Hacking Web Apps: Detecting and Preventing Web Application Security Problems (2012)
Chapter 6. Abusing Design Deficiencies
Information in this chapter:
• Understanding Logic Attacks
• Employing Countermeasures
How does a web site work? This isn’t an existential investigation into its purpose, but a technical one into the inner workings of policies and controls that enforce its security. Sites experience problems with cross-site scripting (XSS) and SQL injection when developers fail to validate incoming data or misplace trust in users to not modify requests. Logic-based attacks target weaknesses in a site’s underlying design and assumptions. Instead of injecting grammar-based payloads (like <script> tags or apostrophes) the hacker is searching for fundamental flaws due to the site’s design. These flaws may be how it establishes stateful workflows atop the stateless HTTP, executes user actions, or enforces authorization. A site may have a secure design, yet still fall victim to implementation errors; this is an understandable problem of human error. For example, development guidelines may require prepared statements to counter SQL injection attacks. But a developer might forget or forgo the guidelines and introduce a vulnerability due to concatenating strings to build a query. (Just like typos show up in a book in spite of automatic spell-checkers.) That’s an implementation error, or perhaps a weakness in the development process that missed a poor programming pattern.1
This chapter focuses on the mistakes in the site’s underlying design that lead to vulnerabilities. A site with pervasive SQL injection problems clearly has a flawed design—its developers have neglected to lay out a centralized resource (be it an object, library, documentation, etc.) to securely handle SQL queries that contain tainted data. Such a design problem arises out of ignorance (developers blissfully unaware of SQL security issues) or omission (lack of instruction on how SQL statements should be built). We’ll encounter other types of design mistakes throughout this chapter. Mistakes that range from ambiguous specifications, to invalid assumptions, to subtle cryptographic errors.
Rarely are any tools other than a browser necessary to exploit logic errors or application state attacks against a site. Unlike XSS (which isn’t a difficult hack anyway), the hacker typically need not understand JavaScript or HTTP details to pull off an attack. In many cases the hackers are the web-equivalent of shoplifters, fraudsters, or pranksters looking for ways to manipulate a web app that are explicitly or implicitly prohibited. This represents quite a different threat than attacks predicated on deep technical understanding of SQL statements, regular expressions, or programming languages. The only prerequisite for the hacker is that they have an analytical mindset and a creative approach to exploiting assumptions.
The attack signatures for these exploits vary significantly from other attacks covered throughout this book. An attack might be a series of legitimate requests repeated dozens of times or in an unexpected sequence. Imagine an online book seller that regularly offers unique discount codes to random customers. The site’s usual workflow for visitors involves steps like the following:
(1) select a book;
(2) add book to the shopping cart;
(3) proceed to checkout;
(4) enter shipping information;
(5) enter coupons;
(6) update price;
(7) provide payment information;
(8) finalize purchase.
An enterprising hacker might set up a dummy account and pick a book at random to take through the checkout process. The attack would proceed through step four (even using a fake shipping address). Once at step five the attacker guesses a discount code. If the result in step six shows a price reduction, the guess was correct. If not, return to step five and try again. The process is tedious if done by hand, but so trivial to automate such that a little programming could create a bot that runs 24 hours a day, collecting discount codes.
Nothing in the previous enumeration of discount codes looked like malicious traffic. At least not in terms of hacks like SQL injection or XSS that contain the usual suspects of angle brackets and apostrophes. The hack targeted a weak design of the checkout process and discount codes:
• Discount codes sent to a customer were weakly tied to the customer’s account. The security of the code (meaning who could use it) was only limited to who had knowledge of the code (its intended recipient). In other words, anyone who guessed a valid code could use it rather than it being explicitly tied to the account for which it was intended.
• The application signaled the difference between valid and invalid codes, which enabled the hacker to brute force valid codes. This type of feedback improves the site’s usability for legitimate customers, but leaks useful information to attackers. If the code were tied to a specific account(thereby limiting the feedback to a per-account basis as opposed to a global basis), then the improved usability would not be at the expense of lesser security.
• The checkout process was not rate-limited. The hacker’s bot could enumerate discount codes as quickly as the site would respond with valid/invalid feedback.
Now imagine the same workflow under a different attack that targets steps five and six with a valid discount code. Maybe it’s just a 5% discount (the rarer 50% off codes haven’t been discovered yet by the brute force enumeration). This time the attacker enters the code, checks the updated price, then proceeds to step seven to provide payment information. Before moving on to step eight the site asks the user to confirm the order, warning that the credit card will be charged in the next step. At this point the attacker goes back to step five (possibly as simple as using the browser’s back history button) and re-enters the discount code. Since the site is waiting for a confirmation, it loses track that a discount has already been applied. So the attacker repeats steps five and six until the 5% coupon a few dozen times to turn a $100 item into a $20 purchase (which coincidentally might be below a $25 fraud detection threshold). Finally, the attacker returns to step seven, reviews the order, and confirms the purchase.
What if the attacker needed to have $200 worth of items before a big-discount code could be applied? The attacker might choose one book, then add a random selection of others until the $200 limit is reached. At this point the attacker applies the code to obtain a reduced price. Finally, before confirming the purchase the hacker removes the extra items (which removes their price from the order)—but the discount remains even though the limit has no longer been met.
Let’s look at yet another angle on our hapless web site. In step four a customer is asked to fill out a shipping address and select a shipping method from a high-cost overnight delivery to low-cost shipment in a week. What happens if the web site tracks the cost and method in different parameters? The attacker might be able to change the selection to a mismatched pair of low-cost rate with high-cost time frame. The attack might be as simple as changing a form submission from something like cost=10&day=1 or cost=1&day=7 to cost=1&day=1. The individual values forcost and day are valid, but the combination of values is invalid—the application shouldn’t be allowing low rates for overnight service. What if we strayed from purely legitimate values to changing the cost of the overnight rate to a negative amount? If the [ital] cost [/ital] parameter is -10, maybe the web application subtracts $10 from the total price because its shipping rate verification ignores the negative sign, but the final calculation includes it.
Even though the previous examples relied quite heavily on conjecture they are based on vulnerabilities from real, revenue-generating web sites. Logic attacks involve a long string of what-ifs whose nature may be quite different from the childhood angst in the poem Whatif by Shel Silverstein from his book A Light in the Attic, but nevertheless carry the same sense of incessant questioning and danger. You’ll also notice that, with the exception of changing a value from 10 to −10 in the previous example, every attack used requests that were legitimately constructed and therefore unlikely to trip web app firewalls or intrusion detection systems. The attacks also involved multiple requests, taking more of the workflow into consideration as opposed to testing a parameter to see if single quote characters can be injected into it. The multiple requests also targeted different aspects of the workflow. We could have continued with several more examples that looked into the site’s reaction to out of sequence events or possibly using it to match stolen credit card numbers with valid shipping addresses. The list of possibilities isn’t endless, but logic-based attacks, or at least potential attacks, tend to be limited by the hacker’s ingenuity and increase as an app becomes more complex.
The danger of logic-based attacks is no less than the more commonly known ones like XSS. These attacks may even be more insidious because there are rarely strong indicators of malicious behavior—attackers don’t always need to inject strange characters or use multiple levels of character encoding to exploit a vulnerability. Exploits against design deficiencies have a wide range of creativity and manifestation. These problems are also more difficult to defend and identify. There is no universal checklist for verifying a web site’s workflow. There are no specific characters to blacklist or common payloads to monitor. Nor are there specific checklists that attackers follow or tools they use to find these vulnerabilities. Beware that even the simplest vulnerability can lose the site significant money.
Understanding Logic & Design Attacks
Attacks against the business logic of a web site do not follow prescribed techniques. They may or may not rely on injecting invalid characters into a parameter. They do not arise from a universal checklist that applies to every web application. No amount of code, from a Python script to Haskell learning algorithm to a complex C++ scanner, can automatically detect logic-based vulnerabilities in an application. Logic-based attacks require an understanding of the web application’s architecture, components, and processes. It is in the interaction of these components where attackers find a design flaw that exposes sensitive information, bypasses an authentication or authorization mechanism, or provides a financial gain or advantage.
This chapter isn’t a catch-all of vulnerabilities that didn’t seem to fit neatly in another category. The theme throughout should be attacks that subvert a workflow specific to an application. The examples use different types of applications, from web forums to e-commerce, but the concepts and thought processes behind the attacks should have more general applications. Think of the approach as define abuse cases for a test environment. Rather than verifying a web site’s feature does or does not work for a user, the attack is trying to out how to make a feature work in a way that wasn’t intended by the developers. Without building a deep understanding of the target’s business logic an attacker only pokes at the technical layers of fault injection, parameter manipulation, and isolated vulnerabilities within individual pages.
Abusing Workflows
We have no checklist with which to begin, but a common theme among logic-based attacks is the abuse of a site’s workflow. This ranges from applying a coupon more than once to drastically reduce the price of an item to possibly changing a price to a negative value. Workflows also imply multiple requests or a sequence of requests that are expected to occur in a specific order. This differs from many of the other attacks covered in this book that typically require a single request to execute. Cross-site scripting, for example, usually needs one injection point and a single request to infect the site. The attacks against a web site’s workflows often look suspiciously like a test plan that the site’s QA department might have (or should have) put together to review features. A few techniques for abusing a workflow might involve:
• Changing a request from POST to GET or vice versa in order to execute within a different code path.
• Skipping steps that normally verify an action or validate some information.
• Repeating a step or repeating a series of steps.
• Going through steps out of order.
• Performing an action that “No one would really do anyway because it doesn’t make sense.”
Exploiting Policies & Practices
We opened this chapter with the caveat that universally applicable attacks are rare in the realm of logic-based vulnerabilities. Problems with policies and practices fall squarely into this warning. Policies define how assets must be protected or how procedures should be implemented. A site’s policies and security are separate concepts. A site fully compliant with a set of policies may still be insecure. This section describes some real attacks that targeted inadequacies in sites’ policies or practices.
Financially motivated criminals span the spectrum of naïve opportunists to sophisticated, disciplined professionals. Wary criminals who compromise bank accounts do not immediately siphon the last dollar (or euro, ruble, darsek, etc.) out of an account. The greatest challenge for criminals who wish to consistently steal money is how to convert virtual currency, numbers in a bank account, into cash. Some will set up auction schemes in which the victim’s finances are used to place outrageous bids for ordinary items. Others use intermediary accounts with digital currency issuers to obfuscate the trail from virtual to physical money. Criminals who launder money through a mix of legitimate and compromised accounts may follow one rule in particular. The US Government established a requirement for financial institutions to record cash, transfer, and other financial transactions that exceed a daily aggregate of $10,000 (http://www.fincen.gov/statutes_regs/bsa/). This reporting limit was chosen to aid law enforcement in identifying money laundering schemes and other suspicious activity.
