Digital Archaeology (2014)
13. Excavating a Cloud
The rapid emergence of cloud computing has added a few new challenges for the digital investigator. Just what is cloud computing? A good definition appears on Novell’s Web site, which defines cloud computing as “a set of services and technologies that enable the delivery of computing services over the Internet in real time, allowing end users instant access to data and applications from any device with Internet access” (Novell 2011). A number of factors contribute to the complexity of identifying and extracting data relevant to an investigation where cloud computing is involved. To a very great extent, the technologies involved differ little from those discussed in the chapters on Web forensics and network forensics. But the approach can be a little different. A good place to begin would be a discussion of how cloud computing works and how it is used by corporations and individuals.
What Is Cloud Computing?
There seems to be some general agreement among basic vendors regarding what cloud computing really is. For the purposes of this book, I turned to an authority on the subject. The National Institute of Standards and Technology (NIST—the folks who brought us forensic tool testing) published a paper called The NIST Definition of Cloud Computing. It states, “Cloud computing is a model for enabling ubiquitous, convenient, on-demand network access to a shared pool of configurable computing resources (e.g., networks, servers, storage, applications, and services) that canbe rapidly provisioned and released with minimal management effort or service provider interaction” (Mell and Grance 2011). The authors define five essential characteristics of cloud computing:
• On-demand service: Computing capabilities, storage capacity, and availability are not limited by time or geography. All of these can be provisioned automatically without intervention from the service provider.
• Broadband network access: For multiple applications running on different platforms, it is necessary to have a standard interface over which traffic flows. It must be able to support both thick- and thin-client applications and be OS independent.
• Resource pooling: All available resources of the service provider should be readily available to all clients in a multitenant environment. This means that a single service provider (whether it be a server pool or a server/application combination) houses many tenants (clients sharing the architecture or running the software).
• Elasticity: Resources available to any given tenant can be scaled upward or downward as requirements change. This may be done manually or automatically. To the end users, the process must be completely transparent and require little or no intervention on their part.
• Measured service: Resource consumption must be monitored and reported accurately, assuring that the client does not pay for more services than are actually consumed. This monitoring must not impact on delivery or efficiency of service.
There are three service models as well, to be covered in the next section—Infrastructure as a Service (IaaS), Software as a Service (SaaS), and Platform as a Service (PaaS). Independent of the service model is the deployment model. NIST defines four deployment models:
• Private cloud: In this model, the infrastructure is constructed and managed for the exclusive benefit of a single entity. Within that entity multiple business units (or consumers) utilize the services provided. While the term “private” may imply direct ownership, this may not be the case. While the organization benefiting from the private cloud may indeed own the infrastructure, it is also possible to contract out these services to one of the commercial service providers who in turn manage an exclusive collection of hardware and software just for this one cloud. A single service provider might provide the same software application or infrastructure model to many clients, but each client is heterogeneously separated from the others.
• Community cloud: An organization consisting of a group of unified users with mutual interests band together and build their own cloud. An example of this would be an organization of realtors or a network of hospitals. The infrastructure might be owned and operated by one (or more) of the community members, or it might be contracted out to a third-party service provider.
• Public cloud: The public cloud is available to anyone who wants to subscribe to the services. Google and Amazon both provide large numbers of cloud-based applications and services to the general public. The cloud provider owns and operates the infrastructure. Not all public clouds are for-profit organizations. Libraries, government organizations, and such all operate public clouds.
• Hybrid cloud: Any two or all three of the above models can be effectively combined. Multiple cloud entities exist within a single larger cloud but are entwined by infrastructure or application architecture.
As you can see, cloud computing covers a lot of territory and entails multiple options for building systems and storing data. There is no one-stop shopping plaza for investigation techniques.
Shaping the Cloud
But wait. Clouds don’t have shape, do they? Aren’t they amorphous objects, shifting every moment with the slightest breeze? To a certain extent, yes, but if that was 100% true, how would banks and publishers and sales organizations embed the foundations of their businesses in it? The fact is that the services provided are locked in place—it is the users that shift with time. Three primary forms of service are provided by companies offering “cloud computing” services. These are
• Infrastructure as a Service
• Software as a Service
• Platform as a Service
Each one of these services offers a different set of challenges, so a quick overview of how each works is in order. However, there are some commonalities between them. All cloud systems have a front end (the client computer) and a back end (database and application servers) connected by middleware. The middleware is the software running on the service provider’s systems that acts as the traffic cop.
Since multiple clients are using a single (albeit extremely complex) system, the middleware also acts as the gatekeeper. The whole system is very much like the old time-sharing mainframes of old. When clients log onto the system, the meter starts running. When they log off, it stops. The server logs keep track of things like the amount of time utilized by the client, the volume of storage in use, and any other billable items. At the end of the month, the client gets an invoice for services used.
The real question to come into play—and the question most relevant to the digital investigator—is just how secure and accessible cloud data is. How does one get to the information stored, and how easily can unauthorized people access the information? And what happens to all the organization’s precious data if the service provider gets taken over by a competitor, is nationalized by a newly hostile third-world government, or is a mile from ground zero after a nuclear attack?
The advantages are fairly straightforward. Cloud computing, as you will see, does have the potential of bringing costs down for an organization. Both hardware and software costs are more easily controlled and more easily monitored. Users can access their data from anywhere they can find an Internet connection. The service engineer on a road trip can log into the company network just as easily from the motel room as from the office cubicle. A powerful incentive, especially for the smaller organization, is that a significant amount of infrastructure is made available to each client.
Infrastructure as a Service
Operating a server farm has never been cheap, and it’s never been easy. Most large companies considered it a necessary evil, and many smaller organizations built networks a server at a time and worried later about how the architecture was coming together. Some organizations seemed to have it together better than others. As broadband became faster and more readily available, some of these companies began to lease out their infrastructure to companies who either couldn’t afford to manage their own or simply chose not to.
A company who uses IaaS pays for the services, storage, and bandwidth that it actually uses. Capital expenditure on large numbers of servers, racks, storage devices, routers, switches, and so forth are drastically reduced. A company that outsources their infrastructure doesn’t have to hire a team of network administrators. Their service provider does all that for them. The theory is that since a single provider acts as the server farm for a large number of customers, the costs are spread out.
The reality of the situation is that when Jones Associates, Inc., leases its infrastructure from MYIAAS.COM, it isn’t leasing a bunch of physical computers. A concept called virtualization comes into play. A single, very powerful computer running a specialized operating system allows dozens (or even hundreds) of virtual machines (VMs) to run simultaneously on a single hardware platform (see Figure 13.1).
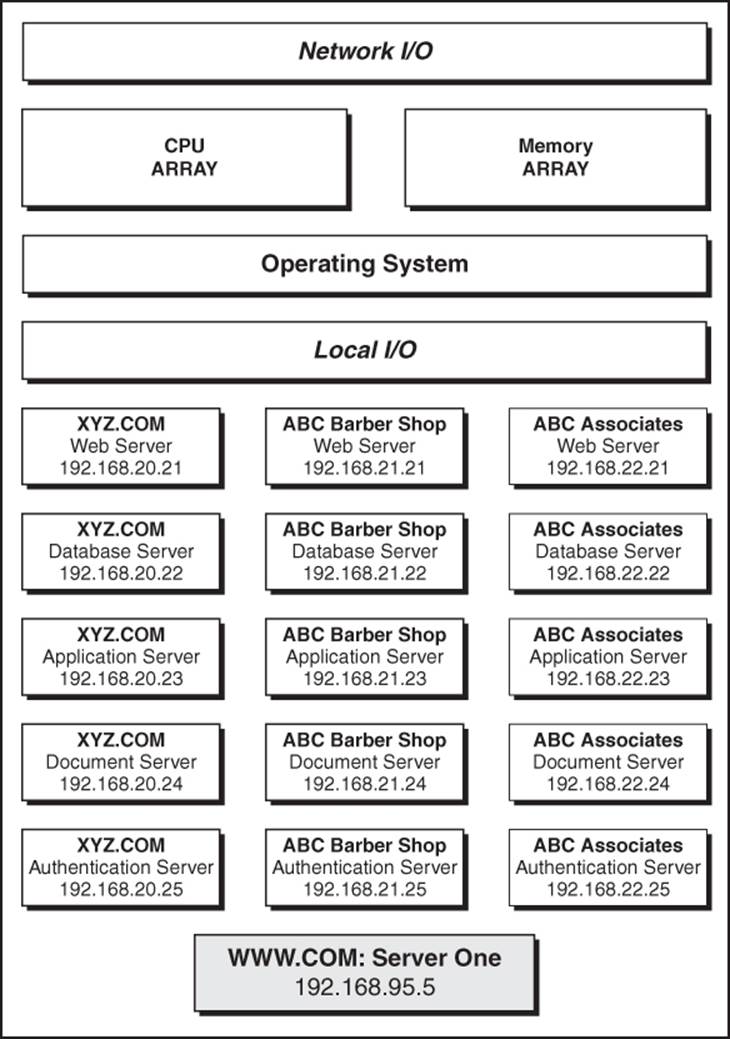
Figure 13.1 Virtual machines are the secret to success for the IAAS provider.
