Understanding Context: Environment, Language, and Information Architecture (2014)
Part IV. Digital Information
The Pervasive Influence of Code
PHYSICAL AND SEMANTIC MODES SHAPED OUR CONTEXTUAL EXPERIENCE ALL ALONE, up until the last century. All that time, the invariant structural principles of natural and built environments changed very slowly, if at all. It’s a third ingredient—digital information—whose influence has so quickly disrupted how we experience the other two modes. It’s what has made so many user experience-related fields necessary to begin with.
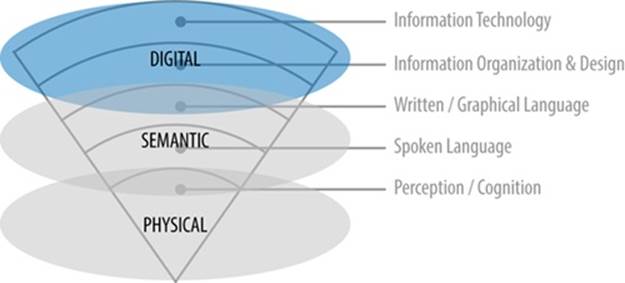
Figure IV.1. Digital information
Part IV explains the origins of digital technology, and why it is different from the other modes. It then explores how digital information influences the way we understand the world, the way we make software, and the properties of digital agents and simulated affordances.
Chapter 12. Digital Cognition and Agency
The electric things have their life, too.
—PHILIP K. DICK
Shannon’s Logic
For the realm of information technology, the word information has a specific history. Just as ecological psychologist James J. Gibson chose the word for his work in psychology, Claude Shannon (1916-2001) appropriated it for his own, separate purposes. An American mathematician, electronic engineer, and cryptographer—often called the “Father of Information Theory”—Shannon was the prime mover behind a way of understanding and using information that has led to the digital revolution we’re experiencing today.[242] His work during World War II, and later at Bell Labs and MIT, is foundational to anything that relies on packaging up information into bits (the word “bit” being a conflation of “binary digit”) and transmitting it over any distance.
One important part of Shannon’s work is how he applied mathematical logic to the problem of transmission, using an encoded (or encrypted) form. Previously, engineers had tried improving the signal of electronic transmission by boosting the power. But that approach could help to only a certain point, at which physics got in the way. Pushing electrons through wires or air over a long-enough distance eventually generates noise, corrupting the signal.
Shannon’s revolutionary discovery: accuracy is improved by encoding the information in a way that works best for machines, not for humans. This turn goes beyond the sort of encoding seen with the telegraph, where codes were simple patterns of signals corresponding to words, common phrases, or (even more abstractly) just letters. Shannon’s idea had origins in his cryptography work during World War II, when he saw that deciphering a message could be handled by analyzing language rather than semantically.
Author and historian James Gleick explains how Shannon proposed this approach in a secret paper written during the war, and in so doing, borrowed and recoined the word “information”:
Shannon had to eradicate “meaning.” The germicidal quotation marks were his. “The ‘meaning’ of a message is generally irrelevant,” he proposed cheerfully. He offered this provocation in order to make his purpose utterly clear. Shannon needed, if he were to create a theory, to hijack the word information. “‘Information’ here,” he wrote, “although related to the everyday meaning of the word, should not be confused with it.”[243]
By framing the signal of a transmission as a series of discrete (abstract) symbols, it became possible to enhance the accuracy of the transmission by adding symbols that help correct errors; this was extra information against which the receiver can check for breaks in transmitted patterns, or clarify the context of such an abstracted, semantics-free signal stream.[244] This approach is similar to how radio operators will use words like Alpha, Bravo, and Charlie for A, B, and C: in a noisy radio signal, it’s hard to tell letters apart, especially given that many of them sound so much alike. Additional information contextualizes the bits of signal, helping ensure accurate reception.