The $10,000 limit is not a magical number that assures criminal transactions of $9876 are ignored by investigators and anti-fraud departments. Yet remaining under this value might make initial detection more difficult. Also consider that many other illegal activities unrelated to credit-cart scams or compromised bank accounts occur within the financial system. The attacker is attempting to achieve relative obscurity so that other, apparently higher-impact activities gather the attention of authorities. In the end, the attacker is attempting to evade detection by subverting a policy.
Reporting limits are not the only type of policy that attackers will attempt to circumvent. In 2008 a man was convicted of a scam that defrauded Apple out of more than 9000 iPod Shuffles (http://www.sfgate.com/cgi-bin/article.cgi?f=/c/a/2009/03/20/BU2L16JRCL.DTL). Apple set up an advance replacement program for iPods so that a customer could quickly receive a replacement for a broken device before the device was received and processed by Apple. The policy states, “You will be asked to provide a major credit card to secure the return of the defective accessory. If you do not return the defective accessory to Apple within 10 days of when we ship the replacement part, Apple will charge you for the replacement.”2 Part of the scam involved using credit cards past their limit when requesting replacement devices. The cards and card information were valid. Thus they passed initial anti-fraud mechanisms such as verification that the mailing address matched the address on file by card’s issuer. So at this point the cards were considered valid by the system. However, the cards were over-limit and therefore couldn’t be used for any new charges. The iPods were shipped and received well before the 10-day return limit, at which time the charge to the card failed because only now was the limit problem detected. Through this scheme and another that swapped out-of-warranty devices with in-warranty serial numbers the scammers collected $75,000 by selling the fraudulently obtained iPods (http://arstechnica.com/apple/news/2008/07/apple-sues-ipodmechanic-owner-for-massive-ipod-related-fraud.ars).
No technical vulnerabilities were exploited in the execution of this scam. It didn’t rely on hacking Apple’s web site with cross-site scripting or SQL injection, nor did it break an authentication scheme or otherwise submit unexpected data to Apple. The credit card numbers, though not owned by the scammers, and all other submitted values followed valid syntax rules that would bypass a validation filter and web application firewall. The scam relied on the ability to use credit cards that would be authorized, but not charged—otherwise the owner of the card might detect unexpected activity. The return policy had a countermeasure to prevent someone from asking for a replacement without returning a broken device. The scammers used a combination of tactics, but one important one was choosing cards that appeared valid at one point in the workflow (putting a card on record), but was invalid at another, more important point in the workflow (charging the card for a failed return).
Apple’s iTunes and Amazon.com’s music store faced a different type of fraudulent activity in 2009. This section opened with a brief discussion of how criminals overcome the difficulty of turning stolen credit cards into real money without leaving an obvious or easily detectable trail from crime to currency. In the case of iTunes and Amazon.com a group of fraudsters uploaded music tracks to the web sites. The music didn’t need to be high quality or have an appeal to music fans of any genre because the fraudsters used stolen credit cards to buy the tracks, thus earning a profit from royalties (http://www.theregister.co.uk/2009/06/10/amazon_apple_online_fraudsters/). The scheme allegedly earned the crew $300,000 dollars from 1500 credit cards.
In the case of iTunes and Amazon.com’s music store neither web site was compromised or attacked via some technical vulnerability. In all ways but one the sites were used as intended; musicians uploaded tracks, customers purchased those tracks, and royalties were paid to the content’s creators. The exception was that stolen credit cards were being used to purchase the music. Once again, no network device, web application firewall, or amount of secure coding could have prevented this type of attack because the site was just used as a conduit for money laundering. The success of the two retailers in stopping the criminals was based on policies and techniques for identifying fraudulent activity and coordinating with law enforcement to reach the point where, instead of writing off $10 downloads as expected losses due to virtual shoplifting, the complete scheme was exposed and the ringleaders identified.
Not all web site manipulation boils down to money laundering or financial gain. In April 2009 hackers modified Time Magazine’s online poll of the top 100 most influential people in government, science, and technology. Any online poll should immediately be treated with skepticism regarding its accuracy. Polls and online voting attempt to aggregate the opinions and choices of individuals. The greatest challenge is ensuring that one vote equals one person. Attackers attempt to bend a poll one way or another by voting multiple times under a single or multiple identities3. In the case of the Time poll, hackers stuffed the virtual ballot box using nothing more than brute force voting to create an elegant acrostic from the first letter of the top 21 candidates (http://musicmachinery.com/2009/04/15/inside-the-precision-hack/).
Reading down the list the attackers managed to create the phrase, “Marblecake also the game.” They accomplished this through several iterations of attack. First, the poll did not have any mechanisms to rate limit, authenticate, or otherwise validate votes. These failings put the poll at the mercy of even the most unsophisticated attacker. Eventually Time started to add countermeasures. The developers enforced a rate limit of one vote per IP address per candidate every 13 seconds. The per candidate restriction enabled the attacks to throw in one positive vote for their candidate and negative votes for other candidates within each 13 second window. The developers also attempted to protect URIs by appending a hash used to authenticate each vote. The hash was based on the URI used to submit a vote and a secret value, referred to as a salt, intended to obfuscate how the hash was generated. (The utility of salts with cryptographic hash functions is discussed in Chapter 4: SQL Injection.) Without knowledge of the salt included in the hash generation attackers could not forge votes. A bad vote would receive the message, “Missing validation key.”
This secret value, the salt, turned an easily-guessed URI into one with a parameter that at first glance appears hard to reverse engineer, as shown below. Note that the salt itself does not appear in the URI, but the result of the hash function that employed the salt appears in the key parameter:
/contentpolls/Vote.do?pollName=time100_2009&id=1885481&rating=100&key=9279fbf4490102b824281f9c7b8b8758
The key was generated by an MD5 hash, as in the following pseudo-code:
salt = ?
key = MD5(salt + ‘/contentpolls/Vote.do?pollName=time100_2009&id=1885481&rating=100’)
Without a correct salt the key parameter could not be updated to accept arbitrary values for the id and rating, which is what needed to be manipulated. If an attacker submitted a URI like the following (note the rating has been changed from 100 to 1), the server could easily determine that the key value doesn’t match the hash that should have been generated. This is how the application would be able to verify that the URI had been generated from a legitimate vote rather than a spoofed one. Only legitimate votes, i.e. voting links created by the Time web site, would have knowledge of the salt in order to create correct key values.
/contentpolls/Vote.do?pollName=time100_2009&id=1885481&rating=1&key=9279fbf4490102b824281f9c7b8b8758
The brute force approach to guess the salt would start iterating through potential values until it produced an MD5 hash that matched the key within the URI. The following Python code shows a brute force attack, albeit one with suboptimal efficiency:
#!/usr/bin/python
import hashlib
key = “9279fbf4490102b824281f9c7b8b8758”
guesses = [”lost”, “for”, “words”]
for salt in guesses:
hasher = hashlib.md5()
hasher.update(salt + “/contentpolls/Vote.do?pollName=time100_2009&id=1885481&rating=100”)
if cmp(key, hasher.hexdigest()) == 0:
print hasher.hexdigest()
break
Brute force takes time and there was no hint whether the salt might be one character, eight characters, or more. A secret value that might contain eight mixed-case alphanumeric and punctuation characters could be any one of roughly 1016 values. One dedicated computer might be able to test around 14,000 guesses per second. An exhaustive brute force attack wouldn’t be feasible without several hundred thousand computers dedicated to the task (or a lucky guess, of course).
The problem for Time was that the salt was embedded in the client-side Flash application used for voting. The client is always an insecure environment in terms of the data received from it and, in this example, the data sent to it. Disassembling the Flash application led the determined hackers to the salt: lego-rules. With this in hand it was once again possible to create URIs with arbitrary values and bypass the key-based authentication mechanism. Note that adding a salt in this case was a step in the right direction; the problem was that the security of the voting mechanism depended on the salt remaining secret, which was impossible since it had to be part of a client-side object.
TIP
If you’re interested in Open Source brute force tools check out John the Ripper at http://www.openwall.com/john/. It supports many algorithms and being Open Source is easily customized by a programmer with C experience. The site also provides various word lists useful for dictionary-based tests. At the very least, you might be interested in seeing the wide range of guesses per second for different password schemes.
The Time poll hack made news not only because it was an entertaining misuse of a site’s functionality, but also because it highlighted the problem with trying to establish identity on the Internet. The attacks only submitted valid data (with the exception of situations where ratings were outside the expected range of 1–100, but those were not central to the success of the attack). The attacks bypassed inadequate rate limiting policies and an obfuscated key generation scheme.
Don’t dismiss these examples as irrelevant to your web site. They share a few themes that apply more universally than just to banks, music sites, and online polls.
• Loophole is just a synonym for vulnerability. Tax laws have loopholes, web sites have vulnerabilities. In either case the way a policy is intended to work is different from how it works in practice. A policy’s complexity may introduce contradictions or ambiguity that translates to mistakes in the way that a feature is implemented or features that work well with expected state transitions from honest users, but fail miserably in the face of misuse.
• Determined attackers will probe monitoring and logging limits. This might be accomplished through assuming low thresholds, generating traffic that overwhelms the monitors such that the actual hidden attack is deeply hidden within the noise, bribe developers to obtain source code, use targeted phishing attacks against developers to obtain source code, and more steps that are limited only by creativity.
• Security is an emergent property of a web application. Individual countermeasures may address specific threats, but may have no effect or a detrimental effect on the site’s overall security due to false assumptions or mistakes that arise from complexity.
• Attacks do not need to submit invalid data or malicious characters to succeed. Abusing a site’s functionality usually means the attacker is skipping an expected step or circumventing a policy by exploiting a loophole.
• The site may be a conduit for an attack rather than a direct target of the attack. In Chapter 2: Cross-Site Request Forgery (CSRF) we discussed how one site might contain a booby-trapped page that executes sensitive commands in the browser to another site without the victim’s knowledge. In other cases the site may be a tool for extracting hard currency from a stolen credit card, such as an auction or e-commerce application.
