Network Security Through Data Analysis: Building Situational Awareness (2014)
Part III. Analytics
Chapter 11. On Fumbling
Up to this point, we have discussed a number of techniques for collecting and analyzing data. We must now marry this with attacker behavior.
Recall from the introduction the distinction between anomaly and signature detection. A focus of this book is on identifying viable mechanisms for detecting and dealing with anomalies, and to find these mechanisms, we must identify general attacker behaviors. Fumbling, which is the topic of this chapter, is the first of several such behaviors.
Fumbling refers to the process of systematically failing to connect to a target using a reference. That reference might be an IP address, a URL, or an email address. What makes fumbling suspicious is that a legitimate user should be given the reference he needs. When you start at a new company, they tell you the name of the email server; you don’t have to guess it.
Attackers don’t have access to that information. They must guess, steal, or scout that data from the system, and they will make mistakes. Often, those mistakes are huge and systematic. Identifying their mistakes and differentiating them from innocent errors is a valuable first step for analysis.
In this chapter, we will look at models of normal user behavior that are violated by attackers. This chapter integrates a variety of results from previous chapters, including material on email, network traffic, and social network analysis.
Attack Models
We need some vocabulary for talking about how attackers behave. There are a number of papers and studies on attack models that try to break the hacking process into a number of discrete steps. These models range from relatively simple linear affairs to extremely detailed attack trees that attempt to catalog each vulnerability and exploit. I’ll start by laying out a simple but flexible model that contains steps common to a majority of attacks.
Reconnaissance
The attacker scouts out the target. Depending on the type of attack, reconnaissance may consist of googling, social engineering (posting on message boards to find and befriend users of a network), or active scanning using nmap or related tools.
Subversion
The attacker launches an exploit against a target and takes control. This may be done via a remote exploit, sending a Trojan file, or even password cracking.
Configuration
The attacker converts the target into a system more suitable for his own use. This may involve disabling antivirus packages, installing additional malware, taking inventory of the system and its capabilities, and/or installing additional defenses to prevent other attackers from taking over the target.
Exploitation
The attacker now uses the host for his own purposes. The nature of exploitation varies based on the attacker’s original reason for being interested in the target (discussed shortly).
Propagation
The attacker will, if possible, use the host to attack other hosts. The host may serve as an expendable proxy, attacking neighbors (for example, other hosts behind a firewall on a 192.168.0.0/16 network).
This model isn’t perfect, but it’s a good general description of how attackers behave without getting bogged down in technical minutiae. There are always common tweaks, for example:
§ Peer-to-peer worm propagation and phishing attacks rely on passive exploits and a bit of social engineering. These attacks rely on a target clicking a link or accessing a file, which requires that the bait (the filename or story surrounding it) be attractive enough to merit a click. At the time of this writing, for example, there’s a spate of phishing attacks using credit ratings as the bait—the earliest informed me that my credit rating had risen and the latest batch is more ominously warning me of the consequences of a recently dropped credit rating. On peer-to-peer networks, attackers will drop Trojans with the names of current games or albums in order to attract victims. Even in this case, “surveillance” is still possible. The phishing attacks done in many APT attacks often depend on scouting out the population and posting habits of a site before identifying victims likely to respond to a crafted mail.
§ Worms often merge the reconnaissance and subversion stages into one step. Some examples of this are shown later in the chapter (notably, in Example 11-1), where an attacker just launches exploits against well-known PHP URLs without checking to see if they actually exist.
YOUR ATTACKER JUST ISN’T THAT INTO YOU: INTERESTED AND UNINTERESTED ATTACKERS
When we think about attackers, we tend to think of technically literate individuals figuring out specific weaknesses on a site in order to grab files or information off of it. This is the classic example of an interested attacker who wants to subvert and control a particular site in order to acquire cash, data, street cred, or who knows what. They make for great stories, but have been, if not a disappearing breed, a progressively minuscule portion of attacks for 10 years or more.
The vast majority of attacks today are conducted by uninterested attackers who want to take over as many hosts as possible and don’t care about the fine details of any particular one. Uninterested attacks are largely automated; they have to be in order to tolerate their inordinately high failure rate. Because of this, the reconnaissance and subversion steps are often merged together. An automated worm may simply launch its attack against every host it encounters, regardless of whether the host is vulnerable.
