High Performance Python (2014)
Chapter 10. Clusters and Job Queues
QUESTIONS YOU’LL BE ABLE TO ANSWER AFTER THIS CHAPTER
§ Why are clusters useful?
§ What are the costs of clustering?
§ How can I convert a multiprocessing solution into a clustered solution?
§ How does an IPython cluster work?
§ How does NSQ help with making robust production systems?
A cluster is commonly recognized to be a collection of computers working together to solve a common task. It could be viewed from the outside as a larger single system.
In the 1990s, the notion of using a cluster of commodity PCs on a local area network for clustered processing—known as a Beowulf cluster—became popular. Google later gave the practice a boost by using clusters of commodity PCs in its own data centers, particularly for running MapReduce tasks. At the other end of the scale, the TOP500 project ranks the most powerful computer systems each year; typically these have a clustered design and the fastest machines all use Linux.
Amazon Web Services (AWS) is commonly used both for engineering production clusters in the cloud and for building on-demand clusters for short-lived tasks like machine learning. With AWS, you can rent sets of eight Intel Xeon cores with 60 GB of RAM for $1.68 each per hour, alongside 244 GB RAM machines and machines with GPUs. Look at Using IPython Parallel to Support Research and the StarCluster package if you’d like to explore AWS for ad hoc clusters for compute-heavy tasks.
Different computing tasks require different configurations, sizes, and capabilities in a cluster. We’ll define some common scenarios in this chapter.
Before you move to a clustered solution, do make sure that you have:
§ Profiled your system so you understand the bottlenecks
§ Exploited compiler solutions like Cython
§ Exploited multiple cores on a single machine (possibly a big machine with many cores)
§ Exploited techniques for using less RAM
Keeping your system to one machine (even if the “one machine” is a really beefy computer with lots of RAM and many CPUs) will make your life easier. Move to a cluster if you really need a lot of CPUs or the ability to process data from disks in parallel, or you have production needs like high resiliency and rapid speed of response.
Benefits of Clustering
The most obvious benefit of a cluster is that you can easily scale computing requirements—if you need to process more data or to get an answer faster, you just add more machines (or “nodes”).
By adding machines, you can also improve reliability. Each machine’s components have a certain likelihood of failing, and with a good design the failure of a number of components will not stop the operation of the cluster.
Clusters are also used to create systems that scale dynamically. A common use case is to cluster a set of servers that process web requests or associated data (e.g., resizing user photos, transcoding video, or transcribing speech) and to activate more servers as demand increases at certain times of the day.
Dynamic scaling is a very cost-effective way of dealing with nonuniform usage patterns, as long as the machine activation time is fast enough to deal with the speed of changing demand.
A subtler benefit of clustering is that clusters can be separated geographically but still centrally controlled. If one geographic area suffers an outage (e.g., flood or power loss), the other cluster can continue to work, perhaps with more processing units being added to handle the demand. Clusters also allow you to run heterogeneous software environments (e.g., different versions of operating systems and processing software), which might improve the robustness of the overall system—note, though, that this is definitely an expert-level topic!
Drawbacks of Clustering
Moving to a clustered solution requires a change in thinking. This is an evolution of the change in thinking required when you move from serial to parallel code that we introduced back in Chapter 9. Suddenly you have to consider what happens when you have more than one machine—you have latency between machines, you need to know if your other machines are working, and you need to keep all the machines running the same version of your software. System administration is probably your biggest challenge.
In addition, you normally have to think hard about the algorithms you are implementing and what happens once you have all these additional moving parts that may need to stay in sync. This additional planning can impose a heavy mental tax; it is likely to distract you from your core task, and once a system grows large enough you’ll probably require a dedicated engineer to join your team.
NOTE
The reason why we’ve tried to focus on using one machine efficiently in this book is because we both believe that life is easier if you’re only dealing with one computer rather than a collection (though we confess it can be way more fun to play with a cluster—until it breaks). If you can scale vertically (by buying more RAM or more CPUs), then it is worth investigating this approach in favor of clustering. Of course, your processing needs may exceed what’s possible with vertical scaling, or the robustness of a cluster may be more important than having a single machine. If you’re a single person working on this task, though, bear in mind also that running a cluster will suck some of your time.
When designing a clustered solution, you’ll need to remember that each machine’s configuration might be different (each machine will have a different load and different local data). How will you get all the right data onto the machine that’s processing your job? Does the latency involved in moving the job and the data amount to a problem? Do your jobs need to communicate partial results to each other? What happens if a process fails or a machine dies or some hardware wipes itself when several jobs are running? Failures can be introduced if you don’t consider these questions.
You should also consider that failures can be acceptable. For example, you probably don’t need 99.999% reliability when you’re running a content-based web service—if on occasion a job fails (e.g., a picture doesn’t get resized quickly enough) and the user is required to reload a page, that’s something that everyone is already used to. It might not be the solution you want to give to the user, but accepting a little bit of failure typically reduces your engineering and management costs by a worthwhile margin. On the flip side, if a high-frequency trading system experiences failures, the cost of bad stock market trades could be considerable!
Maintaining a fixed infrastructure can become expensive. Machines are relatively cheap to purchase, but they have an awful habit of going wrong—automatic software upgrades can glitch, network cards fail, disks have write errors, power supplies can give spikey power that disrupts data, cosmic rays can flip a bit in a RAM module. The more computers you have, the more time will be lost to dealing with these issues. Sooner or later you’ll want to add a system engineer who can deal with these problems, so add another $100,000 to the budget. Using a cloud-based cluster can mitigate a lot of these problems (it costs more, but you don’t have to deal with the hardware maintenance), and some cloud providers also offer a spot-priced market for cheap but temporary computing resources.
