Network Security Through Data Analysis: Building Situational Awareness (2014)
Part II. Tools
Chapter 8. Reference and Lookup: Tools for Figuring Out Who Someone Is
Each alert or logfile line that reports an event provides some basic information about the source of the event. Just from the IP address, you can derive information about geographic location and do a reverse DNS lookup. This chapter covers tools that help you track the identity of a host.
This chapter is focused on the idea of “walking up” the OSI stack, mentioned in Network Layering and Its Impact on Instrumentation. I like to view the OSI layer as a sequence of lookup processes. Each layer offers a different piece of addressing information, such as the MAC address at layer 2, the IP address at 3, and the ports at 4. This information is moved between layers through the agency of various referencing systems: Address Resolution Protocol (ARP) maps IP addresses to MAC addresses, DNS maps domain names to IP addresses, and so on. Again, the abstraction isn’t perfect—DNS translation doesn’t move us up or down the OSI stack—but by walking up each layer, we can describe what the addresses mean and when they are relevant to investigation.
The remainder of this chapter is structured as follows: a section on MAC addresses, then IPv4 and IPv6, followed by Internet-layer information, then DNS, then higher-level protocols. Finally comes a discussion of other important tools that don’t fit in the layering model—in particular, reputation databases and malware repositories.
It’s unfortunate that some of our lookup techniques depend on poorly maintained public databases, but they can still be indispensable as long as you understand this limitation.
MAC and Hardware Addresses
Chapter 2 discusses the basics of a Media Access Controller (MAC) address. MAC addresses are defined in the network hardware to provide a locally unique address for hosts within a single layer 2 network. The majority of MAC addresses follow the 48-bit Extended Unique Identifier (EUI) standard: 6 bytes expressed hexadecimally (e.g., 08-21-23-41-FA-BB). More modern network hardware may use EUI-64, which adds an additional 16 bits. When a frame goes from a 48-bit system to a 64-bit system, the 48-bit address is padded to 64 bits.
Figure 8-1 shows how the EUI-48 and EUI-64 break down.
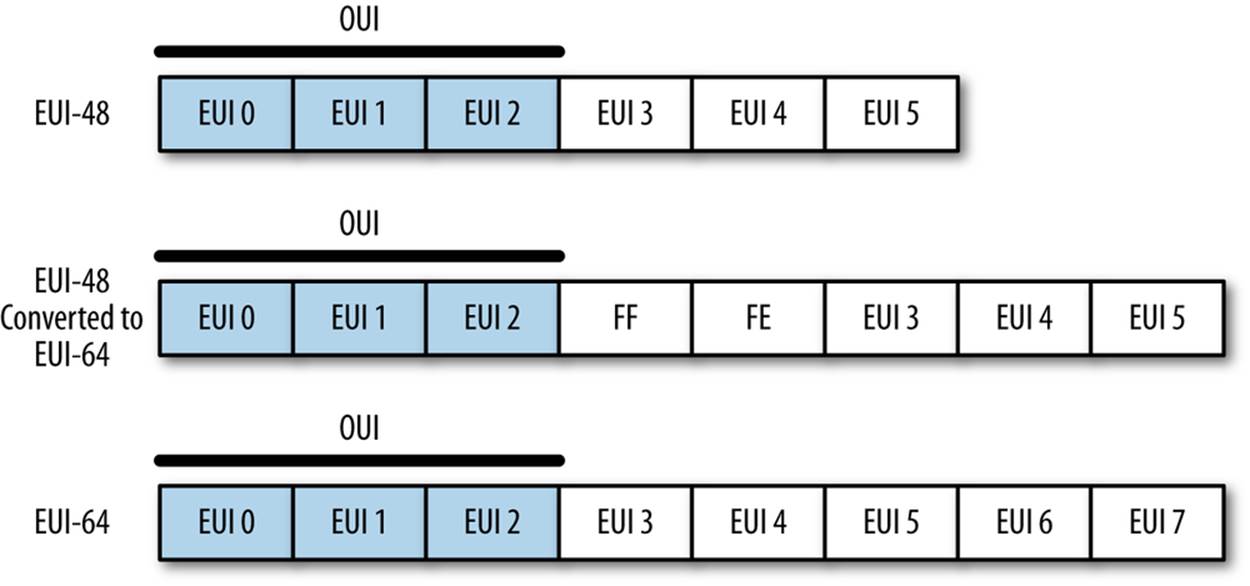
Figure 8-1. The EUI-48 and EUI-64 standards
Note two things in particular. First, if an EUI-48 is converted to an EUI-64, you can tell this by looking at bytes 3 and 4, which will be FFFE. More important is that the first 3 bytes are the Organizationally Unique Identifier (OUI), which is a 24-bit value assigned by the IEEE to the hardware manufacturer. OUI’s are fixed serial numbers, and if you know the OUI, you can find out who manufactured the card. The IEEE maintains a list of OUI assignments, where you can use a search engine to find OUIs by company, or companies by OUI.
For example, consider the following packet from a pcap:
$ tcpdump -c 1 -e -n -r web.pcap
reading from file web.pcap, link-type EN10MB (Ethernet)
00:37:56.480768 8c:2d:aa:46:f9:71 > 00:1f:90:92:70:5a, ethertype IPv4 (0x0800),
length 78: 192.168.1.12.50300 > 157.166.241.11.80: Flags [S],
seq 4157917085, win 65535, options [mss 1460,nop,wscale 4,nop,
nop,TS val 560054289 ecr 0,sackOK,eol], length 0
The communication goes from 8c:2d:aa:46:f9:71 to 00:1f:90:92:70:5a. Looking these up tells us that 8c:2d:aa belongs to Apple, and 00-1f-90 belongs to Actiontec Electronics, who make Verizon’s FIOS routers.
THERE’S LESS WORK THAN YOU THINK
A common analytical stumbling block comes when an analyst tries to build a complicated general solution to a problem when only a limited number of options are present. To use a military example, you don’t have to develop a general solution for identifying aircraft carriers because there are only 20 of them in active service. Instead of working on one big problem, you can solve 20 problems that are considerably smaller and mostly similar.
When dealing with hardware systems and applications, it often helps to stop, step back, and do some market research. The problem often becomes smaller when you find out, for example, that while there are a bunch of systems with embedded web servers, most of them are using Allegro RomPager.
MAC addresses operate entirely within the scope of the local network. To communicate beyond the borders of a router, the host must have an IP address. The relationship between a local MAC and an IP address is managed through the address resolution protocol (ARP). Individual hosts maintain ARP tables that contain mappings between IP addresses and MAC addresses on a network. For example, on my local host, I can query the ARP table using arp -a:
$ arp -a
wireless_broadband_router.home (192.168.1.1) at 0:1f:90:92:70:5a on en1 ifscope
/[ethernet]
new-host-2.home (192.168.1.3) at 0:1e:c2:a6:17:fb on en1 ifscope [ethernet]
new-host.home (192.168.1.4) at cc:8:e0:68:b8:a4 on en1 ifscope [ethernet]
apple-tv-3.home (192.168.1.9) at 7c:d1:c3:26:35:bf on en1 ifscope [ethernet]
? (192.168.1.255) at ff:ff:ff:ff:ff:ff on en1 ifscope [ethernet]
Do the lookups and you’ll find that I really like Apple hardware. Or I prefer to keep my Windows and Linux boxes physically wired.
