Product Details Lean Enterprise: How High Performance Organizations Innovate at Scale (2015)
Part III. Exploit
Prediction is difficult, especially about the future.
Niels Bohr
In Part II, we showed how to explore new opportunities—whether potential products or internal tools and services. In this part, we discuss how to exploit validated ideas. As discussed in Chapter 2, these two domains demand a completely different approach for management and execution. However, both are necessary—and indeed complementary—if we are to effectively balance our enterprise portfolio and adapt to a constantly changing business environment.
We hope you are reading this part because you have successfully exited the explore domain—but it’s just as likely that you are here because you participate in a large program of work in an enterprise which has been set up in the traditional way. Thus, this part of the book primarily describes how to change the way we lead and manage such large-scale programs of work in a way that empowers employees and dramatically increases the rate at which we can deliver valuable, high-quality products to customers. But before we can begin, we must understand our current condition.
In an enterprise context, planned work is usually prioritized through a centralized or departmental planning and budgeting process. Approved projects then go through the development process before going live or being released to manufacturing. Even in organizations which have adopted “agile” development methods, the value stream required to deliver a project often resembles Figure III-1, which we describe as “water-scrum-fall.”105 In cases where one or more of these phases are outsourced, we must also go through a procurement process before we can proceed to the design and development phases following approval. Because this process is so onerous, we tend to batch up work, creating large programs which further exacerbate the problems with the project paradigm.
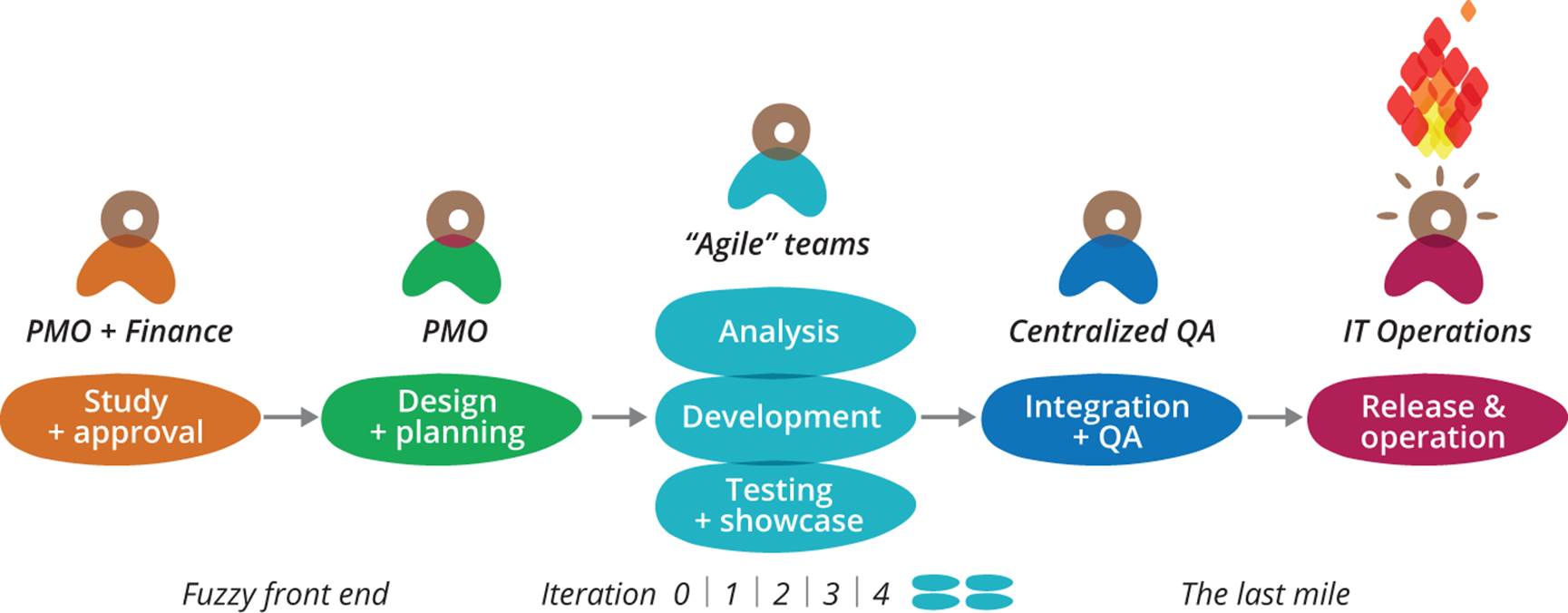
Figure III-1. Water-scrum-fall
This project-based paradigm for carrying out software development at scale has its origins in the post-WWII United States military-industrial complex, where software was crucial for building a new generation of airplanes, missile systems, and spacecraft that had essentially one customer: the US government. It’s no coincidence that the term “software engineering” was coined at a 1968 NATO conference which was convened to work out how to formalize large-scale software development.106
The traditional centralized phase-gate project paradigm was designed in a simpler era. Products could not deliver value until they were fully manufactured, they didn’t need to change substantially over the course of their lifecycle, and we had a high level of confidence that we would not need to change the specification significantly in response to new information discovered in the course of building the product.
