurrent transactions; the first to commit “wins”
Once the journal entries have been committed (point C in Figure 8-1), the datastore applies each committed change to the appropriate entity and appropriate indexes, then marks the change as “applied.” If there are multiple unapplied changes for an entity in the journal, they are applied in the order they were performed.
Here’s the sneaky bit. If the apply phase fails for whatever reason (hard drive failure, power outage, meteorite), the committed transaction is still considered successful. If there are committed but unapplied changes the next time someone performs an operation on an entity in the entity group (within or without an explicit transaction), the datastore reruns the apply phase before performing the operation. This ensures that operations and transactions always see all changes that have been committed prior to the start of the operation or transaction. The datastore also uses background processes to roll forward unapplied operations, as well as purge old journal entries.
The roll-forward mechanism also ensures that subsequent operations can see all committed changes even if the apply phase is still in progress. At the beginning of an operation or transaction, the datastore notes the current time, then waits for all changes committed prior to that time to be applied before continuing.
Notice that the apply phase does not need to occur inside a BigTable transaction. Because of this, the datastore can spread multiple entities in the same group across multiple machines, and can allow an entity group to get arbitrarily large. Only the group’s last-committed timestamp and journal need to be stored close enough together for a BigTable transaction. The datastore makes an effort to store entities of the same group “near” each other for performance reasons, but this does not limit the size or speed of entity groups.
When an app updates an entity outside of a transaction, the datastore performs the update with the same transactional mechanism, as if it were a transaction of just one operation. The datastore assumes that an update performed outside of a transaction is safe to perform at any time, and will retry the update automatically in the event of a concurrency failure. If several attempts fail, the datastore throws the concurrency exception. In contrast, an explicit transaction throws a concurrency exception on the first failure, because the datastore does not know if it is safe to commit thesame changes. The app must retry the explicit transaction on its own. (The @ndb.transactional decorator knows how to rerun the function that performs the transaction, but this occurs as part of the application code.)
Cloud Datastore replicates all data to at least three places in each of at least two different data centers. The replication process uses a consensus algorithm based on “Paxos” to ensure that all sites agree that the change will be committed before proceeding. This level of replication ensures that your app’s datastore remains available for both reads and writes during all planned outages—and most unplanned outages.
TIP
When an app calls the datastore to update data, the call does not return until the apply phase is complete. If an error occurs at any point in the process, the datastore call raises an exception in the application.
This is true even if the error occurs during the apply phase, after the commit phase is complete and the update is guaranteed to be applied before the next transaction. Because the application can’t tell the difference between an error during the commit phase and an error during the apply phase, the application should react as if the update has not taken place.
In most cases, the app can simply retry the update. More care is needed if retrying the update relies on the previous attempt being unsuccessful, but these cases usually require testing the state of the data in a transaction, and the solution is simply to retry the entire transaction. If the transaction creates a new entity, one way to avoid creating a duplicate entity is to use a key name instead of a system-supplied numeric ID, precalculating and testing for the nonexistence of a global unique ID (GUID) if necessary.
Failures during the apply phase are very rare, and most errors represent a failure to commit. One of the most important principles in scalable app design is to be tolerant of the most rare kinds of faults.
How Entities Are Read
The timestamp mechanism explains what happens when two processes attempt to write to the same entity group at the same time. When one process commits, it updates the timestamp for the group. When the other process tries to commit, it notices the timestamp has changed, and aborts. The app can retry the transaction with fresh data, or give up.
The transaction is aborted only if the app attempted to update an entity during the transaction and another process has since committed changes. If the app only reads data in the transaction and does not make changes, the app simply sees the entities as they were at the beginning of the transaction. To support this, the datastore retains several old versions of each entity, marked with the timestamp of the most recently applied journal entry. Reading an entity in a transaction returns the version of the entity most recent to the timestamp at the beginning of the transaction.
Reading an entity outside of a transaction or with an eventual consistency read policy does not roll forward committed-but-unapplied changes. Instead, the read returns the entity as it appears as of the most recently applied changes. This is faster than waiting for pending changes to be applied, and usually not a concern for reads outside of transactions. But this means the entity may appear older or newer than other entities. If you need any consistency guarantees when reading multiple entities, use transactions and the strong consistency read policy.