• Attackers have large, distributed technical and information resources. Organized crime has demonstrated coordinated ATM withdrawals using stolen account information across dozens of countries in a time window measured in minutes. Obviously this required virtual access to steal bank information, but physical presence to act upon it. In other situations attackers may use discussion forums to anonymously share information and collaborate.
Induction
Information is a key element of logic-based attacks. One aspect of information regards the site itself, answering questions such as, “What does this do?” or “What are the steps to accomplish an action?” Other types of information might be leaked by the web site that lead to questions such as, “What does this mean?” We’ll first discuss an example of using induction to leverage information leaks against a web site.
The MacWorld Expo gathers Apple fanatics, press, and industry insiders to San Francisco each year. Prices to attend the event range from restricted passes for the lowly peon to extended privileges and treatment for those with expensive VIP passes. In 2007 the Expo’s web site leaked the access code to obtain a $1695 platinum passes for free (http://news.cnet.com/2100-1002_3-6149994.html). The site used client-side JavaScript to push some validation steps off the server into the web browser. This is a common technique that isn’t insecure if server-side validation is still performed; it helps offload bulk processing into the browser to ease resource utilization on the server. In the case of the MacWorld registration page an array of possible codes were included in the HTML. These codes ranged from small reductions in price to the aforementioned free VIP passes.
The site’s developers, knowing that HTML is not a secure medium for storing secret information, obfuscated the codes with MD5 hashes. So, the code submitted by a user is converted to an MD5 hash, checked against an array of pre-calculated hashes, and accepted as valid if a match occurs. This is a common technique for matching a user-supplied string against a store of values that must remain secret. Consider the case where the site merely compares a value supplied by the user, VIPCODE, with an expected value, PC0602. The comparison will fail and the site will inform the user to please try again. If the site uses the web browser to perform the initial comparison, then a quick peek at the JavaScript source reveals the correct discount code. On the other hand, if the client-side JavaScript compared the MD5 hash of the user’s discount code with a list of pre-calculated hashes, then the real discount code isn’t immediately revealed.
However, hashes are always prone to brute force attacks. Since the conversion is performed fully within the browser adding a salt to the hash function does not provide any incremental security—the hash must be available to, therefore visible within, the browser as well. The next step was to dump the hashes into a brute force attack. In nine seconds this produced a match of ADRY (http://grutztopia.jingojango.net/2007/01/your-free-macworld-expo-platinum-pass_11.html). In far less than a day’s worth of work the clever researcher obtained a free $1695 pass—a pretty good return if you break down the value and effort into an hourly rate.
Epic Fail
In 2005 an online gaming site called Poker Paradise suffered from an issue in which observers could passively monitor the time delay between the site’s virtual Black Jack dealer showing an ace and offering players insurance (http://haacked.com/archive/2005/08/29/online-games-written-by-humans.aspx). Knowing whether the dealer had 21 gave alert players an edge in minimizing their losses. This advantage led to direct financial gain based on nothing more than the virtual analog of watching a dealer’s eyes light up when holding a pocket ten. (This is one of the reasons casino dealers offer insurance before determining if they’re holding an ace and a ten.) This type of passive attack would be impossible for the site to detect. Only the consequence of the exploit, a player or players taking winnings far greater than the expected average, would start to raise suspicions. Even under scrutiny, the players would be seen as doing nothing more than making very good decisions when faced with a dealer who might have 21.
The MacWorld Expo registration example demonstrated developers who were not remiss in security. If the codes had all been nine alphanumeric characters or longer then the brute force attack would have taken considerably longer than a few seconds to succeed. Yet brute force would have still been an effective, valid attack and longer codes might have been more difficult to distribute the legitimate users. The more secure solution would have moved the code validation entirely to server-side functions.4 This example also shows how it was necessary to understand the business purpose of the site (register attendees), a workflow (select a registration level), and purpose of code (an array of MD5 hashes). Human ingenuity and induction led to the vulnerability’s discovery. No automated tool could have revealed this problem nor would auditing the site against security checklist have fully exposed the problem.
Player collusion in gambling predates the Internet, but like many scams the Internet serves as a useful amplifier for fraudsters. These types of scams don’t target the application or try to learn internal information about the card deck as in the case of Poker Paradise. Instead, a group of players attempt to join the same virtual gaming table in order to trade information about cards received and collude against the one or few players who are playing without secret partners. Normally, the policy for a game is that any two or more players caught sharing information is to label the activity cheating and at the very least eject them from the game. That type of policy is easier to enforce in a casino or other situation where all the players are physically present and can be watched. Some cheaters might have a handful of secret signals to indicate good or bad hands, but the risks of being caught are far greater under direct scrutiny.
On the other hand, virtual tabletops have no mechanism for enforcing such a policy. Two players could sit in the same room or be separated by continents and easily use instant messaging or similar to discuss strategy. Some sites may take measures to randomize the players at a table in order to reduce the chances of colluding players from joining the same game. That solution mitigates the risk, but doesn’t remove it. Players can still be at risk from other information-based attacks. Other players might record a player’s betting pattern and store the betting history in a database. Over time these virtual tells might become predictable enough that it provides an advantage to the ones collecting and saving the data. Online games not only make it easy to record betting patterns, but also enable collection on a huge scale. No longer would one person be limited to tracking a single game at a time. These are interesting challenges that arise from the type of web application and have nothing to do with choice of programming language, software patches, configuration settings, or network controls.
Attacks against policies and procedures come in many guises. They also manifest outside of web applications (attackers also adopt fraud to web applications). Attacks against business logic can harm web sites, but attackers can also use web sites as the intermediary. Consider a common scam among online auctions and classifieds. A buyer offers a cashier’s check in excess of the final bid price, including a brief apology and explanation why the check is more. If the seller would only give the buyer a check in return for the excess balance, then the two parties can supposedly end the transaction on fair terms. The catch is that the buyer needs to refund soon, probably before the cashier’s check can be sent or before the seller realizes the check won’t be arriving. Another scam skips the artifice of buying an item. The grifter offers a check and persuades the victim to deposit it, stressing that the victim can keep a percentage, but the grifter really needs an advance on the deposited check. The check, of course, bounces.
These scams aren’t limited to checks, they exploit a loophole in how checks are handled—along with appealing to the inner greed, or misplaced trust, of the victim. Checks do not instantly transfer funds from one account to another. Even though a bank may make funds immediately available, the value of the check must clear before the recipient’s account is officially updated. Think of this as a time of check to time of use (TOCTOU) problem that was mentioned in Chapter 2.
TIP
Craiglist provides several tips on how to protect yourself from scams that try to take advantage of its site and others: http://www.craigslist.org/about/scams.
So where’s the web site in this scam? That’s the point. Logic-based attacks do not need a technical component to exploit a vulnerability. The problems arise from assumptions, unverified assertions, and inadequate policies. A web site might have such a problem or simply be used as a conduit for the attacker to reach a victim.
Using induction to find vulnerabilities from information leaks falls squarely into the realm of manual methodologies. Many other vulnerabilities, from cross-site scripting to SQL injection, benefit from experienced analysis. In Chapter 3: SQL Injection we discussed inference-based attacks (so-called “blind” SQL injection) that used variations of SQL statements to extract information from the database one bit at a time. This technique didn’t rely on explicit error messages, but on differences in observed behavior of the site—differences that ranged from the time required to return an HTTP response to the amount or type of content with the response.
Denial of Service
Denial of Service (DoS) attacks consume a web site’s resources to such a degree that the site becomes unusable to legitimate users. In the early days (relatively speaking, let’s consider the ‘90s as early) of the web DoS attacks could rely on techniques as simple as generating traffic to take up bandwidth. These attacks are still possible today, especially in the face of coordinated traffic from botnets.5 The countermeasures to network-based DoS largely fall out of the purview of the web application. On the other hand, other DoS techniques will target the business logic of the web site and may or may not rely on high bandwidth.
For example, think of an e-commerce application that desires to fight fraud by running simple verification checks (usually based on matching a zip code) on credit cards before a transaction is made. This verification step might be attacked by repeatedly going through a check-out process without completing the transaction. Even if the attack does not generate enough requests to impede the web site’s performance, the amount of queries might incur significant costs for the web site—costs that aren’t recouped because the purchase was canceled after the verification step but before it was fully completed.
Warning
Denial of Service need not always target bandwidth or server resources. More insidious attacks target actions with direct financial consequences. Paying for bandwidth is already a large concern for many site operators, so malicious traffic of any nature is likely to incur undesirable costs. Attacks also target banner advertising by using click fraud to drain money out of the site’s advertising budget. Other attacks might target back-end business functions like credit card verification systems that charge per request. This type of malicious activity doesn’t make the site less responsive for other users, but it has a negative impact on the site’s financial status.
Insecure Design Patterns
Bypassing inadequate validations often occurs when the intent of the filter fails to measure up to the implementation of the filter. In a way, implementation errors bear a resemblance to logic-based attacks. Consider the following examples of poor design.
Ambiguity, Undefined, & Unexpected Behavior
The web’s ecosystem of technologies, standards, and implementations leads to many surprising results. This holds true even for technologies that implement well-known standards. Standards attempt to define proscribed behavior for protocols, but poor wording or neglected scenarios leave developers to define how they think something should work, at least according to their interpretation. This kind of ambiguity leads to vulnerabilities when assumptions don’t match reality or hackers put pressure on corner cases.
Query string parameters are an understandably important aspect of web applications. They also represent the most common attack vector for delivering malicious <script> tags, SQL injection payloads, and other attacks. This is one reason sites, web application firewalls, and intrusion detection systems closely monitor query strings for signs of attack. It’s probably unnecessary to refresh your memory about the typical format of query strings. However, we want to take a fresh look at query strings from the perspective of design issues. Here’s our friend the URL:
http://web.site/page?param1=foo¶m2=bar¶m3=baz
Previous chapters explored the mutation of these parameters into exploits, e.g. param1=foo”><script>alert(9)</script>, or param1=foo’OR+1%2b1. Another way to abuse parameter values is to repeat them in the URL, as follows:
http://web.site/?a=1&a=2&a=3
http://web.site/?a[0]=1&a[0]=2&a[0]=3
http://web.site/?a=1&a[0]=2
The repetition creates an ambiguous value for the parameter. Should a be equal to 1, 2, or 3? The first value encountered or the last? Or an array of all values? How does the web server or the app’s programming language handle array subscripts (e.g. is a=1 equivalent to a[0]=1)?