An insidious problem with a cluster that grows organically over time is that it’s possible that no one has documented how to restart it safely if everything gets turned off. If you don’t have a documented restart plan, then you should assume you’ll have to write one at the worst possible time (one of your authors has been involved in debugging this sort of problem on Christmas Eve—this is not the Christmas present you want!). At this point you’ll also learn just how long it can take each part of a system to get up to speed—it might take minutes for each part of a cluster to boot and to start to process jobs, so if you have 10 parts that operate in succession it might take an hour to get the whole system running from cold. The consequence is that you might have an hour’s worth of backlogged data. Do you then have the necessary capacity to deal with this backlog in a timely fashion?
Slack behavior can be a cause of expensive mistakes, and complex and hard-to-anticipate behavior can cause expensive unexpected outcomes. Let’s look at two high-profile cluster failures and see what lessons we can learn.
$462 Million Wall Street Loss Through Poor Cluster Upgrade Strategy
In 2012, the high-frequency trading firm Knight Capital lost $462 million after a bug was introduced during a software upgrade in a cluster. The software made more orders for shares than customers had requested.
In the trading software, an older flag was repurposed for a new function. The upgrade was rolled out to seven of the eight live machines, but the eighth machine used older code to handle the flag, which resulted in the wrong trades being made. The Securities and Exchange Commission (SEC) noted that Knight Capital didn’t have a second technician review the upgrade and no process to review the upgrade existed.
The underlying mistake seems to have had two causes. The first was that the software development process hadn’t removed an obsolete feature, so the stale code stayed around. The second was that no manual review process was in place to confirm that the upgrade was completed successfully.
Technical debt adds a cost that eventually has to be paid—preferably by taking time when not under pressure to remove the debt. Always use unit tests, both when building and when refactoring code. The lack of a written checklist to run through during system upgrades, along with a second pair of eyes, could cost you an expensive failure. There’s a reason that airplane pilots have to work through a takeoff checklist: it means that nobody ever skips the important steps, no matter how many times they might have done them before!
Skype’s 24-Hour Global Outage
Skype suffered a 24-hour planet-wide failure in 2010. Behind the scenes, Skype is supported by a peer-to-peer network. An overload in one part of the system (used to process offline instant messages) caused delayed responses from Windows clients; some versions of the Windows client didn’t properly handle the delayed responses and crashed. In all, approximately 40% of the live clients crashed, including 25% of the public supernodes. Supernodes are critical to routing data in the network.
With 25% of the routing offline (it came back on, but slowly), the network overall was under great strain. The crashed Windows client nodes were also restarting and attempting to rejoin the network, adding a new volume of traffic on the already overloaded system. The supernodes have a backoff procedure if they experience too much load, so they started to shut down in response to the waves of traffic.
Skype became largely unavailable for 24 hours. The recovery process involved first setting up hundreds of new mega-supernodes configured to deal with the increased traffic, and then following up with thousands more. Over the coming days, the network recovered.
This incident caused a lot of embarrassment for Skype; clearly, it also changed their focus to damage limitation for several tense days. Customers were forced to look for alternative solutions for voice calls, which was likely a marketing boon for competitors.
Given the complexity of the network and the escalation of failures that occurred, it is likely that this failure would have been hard to both predict and plan for. The reason that all of the nodes on the network didn’t fail was due to different versions of the software and different platforms—there’s a reliability benefit to having a heterogenous network rather than a homogeneous system.
Common Cluster Designs
It is common to start with a local ad hoc cluster of reasonably equivalent machines. You might wonder if you can add old computers to an ad hoc network, but typically older CPUs eat a lot of power and run very slowly, so they don’t contribute nearly as much as you might hope compared to one new, high-specification machine. An in-office cluster requires someone who can maintain it. A cluster in link to Amazon’s EC2, or Microsoft’s Azure, or run by an academic institution, offloads the hardware support to the provider’s team.
If you have well-understood processing requirements, it might make sense to design a custom cluster—perhaps one that uses an InfiniBand high-speed interconnect in place of gigabit Ethernet, or one that uses a particular configuration of RAID drives that support your read, write, or resiliency requirements. You might want to combine both CPUs and GPUs on some machines, or just default to CPUs.
You might want a massively decentralized processing cluster, like the ones used by projects like SETI@home and Folding@home through the Berkeley Open Infrastructure for Network Computing (BOINC) system—they still share a centralized coordination system, but the computing nodes join and leave the project in an ad hoc fashion.
On top of the hardware design, you can run different software architectures. Queues of work are the most common and easiest to understand. Typically, jobs are put onto a queue and consumed by a processor. The result of the processing might go onto another queue for further processing, or be used as a final result (e.g., being added into a database). Message-passing systems are slightly different—messages get put onto a message bus and are then consumed by other machines. The messages might time out and get deleted, and they might be consumed by multiple machines. A more complex system is when processes talk to each other using interprocess communication—this can be considered an expert-level configuration as there are lots of ways that you can set it up badly, which will result in you losing your sanity. Only go down the IPC route if you really know that you need it.
How to Start a Clustered Solution
The easiest way to start a clustered system is to begin with one machine that will run both the job server and a job processor (just one for one CPU). If your tasks are CPU-bound, run one job processor per CPU; if your tasks are I/O-bound, run several per CPU. If they’re RAM-bound, be careful that you don’t run out of RAM. Get your single-machine solution working with one processor, then add more. Make your code fail in unpredictable ways (e.g., do a 1/0 in your code, use kill -9 <pid> on your worker, pull the power from the socket so the whole machine dies) to check if your system is robust.
Obviously, you’ll want to do heavier testing than this—a unit test suite full of coding errors and artificial exceptions is good. Ian likes to throw in unexpected events, like having a processor run a set of jobs while an external process is systematically killing important processes and confirming that these all get restarted cleanly by whatever monitoring process you’re using.
Once you have one running job processor, add a second. Check that you’re not using too much RAM. Do you process jobs twice as fast as before?
Now introduce a second machine, with just one job processor on that new machine and no job processors on the coordinating machine. Does it process jobs as fast as when you had the processor on the coordinating machine? If not, why not? Is latency a problem? Do you have different configurations? Maybe you have different machine hardware, like CPUs, RAM, and cache sizes?