Batch Updates
When you read, create, update, or delete an entity, the runtime environment makes a service call to the datastore. Each service call has some overhead, including serializing and deserializing parameters and transmitting them between machines in the data center. If you need to update multiple entities, you can save time by performing the updates together as a batch in one service call. (We introduced batch calls in Chapter 6.)
Here’s a quick example of the Python batch API:
# Creating multiple entities:
e1 = Message(id='m1', text='...')
e2 = Message(id='m2', text='...')
e3 = Message(id='m3', text='...')
message_keys = ndb.put_multi([e1, e2, e3])
# Getting multiple entities using keys:
message_keys = [ndb.Key('Message', 'm1'),
ndb.Key('Message', 'm2'),
ndb.Key('Message', 'm3')]
messages = ndb.get_multi(message_keys)
for message inmessages:
# ...
# Deleting multiple entities:
ndb.delete_multi(message_keys)
When the datastore receives a batch call, it bundles the keys or entities by their entity groups, which it can determine from the keys. Then it dispatches calls to the datastore machines responsible for each entity group. The datastore returns results to the app when it has received all results from all machines.
If the call includes changes for multiple entities in a single entity group, those changes are performed in a single transaction. There is no way to control this behavior, but there’s no reason to do it any other way. It’s faster to commit multiple changes to a group at once than to commit them individually, and no less likely to result in concurrency failures.
Outside of a transaction, a batch call can operate on multiple entity groups. In this case, each entity group involved in a batch update may fail to commit due to a concurrency failure. If a concurrency failure occurs for any update, the API raises the concurrency failure exception—even if updates to other groups were committed successfully.
Batch updates in disparate entity groups are performed in separate threads, possibly by separate datastore machines, executed in parallel to one another. This can make batch updates especially fast compared to performing each update one at a time.
Remember that if you use the batch API during a transaction, every entity or key in the batch must use the same entity group as the rest of the transaction.
How Indexes Are Updated
As we saw in Chapter 7, datastore queries are powered by indexes. The datastore updates these indexes as entities change, so results for queries can be determined without examining the entity properties directly. This includes an index of keys, an index for each kind and property, and custom indexes described by your app’s configuration files that fulfill complex queries. When an entity is created, updated, or deleted, each relevant index is updated and sorted so subsequent queries match the new state of the data.
The datastore updates indexes after changes have been committed, during the apply phase. Changes are applied to indexes and entities in parallel. Updates of indexes are themselves performed in parallel, so the number of indexes to update doesn’t necessarily affect how fast the update occurs.
As with entities, the datastore retains multiple versions of index data, labeled with timestamps. When you perform a query, the datastore notes the current time, then uses the index data that is most current up to that time. However, unless the query has an ancestor filter, the datastore has no way to know which entity groups are involved in the result set and so cannot wait for changes in progress to be applied.
This means that, for a brief period during an update, a query that doesn’t have an ancestor filter (a nonancestor query, or global query) may return results that do not match the query criteria. While another process is updating an entity, the query may see the old version of its index but return the new version of the entity. And because changes to entities and changes to indexes are applied in parallel, it is possible for a query to see the new version of its index but return the old version of the entity.
Figure 8-3 illustrates one possibility of what nontransactional reads and queries may see while changes are being applied.