Analytically, MAC addresses (when you can get them, and you’ll normally have them only for your local network, as already explained) are particularly useful for identifying and differentiating hardware, particularly networking hardware such as routers. IP addresses are considerably more fungible than MAC addresses, and if you need to track a mobile asset like a laptop or anything moderated through DHCP, the MAC address will be your best asset for doing so.
IP Addressing
IP addresses are the most commonly accessed piece of information about a host, and often the only piece of data you will have about a host.
IP is slowly transitioning from IPv4 to IPv6. IPv6 corrects a number of design errors in IPv4, the most notable being IP address exhaustion. An IPv4 address is a 32-bit value, conventionally written in “dotted quad” format: four bytes, written decimally, separated by periods (like 192.168.1.1). At the time of IPv4’s original design, nobody seriously expected that the 4 billion addresses provided would be exhausted, and many of the early allocations of IPv4 addresses are comically generous, as you can see from the master list of /8 allocations. A /8 is a collection of 16 million+ addresses (224) all of which have the same first octet, so 9.0.0.0 to 9.255.255.255 is all owned by IBM, for example. Looking at the list, you’ll see that several of the blocks were assigned large and early to companies such as Xerox and Ford who don’t really use the space they have. The situation has actually improved over the past few years, when several drug companies owned nearly empty /8s and have since returned them to IANA.
The majority of the English-speaking Internet still runs on IPv4, while in Asia and elsewhere, IPv6 is increasingly prevalent. The uneven allocation of IPv4 addresses forces countries who have come to the Internet historically later to build IPv6 infrastructure.
IPv4 Addresses, Their Structure, and Significant Addresses
IPv4 addresses can be expressed using a number of different notations. The most common is the dotted quad format discussed earlier: four integer values between 0 and 255, separated by periods. Addresses can also be referred to directly as a value, usually in hexadecimal. Consequently, the IP address 0xA1010203 is 161.1.2.3 as a dotted quad, and 2701197827 as a decimal integer.
Groups of IP addresses are usually described linearly (e.g., 128.2.11.3–128.2.3.14), or using a Classless Internet Domain Routing (CIDR) block. CIDR blocks, which are discussed in more depth later, are a mechanism for describing the addresses reachable by picking a particular route. Addresses in CIDR notation are represented by a prefix,[11] which is a dotted quad representation of the significant bits of an address, and then a mask, which indicates how many bits make up the prefix.
For example, the CIDR block 128.2.11.0/24 consists of all addresses whose first 24 bits are 128.2.11, so any address from 128.2.11.0 to 128.2.11.255 is in that block.
A number of IP addresses are either reserved or fixed by convention in network configuration. For an individual host on a network, the most important are the broadcast address, gateway, and netmask. IP networks are logically divided into subnets, a collection of contiguous addresses that can all communicate with each other without the need for internal routing. When configuring an IP address, this range is specified using a netmask, which is an IP address with a certain number of its least significant bits zeroed out.
To communicate outside its subnet, a host will have to talk to a router, and does so using a preconfigured gateway address. The gateway address is simply the IP address of the router’s interface to the subnet. Gateway addresses are customarily assigned the lowest value in the subnet, but this is not a requirement.
A network’s broadcast address is set to the subnet mask, but with all the host bits high (e.g., for a network with subnet mask 192.168.1.0, the broadcast address is 192.168.1.255). Messages sent to the broadcast address are sent to every target within the network. The broadcast address is one of a number of addresses you should never see outside of local network traffic. Addresses ending in .255, for lack of a better term, smell funny.
A number of IPv4 addresses are reserved for specific networking functions. These addresses are specifically intended for local use and consequently should not be seen crossing networks. The most significant are:
Local identification addresses
These belong to the 0.0.0.0/8 CIDR block (0.0.0.0–0.255.255.255). Local identification addresses are used during the startup sequence for a host that doesn’t have an IP address yet.
Loopback address
The loopback address of a host is 127.0.0.1. Traffic sent to the loopback address is sent back to the host without entering the network. IANA has reserved the entire 127.0.0.0/8 CIDR block (127.0.0.0–127.255.255.255) for loopback, so as with local identification, nothing from the 127.0.0.0/8 CIDR block should be seen crossing network boundaries.
RFC 1918 netblocks
This document defines a number of netblocks for private use. These addresses can be used within local networks with the intent that they never communicate directly with the global Internet. The RFC netblocks are 10.0.0.0/8, 192.168.0.0/16 and 172.16.0.0/12. Addresses within these blocks are often assigned automatically by local routing tools or DHCP.
Multicast addresses
Multicast addresses are used to classify specific groups of hosts within a subnet. For example, multicast address 224.0.0.2 is the “all routers” multicast address, and all routers within the subnet will receive traffic sent there. Multicast traffic is primarily the focus of routing and other Internet control protocols.
IPv6 Addresses, Their Structure and Significant Addresses
One of the most significant changes between IPv4 and IPv6 is the number of addresses they make available. IPv6 assigns 128 bits to each address; this ensures plenty of addresses, but introduces some problems in notation.
The default format for an address is eight 16-bit hexadecimal values separated by colons, such as 2001:0010:AF3A:FB31:09A8:08A1:1098:1101. Given that this is a long and clumsy representation, addresses are usually represented using a number of shorthand conventions. When writing IPv6 addresses, apply these rules:
§ Leading zeroes in any group are omitted, so 01AA:0002 can be written as 1AA:2.
§ Consecutive groups of zero may be replaced with a pair of colons, so 2001:0:0:0:0:0:0:1 is written as 2001::1. The double-colon reduction can be used only once, so 2001:0:0:0:11:0:0:1 is written as 2001::11:0:0:1.
THE RIRS AND IP ADDRESS ALLOCATION
Researching an IP address often means tracing the chain of ownership from IANA to a specific organization. The process of reservation is hierarchical; at the top level, IP address allocation is controlled by the Internet Assigned Numbers Authority (IANA). IANA is a department of the Internet Corporation for Assigned Names and Numbers (ICANN), the US-based nonprofit in charge of managing IP address and DNS name assignment.
IANA delegates the control of blocks of numbers to the Regional Internet Registries (RIRs), continental organizations that manage the allocation of IP addresses and Autonomous System numbers within their continent. RIRs are the intermediary between IANA and the various national and TLD registrars that actually deal with the allocation of addresses (see Table 8-1).
Table 8-1. The RIRs
|
RIR |
Domain |
URL |
|
ARIN |
US and Canada |
www.arin.net |
|
LACNIC |
Central and South America, the Caribbean |
lacnic.net |
|
RIPE |
Europe, Russia, and the Middle East |
www.ripe.net |
|
APNIC |
Asia and Oceana |
www.apnic.net |
|
AfriNIC |
Africa |
www.afrinic.net |
IANA delegates address blocks to the RIRs, and the RIRs in turn allocate sections of those blocks to organizations within their domains. RIRs then allocate address blocks to their members, and those members can allocate subblocks or addresses as they see fit.