Uninterested attackers rely on tools and the expectation that someone, somewhere, will be vulnerable. In most cases, they won’t even be aware that a host exists until they take it over. Early examples of uninterested attackers harvested robots for DDoS networks. Botmasters would take over a dozen or so machines, install DDoS software on them, and then launch SYN floods against targets. As connectivity increased, the scope and flexibility of botnets increased as well—attackers started installing software to work as proxies, rob images from attached webcams and sell them to porn sites, install spambots, and carry out a virtually limitless catalog of other abuses.
Uninterested attackers consequently operate more like harvesters than a traditional targeted attacker. A uninterested attacker runs a script, then filters through the results of that script to see what she’s pulled in. A host has a webcam, and it’s located on a college dorm? Porn feed. A host has a lot of disk space and a fat pipe? Fileserver. A host is a home machine? Keylogger.
This harvest-based approach means that attackers often have little to no idea what they’re taking over. In the early days of SCADA exploits, it was apparent that the attackers had no idea what they were looking at, just a Windows host with some weird applications and extra directories. Even now, it’s not uncommon to see medical hardware taken over and used as a botnet.
In recent years, a host’s “configuration” also includes its role: who owns it, what its used for, and what kind of bragging rights can be acquired by bagging it. For example, if two countries share a hostile border, resident hacker rings will deface sites in the opposing country. The Department of Defense runs literally thousands of websites, ranging from intelligence servers to grade schools. It’s not hard to find a vulnerable site and then announce to the world that you’ve “hacked the DoD!” after the fact. Something to keep in mind.
Fumbling: Misconfiguration, Automation, and Scanning
We’ll use the term a fumble to refer generically to any failed attempt by a host to access a resource. A fumble in TCP means that a host wasn’t able to reach a particular host address/port combination, whereas a fumble in HTTP refers to the inability to access a URL. Individual fumbles are expected and are not automatically suspicious. What’s more of a concern is a tendency toward repeated fumbling. Fumbling as an aggregate behavior can happen for several reasons: an error in lookup or configuration, automated software, and scanning.
Lookup Failures
Fumbles usually happen because the destination doesn’t exist in the first place. This can be a transient phenomenon due to misaddressing or movement, or it can be due to someone addressing a resource that never existed.
Keep in mind that people rarely enter addresses by hand. Most users will never directly enter an IP address, instead relying on DNS to moderate their communications. Similarly, apart from a TLD, users rarely enter URLs by hand, instead copying or clicking them from other applications. When someone does enter a faulty address or URL, it usually means that something further up the chain of lookup protocols that got him there failed.
When a target moves, misaddressing is a common phenomenon. In the case of a misaddress, the target does exist, but the source is misinformed about the address. For example, an attacker may enter the wrong name or IP address, or use an earlier IP address after a host moves.
Every site has unused IP addresses and port numbers. For instance, a /24 (class C) address space allows 254 addresses (two more are reserved for special purposes), but the network usually uses only a fraction of them. An unused address or port number is called dark space. Legitimate users rarely try to access dark space, but attackers almost always do. However, knocking on the door of an usused IP address or port is not dangerous in itself, and is so common that tracking it isn’t worthwhile.
Misaddressing is often a common mode failure, meaning that it will not be limited to one or two users, but to a large community. The classic example of a misaddress is somebody sending a messsage to a mailing list, and then mistyping the URL. When this happens, you don’t see one or two errors, and you don’t see individual errors. You see the exact same meaningless string occurring over and over again, coming from dozens if not hundreds of sites. If you see a large number of fumbles, coming from different sites, all identical and all indicating a misspelling, then it’s a good sign that the error has a common cause such as a misconfigured DNS, a faulty redirect on the web server, or an email with the wrong URL.
Automation
People are impatient. Very often, when they can’t actually reach a site, they may retry once, but then they’ll go off and find something better to do with their time. Conversely, automated systems retry connections as a reliability measure, and will often return after a relatively short interval to see if the target is up and running.
On a network traffic feed, this means that a protocol that is human-driven (SSH, HTTP, Telnet) is likely to have a lower failure rate per connection than protocols that are largely automated (SMTP, peer-to-peer communications).
Scanning
Scanning is the most common form of attack traffic observed on the network. If you own a nontrivial chunk of IP space (say a /24 or more), you will literally be scanned thousands of times a day.
