Computer Science: A Very Short Introduction (2016)
Chapter 5 The discipline of computer architecture
The physical computer is at the bottom of the hierarchy MY_COMPUTER shown in Figure 1. In everyday parlance the physical computer is referred to as hardware. It is ‘hard’ in that it is a physical artefact that ultimately obeys the laws of nature. The physical computer is the fundamentalmaterial computational artefact of interest to computer scientists.
But if someone asks: ‘What is the nature of the physical computer?’ I may equivocate in my answer. This is because the physical computer, though a part of a larger hierarchy, is itself complex enough that it manifests its own internal hierarchy. Thus it can be designed and described at multiple levels of abstraction. The relationship between these levels combine the principles of compositional, abstraction/refinement, and constructive hierarchy discussed in Chapter 1.
Perhaps the most significant aspect of this hierarchy from a computer scientist’s perspective (and we owe it, in major part, to the genius of the Hungarian-American mathematician and scientific gadfly John von Neumann to first recognize it) is the distinction of the physical computer as a symbol processing computational artefact from the physical components, obeying the laws of physics, that realize this artefact. This separation is important. As a symbol processor, the computer is abstract in exactly the same sense that software is abstract; yet, like software this abstract artefact has no existence without its physical implementation.
The view of the physical computer as an abstract, symbol processing computational artefact constitutes the computer’s architecture. (I have used the term ‘architecture’ before to mean the functional structure of the virtual machines shown in Figure 1. But now, ‘computer architecture’ has a more specific technical connotation.) The physical (digital) components that implement the architecture—the actual hardware—constitutes its technology. We thus have this distinction between ‘computer architecture’ and (digital) technology.
There is another important aspect of this distinction. A given architecture can be implemented using different technologies. Architectures are not independent of technologies in that developments in the latter influence architecture design, but there is a certain amount of autonomy or ‘degrees of freedom’ the designer of computer architectures enjoy. Conversely, the design of an architecture might shape the kind of technology deployed.
To draw an analogy, consider an institution such as a university. This has both its abstract and material characteristics. The organization of the university, its various administrative and academic units, their internal structure and functions, and so on, is the analogue to a computer’s architecture. One can design a university (it is, after all, an artefact), describe it, discuss and analyse it, criticize it, alter its structure, just as one can any other abstract entity. But a university is implemented by way of human and physical resources. They are the analogue to a computer’s (hardware) technology. Thus, while the design or evolution of a university entails a considerable degree of autonomy, its realization can only depend on the nature, availability and efficacy of its resources (the people employed, the buildings, the equipment, the physical space, the campus structure as a whole, etc.). Conversely, the design of a university’s organization will influence the kinds of resources that have to be in place.
So here are the key terms for this discussion: computer architecture is the discipline within computer science concerned with the design, description, analysis, and study of the logical organization, behaviour, and functional elements of a physical computer; all of that constitutes the (physical) computer’s architecture. The task of the computer architect is to design architectures that satisfy the needs of the users of the physical computer (software engineers, programmers and algorithm designers, non-technical users) on the one hand and yet are economically and technologically viable.
Computer architectures are thus liminal artefacts. The computer architect must navigate delicately between the Scylla of the computer’s functional and performance requirements and the Charybdis of technological feasibility.
Solipsistic and sociable computers
The globalization of everything owes much to the computer. If ‘no man is an island entire of itself’, then nor in the 21st century is the computer. But once upon a time, and for many years, computers did indeed exist as islands of their own. A computational artefact of the kind depicted as TEXT in Figure 1 would go about its tasks as if the world beyond did not exist. Its only interaction with the environment was by way of input data and commands and its output results. Other than that, for all practical purposes, the physical computer, along with its dedicated system and application programs and other tools (such as programming languages), lived in splendid, solipsistic isolation.