None of these criteria apply to software-based systems today, and the power of software derives from the fact that it’s cheap to prototype and change. In particular, since we are so frequently wrong about what users of our products and systems will find valuable, planning out big programs of work months in advance leads to an enormous amount of waste and bad blood. Instead of trying to get better at predicting the future, we should improve our ability to adapt rapidly and effectively to new information.107
The modern, lean-agile paradigm we present for running large-scale programs of work discussed in this part is the result of working with and studying a number of organizations that need to get software development off the critical path. They want to move fast at scale, detect weak signals in the market, and exploit them rapidly. This is what allows them to provide better customer service, to reduce the cost of creating and evolving products, and to increase quality and stability of their services.
There are several frameworks that deal with scaling agile software development methods. In general, these frameworks take small teams practicing Scrum and add more structures on top to coordinate their work. However, these teams are still embedded within a phase-gate program and portfolio management process that is more or less unchanged from the traditional project management paradigm. They still apply top-down thinking and tend to batch up work into releases with long cycle times, thus limiting the use of the information collected to guide future decisions. Our approach differs in several important respects from these frameworks, as well as from more traditional phase-gate frameworks.
The most important difference is that instead of presenting a particular set of processes and practices to implement, we focus on implementing continuous improvement at the senior leadership level to drive the evolution of your organization and the processes you use. Continuous improvement cannot be at the edges of our “big diagram”: we put it front and center. This reflects the fact that there is no one-size-fits-all solution and that every organization faces a different set of circumstances. Every organization will take its own path to address changes, aligned to its own business objectives; to create lasting results, we must enable teams to try things out and learn what works and what doesn’t for themselves.
In the following chapters, we will present the following principles for lean-agile product development at scale:
§ Implement an iterative continuous improvement process at the leadership level with concise, clearly specified outcomes to create alignment at scale, following the Principle of Mission.
§ Work scientifically towards challenging goals, which will lead you to identifying and removing—or avoiding—no-value-add activity.
§ Use continuous delivery to reduce the risk of releases, decrease cycle time, and make it economic to work in small batches.
§ Evolve an architecture that supports loosely coupled customer-facing teams which have autonomy in how they work to achieve the program-level outcomes.
§ Reduce batch sizes and take an experimental approach to the product development process.
§ Increase and amplify feedback loops to make smaller, more frequent decisions based on the information we learn from performing our work to maximize customer value.
We’ll also provide several examples of enterprises that have leveraged these principles to create a lasting competitive advantage, and describe how they transformed themselves in the process.
105 The term “water-scrum-fall” was coined by Forrester Research. A value stream is defined as “the sequence of activities an organization undertakes to deliver on a customer request” [martin], p. 2. We cover value streams in Chapter 7.
106 http://homepages.cs.ncl.ac.uk/brian.randell/NATO
107 This is a key claim of Nassim Taleb’s body of work.
Chapter 6. Deploy Continuous Improvement
The paradox is that when managers focus on productivity, long-term improvements are rarely made. On the other hand, when managers focus on quality, productivity improves continuously.
John Seddon
In most enterprises, there is a distinction between the people who build and run software systems (often referred to as “IT”) and those who decide what the software should do and make the investment decisions (often called “the business”). These names are relics of a bygone age in which IT was considered a cost necessary to improve efficiencies of the business, not a creator of value for external customers by building products and services. These names and the functional separation have stuck in many organizations (as has the relationship between them, and the mindset that often goes with the relationship). Ultimately, we aim to remove this distinction. In high-performance organizations today, people who design, build, and run software-based products are an integral part of business; they are given—and accept—responsibility for customer outcomes. But getting to this state is hard, and it’s all too easy to slip back into the old ways of doing things.
