Data Science from Scratch: First Principles with Python (2015)
Chapter 13. Naive Bayes
It is well for the heart to be naive and for the mind not to be.
Anatole France
A Really Dumb Spam Filter
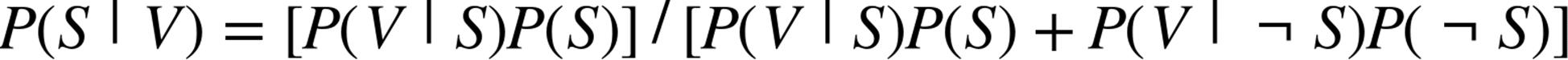
If we have a large collection of messages we know are spam, and a large collection of messages we know are not spam, then we can easily estimate ![]() and
and ![]() . If we further assume that any message is equally likely to be spam or not-spam (so that
. If we further assume that any message is equally likely to be spam or not-spam (so that ![]() ), then:
), then:
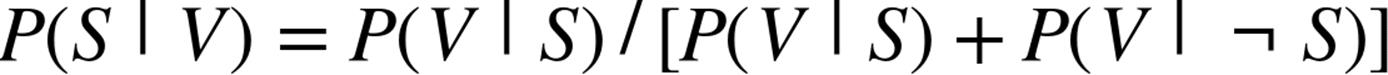
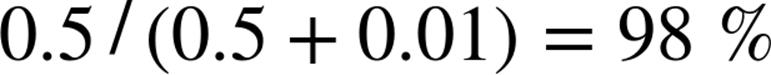
Imagine now that we have a vocabulary of many words ![]() . To move this into the realm of probability theory, we’ll write
. To move this into the realm of probability theory, we’ll write ![]() for the event “a message contains the word
for the event “a message contains the word ![]() .” Also imagine that (through some unspecified-at-this-point process) we’ve come up with an estimate
.” Also imagine that (through some unspecified-at-this-point process) we’ve come up with an estimate ![]() for the probability that a spam message contains the ith word, and a similar estimate
for the probability that a spam message contains the ith word, and a similar estimate ![]() for the probability that a nonspam message contains the ith word.
for the probability that a nonspam message contains the ith word.
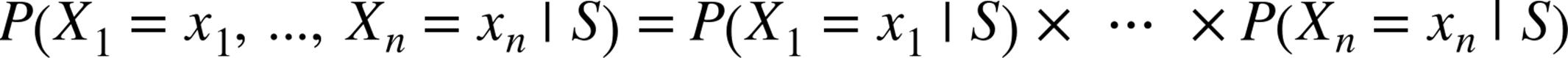
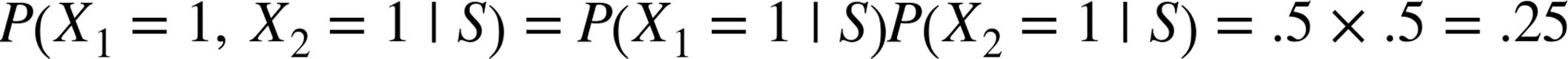
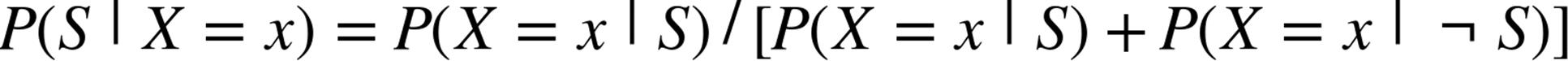
In practice, you usually want to avoid multiplying lots of probabilities together, to avoid a problem called underflow, in which computers don’t deal well with floating-point numbers that are too close to zero. Recalling from algebra that ![]() and that
and that![]() , we usually compute
, we usually compute ![]() as the equivalent (but floating-point-friendlier):
as the equivalent (but floating-point-friendlier):
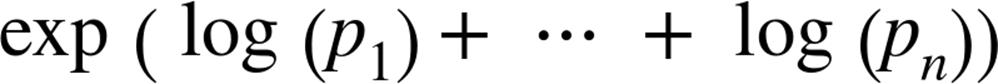
The only challenge left is coming up with estimates for ![]() and
and ![]() , the probabilities that a spam message (or nonspam message) contains the word
, the probabilities that a spam message (or nonspam message) contains the word ![]() . If we have a fair number of “training” messages labeled as spam and not-spam, an obvious first try is to estimate
. If we have a fair number of “training” messages labeled as spam and not-spam, an obvious first try is to estimate ![]() simply as the fraction of spam messages containing word
simply as the fraction of spam messages containing word ![]() .
.
This causes a big problem, though. Imagine that in our training set the vocabulary word “data” only occurs in nonspam messages. Then we’d estimate ![]() . The result is that our Naive Bayes classifier would always assign spam probability 0 to any message containing the word “data,” even a message like “data on cheap viagra and authentic rolex watches.” To avoid this problem, we usually use some kind of smoothing.
. The result is that our Naive Bayes classifier would always assign spam probability 0 to any message containing the word “data,” even a message like “data on cheap viagra and authentic rolex watches.” To avoid this problem, we usually use some kind of smoothing.

Similarly for ![]() . That is, when computing the spam probabilities for the ith word, we assume we also saw k additional spams containing the word and k additional spams not containing the word.
. That is, when computing the spam probabilities for the ith word, we assume we also saw k additional spams containing the word and k additional spams not containing the word.