But, as just noted, few computers are solipsistic nowadays. The advent of the Internet, the institution of emails, the World Wide Web, and the various forms of social media have put paid to computational solipsism. Even the most reclusive user’s laptop or smart phone is a sociable computer as soon as that user goes online to purchase a book or check out the weather or seek directions to go to some place. His computer is sociable in that it interacts and communicates with innumerable other computers (though blissfully unknown to him) physically located all over the planet through the network that is the Internet. Indeed, every emailer, every seeker of information, every watcher of an online video is not just using the Internet: her computer is part of the Internet. Or rather, the Internet is one global interactive community of sociable computational artefacts and human agents.
But there are more modest networks of which a computer can be a part. Machines within an organization (such as a university or a company) are connected to one another through what are called ‘local area networks’. And a constellation of computers distributed over a region may collaborate, each performing its own computational task but exchanging information as and when needed. Such systems are traditionally called multicomputing or distributed computing systems.
The management of multicomputing or distributed computing or Internet computing is effected by a combination of network principles called ‘protocols’ and extremely sophisticated software systems. When we consider the discipline of computer architecture, however, it is the individual computer, whether solipsistic or sociable, that commands our attention. It is this I discuss in the remainder of this chapter.
Outer and inner architectures
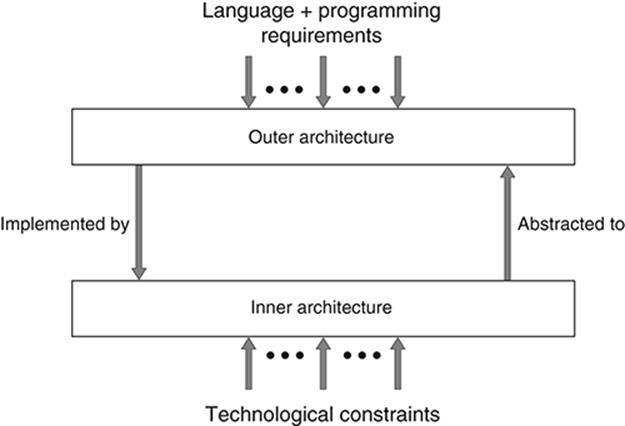
The word ‘architecture’ in the context of computers was first used in the early 1960s by three IBM engineers, Gene Amdahl, Frederick Brooks, and Gerrit Blaauw. They used this term to mean the collection of functional attributes of a physical computer as available to the lowest level programmer of the computer (system programmers who build operating systems, compilers, and other basic utilities using assembly languages); its ‘outer façade’ so to speak. Since then, however, the practice of computer architecture has extended to include the internal logical, structural, and functional organization and behaviour of the physical (hardware) components of the machine. Thus, in practice, ‘computer architecture’ refers to the functional and logical aspects of both the outer façade and the interior of a physical computer. Yet, no agreed upon terms exist for these two aspects; here, for simplicity, I will call them ‘outer’ and ‘inner’ architectures, respectively.
The two are hierarchically related. They are two different abstractions of the physical computer, with the outer architecture an abstraction of the inner one or, conversely, the inner architecture a refinement of the outer one. Or, depending on the design strategy used, one may regard a computer’s inner architecture as an implementation of the outer one.
The design of outer computer architectures is shaped by forces exerted from the computer’s computational environment: since the outer architecture is the interface between the physical computer and system programmers who create the virtual machines the ‘ordinary’ users of the computer ‘see’, it is natural that the functional requirements demanded by this environment will exert an influence on the outer architectural design. For example, if the computer C is intended to support the efficient execution of programs written in a particular kind of language, say L, then the outer architecture of C may be oriented toward the features of L; thus easing the task of the language compiler in translating programs written in L into machine code for C. Or if the operating system OS that sits atop C has certain facilities, then the implementation of OS may be facilitated by appropriate features incorporated into C ’s outer architecture.
On the other hand, since a computer’s inner architecture will be implemented by physical (hardware) components, and these
4. Computer architectures and their external constraints.
components are built using a particular kind of technology T, the design of the inner architecture will be constrained by features of T.
At the same time, the design of the outer architecture may be shaped and constrained by the nature of the inner architecture and vice versa. Thus, there is an intimate relationship between the computational environment, the outer architecture of the computer, its inner architecture, and the physical technology (Figure 4).
