Natural Language Processing - Data Science from Scratch: First Principles with Python (2015)
Data Science from Scratch: First Principles with Python (2015)
Chapter 20.Natural Language Processing
They have been at a great feast of languages, and stolen the scraps.
William Shakespeare
Natural language processing(NLP) refersto computational techniques involving language. It’s a broad field, but we’ll look at a few techniques both simple and not simple.
Word Clouds
InChapter 1, we computedword counts of users’ interests. One approach to visualizing words and counts is word clouds, which artistically lay out the words with sizes proportional to their counts.
Generally, though, data scientists don’t think much of word clouds, in large part because the placement of the words doesn’t mean anything other than “here’s some space where I was able to fit a word.”
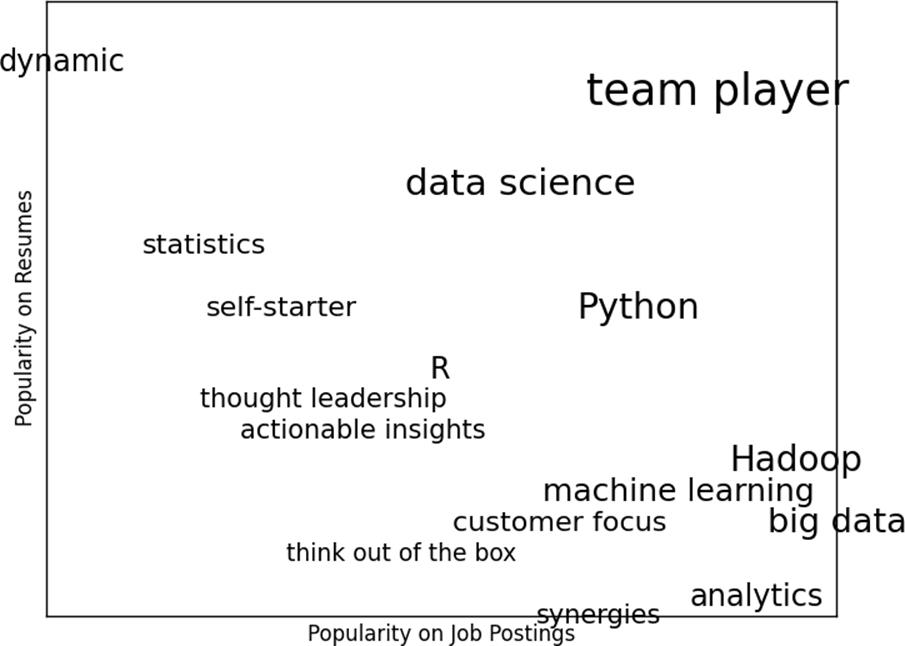
If you ever are forced to create a word cloud, think about whether you can make the axes convey something. For example, imagine that, for each of some collection of data science-related buzzwords, you have two numbers between 0 and 100 — the first representing how frequently it appears in job postings, the second how frequently it appears on resumes:
("actionable insights",40,30),("think out of the box",45,10),
("self-starter",30,50),("customer focus",65,15),
("thought leadership",35,35)]
The word cloud approach is just to arrange the words on a page in a cool-looking font (Figure 20-1).
Figure 20-1.Buzzword cloud
This looks neat but doesn’t really tell us anything. A more interesting approach might be to scatter them so that horizontal position indicates posting popularity and vertical position indicates resume popularity, which produces a visualization that conveys a few insights (Figure 20-2):
deftext_size(total):
"""equals 8 if total is 0, 28 if total is 200"""
return8+total/200*20
forword,job_popularity,resume_popularityindata:
plt.text(job_popularity,resume_popularity,word,
ha='center',va='center',
size=text_size(job_popularity+resume_popularity))
plt.xlabel("Popularity on Job Postings")
plt.ylabel("Popularity on Resumes")
plt.axis([0,100,0,100])
plt.xticks([])
plt.yticks([])
plt.show()
Figure 20-2.A more meaningful (if less attractive) word cloud
n-gram Models
The DataSciencester VP of Search Engine Marketingwants to create thousands of web pages about data science so that your site will rank higher in search results for data science-related terms. (You attempt to explain to her that search engine algorithms are clever enough that this won’t actually work, but she refuses to listen.)
Of course, she doesn’t want to write thousands of web pages, nor does she want to pay a horde of “content strategists” to do so. Instead she asks you whether you can somehow programatically generate these web pages. To do this, we’ll need some way of modeling language.
One approach is to start with a corpus of documents and learn a statistical model of language. In our case, we’ll start with Mike Loukides’s essay“What is data science?”
As inChapter 9, we’ll userequestsandBeautifulSoupto retrieve the data.There are a couple of issues worth calling attention to.
