The Antivirus Hacker's Handbook (2015)
Part II. Antivirus Software Evasion
Chapter 7. Evading Signatures
Evading signatures of antivirus (AV) products is one of the most common tasks for both bad guys (such as malware writers) and good guys (such as penetration testers). The complexity of evading AV signatures depends on the amount of information you have in the signature files, the file format involved, and the number of different antiviruses you want to evade.
As discussed in previous chapters, the most typical detection information found in antivirus signatures includes simple CRC32-based checksums. Evading such signatures (which is covered in Chapter 6) with the ClamAV's signature, named Exploit.HTML.IFrame-6, is a matter of determining the exact offset where the checksum is matched and changing at least one bit. However, there are other more complex signatures that cannot be bypassed with such a simple approach. For example, file-format-aware signatures, such as those specific to portable executable (PE) files, do not rely on a single detected evidence in a fixed-size buffer at a specific offset. The same applies to Microsoft Office-supported file formats, such as OLE2 containers and RTF files, and too many other file formats, such as PDF, Flash, and so on. This chapter discusses some approaches that you can use to bypass signatures for specific file formats.
File Formats: Corner Cases and Undocumented Cases
The number of different file formats that an antivirus engine must support is huge. As such, you cannot expect to understand the various file formats as well as the original creators do. There are, and will always be, different implementations of file format parsers from different AV vendors, and therefore their behavior can vary. Some differences exist because of the complexity of the file format, the quality of the file format's documentation, or the lack thereof. For example, for a long time there was no specification at all for the Microsoft Office binary file formats (such as the ones used by Excel or Word). During that time, writing parsers for such file formats involved reverse-engineering and reading notes from random people or groups working on reverse-engineering such file formats (such as when Microsoft Office was partially reverse-engineered in order to add support to Office files in the StarOffice product). Because of the lack of file format documentation, the level of completeness of the AV parsers for OLE2 containers (that is, Word documents) was at best partial and was based on data that may not have been completely true or on inaccurate reverse-engineering efforts.
In 2008, Microsoft made all of the documentation for the binary Office formats freely available and claimed no trade secret rights. The documentation that was released contained a set of 27 PDF files, each consisting of hundreds of pages and totaling 201MB. Common sense thus dictates that no existing AV product would have implemented the entire file format. For example, if an AV company wanted to correctly support the Microsoft XLS (Excel) file format, its engineers would need to go through 1,185 pages of documentation. This poses a problem for AV engineers. The complexity and time required to implement AV solutions indirectly helps malware writers, reverse-engineers, and penetration testers to do their jobs of evading AV scanners.
Evading a Real Signature
This section looks at a generic detection signature used by Kaspersky Anti-Virus, at the end of January 2015, for the malware it calls Exploit.MSWord.CVE-2010-3333.cp. This signature is designed to catch exploits abusing a vulnerability in some old versions of Microsoft Word when processing RTF file formats. When trying to evade detection, you can do so either haphazardly or systematically. The second option is covered here.
To achieve your goal properly and systematically, you need to find answers to these important questions:
· Where are the virus definition files of this AV product?
· What is the format of the virus definition files?
· Where is the code or signature that is specific to the file for which you want to bypass detection?
You start with the easiest question: Kaspersky virus definition files have the *.AVC extension. There are many such files in a common installation, including the files base0001.avc to basea5ec.avc, extXXX.avc, genXXX.avc, unpXXX.avc, and so on. This example looks at the file called daily.avc, where the daily updated routines are stored. If you open this file in a hexadecimal editor—Pyew, in this case—you see a header similar to the following one:
0000 41 56 50 20 41 6E 74 69 76 69 72 61 6C 20 44 61 AVP Antiviral Da
0010 74 61 62 61 73 65 2E 20 28 63 29 4B 61 73 70 65 tabase. (c)Kaspe
0020 72 73 6B 79 20 4C 61 62 20 31 39 39 37 2D 32 30 rsky Lab 1997-20
0030 31 34 2E 00 00 00 00 00 00 00 00 00 00 00 0D 0A 14..............