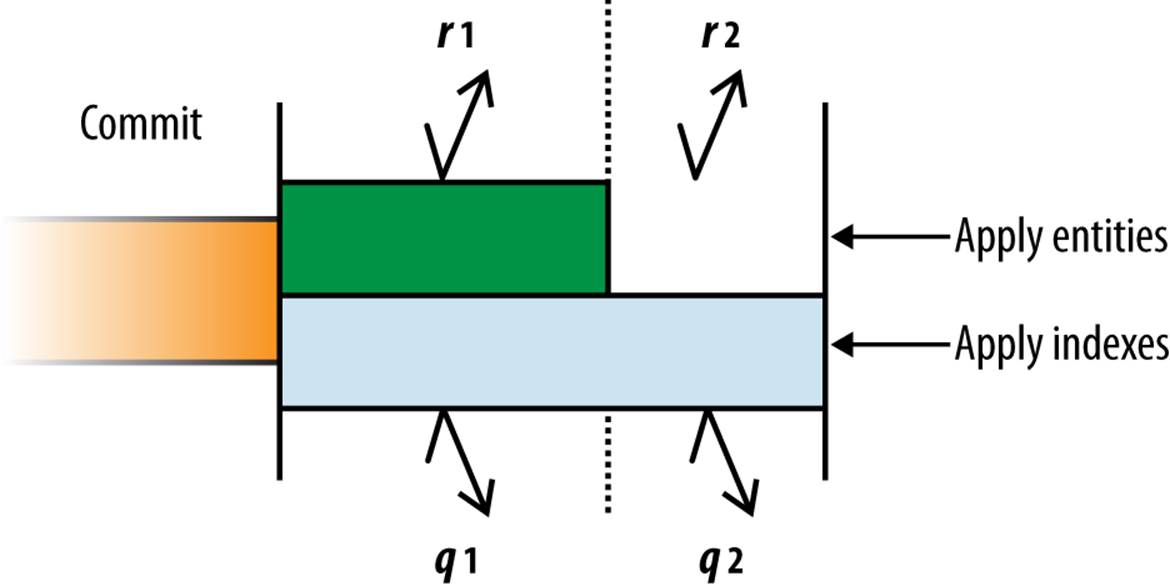
Figure 8-3. What nontransactional fetches and queries may see while changes are applied
Although fetches r1 and r2 both occur after the commit, because they do not occur within transactions, they see different data: r1 fetches the entity as it is before the update, and r2 fetches the entity as it is after the update has been applied. Queries q1 and q2 may use the same (preupdate) index data to produce a list of results, but they return different entity data depending on whether changes have been applied to the entities.
In rare cases, it’s also possible for changes to indexes to be applied prior to changes to entities, and for the apply phase to fail and leave committed changes unapplied until the next transaction on the entity group. If you need stronger guarantees, fetch or query entities within transactions to ensure all committed changes are applied before the data is used.
A query with an ancestor filter knows its entity group, and can therefore offer the same strong consistency guarantees within transactions as fetches. But many useful queries span entity groups, and therefore cannot be performed in transactions. If it is important to your application that a result for a nontransactional query match the criteria exactly, verify the result in the application code before using it.
Cross-Group Transactions
Transactions and entity groups present a fundamental tension in designing data for the App Engine datastore. If all we cared about was data consistency, we’d put all our data in a single entity group, and every transaction would have a consistent and current view of the entire world—and would be battling with every other simultaneous transaction to commit a change. Conversely, if we wanted to avoid contention as much as possible, we’d keep every entity in its own group and never perform more than one operation in a transaction.
Entity groups are a middle ground. They allow us to define limited sets of data that demand strongly consistent transactional updates, and with some thought we can organize these boundaries so an increase in traffic does not result in an increase in simultaneous updates to a single group. For example, if a user only ever updates an entity group dedicated to that user, then an increase in users will never increase the number of users writing to a given group simultaneously.
But real-world data patterns are not always so clean. Most useful applications involve sharing data between users. At another extreme, it’s possible all users can view and modify the same set of data. At that point, we need to make some sacrifices to operate at scale, using techniques like sharding and eventually consistent data structures updated by background tasks to spread the updates over time and space.
There are many common scenarios where it’d be convenient if we could just operate on a few entity groups in a transaction, when one group is too constraining but we don’t need to update the world. Sometimes we need to operate on several disparate sets of data at once, but it’d make our data model too complex to try and manage them in groups. For these cases, App Engine has a feature: cross-group transactions.
A cross-group transaction (or an “XG transaction”) is simply a transaction that’s allowed to operate on up to five entity groups transactionally. The datastore uses a slightly different—and slightly slower—mechanism for this, so to use more than one group transactionally, you must declare that your transaction is of the cross-group variety. The cross-group mechanism is built on top of the existing single-group mechanism in BigTable. It manages the updates so all groups commit or fail completely.
The important idea here is that you do not need to say ahead of time which groups will be involved in a transaction. Any given cross-group transaction can pick any entity groups on which to operate, up to five.
As with a single group transaction, a cross-group transaction can read from, write to, and perform ancestor queries on any of the groups in the transaction. If any group in a given cross-group transaction is updated after the transaction is started but before it tries to commit, the entire transaction fails and must be retried. Whether failure due to contention is more likely with more groups depends entirely on the design of your app.
You declare a transaction as a cross-group transaction by setting the xg=True argument in the @ndb.transactional decorator for the transaction function. If a transactional function is XG, or calls a transactional function that is XG, the entire transaction becomes an XG transaction:
@ndb.transactional(xg=True):
def update_win_tallies(winning_player, losing_player):
# ...