The outer architecture
The sanctum sanctorum of a computer’s outer architecture is its instruction set, which specifies the repertoire of operations the computer can be directly commanded to perform by a programmer. Exactly what types of operations can be performed will both determine and be determined by the set of data types the computer directly supports or ‘recognizes’. For example, if the computer is intended to efficiently support scientific and engineering computations the significant data types will be real numbers (e.g. 6.483, 4 * 108, − 0.000021, etc.) and integers. Thus the instruction set should include a range of arithmetic instructions.
In addition to such domain-specific instructions, there will always be a repertoire of general purpose instructions, for example, for implementing conditional (e.g. if then else), iterative (e.g. while do) and unconditional branch (e.g. goto) kinds of programming language constructs. Other instructions may enable a program to be organized into segments or modules responsible for different kinds of computations, with the capability of transferring control from one module to another.
An instruction is really a ‘packet’ that describes the operation to be performed along with references to the locations (‘addresses’) of its input data objects (‘operands’ in architectural vocabulary) and the location of where its output data will be placed. This idea of address implies a memoryspace. Thus, there are memory components as part of an outer architecture. Moreover, these components generally form a hierarchy:
LONG-TERM MEMORY—known as ‘backing store’, ‘secondary memory’, or ‘hard drive’.
MEDIUM-TERM MEMORY—otherwise known as ‘main memory’.
VERY SHORT-TERM (WORKING) MEMORY—known as registers.
This is a hierarchy in terms of retentivity of information, size capacity, and speed of access. Thus, even though an outer architecture is abstract, the material aspect of the physical computer is rendered visible: space (size capacity) and time are physical, measured in physical units (bits or bytes of information, nanoseconds or picoseconds of time, etc.) not abstract. It is this combination that makes a computer architecture (outer or inner) a liminal artefact.
The long-term memory is the longest in retentivity (in its capacity to ‘remember’)—permanent, for all practical purposes. It is also the largest in size capacity, but slowest in access speed. Medium-term memory retains information only as long as the computer is operational. The information is lost when the computer is powered off. Its size capacity is far less than that of long-term memory but its access time is far shorter than that of long-term memory. Short-term or working memory may change its contents many times in the course of a single computation; its size capacity is several orders of magnitude lower than that of medium-term memory, but its access time is much less than that of long-term memory.
The reason for a memory hierarchy is to maintain a judicious balance between retentivity, and space and time demands for computations. There will be also instructions in the instruction set to effect transfers of programs and data between these memory components.
The other features of outer architecture are built around the instruction set and its set of data types. For example, instructions must have ways of identifying the locations (‘addresses’) in memory of the operands and of instructions. The different ways of identifying memory addresses are called ‘addressing modes’. There will also be rules or conventions for organizing and encoding instructions of various types so that they may be efficiently held in memory; such conventions are called ‘instruction formats’. Likewise, ‘data formats’ are conventions for organizing various data types; data objects of a particular data type are held in memory according to the relevant data format.
Finally, an important architectural parameter is the word length. This determines the amount of information (measured in number of bits) that can be simultaneously read from or written into medium-term (main) memory. The speed of executing an instruction is very much dependent on word length, as also the range of data that can be accessed per unit time.
Here are a few typical examples of computer instructions (or machine instructions, a term I have already used before) written in symbolic (assembly language) notation, along with their semantics (that is the actions these instructions cause to happen).
|
Instruction |
Meaning (Action) |
|
1. LOAD R2, (R1, D) |
R2 ← main-memory [R1 + D] |
|
2. ADD R2, 1 |
R2 ← R2 + 1 |
|
3. JUMP R1, D |
goto main-memory [R1 + D] |
Legend:
R1, R2: registers
main-memory: medium-term memory
1: the integer constant ‘1’
D: an integer number
‘R1 + D’ in (1) adds the number ‘D’ to the contents of register R1 and this determines the main-memory address of an operand. ‘R1 + D’ in (3) computes an address likewise but this address is interpreted as that of an instruction in main-memory to which control is transferred.