This allocation process means that every IP address has a chain of ownership. That ownership begins with IANA, is allocated to one of the RIRs, and then down through one or more ISPs until it reaches whatever party is currently using the address. Beyond the final ISP (generally, below a /24 or a /27), address ownership is more fungible—it’s rare to be able to associate a specific address with a specific person unless that’s a matter of public record via whois, or the ISP is willing to give up that information.
As with IPv4, multiple IPv6 blocks are reserved for specific functions. The most important reservation at this point is 2000::/3 (as with IPv4, CIDR block notation can be used with IPv6 addresses, and the mask can extend up to 128 bits). IPv6 space is huge, and to help keep routes reasonably close together, all routable traffic in IPv6 should be in the 2000::/3 block. Further divisions within the 2000::/3 block are maintained by IANA as it does with the /8 registry for IPv4. The master reference is available on the IPv6 Global Unicast Address Assignments page.
Additional address blocks of note include the ::/128 and ::1/128 blocks, which are the unspecified and loopback address (the equivalent of 0.0.0.0, and 127.0.0.0 for IPv4).
Of particular interest are the utility address blocks 2001:758::/29 and 2001:678::/29. 2001:758:/29 is specifically assigned to Internet Exchange Points (IXPs); an IXP is a physical location where multiple ISPs interconnect with each other. 2001:678::/29 represents a block of provider-independent addresses; users can contact their RIRs directly for these addresses.
For clarity, a summary of local and unroutable addresses is provided in Table 8-2.
Table 8-2. Notable addresses
|
IPv4 block |
IPv6 block |
Description |
|
0.0.0.0/0 |
::/0 |
Default route; addresses from this block shouldn’t be seen |
|
0.0.0.0/32 |
::/128 |
Unspecified address |
|
127.0.0.1/8 |
::1/128 |
Loopback |
|
192.168.16.0/24 |
fc00::/7 |
Reserved for local traffic |
|
10.0.0.0/8 |
fc00::/7 |
Reserved for local traffic |
|
172.16.0.0/12 |
fc00::/7 |
Reserved for local traffic |
|
224.0.0.0/4 |
ff00::/8 |
Multicast addresses |
Checking Connectivity: Using ping to Connect to an Address
The most basic command-line tool for checking connectivity is ping. ping works by using ICMP (see Packet and Frame Formats) messages. ping sends an ICMP echo request (type 8, code 0) to the target. On receiving an echo request message, the target should respond with an echo reply (type 0, code 0). Example 8-1 shows the output of ping and a pcap of the contents.
Example 8-1. ping output
$ ping -c 1 nytimes.com
PING nytimes.com (170.149.168.130): 56 data bytes
64 bytes from 170.149.168.130: icmp_seq=0 ttl=252 time=29.388 ms
$ tcpdump -Xnr ping.pcap
reading from file ping.pcap, link-type EN10MB (Ethernet)
20:38:09.074960 IP 192.168.1.12 > 170.149.168.130:
ICMP echo request, id 44854, seq 0, length 64
0x0000: 4500 0054 0942 0000 4001 5c9b c0a8 010c E..T.B..@.\.....
0x0010: aa95 a882 0800 0fb8 af36 0000 5175 d7f1 .........6..Qu..
0x0020: 0001 24a6 0809 0a0b 0c0d 0e0f 1011 1213 ..$.............
0x0030: 1415 1617 1819 1a1b 1c1d 1e1f 2021 2223 .............!"#
0x0040: 2425 2627 2829 2a2b 2c2d 2e2f 3031 3233 $%&'()*+,-./0123
0x0050: 3435 3637 4567
20:38:09.104250 IP 170.149.168.130 > 192.168.1.12:
ICMP echo reply, id 44854, seq 0, length 64
0x0000: 4500 0054 0942 0000 fc01 a09a aa95 a882 E..T.B..........
0x0010: c0a8 010c 0000 17b8 af36 0000 5175 d7f1 .........6..Qu..
0x0020: 0001 24a6 0809 0a0b 0c0d 0e0f 1011 1213 ..$.............
0x0030: 1415 1617 1819 1a1b 1c1d 1e1f 2021 2223 .............!"#
0x0040: 2425 2627 2829 2a2b 2c2d 2e2f 3031 3233 $%&'()*+,-./0123
0x0050: 3435 3637 4567
Note first the size of the packet and the ttl value. These values are usually set by default by the TCP stack. In the case of Mac OS X, the ICMP packet has a 56-byte payload, which results in an 84-byte packet (20 bytes of IP header, 8 bytes of ICMP header, and 56 bytes payload). The type and code are at 0x0014-0x0015 (08 for the request, 00 for the response). After the ICMP header, note that the contents of the packet are echoed. ICMP has a concept of a session, and in many cases, messages are sent in response to packets from entirely different protocols. Different ICMP messages use different techniques to indicate their point of origin; in the case of ping, this is done by echoing the packet’s original contents.
ping is a simple application: it sends an echo request with an embedded sequence identifier. The application then waits until a specified timeout (usually on the order of 4,000 ms); if the response is received in that time, the response is printed and the next packet is sent. ping is a diagnostic tool, and any serious implementation will provide a number of command line switches for manipulating packet composition.
SWEEPING PINGS AND PING SWEEPING
These are actually different terms, although Google gets confused when you enter a search for them. A ping sweep (or ping sweeping) is a scanning technique that systematically pings all the IP addresses assigned to a network to determine which ones are present and which ones are not. Ping sweeping is supported by nmap and a number of other scanning tools, although you can write a script to do it in about 20 seconds.
A sweeping ping, in contrast, is a sequence of ping messages that undergo size increases with each packet. Sweeping pings are intended to diagnose channels by identifying traffic manipulation or MTU issues. Sweeping pings are enabled by a command-line option on most modern ping implementations.
It’s not uncommon to find networks blocking ICMP messages. Ping sweeping is consequently a middling tool for finding hosts on a network; direct TCP or UDP scanning will generally be more effective.
Tracerouting
traceroute is a tool and technique to identify the routers that forward packets from point A to point B. traceroute produces a sequential list of routers by manipulating packet TTLs.
The TTL (time to live) field of an IP packet is a mechanism developed to prevent packets from bouncing through the Internet forever. Every time a packet is forwarded by a router, its TTL value decreases by one. When the TTL reaches zero, the forwarding router drops the packet and sends an ICMP time exceeded (type 11) message.