So, Shannon’s approach took human meaning out of the enterprise altogether. He took a scalpel to the connection between meaning and transmission, saying in his landmark 1948 Bell Labs paper, “These semantic aspects of communication are irrelevant to the engineering problem.”[245]Shannon redefined “information” much more narrowly as a stochastic construct, built from the most basic logical entity, the Boolean binary unit: yes or no, on or off, one or zero.
In formulating his ecological view of information, Gibson didn’t discount Shannon’s theories so much as set them aside: “Shannon’s concept of information applies to telephone hookups and radio broadcasting in elegant ways but not, I think, to the firsthand perception of being in-the-world, to what the baby gets when first it opens its eyes. The information for perception, unhappily, cannot be defined and measured as Claude Shannon’s information can be.”[246] Shannon’s approach to information can be “defined and measured” in part because it’s the opposite of human language; it doesn’t emerge through messy, cultural usage. It begins with definition and measurement, from abstract, logical principles, with mathematically clear boundaries.
From the human user’s point of view, the native tongue of digital things is, by necessity, decontextualized. It doesn’t afford anything for our perception, either physically or semantically, without translating it back into a form that we can not only perceive but understand.
That significant work of translation has a strong digital influence over the way we think about the world, the way we design and build environments with software, and the way the world around us now behaves. The idea that human meaning is “irrelevant to the engineering problem” is, in a sense, now part of digital technology’s DNA and has a pervasive ripple effect in everything we digitize (Figure 12-1).
This is why I’m using the word “digital” so broadly, beyond the confines of machine languages and binary code. The more of our world we encode for machines, the more of it is opaque to us, out of our reach, detached from the laws that govern the non-digital parts of our world. We understand our experience by coupling with the information the environment provides us; but digital technology, by its nature, decouples its information from our context. It has forever complicated and changed the way we need to think about design’s communication and craft.
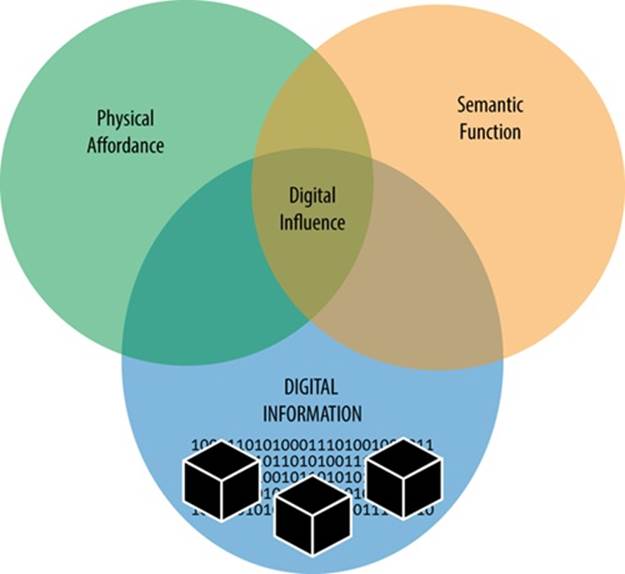
Figure 12-1. The Digital mode has a strong and growing influence over the other modes of information
Digital Learning and Agency
After Shannon’s initial discoveries, information theory didn’t stop at mere transmission and storage. There was another, somewhat more esoteric, area of inquiry going on for several generations: the theory of how machines—using symbolic logic—might do the job of computing. A “computer” had always been a human person, performing the professional role of computing mathematical operations; but human effort often results in human error, and humans can also keep up with only so much computational scale and complexity. So, by the mid-twentieth century, there had been a long-standing interest in ways to automate this activity.
In addition to Shannon, the work of people such as Alan Turing and Norbert Wiener—prefigured by similar efforts a century earlier by Ada Lovelace and Charles Babbage—led to the creation of machines essentially made of logic itself. Turing, in particular, championed the idea that computing is noncorporeal, not dependent on a particular medium or energy system. He invented the idea of an automated computing machine that functions entirely based on symbols—the Turing machine—that (in theory) could function based on rules built of Boolean, binary fundamentals, from the ground up. Anything that could be represented in mathematical symbols and logic could be computed. Not just mathematical problems, but all sorts of human ideas, questions, and communications—as long as they could be represented in the machine.[247] As a result of this line of inquiry, we now have technology that has agency; the ability to make decisions and take actions on its own.