Scanning is one of the great sources for bogus security figures. If you classify a scan as an attack, then you can claim to be dealing with thousands of attacks per day. Attacks you’re going to do precisely nothing about, but still thousands. Scanning is easy, fun, and stupid amusement for script kiddies.
Imagine that your network is a two-dimensional grid, where the x-axis shows your IP addresses and the y-axis shows the ports. The grid will then have 65,536 by k cells, where k is the total number of IP addresses. Now, every time a scanner hits a target (an IP/port combination), mark a cell. If you’re interested in all the capabilities of a single host, you may open up a connection to every port it has, resulting in a single vertical line on the grid, a vertical scan. The complement to a vertical scan is a horizontal scan, where the attacker communicates with every host on the network, but only a specific port.
As a rule of thumb, defenders scan vertically and attackers horizontally. The difference is primarily opportunistic—an attacker scans a network horizontally because he is uninterested in the targets outside of the vulnerabilities he can exploit. An attacker who is interested in a specific target may well scan it vertically. Defenders scan vertically because they can’t predict what an attacker will hit.
If an attacker knows something about the structure of a network ahead of time, she may use a hit-list, a list of IP addresses which she knows or suspects may be vulnerable. An example of a common hit-list attack is described by Alata and Dacier: the attacker begins by using a blind scan of a network to identify SSH hosts and then sometime later uses that list to begin password attacks.[19]
Identifying Fumbling
There are two stages to identifying the process of fumbling. The first is determining what, in a protocol, means that a user failed to correctly access a resource. In other words, what does a failed access “look” like? The second stage is determining whether the failure is consistent or transient, global or local.
TCP Fumbling: The State Machine
Identifying failed TCP connections requires some understanding of the TCP state machine and how it works. As we’ve discussed before, TCP imposes the illusion of a stream-based protocol on top of the packet-based IP. This simulation of a stream is produced using the TCP state machine, shown in Figure 11-1.
Under normal circumstances, a TCP session consists of a sequence of handshake packets that set up initial state.
§ On the client side, the transition is from SYN_SENT (client sends an initial SYN packet) to ESTABLISHED (client receives a SYN|ACK packet from server, sends an ACK in response), and then to normal session operations.
§ On the server side, the transition is from LISTEN to SYN_RCVD (receives a SYN, sends a SYN|ACK), and then to ESTABLISHED (receives an ACK).
§ For either side, closure consists of at least two packets (CLOSE_WAIT to LAST_ACK or FIN_WAIT_1 to CLOSING/FIN_WAIT_2 to TIME_WAIT).