$traceroute www.nytimes.com
traceroute to www.nytimes.com (170.149.168.130), 64 hops max, 52 byte packets
1 wireless_broadband_router (192.168.1.1) 1.189 ms 0.544 ms 0.802 ms
2 l100.washdc-vfttp-47.verizon-gni.net (96.255.98.1) 2.157 ms 1.401 ms
1.451 ms
3 g0-13-2-7.washdc-lcr-22.verizon-gni.net (130.81.59.154) 3.768 ms 3.751 ms
3.985 ms
4 ae5-0.res-bb-rtr1.verizon-gni.net (130.81.209.222) 2.029 ms 2.314 ms
2.314 ms
5 0.xe-3-1-1.br1.iad8.alter.net (152.63.37.141) 2.731 ms 2.759 ms 2.781 ms
6 xe-2-1-0.er2.iad10.us.above.net (64.125.13.173) 3.313 ms 3.706 ms 3.970 ms
7 xe-4-1-0.cr2.dca2.us.above.net (64.125.29.214) 3.741 ms 3.668 ms
xe-3-0-0.cr2.dca2.us.above.net (64.125.26.241) 4.638 ms
8 xe-1-0-0.cr1.dca2.us.above.net (64.125.28.249) 3.677 ms
xe-7-2-0.cr1.dca2.us.above.net (64.125.26.41) 3.744 ms
xe-1-0-0.cr1.dca2.us.above.net (64.125.28.249) 4.496 ms
9 xe-3-2-0.cr1.lga5.us.above.net (64.125.26.102) 24.637 ms
xe-2-2-0.cr1.lga5.us.above.net (64.125.26.98) 10.293 ms 9.679 ms
10 xe-2-2-0.mpr1.ewr1.us.above.net (64.125.27.133) 20.660 ms 10.043 ms
10.004 ms
11 xe-0-0-0.mpr1.ewr4.us.above.net (64.125.25.246) 15.881 ms 16.848 ms
16.070 ms
12 64.125.173.70.t01646-03.above.net (64.125.173.70) 30.177 ms 29.339 ms
31.793 ms
As the next code block shows, traceroute sends an initial 52-byte message, and then proceeds to receive sequential information about each address it contacts en route to 170.149.168.130. Let’s look at the payload in more depth.
$ tcpdump -nXr traceroute.pcap | more
21:06:51.202439 IP 192.168.1.12.46950 > 170.149.168.130.33435: UDP, length 24
0x0000: 4500 0034 b767 0000 0111 ed85 c0a8 010c E..4.g..........
0x0010: aa95 a882 b766 829b 0020 b0df 0000 0000 .....f..........
0x0020: 0000 0000 0000 0000 0000 0000 0000 0000 ................
0x0030: 0000 0000 ....
21:06:51.203481 IP 192.168.1.1 > 192.168.1.12: ICMP time exceeded in-transit,
length 60
0x0000: 45c0 0050 a201 0000 4001 548e c0a8 0101 E..P....@.T.....
0x0010: c0a8 010c 0b00 09fe 0000 0000 4500 0034 ............E..4
0x0020: b767 0000 0111 ed85 c0a8 010c aa95 a882 .g..............
0x0030: b766 829b 0020 b0df 0000 0000 0000 0000 .f..............
0x0040: 0000 0000 0000 0000 0000 0000 0000 0000 ................
21:06:51.203691 IP 192.168.1.12.46950 > 170.149.168.130.33436: UDP, length 24
0x0000: 4500 0034 b768 0000 0111 ed84 c0a8 010c E..4.h..........
0x0010: aa95 a882 b766 829c 0020 b0de 0000 0000 .....f..........
0x0020: 0000 0000 0000 0000 0000 0000 0000 0000 ................
0x0030: 0000 0000 ....
21:06:51.204191 IP 192.168.1.1 > 192.168.1.12: ICMP time exceeded in-transit,
length 60
0x0000: 45c0 0050 a202 0000 4001 548d c0a8 0101 E..P....@.T.....
0x0010: c0a8 010c 0b00 09fe 0000 0000 4500 0034 ............E..4
0x0020: b768 0000 0111 ed84 c0a8 010c aa95 a882 .h..............
0x0030: b766 829c 0020 b0de 0000 0000 0000 0000 .f..............
0x0040: 0000 0000 0000 0000 0000 0000 0000 0000 ................
Note that traceroute sends out UDP messages, starting at port 33435 and incrementing the port number by one with each additional message. The port number is incremented in order to reconstruct the order in which the packets are sent. Note that the ICMP packet from offset 0x001C onward contains the original UDP packet. As noted above, ICMP messages need to use a number of different techniques to provide context—error messages such as TTL exceeded include the IP header and the first 8 bytes of the original packet. This includes the UDP source port number. tracerouteorders the ICMP messages in order of this port number in order to determine the order in which those messages were sent.
While traceroute uses UDP by default, the same technique can be used by TCP or any other protocol where there is a controllable value (such as ephemeral port number) in the first 8 bytes of the IP payload.
ping and traceroute are more useful if you can use them from different locations. To that end, a number of Internet service providers and other organizations provide looking glass servers. A looking glass server is a publicly accessible (generally via the Web) interface to any of a number of common Internet applications. Most looking glasses are managed by NOCs or ISPs, and provide access to multiple routers. There is no standard for implementation, and different looking glasses will provide different services. A comprehesive list is available at www.traceroute.org.
IP Intelligence: Geolocation and Demographics
A number of database and intelligence services provide further information about an IP address. This type of augmentation data includes ownership, geolocation, and demographic information.
It’s important to distinguish this augmentation data from information such as autonomous system, domain name, and whois data. The latter is necessary for the upkeep of the network, and is maintained by Internet organizations related to ICANN. Geolocation, demographic data, and ownership are intelligence products. The companies that produce them use a variety of mechanisms including network scanning as well as shoe-leather investigation to produce it. This leads to several important qualities:
§ The intelligence updates slowly, whereas DNS names can change very rapidly. It takes additional checking to find out that 128.2.11.214 is no longer involved in selling car parts and is now hosting malware.
§ There is always some degree of approximation. As a rule of thumb, intelligence data gets less accurate as you delve down into finer detail. Country information is usually good, but I’m moderately skeptical about city information outside of the US and western Europe, and I never trust physical location.
§ You get what you pay for. The companies that produce this data have customers who need it. Most of the companies started out providing demographic data for large websites, and it’s still common to find limits on the number of queries you can conduct per license. You pay for accuracy and you pay for precision. There are free intelligence databases, but if you want to get finer detail than country codes, prepare to crack open your wallet.
The most commonly used open source reference is MaxMind’s GeoIP, which provides a number of databases for city, country, region, organization, ISP, and network speed. They also provide free services in the form of “lite” databases for finding city and country. All of their products are downloadable databases and are updated regularly. MaxMind has been providing this service for years, along with a number of APIs in Python and other scripting languages that are available to access the database.
For more extensive information, options include Neustar and Digital Envoy’s Digital Element. Both provide more precise measurement, as well as additional demographic data such as Metropolitan Statistical Area (MSA) (contiguous areas of high population density used by the government for statistical analysis) and North American Industry Classification System (NAICS) codes (a numerical identifier akin to a Dewey Decimal number for business type). These services are not cheap, however.
DNS
In a just world, each IP address would have a single DNS name, and finding the DNS name associated with an IP address would be a simple matter of consulting a database. This world is not just.
DNS is the glue that makes the Internet usable by human beings. As one of the older services making the Internet work, DNS overlaps a couple of other services (particularly mail). DNS is, at this point, a distributed database that provides lookup information for a number of different relationships, in particular DNS name to IP address, DNS name to DNS name, email address to mail server, and so on.
DNS Name Structure
A domain name consists of a hierarchical sequence of labels separated by periods, such as www.oreilly.com. Domain names become more general as you read from right to left, ending at the root domain (the root domain is ., but it’s almost always implicit). Domain names do have limits. The total length of a name cannot exceed 253 characters, and individual labels are limited to 64.
