Total Information Risk Management (2014)
PART 1 Total Information Risk Management Background
CHAPTER 2 Enterprise Information Management
Abstract
This chapter gives an introduction to concept of enterprise information management, investigates the influence of Big Data on EIM, and discusses today’s key challenges and pressures for EIM.
Keywords
EIM Strategy; EIM Governance; EIM Components; Big Data and EIM; Challenges for EIM
What you will learn in this chapter
![]() How to set up EIM governance
How to set up EIM governance
![]() Things to be considered when creating a strategy for EIM
Things to be considered when creating a strategy for EIM
![]() What the different components of EIM are that should be considered
What the different components of EIM are that should be considered
![]() How Big Data and other challenges create new pressures for EIM
How Big Data and other challenges create new pressures for EIM
What is enterprise information management?
Enterprise information management (EIM) is the organizational-wide management of information in a coordinated framework of disciplines. Information management is the management of the processes and systems that create, acquire, organize, store, distribute, and use information with the goal of helping people and organizations access, process, and use information efficiently and effectively (Detlor, 2010). David Marco, a leading data management practitioner, defines EIM as “systematic processes and governance procedures for applications, processes, data, and technology at a holistic enterprise perspective” (Marco, 2012). The orchestration of the multitude of disciplines requires a unified governance approach and strategy, which are illustrated in Figure 2.1.
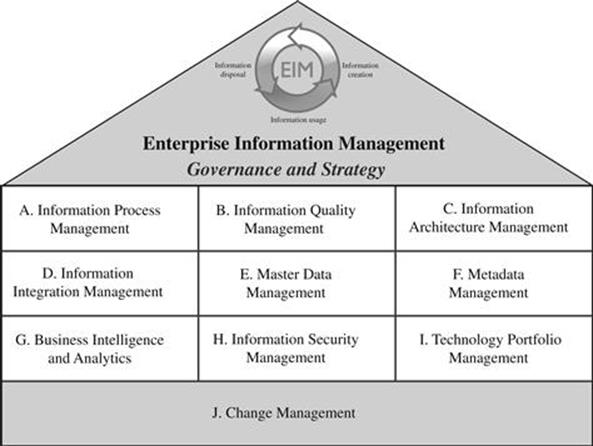
FIGURE 2.1 Key components for EIM.
After describing EIM governance and EIM strategy, subsections A to J describe some of the components of EIM; this is not meant to be an exhaustive list, but rather highlights the diversity of different aspects that need to be considered as part of EIM.
![]() IMPORTANT
IMPORTANT
EIM is the organizational-wide management of the processes and systems that create, acquire, organize, store, distribute, and use information with the goal of helping people and organizations access, process, and use information efficiently and effectively.
![]() ATTENTION
ATTENTION
EIM is an interdisciplinary framework. This means that many parts of EIM overlap with other organizational functions. EIM efforts usually have to be coordinated across the different individual business functions.
EIM governance
EIM governance includes all the issues that arise from the need to manage, protect, control, and report information. The benefits accruing from good enterprise-wide information governance include:
![]() Being confident that the foundation upon which activities are undertaken is based on information that is accurate, up to date, and complete.
Being confident that the foundation upon which activities are undertaken is based on information that is accurate, up to date, and complete.
![]() Having the right information, in the right place, at the right time, available to the right people in the right format, which in turn facilitates faster decision making and execution of the right actions.
Having the right information, in the right place, at the right time, available to the right people in the right format, which in turn facilitates faster decision making and execution of the right actions.
![]() Employees have the best information available to them making them more effective in discharging their responsibilities.
Employees have the best information available to them making them more effective in discharging their responsibilities.
![]() Establishing and maintaining a reputation for reliability and openness in transactions with all stakeholders.
Establishing and maintaining a reputation for reliability and openness in transactions with all stakeholders.
![]() The organization does not leave itself exposed to claims of information malpractice.
The organization does not leave itself exposed to claims of information malpractice.
![]() Being confident that the organization has met its obligations in terms of compliance needs and can confidently withstand any challenges made in this regard.
Being confident that the organization has met its obligations in terms of compliance needs and can confidently withstand any challenges made in this regard.
Good EIM governance can and does lead to enhanced stakeholder experience. It can also help with innovation and expansion policy. Benefits will vary from organization to organization and you may identify other areas where your particular organization can benefit from having good information governance. Information governance does not seek to stifle operations; on the contrary, it seeks to enhance them.
John Ladley defines the following critical success factors for information governance (Ladley, 2012):
![]() Is mandatory for the successful implementation of any project or initiative that uses information.