This sort of agency has powerful, disruptive effects. Kitchin and Dodge put it this way in their book Code/Space: Software and Everyday Life:
The phenomenal growth in software creation and use stems from its emergent and executable properties; that is, how it codifies the world into rules, routines, algorithms...Although software is not sentient and conscious, it can exhibit some of the characteristics of being alive... This property of being alive is significant because it means code can make things do work in the world in an autonomous fashion.[248]
But how does the digital system know anything about that world, which isn’t made of abstractions, but actual concrete stuff? As Paul Dourish explains, we have to create representations of the world with which computers can work:
Computation is fundamentally about representation. The elements from which we construct software systems are representational; they are abstractions over a world of continuous voltages and electronic phenomena that refer to a parallel world of cars, people, conversational topics, books, packages, and so forth. Each element in a software system has this dual nature; on the one hand, it is an abstraction created out of the electronic phenomena from which computers are built, and on the other, it represents some entity, be it physical, social, or conceptual, in the world which the software developer has chosen to model.[249]
Human memory is embodied and only occasionally somewhat literal (when we explicitly memorize something). But computer memory works by making exact copies of abstract representations. Computers don’t find their way to abstraction from the roots of physical perception-and-action; they begin with abstraction.
Every representation has to be intentionally created for the system. This can be done by the people who made the system, or it can be done by some algorithmic process in which the system defines representations for itself. As depicted in Figure 12-2, whereas human cognition emerged from bodily perception and eventually developed the ability to think in terms of abstractions and symbols, digital computing works the other way around. People can go through their entire lives not explicitly defining the entities they encounter. But computers can do little to nothing without these descriptions.
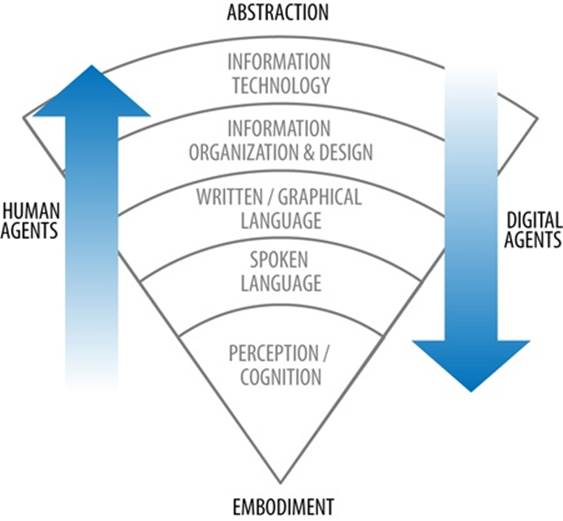
Figure 12-2. Humans and digital agents learn in different directions
Writing is already a form of code, with roughly standardized syntax, spelling, and letter forms. So, computers find writing to be a much easier starting point than spoken language. That is, it’s easier to teach a computer a semantic definition of the written word “berry” than it is to teach the computer how to recognize the word when spoken aloud. Speech introduces all sorts of environmental variation, such as tone of voice or regional inflection.
Although teaching a computer to recognize the spoken word “berry” in some contexts is pretty challenging, teaching it to recognize a picture of a berry is even harder. Sure, we can program it to recognize a specific berry picture, but it really struggles to see any picture of any sort of berry and connect it to “berryness,” which humans tacitly pick up thanks to our embodied experiences with them.