Now add another nine computers and test to see if you’re processing jobs 10 times faster than before. If not, why not? Are network collisions now occurring that slow down your overall processing rate?
To reliably start the cluster’s components when the machine boots, we tend to use either a cron job, Circus or supervisord, or sometimes Upstart (which is being replaced by systemd). Circus is newer than supervisord, but both are Python-based. cron is old, but very reliable if you’re just starting scripts like a monitoring process that can start subprocesses as required.
One you have a reliable cluster you might want to introduce a random-killer tool like Netflix’s ChaosMonkey, which deliberately kills parts of your system to test them for resiliency. Your processes and your hardware will die eventually, and it doesn’t hurt to know that you’re likely to survive at least the errors you predict might happen.
Ways to Avoid Pain When Using Clusters
One particularly painful experience Ian encountered was when a series of queues in a clustered system ground to a halt. Later queues were not being consumed, so they filled up. Some of the machines ran out of RAM, so their processes died. Earlier queues were being processed but couldn’t pass their results to the next queue, so they crashed. In the end the first queue was being filled but not consumed, so it crashed. After that we were paying for data from a supplier that ultimately was discarded. You must sketch out some notes to consider the various ways your cluster will die (not if it dies but when it dies), and what will happen. Will you lose data (and is this a problem?)? Will you have a large backlog that’s too painful to process?
Having a system that’s easy to debug probably beats having a faster system. Engineering time and the cost of downtime are probably your largest expenses (this isn’t true if you’re running a missile defense program, but it is probably true for a start-up). Rather than shaving a few bytes by using a low-level compressed binary protocol, consider using human-readable text in JSON when passing messages. It does add an overhead for sending the messages and decoding them, but when you’re left with a partial database after a core computer has caught fire, you’ll be glad that you can read the important messages quickly as you work to bring the system back online.
Make sure it is cheap in time and money to deploy updates to the system—both operating system updates and new versions of your software. Every time anything changes in the cluster, you risk the system responding in odd ways if it is in a schizophrenic state. Make sure you use a deployment system like Fabric, Salt, Chef, or Puppet or a system image like a Debian .deb, a RedHat .rpm, or an Amazon Machine Image. Being able to robustly deploy an update that upgrades an entire cluster (with a report on any problems found) massively reduces stress during difficult times.
Positive reporting is useful. Every day, send an email to someone detailing the performance of the cluster. If that email doesn’t turn up, then that’s a useful clue that something’s happened. You’ll probably want other early warning systems that’ll notify you faster, too; Pingdom andServerDensity are particularly useful here. A “dead man’s switch” that reacts to the absence of an event is another useful backup (e.g., Dead Man’s Switch).
Reporting to the team on the health of the cluster is very useful. This might be an admin page inside a web application, or a separate report. Ganglia is great for this. Ian has seen a Star Trek LCARS-like interface running on a spare PC in an office that plays the “red alert” sound when problems are detected—that’s particularly effective at getting the attention of an entire office. We’ve even seen Arduinos driving analog instruments like old-fashioned boiler pressure gauges (they make a nice sound when the needle moves!) showing system load. This kind of reporting is important so that everyone understands the difference between “normal” and “this might ruin our Friday night!”
Three Clustering Solutions
In the following sections we introduce Parallel Python, IPython Parallel, and NSQ.
Parallel Python has a very similar interface to multiprocessing. Upgrading your ‘multiprocessing` solution from a single multicore machine to a multimachine setup is the matter of a few minutes’ work. Parallel Python has few dependencies and is easy to configure for research work on a local cluster. It isn’t very powerful and lacks communication mechanisms, but for sending out embarrassingly parallel jobs to a small local cluster it is very easy to use.
IPython clusters are very easy to use on one machine with multiple cores. Since many researchers use IPython as their shell, it is natural to also use it for parallel job control. Building a cluster requires a little bit of system administration knowledge and there are some dependencies (such as ZeroMQ), so the setup is a little more involved than with Parallel Python. A huge win with IPython Parallel is the fact that you can use remote clusters (e.g., using Amazon’s AWS and EC2) just as easily as local clusters.
NSQ is a production-ready queuing system used in companies like Bitly. It has persistence (so if machines die, jobs can be picked up again by another machine) and strong mechanisms for scalability. With this greater power comes a slightly greater need for system administration and engineering skills.
Using the Parallel Python Module for Simple Local Clusters
The Parallel Python (pp) module enables local clusters of workers using an interface that is similar to that of multiprocessing. Handily, this means that converting code from multiprocessing using map to Parallel Python is very easy. You can run code using one machine or an ad hoc network just as easily. You can install it using pip install pp.
With Parallel Python we can calculate Pi using the Monte Carlo method as we did back in Estimating Pi Using Processes and Threads using our local machine—notice in Example 10-1 how similar the interface is to the earlier multiprocessing example. We create a list of work innbr_trials_per_process and pass these jobs to four local processes. We could create as many work items as we wanted; they’d be consumed as workers became free.
Example 10-1. Parallel Python local example
...
import pp
NBR_ESTIMATES = 1e8
def calculate_pi(nbr_estimates):
steps = xrange(int(nbr_estimates))
nbr_trials_in_unit_circle = 0
for step insteps:
x = random.uniform(0, 1)
y = random.uniform(0, 1)
is_in_unit_circle = x * x + y * y <= 1.0
nbr_trials_in_unit_circle += is_in_unit_circle
return nbr_trials_in_unit_circle
if __name__ == "__main__":
NBR_PROCESSES = 4
job_server = pp.Server(ncpus=NBR_PROCESSES)
print "Starting pp with", job_server.get_ncpus(), "workers"
nbr_trials_per_process = [NBR_ESTIMATES] * NBR_PROCESSES
jobs = []
for input_args innbr_trials_per_process:
job = job_server.submit(calculate_pi, (input_args,), (), ("random",))
jobs.append(job)
# each job blocks until the result is ready
nbr_in_unit_circles = [job() for job injobs]
print "Amount of work:", sum(nbr_trials_per_process)
print sum(nbr_in_unit_circles) * 4 / NBR_ESTIMATES / NBR_PROCESSES
In Example 10-2, we extend the example—this time we’ll require 1,024 jobs of 100,000,000 estimates each with a dynamically configured cluster. On remote machines we can run python ppserver.py -w 4 -a -d and remote servers will start using four processes (the default would be eight on Ian’s laptop but we don’t want to use the four HyperThreads so we’ve chosen four CPUs), with autoconnect and with a debug log. The debug log prints debug information to the screen; this is useful for checking that work has been received. The autoconnect flag means that we don’t have to specify IP addresses; we let pp advertise itself and connect to the servers.