0040 4B 61 73 70 65 72 73 6B 79 20 4C 61 62 2E 20 30 Kaspersky Lab. 0
0050 31 20 41 70 72 20 32 30 31 34 20 20 30 30 3A 35 1 Apr 2014 00:5
0060 36 3A 34 31 00 00 00 00 00 00 00 00 00 00 00 00 6:41............
0070 00 00 00 00 00 00 00 00 00 00 00 00 0D 0A 0D 0A ................
0080 45 4B 2E 38 03 00 00 00 01 00 00 00 DE CD 00 00 EK.8............
As you can see, this is a binary file with some ASCII strings and an unknown file format. You would first need to reverse-engineer the Kaspersky kernel to determine the file format and unpack it. However, in this case you are lucky because somebody has already done this for you. The infamous 29A's virus writer z0mbie reverse-engineered some old versions of the Kaspersky kernel, discovered the file format of .AVC files, and wrote an unpacker. A GUI tool and its source code are available on the author's web page athttp://z0mbie.daemonlab.org/.
There is another GUI tool based on this code, which is available through the following forum: www.woodmann.com/forum/archive/index.php/t-9913.html.
This example uses the GUI tool AvcUnpacker.EXE. You can get a copy of the daily.avc file from a working installation of Kaspersky (or find a copy using a Google search on the Kaspersky update servers). Open the daily.avc file with the AvcUnpacker.EXE tool. After selecting the correct file, click the Unpack button. Your screen should contain a window similar to Figure 7.1.
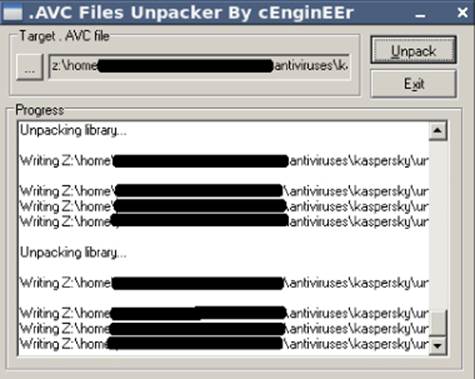
Figure 7.1 The AVC tool unpacking the Kaspersky daily.avc signatures file
After you unpack the daily.avc file, the same directory containing that file will also contain several files and directories (see Figure 7.2).
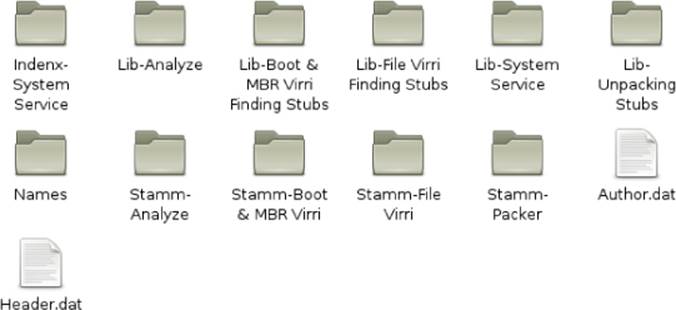
Figure 7.2 Files and directories created after unpacking
Most of the unpacked files are of interest. Start with the first file named Stamm-File Virri/Stamms.txt. If you open it in a text editor, you see something like the following:
------------------------------ 0000 -----------------------------------
File Virri-Signature Length (1) = 00
File Virri-Signature Offset (1) = 0000
File Virri-Signature (1),w = 0000
File Virri-Sub Type = 01
File Virri-Signature (1),dw = 00000000
File Virri-Signature Length (2) = 00
File Virri-Signature Offset (2) = 0000
File Virri-Signature (2),dw = FFFFFFFF
File Virri-Virri Finder stub in=0000-> \\Lib-File Virri Finding
Stubs\Obj0000.obj
File Virri-Name = 000001C9 -> Trojan.Win32.Hosts2.gen
File Virri-Cure Parameter(0) = 00