Is mandatory for the successful implementation of any project or initiative that uses information.
![]() Has to explicitly show business value.
Has to explicitly show business value.
![]() Requires the management of organizational culture change.
Requires the management of organizational culture change.
![]() Is an enterprise effort.
Is an enterprise effort.
One of the most important parts of EIM governance is to create the information policy for an organization. An information policy will provide a set of guidelines within which work processes are performed. It will ensure that all employees know the parameters and boundaries for, among other things, the effective management of information risk. Once the information policy has been developed, then the EIM strategy will articulate how the policy is to be put in effect. This will include internal control procedures for information risk management.
![]() IMPORTANT
IMPORTANT
Information policy is an overarching statement setting out why information management is mission critical to the organization and how it sits within a wider organizational expression of objectives.
![]() ACTION TIP
ACTION TIP
The information policy should be clear, concise, and realistic, and provide employees with a framework upon which they can build and develop skills that enable them (and consequently also the business) to compete effectively in a rapidly changing environment.
Once developed within the organization, the information policy needs to gain not only acceptance but commitment as well. Employee commitment is vital, because without it, the information policy will not gain traction and it will not take its rightful place in organizational activity. This could lead to significant risk. The engagement of employees should be achieved by involving them in discussions about the impact on individual roles and by clarifying what is expected of them to fulfill the policy.
When the information policy has been agreed on, the next step is to develop the EIM strategy that will enable implementation of the policy. This means turning the policies into objectives, targets, milestones, and specific actions, and this is where information governance starts. Strategy implementation may be challenging, and it should not be underestimated. Communication is key but should not be too directional—employees always respond to new ways of working if they feel they have been able to contribute to the debate and their voice has been heard. Build consensus by presenting employees with opportunities and conditions for change. That said, bear in mind that the debate needs to be balanced with fulfilling business objectives. The level of empowerment/debate should be appropriate to both an organization and an employee’s role.
Neither the EIM governance policy nor the EIM strategy should be left unchecked for more than six months. As highlighted previously, the information economy is subject to rapid change. Any business should scan the horizon on a regular basis to find new ways to remain alive to the impact of changes that may have occurred in its current sphere of operations. Information policy and strategy should be flexible enough to respond to any significant changes whether they are internal or external, or indeed a combination of both.
EIM strategy
EIM strategy is the approach that an organization takes to orchestrate its technology, organization, and people to build and sustain the organization’s information management capability. It basically sets the goals and approach for EIM governance. EIM should be derived from and closely aligned to the corporate business strategy and business objectives.
![]() IMPORTANT
IMPORTANT
EIM strategy is the approach that an organization takes to orchestrate its technology, organization, and people to build and sustain the organization’s information management capability.
Sometimes information strategy can influence business strategy as it might have the potential to transform the business to increase competitive advantage. EIM strategy consists of three parts:
1. Technology strategy, which is the approach to manage the IT infrastructure.
2. Systems, which are the information systems and surrounding business processes.
3. Content, which is the information contained in the systems.
The ultimate goal is the creation of an information-enabled enterprise that is driven by information in all its core activities, which can lead to a sustainable competitive advantage in the market. EIM strategy goes far beyond technological issues, incorporating aspects such as strategic management, globalization, change management, and human/cultural issues (Galliers and Leidner, 2009). EIM strategy has to coordinate a number of different disciplines, which are explored in the following sections.
A Information process management
In Chapter 1, the concept of the life cycle of data and information assets was introduced. Data and information assets need to be created, organized and stored, processed, accessed and used, and, at the end of their life, archived or deleted. Different business units in their day-to-day operations will carry out the processes associated with these stages. In some cases, for example, they may share the responsibility of collecting and storing information. Information process management is the stage of ensuring the effective management of all these processes throughout the organization so that not only is the right information delivered to the business units, but also it is available at the right time in the business process.
If you consider the different business processes that are carried out in an organization (e.g., preparing a product for dispatch to the customer), parts of these processes will intersect with the information processes. Focusing on information processes is like viewing the business processes through a filter that shows only the activities related to information. Managers can therefore direct their attention toward determining whether the required information is being provided at the relevant stages of the business process. Typical questions include:
![]() Is the right information being captured?
Is the right information being captured?
![]() Is the information being distributed to the systems that need it?
Is the information being distributed to the systems that need it?
![]() Can the users get access to the information when they need it?
Can the users get access to the information when they need it?
![]() Is the correct information being identified for archiving and deletion?
