Data Science from Scratch: First Principles with Python (2015)
Chapter 9. Getting Data
To write it, it took three months; to conceive it, three minutes; to collect the data in it, all my life.
F. Scott Fitzgerald
stdin and stdout
# egrep.pyimportsys,re
# sys.argv is the list of command-line arguments# sys.argv[0] is the name of the program itself# sys.argv[1] will be the regex specified at the command lineregex=sys.argv[1]
# for every line passed into the scriptforlineinsys.stdin:
# if it matches the regex, write it to stdout
ifre.search(regex,line):
sys.stdout.write(line)
# line_count.pyimportsys
count=0
forlineinsys.stdin:
count+=1
# print goes to sys.stdoutcount
type SomeFile.txt|pythonegrep.py"[0-9]"|pythonline_count.py
cat SomeFile.txt | python egrep.py "[0-9]" | python line_count.pyNOTE
type SomeFile.txt | egrep.py "[0-9]" | line_count.py
# most_common_words.pyimportsys
fromcollectionsimportCounter
# pass in number of words as first argumenttry:num_words=int(sys.argv[1])
except:"usage: most_common_words.py num_words"
sys.exit(1)# non-zero exit code indicates error
counter=Counter(word.lower()# lowercase words
forlineinsys.stdin#
forwordinline.strip().split()# split on spaces
ifword)# skip empty 'words'
forword,countincounter.most_common(num_words):
sys.stdout.write(str(count))
sys.stdout.write("\t")
sys.stdout.write(word)
sys.stdout.write("\n")
C:\DataScience>typethe_bible.txt|pythonmost_common_words.py10
64193 the51380 and34753 of13643 to12799 that12560 in10263 he9840 shall8987 unto8836for
NOTE
The Basics of Text Files
# 'r' means read-onlyfile_for_reading=open('reading_file.txt','r')
# 'w' is write -- will destroy the file if it already exists!file_for_writing=open('writing_file.txt','w')
# 'a' is append -- for adding to the end of the filefile_for_appending=open('appending_file.txt','a')
# don't forget to close your files when you're donefile_for_writing.close()withopen(filename,'r')asf:
data=function_that_gets_data_from(f)
# at this point f has already been closed, so don't try to use itprocess(data)starts_with_hash=0
withopen('input.txt','r')asf:
forlineinfile:# look at each line in the file
ifre.match("^#",line):# use a regex to see if it starts with '#'
starts_with_hash+=1# if it does, add 1 to the count
defget_domain(email_address):
"""split on '@' and return the last piece"""
returnemail_address.lower().split("@")[-1]
withopen('email_addresses.txt','r')asf:
domain_counts=Counter(get_domain(line.strip())
forlineinf
if"@"inline)
Delimited Files
6/20/2014 AAPL 90.91
6/20/2014 MSFT 41.68
6/20/2014 FB 64.5
6/19/2014 AAPL 91.86
6/19/2014 MSFT 41.51
6/19/2014 FB 64.34
importcsv
withopen('tab_delimited_stock_prices.txt','rb')asf:
reader=csv.reader(f,delimiter='\t')
forrowinreader:
date=row[0]
symbol=row[1]
closing_price=float(row[2])
process(date,symbol,closing_price)
date:symbol:closing_price
6/20/2014:AAPL:90.91
6/20/2014:MSFT:41.68
6/20/2014:FB:64.5
withopen('colon_delimited_stock_prices.txt','rb')asf:
reader=csv.DictReader(f,delimiter=':')
forrowinreader:
date=row["date"]
symbol=row["symbol"]
closing_price=float(row["closing_price"])
process(date,symbol,closing_price)
today_prices={'AAPL':90.91,'MSFT':41.68,'FB':64.5}
withopen('comma_delimited_stock_prices.txt','wb')asf:
writer=csv.writer(f,delimiter=',')
forstock,priceintoday_prices.items():
writer.writerow([stock,price])
results=[["test1","success","Monday"],
["test2","success, kind of","Tuesday"],
["test3","failure, kind of","Wednesday"],
["test4","failure, utter","Thursday"]]
# don't do this!withopen('bad_csv.txt','wb')asf:
forrowinresults:
f.write(",".join(map(str,row)))# might have too many commas in it!
f.write("\n")# row might have newlines as well!
test1,success,Mondaytest2,success,kindof,Tuesday
test3,failure,kindof,Wednesday
test4,failure,utter,Thursday
HTML and the Parsing Thereof
<html> <head>
<title>A web page</title>
</head>
<body>
<pid="author">Joel Grus</p>
<pid="subject">Data Science</p>
</body>
</html>pip install html5lib
frombs4importBeautifulSoup
importrequests
html=requests.get("http://www.example.com").text
soup=BeautifulSoup(html,'html5lib')
first_paragraph=soup.find('p')# or just soup.p
first_paragraph_text=soup.p.text
first_paragraph_words=soup.p.text.split()
first_paragraph_id=soup.p['id']# raises KeyError if no 'id'
first_paragraph_id2=soup.p.get('id')# returns None if no 'id'
all_paragraphs=soup.find_all('p')# or just soup('p')
paragraphs_with_ids=[pforpinsoup('p')ifp.get('id')]
important_paragraphs=soup('p',{'class':'important'})
important_paragraphs2=soup('p','important')
important_paragraphs3=[pforpinsoup('p')
if'important'inp.get('class',[])]
# warning, will return the same span multiple times# if it sits inside multiple divs# be more clever if that's the casespans_inside_divs=[span
fordivinsoup('div')# for each <div> on the page
forspanindiv('span')]# find each <span> inside it
Example: O’Reilly Books About Data
http://shop.oreilly.com/category/browse-subjects/data.do?