Each VM runs its own copy of an operating system, loads its own set of drivers, and thinks it’s the only game in town. To the administrator of a server (commonly referred to in virtualization as the node) running VMs, each machine is known as an instance. In Figure 13.1, you see an illustration of a single server hosting three client companies, each of which leases five instances on the server. In a real-world environment, each company would have its own range of IP addresses and varying numbers of instances.
When leasing a virtual computer from a service provider, a client has the ability to configure how fast a virtual CPU it will have, how much memory the server sees as its own, and how much long-term data storage to use. Once the servers are configured, they are available for the client to install their software. In addition to virtual servers, the client can also define network devices such as routers and switches as well as network attached storage or other storage arrays. Most companies that provide IaaS services bill monthly, based on actual resources used, sort of like the gas company.
Software as a Service
SaaS takes IaaS to the next level. SaaS contrasts with the more traditional form of software distribution in which each user of a computer purchases his own copy of the software he needs. In the SaaS model, the service provider not only provides a set of VMs, it also provides the software that runs on them. In a model known as hosted application management, software applications are delivered in real time over an Internet connection. Each user connects to the application over a Web browser. When the user connects, an instance of the software is launched on one of the VMs hosted by the service provider. Figure 13.2 is a conceptualized diagram of the process. In this illustration, the insurance agency utilizes two SaaS providers. One accepts online payments and the other is the insurance carrier. The carrier has a dedicated application for providing quotations to the agency and for processing claims. The online payment system allows the end users to make their payments to the agency and for the agency to make its payments to the carrier.
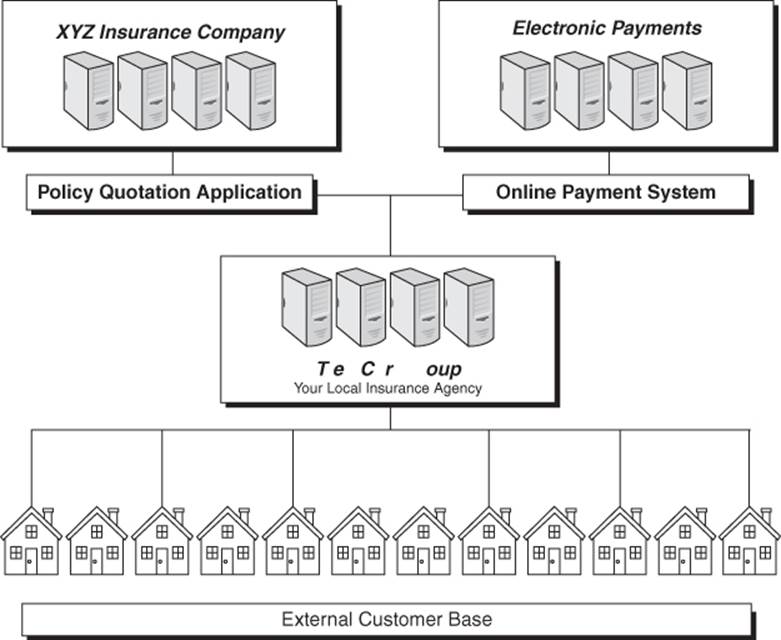
Figure 13.2 SaaS is frequently used by companies with industry-specific applications.
Many vertical markets take advantage of SaaS. There is no need to configure their industry-specific applications on local computers. Individuals can also find services here. Document management services, financial services, automatic form generation, and contact management are just a few examples of many implementations of this concept. If you use Google’s Gmail or Google Docs, you are using SaaS.
As mentioned earlier, cloud computing is multitenant. With SaaS, all clients will run a single version of the application with a single basic configuration. While this is not always the case, the vast majority of SaaS providers also include data storage as part of their service package. Data generated by the application is stored remotely and delivered via the browser.
The advantages of SaaS make it understandable why so many organizations find it attractive—especially for complex proprietary applications related to specific business functions. Administration of the application is offloaded to the vendor. There is no need to train your own IT staff in a new application. Updates and patches are tested and deployed for you as they become available. Since everyone runs the same versions of the software, there is no need to worry about compatibility issues.
SaaS can vary in how it manages certain forms of data, depending on whether it is a public SaaS, such as a Google- or Amazon-provided service, or a private SaaS, such as a contact management solution provided to a vertical market. The public apps are most likely going to provide a single sign-on (SSO) form of security to an entire set of applications. Once signed in, the user can access any of the applications or data storage elements that are covered under their subscription. If that account is compromised, there is little or no way of determining what data has been compromised or added. For example, if a suspect in a pornography case subscribes to Amazon Elastic Block Storage along with the company’s Virtual Private Cloud, knowing the password to one service automatically presumes access to the other service. If the suspect can introduce any reasonable doubt that another person had access to his password, then it is an easy defense to say, “I didn’t put that nasty file there.” There would be no authentic way of proving if that person was lying.
Platform as a Service
PaaS puts the entire computing environment onto the Web. With SaaS, you are running an application over an Internet connection. How the application is configured is completely out of your hands. With PaaS, you are running a system over an Internet connection. Hardware, infrastructure, and software are all deployed over a broadband connection. All the end user requires is a minimally equipped workstation with which to connect to the Internet. The primary difference between PaaS and SaaS is that the client had a degree of control over operating system choice and configuration. Additionally, with some vendors, it is possible to select from different versions of software offerings.
Applications that run on a PaaS can run on virtually any programming language the developer chooses. If a clients are sufficiently sophisticated, they can choose whether their application should be programmed in C+++, Java, Perl, or whatever. From a service provider’s standpoint, this means that each tenant exists in its own isolated little universe. As such, the client can exert a greater degree of control over security, availability, accessibility, and so forth.
Clients have more control over how information is stored and how logging is managed (assuming they have the expertise to do it). Logs can be configured to be stored on a third-party server or even sent back to their own local servers if the service provider allows for that. The advantage of doing this is that if hackers get into the system, they can’t alter logs.
The Implications of Cloud Forensics
When the digital investigator finds herself confronting a situation where the target of the investigation involves computing on the cloud, a new set of problems arise. Warrants issued by a court to search the computer systems of The Graves Group allow just that. She can search the devices owned and operated by The Graves Group. A search of resources on the cloud can be performed to the extent that such a search is limited to cloud infrastructure leased and controlled by the object of the warrant and can be performed on or from devices owned and controlled by that entity. To put it more succinctly, that warrant would allow the forensic copying of each hard disk owned by the Graves Group. It would not allow the copying of hard disks owned and operated by the service provider. Since the resources of cloud computing generally exist on VMs, the conventional bit copy from sector 0 to the end of the disk cannot be performed. There is no physical disk to clone. What appears as Drive C on the VM is a chunk of disk space carved out of a much larger medium, such as a NAS or SAN.
Collecting data from a cloud environment poses some challenges. First of all, the preservation of data must be accomplished in a manner found acceptable by the jurisdiction of the court issuing the warrant. However, if the service provider is a company located in another country, the process of obtaining evidentiary materials from their machines must conform to their laws and regulations as well. So if The Graves Group is contracted with a company in India to provide an IaaS solution, obtaining any material related to the service that is not directly obtainable from a computer inside of The Graves Group would require getting permission from the national and local governments governing the service provider. For example, if part of the solution is a document management solution, documents found and archived from the client workstations would require only a U.S. court order. To obtain metadata from the servers would require approaching the foreign government.