The inner architecture
A physical computer is ultimately a complex of circuits, wires, and other physical components. In principle, the outer architecture can be explained as the outcome of the structure and behaviour of these physical components. However, the conceptual distance between an abstract artefact like an outer architecture and the physical circuits is so large that it is no more meaningful to attempt such an explanation than it is to explain or describe a whole living organism (except perhaps bacteria and viruses) in terms of its cell biology. Cell biology does not suffice to explain, say, the structure and functioning of the cardio-vascular system. Entities above the cell level (e.g. tissues and organs) need to be understood before the whole system can be understood. So also, digital circuit theory does not suffice to explain the outer architecture of a computer, be it a laptop or the world’s most powerful supercomputer.
This conceptual distance in the case of computers—sometimes called ‘semantic gap’—is bridged in a hierarchic fashion. The implementation of an outer architecture is explained in terms of the inner architecture and its components. If the inner architecture is itself complex and there is still a conceptual distance from the circuit level, then the inner architecture is described and explained in terms of a still lower level of abstraction called microarchitecture. The latter in turn may be refined to what is called the ‘logic level’, and this may be sufficiently close to the circuit level that it can be implemented in terms of the latter components. Broadly speaking, a physical computer will admit of the following levels of description/abstraction:
Level 4: Outer architecture
Level 3: Inner architecture
Level 2: Microarchitecture
Level 1: Logic level
Level 0: Circuit level
Computer architects generally concern themselves with the outer and inner architectures, and a refinement of the inner architecture which is shown earlier as microarchitecture (this refinement is explained later). They are interested not only in the features constituting these architectural levels but also the relationship between them.
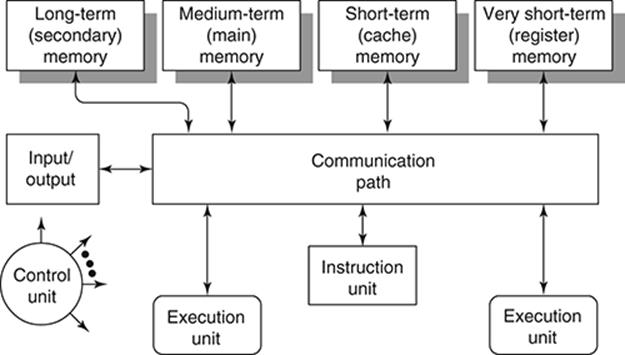
The principal components of a computer’s inner architecture are shown in Figure 5. It consists of the following. First, a memory system which includes the memory hierarchy visible in the outer architecture but includes other components that are only visible in the inner architectural level. This system includes controllers responsible for the management of information (symbol structures) that pass between the memories in the hierarchy, and between the system and the rest of the computer. Second, one or more instruction interpretation units which prepare instructions for execution and control their execution. Third, one or more execution units responsible for the actual execution of the various classes of instructions demanded in a computation. (Collectively, the instruction interpretation system(s) and execution unit(s) are called the computer’s processor.) Fourth, a communication network that serve to transfer symbol structures between the other functional components. Fifth, an input/output system responsible for receiving symbol structures from, and sending symbol structures to, the physical computer’s environment. And finally, the control unit which is responsible for issuing signals that control the activities of the other components.
5. Portrait of a computer’s inner architecture.
The execution units are rather like the organs of a living body. They can be highly specialized for operations of specific sorts on specific data types, or more general purpose units capable of performing comprehensive sets of operations. For example, one execution unit may be dedicated to performing only integer arithmetic operations while another is specialized for arithmetic operations on real numbers; a third only manipulates bit strings in various ways; another does operations on character strings, and so on.
Internally, a processor will have its own dedicated, extremely short-term or transient, memory elements (of shorter term retentivity than the registers visible in the outer architecture, and sometimes called ‘buffer registers’) to which information must be brought from other memories before instructions can be actually processed by the instruction interpretation or processing units. Such buffer registers form the ‘lowest’ level in the memory hierarchy visible in the inner architecture.