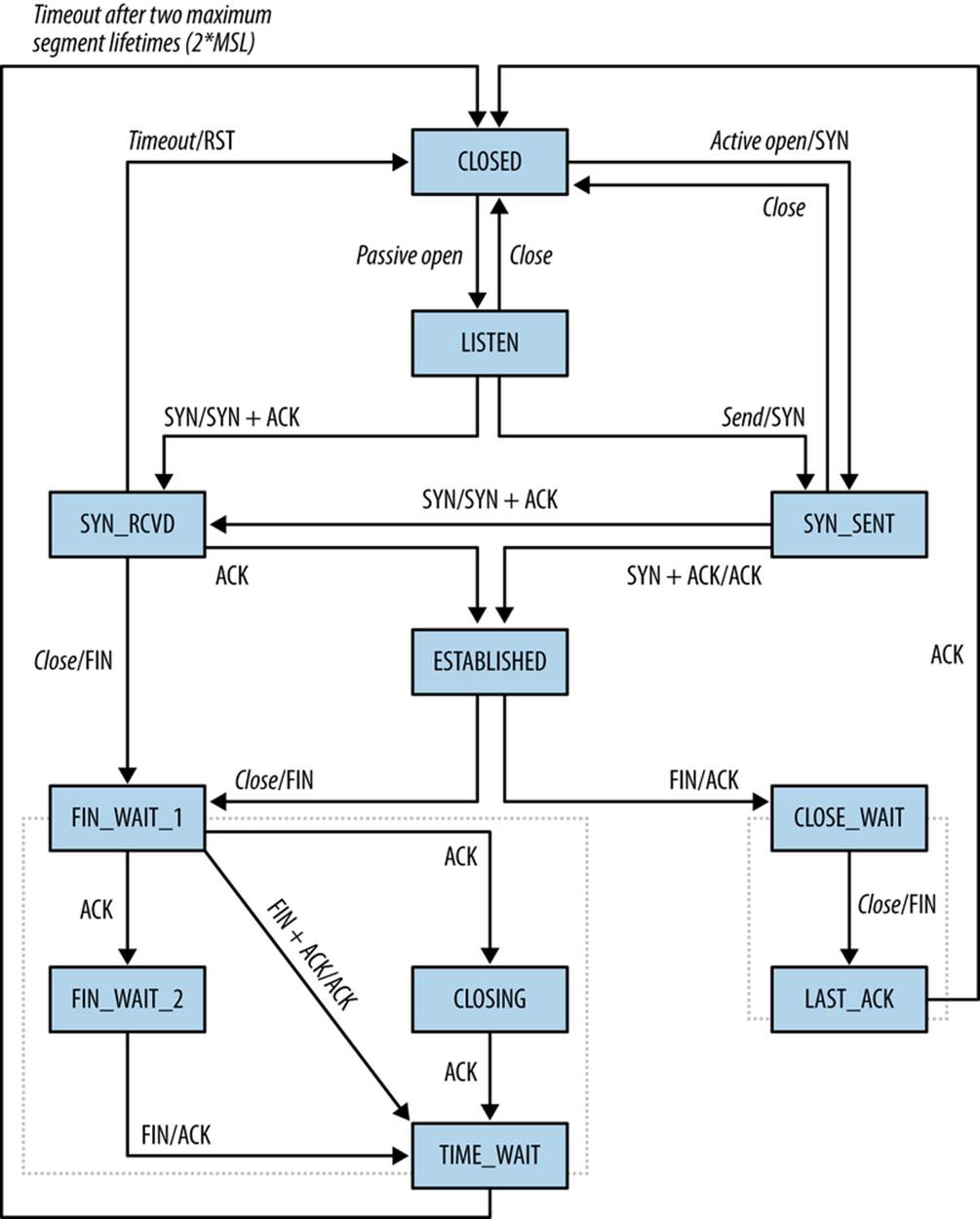
Figure 11-1. The TCP state machine, from texample.net
The net result of these transitions is that a well-behaved TCP/IP session requires at least three packets simply to set up the connection. This is overhead required by TCP, and does not include any communications done by the protocol itself. Throw in a standard MTU of 1,500 bytes, and most legitimate sessions are going to consist of at least several dozen packets.
Automated retry attempts add another layer of complexity to the problem. RFC 1122 establishes basic guidelines for TCP retransmission attempts and recommends a minimum of three retransmissions before giving up on a connection. The actual retry value is usually softcoded and stack-dependent; for example, in Linux systems, the number of retries generally defaults to 3 and is controlled by the tcp_retries1 TCP variable. In Windows systems, the TcpMaxConnectRetransmissions registry value in HKLM\SYSTEM\CurrentControlSet\Services\Tcpip\Parametersgoverns this behavior.
An analyst can identify fumbling by looking at a variety of indicators, depending on the type of data the operator has available and the degree of accuracy necessary. These techniques include relying on a network map, looking for bidirectional traffic, and examining a unidirectional flow for activity. Each technique has strengths and weaknesses, which I’ll discuss.
Network maps
The best tool for identifying fumbling is a current and accurate network map. Network maps can identify a fumble by looking at a single packet, while examining TCP traffic requires looking for replies and reattempts.
That said, a network map is not relying on actual network information—it’s relying on a model of the network that was constructed some time before the event. At the most extreme example, a map of a DHCP network has a limited viable lifetime, but even a statically addressed network will see new services and hosts arrive on a regular basis. When using a network map, make sure to regularly test its integrity using one of the other techniques listed in this section.
Unidirectional flow filtering
If you have access to both sides of a session (i.e., client to server, server to client), identifying complete sessions is simply a matter of joining the two sides together. In the absence of that information, it’s still possible to guess whether packets are part of a whole session.
In my personal experience, I find flows to be more effective than individual packets for detecting fumbling. A fumbler doesn’t interact with a service proper because there is no payload to examine. At the same time, identifying fumbling involves looking for multiple identically addressed packets that occur around the same time, which is the textbook definition of a flow.
Depending on the amount of information needed and the precision required, a number of different heuristics can identify fumbles in TCP flows. The basic techniques involve looking at flags, packet counts, or payload size and packet count.