Is the correct information being identified for archiving and deletion?
![]() IMPORTANT
IMPORTANT
Information process management ensures the effective management of all the processes throughout the life cycle of data and information assets.
To ensure that the information processes deliver what is needed, the quality of the information and how this is affected by the different transformations (e.g., processing and distribution of information) needs to be considered.
B Information quality management
Information quality management (IQM) is concerned with the question of how to sustain information that is fit for all user needs throughout the organization. This implies that in places where information does not meet user requirements, information quality improvement actions have to be initiated. Therefore, a major part of IQM is understanding what and why information is deficient and bringing it up to the required quality level. These activities are typically referred to as information quality assessment and information quality improvement.
![]() IMPORTANT
IMPORTANT
IQM ensures that data and information assets are fit for use for all information user groups. Assessing data and information quality and then initiating changes to improve deficiencies in quality will achieve this aim.
One of the first data and information quality methodologies was Total Data Quality Management (TDQM) (Wang et al., 1998). Wang and colleagues define a TDQM cycle, which consists of four steps: define, measure, analyze, and improve. An information quality methodology can be data or process driven, can concentrate on assessment or improvement, and may follow a special purpose or a general purpose. A majority of information quality assessment techniques support only structured (i.e., in databases) or semi-structured (e.g., XML-formatted data) data but are not suitable for unstructured data, such as presentation slides or word-processed documents. The assessment of information quality can be partly automated with existing software tools like data profiling that include column analysis, matching algorithms, and semantic profiling (see Chapter 12). However, there are limitations with regard to what problems these methods are able to detect.
![]() ACTION TIP
ACTION TIP
Data quality software tools can often help assess the quality of data and information assets.
Information quality improvement uses the outputs of the assessment phase to determine what data needs to be improved and by how much. It may still be possible to operate with data that is not 100% accurate, and therefore the data should only be improved to the level that is needed to operate effectively. Additional resources, time, and effort that are required to improve the data further would be wasted if other key data is waiting to be improved to satisfactory levels. In the long term, and when priorities dictate, organizations can strive for full fitness for purpose of all data and information assets.
C Information architecture management
With multiple information systems at the organization’s disposal and many informational demands from people in various business units, the problem of how to organize and lay out the assortment of systems is critical for effective working. It is not unlike the problems that architects of physical buildings aim to solve in that information architecture is about where the information should be placed and how the different pieces fit together.
In a hotel, where a bathroom is being shared by multiple bedrooms, the architect (hopefully!) places the bathroom where everyone who needs it can get easy access without disturbing others—usually, at the end of the hall. If the architect places the bathroom in one of the bedrooms, then the unlucky person who books the room with the communal bathroom will face unwelcome interruptions by those who want to use the bathroom.
Analogous problems and constraints are faced by the information architect, who must place the information needed by multiple parties in a place where it is easily accessible to those people. There are, however, usually many constraints that dictate factors, such as the size and location of information systems and how they can be connected. The information architecture needs to find the right balance between these constraints while satisfying user needs.
![]() IMPORTANT
IMPORTANT
Information architecture management creates the blueprint for the design of the interaction among the different organizational information systems; it also provides recommendations to general EIM based on the insights generated from the blueprint.
At the more detailed level within each information system, the data must be arranged efficiently and effectively. Data modeling covers how the data will be arranged in the system, and by far the most common structure is the relational model (as evidenced by its use in numerous databases). In this model the process of normalization is used to ensure that a structure is produced that ensures, for example, that data updates are propagated correctly and data redundancy is removed or mitigated.
Given the blueprint for the design of the interaction between the different organizational information systems and the data models, there are technical challenges regarding how best to integrate the information from one system to another.
D Information integration management
Cast your mind back to the days when an organization only had one information system. Based on the efficiencies and potential that this system offered, it was not long before other departments in the organization followed suit and introduced their own systems; this brought with it the new technical challenge of how to share and merge the data between these systems. What is needed in this case is for the information from one system to be correctly integrated into the information in another system so that the users can access the new information seamlessly.
Information integration is needed in numerous different scenarios:
![]() Application consolidation (combining two or more information systems into one)
Application consolidation (combining two or more information systems into one)
![]() Replacement of legacy systems (moving the data to the new system)
Replacement of legacy systems (moving the data to the new system)
![]() Finding new uses for the data (moving the data to the new system)
Finding new uses for the data (moving the data to the new system)
![]() Archiving and moving data to a place where future analysis can be performed (a common destination is a data warehouse)
Archiving and moving data to a place where future analysis can be performed (a common destination is a data warehouse)
![]() Batch/continuous transfer of information between systems (to keep overlapping systems synchronized)
Batch/continuous transfer of information between systems (to keep overlapping systems synchronized)
While information integration is needed for numerous applications, it is not an easy task, and the key challenges stem from the differences in syntax, semantics, and structure of the information.