File Virri-Cure Parameter(1) = 0000
File Virri-Cure Parameter(2) = 0000
File Virri-Cure Parameter(3) = 0000
File Virri-Cure Parameter(4) = 0000
File Virri-Cure Parameter(5) = 0000
-------------------------------------- 0001 --------------------------
File Virri-Signature Length (1) = 04
File Virri-Signature Offset (1) = 0000
File Virri-Signature (1),w = 5C7B
File Virri-Sub Type = 01
File Virri-Signature (1),dw = 7B270921
File Virri-Signature Length (2) = 00
File Virri-Signature Offset (2) = 0000
File Virri-Signature (2),dw = 00000000
File Virri-Virri Finder stub in = 0001 -> \\Lib-File Virri Finding
Stubs\Obj0001.obj
File Virri-Name = 00000000 -> Exploit.MSWord.CVE-2010-3333.cp
File Virri-Cure Parameter(0) = 02
File Virri-Cure Parameter(1) = 0000
File Virri-Cure Parameter(2) = 0000
File Virri-Cure Parameter(3) = 0000
File Virri-Cure Parameter(4) = 0000
File Virri-Cure Parameter(5) = 0000
(…many more lines stripped…)
As you can see, this file contains the virus name, Exploit.MSWord.CVE-2010-3333.cp, and the path to the finder stub, which is actually in the Common Object File Format (COFF), with all the code required for detecting such exploits. Launch IDA Pro and then open this COFF object file. After the initial auto-analysis stage, IDA successfully analyzes the COFF file and displays a very good disassembly with symbol names! The interesting function in this case is _decode. Press Ctrl+E to select the entry point you want, locate the _decodeentry point, and then press Enter to jump to its disassembly listing. You should see a disassembly like the one in Figure 7.3.
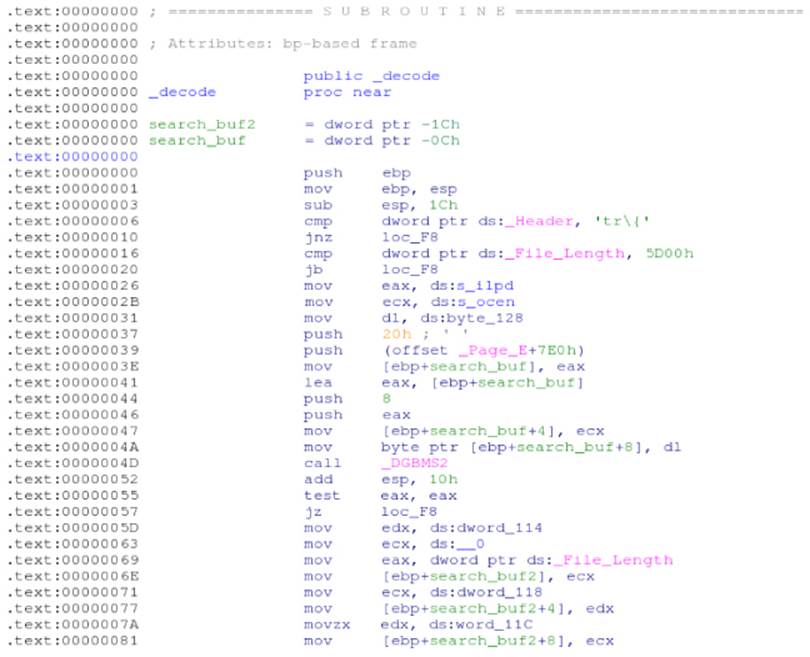
Figure 7.3 Generic detection for uncovering some CVE-2010-3333 exploits
This is all of the code required to detect what Kaspersky calls Exploit.MSWord.CVE-2010-3333.cp. It first checks whether the file header (the ds:_Header external symbol) starts with 0x74725C7B (hexadecimal for 'tr\{') and then checks whether the file length (ds:_File_Length) is longer than 0x5D00 bytes (23,808 bytes). After these initial checks, it references the ASCII strings ilpd and ocen and calls a function named DGBMS2, as shown here:
.text:00000026 mov eax, ds:s_ilpd
.text:0000002B mov ecx, ds:s_ocen
.text:00000031 mov dl, ds:byte_128
.text:00000037 push 20h ; ' '
.text:00000039 push (offset _Page_E+7E0h)
.text:0000003E mov [ebp+search_buf], eax
.text:00000041 lea eax, [ebp+search_buf]
.text:00000044 push 8
.text:00000046 push eax
.text:00000047 mov [ebp+search_buf+4], ecx