sortby=publicationDate&page=1
http://oreilly.com/terms/
Crawl-delay: 30
Request-rate: 1/30
NOTE
# you don't have to split the url like this unless it needs to fit in a bookurl="http://shop.oreilly.com/category/browse-subjects/"+\
"data.do?sortby=publicationDate&page=1"
soup=BeautifulSoup(requests.get(url).text,'html5lib')
<tdclass="thumbtext">
<divclass="thumbcontainer">
<divclass="thumbdiv">
<ahref="/product/9781118903407.do">
<imgsrc="..."/>
</a>
</div>
</div>
<divclass="widthchange">
<divclass="thumbheader">
<ahref="/product/9781118903407.do">Getting a Big Data Job For Dummies</a>
</div>
<divclass="AuthorName">By Jason Williamson</div>
<spanclass="directorydate">December 2014</span>
<divstyle="clear:both;">
<divid="146350">
<spanclass="pricelabel">
Ebook:
<spanclass="price">$29.99</span>
</span>
</div>
</div>
</div>
</td>tds=soup('td','thumbtext')
len(tds)
# 30defis_video(td):
"""it's a video if it has exactly one pricelabel, and if
the stripped text inside that pricelabel starts with 'Video'"""pricelabels=td('span','pricelabel')
return(len(pricelabels)==1and
pricelabels[0].text.strip().startswith("Video"))
len([tdfortdintdsifnotis_video(td)])
# 21 for me, might be different for youtitle=td.find("div","thumbheader").a.text
author_name=td.find('div','AuthorName').text
authors=[x.strip()forxinre.sub("^By ","",author_name).split(",")]
isbn_link=td.find("div","thumbheader").a.get("href")
# re.match captures the part of the regex in parenthesesisbn=re.match("/product/(.*)\.do",isbn_link).group(1)
date=td.find("span","directorydate").text.strip()
defbook_info(td):
"""given a BeautifulSoup <td> Tag representing a book,
extract the book's details and return a dict"""title=td.find("div","thumbheader").a.text
by_author=td.find('div','AuthorName').text
authors=[x.strip()forxinre.sub("^By ","",by_author).split(",")]
isbn_link=td.find("div","thumbheader").a.get("href")
isbn=re.match("/product/(.*)\.do",isbn_link).groups()[0]
date=td.find("span","directorydate").text.strip()
return{
"title":title,
"authors":authors,
"isbn":isbn,
"date":date
}
frombs4importBeautifulSoup
importrequests
fromtimeimportsleep
base_url="http://shop.oreilly.com/category/browse-subjects/"+\
"data.do?sortby=publicationDate&page="
books=[]
NUM_PAGES=31# at the time of writing, probably more by now
forpage_numinrange(1,NUM_PAGES+1):
"souping page",page_num,",",len(books)," found so far"
url=base_url+str(page_num)
soup=BeautifulSoup(requests.get(url).text,'html5lib')
fortdinsoup('td','thumbtext'):
ifnotis_video(td):
books.append(book_info(td))
