Total Information Risk Management (2014)
PART 1 Total Information Risk Management Background
CHAPTER 3 How Data and Information Create Risk
Abstract
This chapter presents a model on how data and information create risk in an organization. It is explained how poor information management leads to data and information quality problems, which then lead to lowered business process performance and eventually create risks in organizations and affect core business objectives.
Keywords
Anatomy of Information Risks; Sources of Information Risk; Information Risk Mitigation; Upside of Information Risk; Quantifying Information Risk
What you will learn in this chapter
![]() An introduction to the anatomy of information risks
An introduction to the anatomy of information risks
![]() The sources of information risk
The sources of information risk
![]() Ways to mitigate information risk
Ways to mitigate information risk
![]() The upside of information risk
The upside of information risk
![]() Why quantifying information risk is worth the effort
Why quantifying information risk is worth the effort
![]() How risk management can help to improve EIM
How risk management can help to improve EIM
Introduction
Information is increasingly becoming an extremely valuable asset in organizations. The dependence on information increases as it becomes more valuable. As value and dependence increase, so does the likelihood of risk. Information risk in this book is defined as the risk that arises from not having the right information of the required quality for a business activity available at the right time. Let’s give you a few examples. If data regarding customer orders is not clearly and accurately captured, your ability to meet the orders at the required quality, quantity, cost, and time will be compromised. If you do not implement long-term strategic management of your physical assets, it can lead to asset failure and production or service loss (e.g., in a power or water network), compromise health and safety, or create environmental, regulatory, and compliance risks. If you are unaware of current market trends, you might invest in the wrong direction, make the wrong acquisitions, and develop the wrong strategies. It is not an exaggeration to claim that information has an important input to most organizational activities. It drives the decisions that we make on a daily basis at all levels of an organization. Therefore, when information is not managed and utilized properly, it can lead to countless risks all over the business. These risks may not always be new risks, however, information can be a key constituent of risks and their mitigation.
In many organizations, lack of data is often not the problem; indeed, the sheer volume of “legacy” data and information available on the web can in itself be quite overwhelming. The issue is how to capture the right data, of the right quality, and make it available to the right decision maker at the right time. Ensuring good data management practices and getting the quality of information right can be a key enabler of success. Many organizations have experienced the same issue: it is too easy to get lost in the overwhelming depth of data that is available, which makes it extremely difficult to choose the right path—one that is closely aligned to the corporate and divisional business strategy—to overcome the obstacles created by poor information. Yet, in our world of constrained resources, it is simply not economically viable or timely to improve the quality of all information assets at the same time. Many activities aimed at improving the quality of information cost time and effort and can only succeed if resources are as targeted as possible to achieve the benefits. We have to prioritize wisely and decide what to prioritize (e.g., resources, activities, and/or information). For this, a thorough understanding of the risk arising from information is the principal key to success. This book will show you a practically proven way that can help you implement an effective information risk management program.
Introduction to the anatomy of information risks
To manage data and information risk, it is important to have an understanding of the way data and information impact an organization. Over the last few years, through consulting and researching with varied organizations across different business sectors, we analyzed hundreds of different data and information risks that we found in these organizations, and with all this material, we created a model that explains and helps to quantify these risks.
Figure 3.1 shows a high-level model of how information risk is created. As discussed in Chapter 2, information management is the organizational capability to manage technology, organization, and people cross-functionally to provide a high-quality level of information quality to all business users. To be successful in information management, for example, the right software tools need to be in place, data collection and processing processes have to be clearly defined, and all the other practices that good information management books teach you need to be promoted and implemented.
![]() IMPORTANT
IMPORTANT
Poor EIM leads to data and information quality problems; this lowers business process performance and eventually leads to negative risks in organizations.
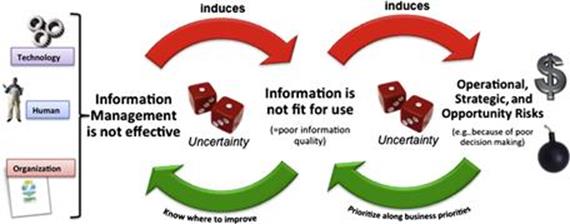
FIGURE 3.1 The anatomy of information risk. (Source: Based on Klassen et al., 2012.)
The consequence of ineffective information management is poor data and information quality
What happens when something does not work optimally in information management? It affects business users’ experience of using information. When information processes are poorly defined and/or poorly implemented, then collected data may not be accurate or it may be ill-formatted or even not collected at all. These issues then create problems once the information needs to be used. When information quality is not monitored (e.g., when no business rules have been defined to check data), problems are not detected on time and they can adversely impact the business processes.