This ambiguity may allow a hacker to bypass filters or detection mechanisms. For example, a filter might check the first instance of the parameter, but the app may use the value from the last instance of the parameter:
http://web.site/?s=something&s=”><img/src%3dx+onerror%3dalert(9)>
Another possibility is that the server concatenates the parameters, turning two innocuous values into a working exploit:
http://web.site/?s=”><img+&s=+src%3dx+onerror%3dalert(9)>
This type of ambiguity in parameter values is not specific to web applications. For example, the g++ compiler warns of these kinds of “shadow” variables. The following code demonstrates this programming error:
int f(int a) {
int a = 3;
return a;
}
int main(int argc, const char ∗argv[]) {
return f(3);
}
And the warning generated by the compiler:
$ g++ -o main shadow.cc
shadow.cc: In function ‘int f(int)’:
shadow.cc:5: error: declaration of ‘int a’ shadows a parameter
Web application security circles have labeled this type of problem HTTP Parameter Pollution or Value Shadowing.
PHP has historically had a similar problem related to its “superglobals” array. This is one reason why the register_globals setting was deprecated in the June 2009 release of PHP 5.3.0. In fact, the superglobals had been a known security issue for several years before that. Any PHP site that relies on this behavior is asking for trouble. More background on superglobals is available at http://www.php.net/manual/en/security.globals.php.
Insufficient Authorization Verification
Our first encounter with authorization in this book was in Chapter 5, which addressed the theme more in terms of sniffing authentication tokens and account impersonation. Each action a user may take on a web site must be validated against a privilege table to make sure the user is allowed to perform the action. An authorization check might be performed at the beginning of a process, but omitted at later steps under the assumption that the process may only start at step one. If some state mechanism permits a user to start a process at step two, then authorization checks may not be adequately performed.
Closely related to authorization problems are incorrect privilege assignments. A user might have conflicting levels of access or be able to escalate a privilege level by spoofing a cookie value or flipping a cookie value. Privilege tables that must track more than a few items quickly become complex to implement and therefore difficult to verify.
Inadequate Data Sanitization
Some filters attempt to remove strings that match a blacklist. For example, the filter might look strip any occurrence of the word “script” in order to prevent cross-site scripting exploits that attempt to create <script> elements. In other cases a filter might strip SQL-related words like “SELECT” or “UNION” with the idea that even if a SQL injection vulnerability is discovered and attacker would be unable to fully exploit it. These are poor countermeasures to begin with—blocking exploits has a very different effect than fixing vulnerabilities. It’s much better to address the vulnerabilities than trying to outsmart a determined attacker.
Let’s look at the other problems with sanitizing data. Imagine that “script” is stripped from all input. The following payload demonstrates how an attacker might abuse such simple logic. The payload contains the blacklisted word.
/?param=”%3c%3cscripscriptt+src%3d/site/a.js%3e
The filter naively removes one “script” from the payload, leaving a hole between “scrip” and “t” that reforms the blacklisted word. Thus, one pass removes the prohibited word, but leaves another. This approach fails to recursively apply the blacklist.
Commingling Data & Code
Grammar injection is an umbrella term for attacks like SQL injection and cross-site scripting (XSS). These attacks work because the characters present in the data are misinterpreted as control elements of a command. Such attacks are not limited to SQL statements and HTML.
• Apache Struts 2 passed cookie names through a parser that supports the getting/setting properties and executing methods within Java. This effectively turned the cookie name into an arbitrary code execution vector. (https://www.sec-consult.com/files/20120104-0_Apache_Struts2_Multiple_Critical_Vulnerabilities.txt).
• Poor JSON parsers might execute JavaScript from a malicious payload. Parsers that use eval() to extract JSON or mash-ups that share data and functions expose themselves to vulnerabilities if JavaScript content isn’t correctly scrubbed.
• XPATH injection targets XML-based content (http://www.packetstormsecurity.org/papers/bypass/Blind_XPath_Injection_20040518.pdf).
• LDAP queries can be subject to injection attacks (http://www.blackhat.com/presentations/bh-europe-08/Alonso-Parada/Whitepaper/bh-eu-08-alonso-parada-WP.pdf).
A common trait among these attacks is that the vulnerability arises due to piecing data (the content to be searched) and code (the grammar of that defines how the search is to be made) together in a single string without clear delineation between the two.
Incorrect Normalization & Synonymous Syntax
Chapter 2 discussed the importance of normalizing data before applying validation routines in order to prevent HTML injection (also known as cross-site scripting, or XSS). Such problems are not limited to the realm of XSS. SQL injection exploits target decoding, encoding, or character set issues specific to databases and the SQL language—including vendor-specific dialects—rather than the application’s programming language. A similar problem holds true for strings that contain %00 (NULL) values that are interpreted differently between the web application and the operating system.
A missed equivalency is a character or characters with synonymous meanings but different representations. This is another area where normalization can fail because a string might be reduced to its syntactic basis (characters decoded, acceptable characters verified), but have a semantic meaning that bypasses a security check. For example, there are many different ways of referencing the /etc/hosts file on a UNIX-based system as shown by the following strings.
/etc/hosts
/etc/./hosts
../../../../../../../../etc/hosts
/tmp/../etc/hosts
Characters used in cross-site scripting or SQL injection might have identical semantic meanings with blacklisted values. In Chapter 3: SQL Injection we covered various methods of obfuscating a SQL statement. As a reminder, here are two ways of separating SQL commands:
UNION SELECT
UNION/∗∗/SELECT
Cross-site scripting opens many more possibilities because of the powerfully expressive nature of JavaScript and the complexity of parsing HTML. Here are some examples of different XSS attacks that avoid more common components like <script> or using “javascript” within the payload.
<img src=a:alert(alt) onerror=eval(src) alt=no_quotes>
<img src=a:with(document)alert(cookie) onerror=eval(src)>
To demonstrate the full power of JavaScript, along with its potential for inscrutable code, try to understand how the following code works, which isn’t nearly as obfuscated as it could be.6
<script>
_=’’
__=_+’e’+’val’
$$=_+’aler’+’t’
a=1+[]
a=this[__]
b=a($$+’(/hi/.source)’)
</script>
Normalization is a necessary part of any validation filter. Semantic equivalencies are often overlooked. These issues also apply to monitoring and intrusion detection systems. The site may be lulled into a false sense of security if the web application firewall or network monitor fails to trigger on attacks that have been obfuscated.
Unhandled State Transitions
The abundance of JavaScript libraries and browser-heavy applications has given rise to applications with complex states. This complexity doesn’t always adversely affect the application since the browser is well-suited to creating a user experience that mimics a desktop application. On the other hand, maintaining a workflow’s state solely within the client can lead to logic-based issues in the overall application. The client must be considered an active adversary. The server cannot assume that requests should be performed sequentially or that are not supposed to be repeated will not arrive from the browser.
There are many examples of state mechanisms across a variety of applications. There are equally many ways of abusing poor state handlers. A step might be repeated to the attacker’s advantage, such as applying a coupon code more than once. A step might be repeated in order to cause an error, crash, or data corruption in the site, such as deleting an e-mail message more than once. In other cases a step might be repeated to a degree that it causes a denial of service, such as sending thousands of e-mails to thousands of recipients. Another tack might involve skipping a step in the workflow in order to bypass a security mechanism or rate limiting policy.
Client-side Confidence
Client-side validation is a performance decision, not a security one. A mantra repeated throughout this book is that the client is not to be trusted. Logic-based attacks, more so than other exploits, look very similar to legitimate traffic; it’s hard to tell friend and foe apart on the web. Client-side routines are trivially bypassed. Unless the validation routine is matched by a server-side function the validation serves no purpose other than to take up CPU cycles in the web browser.
Implementation Errors in Cryptography
We take a slight turn from design to implementation mistakes in this section. Primarily because web developers should not be designing encryption algorithms or cryptographically secure hash functions. Instead, they should be using well-established algorithms that have been tested by people for more familiar with cryptographic principles. However, it’s still possible to misuse or misunderstand encryption. The following sections elaborate the consequences of such mistakes.
Insufficient Randomness
Many cryptographic algorithms rely on strong pseudo-random numbers to operate securely. Any good library that provides encryption and hashing algorithms will also provide guidance on generating random numbers. Follow those guidelines.
A common mistake regarding the generation of random numbers (i.e. generating entropy) is conflating the amount of bits with the predictability of bits. For example, a 32-bit integer generated by a system’s rand() function that is subsequently hashed by SHA-256 to generate a 256-bit value has not become “more random.” The source of entropy remains only as good as the source used by rand() to create the initial integer. Assuming the 32-bit integer is uniformly distributed across the possible range, then an attacker needs to target a 32-bit space, not a 256-bit space.
The other mistake related to random numbers is how they are seeded. The aforementioned rand() function is seeded with the srand() function, as shown in the following code:
#include <iostream>
using namespace std;
int main(int argc, char ∗argv[]){
srand(1);
cout << rand() << endl;
}
Every execution of the previous code will generate the same value because the seed is static. A static seed is the worst case, but other cases are not much better. Seeds that are timestamps (seconds or milliseconds), IP addresses, port numbers, or process IDs are equally bad. In each case the space of possible values falls into a reasonable range. Port numbers, for example, are ostensibly 16-bit values, but in practice usually fall into a range of a few hundred possibilities. IP addresses might be 32-bit values, but smart guesswork can narrow the probable range to as narrow as 8 bits for a known class C network.
In short, follow the library’s recommended pseudo-random number generator (PRNG). An example of a strong PRNG is ISAAC (http://burtleburtle.net/bob/rand/isaacafa.html). Programs like OpenSSL (http://openssl.org/) and GnuTLS (http://www.gnu.org/software/gnutls/) have their own generators, which may serve as good reference implementations. Finally, documentation on recommended standards is available at http://csrc.nist.gov/groups/STM/cavp/index.html (refer to the RNG and DRBG sections).
Epic Fail
A infamous example of this mistake is the Debian OpenSSL md_rand.c bug. Briefly, a developer removed code that had been causing warnings from profiling tools intended to evaluate the correctness of code. The modification severely weakened the underlying PRNG used to generate SSL and SSH keys. A good starting point for reading more about this flaw is athttp://digitaloffense.net/tools/debian-openssl/.