.text:0000004A mov byte ptr [ebp+search_buf+8], dl
.text:0000004D call _DGBMS2
.text:00000052 add esp, 10h
If you are unclear as to what the function DGBMS2 does, you could guess that it tries to find a string in the file. Actually, it is trying to find the strings dpli and neco somewhere after the Page_E symbol (each Page_X symbol contains bytes from the file; for example, Page_Acorresponds to the first kilobyte, Page_B to the second kilobyte, and so on). After this search, and only if the search finds something, it seeks to 23,808 bytes before the end of the file, reads 512 bytes in Page_C, and searches for the strings {\\sp2{\\sn1 pF and ments}:
.text:0000005D mov edx, dword ptr ds:__0+4 ; "2{\\sn1 pF"
.text:00000063 mov ecx, dword ptr ds:__0 ; "{\\sp2{\\sn1 pF"
.text:00000069 mov eax, dword ptr ds:_File_Length
.text:0000006E mov [ebp+search_buf2], ecx
.text:00000071 mov ecx, dword ptr ds:__0+8 ; "n1 pF"
.text:00000077 mov [ebp+search_buf2+4], edx
.text:0000007A movzx edx, word ptr ds:__0+0Ch ; "F"
.text:00000081 mov [ebp+search_buf2+8], ecx
.text:00000084 mov ecx, dword ptr _ ; "ments}"
.text:0000008A mov word ptr [ebp+search_buf2+0Ch], dx
.text:0000008E movzx edx, word ptr _+4 ; "s}"
.text:00000095 push 200h ; _DWORD
.text:0000009A add eax, 0FFFFA300h
.text:0000009F mov [ebp+search_buf], ecx
.text:000000A2 mov cl, byte ptr _+6 ; ""
.text:000000A8 push offset _Page_C ; _DWORD
.text:000000AD push eax ; _DWORD
.text:000000AE mov word ptr [ebp+search_buf+4], dx
.text:000000B2 mov byte ptr [ebp+search_buf+6], cl
.text:000000B5 call _Seek_Read
.text:000000BA add esp, 0Ch
.text:000000BD cmp eax, 200h
.text:000000C2 jnz short loc_F8
.text:000000C4 push eax ; _DWORD
.text:000000C5 push offset _Page_C ; _DWORD
.text:000000CA lea edx, [ebp+search_buf2]
.text:000000CD push 0Dh ; _DWORD
.text:000000CF push edx ; _DWORD
.text:000000D0 call _DGBMS2
.text:000000D5 add esp, 10h
.text:000000D8 test eax, eax
.text:000000DA jz short loc_F8
.text:000000DC push 200h ; _DWORD
.text:000000E1 push offset _Page_C ; _DWORD
.text:000000E6 lea eax, [ebp+search_buf]
.text:000000E9 push 6 ; _DWORD
.text:000000EB push eax ; _DWORD
.text:000000EC call _DGBMS2
.text:000000F1 add esp, 10h
If everything is successful, then it returns 1, which means that the file is infected. If any of the evidence is missing, it returns 0, which means that the file is clean. The entire signature can be best viewed in pseudo-code using the Hex-Rays decompiler, as shown inFigure 7.4.