Example 10-2. Parallel Python over a cluster
...
NBR_JOBS = 1024
NBR_LOCAL_CPUS = 4
ppservers = ("*",) # set IP list to be autodiscovered
job_server = pp.Server(ppservers=ppservers, ncpus=NBR_LOCAL_CPUS)
print "Starting pp with", job_server.get_ncpus(), "local workers"
nbr_trials_per_process = [NBR_ESTIMATES] * NBR_JOBS
jobs = []
for input_args in nbr_trials_per_process:
job = job_server.submit(calculate_pi, (input_args,), (), ("random",))
jobs.append(job)
...
Running with a second powerful laptop, the computation time roughly halves. On the other hand, an old MacBook with one CPU barely helps—often it’ll compute one of the jobs so slowly that the fast laptop is left idle with no more work to perform, so the overall completion time is longer than if just the fast laptop were used by itself.
This is a very useful way to begin building an ad hoc cluster for light computation tasks. You probably don’t want to use it in a production environment (Celery or GearMan is likely a better choice), but for research and easy scaling when learning about a problem it gives you a quick win.
pp doesn’t help with distributing code or static data to remote machines; you have to move external libraries (e.g., anything you might have compiled into a static library) to the remote machines and provide any shared data. It does handle pickling the code to run, additional imports, and the data you supply from the controller process.
Using IPython Parallel to Support Research
The IPython cluster support comes via ipcluster. IPython becomes an interface to local and remote processing engines where data can be pushed among the engines and jobs can be pushed to remote machines. Remote debugging is possible, and the message passing interface (MPI) is optionally supported. This same communication mechanism powers the IPython Notebook interface.
This is great for a research setting—you can push jobs to machines in a local cluster, interact and debug if there’s a problem, push data to machines, and collect results back, all interactively. Note also that PyPy runs IPython and IPython Parallel. The combination might be very powerful (if you don’t use numpy).
Behind the scenes, ZeroMQ is used as the messaging middleware, so you’ll need to have this installed. If you’re building a cluster on a local network, you can avoid SSH authentication. If you need some security, then SSH is fully supported, but it makes configuration a little more involved—start on a local trusted network and build out as you learn how each component works.
The project is split into four components. An engine is a synchronous Python interpreter that runs your code. You’ll run a set of these to enable parallel computing. A controller provides an interface to the engines; it is responsible for work distribution and supplies a direct interface and aload-balanced interface that provides a work scheduler. A hub keeps track of engines, schedulers, and clients. Schedulers hide the synchronous nature of the engines and provide an asynchronous interface.
On the laptop, we start four engines using ipcluster start -n 4. In Example 10-3 we start IPython and check that a local Client can see our four local engines. We can address all four engines using c[:], and we apply a function to each engine—apply_sync takes a callable, so we supply a zero-argument lambda that will return a string. Each of our four local engines will run one of these functions, returning the same result.
Example 10-3. Testing that we can see the local engines in IPython
In [1]: from IPython.parallel import Client
In [2]: c = Client()
In [3]: print c.ids
[0, 1, 2, 3]
In [4]: c[:].apply_sync(lambda:"Hello High Performance Pythonistas!")
Out[4]:
['Hello High Performance Pythonistas!',
'Hello High Performance Pythonistas!',
'Hello High Performance Pythonistas!',
'Hello High Performance Pythonistas!']
Having constructed our engines, they’re now in an empty state. If we import modules locally, they won’t be imported in the remote engines. A clean way to import both locally and remotely is to use the sync_imports context manager. In Example 10-4 we’ll import os on both the local IPython and the four connected engines, then call apply_sync again on the four engines to fetch their PIDs. If we didn’t do the remote imports we’d get a NameError, as the remote engines wouldn’t know about the os module. We can also use execute to run any Python command remotely on the engines.
Example 10-4. Importing modules into our remote engines
In [5]: dview=c[:] # this is a direct view (not a load-balanced view)
In [6]: with dview.sync_imports():
....: import os
....:
importing os on engine(s)
In [7]: dview.apply_sync(lambda:os.getpid())
Out[7]: [15079, 15080, 15081, 15089]
In [8]: dview.execute("import sys") # another way to execute commands remotely
You’ll want to push data to the engines. The push command shown in Example 10-5 lets you send a dictionary of items that are added to the global namespace of each engine. There’s a corresponding pull to retrieve items: you give it keys and it’ll return the corresponding values from each of the engines.
Example 10-5. Pushing shared data to the engines
In [9]: dview.push({'shared_data':[50, 100]})
Out[9]: <AsyncResult: _push>
In [10]: dview.apply_sync(lambda:len(shared_data))
Out[10]: [2, 2, 2, 2]
Now let’s add a second machine to the cluster. First we’ll kill the ipengine engines that we created before and exit IPython. We’ll start from a clean slate. You’ll need a second machine available that has SSH configured to allow you to automatically log in.
In Example 10-6 we’ll create a new profile for our cluster. A set of configuration files is placed in the <HOME>/.ipython/profile_mycluster directory. By default the engines are configured to accept connections from localhost only, and not from external devices. Edit ipengine_config.py to configure the HubFactory to accept external connections, save, and then start a new ipcluster using the new profile. We’re back to having four local engines.