Evidence must be collected without compromising its integrity. In the paragraph above, I mention the difference between collecting the document and the metadata. In many cases, the document is of little value without the metadata. It is the metadata that proves when it was created, opened, edited, or copied. A document that says “I robbed the Glendale Train. Signed, Michael Graves” looks very incriminating. However, my sworn enemy may have written the letter and slipped into my system in a Trojan horse. Metadata tells us who originally created the file and in many applications may show the identities of everyone who edited to it. While it is true that metadata can be manipulated, a digital document with no metadata is of virtually no value. Substantial amounts of supporting evidence must be provided in order to create value.
Additionally, the methods by which the investigating team collects the evidence must be reproducible. Another team should be able to come up with the same data and reach similar conclusions, even if they use a somewhat different approach to collecting evidence. My FTK forensics suite should not be obtaining significantly different results than your Encase tool kit.
The next few pages are going to discuss several critical questions the investigating team must address whenever their investigation takes them into the cloud.
• The structure of the cloud
• Technical aspects of cloud forensics
• What types of data are stored by the service provider?
• What logs are generated by the service provider, and where are they stored?
• Where is it stored?
• How is it accessed?
• How is it possible to identify and capture the data required by the investigation?
• Evidentiary materials
• Do the service provider’s systems allow them to vouch for the authenticity of evidentiary material collected?
• How does the team separate evidentiary materials from data that is irrelevant and possibly even protected?
• Where is it stored?
• How is it accessed?
• How is it possible to identify and capture the data required by the investigation?
• Does the service provider store the data in some proprietary format or platform that will require their involvement in data extraction and analysis?
Finding answers to these questions is not simply a technical hurdle. There are legal ramifications (as mentioned earlier) as well as organizational challenges. A digital investigation involving cloud resources will require a significant degree of collaboration between the client, the service provider, and law enforcement. As the subject of the investigation, the client may not be supportive of your efforts. The service provider is mostly concerned about the consequences of failing to comply with a court order. On the other hand, they are equally concerned about protecting the security, privacy, and integrity of their other clients. Since they are a multitenant service, this becomes quite a challenge.
The best way to approach this discussion will be to divide it into the technical aspects, the organizational aspects, and the legal aspects. As each topic circles around to the next, the overall picture should become increasingly clear.
The Structure of the Cloud
For cloud computing to work, the service provider must design and configure three basic models that apply to each client on the system (Armbrust et al. 2009). All three of these models must be considered in preparing for an investigation involving cloud resources.
• A computational model
• A storage model
• A communications model
Each of these models generates and stores data specific to its role. The location and type of data to be collected varies from one model to the next. How the data is accessed is also different from one tier to the next. Cloud structure can also be centralized or distributed. A centralized cloud has most or all of its infrastructure in one or more data centers. Failover or disaster recovery sites will be located in a different area for safety and security reasons, but will still be contained within the confines of one or more data centers. Distributed clouds are scattered among numerous locations across a wide geographical area and generally communicate via the peer-to-peer communications model discussed later in this section.
The Computational Model
The computational model has been touched on in this chapter already. The platform (PaaS, IaaS, or SaaS) has some impact on how each customer is configured on the host platform. However, a key ingredient to all platforms is virtualization. Another element to be considered is elasticity. As a client’s needs increase or decrease, the provider needs to be able to increase or decrease the resources utilized accordingly, or the costs associated with maintaining the client are less easily controlled. Applications designed for cloud computing, as well as the hardware, must be able to scale up or down.
The Storage Model
Storage must be secure, scalable, and dependable. The clients must be assured that the information they store is only accessible by those they allow and not by those allowed by the service provider. As storage needs increase, the architecture needs to expand with those needs. Two options exist for scaling storage in any given environment. Block store storage models generally have a fixed amount of storage configured for the client. In order to increase or decrease this amount, the client submits a request and the service provider fulfills that request and adjusts their billing accordingly. Dynamic scaling grows or shrinks capacity as needs change. If a client has been utilizing an average of 20GB of storage over several months, then their virtual infrastructure will make a bit more than that available. When something comes along to suddenly change the capacity requirements, the client need take no action. The system will automatically adjust. So will the monthly bill.
Communications Model
All networks employ some model of communications. A peer-to-peer (P2P) network (Figure 13.3) treats every node on the network as an equal. A uniformly deployed protocol acts as a gatekeeper to make sure that one node doesn’t hog all the network resources, and each node uses time-sharing to find communications time on the medium. A client-server network (Figure 13.4) utilizes one or more computers that act as controllers to the rest of the network. Clients must ask the server for access to resources. A cloud implementation will make use of one or both of these models within the infrastructure, and then combine virtual networking with the equation.
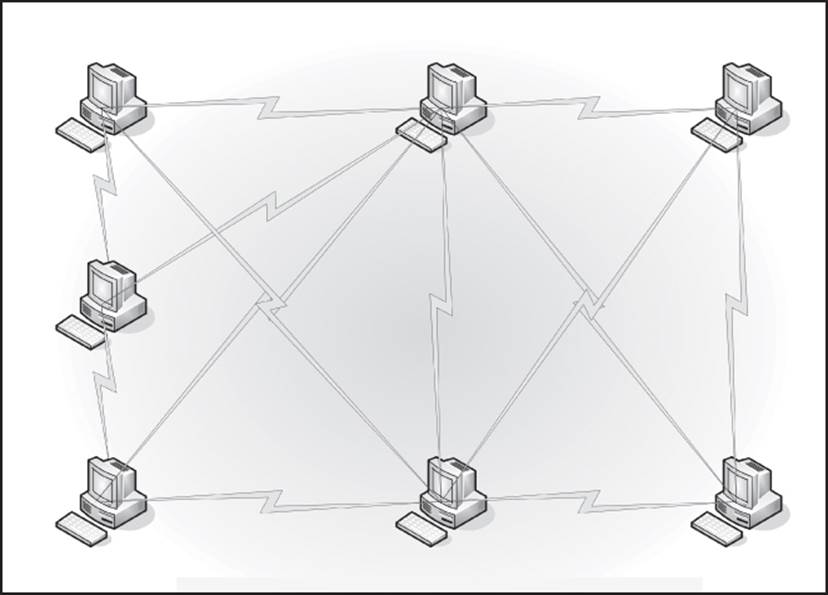
Figure 13.3 Peer-to-peer networking
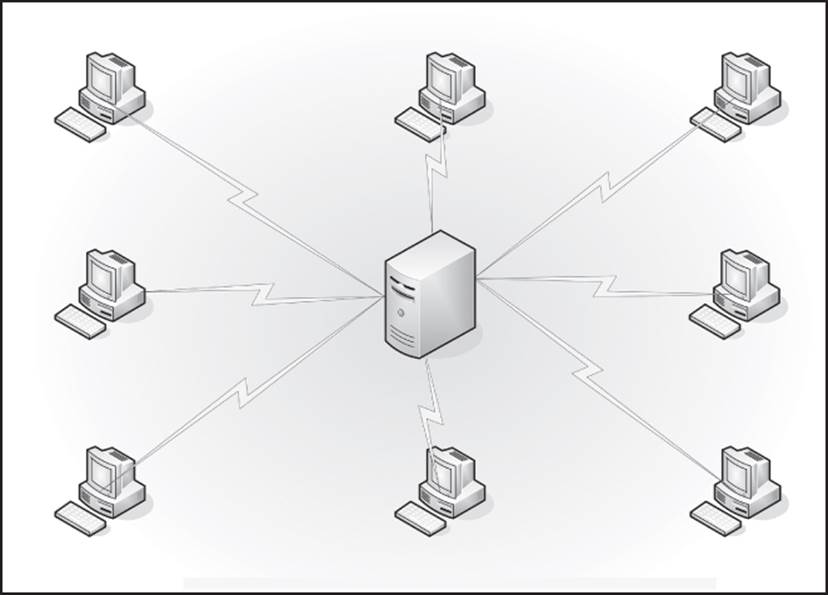
Figure 13.4 Client-server networking
On a deeper level, you also have models based on the technology they employ. In the old days of telecommunications, modems could communicate in either simplex or duplex mode. Simplex meant that only one device could transmit at a time. One device in the conversation could not send until the other finished. With duplex communication, all devices on the network could transmit simultaneously (sort of). The communications protocols policed the medium and enforced a set of time-sharing regulations.