Computers, however, don’t have bodies unless we add them onto the computing “brain.” Teaching a computer to use a robotic body to find and pick berries is even more complex than visual recognition. It requires definitions not just about the visual qualities of berries, but how to gently harvest something so fragile in the first place, not to mention how to negotiate its body through everything else in the environment.[250] This insight about computers is called Moravec’s paradox, named after AI researcher Hans Moravec, who was one of a group of scientists who articulated it in the 1980s. In Moravec’s words, “It is comparatively easy to make computers exhibit adult level performance on intelligence tests or playing checkers, and difficult or impossible to give them the skills of a one-year-old when it comes to perception and mobility.”[251]
Of course, since the time of Shannon and Turing, and even Moravec, computers have become much more adept at processing fuzzy ecological and semantic information inputs. Face and voice recognition, street navigation, and other complex pattern-matching capabilities are more possible now with powerful, cheap processors and advanced algorithms. Still, these are extremely limited capabilities, with narrow contextual accuracy.
This isn’t to say computers will never have embodied learning. There has been some cutting-edge research in biocomputing, which grows computers with organic cells, or even with bodies of a sort, in order to learn more environmentally. For most of us, however, our design work will not involve these exotic creatures. We need to make do with the silicon and bits that are available to us. That means we have to understand the layers of semantic substrate required to make our gadgets do the wonderful things we take for granted.
We can see this in action when Apple’s Siri attempts (with often hilarious missteps) to understand “where’s the closest gas station?” Here, Siri must rely on the structure of the vocalized vibrations and match them with semantic frameworks that are defined and generated as encoded language. Someone, somewhere, had to use writing to even start teaching Siri how to learn what we mean when we talk to it. Context had to be artificially generated, from already-abstracted inputs.
And when we use Shazam to recognize a song, the song is not meaningful to the device as it is to us. Shazam is matching the structure of the song with the structures indexed in vast databases. The emotional or cultural context of the song isn’t a factor, unless it’s defined by people in some way. For video content, Netflix has become a market leader in defining these subtle, oblique permutations, which they internally call altgenres, such as “Critically Acclaimed Emotional Underdog Movies” or “Spy Action & Adventure from the 1930s.”[252] The Netflix categories exist only because of enormous work behind the scenes, translating between the nested variety of human life and the binary structures of digital information.
Everyday Digital Agents
We’re increasingly giving our environment over to digital agents, programming them as best we can and then setting them loose to do their work. An example of simple digital agency is how my car (a Kia Forte coup) won’t let me perform certain actions in its digital interface if the car is in motion. I was trying to Bluetooth-pair my phone from the passenger seat when I saw this screen. My wife, Erin, was driving. But the system didn’t know that, so it followed the rules it was taught, making the function “Not Available” (Figure 12-3).
This is similar to the mechanical limitation that keeps me from turning off the engine while the car is still in gear. In both cases, it’s a hidden rule in the system of my car, made manifest by limiting my action. But mechanical limitations can be only as complex as the limits of physical objects will allow. Digital information itself has no such mechanical restriction; it can enact as many thousands of complex rules as will fit on device’s microchips.
Figure 12-3. “I’m sorry, Andrew, I’m afraid I can’t do that.” My Kia Forte, channeling HAL 9000[253]
That is, digital information has almost no inertia, compared to physical information. If we add to that lack of friction a huge number of more complex, algorithm-based agents, massively disproportionate effects can result. In 2010, the financial world got a bit of a scare when the markets took a momentary plunge of over 9 percent—nearly 1,000 points within minutes, equating to many millions of lost dollars—before recovering most of the drop by the end of the hour (see Figure 12-4). What happened? It turns out that it was due to automated “high-frequency trading,” conducted by computer algorithm. These trades happen much faster than humans could ever conduct business. At the time of the blip, this rapid automated trading accounted for somewhere between 50 and 75 percent of daily trading volume.[254]
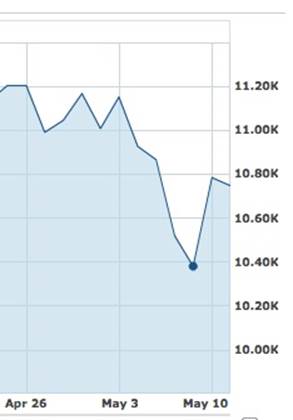
Figure 12-4. The sudden, algorithm-generated dip that shocked the market in 2010 (graph from finance.yahoo.com)
It came to be called the Flash Crash, and it scared everyone enough to spur investigations and Congressional hearings. Eventually so-called “circuit breakers” were added to systems, but some critics are still wary of high-frequency trading software.[255] And maybe for good reason, since as early as 2012, a “single mysterious computer program” made high-frequency orders and then cancelled them—enough to account for 4 percent of US trading activity in that week. According to one news report, “the motive of the algorithm is still unclear.”[256]
This is the world we live in now, where we have to guess at the motivations not of Olympian gods, but of computer-process daemons whirring away in the nervous system of our global economy. Digital agents are natively mathematical creatures, unconcerned with slowing down enough for us to keep up, or being transparent about their inner dynamics, unless we design them to be otherwise.