Example 10-6. Creating a local profile that accepts public connections
$ ipython profile create mycluster --parallel
$ gvim /home/ian/.ipython/profile_mycluster/ipengine_config.py
# add "c.HubFactory.ip = '*'" near the top
$ ipcluster start -n 4 --profile=mycluster
Next we need to pass this configuration file to our remote machine. In Example 10-7 we use scp to copy ipcontroller-engine.json (which was created when we started ipcluster) to the remote machine’s .config/ipython/profile_default/security directory. Once it is copied, run ipengineon the remote machine. It will look in the default directory for ipcontroller-engine.json; if it connects successfully, then you’ll see a message like the one shown here.
Example 10-7. Copying the edited profile to the remote machine and testing
# On the local machine
$ scp /home/ian/.ipython/profile_mycluster/security/ipcontroller-engine.json
ian@192.168.0.16:/home/ian/.config/ipython/profile_default/security/
# Now on the remote machine
ian@ubuntu:~$ ipengine
...Using existing profile dir: u'/home/ian/.config/ipython/profile_default'
...Loading url_file u'/home/ian/.config/ipython/profile_default/security/
ipcontroller-engine.json'
...Registering with controller at tcp://192.168.0.128:35963
...Starting to monitor the heartbeat signal from the hub every 3010 ms.
...Using existing profile dir: u'/home/ian/.config/ipython/profile_default'
...Completed registration with id 4
Let’s test the configuration. In Example 10-8 we’ll start a local IPython shell using the new profile. We’ll retrieve a list of five clients (four locally and one remotely), then we’ll ask for Python’s version info—you can see that on the remote machine we’re using the Anaconda distribution. We only get one additional engine, as the remote machine in this case is a single-core MacBook.
Example 10-8. Test that the new machine is a part of the cluster
$ ipython --profile=mycluster
Python 2.7.5+ (default, Sep 19 2013, 13:48:49)
Type "copyright", "credits" or"license" for more information.
IPython 1.1.0—An enhanced Interactive Python.
...
In [1]: from IPython.parallel import Client
In [2]: c = Client()
In [3]: c.ids
Out[3]: [0, 1, 2, 3, 4]
In [4]: dview=c[:]
In [5]: with dview.sync_imports():
...: import sys
In [6]: dview.apply_sync(lambda:sys.version)
Out[6]:
['2.7.5+ (default, Sep 19 2013, 13:48:49) \n[GCC 4.8.1]',
'2.7.5+ (default, Sep 19 2013, 13:48:49) \n[GCC 4.8.1]',
'2.7.5+ (default, Sep 19 2013, 13:48:49) \n[GCC 4.8.1]',
'2.7.5+ (default, Sep 19 2013, 13:48:49) \n[GCC 4.8.1]',
'2.7.6 |Anaconda 1.9.2 (64-bit)| (default, Jan 17 2014, 10:13:17) \n
[GCC 4.1.2 20080704 (Red Hat 4.1.2-54)]']
Let’s put it all together. In Example 10-9 we’ll use the five engines to estimate pi as we did in Using the Parallel Python Module for Simple Local Clusters. This time we’ll use the @require decorator to import the random module in the engines. We use a direct view to send our work out to the engines; this blocks until all the results come back. Then we estimate pi as we’ve done before.
Example 10-9. Estimating pi using our local cluster
from IPython.parallel import Client, require
NBR_ESTIMATES = 1e8
@require('random')
def calculate_pi(nbr_estimates):
...
return nbr_trials_in_unit_circle
if __name__ == "__main__":
c = Client()
nbr_engines = len(c.ids)
print "We're using {} engines".format(nbr_engines)
dview = c[:]
nbr_in_unit_circles = dview.apply_sync(calculate_pi, NBR_ESTIMATES)
print "Estimates made:", nbr_in_unit_circles
# work using the engines only
nbr_jobs = len(nbr_in_unit_circles)
print sum(nbr_in_unit_circles) * 4 / NBR_ESTIMATES / nbr_jobs
IPython Parallel offers much more than what’s shown here. Asynchronous jobs and mappings over larger input ranges are, of course, possible. It also has a CompositeError class, which is a higher-level exception that wraps up the same exception that’s occurred on multiple engines (rather than you receiving multiple identical exceptions if you’ve deployed bad code!); this is a convenience when you’re dealing with lots of engines.[26]
One particularly powerful feature of IPython Parallel is that it allows you to use larger clustering environments, including supercomputers and cloud services like Amazon’s EC2. To further ease this sort of cluster’s development, the Anaconda distribution includes support for StarCluster. Olivier Grisel gave a great tutorial on advanced machine learning with scikit-learn at PyCon 2013; at the two-hour point he demos using StarCluster for machine learning via IPython Parallel on Amazon EC2 spot instances.
NSQ for Robust Production Clustering
In a production environment, you will need a solution that is more robust than the other solutions we’ve talked about so far. This is because during the everyday operation of your cluster, nodes may become unavailable, code may crash, networks may go down, or one of the other thousands of problems that can happen may happen. The problem is that all the previous systems have had one computer where commands are issued and a limited and static number of computers that read the commands and execute them. Instead, we would like a system where we can have multiple actors communicating via some message bus—this would allow us to have an arbitrary and constantly changing number of message creators and consumers.
One simple solution to these problems is NSQ, a highly performant distributed messaging platform. While it is written in GO, it is completely data format and language-agnostic. As a result, there are libraries in many languages, and the basic interface into NSQ is a REST API that requires only the ability to make HTTP calls. Furthermore, we can send messages in any format we want: JSON, Pickle, msgpack, etc. Most importantly, however, it provides fundamental guarantees regarding message delivery, and it does all of this using two simple design patterns: queues and pub/subs.