There is yet another component of the memory hierarchy visible in the inner architecture but (usually) abstracted away in the outer architecture. This is a memory element called cache memory that lies between the medium-term (main) memory and the very short-term (register) memory. InFigure 5, this is shown as ‘short-term memory’. Its capacity and speed of access lie between the two. The basic idea of a cache is that since instructions within a program module execute (usually) in sequence, a chunk of instructions can be placed in the cache so that instructions can be accessed more rapidly than if main memory is accessed. Likewise, the nature of program behaviour is such that data is also often accessed from sequential addresses in main memory so data chunks may also be placed in a cache. Only when the relevant instruction or data object is not found in the cache, will main memory be accessed, and this will cause a chunk of information in the cache to be replaced by the new chunk in which the relevant information is located so that future references to instructions and data will be available in the cache.
‘The computer-within-the computer’
So how can we connect the outer to the inner architecture? How do they actually relate? To understand this we need to understand the function of the control unit (which, in Figure 5 stands in splendid black box-like isolation).
The control unit is, metaphorically, the computer’s brain, a kind of homunculus, and is sometimes described as a ‘computer-within-the-computer’. It is the organ which manages, controls, and sequences all the activities of the other systems, and the movement of symbol structures between them. It does so by issuing control signals (symbol structures that are categorically distinct from instructions and data) to other parts of the machine as and when required. It is the puppeteer that pulls the strings to activate the other puppet-like systems.
In particular, the control unit issues signals to the processor (the combination of the instruction interpretation and execution units) to cause a repetitive algorithm usually called the instruction cycle (ICycle for short) to be executed by the processor. It is the ICycle which ties the outer to the inner architecture. The general form of this is as follows:
ICYCLE:
Input: main-memory: medium-term memory; registers: short-term memory;
Internal: pc: transient buffer; ir: transient buffer; or: transient buffer
{pc, short for ‘program counter’, holds the address of the next instruction to be executed; ir, ‘instruction register’, holds the current instruction to be executed; or will hold the values of the operands of an instruction}.
FETCH INSTRUCTION: Using value of pc transfer instruction from main-memory to ir (ir ← main-memory [pc])
DECODE the operation part of instruction in ir;
CALCULATE OPERAND ADDRESSES: decode the address modes of operands in instruction in ir and determine the effective addresses of operands and result locations in main-memory or registers.
FETCH OPERANDS from memory system into or.
EXECUTE the operation specified in the instruction in ir using the operand values in or as inputs.
STORE result of the operation in the destination location for result specified in ir.
UPDATE PC: if the operation performed in EXECUTE is not a goto type operation then pc ← pc + 1. Otherwise do nothing: EXECUTE will have placed the address of the target goto instruction in ir into pc.
The ICycle is controlled by the control unit but it is the instruction interpretation unit that performs the FETCH INSTRUCTION through FETCH OPERANDS steps of the ICycle, and then the STORE and UPDATE steps, and an execution unit will perform the EXECUTE step. As a specific example consider the LOAD instruction described earlier:
LOAD R2, (R1, D)
Notice that the semantics of this instruction at the outer architectural level is simply
R2 ← Main-memory [R1 + D]
At the inner architectural level, its execution entails the performance of the ICycle. The instruction is FETCHed into ir, it is DECODEd, the operand addresses are CALCULATEd, the operands are FETCHed, the instruction is EXECUTEd, and the result STOREd into register R2. All these steps of the ICycle are abstracted out in the outer architecture as unnecessary detail as far as the users of the outer architecture (the system programmers) are concerned.