XOR
“There is nothing more dangerous than security.” Francis Walsingham.7
As humans, we love gossip as much as we love secrets. (It’s not clear what computers love, since we’ve had telling lessons from the likes of Orac, Hal, and Skynet.) In web applications, the best way to keep data secret is to encrypt it. At first glance, encryption seems a straightforward concept: apply some transmutation function to plaintext input to obtain a ciphertext output. Ideally, the transmutation will increase the diffusion (hide statistical properties of the input) and confusion (require immense computational power even if statistical properties of the input are known) associated with the ciphertext in order to make it infeasible to decrypt.8
Encryption has appeared throughout history, from the Roman Empire, to Elizabethan England (under the spy master Francis Walsingham), to literary curiosities like Edgar Allan Poe’s 1843 short story The Gold Bug (also a snapshot of America’s social history). There is an allure to the world of secrets, spies, and cryptography. Alas, there is also a vast expanse of minefields in terms of using cryptographic algorithms correctly.
Our attention first turns to one of the older forms of encryption, the XOR cipher. It is provably secure, in a mathematical sense, when implemented as a one-time pad (OTP). On the other hand, it is inexcusably insecure when misused. If the hacker can influence the plaintext to be encrypted, then it’s possible to determine the length of the key. The following hexdump shows the result of xor-ing AAAAAAAAAAAAAAAA with an unknown key. The plaintext has a regular pattern (all one letter). The ciphertext has a suspicious repeating pattern, indicating that the key was probably four characters long:
20232225202322252023222520232225
The repeated pattern is similar to the behavior exhibited by the electronic code book (ECB) encryption mode of block ciphers. Basically, each block of plaintext is processed independent of any other block. This means that the same plaintexts always encrypt to the same ciphertexts regardless of previous input. We’ll examine why this is undesirable behavior in a moment.
Warning
Encrypted content (ciphertexts) often contain 8-bit values that are not “web safe” (i.e. neither printable ASCII nor UTF-8 characters). Therefore, they are usually encoded in base64 in order to be used as cookie values, etc. As a first step to analyzing a ciphertext, make sure you’re working with its correct representation and not its base64 version.
Another interesting aspect of xor encryption is that the xor of two ciphertexts equals the xor of their original plaintexts. Table 6.1 shows the inter-relationship between plaintexts and ciphertexts. The key used to generate the ciphertext is unknown at the moment.
Table 6.1 Comparing the XOR for Plaintext and Ciphertext Messages
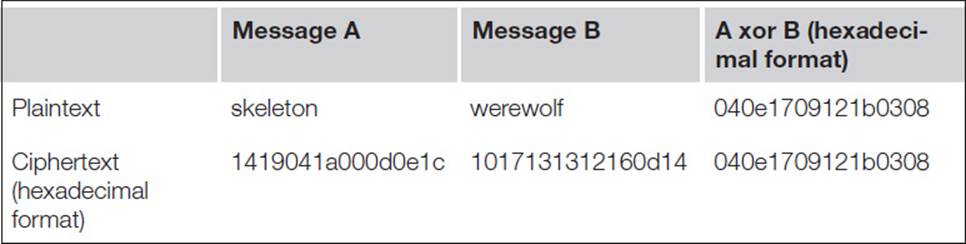
Table 6.1 demonstrated the symmetry between input and output for xor operations. At this point a perceptive reader might realize how to obtain the key used to generate the table’s ciphertexts. Before we reveal the trick, let’s examine some more aspects of this encryption method. Table 6.1demonstrates a known plaintext attack: the hacker is able to obtain the original message and its encrypted output. Before that we used a chosen plaintext attack to determine the length of the encryption key by submitting a sequence of uniform characters and looking for subsequent patterns in the result.
Some useful analysis can still be applied if only the encrypted output (i.e. ciphertext) is available. For example, imagine we have encountered the following ciphertext (converted to hexadecimal format):
210000180e1c0f0110021b0f5612181252100f1741120a1a151d16.
The first clue is that the second and third bytes are 00. This indicates that these two bytes of the plaintext exactly match two bytes from the secret key. A value xor’ed with itself is always zero, e.g. 19 xor 19 = 0. (Conversely, a value xor’ed with zero is unchanged, e.g. 19 xor 0 = 19. So another chosen plaintext attack would be to inject a long sequence of NULL bytes, e.g. %00%00%00%00, in order to reveal the original key.)
The second trick is to start shifting the ciphertext byte by byte and xor’ing it with itself to look for patterns that help indicate the key’s length. The goal is to shift the ciphertext by the length of the key, then xor the shifted ciphertext with the unshifted ciphertext. This is more useful for long sequences. In our example, we have determined that the key length is eight bytes. So we shift the ciphertext and examine the result, as in the following code:
210000180e1c0f0110021b0f5612181252100f1741120a1a151d16 xor
10021b0f5612181252100f1741120a1a151d16 =
321708004b120f005411010b00130e10
The 00 bytes indicate that two plaintext values have been xor’ed with each other. This information can help with making intelligent brute force attacks or conducting frequency analysis of the encrypted output.
Warning
Encrypted content in web applications usually appears in cookies, hidden form fields, or query string parameters. The length of the ciphertext is typically too short to effectively apply frequency analysis. However, the topic is interesting and fundamental to breaking certain types of ciphers. For more background on applications of frequency analysis check out Simon Singh’s Black Chamber athttp://www.simonsingh.net/The_Black_Chamber/crackingsubstitution.html.
It’s possible to analyze XOR-based encryption using JavaScript. The examples in this section relied on the Stanford JavaScript Crypto Library (http://crypto.stanford.edu/sjcl/). The following code demonstrates one way to leverage the library. You’ll need the core sjcl.js and bitArray.js files.
<script src=”sjcl.js”></script>
<script src=”bitArray.js”></script>
<script>
function xor(key, msg) {
var ba = sjcl.bitArray;
var xor = ba._xor4;
var keyLength = sjcl.bitArray.bitLength(key);
var msgLength = sjcl.bitArray.bitLength(msg);
var c = [];
var slice = null;
for(var i = 0; i < msgLength; i += keyLength) {
slice = sjcl.bitArray.bitSlice(msg, i);
slice = xor(key, slice);
var win = msgLength - i;
var bits = win > keyLength ? keyLength : win;
c = sjcl.bitArray.concat(c, sjcl.bitArray.bitSlice(slice, 0, bits));
}
return c;
}
var key = sjcl.codec.utf8String.toBits(“???”);
var msgA = sjcl.codec.utf8String.toBits(“skeleton”);
var msgB = sjcl.codec.utf8String.toBits(“werewolf”);
var ciphA = xor(key, msgA);
var ciphB = xor(key, msgB);
var xorPlaintexts = xor(msgA, msgB);
var xorCiphertexts = xor(ciphA, ciphB);
/∗ use sjcl.codec.hex.fromBits(x) to convert a bitArray to hexadecimal format,
e.g. sjcl.codec.hex.fromBits(ciphA) ∗/
</script>
Use the previous code to figure out the secret key used to generate the ciphertext in Table 6.1.
Attacking Encryption with Replay & Bit-Flipping
Attacks against encrypted content (cookies, parameter values, etc.) are not limited to attempts to decrypt or brute force them. The previous section discussed attacks against xor (and, by extension, certain encryption modes of block-based algorithms) that try to elicit information about the secret key or how to obtain the original plaintext. This section switches to techniques that manipulate encrypted content rather than try to decipher it.
Replay attacks work on the premise that an encrypted value is stateless—the web application will use the value regardless of when it is received. We’ve already seen replay attacks in Chapter 5 related to authentication cookies. If a hacker obtains another user’s cookie through sniffing or some other means, then the hacker can replay the cookie in order to impersonate the victim. In this case, the cookie’s value may merely be a pseudo-random number that points to a server-side record of the user. Regardless of the cookie’s content, it represents a unique identifier for a user. Any time the site receives a request with that cookie, it assumes it’s working within a particular user’s context.
For example, here’s an encrypted authentication cookie encoded with base64:
2IHPGHoYAYQKpLjdYsiIuE6WHewHKRniWfml8F0BMYf2AWY0ogWBwrRFxYk1%2bxkQ
K%2bvj%2b9SWpKFHxsCAEbZ7Fg%3d%3d
Replaying this cookie would enable the hacker to impersonate the user. It’s not necessary to decrypt or otherwise care about the cookie’s value. The server receives it, decrypts it, extracts the user data, and carries on based on the user defined in the cookie. The hacker didn’t even need to guess a password. (See Chapter 5 for more details on using sniffers to obtain cookies.)
Bit-flipping attacks work with the premise that changing a bit in the encrypted ciphertext changes the plaintext. It’s not possible to predict what the modified plaintext will look like, but that doesn’t prevent the hacker from testing different bits to observe the effect on the web app. Let’s return to the previous authentication cookie. The following shows its hexadecimal format after being decoded from base64. (The output is obtained with the handy xxd command.):
0000000: d881 cf18 7a18 0184 0aa4 b8dd 62c8 88b8 ....z.......b...
0000010: 4e96 1dec 0729 19e2 59f9 a5f0 5d01 3187 N....)..Y...].1.
0000020: f601 6634 a205 81c2 b445 c589 35fb 1910 ..f4.....E..5...
In this scenario, the web site has a welcome page for authenticated users. When this cookie is submitted, the site responds with, “Hello Mike” along with a profile that shows the email address as “mike@deadliestwebattacks.com.” Now we flip a single bit by changing the leading d881 toe881. The cookie is converted back to binary, encoded with base64, and re-submitted to the web site. The following command shows how to handle the conversion and encoding with xxd and openssl:
$ xxd -r cookie.hex > cookie.bin
$ openssl enc -base64 -in cookie.bin -out cookie.base64
$ cat cookie.base64
6IHPGHoYAYQKpLjdYsiIt06WHewHKRniWfml8F0BMYf2AWY0ogWBwrRFxYk1+xkQ
K+vj+9SWpKFHxsCAEbZ7Fg==
The next step is to submit the new cookie to the web site. In this case, the site responds with an error (such as reporting an explicit “Invalid cookie” or returning to the login page). The error response indicates the cookie was decrypted, but the decrypted string was too corrupted to be used as an identifier. This modified cookie hasn’t succeeded in impersonating someone else or changing our privileges with this site. Nevertheless, the error provides useful information. It enables us to start a series of probes that change different bits in order to find a change that the site accepts.