Flags are a good indicator of fumbling, but using them is complicated by a messy collection of corner cases happily exploited by scanners to differentiate different IP stack implementations. Recall from the Figure 11-1 that a client sends an ACK flag only after receiving an initial SYN + ACK from the server. In the absence of a response, the client should not send an ACK flag; consequently, flows with a SYN and no ACK flag are a good indicator of a fumble. There exists the potential that a response came outside of the timeout of the flow collector, but that’s rare in applied cases.
Attackers craft packets with odd flag combinations in order to determine stack and firewall configurations. The best known of these combinations is the “Christmas tree” packet (so called because all flags are lit up like a Christmas tree), setting SYN ACK FIN PUSH URG RST. Combinations of flags with both SYN and FIN high are common as well. When dealing with long-lived protocols (such as SSH), it’s not uncommon to encounter a packet consisting solely of an ACK. These packets are TCP keep-alive packets and are not fumbling.
Another odd, non-fumbling behavior is backscatter. Backscatter occurs when a host opens a connection to an existing server using a spoofed address, and the server sends the corresponding response to the original spoofed address. Lone SYN, ACK, and RST packets that don’t hit a target are likely to be backscatter.
An easy, if rough, indicator of whether a flow shows a complete session is to simply look at the number of packets. A legitimate TCP session requires at least three packets of overhead before it considers transmitting service data. Furthermore, most stacks set their retry value to between three and five packets. These rules provide a simple filter: TCP flows that have five packets or less are likely to be fumbles.
Flow size can be complemented by looking at the ratio of packet size to number of packets. TCP SYN packets contain a number of TCP options of variable length. During a failed connection, the host will send the same SYN packet options repeatedly. Consequently, if a flow is an n-packet SYN fumble, we can expect that the total number of bytes sent is n×(40 + k), where k is the total size of the options.
ICMP Messages and Fumbling
ICMP is actually designed to inform a user that she has failed to make a connection. ICMP type 3 messages (destination unreachable) are supposed to be sent to a host to indicate that the target network (code 0), host (code 1), or port (code 3) cannot be reached by the client packet. ICMP also provides messages indicating that a route is unknown (code 7) or administratively prohibited (code 13).
With the exception of pings, ICMP messages appear in response to failures in other protocols. Several messages, such as host or net unreachable, originate from some point other than the destination address—generally the nearest router. ICMP messages may also be filtered, depending on the policies of the network in question, and consequently not received by your sensors.
This asymmetry means that when tracking fumbling from ICMP traffic, it is more productive to look for the response. If you see a sudden spike in messages originating from a router, it’s a good bet that the target it’s sending the messages to has been probing that router’s network. You can then look at the host’s traffic to identify what it did communicate with that might be suspicious.
YOU WERE SCANNED, HERE’S YOUR MEDAL
At this point, scanning is so omnipresent, unstoppable, and obnoxious that it has ceased to be an attack and instead has become a form of Internet weather. I can place a reasonable bet that you’re mostly being scanned on TCP ports 80, 443, 22, 25, and 135 without looking at your network.
So, scanning in and of itself is uninteresting, but there is still value in scan detection. Primarily, this is an optimization issue. As discussed in Chapter 4, scanning data can be shunted off during postprocessing in order to reduce the number of records that an analyst encounters in the main data flow. As you monitor larger networks, the problem of scan data becomes increasingly more and more important—a dumb scanner on a /16 will generate 65,535 flows for every port he decides to hit. You may see eight flows for a long lived SSH session, if you see them among all the scanning noise.
Scan removal is best done on an IP-by-IP basis, because if a host is scanning the network, it’s likely not doing anything legitimate. Identify each scanning address and remove all traffic originating from that address. This traffic set can then be trended by identifying the destination ports of the scans, determining the exploits used (if identified by IDS), and comparing the types of scans conducted over time. Top-n lists are generally not particularly useful for scan trending because the top five positions have been fairly static for the past five years.
In operational environments, I generally haven’t been too fussy about exactly identifying flow traffic, instead opting to use the high-pass filter approach to split TCP traffic into short and long files, and then using the long files as the default dataset for queries. In occasions when I really need to access the short files, the data is there, and the probability of a short communication actually being meaningful and all traffic from that host being in the short file is pretty much nonexistent.