Examples of syntax differences relate to data fields that may contain abbreviated values in one system and not in another, values that are formatted differently (e.g., U.S. and U.K. date formats), and telephone numbers that contain the area code in one system and omit the area code in another system.
Semantic differences are exemplified by data values that inadvertently change meaning when transferred to another system. For example, this can occur when each system references countries via different codes—in one system the United States could be allocated the code 1 and the United Kingdom the code 2, and in another system these could be reversed. Any data that is transferred between these systems that does not take this semantic difference into account will reference the wrong country.
Differences in data structures between the systems can occur, for example, where the field names and data types (e.g., text or numerical) for data values differ; the data values for a customer may be in a single row in one table in the destination system, whereas in the originating system, those values may be dispersed between different tables, and the originating source may hold data in an unstructured way; the latter would need to be given the relevant structure before it is integrated.
These challenges provide many opportunities to introduce errors into the data when transferring it to another system, and therefore close attention to any reduction in information quality is needed during the integration process. It is not surprising, therefore, that organizations often take the chance during information integration to attempt to actually improve the quality of the data in the original system and clean up any problems before the data is loaded into the new system.
The general process of information integration involves extracting the information from the originating system, analyzing it, and making the necessary transformations. These activities are key to ensuring that information quality is not reduced during information integration before the transformed data is then loaded into the target system. This is commonly referred to as extract, transform, and load (ETL).
The loading process changes are dependent on the data type in the target system. For example, with data such as customer records, it would not be desirable to append multiple records of the same customer to the target system. The loading process needs to ensure that only a single customer record is retained. Whereas in the case of historical data, it may be desirable to append similar-looking records to facilitate temporal analysis.
E Master data management
Certain data, such as customer records, are central to an organization and are utilized by multiple departments. Each department may have its own system that references the customer record. Master data management covers the procedures that are needed to handle this type of key organizational data to ensure that it is managed correctly and that each user has access to it when needed. The main challenge with master data is the detection and removal of duplicate records (e.g., customer names). Effective master data management should not allow different users of the systems to make changes to one customer record while disseminating a different customer record to other departments (or even the same department).
Master data management solutions to duplicate records involve either ensuring the correct synchronization between duplicates by ensuring that any data updates are propagated to the other identical record(s) or removing the duplicates altogether. Over the years, a significant amount of effort has gone into duplicate detection and removal, which is also known as identity resolution, the merge-purge problem, record linkage, etc. These techniques often involve comparing the records to determine whether the values are similar and then classifying two records as a match, nonmatch, or unknown. In the latter case, it is often necessary for human users to review and make the final decision as to whether the records refer to the same entity.
F Metadata management
Metadata is data about data. Metadata management is about proposing, reviewing, agreeing to, endorsing, facilitating the observance of, rewarding compliance with, and managing metadata policies. Policies consist of a concept, a context, and a process. There are different types and layers of metadata:
![]() Business definitions of metadata include concepts, business terms, definitions, and semantics of data.
Business definitions of metadata include concepts, business terms, definitions, and semantics of data.
![]() Reference metadata includes conceptual domains, value domains, reference tables, and mapping. Data elements metadata includes critical data elements, data elements definitions, data formats, and aliases/synonyms.
Reference metadata includes conceptual domains, value domains, reference tables, and mapping. Data elements metadata includes critical data elements, data elements definitions, data formats, and aliases/synonyms.
![]() Information architecture metadata includes entity models, relational tables, and master object directory.
Information architecture metadata includes entity models, relational tables, and master object directory.
![]() Data governance metadata includes information usage, information quality, information quality service-level agreements (SLAs), and access controls.
Data governance metadata includes information usage, information quality, information quality service-level agreements (SLAs), and access controls.
![]() Services metadata includes service directory, service users, and interfaces.
Services metadata includes service directory, service users, and interfaces.
![]() Business metadata includes business policies, information policies, and business rules.
Business metadata includes business policies, information policies, and business rules.
![]() Metadata policies need to analyze, identify, document, and harmonize definitions and put shared repositories into place.
Metadata policies need to analyze, identify, document, and harmonize definitions and put shared repositories into place.