Microprogramming
To repeat, the ICycle is an algorithm whose steps are under the control of the control unit. In fact, one might grasp easily that this algorithm can be implemented as a program executed by the control unit with the rest of the computer (the memory system, the instruction interpretation unit, the execution units, the communication pathways, the input/output system) as part of the ‘program’s’ environment. This insight, and the design of the architecture of the control unit based on this insight, was named microprogramming by its inventor, British computer pioneer Maurice Wilkes. And it is in the sense that the microprogrammed control unit executes a microprogram that implements the ICycle for each distinct type of instruction that led some to call the microprogrammed control unit the computer-within-the-computer. In fact, the architecture of the computer as themicroprogrammer sees it is necessarily more refined than the inner architecture indicated in Figure 5. This microprogrammer’s (or control unit implementer’s) view of the computer is the ‘microarchitecture’ mentioned earlier.
Parallel computing
It is in the nature of those who make artefacts (‘artificers’)—engineers, artists, craftspeople, writers, etc.—to be never satisfied with what they have made; they desire to constantly make better artefacts (whatever the criterion of ‘betterness’ is). In the realm of physical computers the two dominant desiderata are space and time: to make smaller and faster machines.
One strategy for achieving these goals is by way of improving physical technology. This is a matter of solid state physics, electronics, fabrication technology, and circuit design. The extraordinary progress over the sixty or so years since the integrated circuit was first created, producing increasingly denser and increasingly smaller components and the concentration of ever increasing computing power in such components is evident to all who use laptops, tablets, and smart phones. There is a celebrated conjecture—called Moore’s law, after its inventor, American engineer Gordon Moore—that the density of basic circuit components on a single chip doubles approximately every two years, which has been empirically borne out over the years.
But given a particular state of the art of physical technology, computer architects have evolved techniques to increase the throughput or speedup of computations, measured, for example, by such metrics as the number of instructions processed per unit time or the number of some critical operations (such as real number arithmetic operations in the case of a computer dedicated to scientific or engineering computations) per unit time. These architectural strategies fall under the rubric of parallel processing.
The basic idea is quite straightforward. Two processes or tasks, T1, T2 are said to be executable in parallel if they occur in a sequential task stream (such as instructions in a sequential program) and are mutually independent. This mutual independence is achieved if they satisfy some particular conditions. The exact nature and complexity of the conditions will depend on several factors, specifically:
(a) The nature of the tasks.
(b) The structure of the task stream, e.g. whether it contains iterations (while do types of tasks), conditionals (if then elses) or gotos.
(c) The nature of the units that execute the tasks.
Consider, for example, the situation in which two identical processors share a memory system. We want to know under what conditions two tasks T1, T2 appearing in a sequential task stream can be initiated in parallel.
Suppose the set of input data objects to and the set of output data objects from T1 are designated as INPUT1 and OUTPUT1 respectively. Likewise, for T2, we have INPUT2 and OUTPUT2 respectively. Assume that these inputs and outputs are locations in main memory and/or registers. Then T1 and T2 can be executed in parallel (symbolized as T1 || T2) if all the following conditions are satisfied:
(a) INPUT1 and OUTPUT2 are independent. (That is, they have nothing in common.)
(b) INPUT2 and OUTPUT1 are independent.
(c) OUTPUT1 and OUTPUT 2 are independent.
These are known as Bernstein’s conditions after the computer scientist A.J. Bernstein, who first formalized them. If any one of the three conditions are not met, then there is a data dependency relation between them, and the tasks cannot be executed in parallel. Consider, as a simple example, a segment of a program stream consisting of the following assignment statements
[1] A ← B + C;
[2] D ← B * F/E;
[3] X ← A – D;
[4] W ← B – F.
Thus:
INPUT1 = {B, C}, OUTPUT1 = {A}
INPUT2 = {B, E, F}, OUTPUT2 = {D}
INPUT3 = {A, D}, OUTPUT3 = {X}
INPUT4 = {B, F}, OUTPUT4 = {W}
Applying Bernstein’s condition, it can be seen that (i) statements [1] and [2] can be executed in parallel; (ii) statements [3] and [4] can be executed in parallel; however, (iii) statements [1] and [3] have a data dependency (variable A); (iv) statements [2] and [3] have a data dependency constraint (variable D); thus these pairs cannot be executed in parallel.