Within the infrastructure, there is generally a distinct separation between the computational and storage tiers. Depending on the needs of the clients, applications can be either stateless or stateful. A stateful computation model remembers the environment from one session to the next. For example, when a user opens Microsoft Word on her computer, the File menu remembers the last few files that were open. All configured options and settings follow the user’s profile. That is an example of stateful computing. By default, a Web browser is stateless. It processes each request for a URL as if it were the first request ever made for that resource. Browser developers get around what many users would consider a weakness (everybody wants their favorites to appear, after all) with application programming interfaces (APIs) to provide a sense of state. Storage, on the other hand, must be stateful in order for a user to always be able to find the files she’s stored on the service provider’s site.
The Challenges of Collecting Data
Among the technical aspects of cloud investigations, identifying the data to be collected is the most critical. Until it is decided what information must be found, the methods by which data is collected and the legal requirements for obtaining permission cannot be defined. As mentioned, simply collecting documents that are easily discovered via a client application is most likely covered under the initial warrant, court order, or writ granting permission to search. Collecting logs moves the investigator from the client side to the server side and a different set of legal issues arise.
Something that the investigator has to consider is the difference in how cloud clients access data compared to how data is retrieved from local networks. On the local network, the local administrators control how and where data is stored. Directly coincident with this is the fact that artifacts relevant to the actual customer data, such as deleted files and metadata, are also controlled by local administrators. In the cloud environment, method of access and locations of data are dictated by the service provider. While there will be a user interface for loading and viewing files stored on the cloud network, there is less likelihood that there will be a user interface for metadata, server logs, and other nondocument data useful to the investigator. Coordination with the service provider will be needed in order to gain access to such information, assuming that it remains on the servers to be extracted. Information regarding VM configuration, size and location of disk images, and VM file system metadata are examples of the type of information that falls under this classification.
It is highly unlikely that it will be possible to make a true forensic image of a physical disk. It is a virtual machine, and not a physical one. The disk drive consists of a file with a name along the lines of myvm.vmdk. It is very elastic in nature, and as long as it stays live, data is being added and deleted from the virtual system. Complicating matters is the fact that its “disk drives” are likely spread across multiple disks on a RAID array, mixed in with the drives of many other VMs. Capturing the physical disks of the server that hosts a VM would also entail capturing the data from other virtual systems on the machine. The risk of exposing the private information of nontargeted clients means that there would have to be very pointed reasons for capturing the entire disk before a judge would ever issue a warrant. However, it is possible to clone each individual VM managed by the client and treat the clone as a disk image.
The virtual image that represents the VM is replicable but is likely to require a completely separate court order. It is not technically the property of the client. As far as real-time monitoring of the service provider’s network—you can almost forget about that. While the court may consider issuing a warrant for such activity in extenuating circumstances, the risk of privacy breach affecting other clients will be an obstacle to overcome. You can, however, monitor network activity across the virtual switches and interfaces. To do this, it would be necessary to install the network monitoring software or its agent onto the virtual device you plan to monitor.
Recovering deleted data from public cloud service providers is extremely difficult. With most cloud services, only the client holds the right to add or delete files. Once a file is deleted, the disk space it occupied is immediately made available to future write operations. The speed with which new data pours into the host arrays almost assures that in short order this disk space will be overwritten.
On Virtualization
As has been repeatedly mentioned, a key aspect of cloud computing is that the service provider is managing a multitenanted behemoth, and as an investigator, you are only privileged to search the resources of the tenant defined in the warrant or discovery order. You will be working within the confines of a complex, virtualized environment. It is also an environment that is configured to fulfill one of the promises made by the vendor to each client. That is the concept of “pay for what you use.” A virtualized environment may be expanded or contracted to fit the current needs of the client. More critically, if capacity changes are sufficient to justify the effort, the environment may also be somewhat migratory. By that I mean that a client that needs a relatively small server with moderate horse power one day may experience sudden growth and find that they now need a multiprocessor server with four times as much memory. The service provider smiles and says, “No problem,” and then moves the client’s entire environment from one rack of servers to another. So much for searching slack space for deleted files.
VMs exist as guests on a host server. The server runs the host operating system, and each VM runs as an independent entity and operates its own guest operating system. The host OS and the guest OS don’t need to be the same platform at all. A Linux box running Oracle’s VirtualBox can support dozens of guest machines running Windows, Linux, or OSX. Do you have a specialty OS that you want to experiment with? Set up a VM, and install it there. Some commonly used VM server applications include the aforementioned VirtualBox, VMWare, and Microsoft Virtual Machine Manager. Individual users might be using Microsoft Virtual PC for smaller implementations. While there are certainly differences between the various products, they are similar enough to discuss as a unit.
Multiple VMs may be grouped together in a virtual network as a team. A team is a group of VMs that act as a multitier environment for a particular implementation. For example, a database server might be teamed with an application server and a storage server. Teaming allows all machines that are configured in a team to start up together, in a preconfigured boot order.
Not all files related to a VM are stored inside of the VM. The host has multiple files related to the configuration of the VM. There may also be a shared folder on the host that teamed VM access for mutually required data or configuration files. Whenever possible, try to capture the entire VM. As we will see later in the chapter, this is not always feasible.
Files Specific to the Virtual Machines
Naturally, it isn’t just the user data that will be of interest. If possible, we would like to collect deleted data as well. Additionally, there will be log files and other system files that will help in building timelines, identifying user behavior, and so forth. A common commercial tool used for creating VMs is VMWare. On any given VMWare server, there are several files related to each VM (see Table 13.1). With VirtualBox, there is a single XML file for all configuration settings with an extension of .VBOX and a file for the virtual disk with a .VDI extension.

Table 13.1 VMWare Virtual Machine Files
Understanding Virtual Networking
For all of the machines in a cloud to work together, they have to communicate with one another. Being virtual, they don’t each have separate network adapters, and they don’t connect directly to a switch. All of this, just like the machine, is done virtually. Virtual networking require a virtual adapter (simply called the VNIC from here on out) and a virtual switch (VS). Figure 13.5 is a virtual illustration of a virtual network.
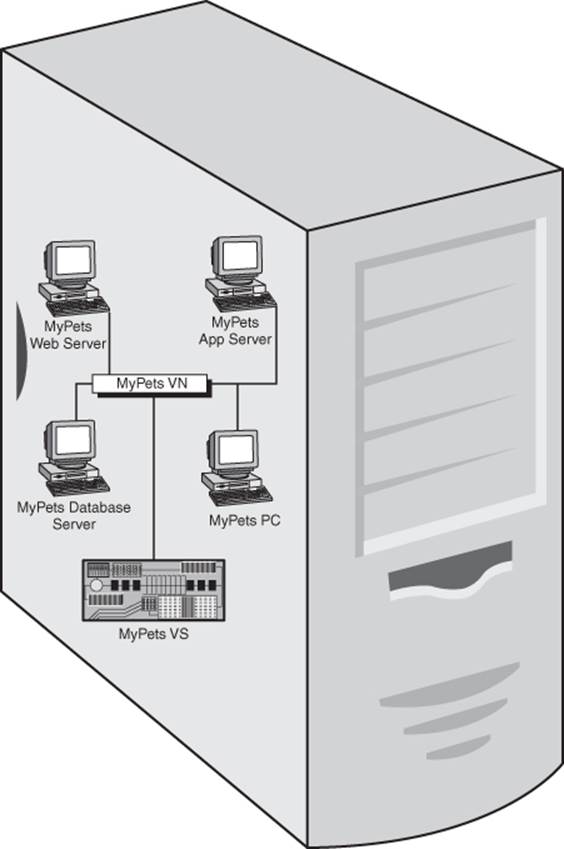
Figure 13.5 Virtual networks are built within the host server, the same way as virtual machines, complete with virtual NICs and virtual switches.
A VNIC is treated no differently than a physical adapter. It is assigned a physical address (the MAC address, as it is called, from the fact that it runs on the Media Access Control layer of networking) and an IP address. Two configuration settings often required of physical adapters that a VNIC does not require are adapter speed settings and the communications model (duplex, simplex, etc.) The VNIC is configured as a device on the guest machine and managed the same way as any other NIC.