Another task area is providing naming standards for data (e.g., “PersonLastName”, “OrderMonthly TotalAmount”), which can improve syntactical and semantic consistency, reduce lexical complexity, and help employ a controlled vocabulary. Furthermore, data model standards have to be designed for data elements (e.g., data element names, types, representations, formats, and entity modeling standards), which can include master data domains and standards attributes. Part of the activity process should also discover existing metadata (i.e., data values, business rules, and object relationships) and make it explicit. Data standards need to be harmonized into one coherent policy document that everyone in the organization has to comply with. A core aim should be to educate the rest of the organization that this policy document exists and how they can comply with it. Moreover, data and business rules are defined with due consideration to the business policy and context.
Metadata can support information integration across the enterprise, standardize the use of information, simplify data management, and make master data management consistent. It can, therefore, enable and improve effective business intelligence. Difficulties in metadata management appear because data policies are often defined but not enforced and complied with in practice.
![]() ATTENTION
ATTENTION
Many organizations neglect the importance of metadata. An enterprise-wide approach to metadata management is essential, otherwise all other EIM efforts may be jeopardized.
G Business intelligence and analytics
Business intelligence has the goal of providing decision makers with timely and actionable business insights. The term refers to the capability of the organization to transform its information into useful knowledge. Business intelligence is often implemented using a data warehouse that can hold vast amounts of information, primed for various types of analysis.
Business analytics builds on business intelligence solutions and involves analyzing and interpreting organizational data with advanced methods (e.g., statistical analysis and data mining) to improve decision making and optimize business processes. When large data sets are analyzed, the notion of Big Data analytics is frequently used and often builds on new technologies, such as Hadoop, to enable the analysis of these large data sets.
![]() IMPORTANT
IMPORTANT
Business intelligence has the goal of providing decision makers with timely and actionable business insights, often in the form of a data warehouse. Business analytics involves analyzing and interpreting organizational data with advanced methods (e.g., statistical analysis and data mining).
Since a successful business intelligence and analytics project can directly drive the success of core business activities, it is usually considered a strategic investment. To succeed, besides using new technology, business analytics projects usually require a change in organizational mindset as well as the up-skilling of employees in analytics and in the use of new technologies.
Data analysis, reporting, and query tools are all part of business intelligence and can help to deal with the volume of data. Although traditionally business intelligence is usually tightly connected to data warehousing, there are attempts to transform business intelligence by linking it with service-oriented architectures that can provide data from the furthest corners of the business.
With the significant effort that organizations invest in maintaining and analyzing their key data, another very important area in EIM is keeping this information secure.
H Information security management
All organizations hold some information that is private to them and they would not want people external to the organization to gain access to, especially their competitors. Besides business secrets, organizations may be under obligations to protect parts of their information from public consumption, such as private customer information; the Data Protection Act in the United Kingdom is an example of regulations that can require this kind of protection. Information security is concerned with the practice of protecting this information from unauthorized access, use, disclosure, modification, or destruction.
Access to information within organizational information systems is granted (or withheld) by the access control mechanisms. Most of us are familiar with the process of logging into our computers with a username and password; this is a form of access control authentication. Authentication is used by the system to verify your identity—that is, determine that you are who you say you are. Once your identity has been established, the process of authorization is used to ensure that you only have access to the information in the system that you should have access to. Not all users should have access to all the information within a system, and a typical example is with military information. Depending on the value of the information, it is assigned different levels of classification from top secret to unclassified. The access control mechanism ensures that only those people who are cleared to see top-secret information can do so. This is referred to as mandatory access control. Most organizations use a slightly more convenient model called role-based access control where access to information resources is granted based on the role that the user performs within the organization.
Incorrect operation of access control can have consequences on data quality. For instance, if the access control mechanism unnecessarily withholds data from the users, then this affects the accessibility of the data, and the users may be forced to make decisions without all the necessary data. There is a constant trade-off between making the data accessible to the users and keeping it secure: to make the information in a system completely secure, you simply withhold all information from everyone, and to make the information accessible, you simply release everything. Clearly, most organizations need to find a balance between these two extremes.
I Technology portfolio management
Data and information rely heavily on the support of information technology, which includes hardware, middleware (e.g., databases and server management programs), and software applications. The introduction of a new IT system is often very expensive and requires a lot of effort. As a number of IT projects are often run simultaneously, the technology portfolio has to be managed in a unified manner. Many organizations face challenges in evaluating IT investments in terms of costs and benefits as part of the investment decisions, since it is very difficult to identify all changes that will be attributable to the IT investment, and it is even more difficult to understand how to measure the changes in terms of value. The main benefits of IT investments typically include an enhancement of the business architecture and an improvement of business processes. Information risk management can provide important input to IT project portfolio management and planning. Technological changes are often needed to address data and information quality problems.