Analytically, scan data is often more useful for identifying who responded to a scan rather than who sent it. Attackers are likely to scan your network far more actively and far more often than your own network management staff, meaning that by keeping track of the hosts that responded to scans, you will likely discover new systems and services long before your next audit.
Speculatively, there may be some value in scan trending. SANS, among other organizations, does keep track of current scanning statistics on the Internet storm center. However, if there is value in trending, it has to get past the overwhelming dominance of the top five ports: ports 22, 25, 80, 443, and 139.
Identifying UDP Fumbling
It’s rarely possible to identify a failed UDP connection from the UDP traffic itself. TCP has symmetry baked into the protocol, whereas UDP doesn’t provide any guarantees of delivery. If a UDP service provides some form of symmetry or other reciprocity, that’s a service-specific attribute. In order of preference, network maps and ICMP traffic are the best ways to identify UDP fumbling.
Fumbling at the Service Level
Service-level fumbling commonly results from scanning, automated exploits, and a number of scouting tools. Unlike network-level fumbling, service-level fumbling is usually clearly identifiable as such because there are error codes in most major services that are logged and can be used to differentiate illegitimate connections from legitimate requests.
HTTP Fumbling
Recall that each HTTP transaction returns a three-digit status code, of which the 4xx family of status codes are reserved for client errors. In the 4xx family, the two most important and common access errors are 404 (not found) and 401 (unauthorized).
404 indicates that a resource was not available at the URL specified by the requestor, and is the most common HTTP error in existence. Users will often trigger 404 errors by hand, such as when they mistype a complex URL. Misconfiguration will often cause problems as well, such as when someone publicizes a URL that doesn’t exist.
These types of errors, from a misconfigured URL announcement or fat-fingering, are relatively easy to identify. In the first case, fat-fingering should be relatively rare. Fat-fingered URLs will rarely repeat—if one user is mistyping, he’ll mistype slightly differently each time. At the same time, since fat-fingering is an individual mistake, the same fat-fingering will not appear from multiple locations. If you see the same mistake coming from multiple discrete locations, that is more likely to be a result of a misconfigured URL announcement. Such an announcement may be identifiable by examining the HTTP Referer header. If the Referer points to a site you have control over, then you can identify and fix the error on that site.
The third common source for 404 errors is bots scanning HTTP sites for well-known vulnerabilities. Because most modern HTTP sites are built on top of a collection of other applications, they often carry vulnerabilities from one or more of their component applications. These vulnerabilities are well-known, placed in common locations, and consequently hunted for by bots everywhere. The URLs referenced in Example 11-1 are all associated with phpMyAdmin, a common MySQL database management tool.
Example 11-1. Botnets attempting to fetch common URLs
223.85.245.54 - - [16/Feb/2013:20:10:12 -0500]
"GET /pma/scripts/setup.php HTTP/1.1" 404 390 "-" "ZmEu"
223.85.245.54 - - [16/Feb/2013:20:10:15 -0500]
"GET /MyAdmin/scripts/setup.php HTTP/1.1" 404 394 "-" "ZmEu"
188.230.44.113 - - [17/Feb/2013:16:54:05 -0500]
"GET http://www.scanproxy.net:80/p-80.html HTTP/1.0" 404 378 "-"
194.44.28.21 - - [18/Feb/2013:06:20:07 -0500]
"GET /w00tw00t.at.blackhats.romanian.anti-sec:) HTTP/1.1" 404 410
"-" "ZmEu"
194.44.28.21 - - [18/Feb/2013:06:20:07 -0500]
"GET /phpMyAdmin/scripts/setup.php HTTP/1.1" 404 397 "-" "ZmEu"
194.44.28.21 - - [18/Feb/2013:06:20:08 -0500]
"GET /phpmyadmin/scripts/setup.php HTTP/1.1" 404 397 "-" "ZmEu"
194.44.28.21 - - [18/Feb/2013:06:20:08 -0500]
"GET /pma/scripts/setup.php HTTP/1.1" 404 390 "-" "ZmEu"
194.44.28.21 - - [18/Feb/2013:06:20:09 -0500]
"GET /myadmin/scripts/setup.php HTTP/1.1" 404 394 "-"
Unlike the 404 errors discussed earlier, 404 scanning is generally identifiable by being completely unrelated to the actual structure of a site. Attackers are guessing that something is there and are going by the documentation and common practice to try to reach a vulnerable target.