![]() An ill-defined information architecture can lead to information not being able to be exchanged between different software systems where needed.
An ill-defined information architecture can lead to information not being able to be exchanged between different software systems where needed.
![]() Poorly designed data models will make it more difficult to find the right information for users.
Poorly designed data models will make it more difficult to find the right information for users.
![]() Databases that are not fully integrated do not allow information to be combined where it makes business sense for that information to be combined. Therefore, you could create a situation where business users do not to have access to the information they need to optimally run their business processes.
Databases that are not fully integrated do not allow information to be combined where it makes business sense for that information to be combined. Therefore, you could create a situation where business users do not to have access to the information they need to optimally run their business processes.
![]() A lack of high-quality business intelligence and analytics software leads to similar outcomes as those mentioned before.
A lack of high-quality business intelligence and analytics software leads to similar outcomes as those mentioned before.
![]() Missing metadata makes it more difficult to understand the context of the data and makes it more difficult to manage.
Missing metadata makes it more difficult to understand the context of the data and makes it more difficult to manage.
![]() Not providing well-defined access control to information can allow people to access data when they shouldn’t be. Alternatively, rules that are not granular enough might prevent business users from being able to access critical information.
Not providing well-defined access control to information can allow people to access data when they shouldn’t be. Alternatively, rules that are not granular enough might prevent business users from being able to access critical information.
![]() Similarly, if employees do not follow data and business rules, it can also lead directly to data defects. Data and information that suffer from defects can be less fit for use.
Similarly, if employees do not follow data and business rules, it can also lead directly to data defects. Data and information that suffer from defects can be less fit for use.
The consequence of poor information quality is a lowered business process performance
As stated, ineffective information management leads to data defects and a lowered level of information quality. When information is inaccurate, incomplete, ill-formatted, inaccessible, insecure, difficult to understand, or simply unavailable, it is not fit for use and might create problems and lower the performance of business processes for which the information is critical or important. Take, for example, a call center agent who has to respond to a customer request. Not being able to explore the customer history with the company, or being provided with inaccurate information, makes it very likely that the agent will not be able to provide the high level of service that is expected by this customer. However, this does not necessarily always need to be the case. Let’s assume that the address data of the customer making the telephone call is inaccurate in the database of the CRM system, as the zip code is incorrect. Only one-third of the calls might require just the address information. And maybe even fewer than one-third of customer queries really rely on having access to the correct zip code. When something is sent to a wrong zip code, it might still arrive at the right address, if the rest of the address information, such as the house number, street name and city, are correct. Therefore, poor data and information quality can affect the performance of a business process. Yet, there is inherent uncertainty in the effects of information quality. The same information quality problem that leads to a business problem in one situation may not cause a business problem at all in a different situation.
Lowered business process performance creates operational, strategical, and opportunity risk
As we have previously shown, ineffective information management can cause information quality problems and lower business processes performance. This can eventually lead to increased organizational risk. When information is not fit for use in a business process, it can negatively affect many different business objectives as illustrated in Figure 3.2.
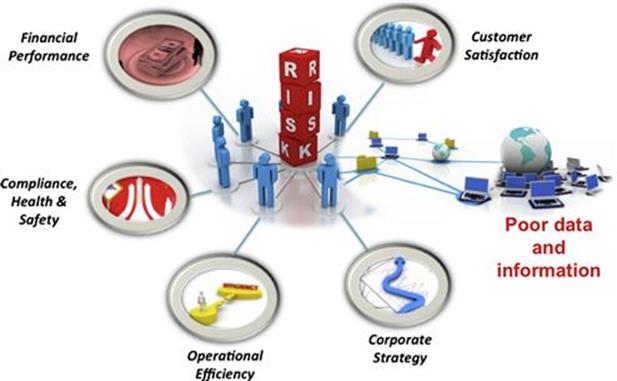
FIGURE 3.2 Poor data and information can affect many different objectives. (Source: jscreationzs / FreeDigitalPhotos.net.)
In the previous example of the call center, customers might not be served as well as desired. When the customer information record is inaccurate or incomplete, this might lower their satisfaction levels and could lead to fewer sales in the long term and therefore to poorer profitability. A company that tries to build its reputation and brand upon being very customer friendly might also have their corporate strategy compromised by such problems.
Moreover, if customers are telephoned with a sales pitch offering them a product that is unsuitable given their particular personal circumstances, then the call center agent’s time is wasted; this will have a negative effect on operational efficiency. As before, the impact on business objectives is not deterministic, but in a case such as this, there is a likelihood that the business objective is actually affected by an information quality problem.