The first is that the apostrophes in the text are actually the Unicode characteru"\u2019". We’ll create a helper function to replace them with normal apostrophes:
deffix_unicode(text):
returntext.replace(u"\u2019","'")
The second issue is that once we get the text of the web page, we’ll want to split it into a sequence of words and periods (so that we can tell where sentences end). We can do this usingre.findall():
We certainly could (and likely should) clean this data further. There is still some amount of extraneous text in the document (for example, the first word is “Section”), and we’ve split on midsentence periods (for example, in “Web 2.0”), and there are a handful of captions and lists sprinkled throughout. Having said that, we’ll work with thedocumentas it is.
Now that we have the text as a sequence of words, we can model language in the following way: given some starting word (say “book”) we look at all the words that follow it in the source documents (here “isn’t,” “a,” “shows,” “demonstrates,” and “teaches”). We randomly choose one of these to be the next word, and we repeat the process until we get to a period, which signifies the end of the sentence. We call this abigram model, asit is determined completely by the frequencies of the bigrams (word pairs) in the original data.
What about a starting word? We can just pick randomly from words thatfollowa period. To start, let’s precompute the possible word transitions. Recall thatzipstops when any of its inputs is done, so thatzip(document, document[1:])gives us precisely the pairs of consecutive elements ofdocument:
bigrams=zip(document,document[1:])
transitions=defaultdict(list)
forprev,currentinbigrams:
transitions[prev].append(current)
Now we’re ready to generate sentences:
defgenerate_using_bigrams():
current="."# this means the next word will start a sentence
current=random.choice(next_word_candidates)# choose one at random
result.append(current)# append it to results
ifcurrent==".":return" ".join(result)# if "." we're done
The sentences it produces are gibberish, but they’re the kind of gibberish you might put on your website if you were trying to sound data-sciencey. For example:
If you may know which are you want to data sort the data feeds web friend someone on trending topics as the data in Hadoop is the data science requires a book demonstrates why visualizations are but we do massive correlations across many commercial disk drives in Python language and creates more tractable form making connections then use and uses it to solve a data.
Bigram Model
We can make thesentences less gibberishy by looking attrigrams, triplets of consecutive words. (More generally, you might look atn-gramsconsisting ofnconsecutive words,but three will be plenty for us.) Now the transitions will depend on the previoustwowords:
trigrams=zip(document,document[1:],document[2:])
trigram_transitions=defaultdict(list)
starts=[]
forprev,current,nextintrigrams:
ifprev==".":# if the previous "word" was a period
starts.append(current)# then this is a start word
trigram_transitions[(prev,current)].append(next)
Notice that now we have to track the starting words separately. We can generate sentences in pretty much the same way:
defgenerate_using_trigrams():
current=random.choice(starts)# choose a random starting word
In hindsight MapReduce seems like an epidemic and if so does that give us new insights into how economies work That’s not a question we could even have asked a few years there has been instrumented.
Trigram Model
Of course, they sound better because at each step the generation process has fewer choices, and at many steps only a single choice. This means that you frequently generate sentences (or at least long phrases) that were seen verbatim in the original data. Having more data would help; it would also work better if you collectedn-grams from multiple essays about data science.
Grammars
A different approach to modeling language is withgrammars, rules for generating acceptable sentences.In elementary school, you probably learned about parts of speech and how to combine them. For example, if you had a really bad English teacher, you might say that a sentence necessarily consists of anounfollowed by averb. If you then have a list of nouns and verbs, you can generate sentences according to the rule.
We’ll define a slightly more complicated grammar:
grammar={
"_S":["_NP _VP"],
"_NP":["_N",
"_A _NP _P _A _N"],
"_VP":["_V",
"_V _NP"],
"_N":["data science","Python","regression"],
"_A":["big","linear","logistic"],
"_P":["about","near"],
"_V":["learns","trains","tests","is"]
}
I made up the convention that names starting with underscores refer torulesthat need further expanding, and that other names areterminalsthat don’t need further processing.
So, for example,"_S"is the “sentence” rule, which produces a"_NP"(“noun phrase”) rule followed by a"_VP"(“verb phrase”) rule.
The verb phrase rule can produce either the"_V"(“verb”) rule, or the verb rule followed by the noun phrase rule.
Notice that the"_NP"rule contains itself in one of its productions. Grammars can be recursive, which allows even finite grammars like this to generate infinitely many different sentences.
How do we generate sentences from this grammar? We’ll start with a list containing the sentence rule["_S"]. And then we’ll repeatedly expand each rule by replacing it with a randomly chosen one of its productions. We stop when we have a list consisting solely of terminals.