J Change management
Most data and information management projects require changes in the organization, which is one of the most difficult things to do as humans are naturally resistant to change. The success of a strategy and a project is strongly dependent on the capability of the management to mobilize their employees to follow the strategy and the changes outlined in the project. Change management is an art of its own, with many excellent books written on the topic. It requires some basic knowledge of the theory of change management and a lot of practical experience in dealing with human psychology and the politics in an organization. Chapter 13 addresses these important “softer” factors of EIM.
Big data and how it requires new thinking in EIM
We have discussed how the amount of data that is captured and stored is growing exponentially. Never before has so much data been available about so many different things. Data can be captured in all parts of real life by ubiquitous computing systems armed with different types of wireless sensors, data logs, cameras, mobile devices, GPS, microphones, or RFID tags (to name a few). In 2009, the data available on the web reached 500 billion gigabytes, and it is expanding fast day by day. At the time of writing, over 600 million people around the world are sharing information about their social life on platforms like Facebook, Google Plus, and Twitter. Scientific experiments have a growing need for computing capacity as they try to find unexpected patterns and interpret evidence in very large data sets. An example of the latter is provided in the following case study.
CASE STUDY: BIG DATA AT THE WORLD’S LARGEST EXPERIMENT
At CERN, the European Organization for Nuclear Research, the world’s largest multinational science experiments take place in the Large Hadron Collider (LHC). These experiments aim to provide answers to fundamental questions about our universe. In very recent times the Higgs Boson particle was discovered at CERN, which has often been referred to as the “God particle” by the media, as it enables answers to be given to many important questions raised about the universe. Twenty European nations are currently members in the large experiments taking place in the LHC. CERN has its own farm of 10,000 servers plus an international network of over 150 data centers around the world. The data network processes 300,000 MB per second of experimental data that describes events happening in the accelerator tunnel as part of the ATLAS experiments. Due to limited storage capacity, of the 300,000, only 300 MB can actually be saved, thus decisions in real time have to be made about which event data is actually saved. This requires very efficient selection algorithms that evaluate these events. Per year,15 million gigabytes of data are saved in over 10 data centers across Europe, which are further processed and analyzed by the 150+ data centers. In parallel to the experiments, Monte Carlo simulations are run that simulate what the theory predicts will happen in the accelerator to enable comparison with what actually happens. This allows the testing of existing theories about high-energy particles, matter, antimatter, and our universe. Currently, CERN is evaluating if cloud computing could be used in the future, in addition to the existing grid of data centers, to form something that is referred to as the science cloud. CERN is only one example of how the volume of data is growing and the challenges that arise from this.
(Jones, 2012)
![]() ACTION TIP
ACTION TIP
There are two simple but important rules for Big Data strategy:
1. You have to know what you want to get out of the data and information assets.
2. You have to know where data and information quality have to be improved so you are really able to get what you need out of your data and information assets.
Additionally, concepts such as cloud and mobile computing are emerging as potentially game-changing paradigms. Many real-word activities require interactions between humans and computers, and these occur in an online environment where a lot of data about these interactions is stored. When data sets become too big to handle, new methods are required for capturing, storage, retrieval, sharing, analysis, and visualization; these set new requirements for effective information management.
EIM is at a crossroads because we are entering a new era, the era of Big Data, in which many data sets are becoming too big to be managed with conventional database management tools. Big Data has become a fashionable buzzword these days. It typically refers to the three V’s of data: volume, variety, and velocity. In organizational management, Big Data is understood to be the challenge that is set by these large data sets that in turn leads to a requirement to develop a new strategy in information management. Traditionally, data has often been stored and processed without too much thought about what it is actually needed for, or for a primary purpose. However, other secondary usages have not always been taken into consideration (e.g., data that is collected in a sales process for accounting purposes) might also be of significance to make marketing decisions. Organizations have to rethink their approaches if they want to succeed in the era of Big Data. Because there is so much data and information available, it is necessary to have a plan. You have to know what you want to get out of the data and information assets. Moreover, data and information quality is often not good enough, but it is simply impossible to improve the large volumes of diverse information and data. You have to know where data and information quality is most important for your business and have a clear focus.
Further challenges for EIM
Besides Big Data there are many other changes that arise from technology, politics, society, and business that impact EIM and present new challenges. Some of the challenges are discussed in the following sections.