Block-based ciphers work on block sizes based on powers of two. Notice that the only assumption we’ve made so far is that a block cipher encrypted the cookie. It could be DES, although even Triple DES is discouraged by now. AES is a good guess, although we don’t know whether its AES-128, -192, or -256. And for now we don’t care. For the moment we’re interested in flipping ciphertext bits in a way that doesn’t generate an error in the web site. Going back to the power of two block size, we try a new modification as shown in the leading byte at offset 0×10 below:
0000010: 4e96 1dec 0729 19e2 59f9 a5f0 5d01 3187 N....)..Y...].1.
0000010: 5e96 1dec 0729 19e2 59f9 a5f0 5d01 3187 N....)..Y...].1.
The site responds differently in this case. We receive the message, “Hello Mike”—which indicates we didn’t change a value that affects the name tracked in the cookie. However, the email address for this profile now looks like “mike@Y.” This curious change hints that we’ve modified a bit that affected a different block than the one that contains the user name.
From here on the attack may take several paths depending on how the site responds to bit changes in the cookie. This becomes a brute force test of different values that seeks anomalies in the site’s response. The cookie (or whatever value is being tested) may elicit the welcome page, an error page, a SQL error due to a badly formatted email address, or even access to another user’s account.
Note
A 2001 paper by Kevin Fu, Emil Sit, Kendra Smith, and Nick Feamster titled, “Do’s and Don’ts of Client Authentication on the Web,” describes an excellent analysis of poor encryption applied to cookies (http://cookies.lcs.mit.edu/pubs/webauth:tr.pdf). Don’t dismiss the paper’s age; its techniques and insight are applicable to modern web sites.
A worst-case scenario for encrypted content is when content can be cut-and-pasted from one ciphertext to another. The following example highlights the problem of using ECB encryption mode to protect a cookie. Consider a cookie whose decrypted format looks like the following, a username, user ID, email address, and a timestamp:
Mike|24601|mike@deadlestwebattacks.com|1328810156
The encrypted value of the cookie looks this when passed through xxd.
0000000: 38f1 cac7 0174 fde5 f0a8 66f2 cc67 e37e 8....t....f..g.∼
0000010: 2aec 1d76 9d5d a765 8e8c 6ac2 88d6 b02e ∗..v.].e..j.....
0000020: 86b6 dc2d 0e88 4867 2501 49c6 f18c dcd0 ...-..Hg%.I.....
0000030: 1899 d2f2 7240 5574 9071 de3f 3cd8 633a ....r@Ut.q.?<.c:
Next, a hacker creates an account on the site, setting up a profile that ends up in a cookie with the decrypted format of:
ekiM|12345|mike@evil.site|1328818078
The corresponding ciphertext looks like this with xxd:
0000000: ca3d 866f 927f da5c 7564 5c80 44ea d5b7 .=.o...\ud\.D...
0000010: 35c2 1d40 c0ea 22dd 026d 91d6 1e34 60c1 5..@..”..m...4‘.
0000020: d44d b7f1 d4f9 f943 b6eb 2923 99d6 f98e .M.....C..)#....
Check out the effect of mixing these ciphertexts. We’ll preserve the initial 16 bytes from the first user (with user ID 24601). Then append all but the initial 16 bytes from the second user (with user ID 12345).
0000010: 38f1 cac7 0174 fde5 f0a8 66f2 cc67 e37e 8....t....f..g.∼
0000020: 35c2 1d40 c0ea 22dd 026d 91d6 1e34 60c1 5..@..”..m...4‘.
0000030: d44d b7f1 d4f9 f943 b6eb 2923 99d6 f98e .M.....C..)#....
The server decrypts to a plaintext that is a hybrid of the two cookies. The first 8 characters are decrypted from the first 16 bytes of ciphertext. Thus, the correspond to the first 8 characters to that user’s cookie value. The remaining characters come from the hacker’s ciphertext cookie.
Mike|24601|mike@evil.site|1328818078
This example was designed so that the email address fell nicely across an AES block (i.e. 128 bits, 16 bytes). While somewhat contrived, it illustrates the peril of using an encryption scheme like XOR or AES in ECB mode. Instead of changing an email address, this type of hack has the potential to change a user ID, authorization setting, or similar. The situations where this appears may be few and far between, but it’s important to be aware of how encryption is misused and abused.
Message Authentication Code Length-Extension Attacks
Web developers know not to trust that data received from the client has not been tampered with. Just because the app sets a cookie like “admin=false” doesn’t mean the sneaky human behind the browser won’t switch the cookie to “admin=true.” However, the nature of web applications requires that sites share data or expose functions whose use must be restricted. One mechanism for detecting the tampering of data is to include a token that is based on the content of the message to be preserved along with a secret known only to the web application. The message is shared with the browser so its exposure should have no negative effect on the token. The secret stays on the server where the client cannot access its value. Using a cryptographic hashing algorithm to generate a token from a message and a secret is the basis of a message authentication code(MAC).
Before we dive into the design problems of a poorly implemented MAC, let’s examine why relying on the hash of a message (without a secret) is going to fail. First, we need a message. The following code shows our message and its SHA-1 hash as calculated by the shasum command line tool:
echo -n “The family of Dashwood had long been settled in Sussex.” | shasum -a1 -
3b97b55f1b05dd7744b1ca61f1e53fc0e06d5339
The content of this message might be important for many reasons: Jane Austen could be sending the first line of her new novel to an editor, or a spy may be using the location as the indicator of a secret meeting place. The sender wants to ensure that the message is not modified in transit, so she sends the hash along with the message:
http://web.site/chat?msg=...Sussex&token=3b97b55f1b05dd7744b1ca61f1e53fc0e06d5339
The recipient compares the message to the token. If they match, then nothing suspicious has happened in transit. For example, someone might try to change the location, which would result in a different SHA-1 hash:
echo -n “The family of Dashwood had long been settled in London.” | shasum -a1 -
0847d8016d4c0b9e0182b443c5b891d098f2a961
A quick comparison confirms that the “Sussex” version of the message does not produce the same hash as one that refers to “London” instead. Sadly, there’s an obvious flaw in this protocol: the message and token are sent together. There’s nothing to prevent an intermediary (a jealous peer or a counterspy) to change both the message and its token. The recipient will be none the wiser to the switch:
http://web.site/chat?msg=...London&token=0847d8016d4c0b9e0182b443c5b891d098f2a961
If we include a secret key, then the hash (now officially a MAC) becomes more difficult to forge. The following code shows the derivation of the MAC. The secret is just a sequence of characters placed before the message. Then the hash of the secret concatenated with the message is taken:
echo -n “_________The family of Dashwood had long been settled in Sussex.” | shasum -a1 -
d9aaa02c380ab7b5321a7400ae13d2ca717122ae
Next, the sender transmits the message along with the MAC.
http://web.site/chat?msg=...Sussex&token=d9aaa02c380ab7b5321a7400ae13d2ca717122ae
Without knowing the secret, it should be impossible (or, more accurately speaking, computationally infeasible) for anyone to modify the message and generate a valid hash. We’ve assumed that the sender and recipient share knowledge of the secret, but no one else does. Our intercepting agent can still try to forge a message, but is relying on luck to generate a valid MAC as shown in the following attempts:
echo -n “secretThe family of Dashwood had long been settled in Sussex.” | shasum -a1 -
7649f80b4a2db8d8494aba5091a1de860573a87c
echo -n “JaneAustenThe family of Dashwood had long been settled in Sussex.” | shasum -a1 -
5751e9be0bb8fcfae9d7bf0a9c509821e7337af8
echo -n “abcdefghiThe family of Dashwood had long been settled in Sussex.” | shasum -a1 -
ee45cc7f86a16fcbbadc6afe2c76b1ccb1eb20a2
The naive hacker will either try to brute force the secret or give up. A more crafty hacker will resort to a length extension attack that only requires guessing the number of characters in the secret rather than guessing its value. We can illustrate this relatively simple hack using JavaScript and cryptographic functions from the Stanford JavaScript Crypto Library (http://crypto.stanford.edu/sjcl/). You will need the library’s core sjcl.js file and the sha1.js file, which is not part of the default library.
We’ll start with a message and its corresponding MAC. The secret is, well, kept secret because its value needn’t be known for this attack to work:
<script src=”sjcl.js”></script>
<script src=”sha1.js”></script>
<script>
/∗ The MAC is obtained by concatenating the secret and msg, then calculating the SHA-1 hash.
The following value is obtained by the function sjcl.hash.sha1.hash(secret + msg).
Only the message and the MAC are known to the hacker. ∗/
var msg = “Jane Austen wrote Sense and Sensibility.”;
var macAsHex = “f168dbe422860660509801146c137aee116cb5b8”;
</script>
Cryptographic hashing algorithms like MD5 and the SHA family operate on blocks of data, passing each block through a set of operations until the entire message has been consumed. SHA-1 starts with a fixed Initialization Vector (IV) and operates on 512 bit blocks to produce a 160 bit output. The final block of data is padded with a one bit (1) followed by zeros up to the last 64 bits, which contain the length of the data. Figure 6.1 shows the five 32-bit values that comprise the IV and how the secret plus the message are placed in a block. In this example, the complete message fits within a single 512 bit block.
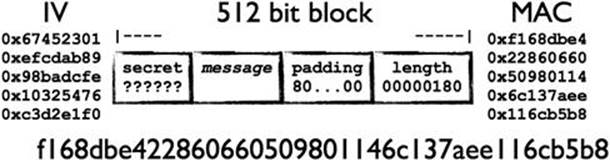
Figure 6.1 Contents of a Single Round MAC
Our goal is to modify the message and fix the MAC so tampering isn’t detected. We don’t know the secret, but we know the original message and its MAC. We also know that, if the SHA-1 operation were to continue onto a new block of data, then the output of the previous block would serve as the input to the current block—this is the IV, if you recall. The first block has no previous output, so its IV is fixed. In our example, the final hash is f168dbe422860660509801146c137aee116cb5b8.
We wish to append “and Rebecca” to the original message in order to trick the server into accepting incorrect data. In order to do this, we start a new SHA-1 operation. Normally, this requires starting with the five 32-bit values of IV defined by the algorithm: {0x67452301, 0xefcdab89, 0x98badcfe, 0x10325476, 0xc3d2e1f0}. Then padding out the message, inserting its length in the last 64 bits of the block, and producing the final hash—another five 32-bit values (for a 160 bit output).