Queues
A queue is a type of buffer for messages. Whenever you want to send a message to another part of your processing pipeline, you send it to the queue, and it’ll wait in the queue until there is an available worker to read it. A queue is most useful in distributed processing when there is an imbalance between production and consumption. If this imbalance occurs, we can simply scale horizontally by adding more data consumers until the message production rate and consumption rate are equal. In addition, if the computers responsible for consuming messages go down, the messages are not lost and are simply queued until there is an available consumer, thus giving us message delivery guarantees.
For example, let’s say we would like to process new recommendations for a user every time that user rates a new item on our site. If we didn’t have a queue, then the “rate” action would directly call the “recalculate-recommendations” action, regardless of how busy the servers dealing with recommendations were. If all of a sudden thousands of users decided to rate something, our recommendations servers could get so swamped with requests that they could start timing out, dropping messages, and generally becoming unresponsive!
On the other hand, with a queue the recommendations servers ask for more tasks when they are ready. A new “rate” action would put a new task on the queue, and when a recommendations server becomes ready to do more work it would grab it from the queue and process it. In this setup, if more users than normal start rating items, our queue would fill up and act as a buffer for the recommendations servers—their workload would be unaffected and they could still process messages until the queue was empty.
One potential problem with this is that if a queue becomes completely overwhelmed with work, it will be storing quite a lot of messages. NSQ solves this by having multiple storage backends—when there aren’t many messages they are stored in memory, and as more messages start coming in the messages get put onto disk.
NOTE
Generally, when working with queued systems it is a good idea to try to have the downstream systems (i.e., the recommendations systems in the preceding example) be at 60% capacity with a normal workload. This is a good compromise between allocating too many resources for a problem and giving your servers enough extra power for when the amount of work increases beyond normal levels.
Pub/sub
A pub/sub (short for publisher/subscriber), on the other hand, describes who gets what messages. A data publisher can push data out of a particular topic, and data subscribers can subscribe to different feeds of data. Whenever the publisher puts out a piece of information, it gets sent to all of the subscribers—they each get an identical copy of the original information. You can think of this like a newspaper: many people can subscribe to a particular newspaper, and whenever a new edition of the newspaper comes out, every subscriber gets an identical copy of it. In addition, the producer of the newspaper doesn’t need to know all of the people its papers are being sent to. As a result, publishers and subscribers are decoupled from each other, which allows our system to be more robust as our network changes while still in production.
In addition to this, NSQ adds the notion of a data consumer; that is, multiple processes can be connected to the same data subscription. Whenever a new piece of data comes out, every subscriber gets a copy of the data; however, only one consumer of each subscription sees that data. In the newspaper analogy, you can think of this as having multiple people in the same household who read the newspaper. The publisher will deliver one paper to the house, since that house only has one subscription, and whoever in the house gets to it first gets to read that data. Each subscriber’s consumers do the same processing to a message when they see it; however, they can potentially be on multiple computers and thus add more processing power to the entire pool.
We can see a depiction of this pub/sub/consumer paradigm in Figure 10-1. If a new message gets published on the “clicks” topic, all of the subscribers (or, in NSQ parlance, channels—i.e., “metrics,” “spam_analysis,” and “archive”) will get a copy. Each subscriber is composed of one or more consumers, which represent actual processes that react to the messages. In the case of the “metrics” subscriber, only one consumer will see the new message. The next message will go to another consumer, and so on.
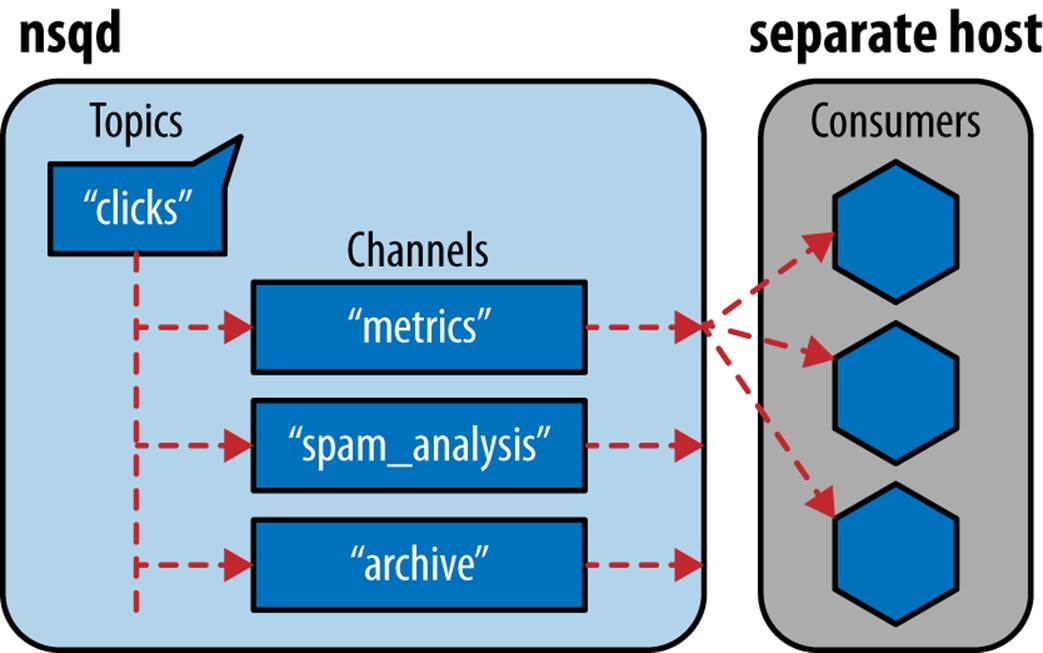
Figure 10-1. NSQ’s pub/sub-like topology
The benefit of spreading the messages out among a potentially large pool of consumers is essentially automatic load balancing. If a message takes quite a long time to process, that consumer will not signal to NSQ that it is ready for more messages until it’s done, and thus the other consumers will get the majority of future messages (until that original consumer is ready to process again). In addition, it allows existing consumers to disconnect (whether by choice or because of failure) and new consumers to connect to the cluster while still maintaining processing power within a particular subscription group. For example, if we find that “metrics” takes quite a while to process and often is not keeping up with demand, we can simply add more processes to the consumer pool for that subscription group, giving us more processing power. On the other hand, if we see that most of our processes are idle (i.e., not getting any messages), we can easily remove consumers from this subscription pool.