401 errors are authentication errors, and come from HTTP’s basic access authentication mechanism—which you should never use. 401 authentication was baked into the HTTP standard early on,[20] and uses unencrypted base64-encoded passwords to authenticate a user’s access to protected directories.
Basic access authentication is a disaster and should not be used by any modern web server. If you do see 401 errors in your system logs, you should identify and eliminate the source of them on your server. Unfortunately, basic authentication still occasionally pops up in embedded systems as the only form of authentication available.
WEBCRAWLERS AND ROBOTS.TXT
Search engines employ automated processes called, variously, crawlers, spiders, or robots to scout out websites and identify searchable content. These crawlers can be phenomenally aggressive in copying site contents; website owners can define what the crawlers access using the robot exclusion standard, or robots.txt. The standard defines a common file (the aforementioned robots.txt), which is accessed by the crawler and provides instructions about which files it can and can’t access.
A host that doesn’t access robots.txt and immediately begins poking around the site is suspicious. Furthermore, robots.txt is a voluntary standard; there’s nothing preventing a crawler from ignoring it, and it’s not uncommon for unethical or new crawlers to ignore the instructions.
It’s also not uncommon for scanners who want to probe a site to pretend to be a crawler. Crawlers are usually identifiable by two behaviors: they use a User-Agent string unique to the crawler, and they come from a fixed range of IP addresses.[21] Most search engines publish their address ranges to help stop masquerading; these address ranges can change, so regularly checking a site such as the Robots Database or List of User-Agents is a good idea.
SMTP Fumbling
For our purposes, SMTP fumbling occurs when a host sends mail to a nonexistent address. Depending on SMTP server configurations, this will result in one of three actions: a rejection, a bounce, or (in the case of a catch-all configuration) redirection to a catch-all account. All of these events should be logged by the SMTP server that makes the final routing decision.
Analyzing SMTP fumbles runs into the same problem that analyzing all SMTP traffic does: spam. There are a lot of failed addresses sent in SMTP messages because spammers will send mail to every conceivable address.[22] Consequently, the relatively innocuous reasons for fumbling (misaddressing) may exist but are drowned in spam. At the same time, the reasons for attackers to fumble (reconnaissance) are effectively pointless because spammers don’t probe to see whether an address exists; they spam it.
There may be one good reason to analyze failed SMTP addresses: uncovering deception. In several APT-type spear-phishing emails, I’ve seen the attackers seed the To: line with several realistic but fake looking addresses. I assume that the addresses are either out of date due to enterprise turnover or intentionally added to provide the mail with a veneer of legitimacy.
Analyzing Fumbling
Until some brilliant researcher comes up with a better technique, scan detection will boil down to testing for X events of interest across a Y-sized time window.
— Stephen Northcutt
Fumbling alarms can be used to detect scans, spams, and other phenomena where the attacker has next to no knowledge about the target network.
Building Fumbling Alarms
When tracking fumbles, the goal is to raise an alarm when there’s suspicion that fumbling is not simply accidental. To do so, the alarm must first collect fumbling events using the rules discussed previously in this chapter. These mechanisms include:
1. Creating or consulting a map of targets to determine whether the attacker is reaching a real target.
2. Examining traffic for evidence of a failure to connect. Examples of failures to connect include:
a. Asymmetric TCP sessions, or TCP sessions without ACK flags
b. HTTP 404 records
c. Email bounce logs
Innocuous fumbling, as a false positive, are generally the result of some form of misconfiguration or miscommunication to the target. For example: the DNS name for destination.com is moved from IP address A to IP address B; until the change thoroughly propagates through the DNS system, users will accidentally visit address A instead of B. These types of errors, when they occur, will come from multiple sources and will be consistent. Going back to the destination.com case, address A is no longer used and address C on the same network is dark (that is, it has no domain name); users may accidentally visit A for a while, but they will not visit C. Suspicious fumbling involves users who visit multiple nonexistent destinations; a host may visit A due to a configuration error, he might possibly visit C due to chance, but if he visits A and C, then he’s more likely scouting out a target.