Historically, labels were limited to a restricted subset of ASCII characters for the name. Since 2009, it has been possible to acquire internationalized domain names, which are encoded using character systems such as Chinese, Greek, and so on.[12] The mechanical limits of 253 characters per name still hold, though the encoding is more complex.
NICS AND DOMAIN NAME ALLOCATION
The authority to allocate domain names, as with IP addresses, begins with ICANN. ICANN controls the root zone and defines the top-level domains (TLDs) that lie just below the root of the tree. As with addresses, each TLD has a managing authority referred to as a network information center (NIC). Each NIC establishes different policies for name allocation—for example, anyone can get a .com address, but only accredited educational institutions qualify for a .edu address. Depending on NIC policy, registration authority may be further delegated to one or more registrars.
IANA defines four categories of TLD. The oldest category is the generic TLDs (gTLD); these are country-agnostic top-level domains such as .com or .edu. Following gTLDs is the one-domain infrastructural TLD, which contains the .arpa domain used for reverse DNS lookups. A country code TLD (ccTLD) is a two-letter top-level domain for a countries (e.g., .ie for Ireland). A new set of internationalized TLDs (IDN ccTLD) allow non-Latin characters.
Each TLD has its own NIC. Table 8-3 below shows the NICs for a number of commonly consulted TLDs.
Table 8-3. Notable NICs
|
TLD |
NIC |
URL |
|
.org |
Public Interest Registry |
www.pir.org |
|
.biz |
Neustar |
www.neustar.biz/enterprise/domain-name-registry |
|
.com |
VeriSign |
www.verisigninc.com/ |
|
.net |
VeriSign |
www.verisigninc.com/ |
|
.edu |
Educause |
www.educause.ed |
|
.int |
IANA |
www.iana.org/domains/int |
|
.fr |
AFNIC |
www.afnic.fr/ |
|
.uk |
Nominet |
www.nominet.org.uk |
|
.ru |
Coordination Center for TLD RU |
www.cctld.ru/en/ |
|
.cn |
CNNIC |
www1.cnnic.cn/ |
|
.kr |
KISA |
www.kisa.or.kr/ |
This hierarchy of nameservers also serves to determine which servers are authoritative. Top-level registries assign authority to subregistries by granting them zones. Each zone has one master server that maintains its domain names and is authoritative when queried, but zones can be nested in order to give different servers authority.
Forward DNS Querying Using dig
The basic DNS query tool is domain information groper (dig), a command-line DNS client that enables you to query DNS for all of the major records. Begin by conducting a simple dig query:
$ dig oreilly.com
dig oreilly.com
; <<>> DiG 9.8.3-P1 <<>> oreilly.com
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 29081
;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 0
;; QUESTION SECTION:
;oreilly.com. IN A
;; ANSWER SECTION:
oreilly.com. 383 IN A 208.201.239.101
oreilly.com. 383 IN A 208.201.239.100
;; Query time: 10 msec
;; SERVER: 192.168.1.1#53(192.168.1.1)
;; WHEN: Sat Jul 20 19:11:17 2013
;; MSG SIZE rcvd: 61
$ dig +short oreilly.com
208.201.239.101
208.201.239.100
We will consider dig’s display options, and then the structure of the DNS response. As seen in the previous example, the basic dig command provides extensive information about the query, beginning with a list of options invoked, then a DNS header, and then several sections corresponding to the query. Note the QUERY, ANSWER, AUTHORITY, and ADDITIONAL fields in the header line, and how those correspond to the lines in the corresponding sections. Because this domain returned no AUTHORITY or ADDITIONAL records, none are shown in the output. The query is followed by a set of statistics about the query: the server, the time it took, and the size of the message.
dig provides an enormous number of output options; the previous example showed the default display. Individual sections of that display can be turned off using +nocomments (which kills all the comments beginning with a double semicolon), +nostats (killing the statistics at the end), and +noquestion and +noanswer (to eliminate the DNS responses). +short will simply remove all the cruft and show the responses.
dig is simply a DNS client, so the majority of information seen is from the DNS server itself. dig enables queries to different servers by using @ in the command line. For example:
$ # 8.8.8.8 is Google's public DNS server; let's query a CDN using it
$ dig @8.8.8.8 www.foxnews.com
; <<>> DiG 9.8.3-P1 <<>> @8.8.8.8 www.foxnews.com
; (1 server found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 18702
;; flags: qr rd ra; QUERY: 1, ANSWER: 4, AUTHORITY: 0, ADDITIONAL: 0
;; QUESTION SECTION:
;www.foxnews.com. IN A
;; ANSWER SECTION:
www.foxnews.com. 282 IN CNAME www.foxnews.com.edgesuite.net.
www.foxnews.com.edgesuite.net. 21582 IN CNAME a20.g.akamai.net.
a20.g.akamai.net. 2 IN A 204.245.190.42
a20.g.akamai.net. 2 IN A 204.245.190.8
;; Query time: 141 msec
;; SERVER: 8.8.8.8#53(8.8.8.8)
;; WHEN: Sat Jul 20 19:48:01 2013
;; MSG SIZE rcvd: 135
$ # Query using my default server
$ dig www.foxnews.com
; <<>> DiG 9.8.3-P1 <<>> www.foxnews.com
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 47098
;; flags: qr rd ra; QUERY: 1, ANSWER: 4, AUTHORITY: 0, ADDITIONAL: 0
;; QUESTION SECTION:
;www.foxnews.com. IN A
;; ANSWER SECTION:
www.foxnews.com. 189 IN CNAME www.foxnews.com.edgesuite.net.
www.foxnews.com.edgesuite.net. 9699 IN CNAME a20.g.akamai.net.
a20.g.akamai.net. 9 IN A 23.66.230.160
a20.g.akamai.net. 9 IN A 23.66.230.106
;; Query time: 97 msec
;; SERVER: 192.168.1.1#53(192.168.1.1)
;; WHEN: Sat Jul 20 19:48:09 2013
;; MSG SIZE rcvd: 135
As you can see, querying a CDN-moderated site (Fox News uses Akamai) results in radically different IP addresses for the same name. CDNs manipulate the DNS to ensure that caches of published data are geographically close to their target. If you don’t specify the server using @, dig will default to whatever server the system is configured to use (for example, in Unix systems this is maintained in /etc/resolv.conf).
A CDN is a caching network that makes the Internet viable. Before the Web, a user might visit four to five hosts in an hour; after the Web, a request to a web page might launch a hundred different HTTP requests. The majority of these requests are redirected via DNS to caching servers that are located geographically nearby.
CDNs add an annoying wrinkle to web analysis, because a single CDN server may host multiple websites. Once an address is identified as a CDN, figuring out exactly what it is tends to be prohibitively difficult.
Now, let’s look at the DNS data. DNS is a federated database system. So queries go first to a local DNS server, which sends a response if it possesses the answer to the query. If the server doesn’t have the information, it uses the hierarchical structure of the name to figure out where to send the request, waits for a response, and sends the response back. DNS supports a number of different queries, termed resource records (RRs), and the options sent during the query specify the resource record requested as well as options for querying additional servers. The values with As orCNAMES in the lines above are resource records.