So, in effect, taking these parallel and non-parallel conditions into account, and assuming that there are enough processors that can execute parallel statements simultaneously, the actual ordering of execution of the statements would be:
Statements [1] || Statement [2];
Statement [3] || Statement [4].
This sequential/parallel ordering illustrates the structure of a parallel program in which the tasks are individual statements described using a programming language. But consider the physical computer itself. The goal of research in parallel processing is broadly twofold: (a) Inventing algorithms or strategies that can detect parallelism between tasks and schedule or assign parallel tasks to different task execution units in a computer system. (b) Designing computers that support parallel processing.
From a computer architect’s perspective the potential for parallelism exists at several levels of abstraction. Some of these levels of parallelism are:
(1) Task (or instruction) streams executing concurrently on independent data streams, on distinct, multiple processors but with the task streams communicating with one another (for example, by passing messages to one another or transmitting data to one another).
(2) Task (or instruction) streams executing concurrently on a single shared data stream, on multiple processors within a single computer.
(3) Multiple data streams occupying multiple memory units, accessed concurrently by a single task (instruction) stream executing on a single processor.
(4) Segments (called ‘threads’) of a single task stream, executing concurrently on either a single processor or multiple processors.
(5) The stages or steps of a single instruction executing concurrently within the ICycle.
(6) Parts of a microprogram executed concurrently within a computer’s control unit.
All parallel processing architectures exploit variations of the possibilities just discussed, often in combination.
Consider, as an example, the abstraction level (5) given earlier. Here, the idea is that since the ICycle consists of several stages (from FETCH INSTRUCTION to UPDATE pc), the processor itself that executes the ICycle can be organized in the form of a pipeline consisting of these many stages. A single instruction will go through all the stages of the pipeline in sequential fashion. The ‘tasks’ at this level of abstraction are the steps of the ICycle through which an instruction moves. However, when an instruction occupies one of the stages, the other stages are free and they can be processing the relevant stages of other instructions in the instruction stream. Ideally, a seven-step ICycle can be executed by a seven-stage instruction processor pipeline, and all the stages of the pipeline are busy, working on seven different instructions in parallel, in an assembly line fashion. This, of course, is the ideal condition. In practice, Bernstein’s conditions may be violated by instruction pairs in the instruction stream and so the pipeline may have stages that are ‘empty’ because of data dependency constraints between stages of instruction pairs.
Architectures that support this type of parallel processing are called pipelined architectures (Figure 6).
As another example, consider tasks at abstraction level (1) presented earlier. Here, multiple processors (also called ‘cores’)—within the same computer—execute instruction streams (belonging to, say, distinct program modules) in parallel. These processors may be accessing a single shared memory system or the memory system itself may be decomposed into distinct memory modules. At any rate, a sophisticated ‘processor-memory interconnection network’ (or ‘switch’) will serve as the interface between the memory systems and the processors (Figure 7). Such schemes are called multiprocessor architectures.

6. An instruction pipeline.
As mentioned before, the objective of parallel processing architectures is to increase the throughput or speedup of a computer system through purely architectural means. However, as the small example of the four assignment statements illustrated, there are limits to the ‘parallelization’ of a task stream because of data dependency constraints; thus, there are limits to the speedup that can be attained in a parallel processing environment. This limit was quantitatively formulated in the 1960s by computer designer Gene Amdahl, who stated that the potential speedup of a parallel processing computer is limited by that part of the computation that cannot be parallelized. Thus the speedup effect of increasing the number of parallel execution units levels off after a certain point. This principle is called Amdahl’s law.
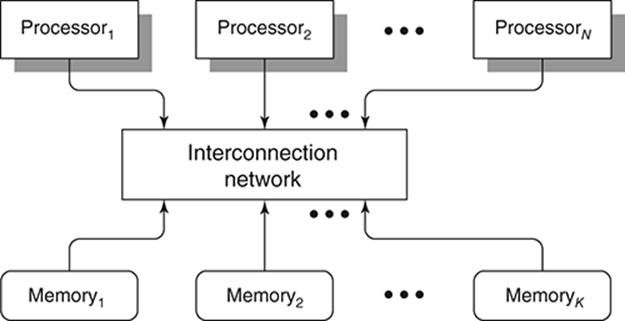
7. Portrait of a multiprocessor.
The science in computer architecture
The reader having reached this section of the chapter may well ask: granted that computer architectures are liminal artefacts, in what sense is the discipline a science of the artificial?