To apply the length extension attack, we start with an IV of the original message’s MAC, in this case the five 32-bit words {f168dbe4, 0x22860660, 0x50980114, 0x6c137aee, 0x116cb5b8}. Then we apply the SHA-1 operations as normal to our message, “and Rebecca,” in order to produce a new output: da699b87a92c833c67a7f3cdfe90af29f7e695ee. (As a point of comparison, the correct SHA-1 hash of the message, “and Rebecca” is 99d38d3e32ac99897b36bfbb46ec432187d0cd5a. We have created a different value on purpose.)
The final step to this attack is reverse engineering the padding of the original message’s block. This means we need to guess how long the secret was, append a one bit the message, append zeros, then append the 64-bit length that we guessed. Figure 6.2 shows how this would become the IV of the next block of data if we were to extend the message with the words “and Rebecca.” Note that the first block is in fact part of the message; the padding and length (0×180 bits) have been artificially added. The message only uses 96 bits of the second block, but the full length of the message is 512 +96 bits, or 0×260 as seen in the length field at the end of the second block.
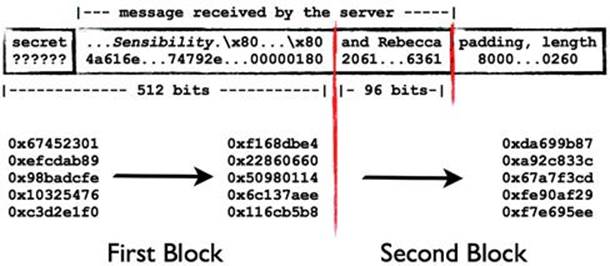
Figure 6.2 Second Round MAC Takes the Previous Round’s Output
What we have done is created a full 512-bit block of the original message, its padding, and length, and extended our message into a subsequent block. The sever is expected to fill in the beginning of the first block with the unknown (to us) value of the secret. The URL-encoded version of the spoofed message appears in the code block below. Note how the original message has been extended with “and Rebecca.” The catch is that it was also necessary to insert bits for padding of length of the original 512-bit block; those are the %80%00...%01%80 characters. If we submitted this message along with the MAC of da699b87a92c833c67a7f3cdfe90af29f7e695ee, the server would calculate the same MAC based on its knowledge of the secret.
Jane%20Austen%20wrote%20Sense%20and%20Sensibility.%80%00%00%00%00%00%00%00%00%00%00%00%00%00%01%80%20and%20Rebecca
The following JavaScript walks through this process. The easiest step is extending the MAC with an arbitrary message. The key points are that the “old” MAC is used as the IV and the length of the new message must include the “previous” 512 bit block:
<script src=”sjcl.js”></script>
<script src=”sha1.js”></script>
<script>
var msg = “Jane Austen wrote Sense and Sensibility.”;
var macAsHex = “f168dbe422860660509801146c137aee116cb5b8”;
var mac = sjcl.codec.hex.toBits(macAsHex);
var extendedMsg = sjcl.codec.utf8String.toBits(“and Rebecca”);
/∗ establish a new IV based on the MAC to be extended ∗/
sjcl.hash.sha1.prototype._init = mac;
/∗ create a new hashing object ∗/
var s = new sjcl.hash.sha1();
/∗ along with a new IV, the length of the message is considered
to already have at least 512 bits from the “previous” block ∗/
s._length += 512;
/∗ perform the usual SHA-1 operations with the modified IV and length ∗/
s.update(“and Rebecca”);
var newMAC = s.finalize();
/∗ da699b87a92c833c67a7f3cdfe90af29f7e695ee ∗/
var hex = sjcl.codec.hex.fromBits(newMAC)
/∗ the new MAC contained in the ‘hex’ variable can be sent to the
server to verify the new message. ∗/
</script>
Now that we have a new MAC we must generate the fully padded message to be sent to the server. Note that we’ve skipped over the steps of guessing the length of the server’s secret. This would be determined by trying different lengths and observing whether the server accepted or rejected the tampered message.
<script src=”sjcl.js”></script>
<script>
var secretBits = 64;
var msg = “Jane Austen wrote Sense and Sensibility.”;
var msgBits = msg.length ∗ 8 + secretBits;
var msgBitsHexString = msgBits.toString(16);
var paddingHexString = “8”;
var zeros = 512 - 8 - msgBits - (16 - msgBitsHexString.length);
for(var i = 0; i < zeros / 8; ++i) {
paddingHexString += “00”;
}
paddingHexString += msgBitsHexString;
var padding = sjcl.codec.hex.toBits(paddingHexString);
/∗ Hexadecimal representation of the 512 bit block
................ <-- secret inserted by the server
44617368776f6f64 {
4a616e6520417573
74656e2077726f74 message
652053656e736520
616e642053656e73
6962696c6974792e }
8000000000000000 <-- padding, binary “1” followed by “0”s
0000000000000180 <-- message length (384 bits)
∗/
</script>
Now that you’ve seen how trivial it is to extend a MAC,9 consider how the attack could be made more effective against web applications. For example, rather than appending random words a hacker could add HTML injection payloads like <script>alert(9)</script> or SQL injection payloads that extract database contents.
A more elegant example is the work published in September 2009 by Thai Duong and Juliano Rizzo against the hash signatures used to protect Flickr’s web API (http://netifera.com/research/flickr_api_signature_forgery.pdf).
The countermeasure to this type of attack is to employ a keyed MAC or a Hash-based MAC (HMAC). The sjcl JavaScript library used in this section provides a correct implementation of an HMAC. Most programming languages have libraries that provide the algorithms. As always, prefer the use of established, tested cryptographic routines rather than creating your own—even if you plan to develop against standards.
More information on HMAC can be found at http://csrc.nist.gov/publications/fips/fips198-1/FIPS-198-1_final.pdf and http://csrc.nist.gov/publications/nistpubs/800-107/NIST-SP-800-107.pdf.
Note
Hopefully these last few sections have whetted your appetite for cryptanalysis. A recent topic in web security has been the search for Padding Oracles. A clear explanation of this type of attack, along with its employment against web applications, can be found in the “Practical Padding Oracle Attacks” paper by Juliano Rizzo and Thai Duong (http://www.usenix.org/event/woot10/tech/full_papers/Rizzo.pdf). Another well-written reference is at http://www.isg.rhul.ac.uk/%7Ekp/padding.pdf. The references sections of the papers provide excellent departure points for more background on this technique. Make sure to set aside a good amount of free time to explore this further!
Information Sieves
Information leakage is not limited to indirect data such as error messages or timing related to the execution of different requests. Many web sites contain valuable information central to their purpose. The site may have e-mail, financial documents, business relationships, customer data, or other items that have value not only to the person that placed it in the site, but to competitors or others who would benefit from having the data.
• Do you own the data? Can it be reused by the site or others? In July 2009 Facebook infamously exposed users’ photos by placing them in advertisements served to the user’s friends (http://www.theregister.co.uk/2009/07/28/facebook_photo_privacy/). The ads’ behavior violated Facebook’s policies, but represented yet another reminder that it is nearly impossible to restrict and control information placed on the web.
• How long will the data persist? Must data be retained for a specific time period due to regulations? An interesting example of this was the January 2012 shutdown of the Megaupload web site by US agents. The shutdown, initiated due to alleged copyright infringement, affected all users and their data—personal documents, photos, etc.—stored on Megaupload servers (http://www.theregister.co.uk/2012/01/30/megaupload_users_to_lose_data/).
• Can you delete the data? Does disabling your account remove your information from the web site or merely make it dormant?
• Is your information private? Does the web site analyze or use your data for any purpose?
These questions lead to more issues that we’ll discuss in Chapter 7: Web of Distrust.
Employing Countermeasures
Even though attacks against the business logic of a web site varies as much as the logic does among different web sites, there are some fundamental steps that developers can take to prevent these vulnerabilities from cropping up or at least mitigate the impact of those that do. Take note that many of these countermeasures focus on the larger view of the web application. Many of the steps require code, but the application as a whole must be considered—including what type of application it is and how it is expected to be used.
Documenting Requirements
This is the first time that the documentation phase of a software project has been mentioned within a countermeasure. All stages of the development process, from concept to deployment, influence a site’s security. Good documentation of requirements and how features should be implemented bear significant aid toward identifying the potential for logic-based attacks. Requirements define what users should be able to do within an application. Requirements are translated into specific features along with implementation details that guide the developers.
Careful review of a site’s workflows will elicit what-if questions, e.g. what if a user clicks on link C before link B or submits the same form multiple times or tries to upload a file type that isn’t permitted? These questions need to be asked and answered in terms of threats to the application and risks to the site or user information if a piece of business logic fails. Attackers do not interact with sites in the way users are “supposed to.” Documentation should clearly define how a feature should respond to users who make mistakes or enters a workflow out of order. A security review should look at the same documentation with an eye for an adversarial opponent looking for loopholes that allow requirements to be bypassed.
Creating Robust Test Cases
Once a feature is implemented it may be passed off to a quality assurance team or run through a series of regression tests. This type of testing typically focuses on concepts like acceptance testing. Acceptance testing ensures that a feature works the way it was intended. The test scenarios arise from discussions with developers and reflect how something is supposed to work. These tests usually focus on discrete parts of a web site and assume a particular state going into or out of the test. Many logic-based attacks build on effects that arise from the combination of improper use of different functions. They are not likely to be detected at this phase unless or until a large suite of tests start exercising large areas of the site.
A suite of security tests should be an explicit area of testing. The easier tests to create deal with validating input filters or displaying user-supplied data. Such tests can focus on syntax issues like characters or encoding. Other tests should also be created that inject unexpected characters or use an invalid session state. Tests with intentionally bad data help determine if an area of the web site fails secure. The concept of failing secure means that an error causes a function to fall back to a lower privilege state, for example actively invalidating a session, forcibly logging out the user, or reverting to the initial state of a user who has just logged into the site. The goal of failing secure is to ensure the web application does not confuse errors with missing information or otherwise ignores the result of a previous step when entering a new state.
Throughout this chapter we’ve hesitated to outline specific checklists in order to emphasize how many logic attacks are unique to the affected web site. Nevertheless, adhering to good design principles will always benefit a site’s security, either through proactive defenses or enabling quick fixes because the code base is well maintained. Books like Writing Secure Code by Michael Howard and David LeBlanc cover design principles that apply to all software development from desktop applications to web sites.