Figure 7.4 Pseudo-code for the _decode routine
After you analyze the logic behind the detection code in the OBJ file, it becomes obvious that you have many different methods for bypassing detection. For example, if you could somehow change the file's header or craft an exploit smaller than 0x5D00 bytes, this code would no longer catch variations of the file. If you could change at least one of the strings that it tries to find after the initial checks are made, the same thing would happen. Because not all the evidence is revealed in the file, it would be discarded by this generic detection. Now that you know what to do, make one small change to the file by putting a space between the \sp2 and \sn1 control words. For illustration purposes, use the malware sample with the following SHA1 hash: deac10f97dd061780b186160c0be863a1ae00579. Check the VirusTotal report for this file at https://www.virustotal.com/ file/651281158d96874277497f769e62827c48ae495c622141e183fc7f7895d95e3f/analysis/
This report show that it is detected by 24 out of 57 scanners, Kaspersky being one of them. If you search for the string {\\sp2{\\sn1 pF and ments} that Kaspersky tries to match, you will find it at offset 0x11b6:
$ pyew 651281158d96874277497f769e62827c48ae495c622141e183fc7f7895d95e3f
0000 7B 5C 72 74 78 61 7B 5C 61 6E 73 69 7B 5C 73 68 {.rtxa{.ansi{.sh
0010 70 7B 5C 2A 5C 73 68 70 69 6E 73 74 5C 73 68 70 p{.*.shpinst.shp
(…many lines stripped…)
[0x00000000]> /s \sp2
HINT[0x000011b6]: .sp2{.sn1 pF}{.sn2 rag}{.*.comment}{.sn3 ments}
{.sv22 3;8;15
You can open this RTF file in a text editor (as RTF files are just plain text files) and add a space between the \sp2 and {\sn1 strings. The exploit will still work, but the number of AV scanners detecting it as malicious will drop, as you can see in the following VirusTotal report: https://www.virustotal.com/file/f2b9ed2833963abd1f002261478f03c719e4f73f0f801834bd602652b86121e5/analysis/1422286268/.
It dropped from 24 out of 57 to 18 out of 56. And, naturally, the antivirus that you targeted, Kaspersky, disappeared from this report.
Congratulations, you just bypassed this Kaspersky generic detection in an elegant way.
Evasion Tips and Tricks for Specific File Formats
The number of file formats that can be used to distribute malware, as well as the number of tricks employed by malware, are incredibly large; however, the following sections will cover only some of the most common ones. The focus here is on teaching you how to evade antivirus detection for PE, JavaScript, and PDF files.
PE Files
Windows executable files are also known as PE (portable executable) files. Naturally, executable files are the most preferred formats among malware writers, because they are self-contained and can run without the need to launch another program (as is the case with Microsoft Word files). Executable files need not be the first line of attack, because they can be easily detected. Instead, malware is often distributed in the form of PDF or Microsoft Office files and often via a web browser exploit; however, the final stage of the exploit may end up dropping one or more PE files at some point.
There are innumerable ways of modifying a PE file without actually changing its behavior or corrupting it. Some of the most typical changes (which are also very complex) are listed in the Corkami project's wiki page that talks about the PE file format:https://code.google.com/p/corkami/wiki/PE.
The Corkami project is a repository for some of the craziest ideas that Ange Albertini—a security researcher who loves to play with file formats—has compiled and released to the public. Some of the most basic and useful tricks extracted from this web page are listed here:
· Section names—The name of a section, except in the case of some specific packers and protectors, is meaningless. You can change the name of any section to whatever you want as long as you preserve the field size (a maximum of eight characters). Some antivirus generic detections check the section names to determine whether the names match up with a particular family of malware.
· TimeDateStamp—In some cases, a family of malware shares the same TimeDataStamp (the date when the files were built), and this timestamp can be used by generic AV detections as evidence. Sometimes, the timestamp field alone can also be the entire signature. Naturally, this field is meaningless to the operating system and can be changed to anything you want. It can even be NULL.
· MajorLinkerVersion/MinorLinkerVersion—Although this field is not relevant to the operating system, in general, it can be used in the same way as the TimeDataStamp case; as such, it can be modified without causing the PE file to malfunction.
· Major/Minor OperatingSystemVersion and ImageVersion/MinorImageVersion—This field is exactly the same as for TimeDataStamp and MajorLinkerVersion/MinorLinkerVersion.
· AddressOfEntryPoint—This value is believed to be not NULL. However, it can be NULL, which means, simply, that the entry point of the program will be at offset 0x00, exactly at its IMAGE_DOS_HEADER, which starts with MZ magic bytes.
· Maximum number of sections—In Windows XP, the maximum number of sections in a PE file was 96. In Windows 7, it could be 65,535. Some antivirus engines, for performance reasons, try to determine whether the PE is broken before actually launching most of their generic detections. One check in antivirus engines is that the number of sections expected cannot be greater than 96. This assumption is erroneous for any OS more recent than Windows XP (which is, by the way, no longer a supported OS).