To answer this question we must recognize that the most striking aspect of the discipline is that its knowledge space consists (mainly) of a body of heuristic principles, and the kind of reasoning used in designing computer architectures is heuristic reasoning.
Heuristics—from the Greek word hurisko, ‘to find’—are rules or propositions that offer hope or promise of solutions to certain kinds of problems (discussed in the next chapter) but there is no guarantee of success. To paraphrase Hungarian-American mathematician George Polya who famously recognized the role of heuristics in mathematical discovery, heuristic thinking is never definite, never final, never certain; rather, it is provisional, plausible, tentative.
We are often obliged to use heuristics because we may not have any other option. Heuristics are invoked in the absence of more formal, more certain, theory-based principles. The divide-and-conquer principle discussed in Chapter 3 is an example of an ubiquitous heuristic used in problem solving and decision making. It is a plausible principle which might be expected to help solve a complex problem but is not guaranteed to succeed in a particular case. Experiential knowledge is the source of many heuristics. The rule ‘if it is cloudy, take an umbrella’ is an example. The umbrella may well be justified but not always.
The use of heuristics brings with it the necessity of experiment. Since heuristics are not assured of success the only recourse is to apply them to a particular problem and see empirically if it works; that is, conduct an experiment. Conversely, heuristic principles may themselves be derived based on prior experiments. Heuristics and experiments go hand in hand, an insight such pioneers in heuristic thinking as Allen Newell and Herbert Simon, and pioneers of computer design such as Maurice Wilkes fully grasped.
All this is a prelude to the following: The discipline of computer architecture is an experimental, heuristic science of the artificial.
Over the decades since the advent of the electronic digital computer, a body of rules, principles, precepts, propositions, and schemas have come into being concerning the design of computer architectures, almost all of which are heuristic in nature. The idea of a memory hierarchy as a design principle is an example. The principle of pipelining is another. They arise from experiential knowledge, drawing analogies, and common sense observations.
For example, experiences with prior architecture design and the difficulties faced in producing machine code using compilers have yielded heuristic principles to eliminate the difficulties. In the 1980s, the computer scientist William Wulf proposed several such heuristics based on experience with the design of compilers for certain computers. Here are some of them:
Regularity. If a particular (architectural) feature is realized in a certain way in one part of the architecture then it should be realized in the same way in all parts.
Separation of concerns. (Divide and rule.) The overall architecture should be partitionable into a number of independent features, each of which can be designed separately.
Composability. By virtue of the two foregoing principles it should be possible to compose the separate independent features in arbitrary ways.
But experiments must follow the incorporation of heuristic principles into a design. Such experiments may entail implementing a ‘prototype’ or experimental machine and conducting tests on it. Or it may involve constructing a (software) simulation model of the architecture and conducting experiments on the simulated architecture.
In either case the experiments may reveal flaws in the design, in which case the outcome would be to modify the design by rejecting some principles and inserting others; and then repeat the cycle of experimentation, evaluation, and modification.
This schema is, of course, almost identical to the model of scientific problem solving advanced by philosopher of science Karl Popper:
![]()
Here, P1 is the ‘current’ problem situation; TT is a tentative theory advanced to explain or solve the problem situation; EE is the process of error elimination applied to TT (by way of experiments and/or critical reasoning); and P2 is the resulting new problem situation after the errors have been eliminated. In the context of computer architecture, P1 is the design problem, specified in terms of goals and requirements the eventual computer must satisfy; TT is the heuristics-based design itself (which is a theory of the computer); EE is the process of experimentation and evaluation of the design, and the elimination of its flaws and limitations; and the outcome P2 is a possibly modified set of goals and requirements constituting a new design problem.