Sources of information risk
Poor data quality can arise due to a variety of different reasons and sources, such as:
![]() Different types of systems in use
Different types of systems in use
![]() Transfer of data between different (often incompatible) systems
Transfer of data between different (often incompatible) systems
![]() Accidental/intentional removal of data
Accidental/intentional removal of data
![]() Improper data governance
Improper data governance
![]() Lack of responsibility and authority for managing data
Lack of responsibility and authority for managing data
![]() Lack of awareness of value of information
Lack of awareness of value of information
![]() Lack of integration between IT and business processes
Lack of integration between IT and business processes
![]() Lack of training and motivation
Lack of training and motivation
A large amount of data has been collected over centuries using hand-based and computer-based systems. The average life cycle of an IT system is usually significantly shorter than the lifespan of the information it contains. Data that has been collected in the past often does not suffice and differs from today’s data specifications and requirements, and is frequently inaccurate and incomplete. Data formats are often inconsistent and create difficultly when attempting to combine different data sources. Quality deteriorates, as often the data is not regularly maintained or updated. Data is often not considered a top priority for operational staff, but is rather a neglected side activity in the hectic day-to-day nature of operations.
Another reason for poor utilization of data and information assets is the lack of awareness of the value of data in an organization and how it can be used more effectively to drive business process performance. Many business processes rely heavily on managers’ own experiences and gut feelings instead of being fact and information driven. Also, certain information usage habits are established once a business process matures, which are not changed without an internal or external impulse, even if there might be new or better ways to use the information to drive decisions in the process. Moreover, IT systems are often poorly integrated and usually not very well aligned to the true business needs. Historically grown, each department often has its own IT systems, its own data definitions, and its own terminology, which makes it hard to share data with other parts of the business. It is hard to convince managers to give up, voluntarily, some of their competencies. And, of course, in the Information Age, information means power, which prevents many people and business divisions from sharing information effectively. Finally, there is traditionally a wall of misunderstanding and miscommunication between the IT function and the rest of the business. The IT function has frequently to make assumptions about the IT users, which are often simply wrong or do not take the full situation into consideration.
Different ways to mitigate information risk
As we have seen, there are many metaphorical brick walls being hit that compromise the effective usage of information assets and cause risks in the business; however, there also are new opportunities in business and technology that have much to offer. In Chapter 2 we discussed the wide range of different components of EIM that span across multiple disciplines. All of these components of EIM can be used to mitigate information risk. There is not only an increasing support for automated data quality assessment and the application of business rules in IT systems, but also for managing master data. Business intelligence technologies and data warehouses can combine data from different sources available in the enterprise.
An important recent development is the rise of the area of data and business analytics that aim to generate new insights from enterprise-wide data by using advanced data mining, statistics, visualization, and analytics tools. There is a clear trend in organizations to aim for more fact- and data-driven decisions, in operations as well as in corporate strategy. A rather novel development is crowd sourcing, a term coined by Jeff Howe of Wired Magazine in 2006. Drawing an analogy to computer-based computation, in the “cloud,” tasks that require human-based computing are outsourced to a “crowd.” This is a large human task force of Internet users who want to do the work for free because it is fun (games with purpose), or they want to support the work (e.g., users who write Wikipedia articles), or they are paid by the task-issuing party per task successfully completed on crowd-sourcing platforms like Amazon Mechanical Turk and Clickworker. There are many successful examples of crowd sourcing, including the classification of galaxies by Internet users, and it is a promising concept that has already proven to be useful for all sorts of human information processing.
The upside of information risk
Information risk also has a positive side to it: the opportunities that can be created. Your organization collects a lot of data every single day. Most of the data is stored in some kind of database and probably never used again. You should try to identify your hidden treasures in data and information. The basic approach is straightforward. Manage your data well so that it is of high quality, integrate your data, apply data analytics, and make your decisions more data driven to make them more successful, as suggested by Tom Davenport in his book Competing on Analytics (Davenport et al., 2007).
But where does information risk come into this? Understanding where information is not fit for use can help you to identify areas where you should focus on improving, using better information, or using information more effectively. It is hard to decide where to begin with data analytics as you have a lot of data and business processes that need data, so you should start where it creates the highest value—information risk management can help you with that. Wake up the unlimited opportunities that are sleeping in your databases. Knowing your customers better, and understanding your supply chain, products, shareholders, and competitors can give an edge to your business.