A VS is a little more complex than a VNIC, in that some of the configuration must be done when it is first created. A MAC layer forwarding engine is dependent upon what type of VNIC was configured on the various VMs. VLANs are another object that must be configured at creation time. A VLAN is a virtual local area network. Essentially, you are creating a virtual network within a virtual network. Many other features are similar to conventional switches. Various ports are configured to point to specific virtual devices on the network. When a packet arrives at the VS, it examines the packet’s header for addressing information, finds the correct port, and forwards the packet out of that port. Each port is owned by a specific device, and only traffic intended for that device travels across the port.
A key difference between a VS and a physical switch is that on any given virtual network on a single host, only one VS is required (or allowed, for that matter). In VMWare, a switch can have up to 1,016, and a given host can support up to 4,096, total ports distributed among all VSs installed on the host. Limitations are not published for Microsoft or VirtualBox.
Virtual Machine Snapshots
A key attribute of VMs is that they can be “put to sleep” and revived to use later. A snapshot is a file that records the configuration and state of any given VM on a host. This is somewhat like putting a laptop computer into hibernation, except that unlike the laptop hibernation file, it isn’t the contents of RAM that are stored. The snapshot contains the VM hardware configuration settings, network configuration, active state, and physical location of all virtual disks assigned to the VM, and (if the VM was running when the snapshot was made) the contents of VM memory. Initially, a snapshot file is not overly large. As more data is added to the hard disk, it becomes increasingly larger. In order to prevent snapshot files from becoming excessively large, VM management systems typically use a process called differencing. With differencing, each subsequent snapshot taken of a VM records only the changes that have been made to the VM since the last snapshot.
Using a snapshot to restore a VM carries the risk of deleting critical data. Going back to a snapshot permanently deletes any disk write operations that occurred in the interval since the snapshot was made. If an administrator inadvertently goes back to an earlier snapshot than the most recent, a significant amount of data can be destroyed.
Technical Aspects of Cloud Forensics
While the field of cloud forensics is relatively new, it employs a number of common techniques in its approach. Capturing a VM as an image is most certainly possible, with cooperation from the service provider. With VMWare, as well as some of the open-source VM managers, it is possible to capture the image and mount it as a drive image. FTK Imager will add a VM as an evidence item, and the investigator can use the usual tricks to search for evidence. Therefore, once an image is acquired, the process of examining it isn’t much different than for a disk image. However, in a cloud environment, simply getting a single machine image may not be the total solution.
Insomuch as cloud forensics is still in its infancy, there are currently no sophisticated tools specific to the task. The same techniques of acquiring data in the various other forms of forensic acquisition will have to suffice. The challenges lie in collecting the data images to analyze. Both technical and legal hurdles prohibit going into a service provider’s server farm and seizing a cluster of blades that hosts the VMs you want to search. The other clients whose VMs exist on that same cluster will take a dim view of that.
Live response is just as critical in the virtual environment as it is on physical machines. Perhaps it is even more important, since the virtual environment is more subject to change. Specialized tools need to be developed for capturing the memory image of a virtual server over a remote connection. For conventional data searches, such as e-discovery compliance or similar document searches, conventional tools are adequate.
The collection of artifacts will be done on both the client side and the service provider side. Client-side artifacts pose no problems any more complex than any other system search. The provider side is where it gets complex. The investigation team has to work with the provider to assure segregation of tenants. The problem faced here is that currently no tools available are really up to the task of identifying artifacts on a machine hosting multiple VMs. CPU and graphics processor caching is not segregated in such a way that you can simply copy the memory locations without pulling down information related to other tenants on the system.
Earlier in the chapter, I mentioned that one of the first questions to ask before starting to dig was what kinds of data was being sought along with where and how it would be stored. You also have to figure out how you are going to get at the data. In an SaaS environment, data files generated by the application will be stored in a data archive somewhere in the vendor’s environment. However, it is also possible that copies of files might exist on the client machine as well. In PaaS or IaaS, you should assume some sort of stateful storage has been configured. You should notassume that all data stored in a cloud environment was generated by an application running on that cloud. Many services give control over the storage environment to the customer. So a virtual data warehouse designed to hold financial records might also be a convenient place to store illegal downloads.
The Types of Data Stored in a Cloud
The type of data you seek is very similar to what you would look for in any other investigation. You are looking for specific user files related to the case at hand. You are looking for deleted files that may be of interest, and you are looking for any temporary files created during the work process that generates user data. User data is generally relatively easy to map if you have the cooperation of the service provider. Their technical team will have configured the file structure used by the client. These are the people who can tell you specifically where each application used by a client stores its data. Therefore, one of the questions you ask the service provider early on is, For what services has this particular client contracted with your firm?
Understand the form in which the data resides as well. A document imaging system is likely to store documents in large cabinet files or folders (Figure 13.6). The file naming convention used by the application is unlikely to shed any light on the contents of each file. That information is maintained in metadata contained in separate database files (Figure 13.7).
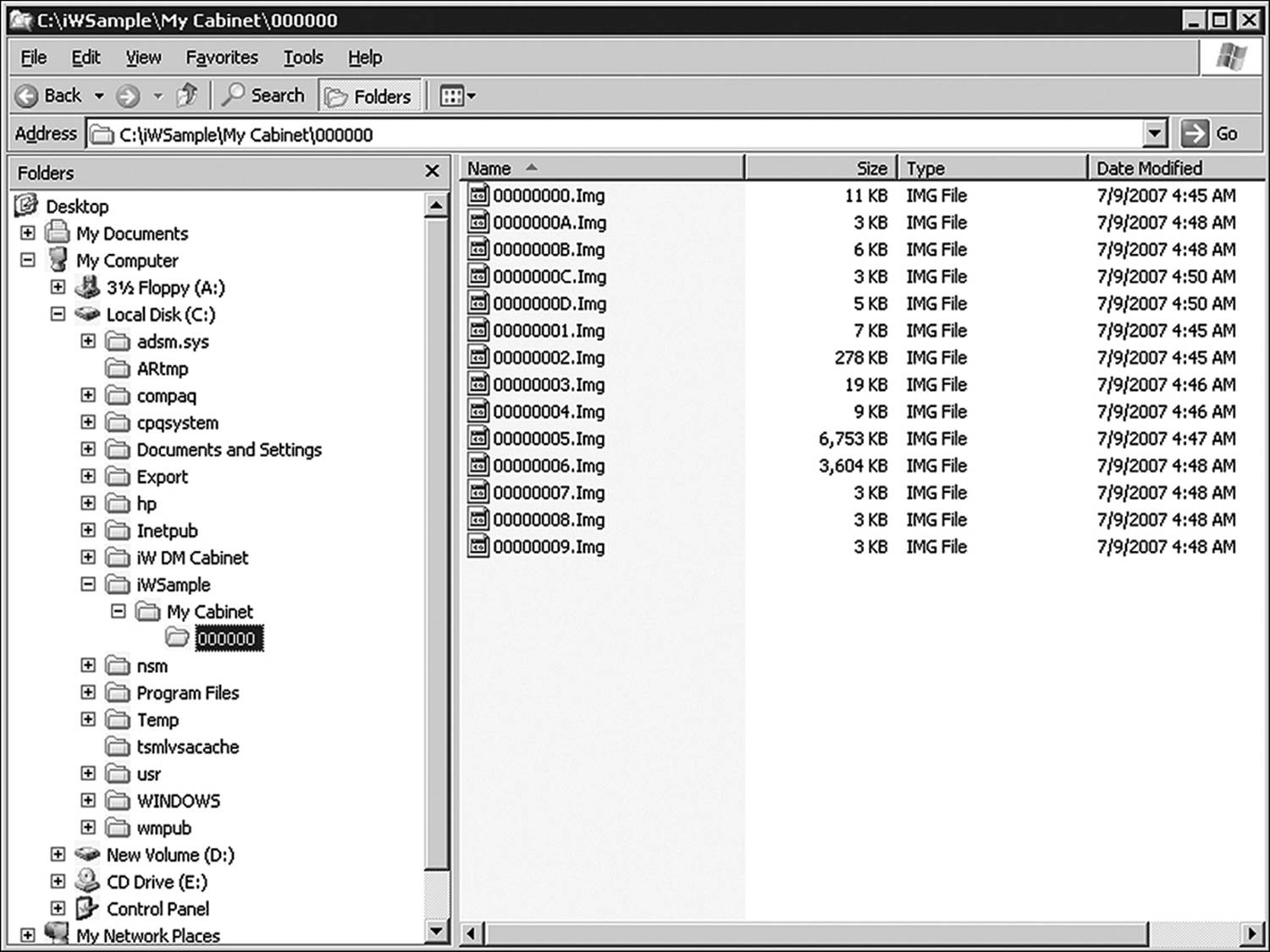
Figure 13.6 Files stored by document imaging systems use generic system-generated file names.