For example, one such progression might look like:
How do we implement this? Well, to start, we’ll create a simple helper function to identify terminals:
defis_terminal(token):
returntoken[0]!="_"
Next we need to write a function to turn a list of tokens into a sentence. We’ll look for the first nonterminal token.If we can’t find one, that means we have a completed sentence and we’re done.
If we do find a nonterminal, then we randomly choose one of its productions. If that production is a terminal (i.e., a word), we simply replace the token with it. Otherwise it’s a sequence of space-separated nonterminal tokens that we need tosplitand then splice into the current tokens. Either way, we repeat the process on the new set of tokens.
# if we get here we had all terminals and are done
returntokens
And now we can start generating sentences:
defgenerate_sentence(grammar):
returnexpand(grammar,["_S"])
Try changing the grammar — add more words, add more rules, add your own parts of speech — until you’re ready to generate as many web pages as your company needs.
Grammars are actually more interesting when they’re used in the other direction. Given a sentence we can use a grammar toparsethe sentence. This then allows us to identify subjects and verbs and helps us make sense of the sentence.
Using data science to generate text is a neat trick; using it tounderstandtext is more magical. (See“For Further Investigation”for libraries that you could use for this.)
An Aside: Gibbs Sampling
Generating samples from some distributions is easy. We can get uniform random variables with:
random.random()
and normal random variables with:
inverse_normal_cdf(random.random())
But some distributions are harder to sample from.Gibbs samplingis a techniquefor generating samples from multidimensional distributions when we only know some of the conditional distributions.
For example, imagine rolling two dice. Letxbe the value of the first die andybe the sum of the dice, and imagine you wanted to generate lots of (x, y) pairs. In this case it’s easy to generate the samples directly:
defroll_a_die():
returnrandom.choice([1,2,3,4,5,6])
defdirect_sample():
d1=roll_a_die()
d2=roll_a_die()
returnd1,d1+d2
But imagine that you only knew the conditional distributions. The distribution ofyconditional onxis easy — if you know the value ofx,yis equally likely to bex+ 1,x+ 2,x+ 3,x+ 4,x+ 5, orx+ 6:
defrandom_y_given_x(x):
"""equally likely to be x + 1, x + 2, ... , x + 6"""
returnx+roll_a_die()
The other direction is more complicated. For example, if you know thatyis 2, then necessarilyxis 1 (since the only way two dice can sum to 2 is if both of them are 1). If you knowyis 3, thenxis equally likely to be 1 or 2. Similarly, ifyis 11, thenxhas to be either 5 or 6:
defrandom_x_given_y(y):
ify<=7:
# if the total is 7 or less, the first die is equally likely to be
# 1, 2, ..., (total - 1)
returnrandom.randrange(1,y)
else:
# if the total is 7 or more, the first die is equally likely to be
# (total - 6), (total - 5), ..., 6
returnrandom.randrange(y-6,7)
The way Gibbs sampling works is that we start with any (valid) value forxandyand then repeatedly alternate replacingxwith a random value picked conditional onyand replacingywith a random value picked conditional onx. After a number of iterations, the resulting values ofxandywill represent a sample from the unconditional joint distribution:
defgibbs_sample(num_iters=100):
x,y=1,2# doesn't really matter
for_inrange(num_iters):
x=random_x_given_y(y)
y=random_y_given_x(x)
returnx,y
You can check that this gives similar results to the direct sample:
defcompare_distributions(num_samples=1000):
counts=defaultdict(lambda:[0,0])
for_inrange(num_samples):
counts[gibbs_sample()][0]+=1
counts[direct_sample()][1]+=1
returncounts
We’ll use this technique in the next section.
Topic Modeling
When we builtour Data Scientists You Should Know recommender inChapter 1, we simply looked for exact matches in people’s stated interests.
A more sophisticated approach to understanding our users’ interests might try to identify thetopicsthat underlie those interests. A technique calledLatent Dirichlet Analysis(LDA) is commonly used to identify common topics in a set of documents.We’ll apply it to documents that consist of each user’s interests.
LDA has some similarities to the Naive Bayes Classifier we built inChapter 13, in that it assumes a probabilistic model for documents. We’ll gloss over the hairier mathematical details, but for our purposes the model assumes that:
§ There is some fixed numberKof topics.
§ There is a random variable that assigns each topic an associated probability distribution over words. You should think of this distribution as the probability of seeing wordwgiven topick.
§ There is another random variable that assigns each document a probability distribution over topics. You should think of this distribution as the mixture of topics in documentd.
§ Each word in a document was generated by first randomly picking a topic (from the document’s distribution of topics) and then randomly picking a word (from the topic’s distribution of words).
In particular, we have a collection ofdocumentseach of which is alistof words. And we have a corresponding collection ofdocument_topicsthat assigns a topic (here a number between 0 andK- 1) to each word in each document.