Note that the header lists eight fields:
opcode
This field was intended to specify a number of different actions, such as queries, inverse queries, and server status. In practice, it should always be set to query. A number of other opcodes exist, but they are used to communicate information between servers.
status
The status of the response. Three messages appear most often: NOERROR, NXDOMAIN, and SERVFAIL. NOERROR indicates that the query was successful, NXDOMAIN indicates that no domain was available, and SERVFAIL indicates that authoritative servers for the domain were unreachable.
id
The message ID. DNS is a UDP-moderated protocol and uses message IDs to track queries and responses.
flags
These provide information on the response, and include qr (set high for a response), aa (set high when the answer is from an authoritative server), ra (recursion desired), and rd (recursion available).
The remaining four fields refer to the categories of records sent in response. These four are:
QUERY
This record is simply a copy of the original request; you can see in this case that the query is echoed in what dig refers to as the QUESTION section.
ANSWER
Contains the response.
AUTHORITY
Reserved for records that identify other servers.
ADDITIONAL
Provides additional information, such as the expected responses to future queries.
Additional information is very much a function of the nameserver’s administrators. A common example of its use follows, where the information provides a name lookup for the mail server identified by an MX query:
$ dig +nostats +nocmd mx cmu.edu
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 30852
;; flags: qr rd ra; QUERY: 1, ANSWER: 4, AUTHORITY: 0, ADDITIONAL: 3
;; QUESTION SECTION:
;cmu.edu. IN MX
;; ANSWER SECTION:
cmu.edu. 20051 IN MX 10 CMU-MX-02.ANDREW.cmu.edu.
cmu.edu. 20051 IN MX 10 CMU-MX-03.ANDREW.cmu.edu.
cmu.edu. 20051 IN MX 10 CMU-MX-04.ANDREW.cmu.edu.
cmu.edu. 20051 IN MX 10 CMU-MX-01.ANDREW.cmu.edu.
;; ADDITIONAL SECTION:
CMU-MX-03.ANDREW.cmu.edu. 20412 IN A 128.2.155.68
CMU-MX-01.ANDREW.cmu.edu. 20232 IN A 128.2.11.59
CMU-MX-02.ANDREW.cmu.edu. 20051 IN A 128.2.11.60
Now, let’s discuss what those resource records actually mean. DNS has upward of 20 resource records for different functions. The major ones are:
A
An answer record, providing the IP address associated with a particular name.
AAAA
Like A, but provides an IPv6 address for a name.
CNAME
Relates two names, a canonical name and an alias.
MX
Returns the mailserver for a domain.
PTR
Points to a canonical name; mostly used for DNS reverse lookups.
TXT
Contains arbitrary text data.
NS
Describes the nameserver for an address.
SOA
Provides information about the authoritative nameserver for an address.
dig starts all resource records with the same four values: a name, a time to live (TTL), a class, and an identifier for the RR (for example: cmu.edu, 20051, IN, MX). The name is passed with the query. The TTL indicates for how long (in seconds) the value of the name can be trusted; DNS relies heavily on caching and the TTL provides instructions on when to refresh the cache. The class will almost invariably be IN (Internet); other class names are possible, but outside the scope of this book.
A and AAAA provide basic DNS functionality: they associate the queried name with an IP address. A records provide IPv4 addresses, and AAAA records provide IPv6 addresses. By default, dig queries for A records, while other record types are specified by adding them to the command line, seen here:
$ dig +nocomment +noquestion +nostats +nocmd www.google.com
www.google.com. 55 IN A 74.125.228.81
www.google.com. 55 IN A 74.125.228.83
www.google.com. 55 IN A 74.125.228.84
www.google.com. 55 IN A 74.125.228.80
www.google.com. 55 IN A 74.125.228.82
$ dig +nocomment +noquestion +nostats +nocmd aaaa www.google.com
www.google.com. 18 IN AAAA 2607:f8b0:4004:802::1014
Note that the query to Google responds with five A records. This is an example of round robin DNS allocation, a common load balancing technique. In round robin allocation, the same domain name is assigned to multiple IP addresses. Consequently, when a query chooses an IP address to contact for the name, it effectively picks the name randomly from the set of targets. Round robin DNS allocation is one of many DNS hacks that makes reverse lookups (IP addresses from names) incredibly annoying.
Note also the short TTL values. If a particular Google server goes down, the TTL guarantees that in 55 seconds, the user has good odds of contacting another server.
Canonical name (CNAME) records are used to associate an alias to a canonical name. For example, consider lookups for www.oreilly.com:
dig +nocomment +noquestion +nostats +nocmd www.oreilly.com
www.oreilly.com. 3563 IN CNAME oreilly.com.
oreilly.com. 506 IN A 208.201.239.101
oreilly.com. 506 IN A 208.201.239.100
As this shows, the name www.oreilly.com actually points to oreilly.com. www.oreilly.com does not have an IP address; it points to oreilly.com, and that name has an IP address. Canonical names are used for shortcuts (as in the previous example), and also to manage content distribution. The example using Fox News showed how Akamai first aliases all of Fox News’ sites into its own network names using CNAME.
DNS provides the lookup functions for email, through the agency of the mail exchange (MX) record. MX records record the addresses of mail servers for a particular domain. For example, if I decide to mail jbro@andrew.cmu.edu, I can find the mail server for doing so by looking up the MX records for cmu.edu:
$dig +noquestion +nostats +nocmd mx cmu.edu
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 49880
;; flags: qr rd ra; QUERY: 1, ANSWER: 4, AUTHORITY: 0, ADDITIONAL: 2
;; ANSWER SECTION:
cmu.edu. 21560 IN MX 10 CMU-MX-03.ANDREW.cmu.edu.
cmu.edu. 21560 IN MX 10 CMU-MX-04.ANDREW.cmu.edu.
cmu.edu. 21560 IN MX 10 CMU-MX-01.ANDREW.cmu.edu.
cmu.edu. 21560 IN MX 10 CMU-MX-02.ANDREW.cmu.edu.
;; ADDITIONAL SECTION:
CMU-MX-01.ANDREW.cmu.edu. 21519 IN A 128.2.11.59
CMU-MX-02.ANDREW.cmu.edu. 21159 IN A 128.2.11.60
MX records include a server name (such as CMU-MX-03.ANDREW.cmu.edu), as well as a priority value for the email server. The weighting value is used to choose a mail server: mail clients should pick mail servers in order of ascending priority (i.e., 1 should be chosen before 10).
Of note in this example are the A records shoved into the additional section. These records resolve the CMU-MX-01 and CMU-MX-02 addresses. This is a conscious decision by CMU’s DNS administrators to include this information and reduce the number of lookups done.
NS records are used to find the authoritative nameserver for a zone. For example, for O’Reilly Media:
$ dig +nostat ns oreilly.com
; <<>> DiG 9.8.3-P1 <<>> +nostat ns oreilly.com
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 32310
;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 0
;; QUESTION SECTION:
;oreilly.com. IN NS
;; ANSWER SECTION:
oreilly.com. 3600 IN NS nsautha.oreilly.com.
oreilly.com. 3600 IN NS nsauthb.oreilly.com.