For example, if “data” occurs in 0/98 spam documents, and if k is 1, we estimate ![]() as 1/100 = 0.01, which allows our classifier to still assign some nonzero spam probability to messages that contain the word “data.”
as 1/100 = 0.01, which allows our classifier to still assign some nonzero spam probability to messages that contain the word “data.”
deftokenize(message):
message=message.lower()# convert to lowercase
all_words=re.findall("[a-z0-9']+",message)# extract the words
returnset(all_words)# remove duplicates
defcount_words(training_set):
"""training set consists of pairs (message, is_spam)"""
counts=defaultdict(lambda:[0,0])
formessage,is_spamintraining_set:
forwordintokenize(message):
counts[word][0ifis_spamelse1]+=1
returncounts
defword_probabilities(counts,total_spams,total_non_spams,k=0.5):
"""turn the word_counts into a list of triplets
w, p(w | spam) and p(w | ~spam)"""return[(w,
(spam+k)/(total_spams+2*k),
(non_spam+k)/(total_non_spams+2*k))
forw,(spam,non_spam)incounts.iteritems()]
defspam_probability(word_probs,message):
message_words=tokenize(message)
log_prob_if_spam=log_prob_if_not_spam=0.0
# iterate through each word in our vocabulary
forword,prob_if_spam,prob_if_not_spaminword_probs:
# if *word* appears in the message,
# add the log probability of seeing it
ifwordinmessage_words:
log_prob_if_spam+=math.log(prob_if_spam)
log_prob_if_not_spam+=math.log(prob_if_not_spam)
# if *word* doesn't appear in the message
# add the log probability of _not_ seeing it
# which is log(1 - probability of seeing it)
else:
log_prob_if_spam+=math.log(1.0-prob_if_spam)
log_prob_if_not_spam+=math.log(1.0-prob_if_not_spam)
prob_if_spam=math.exp(log_prob_if_spam)
prob_if_not_spam=math.exp(log_prob_if_not_spam)
returnprob_if_spam/(prob_if_spam+prob_if_not_spam)
classNaiveBayesClassifier:
def__init__(self,k=0.5):
self.k=k
self.word_probs=[]
deftrain(self,training_set):
# count spam and non-spam messages
num_spams=len([is_spam
formessage,is_spamintraining_set
ifis_spam])
num_non_spams=len(training_set)-num_spams
# run training data through our "pipeline"
word_counts=count_words(training_set)
self.word_probs=word_probabilities(word_counts,
num_spams,
num_non_spams,
self.k)
defclassify(self,message):
returnspam_probability(self.word_probs,message)
Testing Our Model
importglob,re
# modify the path with wherever you've put the filespath=r"C:\spam\*\*"
data=[]
# glob.glob returns every filename that matches the wildcarded pathforfninglob.glob(path):
is_spam="ham"notinfn
withopen(fn,'r')asfile:
forlineinfile:
ifline.startswith("Subject:"):
# remove the leading "Subject: " and keep what's left
subject=re.sub(r"^Subject: ","",line).strip()
data.append((subject,is_spam))
random.seed(0)# just so you get the same answers as me
train_data,test_data=split_data(data,0.75)
classifier=NaiveBayesClassifier()
classifier.train(train_data)# triplets (subject, actual is_spam, predicted spam probability)classified=[(subject,is_spam,classifier.classify(subject))
forsubject,is_spamintest_data]
# assume that spam_probability > 0.5 corresponds to spam prediction# and count the combinations of (actual is_spam, predicted is_spam)counts=Counter((is_spam,spam_probability>0.5)
for_,is_spam,spam_probabilityinclassified)
# sort by spam_probability from smallest to largestclassified.sort(key=lambdarow:row[2])
# the highest predicted spam probabilities among the non-spamsspammiest_hams=filter(lambdarow:notrow[1],classified)[-5:]
# the lowest predicted spam probabilities among the actual spamshammiest_spams=filter(lambdarow:row[1],classified)[:5]
defp_spam_given_word(word_prob):
"""uses bayes's theorem to compute p(spam | message contains word)"""
# word_prob is one of the triplets produced by word_probabilities
word,prob_if_spam,prob_if_not_spam=word_prob
returnprob_if_spam/(prob_if_spam+prob_if_not_spam)
words=sorted(classifier.word_probs,key=p_spam_given_word)
spammiest_words=words[-5:]
hammiest_words=words[:5]
§ Look at the message content, not just the subject line. You’ll have to be careful how you deal with the message headers.
§ Our classifier takes into account every word that appears in the training set, even words that appear only once. Modify the classifier to accept an optional min_count threshhold and ignore tokens that don’t appear at least that many times.
§ The tokenizer has no notion of similar words (e.g., “cheap” and “cheapest”). Modify the classifier to take an optional stemmer function that converts words to equivalence classes of words. For example, a really simple stemmer function might be:
§defdrop_final_s(word):
returnre.sub("s$","",word)
Creating a good stemmer function is hard. People frequently use the Porter Stemmer.
§ Although our features are all of the form “message contains word ![]() ,” there’s no reason why this has to be the case. In our implementation, we could add extra features like “message contains a number” by creating phony tokens like contains:number and modifying the
,” there’s no reason why this has to be the case. In our implementation, we could add extra features like “message contains a number” by creating phony tokens like contains:number and modifying the tokenizer to emit them when appropriate.
For Further Exploration
§ Paul Graham’s articles “A Plan for Spam” and “Better Bayesian Filtering” (are interesting and) give more insight into the ideas behind building spam filters.
§ scikit-learn contains a BernoulliNB model that implements the same Naive Bayes algorithm we implemented here, as well as other variations on the model.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.