So that the fifth word in the fourth document is:
documents[3][4]
and the topic from which that word was chosen is:
document_topics[3][4]
This very explicitly defines each document’s distribution over topics, and it implicitly defines each topic’s distribution over words.
We can estimate the likelihood that topic 1 produces a certain word by comparing how many times topic 1 produces that word with how many times topic 1 producesanyword. (Similarly, when we built a spam filter inChapter 13, we compared how many times each word appeared in spams with the total number of words appearing in spams.)
Although these topics are just numbers, we can give them descriptive names by looking at the words on which they put the heaviest weight. We just have to somehow generate thedocument_topics. This is where Gibbs sampling comes into play.
We start by assigning every word in every document a topic completely at random. Now we go through each document one word at a time. For that word and document, we construct weights for each topic that depend on the (current) distribution of topics in that document and the (current) distribution of words for that topic. We then use those weights to sample a new topic for that word. If we iterate this process many times, we will end up with a joint sample from the topic-word distribution and the document-topic distribution.
To start with, we’ll need a function to randomly choose an index based on an arbitrary set of weights:
defsample_from(weights):
"""returns i with probability weights[i] / sum(weights)"""
total=sum(weights)
rnd=total*random.random()# uniform between 0 and total
For instance, if you give it weights[1, 1, 3]then one-fifth of the time it will return 0, one-fifth of the time it will return 1, and three-fifths of the time it will return 2.
Our documents are our users’ interests, which look like:
For example, once we populate these, we can find, for example, the number of words indocuments[3]associated with topic 1 as:
document_topic_counts[3][1]
And we can find the number of timesnlpis associated with topic 2 as:
topic_word_counts[2]["nlp"]
Now we’re ready to define our conditional probability functions. As inChapter 13, each has a smoothing term that ensures every topic has a nonzero chance of being chosen in any document and that every word has a nonzero chance of being chosen for any topic:
defp_topic_given_document(topic,d,alpha=0.1):
"""the fraction of words in document _d_
that are assigned to _topic_ (plus some smoothing)"""
return((document_topic_counts[d][topic]+alpha)/
(document_lengths[d]+K*alpha))
defp_word_given_topic(word,topic,beta=0.1):
"""the fraction of words assigned to _topic_
that equal _word_ (plus some smoothing)"""
return((topic_word_counts[topic][word]+beta)/
(topic_counts[topic]+W*beta))
We’ll use these to create the weights for updating topics:
There are solid mathematical reasons whytopic_weightis defined the way it is, but their details would lead us too far afield. Hopefully it makes at least intuitive sense that — given a word and its document — the likelihood of any topic choice depends on both how likely that topic is for the document and how likely that word is for the topic.
This is all the machinery we need. We start by assigning every word to a random topic, and populating our counters appropriately:
Our goal is to get a joint sample of the topics-words distribution and the documents-topics distribution. We do this using a form of Gibbs sampling that uses the conditional probabilities defined previously:
foriterinrange(1000):
fordinrange(D):
fori,(word,topic)inenumerate(zip(documents[d],
document_topics[d])):
# remove this word / topic from the counts
# so that it doesn't influence the weights
document_topic_counts[d][topic]-=1
topic_word_counts[topic][word]-=1
topic_counts[topic]-=1
document_lengths[d]-=1
# choose a new topic based on the weights
new_topic=choose_new_topic(d,word)
document_topics[d][i]=new_topic
# and now add it back to the counts
document_topic_counts[d][new_topic]+=1
topic_word_counts[new_topic][word]+=1
topic_counts[new_topic]+=1
document_lengths[d]+=1
What are the topics? They’re just numbers 0, 1, 2, and 3. If we want names for them we have to do that ourselves. Let’s look at the five most heavily weighted words for each (Table 20-1):
fork,word_countsinenumerate(topic_word_counts):
forword,countinword_counts.most_common():
ifcount>0:printk,word,count
Topic 0
Topic 1
Topic 2
Topic 3
Java
R
HBase
regression
Big Data
statistics
Postgres
libsvm
Hadoop
Python
MongoDB
scikit-learn
deep learning
probability
Cassandra
machine learning
artificial intelligence
pandas
NoSQL
neural networks
Table 20-1.Most common words per topic
Based on these I’d probably assign topic names:
topic_names=["Big Data and programming languages",
"Python and statistics",
"databases",
"machine learning"]
at which point we can see how the model assigns topics to each user’s interests:
and so on. Given the “ands” we needed in some of our topic names, it’s possible we should use more topics, although most likely we don’t have enough data to successfully learn them.
For Further Exploration
§ Natural Language Toolkitis a popular (and pretty comprehensive) library of NLP tools for Python. It has its own entirebook, which is available to read online.
§ gensimis a Python library for topic modeling, which is a better bet than our from-scratch model.