Now look at the NS record for a site managed by a CDN, such as Fox News again:
$ dig +nostat ns foxnews.com
; <<>> DiG 9.8.3-P1 <<>> +nostat ns foxnews.com
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 38538
;; flags: qr rd ra; QUERY: 1, ANSWER: 8, AUTHORITY: 0, ADDITIONAL: 5
;; QUESTION SECTION:
;foxnews.com. IN NS
;; ANSWER SECTION:
foxnews.com. 300 IN NS usc2.akam.net.
foxnews.com. 300 IN NS ns1.chi.foxnews.com.
foxnews.com. 300 IN NS ns1-253.akam.net.
foxnews.com. 300 IN NS dns.tpa.foxnews.com.
foxnews.com. 300 IN NS usw1.akam.net.
foxnews.com. 300 IN NS usw3.akam.net.
foxnews.com. 300 IN NS asia3.akam.net.
foxnews.com. 300 IN NS usc4.akam.net.
;; ADDITIONAL SECTION:
usw1.akam.net. 28264 IN A 96.17.144.195
usw3.akam.net. 50954 IN A 69.31.59.199
asia3.akam.net. 28264 IN A 222.122.64.134
usc4.akam.net. 28264 IN A 96.6.112.196
usc2.akam.net. 88188 IN A 69.31.59.199
Note that in this case, the authoritative nameservers are largely owned by akam.net (Akamai). Fox News is hosted by Akamai’s CDN, and Akamai modifies the names of the hosts as necessary in order to boost performance.
SOA records contain summary information about the authoritative server for a domain. These records are most commonly encountered during failed lookups. When an address isn’t found, the SOA information for that zone’s server is returned instead.
dig @8.8.4.4 +multiline +nostat zlkoriongomk.com
; <<>> DiG 9.8.3-P1 <<>> @8.8.4.4 +multiline +nostat zlkoriongomk.com
; (1 server found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 11857
;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 1, ADDITIONAL: 0
;; QUESTION SECTION:
;zlkoriongomk.com. IN A
;; AUTHORITY SECTION:
com. 899 IN SOA a.gtld-servers.net. nstld.verisign-grs.com. (
1374373035 ; serial
1800 ; refresh (30 minutes)
900 ; retry (15 minutes)
604800 ; expire (1 week)
86400 ; minimum (1 day)
)
The SOA field begins with the source host, followed by a contact email address. After this address comes a serial number, which indicates how many times the source file has been modified, and then timeout statistics. Note the \+multiline option for dig; this will provide a multiple line, more human-readable output for the SOA record.
The TXT field is a wildcard field used for any text output that the server administrator feels like passing. For example, Google passes strings for managing Google Apps:
$ dig +short txt google.com
"v=spf1 include:_spf.google.com ip4:216.73.93.70/31 ip4:216.73.93.72/31 ~all"
The DNS Reverse Lookup
A reverse lookup is the process of reconstructing a DNS name from an IP address. For example, if I want to find out who owns 208.201.139.101, I do so using dig -x:
$ dig +nostat -x 208.201.139.101
; <<>> DiG 9.8.3-P1 <<>> +nostat -x 208.201.139.101
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 7519
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0
;; QUESTION SECTION:
;101.139.201.208.in-addr.arpa. IN PTR
;; ANSWER SECTION:
101.139.201.208.in-addr.arpa. 21600 IN PTR host-d101.studley.com.
Reverse lookups are requests to get DNS names from IP addresses. Note that the question section does not request the IP address, 208.201.139.101, but 101.139.201.208.in-addr.arpa, which lists the fields of the IP address in reverse order. When DNS does a reverse lookup, it creates a special domain name to query in the in-addr.arpa TLD.[13] The string of digits and periods used for a reverse lookup is the original IP address reversed. The is because DNS names and IP addresses are defined in a contradictory fashion. A DNS name becomes more finely defined (from TLD to domain to individual host) by reading from right to left, while IP addresses are more finely defined reading from left to right.
Reverse lookups are a kludge. Note that the record returned in the answer is a Pointer (PTR) record. PTR records are not automatically created with the canonical A records, but are instead registered separately by the NIC. More important, there’s no requirement that a PTR record be registered, and the relationship between names and IP addresses is tenuous at best.
For example, consider a CDN. If I look up one of Fox News’ IP addresses, such as 23.66.230.66, I get this:
dig +nostat +nocmd -x 23.66.230.66
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 56379
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0
;; QUESTION SECTION:
;66.230.66.23.in-addr.arpa. IN PTR
;; ANSWER SECTION:
66.230.66.23.in-addr.arpa. 290 IN
PTR a23-66-230-66.deploy.static.akamaitechnologies.com.
The CDN becomes an informational dead end; the answer from the reverse lookup has no meaningful relation to the names in the original query.
In general, DNS information is best collected at the time of the original query. The uncertainty of reverse lookups is part of the reason for this. However, even if reverse lookups worked perfectly, attackers often use very short-lived names. Where possible, record domain names as they’re used (such as the URL in HTTP logs) rather than trying to reconstruct them after the fact.
Using whois to Find Ownership
While DNS can provide information on a domain’s name, the meat of ownership information is provided by whois. This is a federated protocol (RFC 3921) that lists the putative owners of DNS names. The standard whois query on a domain will return ownership and contact information for a domain, as seen in Example 8-2.
Example 8-2. A whois query for oreilly.com
$whois oreilly.com
<boilerplate>
Domain Name: OREILLY.COM
Registrar: GODADDY.COM, LLC
Whois Server: whois.godaddy.com
Referral URL: http://registrar.godaddy.com
Name Server: NSAUTHA.OREILLY.COM
Name Server: NSAUTHB.OREILLY.COM
Status: clientDeleteProhibited
Status: clientRenewProhibited
Status: clientTransferProhibited
Status: clientUpdateProhibited
Updated Date: 26-may-2012
Creation Date: 27-may-1997
Expiration Date: 26-may-2013
<more boilerplate>
Registered through: GoDaddy.com, LLC (http://www.godaddy.com)
Domain Name: OREILLY.COM
Created on: 26-May-97
Expires on: 25-May-13
Last Updated on: 26-May-12
Registrant:
O'Reilly Media, Inc.
1005 Gravenstein Highway North
Sebastopol, California 95472
United States
Administrative Contact:
Contact, Admin nic-ac@oreilly.com
O'Reilly Media, Inc.
1005 Gravenstein Highway North
Sebastopol, California 95472
United States
+1.7078277000 Fax -- +1.7078290104
Technical Contact:
Contact, Tech nic-tc@oreilly.com
O'Reilly Media, Inc.
1005 Gravenstein Highway North
Sebastopol, California 95472
United States
+1.7078277000 Fax -- +1.7078290104
Domain servers in listed order:
NSAUTHA.OREILLY.COM
NSAUTHB.OREILLY.COM
You’ll note that a whois entry for a domain returns an enormous amount of boilerplate information. You will also find that the information returned has no particular fixed format—whois information is the electronic equivalent of 3×5 index cards. Depending on who owns the card and how they decide to administer it, you may get phone numbers and biographies, or nothing at all.