# now be a good citizen and respect the robots.txt!
sleep(30)
NOTE
defget_year(book):
"""book["date"] looks like 'November 2014' so we need to
split on the space and then take the second piece"""returnint(book["date"].split()[1])
# 2014 is the last complete year of data (when I ran this)year_counts=Counter(get_year(book)forbookinbooks
ifget_year(book)<=2014)
importmatplotlib.pyplotasplt
years=sorted(year_counts)
book_counts=[year_counts[year]foryearinyears]
plt.plot(years,book_counts)
plt.ylabel("# of data books")plt.title("Data is Big!")plt.show()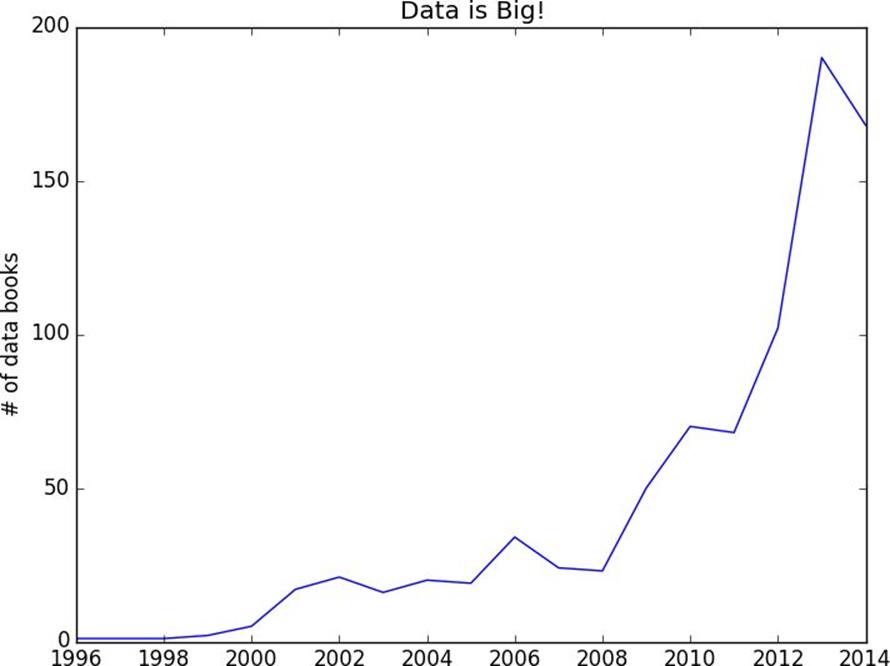
Figure 9-1. Number of data books per year
JSON (and XML)
{"title":"Data Science Book",
"author":"Joel Grus",
"publicationYear":2014,
"topics":["data","science","data science"]}
importjson
serialized="""{ "title" : "Data Science Book",
"author" : "Joel Grus", "publicationYear" : 2014, "topics" : [ "data", "science", "data science"] }"""# parse the JSON to create a Python dictdeserialized=json.loads(serialized)
if"data science"indeserialized["topics"]:
deserialized
<Book><Title>Data Science Book</Title>
<Author>Joel Grus</Author>
<PublicationYear>2014</PublicationYear>
<Topics>
<Topic>data</Topic>
<Topic>science</Topic>
<Topic>data science</Topic>
</Topics>
</Book>Using an Unauthenticated API
importrequests,json
endpoint="https://api.github.com/users/joelgrus/repos"
repos=json.loads(requests.get(endpoint).text)
u'created_at':u'2013-07-05T02:02:28Z'
pipinstallpython-dateutil
fromdateutil.parserimportparse
dates=[parse(repo["created_at"])forrepoinrepos]
month_counts=Counter(date.monthfordateindates)
weekday_counts=Counter(date.weekday()fordateindates)
last_5_repositories=sorted(repos,
key=lambdar:r["created_at"],
reverse=True)[:5]
last_5_languages=[repo["language"]
forrepoinlast_5_repositories]
Finding APIs
Getting Credentials
1. Go to https://apps.twitter.com/.
2. If you are not signed in, click Sign in and enter your Twitter username and password.
3. Click Create New App.
4. Give it a name (such as “Data Science”) and a description, and put any URL as the website (it doesn’t matter which one).
5. Agree to the Terms of Service and click Create.
6. Take note of the consumer key and consumer secret.
7. Click “Create my access token.”
8. Take note of the access token and access token secret (you may have to refresh the page).
Caution
fromtwythonimportTwython
=Twython(CONSUMER_KEY,CONSUMER_SECRET)
# search for tweets containing the phrase "data science"forstatusintwitter.search(q='"data science"')["statuses"]:
user=status["user"]["screen_name"].encode('utf-8')
text=status["text"].encode('utf-8')
user,":",text
print
NOTE
haithemnyc: Data scientists with the technical savvy & analytical chops to
derive meaning from big data are in demand. http://t.co/HsF9Q0dShP
RPubsRecent: Data Science http://t.co/6hcHUz2PHM
spleonard1: Using #dplyr in #R to work through a procrastinated assignment for
@rdpeng in @coursera data science specialization. So easy and Awesome.
fromtwythonimportTwythonStreamer
# appending data to a global variable is pretty poor form# but it makes the example much simplertweets=[]
classMyStreamer(TwythonStreamer):
"""our own subclass of TwythonStreamer that specifies
how to interact with the stream"""defon_success(self,data):
"""what do we do when twitter sends us data?
here data will be a Python dict representing a tweet""" # only want to collect English-language tweets
ifdata['lang']=='en':
tweets.append(data)
"received tweet #",len(tweets)
# stop when we've collected enough
iflen(tweets)>=1000:
self.disconnect()
defon_error(self,status_code,data):
status_code,data
self.disconnect()
stream=MyStreamer(CONSUMER_KEY,CONSUMER_SECRET,
ACCESS_TOKEN,ACCESS_TOKEN_SECRET)
# starts consuming public statuses that contain the keyword 'data'stream.statuses.filter(track='data')# if instead we wanted to start consuming a sample of *all* public statuses# stream.statuses.sample()top_hashtags=Counter(hashtag['text'].lower()
fortweetintweets
forhashtagintweet["entities"]["hashtags"])
top_hashtags.most_common(5)
NOTE
§ pandas is the primary library that data science types use for working with (and, in particular, importing) data.
§ Scrapy is a more full-featured library for building more complicated web scrapers that do things like follow unknown links.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.