Although it takes specialized knowledge to create a market-trading algorithm, laypeople increasingly have access to tools for making their own decision-making agents. For example, IFTTT—If This Then That—is a cloud-based service with which users can create “recipes” for simple procedural connections between other online services (see Figure 12-5). For example, “If I post a picture to Instagram, store a copy in my Dropbox archive.” IFTTT is like a virtual Lego set made of semantic functions with which we can create our own digital helpers. It provides active digital objects we can use to conditionally invoke events, interwoven with defined places—and increasingly with physical objects.
IFTTT has started adding new triggers for physical devices, such as wearables and smart home products.[257]

Figure 12-5. Recipes from IFTTT.com
These new tools change the nature of the places they’re connected to, whether an online place such as Instagram, or a physical place like the home, or an object such as one’s own body.
IFTTT has made a nicely understandable system that enables a lot of complexity with simple rules. Still, these invisible agents can scale only so far until an average person will have trouble keeping up with them all. Memory typically requires repeated exposure to a perceivable pattern, but the purpose of most such agents is to “set it and forget it.” There are already many common set-and-forget services, like online subscriptions to medicine and groceries, or automated bill-pay withdrawals—and these will seem primitive and few in another 5 to 10 years. It leads us to question what will help us manage all this personal automation. Will we need agents for keeping track of our agents?
Ontologies
Computers are machines that do not need human-understandable context to function within and among themselves. Sure, we created them, but there is no intrinsic requirement that once made, they ever have to provide an output that we can comprehend. Early computers required their users to interpret hole-punched cards and patterns of blinking lights to read their computed results. For example, the 1970s Altair hobbyist computer (Figure 12-6) had only switches and red LEDs on its front panel as input and output mechanisms for entering and reading the results of simple programs.
As computers became more powerful, they could be used to store and process more-complex concepts. But those concepts have to be described and modeled for the machine to work with them. To accomplish this task, information science makes use of an old concept in a new way: something called ontology.

Figure 12-6. The Altair 8800b user interface[258]
For centuries, ontology has referred to the philosophical study of being, existence, or reality. It also has to do with the categories of things that exist, and the relationships between those categories. This conceptual sort of ontology is part of an ancient branch of philosophy called metaphysics. Language’s role in ontological questions has increased in significance over the centuries, as philosophers (and anyone else concerned with language) have come to realize that language and “being” are fundamentally connected. What does it mean to say, “There is a calendar hanging on the wall, and I know it is there, and I know it has information on it that means X or Y”; and what does it mean to say, “We both exist in the same place and are experiencing the same calendar?” To consider the question fully requires talking or writing about it; ontological questions are, after all, questions.
Ontology is also a term used in information science for a related, but different meaning: the formal representation of a set of concepts within a domain, and the specification of the relationships between those concepts. That’s a mouthful, but all it really means is the way we teach digital machines how to understand the inputs we expect them to process. A business software platform such as Microsoft Outlook has data objects that must be defined so that the system knows what its calendar is and what functions are expected of it. Google’s search algorithms and massive semantic databases have to know what people mean when they search for things related to calendars—all the synonyms and related products, conversations, or anything else that has to do with how we use the word “calendar” in English-speaking culture.