A good way to get a feel for the differences in registration is to take a look at the registration files for different countries. There is no central whois database—instead, depending on the top-level domain, whois information may be maintained by any of a number of whois servers. For example, Russian whois data (the .ru domain) is maintained by whois.ripn.net, French by lvs-vip.nic.fr, and Brazilian by registro.br. Fortunately, the good folks at whois-servers.net provide aliases for every country and TLD, and depending on your whois implementation, the information may be baked into the executable for you already.
At the minimum, any whois implementation will provide the ability to specify a lookup server using the -h switch. So whois -h ru.tld-servers.net is identical to whois -h whois.ripn.net. Several whois implementations offer a country-specific -c option, making whois -c RU identical to both of the previous examples.
In addition to providing information on domain names, whois is also useful for providing information on address allocation and ownership. If whois is called with an IP address rather than a name, like in Example 8-3, it will provide information on the organization that owns that address, often in the form of a netblock. For example, if I look up the whois information for Voila, a French search engine, I get different information based on whether I look at RIPE (the European top-level registry) or the French NIC. RIPE is informative; the French NIC is considerably less so.
Example 8-3. Using whois with an IP address
$dig +short voila.fr
193.252.148.80
$ whois -h whois.ripe.net 193.252.148.80
% This is the RIPE Database query service.
% The objects are in RPSL format.
%
% The RIPE Database is subject to Terms and Conditions.
% See http://www.ripe.net/db/support/db-terms-conditions.pdf
% Note: this output has been filtered.
% To receive output for a database update, use the "-B" flag.
% Information related to '193.252.148.0 - 193.252.148.255'
% Abuse contact for '193.252.148.0 - 193.252.148.255' is 'gestionip.ft@orange.com'
inetnum: 193.252.148.0 - 193.252.148.255
netname: ORANGE-PORTAILS
descr: France Telecom
descr: internet portals for multiple services
country: FR
admin-c: WPTR1-RIPE
tech-c: WPTR1-RIPE
status: ASSIGNED PA
remarks: for hacking, spamming or security problems send mail to
remarks: abuse@orange.fr
mnt-by: FT-BRX
source: RIPE # Filtered
role: Wanadoo Portails Technical Role
address: France Telecom - OPF/Portail/DOP/Hebex
address: 48, rue Camille Desmoulins
address: 92791 Issy Les Moulineaux Cedex 9
address: FR
phone: +33 1 5888 6500
fax-no: +33 1 5888 6680
admin-c: WPTR1-RIPE
tech-c: WPTR1-RIPE
nic-hdl: WPTR1-RIPE
mnt-by: FT-BRX
source: RIPE # Filtered
% This query was served by the RIPE Database Query Service version 1.60.2 (WHOIS4)
$ whois -h fr.whois-servers.net 195.152.120.129
%%
%% This is the AFNIC Whois server.
%%
%% complete date format : DD/MM/YYYY
%% short date format : DD/MM
%% version : FRNIC-2.5
%%
%% Rights restricted by copyright.
%% See http://www.afnic.fr/afnic/web/mentions-legales-whois_en
%%
%% Use '-h' option to obtain more information about this service.
%%
%% [96.255.98.126 REQUEST] >> 195.152.120.129
%%
%% RL Net [##########] - RL IP [#########.]
You will find that the situation is reversed with Asian information. The APNIC whois is often fairly sparse, but the whois entries at the country level are usually informative.
Whois information is particularly useful when you can’t get much useful data out of a DNS reverse lookup. If you can’t find the specific domain name, you can use whois to at least find the block of addresses that host the domain.
Additional Reference Tools
In addition to network and routing information, there exist a number of commonly accessible sites containing information on exploits, attacks, and the reputation of particular IP addresses. These sites are usually small, volunteer-run and have a fair degree of turnover to them.
DNSBLs
A DNS Blackhole List (DNSBL) is a DNS-based IP address database used primarily as an antispam technique. The first DNSBLs were actually implemented using BGP, and were intended to actively drop routes associated with spammer IP addresses. DNSBLs are instead DNS-moderated, they serve as reputation databases for email software. For example, a mail transfer agent can consult a DNSBL to determine if the sending IP is a spammer and react accordingly.
DNSBLs work by providing a reverse-lookup style functionality on their DNS servers. For example, I can look up an echo address on a DNSBL using dig:
$ dig 2.0.0.127.sbl.spamhaus.org
; <<>> DiG 9.8.3-P1 <<>> 2.0.0.127.sbl.spamhaus.org
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 45434
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0
;; QUESTION SECTION:
;2.0.0.127.sbl.spamhaus.org. IN A
;; ANSWER SECTION:
2.0.0.127.sbl.spamhaus.org. 300 IN A 127.0.0.2
;; Query time: 39 msec
;; SERVER: 192.168.1.1#53(192.168.1.1)
;; WHEN: Sun Jul 28 15:10:23 2013
;; MSG SIZE rcvd: 60
The address I intended to query was 127.0.0.2. Note that, as with a reverse lookup, I reverse the IP address. After reversing the address, I attach it to the name of the list and query. This process is effectively a reverse lookup without relying on the hard-coded .arpa TLD. Instead, the response is provided by an A record provided by Spamhaus’s SBL server.
DNSBLs differ depending on the list and provider. Providers may provide several different forms of lists for different categories of traffic. Different providers will also provide different policies for adding or removing addresses from the DNSBL. How different organizations handle delisting(address removal) radically impacts the character of the list. Most automatically drop an address a fixed number of days after the last abuse; others require manual intervention.
Some notable DNSBLs include:
Spam and Open Relay Blocking System (SORBS)
Provides over 15 different DNSBLs that categorize hosts into a number of different behaviors. SORBS is particularly useful for categorizing dynamic addresses such as dialup and DSL addresses through a specialized list, the Dynamic User and Host List (DUHL).
Spamhaus
A nonprofit private company that produces a number of distinct blacklists and whitelists. Spamhaus’s most commonly used lists are the PBL (end-user addresses), SBL (spam addresses), and XBL (hijacked IP addresses and bots). These lists are accessible as a single combined service, ZEN.
SpamCop
Currently owned by Cisco Systems, SpamCop began as a private effort and eventually became part of IronPort’s email reputation system. Currently, SpamCop provides one public list, the SpamCop Block List (SCBL).
DNSBLs are useful as a categorized source of hostile activity. Using a DNSBL, an analyst can determine whether a particular address has been doing something hostile elsewhere on the Internet and possibly what kind of activity it was. They supplement the more basic lookup information discussed earlier by providing some idea of a site’s past history.
DNSBLs are designed to be real-time tools that work primarily with mail agents, not to support forensic analysis. Records will change quickly and unpredictably, so an address may be recognized by the DNSBL as hostile at the time of an event, but be delisted when an analyst examines it later. Most of the blacklists sell some kind of feed or data dump that, for forensic purposes, is preferable.
[11] Note that the prefix is the equivalent to a subnet’s netmask.
[12] Internationalized domain names raise the risk of homographic attacks, such as creating a domain name that looks like oreilly.com but uses a Cyrillic O.
[13] .arpa officially stands for Address and Routing Parameter area. This name is a backronym, because the abbreviation originally meant Advanced Research Projects Agency, the DoD agency that originally funded Internet development
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.