The case for quantifying information risk
Do you need to quantify data and information risks? This is a legitimate question, because a lot of quantitative numbers need to be gathered to quantify information risk in a meaningful manner. You can save time and effort and just use a simple qualitative scale instead—for example, from 0 to 10 with 0 being no risk and 10 being very high risk. In some cases it can be the right thing to do, especially when reliable numbers for the probabilities and impact of risk cannot be obtained or where costs exceed the benefits of quantitative measurements. Hubbard, a widely acknowledged measurement expert, who defines measurement as “a quantitatively expressed reduction of uncertainty based on one or more observations,” emphasizes, “the only valid basis to say that a measurement shouldn’t be made is that the cost of the measurement exceeds its benefits” (Hubbard, 2010).
In his book How to Measure Anything: Finding the Value of Intangibles in Business, Hubbard stresses that management loves quantitative measurements and he criticizes the use of purely qualitative scales for decision making in organizations (Hubbard, 2010):
One place I’ve seen this many times is in the “steering committees” that review proposed investments and decide which to accept or reject. The proposed investments may be related to IT, new product research and development, major real estate development, or advertising campaigns. In some cases, the committees were categorically rejecting any investment where the benefits were primarily “soft” ones. Important factors with names like “improved word-of-mouth advertising,” “reduced strategic risk,” or “premium brand positioning” were being ignored in the evaluation process because they were considered immeasurable. It’s not as if the idea was being rejected simply because the person proposing it hadn’t measured the benefit (a valid objection to a proposal); rather it was believed that the benefit couldn’t possibly be measured—ever. Consequently, some of the most important strategic proposals were being overlooked in favor of minor cost-savings ideas simply because everyone knew how to measure some things and didn’t know how to measure others. Equally disturbing, many major investments were approved with no basis for measuring whether they ever worked at all.
Hubbard also argues that taking quantitative measurements does not have to be too costly. We highly recommend the book to everyone who wants to understand the basics of quantitative measurement of intangibles such as information risk.
Why risk management becomes important for information management
To summarize, data and information are powerful resources that you should utilize and care deeply about. Getting it right can provide you with almost endless new opportunities, but getting it wrong not only makes you miss out on these opportunities, but also creates risks all over your business that prevent you from performing well. Poor data and information assets can lead to operational and strategic risks in all of your business processes that are crucial to achieve the organization’s goals and objectives. There are a variety of techniques that you could use to improve the quality level of your data and information, as well as to increase the insights that you can gain for your business and eventually transform it into an information-driven enterprise. The problem lies in ensuring that you are making the right choice of techniques out of the mass available.
An extensive understanding of how information (with inadequate quality levels) can cause risks in your organization is crucial to ensure that the right IT investment decisions are made. Building information systems that can cope with various types of risks can cost a fortune, and it can take many years from the initial investment decision to the operationalization of the system. Data usually needs to be migrated from legacy systems and this almost invariably involves high costs and risks. Many external services may be needed to introduce the system. Getting the wrong alignment to business needs in the planning stage of large IT systems is therefore an absolute no-go, something that most organizations simply cannot afford—financially, strategically, and culturally. Unfortunately, poorly planned IT investments do happen all too frequently.
![]() IMPORTANT
IMPORTANT
Risk management methods should be applied to EIM to ensure the effective management of information risks.
Not everything can be planned and there will be always many risks involved in an IT project. However, a major reason for misguided investments is that business plans for IT systems and data quality projects are based on many general assumptions being made about what the business needs. Unfortunately, holding truth without a rigorous analysis of information risks does not often support such business needs. The most important inputs to such projects come from business users who undertake this endeavor only as a side activity in addition to their very demanding day-to-day occupation. Existing organizational processes do not allow business users to be sufficiently involved in the analysis of the business impact of data and information. Additionally, current methods that are available to undertake such an impact analysis are particularly weak and do not provide enough depth and structure.
There is a lot of cognitive bias on what people think about where and how information with inadequate quality levels affects their business. Well-structured methods for assessing information risk that deal with the inherent uncertainty in the relationship between information impact and business outcomes could help to overcome these biases. Such methods have, however, not yet been developed for a general-purpose usage. Fortunately, there is a whole discipline that can provide many helpful concepts, tools, and techniques to deal and manage the effect of uncertainty on business objectives: risk management, which we will introduce in the next chapter.
References
1. Davenport TH, Harris JG. Competing on Analytics: The New Science of Winning. Cambridge, MA: Harvard Business School Press; 2007.
2. Hubbard DW. How to Measure Anything: Finding the Value of Intangibles in Business. New York: John Wiley and Sons; 2010.
3. Klassen V, Borek A, Kern R, Parlikad AK. Quantifying the Business Impact of Information Quality: A Risk-Based Approach. 2012; European Conference on Information Systems, 11-13 June 2012. Barcelona, Spain.