· File length—Although not specific to this file format, PE files are often discarded when they are bigger than some specified size. It is possible to add as much data as you want in the overlay (the end of the PE file) without disrupting the execution of the modified executable file. This is typical, for example, with many heuristic engines (discarding large files can offer a small performance improvement, as most malware files are usually “small”).
A large number of tricks can be used in order to evade detection of PE files, and so it is recommended that you check Ange Albertini's wiki page on the PE file format for more details.
Note
While many of the tricks listed in Albertini's web page can be useful for evading malware detection, it is worth mentioning that these tricks are unusual. This means that once a sample with such characteristics appears, it will be considered suspicious. In order to make a program appear benign to antivirus products, it is recommended that you simply make it look like a goodware file. For example, building programs that look like ordinary Microsoft Visual C++ compiled files without obfuscation, packing, and so on will make them appear less suspicious, which will, in turn, make it less obvious to a researcher that the program is malicious.
JavaScript
Most malware distributed on the web is in the form of JavaScript-based exploits for browser vulnerabilities. A large number of malware infections come from this exact vector: a vulnerability in a web browser such as Internet Explorer or Firefox, exploited via an iframe injection or by tricking a user into browsing to some website that finally drops an executable file, such as a PE. As a result, antivirus engineers expend a lot of time researching how to detect malicious JavaScript. However, JavaScript is a very open language that allows code creation on the fly, as well as the creation of many unusual, though valid, constructs and code patterns that are difficult to read and interpret by humans (but easy to run for a JavaScript interpreter).
For example, can you tell what the following code does?
alert(Number(51966).toString(16));
It shows the message cafe by converting the decimal number 51966 to its hexadecimal representation 0xcafe and returning a string via toString(16). Easy, right? What about the next chunk of JavaScript code:
window[Number(14).toString(16) +
Number(31).toString(36) +
Number(10).toString(16) +
Number(Math.sqrt(441)).toString(35)
](unescape("alert%28%22Hi%22%29"));
This shows the message Hi. Not as simple, but it could be even worse. What does the code shown in Figure 7.5 do?

Figure 7.5 Obfuscated JavaScript code
It simply shows the message Hi in the browser. As you can see, the number of tricks available to obfuscate JavaScript code or to hide the logic, as well as to evade detection, is limited only by your imagination. The following sections list some interesting tricks for JavaScript obfuscation.
String Encoding
String characters can be encoded in many ways. For example, a series of variable concatenations can be used to partially hide the real string being used:
var a = "e"; var x = "v"; var n= "a"; var zz_0 = "l";
real_string = a + x + n + zz_0;
Another example—similar to those in the previous section—involves encoding strings as numbers and then converting them to strings later. Another trick is accomplished by using the escape and unescape functions, as in the following example:
unescape("alert%28%22Hi%22%29");
In this example, the complete string “alert('Hi')” is obfuscated so that it cannot be easily guessed. If you apply various string-encoding methods, humans are unable to read your JavaScript, and de-obfuscation tools are required.
Executing Code on the Fly
Many interpreters allow code creation and execution on the fly. For example, in JavaScript, you can execute code by passing as an argument a string with all the code you want by using functions such as eval. However, there are other functions, such as setTimeout (a function used to set up a timer to execute a code after a number of seconds has passed), addEventListener, or even document.write, which can write HTML and JavaScript code. As with JavaScript, you can mix many tricks together: for example, a string can be executed, after a delay via setTimeout, that writes more obfuscated HTML and JavaScript via document.write and finally executes the true code via eval. You can chain such tricks as many times as you want.
Hiding the Logic: Opaque Predicates and Junk Code
Another typical trick, although not specific to JavaScript, is to use junk code to hide logic and opaque predicates. The predicates, for which the answer is known beforehand by the malware writers, can be difficult to detect without an AV engine that has a sophisticated static analyzer:
var a1 = 10; // Set the predicate earlier in the program
// …
// some more junk code
// …
if ( a1 == 10 )
{
// real code
}
else
{
// junk code
}
This example can be mixed with more tricks to hide the logic, where code could be constructed on the fly with meaningless names for variables and functions, or with names not corresponding to the actions being executed. For example, the object's toString method can be overwritten and then executed indirectly through its parent object, but instead of having toString return some string representation, it executes code via a call to eval. As with JavaScript, you can chain together many tricks, which makes it really difficult for a human to determine what the code is actually doing. When all those obfuscation tricks are used, it becomes problematic to create generic detection routines and signatures based solely on typical evidence-gathering techniques (basic string matching). Antivirus companies are well aware of such malware trends and try to combat them by including a JavaScript interpreter/emulator in their products; however, this solution will still miss many emerging obfuscation tricks.