It is also important to note that anything can publish data. A consumer doesn’t simply need to be a consumer—it can consume data from one topic and then publish it to another topic. In fact, this chain is an important workflow when it comes to this paradigm for distributed computing. Consumers will read from a topic of data, transform the data in some way, and then publish the data onto a new topic that other consumers can further transform. In this way, different topics represent different data, subscription groups represent different transformations on the data, and consumers are the actual workers who transform individual messages.
Furthermore, there is an incredible redundancy in this system. There can be many nsqd processes that each consumer connects to, and there can be many consumers connected to a particular subscription. This makes it so that there is no single point of failure and your system will be robust even if several machines disappear. We can see in Figure 10-2 that even if one of the computers in the diagram goes down, the system is still able to deliver and process messages. In addition, since NSQ saves pending messages to disk when shutting down, unless the hardware loss is catastrophic your data will most likely still be intact and be delivered. Lastly, if a consumer is shut down before responding to a particular message, NSQ will resend that message to another consumer. This means that even as consumers get shut down, we know that all the messages in a topic will be responded to at least once.[27]
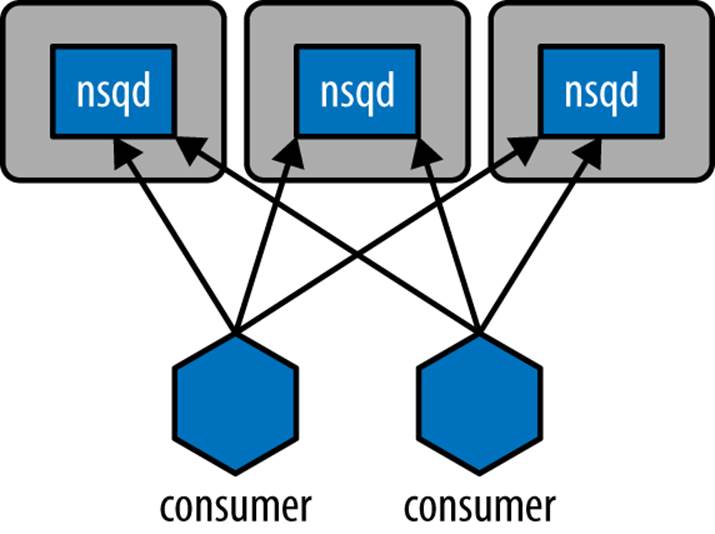
Figure 10-2. NSQ connection topology
Distributed Prime Calculation
Code that uses NSQ is generally asynchronous[28] (see Chapter 8 for a full explanation of this), although it doesn’t necessarily have to be. In the following example, we will create a pool of workers that read from a topic called numbers where the messages are simply JSON blobs with numbers in them. The consumers will read this topic, find out if the numbers are primes, and then write to another topic, depending on whether the number was prime. This will give us two new topics, primes and non_primes, that other consumers can connect to in order to do more calculations.[29]
As we’ve said before, there are many benefits to doing CPU-bound work like this. Firstly, we have all the guarantees of robustness, which may or may not be useful for this project. More importantly, however, we get automatic load balancing. That means that if one consumer gets a number that takes a particularly long time to process, the other consumers will pick up the slack.
We create a consumer by creating an nsq.Reader object with the topic and subscription group specified (as can be seen at the end of Example 10-10). We also must specify the location of the running nsqd instance (or the nsqlookupd instance, which we will not get into in this section). In addition, we specify a handler, which is simply a function that gets called for each message from the topic. To create a producer, we create an nsq.Writer object and specify the location of one or more nsqd instances to write to. This gives us the ability to write to nsq asynchronously, simply by specifying the topic name and the message.[30]
Example 10-10. Distributed prime calculation with NSQ
import nsq
from tornado import gen
from functools import partial
import ujson as json
@gen.coroutine
def write_message(topic, data, writer):
response = yield gen.Task(writer.pub, topic, data) # ![]()
if isinstance(response, nsq.Error):
print "Error with Message: {}: {}".format(data, response)
yield write_message(data, writer)
else:
print "Published Message: ", data
def calculate_prime(message, writer):
message.enable_async() # ![]()
data = json.loads(message.body)
prime = is_prime(data["number"])
data["prime"] = prime
if prime:
topic = 'primes'
else:
topic = 'non_primes'
output_message = json.dumps(data)
write_message(topic, output_message, writer)
message.finish() # ![]()
if __name__ == "__main__":
writer = nsq.Writer(['127.0.0.1:4150', ])
handler = partial(calculate_prime, writer=writer)
reader = nsq.Reader(
message_handler = handler,
nsqd_tcp_addresses = ['127.0.0.1:4150', ],
topic = 'numbers',
channel = 'worker_group_a',
)
nsq.run()
![]()
We will asynchronously write the result to a new topic, and retry writing if it fails for some reason.
![]()
By enabling async on a message, we can perform asynchronous operations while processing the message.
![]()
With async-enabled messages, we must signal to NSQ when we are done with a message.
In order to set up the NSQ ecosystem, we will start an instance of nsqd on our local machine:
$ nsqd
2014/05/10 16:48:42 nsqd v0.2.27 (built w/go1.2.1)
2014/05/10 16:48:42 worker id 382
2014/05/10 16:48:42 NSQ: persisting topic/channel metadata to nsqd.382.dat
2014/05/10 16:48:42 TCP: listening on [::]:4150
2014/05/10 16:48:42 HTTP: listening on [::]:4151
Now, we can start as many instances of our Python code (Example 10-10) as we want. In fact, we can have these instances running on other computers as long as the reference to the nsqd_tcp_address in the instantiation of the nsq.Reader is still valid. These consumers will connect tonsqd and wait for messages to be published on the numbers topic.