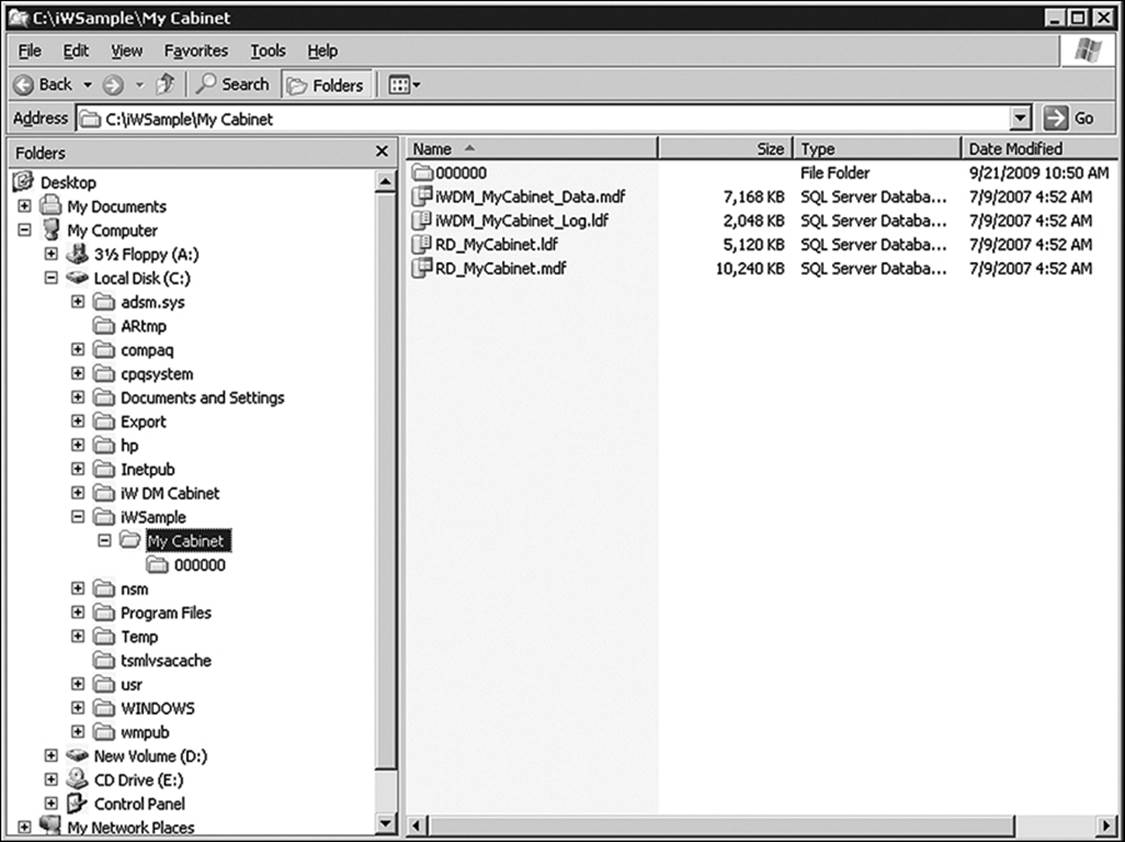
Figure 13.7 Information about document images is stored in database files containing the metadata.
In Figure 13.7, you see two pairs of files with .mdf extensions and two pairs with .ldf extensions. MDF stands for master database file. This file contains information that tells the document imaging system how to find a specific file in the archives. It also contains MAC data. Figure 13.9shows what the user sees when opening Canon Imageware. The folders, binders, and properties are all maintained within the .mdf file. Figure 13.8 shows what SysTools SQL MDF viewer sees. Note that there is a significant amount of information stored for documents and folders that the general user doesn’t see. Figure 13.8 is a screenshot of what the user sees, based on the contents of the .mdf file.
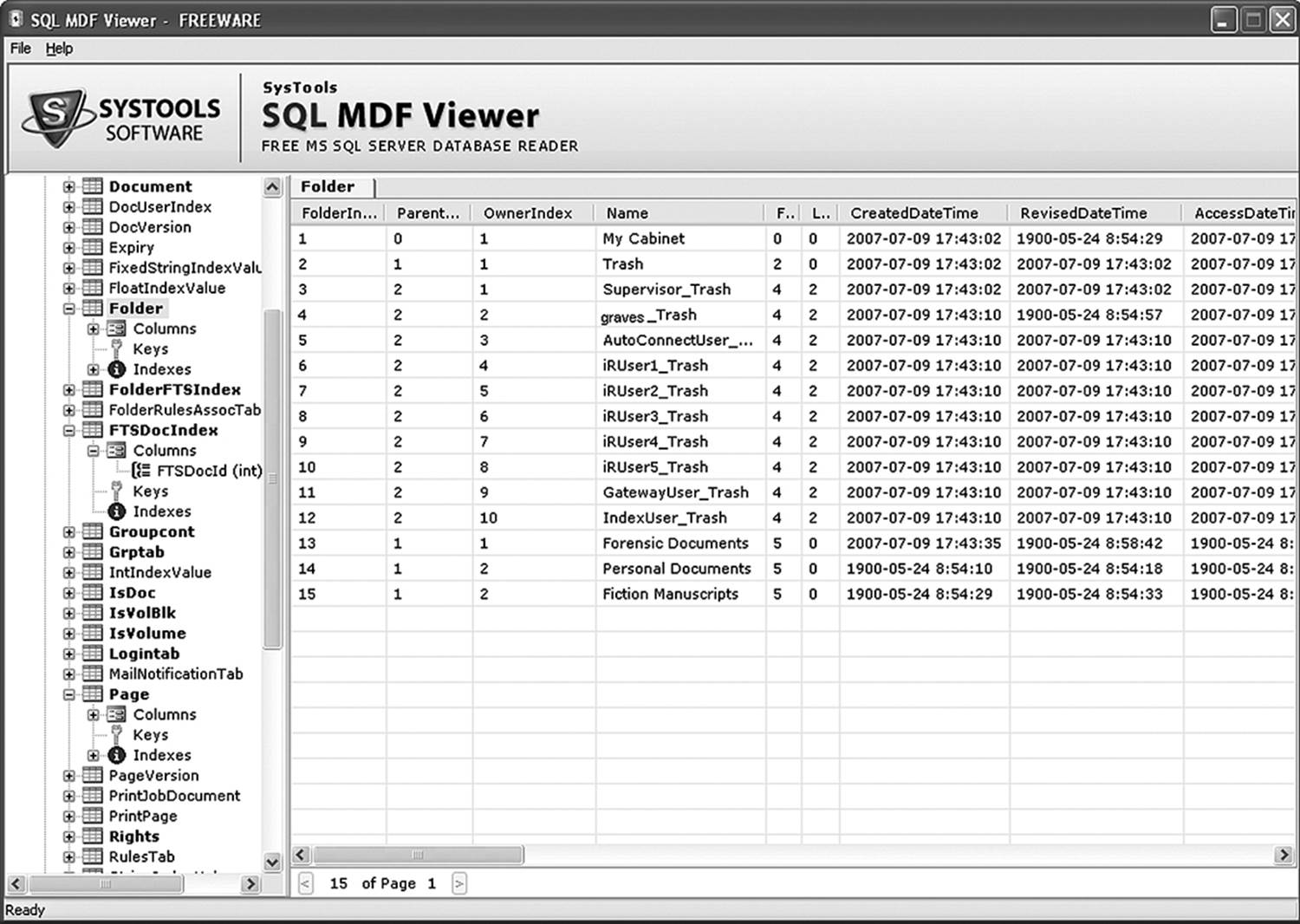
Figure 13.8 Data that tells the user about an individual file name and storage location is stored in the MDF file.