Security Testing
This recommendation applies to the site’s security in general, but is extremely important for quashing logic-based vulnerabilities. Engage in full-knowledge tests as well as blackbox testing. Blackbox testing refers to a browser-based view of the web site by someone without access to the site’s source code or any significant level of knowledge about the application’s internals. Automated tools excel at this step; they require little human intervention and may run continuously. However, blackbox testing may fail to find a logic-based vulnerability because a loophole isn’t exposed or observable to the tester. Full-knowledge tests require more time and more experienced testers, which translates to more expensive effort conducted less often. Nevertheless, security-focused tests are the only way to proactively identify logic-based vulnerabilities. The other options are to run the site in ignorance while attackers extract data or wait for a call from a journalist asking for confirmation regarding a compromise.
The OWASP Testing Guide is a good resource for reviewing web site security (https://www.owasp.org/index.php/OWASP_Testing_Project). The guide has a section on business logic tests as well as recommendations for testing other components of a web application.
Note
Although we’ve emphasized that automation is not likely to independently discover a logic-based vulnerability that doesn’t mean that attackers only exploit vulnerabilities with manual attacks. After a vulnerability has been identified it’s trivial for an attacker to automate an exploit.
Learning From Mistakes
Analyze past attacks, successful or not, to identify common patterns or behaviors that tend to indicate fraud. This is another recommendation to approach with caution. A narrow focus on what you know (or can discern) from log files can induce a myopia that only looks for attacks that have occurred in the past that will miss novel, vastly different attacks of the future. Focusing on how attackers probe a site looking for SQL injection vulnerabilities could help discover similar invalid input attacks like cross-site scripting, but it’s not going to reveal a brute force attack against a login page. Still, web sites generate huge amounts of log data. Some sites spend time and effort analyzing data to determine trends that affect usage, page views, or purchases. With the right perspective, the same data may lead to identifying fraud and other types of attacks.
Mapping Policies to Controls
Policies define requirements. Controls enforce policies. The two are tightly coupled, but without well-defined policies developers may create insufficient controls or testing may fail to consider enough failure scenarios. Part of a high-level checklist for reviewing a site’s security is “specification auditing”—enumerating threats, then evaluating whether a code component addresses the threat and how well it mitigates a problem.10
Access control policies vary greatly depending on the type of web site to be protected. Some applications, web-based e-mail for one, are expected to be accessible at all hours of the day from any IP address. Other web sites may have usage profiles so that access may be limited by time of day, day of the week, or network location. Time can also be used as a delay mechanism. This is a different type of rate limiting that puts restrictions on the span between initiating an action and its execution.
Another type of control is to bring a human into the workflow. Particularly sensitive actions could require approval from another user. This approach doesn’t scale well, but a vigilant user may be more successful at identifying fraud or suspicious activity than automated monitors.
Defensive Programming
Identifying good code is a subjective endeavor prone to bias and prejudice. A Java developer might disparage C# as having reinvented the wheel. A Python developer might scoff at the unfettered mess of PHP. Ruby might be incomprehensible to a Perl developer. Regardless of one developer’s view (or a group of developers), each of the programming languages listed in this paragraph have been used successfully to build well-known, popular web sites. Opinions aside, good code can be found in any language.11 Well-written code is readable by another human being, functions can be readily understood by another programmer after a casual examination, and simple changes do not become Herculean tasks. At least, that’s what developers strive to attain. Vulnerabilities arise from poor code and diminish as code becomes cleaner.
Generate abstractions that enable developers to focus on the design of features rather than technical implementation details. Some programming languages lend themselves more easily to abstractions and rapid development, which is why they tend to be more popular for web sites or more accessible to beginning developers. All languages can be abstracted enough so that developers deal with application primitives like User or Security Context or Shopping Cart rather than creating a linked-list from scratch or using regular expressions to parse HTML.
Verifying the Client
There are many performance and usability benefits to pushing state handling and complex activities into the web browser. The reduced amount of HTTP traffic saves on bandwidth. The browser can emulate the look and feel of a desktop application. Regardless of how much application logic is moved into the browser, the server-side portion of the application must always verify state transitions and transactions. The web browser will prevent honest users from making mistakes, but it can do nothing to stop a determined attacker from bypass client-side security measures.
Encryption Guidelines
Using cryptography correctly deserves more instruction than these few paragraphs. The fundamental position on its use should be to defer to language libraries, crypto-specific system APIs, or well-respected Open Source libraries. An excellent example of the latter is Keyczar (http://www.keyczar.org/). Using these libraries doesn’t mean your code and data are secure; it means you’re using the correct building blocks for securing data. The details (and bugs!) come in the implementation.
• If you will be implementing encryption, use established algorithms from established libraries. If this chapter was your first exposure to the misuse of encryption, then you have a lot of reading ahead of you. Two good references for cryptographic principles and practices are Applied Cryptography: Protocols, Algorithms, and Source Code in C by Bruce Schneier and Cryptography Engineering: Design Principles and Practical Applications by Bruce Schneier, Niels Ferguson, and Tadayoshi Kohno.
• Use an HMAC to detect tampering of encrypted data. The .NET ViewState object is a good example of this concept (http://msdn.microsoft.com/en-us/library/ms972976.aspx). The ViewState may be plaintext, encrypted, or hashed in order to prevent the client from modifying it.
• Understand both the encryption algorithm and the mode used with the algorithm. The CBC and CTR modes for block ciphers are more secure than ECB mode. Documentation regarding the application of secure modes is available athttp://csrc.nist.gov/groups/ST/toolkit/BCM/current_modes.html.
• Do not report decryption errors to the client. This would allow a hacker to profile behavior related to manipulating ciphertext.
• Have a procedure for efficiently updating keys in case a key is compromised. In other words, if you have a hard-coded secret key in your app and it takes a week to compile, test, and verify a new build of your site, then you have a significant exposure if a key is compromised.
• Minimize where encryption is necessary; reduce the need for the browser to have access to sensitive data. For example, the compromise of a pseudo-random session cookie has less impact than reverse engineering an encrypted cookie that contains a user’s data.
• Identify the access points to the unencrypted version of data. If a special group of users is able to access plaintext data where “normal” users only see encrypted data, that special group’s access should be audited, monitored, and separated from the web app used by “normal” users.
• Use strong sources of entropy. This rule is woefully brief. You can also interpret it to mean, use a crypto library’s PRNG functions to generate random numbers as opposed to relying system functions.
Summary
It’s dangerous to assume that the most common and most damaging attacks against web sites are the dynamic duo of cross-site scripting and SQL injection. While that pair does represent a significant risk to a web site, they are only part of the grander view of web security. Vulnerabilities in the business logic of a web application may be more dangerous in the face of a determined attacker. Logic-based attacks target workflows specific to the web application. The attacker searches for loopholes in features and policies within the web site. The exploits are also difficult to detect because they rarely use malicious characters or payloads that appear out of the ordinary.
Vulnerabilities in the business logic of a web site are difficult to identify proactively. Automated scanners and source code analysis tools have a syntactic understanding of the site (they excel at identifying invalid data problems or inadequate filters). These tools have some degree of semantic understanding of pieces of the site, such as data that will be rendered within the HTML or data that will be part of a SQL statement. None of the tools can gain a holistic understanding of the web site. The workflows of a web-based e-mail program are different from an online auction site. Workflows are even different within types of applications; one e-mail site has different features and different implementation of those features than another e-mail site. In the end, logic-based vulnerabilities require analysis specific to each web application and workflow. This makes them difficult to discover proactively, but doesn’t lessen their risk.
1 Microsoft’s secure development process has greatly improved its software’s security (http://www.microsoft.com/security/sdl/default.aspx). While their compilers have options for strict code-checking and security mechanisms, the reliance on tools is part of a larger picture of design review. Tools excel at finding implementation bugs, but rarely provide useful insight into design errors.
2 http://www.apple.com/support/ipod/service/faq/#acc3.
3 YouTube is rife with accounts being attacked by “vote bots” in order to suppress channels or videos with which the attackers disagree. Look for videos about them by searching for “vote bots” or start with this link, http://www.youtube.com/watch?v=AuhkERR0Bnw, to learn more about such attacks.
4 As an aside, this is an excellent example where cloud computing, or computing on demand, might have been a positive aid in security. The MacWorld registration system must be able to handle spikes in demand as the event nears, but doesn’t require the same resources year round. An expensive hardware investment would have been underutilized the rest of the year. Since code validation was potentially a high-cost processing function, the web site could have used an architecture that moved processing into a service-based model that would provide scaleability on demand only at times when the processing was actually needed.
5 Botnets have been discovered that range in size from a few thousand compromised systems to a few million. Their uses range from spam to DoS to stealing personal information. One list of botnets can be found at http://blog.damballa.com/?p=1120.
6 The BlackHat presentation slides at http://www.blackhat.com/presentations/bh-usa-09/VELANAVA/BHUSA09-VelaNava-FavoriteXSS-SLIDES.pdf provide many more examples of complex JavaScript used to bypass filters and intrusion detection systems. JavaScript obfuscation also rears it head in malware payloads injected into compromised web pages.
7 Referenced from Walsingham: Elizabeth’s Spymaster by Alan Haynes. A tough book to get through, but of an intriguing subject of espionage in the era of royal courts and Shakespeare.
8 Claude Shannon’s 1949 paper, “Communication Theory of Secrecy Systems,” provides more rigorous explanations of these properties (http://netlab.cs.ucla.edu/wiki/files/shannon1949.pdf).
9 The examples used the SHA-1 algorithm, but any algorithm based on a Merkle-Damgard transformation is vulnerable to this attack, regardless of bit length. For one point of reference on this type of hash function, check out http://cs.nyu.edu/~puniya/papers/merkle.pdf. As a bonus exercise, consider how this attack may or may not work if the secret key is appended to the message rather than prepended to it.
10 An overview of web application security, including specification checking, is at http://www.clusif.asso.fr/fr/production/ouvrages/pdf/CLUSIF-2010-Web-application-security.pdf.
11 Obfuscated code contents stretch the limits of subjectivity and sane programming. Reading obfuscated code alternately engenders appreciation for a language and bewilderment that a human being would abuse programming in such a horrific manner. Check out the Obfuscated C Contest for a start, http://www.ioccc.org/. There’s a very good chance that some contest has been held for the language of your choice.