Sophisticated information systems require these sorts of definitions in order to make sense of the work we give them to do. Ontologies stand as a digital system’s version of invariant structure for its nested semantic environment—the lens a computer uses to process human ideas and entities. For example, the BBC has a publicly available set of ontologies (see Figure 12-7) it uses for structuring its information, including what it means when it refers to a television “series” versus an “episode,” or what it means to publish a “story” and its various related components.
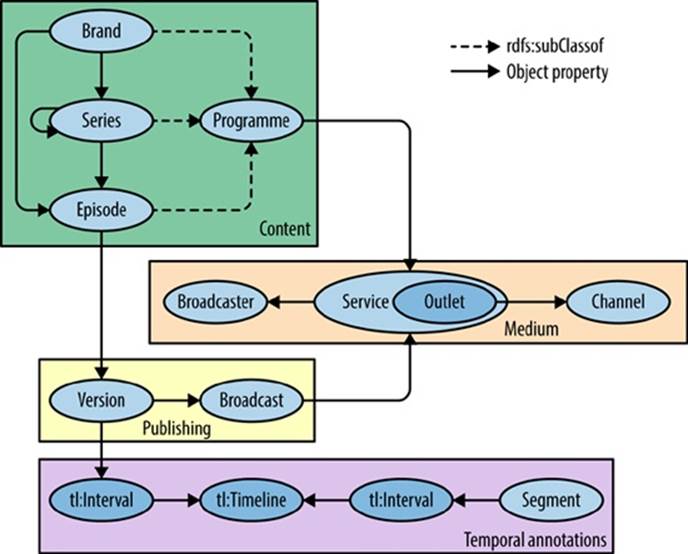
Figure 12-7. The “programme” ontology from the BBC[259]
In short, this is a foundation for how we teach digital systems about human context. There’s plenty of digital information that computers share that is only about computing, so it doesn’t require semantic context. Yet, we made computers to be part of the human environment, so most of what they do eventually needs to be translated into signifiers that people can comprehend.
When designing systems for people to use, we should consider both the conceptual and formal definitions of ontology, because much of our work is about creating a bridge between those poles. Looking at the Google Calendar example in Chapter 11, we can see how ontology is at the center of the problem. What is “Calendar” in the Google ecosystem? In some places, the word is used to indicate the simulated physical calendar we see on a screen. In other instances, however, it indicates the subscribed calendar-feeds that are only subsets of the entire calendar environment. The digital layer has clear definitions for what these calendars are, because each construct has a machine-friendly name and description. But to the end user, they’re all just “calendar.”
Google had a related ontological problem in 2010 with the service it called Buzz, which attempted to integrate social networking into the successful Gmail platform. When Buzz rolled out, it created a prepopulated list of “friends” for every user, based on measurements gathered from users’ Gmail history, such as frequency of contact.
Upon launch, many Gmail users were surprised to discover this new set of rules and structures that changed the meaning of their Gmail environment, which went from being about email to being about email-plus-something-else that wasn’t entirely clear to them. The biggest problem was this: Buzz automatically decided for users just who those friends were versus people they didn’t want in such a list, such as bosses, coworkers, or hostile ex-spouses. The system also, by default, publicly showed your list of friends—letting everyone know the people with whom you communicate most.[260] These missteps cost Google, among other penalties, 20 years of auditing by the United States Federal Trade Commission.[261]
Buzz was working from an ontology that defined “friend” too simplistically, walking into the same trap that Facebook’s Beacon had tripped only a few years earlier. “Friend” is nested in our lives, not a rigidly hierarchical entity. We might refer to someone as a friend in one circle of people but in another circle say that person is an acquaintance or partner. However, Buzz created a digital agent (based on an algorithm) that saw the world through a narrow spectrum that was efficient for the machine’s perspective but disastrously wrong from the human point of view.