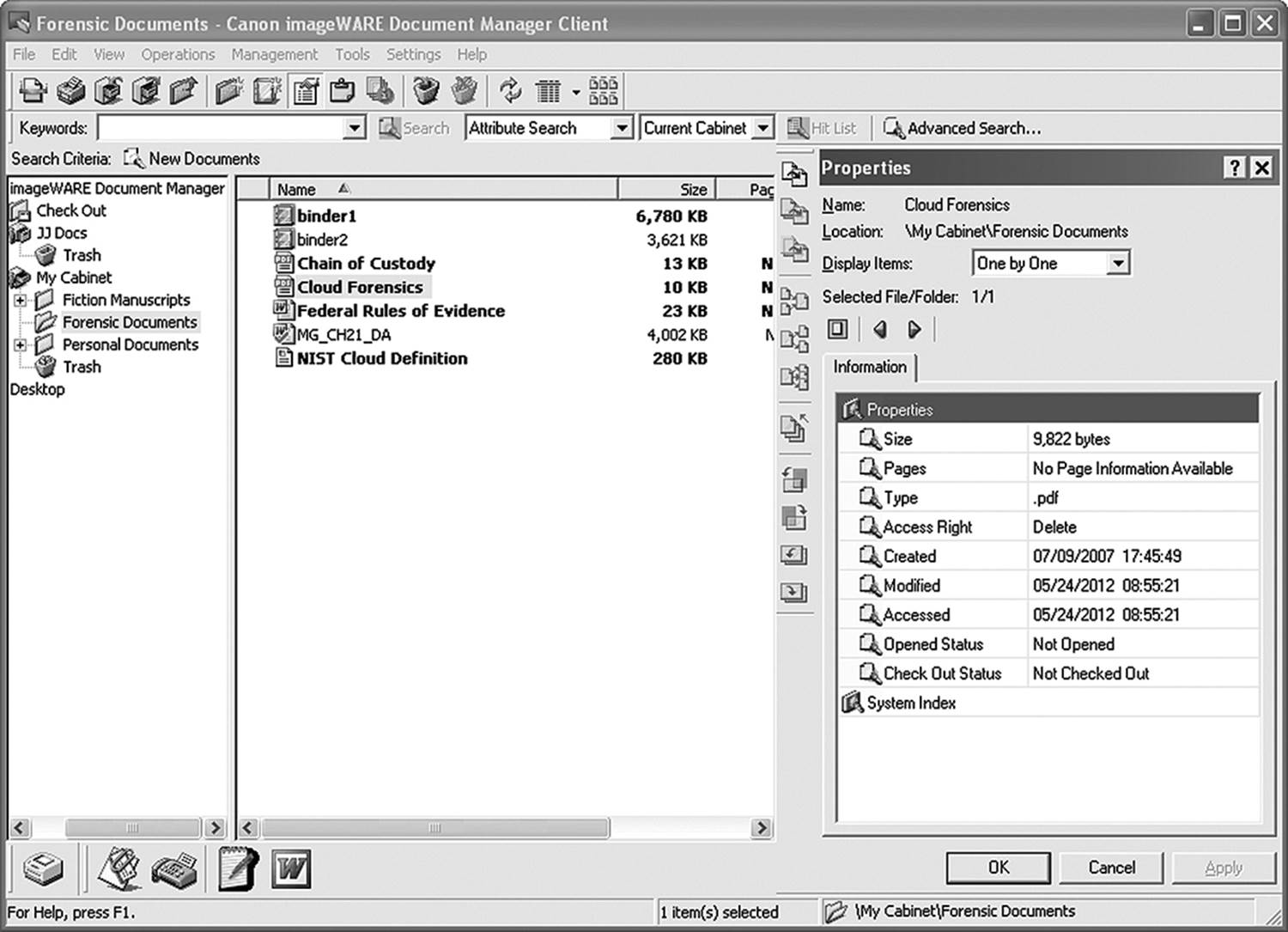
Figure 13.9 Data from the .mdf file fills in the screen that the user sees.
Database transaction logs are located in the log data file (LDF). This file records all transactions against the database and any modifications made to the database. An investigator can find out what user ID was logged on when specific changes to a database were made. Database engines, such as SQL Server, can use the LDF file to roll back transactions that were not completed. LDF files require an application such as SQL Server Management Studio to analyze.
This is just one example of how different applications that might run on a PaaS might store data. Know the applications that the client runs, and do your research on each one to find out what its data structure is and if it stores supplementary files of any sort.
The Process of Capturing Virtual Machines
When there is no danger posed by having the client know that the investigation is in progress, and it is known what specific servers contain the information being sought, VMs managed by a client can be cloned and uploaded to a forensics server. This makes the forensics process no more complicated than any other digital investigation. An image of the VM, virtually identical to a disk image, is collected and analyzed.
Frequently the client must be kept out of the loop. Live data collection might be the focus of the investigation, and shutting down the VM is not an option. In a traditional forensics investigation, one of the first things the investigator does is to isolate the “crime scene” from any environment that can possibly contaminate it. The investigator has no control over the virtual environment of the host provider, so it must rely on cooperation with the vendor to accomplish this. As stated previously, the customer’s services exist on the provider’s network as an individual instance, and multiple instances exist on a single server or node.
Delport, Olivier, and Köhn (2011) propose that the solution to this dilemma is to isolate the instance in the service provider’s environment. This means either moving the instance from one server to another or moving all other instances on the server to another, leaving the target instance intact. This is not something the investigator can do. Only the service provider can do this, and they aren’t going to do it as a casual favor. You will need to work in conjunction with the legal team, the provider’s technical services department, and your forensics team to make it all come together.
While it seems logically easier to move one instance away from several others instead of the several from one, there is this to consider. Each instance on the servers is protected in regards to confidentiality, integrity, and availability. Consider the instances as starship cruisers in a fleet. When one starship is about to launch, all the others raise their shields in case the one taking off blows to smithereens. VMs protect themselves in much the same way. When one instance is moving, all the others on the node raise their shields. If any data is going to be lost, it will be from the instance being moved. Since it is critical to protect the data on the suspect instance, then forensically speaking, it is better to move the others.
On the other hand, if the investigation is going on without the knowledge of the users on a suspect instance, then it becomes more critical to prevent them from knowing that your team is in there poking around. Moving the instance requires that it be shut down momentarily. Knocking the users off the network is not always conducive to maintaining a low profile. Therefore, sometimes it might be necessary to move the suspect instance, and other times it might be necessary to leave it in state and move all the others.
Instance relocation can be done manually or automatically. Manual relocation involves the administrators of the virtual network creating a new instance and ending the old one (or vice versa). This method allows virtual memory, virtual disks, and allocated memory to be copied to files and saved. The new instance is configured to have all of the same network resources as the old and then switched on. From a forensic standpoint, this method is preferable, in that a static image of the VM can be made and the image analyzed in conventional forensic software.
Constitutional Issues
Legal ramifications have been mentioned several times throughout the course of this chapter. This section will demonstrate just how confusing this issue is. As with any other issues covered by this book, a forensic investigation into the cloud must meet all constitutional criteria when the government is involved and all legal standards imposed by legislation in private enquiries. Essentially, the rights of the individual don’t change just because the computing platform moved from the living room to the Internet. However, the doorways through which the data must pass, as well as the halls in which it resides, differ greatly. Accordingly, the methods by which data is excavated changes as well. This section will deal with some Fourth and Fifth Amendment issues specific to cloud computing. Just as the technology of cloud computing offers new challenges on the technical side, the arguments posed by the technology are convoluting the legal side.
Fourth Amendment Issues of Cloud Computing
To review some issues covered in Chapter 3, “Search Warrants and Subpoenas,” you will recall that a very formidable foe of the prosecutor was the exclusionary rule. If evidence is obtained in a manner inconsistent with constitutional dogma or legislative rule, then it doesn’t exist. You can have thousands of graphic images of child pornography that it is easy to prove came from the defendant’s computer. However, if the defense can convince the court that the computer was seized illegally or that the search was in any way inappropriate, those images will be inadmissible. That is the basic tenet of the Fourth Amendment.