The Portable Document Format (PDF) is a file format intended to show documents that need to look the same, regardless of the application software and operating system used. It was developed by Adobe around 1991 (and was first called Camelot) and is now used in all major operating systems. As with all old file formats that have been widely adopted, PDF is incredibly complex, the specifications are long and full of errors, and the files are plagued by details and exceptions that are poorly documented, if at all.
The complexity of the PDF file format “standard” makes it very easy to modify such files in order to evade detection. For experimentation purposes, this example uses the file with SHA1 hash 88b6a40a8aa0b8a6d515722d9801f8fb7d332482. If you check its report in VirusTotal (https://www.virustotal.com/file/05d44f5a3fd6ab442f64d6b20e35af77f8720ec47b0ce48f437481cbda7cdbad/analysis/), you will see that it is detected by 25 out of 57 engines.
You will now learn some tricks about the PDF file format in order to try to minimize the number of existing antivirus products that match their signatures against this exploit. As expected, this exploit contains JavaScript code. The objects in the PDF file with JavaScript code are referenced by either the /JS or the/JavaScript tags. The names JS or JavaScript can be encoded in two ways: as ASCII notation and hexadecimal notation. For example, you can change the character "a" with its hexadecimal representation, prefixed with the # character, so it would be /J#61v#61Script instead of /JavaScript. You can do the same with the entire JavaScript string.
As another example, you can replace all occurrences of the string /JavaScript with the new string /#4a#61#76#61#53#63#72#69#70#74, save it, and upload it again to VirusTotal. The new report file for this change is found here: https://www.virustotal.com/ file/2d77e38a3ecf9953876244155273658c03dba5aa56aa17140d8d6ad6160173a0/analysis/.
From the report on VirusTotal, it seems this approach failed because now a new antivirus product, Dr.Web—which was not mentioned in the previous report—has detected it. This happens sometimes: when a trick evades one antivirus product, it can be caught by a new one. Now go back to the original PDF file by reverting the changes, and apply a new trick: object confusion. In a PDF file, an object has the following format:
1 0 obj <</Filter /FlateDecode >>
stream
…data…
endstream
endobj
2 0 obj
…
endobj
This example has object numbers (1 or 2), the revision number (0 in both examples), and a set of filters applied to the object data between the << and the >> characters. What follows is a stream tag indicating that anything following it is the object's data. Both tags are closed with endstream and endobj, and then a new object appears. So, what happens if there are objects with repeated numbers (for example, two objects with the same object number)? The last object is the one that is really used, and the previous ones are ignored. Are antivirus engines aware of this feature of the PDF file format? To find out, create a dummy PDF object with object number 66. You just need to create another fake object with this same number and revision before the true one. You add the following chunk of data before the line 66 0 obj appears:
66 0 obj
<</Filter /AsciiHexDecode /FlateDecode /FlateDecode /FlateDecode
/FlateDecode >>
stream
789cab98f3f68e629e708144fbc3facd9c46865d0e896a139c13b36635382ab7c55930c8
6d57e59ec79c7071c5afb385cdb979ec0a2d13585dc32e79d55c5ef2fef39c0797f7d754d
ad7fd
2c349dd96378cedebee6f7cf17090c4060fdeecfb7a47c53b69ec54fbfcedefe1e28d210
fbfddfc787ffaa447e54ff7af3755b3f2350ccecdde51ab3d87a8e3f76bf37ec7f9b0c52
d55bfd
ebf9bbab55dc3ff6c5d858defc660a143b70ec2e071b9076e8021bbd05c2e906738e2073
4665a82e5333f7fcbcf5db1a5efe2dfaf8a98281e1cff34f47d71baafd67609ceebb1700
153f9a
9d
endstream
endobj
66 0 obj
(…)
Once you have added this fake object (with another trick that will also be covered), you can upload it to VirusTotal to see what happens:https://www.virustotal.com/file/e43f3f060e82af85b99743e68da59ff555dd2d02f2af83ecac84f773b41f3ca7/analysis/1422360906/.