Distinguishing malicious fumbling from innocuous failures is therefore, as Northcutt says, about deciding on a threshold—the number of events tolerated before you raise an alert. There are a number of mechanisms to do this:
1. Calculate an expected value for the number of hosts on the network that a user should contact within a fixed period.
2. An alternative method is to use sequential hypothesis testing, a statistical technique that calculates the likelihood that a phenomenon will pass or fail a particular test multiple times. This approach was pioneered in infosec by Jaeyeoon Jung in her 2004 paper, “Fast Portscan Detection Using Sequential Hypothesis Testing.”[23]
3. Raise an alert whenever a user visits a dark address.
The thing about malicious fumbling is that the attackers, generally, have no particular reason to be subtle. If someone is scanning a site, she’s going to hit everything quickly. Statistical methods are primarily useful to find the attacker quickly, and consequently have more use in active defense rather than in alarm generation.
Forensic Analysis of Fumbling
Scanning qua scanning is basically of no interest. Every idiot on the planet scans the Internet, and a number of them scan it multiple times daily. There is some worm-based scanning (such as with Code Red and SQLSlammer, if you want to get truly Jurassic), which has gone on for yearswithout any noticeable effect. Scanning is like rain: it’s going to happen, and the real question is identifying the damage that it causes.
When receiving a scan alarm, there are several basic questions to ask:
1. Who responded to the scanner? As far as I’m concerned, scanners can visit as much of my dark space as they like. What I’m really concerned about is whether anyone in my network talked back to the scanner, and what they did afterward. More specific questions include:
a. Did the scanner have a serious conversation with any host? Attack software usually rolls scanning and exploit into a two-step process. Consequently, my first question about any scan is whether it ended before the true exploit.
b. Did any responding host have suspicious conversations afterward? Suspicious conversations include communications with external hosts (especially if it’s an internal server), receipt of a file, and communications on odd ports.
2. Did the scanner find out something about my network I didn’t know? Inventories are always at least slightly out of date, and attacks are taking place all the time. Given that, it makes sense to take advantage of the scanner’s hard work for our own benefit.
a. Did the scanner identify previously unknown hosts? This is an example of the previous item about unknown information.
b. Did the scanner identify previously unknown services?
3. What else did the scanner do? Bots usually do multiple things at one time, and it’s good to check whether the scanner scanned other ports, engaged in other types of probes, or tried multiple types of attacks.
There are several good questions to ask about fumblers in general:
1. What else did the fumbler do? If the same address or source is sending mail to multiple targets, it’s likely to be a spammer and, much like a scanner, is using a bot as a utility knife kind of tool.
2. Are there preferred targets? This particularly applies to fumbling with email addresses, because IP addresses are drawn from a much smaller pool. Are there common target addresses on your network? If so, they’re good candidates for further instrumentation.
Engineering a Network to Take Advantage of Fumbling
Fumbling often takes advantage of common network configuration and assumptions. Most obviously, attackers scan common ports like 22 because they expect to encounter services there. You can take advantage of these assumptions to place more sensitive instrumentation on the network, such as full packet capture.
Because malicious scans exploit the regularity of most target sites, you can make the lives of attackers a bit harder by configuring your site in a somewhat irregular way:
Rearrange addresses
Most scanning is linear: the attacker will hit address X, then X+1, and so on. Most administrators and DHCP implementations also assign addresses linearly. It’s not uncommon to have a /24 or /27 where the upper half is entirely dark. Rearranging addresses so that they’re scattered evenly across the network, or leaving large empty gaps in the network is a simple method that creates dark space.
Move targets
Port assignments are largely a social convention, and most modern applications should be able to handle a service located on an unorthodox port. Especially when dealing with internal services, which shouldn’t be accessed by the outside world, port reassignment is a cheap mechanism to frustrate more basic scanners.
Further Reading
1. Jaeyeon Jung, Vern Paxson, Arthur W. Berger, and Hari Balakrishnan, “Fast Portscan Detection Using Sequential Hypothesis Testing,” Proceedings of the 2004 IEEE Symposium on Security and Privacy.
[19] Alata, E. et al., “Lessons learned from the deployment of a high-interaction honeypot,” EDCC 2006.
[20] See RFC 1945 and RFC 2617.
[21] Googlebot is a notable exception to this, and includes instructions on how to verify Googlebot.
[22] I once logged onto an account I had never used and was greeted by 3,000 spam messages.
[23] Jung, Jaeyeon et al. “Fast Portscan Detection Using Sequential Hypothesis Testing.” Paper presented at the IEEE Symposium on Security and Privacy, Oakland, CA, May 2004.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.