There are many ways data can be published to the numbers topic. We will use command-line tools to do this, since knowing how to poke and prod a system goes a long way in understanding how to properly deal with it. We can simply use the HTTP interface to publish messages to the topic:
$ for i in `seq 10000`
> do
> echo {\"number\": $i} | curl -d@- "http://127.0.0.1:4151/pub?topic=numbers"
> done
As this command starts running, we are publishing messages with different numbers in them to the numbers topic. At the same time, all of our producers will start outputting status messages indicating that they have seen and processed messages. In addition, these numbers are being published to either the primes or the non_primes topic. This allows us to have other data consumers that connect to either of these topics to get a filtered subset of our original data. For example, an application that requires only the prime numbers can simply connect to the primes topic and constantly have new primes for its calculation. We can see the status of our calculation by using the stats HTTP endpoint for nsqd:
$ curl "http://127.0.0.1:4151/stats"
nsqd v0.2.27 (built w/go1.2.1)
[numbers ] depth: 0 be-depth: 0 msgs: 3060 e2e%:
[worker_group_a ] depth: 1785 be-depth: 0 inflt: 1 def: 0
re-q: 0 timeout: 0 msgs: 3060 e2e%:
[V2 muon:55915 ] state: 3 inflt: 1 rdy: 0 fin: 1469
re-q: 0 msgs: 1469 connected: 24s
[primes ] depth: 195 be-depth: 0 msgs: 1274 e2e%:
[non_primes ] depth: 1274 be-depth: 0 msgs: 1274 e2e%:
We can see here that the numbers topic has one subscription group, worker_group_a, with one consumer. In addition, the subscription group has a large depth of 1,785 messages, which means that we are putting messages into NSQ faster than we can process them. This would be an indication to add more consumers so that we have more processing power to get through more messages. Furthermore, we can see that this particular consumer has been connected for 24 seconds, has processed 1,469 messages, and currently has 1 message in flight. This status endpoint gives quite a good deal of information to debug your NSQ setup! Lastly, we see the primes and non_primes topics, which have no subscribers or consumers. This means that the messages will be stored until a subscriber comes requesting the data.
NOTE
In production systems you can use the even more powerful tool nsqadmin, which provides a web interface with very detailed overviews of all topics/subscribers and consumers. In addition, it allows you to easily pause and delete subscribers and topics.
To actually see the messages, we would create a new consumer for the primes (or non-primes) topic that simply archives the results to a file or database. Alternatively, we can use the nsq_tail tool to take a peek at the data and see what it contains:
$ nsq_tail --topic primes --nsqd-tcp-address=127.0.0.1:4150
2014/05/10 17:05:33 starting Handler go-routine
2014/05/10 17:05:33 [127.0.0.1:4150] connecting to nsqd
2014/05/10 17:05:33 [127.0.0.1:4150] IDENTIFY response:
{MaxRdyCount:2500 TLSv1:false Deflate:false Snappy:false}
{"prime":true,"number":5}
{"prime":true,"number":7}
{"prime":true,"number":11}
{"prime":true,"number":13}
{"prime":true,"number":17}
Other Clustering Tools to Look At
Job processing systems using queues have existed since the start of the computer science industry, back when computers were very slow and lots of jobs needed to be processed. As a result, there are many libraries for queues, and many of these can be used in a cluster configuration. We strongly suggest that you pick a mature library with an active community behind it, supporting the same feature set that you’ll need and not too many additional features.
The more features a library has, the more ways you’ll find to misconfigure it and waste time on debugging. Simplicity is generally the right aim when dealing with clustered solutions. Here are a few of the more commonly used clustering solutions:
§ Celery (BSD license) is a widely used asynchronous task queue using a distributed messaging architecture, written in Python. It supports Python, PyPy, and Jython. Typically it uses RabbitMQ as the message broker, but it also supports Redis, MongoDB, and other storage systems. It is often used in web development projects. Andrew Godwin discusses Celery in Task Queues at Lanyrd.com.
§ Gearman (BSD license) is a multiplatform job processing system. It is very useful if you are integrating job processing using different technologies. Bindings are available for Python, PHP, C++, Perl, and many other languages.
§ PyRes is a Redis-based lightweight task manager for Python. Jobs are added to queues in Redis and consumers are set up to process them, optionally passing results back on a new queue. It is a very easy system to start with if your needs are light and Python-only.
§ Amazon’s Simple Queue Service (SQS) is a job processing system integrated into Amazon Web Services. Job consumers and producers can live inside AWS or can be external, so SQS is easy to start with and supports easy migration into the cloud. Library support exists for many languages.
Clusters can also be used for distributed numpy processing, but this is a relatively young development in the Python world. Both Enthought and Continuum have solutions, via the distarray and blaze packages. Note that these packages attempt to deal with the complicated problems of synchronization and data locality (there is no one-size-fits-all solution) on your behalf, so be aware that you’ll probably have to think about how your data is laid out and accessed.
Wrap-Up
So far in the book, we’ve looked at profiling to understand slow parts of your code, compiling and using numpy to make your code run faster, and various approaches to multiple processes and computers. In the penultimate chapter, we’ll look at ways of using less RAM through different data structures and probabilistic approaches. These lessons could help you to keep all your data on one machine, avoiding the need to run a cluster.
[26] For further details, see http://bit.ly/parallel-exceptions.
[27] This can be quite advantageous when we’re working in AWS, where we can have our nsqd processes running on a reserved instance and our consumers working on a cluster of spot instances.
[28] This asynchronicity comes from NSQ’s protocol for sending messages to consumers being push-based. This makes it so our code can have an asynchronous read from our connection to NSQ happen in the background and wake up when a message is found.
[29] This sort of chaining of data analysis is called pipelining and can be an effective way to perform multiple types of analysis on the same data efficiently.
[30] You can also easily publish a message manually with an HTTP call; however, this nsq.Writer object simplifies much of the error handling.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.