Globalization as a challenge and driver for better EIM
Friedman analyzed in his bestseller The World Is Flat: A Brief History of the Twenty-First Century how our world has recently become more closely connected as globalization has penetrated all parts of the economy (Friedman, 2007). Politically, there are fewer boundaries for international economic activities after the end of the Cold War, symbolized by the fall of the Berlin Wall. Technically, the rise of the Internet made information accessible and software-enabled organizations could collaborate in real time all over the world. Many products became digital, and can now be delivered to customers in the blink of an eye—most noticeably music (iTunes instead of CDs), magazines, and books (Amazon’s Kindle replaces your newsstand and corner bookstore). A lot of economic activities are outsourced to third parties or offshored to new company sites to markets with cheaper labor. A typical manufacturing company often manufactures its products in production sites on more than one continent. It is also supplied with parts and materials by a net of suppliers spanning the globe. Customers are similarly distributed internationally. Increasing globalization sets high demands for information management in organizations. With this panorama, it becomes difficult and complex to orchestrate the supply chain and customer sales and delivery. Providing real-time high-quality information about what is happening locally in different sites of an organization and in the supply-chain network is not only helpful but essential. Consequently, being able to understand the different needs of customers that are globally distributed also sets new challenges for effective EIM.
Customers becoming more demanding
Customers become more demanding because they know that you actually have the information that is needed to fulfill their needs. Customers understand the possibilities that come with the Internet and increasingly sophisticated IT systems, as they are users of such systems themselves. Twenty years ago, a customer would have been much more understanding if he could not get an answer to his or her question about which shop of a retail store chain a particular product could be found in. Today, it is seen as something basic—that is, information about what is going on in a business is available at one click within seconds. Their customers increasingly perceive organizations that cannot provide timely information as being incompetent. Treacey and Wiersema identified customer intimacy as a third strategic way for competitive advantage besides product leadership and cost leadership, in a very influential Harvard Business Review article (Treacey and Wiersema, 1993). Customer intimacy is the capability to understand customers and react to their changing needs in a very responsive and flexible manner; Big Data is a key enabler of this. Operational intelligence is not something that you can do, it is something that is expected by your customers because they know that it is possible.
Social networks and media
Within a few years, the Web 2.0 could see over half a billion people using social network platforms like Facebook, MySpace, LinkedIn, or Friendster on a daily basis to communicate with their friends, colleagues, and business contacts. In the first phase of the web, mostly factual information was shared among users. Today, a large proportion of information contains social information around private and professional lives—feelings and emotions, photos and videos, and things that people “like.” This large amount of data adds a new dimension to understanding your customers. Social data can be used to complement existing customer relationship management (CRM) corporate data to get a greater understanding of customers. It can enable very powerful marketing analytics. For instance, Twitter data can reveal what customers think about the organization, its products, and service, as well as provide an understanding of which issues affect its reputation. Another popular example is Facebook and LinkedIn data, which can give a richer picture about customers and customer segments, their social network, and their personal preferences. It is important for organizations to tap into this new rich source of personal information without offending their customers and employees.
Growing complexity in enterprise information architectures
When organizations are global, information needs to be shared globally. Different information systems have to be able to communicate with one another across time and geographical boundaries. The numbers of different IT systems, databases, and applications have grown significantly over the past few decades. In many organizations, the IT systems form a labyrinth that no one individual can fully oversee. The IT systems landscape has grown historically without an architecture that has been planned—the architecture simply just emerged. It is like starting the construction of a property without having an architect to design and oversee the development. Moreover, many systems are poorly integrated and are frequently unable to communicate with each other. Each application and database uses its own terminology, formats, and semantics. These matters are further complicated by the cultural environment in the function within which the system is administered and used, as well as its geographical location. IT departments often struggle to get an overview and to manage the systems consistently and effectively. Therefore, reducing the complexity and simplifying IT in a way that it becomes manageable again is one of the major challenges in today’s workplace.
The burden of legacy data and systems
Closely related to this growing complexity is the challenge posed by legacy data and systems that are still required in a business but do not comply with today’s standards. It can be very hard to replace the systems and migrate the data. For instance, approaches to data capture and data models change over time, but the data that has initially been captured according to these methods and models cannot be recaptured again. One has to live with this burden from the past. However, organizations need to control and mitigate the risks that come from these legacy systems and data.