Several questions are considered by the court when deciding whether evidence is admissible. This was covered in Chapter 3, but to review, those questions include
• Was the search legal?
• Did the individual have a reasonable expectation of privacy?
• Did the individual knowingly expose private information to the public?
If the evidence presented passes through all three filters intact, it is considered admissible. The courts try to interpret these issues using existing case law as much as possible, using analogies such as the closed container rule applied to hard disks. After all, it is quite obvious that in today’s digital world, a man’s computer is his castle. What happens when the “castle” is shared with two dozen others on a single drive array in a server farm two thousand miles away? Where do the castle walls stand?
When can an investigator search the castle? As we saw in Chapter 3, the personal computers and hard disks of defendants were vigorously protected under Fourth Amendment law. When it came to cloud computing, the walls started to blur. The Electronic Stored Communications Act (ESCA) of 1986 exposed one limitation to these walls long before cloud computing was imagined. Under this legislation, a court can order an ISP to turn over any e-mails or electronic records that have resided on an external server for more than 180 days (ESCA 1986), without notifying the owner of those files. That was all fine and good when it was assumed that records left on a public server that long could be essentially considered abandoned. However, with cloud computing, the client is using public servers as the permanent storage mechanism. Any person with a subscription more than 180 days old is subject to having the older files grabbed for any reason, without the need of the investigator having a warrant.
When it comes to the concept of “reasonable expectation of privacy,” the courts have been friendlier to prosecutors than defendants in some regards. A case used frequently as a precedent for granting access to remotely stored electronic data is U.S. v. Miller (1976). Here, the courts declared that the defendant had no reasonable expectation of privacy regarding his bank records because by revealing his affairs to another entity (in this case, the defendant’s bank), he assumed the risk that such information would be vulnerable and made available to government scrutiny. The same philosophy has been applied to acquiring telephone records as well.
Intentional use of cloud services really blurs the lines when it comes to whether or not the individual has intentionally exposed information to the public. Cloud services are generally considered public utilities, in some cases, even where a private cloud has been configured. Applications and operating systems designed with cloud computing in mind, such as Google Chrome and Google Apps, store calendars, notes, documents, images, and contact information on public servers. A reasonable expectation of privacy is implied by the fact that the user is required to enter a user ID and password in order to access this information. However, the ground rules of the ESCA also apply. Which takes precedence?
Applications such as Facebook allow the users to set the configuration on their personal page to allow their “friends” to edit the page, which enables lively exchanges of ideas, resources, and insults. In allowing external edits, the user has essentially given up all expectation of privacy. They are not only saying, “Come in and look,” but they are also saying, “Add your own illegal content while you’re in here.” At what point does the account owner give up responsibility for content?
The courts more recently took a proactive step in the direction of the individual user rights in State v. Bellar. In this case, images of child pornography were discovered on a suspect’s computer. Justice Edmonds, in writing the decision, specifically targeted cloud computing when he wrote, “I suspect that most citizens would regard that data as no less confidential or private because it was stored on a server owned by someone else” (State v. Bellar 2009).
It is clear that there is a substantial amount of work to be done before there is clarity on the legal issues of a cloud search. With courts disagreeing with one another, it is not surprising that law enforcement is confused. The legal issues are as new as the technologies when it comes to the cloud, and it is essential that legal counsel be obtained whenever there is doubt about direction. When in doubt, get a warrant.
Fifth Amendment Issues of Cloud Computing
The other constitutional battleground involving the cloud will be over passwords. Accessing a suspect’s data and applications in the cloud will require knowing the user ID and password in virtually every case. Is forcing the surrender of a password in violation of the Fifth Amendment?
In re Boucher, the court stated that production of a password might be deemed self-incriminatory if it was the production of the password that induced the incrimination. In the decision, the judges wrote, “A password, like a combination, is in the suspect’s mind, and is therefore testimonial and beyond the reach of the grand jury subpoena” (re Boucher 2009). However, the same court also allowed the inclusion of the evidence obtained because the knowledge of what existed on the hard drive existed before the search was initiated. The court ordered that the production of an unencrypted hard disk did not infringe on the suspect’s rights.
This concept was revisited in U.S. v. Fricosu (2012). Government prosecutors argued that the password used to encrypt a hard drive was a token and thereby not necessarily protected under the Fifth Amendment. The defense argued that since the password was something contained within the defendant’s mind and not a physical entity, forcing her to divulge the password would infringe upon her rights. The Tenth U.S. District Court of Appeals took an end around in this case. The judge did not order Fricosu to divulge her password but did order her to turn over an unencrypted copy of the hard disk for examination. It is very likely that this case will be appealed and may eventually wind up in the Supreme Court, as it poses significant questions regarding the relevance of the Fifth Amendment in the digital age.
The arguments center on whether a password is considered to be a “key,” which is a physical thing and covered under the Fourth Amendment, or more akin to the combination to a safe. Doe v. United States (1988) tackled the role of combinations to safes long before passwords to encrypted drives were an issue. In this seminal case, the Supreme Court stated that a suspect might be “forced to surrender a key to a strongbox containing incriminating documents” but not “compelled to reveal the combination to a wall safe.” This puts the password as a combination securely into the purview of the Fifth Amendment. The criminal who locks away all trace of sin with a key can be forced to give it up. The one who uses a combination lock can keep it a secret for a long time. It is an argument that is likely to go on for several years.
Chapter Review
1. What are the three forms of service offered by cloud computing? Briefly describe each one in terms of form and function.
2. When a warrant is issued to search the computer systems of a particular entity, it generally specifies what forms of hardware are to be searched and the location of that hardware. Why is that impossible if the target of the warrant employs cloud computing? How can this problem be overcome?
3. Briefly describe the concept of virtualization. How is it relevant to the concept of digital forensics?
4. A suspect in a particular case employs an enterprise-level document imaging system to manage his files. The files all carry file names such as 003224.img. What are some other files managed by the system that will help isolate and identify these files?
5. Describe the process of capturing a virtual machine. How is it different than acquiring a conventional disk image? How is it similar? What are some factors that must be considered before you even begin?
Chapter Exercises
1. Browse to Amazon Web Services (currently at http://aws.amazon.com/) and examine their services offered. Which services are IaaS, which are SaaS, and which are PaaS?
2. Look up the case Metro-Goldwyn-Mayer Studios Inc. v. Grokster, Ltd., and consider the following. Grokster and StreamCast were held liable for copyright infringement, simply on the merit that they provided the software that made the storage, search, and distribution of copyrighted materials possible. Briefly discuss how this decision could potentially affect companies who offer SaaS services.
References
Armbrust et al. 2009. Above the clouds: A Berkeley view of cloud computing. http://x-integrate.de/x-in-cms.nsf/id/DE_Von_Regenmachern_und_Wolkenbruechen_-_Impact_2009_Nachlese/$file/abovetheclouds.pdf (accessed May 23, 2012).
Delport, W., M. Olivier, and M. Köhn. 2011. Isolating a cloud instance for a digital forensic investigation. http://icsa.cs.up.ac.za/issa/2011/Proceedings/Research/Delport_Olivier_Kohn.pdf (accessed May 14, 2012).
Doe v. United States, 487 U.S. 201, 210 (1988).
Electronic Stored Communications Act of 1986. Pub. L. 99–508, 100 Stat. 1848.
Mell, P., and T. Grance. 2011. The NIST definition of cloud computing. Special Publication 800-145. http://csrc.nist.gov/publications/nistpubs/800-145/SP800-145.pdf (accessed May 1, 2012).
Novell. 2011. Cloud computing: What is the cloud? www.novell.com/communities/node/13328/cloud-computing-what-is-the-cloud (accessed May 7, 2012).
re Boucher, 2007 WL 4246473 (Nov. 29, 2009).
State v. Bellar, 050230673; A129493. Multnomah County Court (2009).
United States v. Fricosu, No. 10-cr-00509-REB-02 (Jan. 23, 2012).
United States v. Miller, 425 U.S. 435, 443 (1976).