Good! Now, 15 out of 57 engines cannot detect it. This can be either because they did not know that objects could be repeated or because they failed in the other trick that was used here. This other trick is that the stream's data can be compressed and encoded. In this example, the fake object that was added is compressed (/FlateDecode) many times and also encoded as a hexadecimal (/AsciiHexDecode). When this object is decoded and decompressed, it will consume 256MB of RAM. Now if you apply the previous trick (the hexadecimal encoding) again, it may work this time: https://www.virustotal.com/file/e43f3f060e82af85b99743e68da59ff555dd2d02f2af83ecac84f773b41f3ca7/analysis/1422360906/.
The detection rate drops to 14 out of 57. It is worth repeating that a trick that does not work alone may work after some changes and thus manage to bypass one more antivirus.
Now try again by applying the previous trick and adding a new set of repeated objects. The object number 70 points to JavaScript code:
70 0 obj
<<
/JS 67 0 R
/S /JavaScript
>>
endobj
This object points to another object (/JS 67) with the true JavaScript content. Now try to fool an antivirus product by creating a new copy of the object 70 before the true object 70, as you did previously:https://www.virustotal.com/file/b62496e6af449e4bcf834bf3e33fece39f5c04e47fc680f8f67db4af86f807c5/analysis/1422361191/.
Again, the number of detections dropped, this time to 13 out of 57. Now try with a more hard-core trick. Do you remember the objects and streams? The Adobe Acrobat parser does not require either the objects or the streams to be closed. Take the object number 66 that was just added, the fake one, and remove the lines endstream and endobj. Observe again with VirusTotal how the results drop, this time from 13 to 3 detections:https://www.virustotal.com/file/4f431ef4822408888388acbcdd44554bd0273d521f41a9e9ea28d3ba28355a36/analysis/1422363730/.
It was a nice trick! And, what is more important is that the functionality of the embedded exploit did not change at all because you're only targeting how the Adobe PDF parser works. It would be different if you were targeting another PDF reader.
Summary
This chapter discussed some approaches that you can use to bypass signature-based detection in general and for specific file formats. The chapter included many hands-on examples and walkthroughs on how to evade signature detection for PE, JavaScript, and PDF files.
To recap, the following topics were covered:
· Implementing file format parsers is a tedious process. When documentation is not present, hackers rely on reverse-engineering efforts. In both cases, it is impossible to write a bug-free implementation for a complex file format.
· Evading signature-based detection can be done systematically or haphazardly. When done systematically, you have to answer three questions: Where are the virus definition files? What is their file format? How is the signature for a given file encoded in the signature file or files? After those questions are answered, you can see what pattern the AV looks for in order to detect the file you want to avoid being detected. You can then make changes to the files accordingly. Haphazardly evading signatures was covered in the previous chapter. Essentially, you have to keep modifying the malicious file, without changing how it executes, until it is no longer detected.
· AVs detect many file formats. For each file type to be evaded, you need to understand the file format to learn how to make evasion modifications.
· The PE file format has many embedded structures. Various fields in those structures are not very important to the operating system, such as the PE file's TimeDateStamp field. Some antivirus signatures may rely on this field and other fields to identify malware. Therefore, modifying these fields can render a file undetectable.
· JavaScript is used for web-based exploits. Because JavaScript is so versatile, the attackers rely on code obfuscation to hide the exploitation logic and also to evade detection.
· PDF files are a universally adopted document format. They can be rendered seamlessly and independently of the operating system. Under the hood, the PDF file format specification is big and complex. This is a positive point for hackers because they have many ways to hide exploits in PDF files and avoid detection: encoding the embedded JavaScript differently, the use of redundant stream ids, streams compressed and encoded multiple times with different encoders and compressors, and so on.
The next chapter covers how to evade scanners rather than signatures.