The Internet of Things
”The Internet of Things” is a buzz phrase coined by researchers at the Auto-ID Center initiated by the Massachusetts Institute of Technology to describe the increasing digitalization of the real world (Gershenfeld et al., 2004). We will see sensors and chips being integrated more and more often into our “normal”, meaning nondigital, life. For example, a refrigerator will become more intelligent in the future: it will know what food and drink it contains, when the “consume by” date expires, and which items are running low on stock. A car will know which replacement parts it needs automatically. Our own health could be monitored using sensors and chips strapped to our bodies. Many great opportunities will arise from this trend, but it will almost certainly lead to a new debate on consumer information privacy. Only if consumers trust the systems will they be willing to use them.
Leveraging IT for enterprise-wide transformation
Many new opportunities will arise through enhanced innovative technology. IT investments with innovative and rule-changing characteristics can transform an enterprise as a whole. Organizations have to identify their potential for radical transformation of their business processes. These improvements are not step-by-step improvements, but rather disruptive changes. Organizations need to make themselves ready for transformation; this is an important organizational capability that has to be developed over time. Change is challenging for most people, so effective leadership is key.
Poor alignment of business and IT
Traditionally, the culture in IT departments differs from that seen in other business functions. IT has an interfacing role because its main function is to support core business processes. However, employees who work in the IT department are often more interested in the technology and software than in the business processes supported by such. On the other hand, many business users do not willingly participate in IT projects if they do not have to, because it is a distraction from their day-to-day duties. The environment of the IT department often challenges them due to the lack of legitimacy, multiplicity of stakeholders, and pressures from strategy and financial control. As a consequence, often IT is poorly aligned with the business functions it supports and with the overall business strategies. Approaches such as information architecture management have been developed to improve the alignment between business and IT.
The movement toward the analytical and fact-driven enterprise
A data-driven culture is important for information management success. A metaphorical brick wall to an information-enabled enterprise is that management does not often demand the use of data-driven decisions. McCormack and Trkman draw upon an example of a hotel chain where the use of self-made simple spreadsheet analytics leads to lower employee efficiency because employees spend more time executing a task to make an analytical decision (McCormack and Trkman, 2012). However, this could conversely lead to better results for the organization. The employees stopped applying the analytics because the management did not recognize the value of it and perceived the analytics as a waste time.
The same decision can be made by gut feeling, using an Excel calculation or advanced business analytics, leading most often to better outcomes. Very often management does not push for data-driven decisions. Similarly to the described case, it is sometimes even measured as employee inefficiency because employees need longer to undertake the analytics to reach a better decision. When value is not measured, there is no incentive to look for more analytical decisions.
Summary
This chapter introduced key components of enterprise information management, commenting on current trends and challenges. EIM is the enterprise-wide coordinated management of data and information assets throughout their life cycle. Big Data and other major shifts, such as the globalization of all economies, the advents of social media, and “the Internet of things,” are placing new pressures on EIM.
References
1. Batini C, Cappiello C, Francalanci C, Maurino A. Methodologies for Data Quality Assessment and Improvement. ACM Computing Surveys (CSUR). 2009;41(3):16.
2. Detlor B. Information Management. International Journal of Information Management. 2010;30(2):103–108.
3. Friedman TL. The World Is Flat: The Globalized World in the Twenty-first Century. 2nd ed. New York: Penguin Books; 2007.
4. Galliers RD, Leidner DE, eds. Strategic Information Management: Challenges and Strategies in Managing Information Systems. 4th ed London: Routledge; 2009.
5. Gershenfeld N, Krikorian R, Cohen D. The Internet of Things. Scientific American. 2004;291(4):76–81.
6. Jones B. Big Data at CERN. Barcelona: Keynote at the European Conference on Information Systems (ECIS 2012); 2012.
7. Ladley J. Data Governance: How to Design, Deploy and Sustain an Effective Data Governance Program. 1st ed. San Francisco: Morgan Kaufmann; 2012.
8. Marco D. The First 11 Steps to Starting a World-Class Enterprise Data Stewardship and Governance Program. San Diego: Tutorial at the Data Governance and Information Quality Conference (DGIQ); 2012.
9. McCormack K, Trkman P. Business Analytics and Information Processing Needs: A Case Study. Barcelona: European Conference on Information Systems; 2012.
10. Pascale RT, Athos AG. The Art of Japanese Management. Vol. 24.6 New York: Penguin Books; 1981.
11. Treacy M, Wiersema F. Customer Intimacy and Other Value Disciplines. Harvard Business Review. 1993;71 84–84.
12. Wang RY, Lee YW, Pipino LL, Strong DM. Manage Your Information as a Product. Sloan Management Review. 1998;39:95–105.