This happened even though Buzz was tested extensively within the huge corporate social context of Google before it was launched.[262] That prelaunch context was misleading, though, because a corporate environment has tacit cultural norms that make it a very different place compared to nonwork life. Add to this problem the fact that users had already become used to Gmail as an environment with predictable, invariant qualities. Buzz introduced new rules and structures, changing the architecture of how Gmail worked. It didn’t just add features—it changed the nature of the environment fundamentally.
There are information-science specialists who can create ontologies that work well for machines, and there are philosophers who continue to explore what it means to “be.” But, for those of us making user-facing environments, ontology is about establishing understandable semantic functionthat solves for the contextual gap between person and machine.
[242] The amazing, fascinating history of information theory and figures like Shannon is beyond our scope, alas. For a delightful telling of these stories, read James Gleick’s The Information: A History, a Theory, a Flood.
[243] Gleick, James. The Information: A History, a Theory, a Flood. New York: Random House, Inc., 2011, Kindle locations: pp. 3848-53.
[244] Gleick, James. The Information: A History, a Theory, a Flood. New York: Random House, Inc., 2011, Kindle location: 3922.
[245] Shannon, C. E. “A Mathematical Theory of Communication.” Reprinted with corrections from The Bell System Technical Journal July, October, 1948;Volume 27:379-423, 623-56.
[246] Gibson, 1979, p. 24
[247] For an excellent overview of how Turing’s ideas intersect with Gibsonian ecological theory, see the section called “When is a Turing Machine Not a Turing Machine” in Louise Barrett’s Beyond the Brain (2011). Also, see the following writings by Andrew Wells: Wells, A. “Gibson’s affordances and Turing’s theory of computation.” Ecological Psychology 2002; Volume 14: 140-80, and ———. Rethinking Cognitive Computation: Turing and the Science of the Mind. London: Palgrave, 2006.
[248] Kitchen and Dodge, 2011:5.
[249] Dourish, Paul. Where the Action Is: The Foundations of Embodied Interaction. Cambridge, MA: MIT Press, 2004:137, Kindle edition.
[250] In fact, new embodied paradigms in robotics have resulted in robots that gracefully navigate all sorts of terrain, such as the naturally limbed but small-brained “Big Dog” robot designed by Boston Dynamics, a company recently acquired by Google (http://www.bostondynamics.com/robot_bigdog.html).
[251] Moravec, Hans. Mind Children. Cambridge: Harvard University Press, 1988:15.
[252] Madrigal, Alexis C. “How Netflix Reverse Engineered Hollywood” The Atlantic (theatlantic.com) January, 2015 (http://theatln.tc/1sKXxHF).
[253] Photo by author.
[254] “Surge of Computer Selling After Apparent Glitch Sends Stocks Plunging.” New York Times May 6, 2010 (http://nyti.ms/1uzHTNF).
[255] http://en.wikipedia.org/wiki/2010_Flash_Crash
[256] “Mysterious Algorithm Was 4% of Trading Activity Last Week.” CNBC.com, Monday Oct 8, 2012 (http://www.cnbc.com/id/49333454).
[257] https://ifttt.com/jawbone_up and https://ifttt.com/wemo_motion
[258] Wikimedia Commons: http://bit.ly/1xaAIws
[259] http://www.bbc.co.uk/ontologies/
[260] Carlson, Nicholas. “WARNING: Google Buzz Has A Huge Privacy Flaw” Business Insider (businessinsider.com) February 20, 2010 (http://read.bi/1rpOyrE).
[261] Wouters, Jorgen. “Google Settles With FTC Over Privacy Violations on Buzz” DailyFinance.com, March 31, 2011 (http://aol.it/1vHPCgF).
[262] Krazit, Tom. “What Google needs to learn from Buzz backlash” CNet.com, February 16, 2010 (http://news.cnet.com/8301-30684_3-10454683-265.html).