Achieving high performance in organizations that treat software as a strategic advantage relies on alignment between the IT function and the rest of the organization, along with the ability of IT to execute. It pays off. In a report for the MIT Sloan Management Review, “Avoiding the Alignment Trap in Information Technology,” the authors surveyed 452 companies and discovered that high performers (7% of the total) spent a little less than average on IT while achieving substantially higher rates of revenue growth.108
However, how you move from low performance to high performance matters. Companies with poor alignment and ineffective IT have a choice. Should they pursue alignment first, or try to improve their ability to execute? The data shows that companies whose IT capabilities were poor achieve worse results when they pursue alignment with business priorities before execution, even when they put significant additional investment into aligned work. In contrast, companies whose engineering teams do a good job of delivering their work on schedule and simplifying their systems achieve better business results with much lower cost bases, even if their IT investments aren’t aligned with business priorities.
The researchers concluded that to achieve high performance, companies that rely on software should focus first and foremost on their ability to execute, build reliable systems, and work to continually reduce complexity. Only then will pursuing alignment with business priorities pay off.
However, in every team we are always balancing the work we do to improve our capability against delivery work that provides value to customers. In order to do this effectively, it’s essential to manage both kinds of work at the program and value stream levels. In this chapter we describe how to achieve this by putting in place a framework called Improvement Kata. This is the first step we must take to drive continuous improvement in our execution of large scale programs. Once we have achieved this, we can use the tools in the following chapters to identify and remove no-value-add activity in our product development process.
The HP LaserJet Firmware Case Study
We will begin with a case study from the HP LaserJet Firmware team, which faced a problem with both alignment and execution.109 As the name suggests, this was a team working on embedded software, whose customers have no desire to receive software updates frequently. However, it provides an excellent example of how the principles described in the rest of Part III work at scale in a distributed team, as well as of the economic benefits of adopting them.
HP’s LaserJet Firmware division builds the firmware that runs all their scanners, printers, and multifunction devices. The team consists of 400 people distributed across the USA, Brazil, and India. In 2008, the division had a problem: they were moving too slowly. They had been on the critical path for all new product releases for years, and were unable to deliver new features: “Marketing would come to us with a million ideas that would dazzle the customer, and we’d just tell them, ‘Out of your list, pick the two things you’d like to get in the next 6-12 months.’” They had tried spending, hiring, and outsourcing their way out of the problem, but nothing had worked. They needed a fresh approach.
Their first step was to understand their problem in greater depth. They approached this by using activity accounting—allocating costs to the activities the team is performing. Table 6-1 shows what they discovered.
|
% of costs |
Activity |
|
10% |
Code integration |
|
20% |
Detailed planning |
|
25% |
Porting code between version control branches |
|
25% |
Product support |
|
15% |
Manual testing |
|
~5% |
Innovation |
|
Table 6-1. Activities of the HP LaserJet Firmware team in 2008 |
|
This revealed a great deal of no-value-add activity in their work, such as porting code between branches and detailed upfront planning. The large amount spent on current product support also indicated a problem with the quality of the software being produced. Money spent on support is generally serving failure demand, as distinct from value demand, which was only driving 5% of the team’s costs.110
The team had a goal of increasing the proportion of spending on innovation by a factor of 10. In order to achieve that goal, they took the bold but risky decision to build a new firmware platform from scratch. There were two main architectural goals for the new “FutureSmart” platform. The first goal was to increase quality while reducing the amount of manual testing required for new firmware releases (a full manual testing cycle required six weeks). The team hoped that this goal could be achieved through:
§ The practice of continuous integration (which we describe in Chapter 8)
§ Significant investment in test automation
§ Creating a hardware simulator so that tests could be run on a virtual platform
§ Reproduction of test failures on developer workstations
Three years into the development of the new firmware, thousands of automated tests had been created.
Second, they wanted to remove the need for the team to spend time porting code between branches (25% of total costs on the existing system). This was caused by the need to create a branch—effectively a copy of the entire codebase—for every new line of devices under development. If a feature or bug-fix added to one line of devices was required for any others, these changes would need to be merged (copied back) into the relevant code branches for the target devices, as shown in Figure 6-1. Moving away from branch-based development to trunk-based development was also necessary to implement continuous integration. Thus the team decided to create a single, modular platform that could run on any device, removing the need to use version control branches to handle the differences between devices.
The final goal of the team was to reduce the amount of time its members spent on detailed planning activities. The divisions responsible for marketing the various product lines had insisted on detailed planning because they simply could not trust the firmware team to deliver. Much of this time was spent performing detailed re-plans after failing to meet the original plans.
Furthermore, the team did not know how to implement the new architecture, and had not used trunk-based development or continuous integration at scale before. They also understood that test automation would require a great deal of investment. How would they move forward?
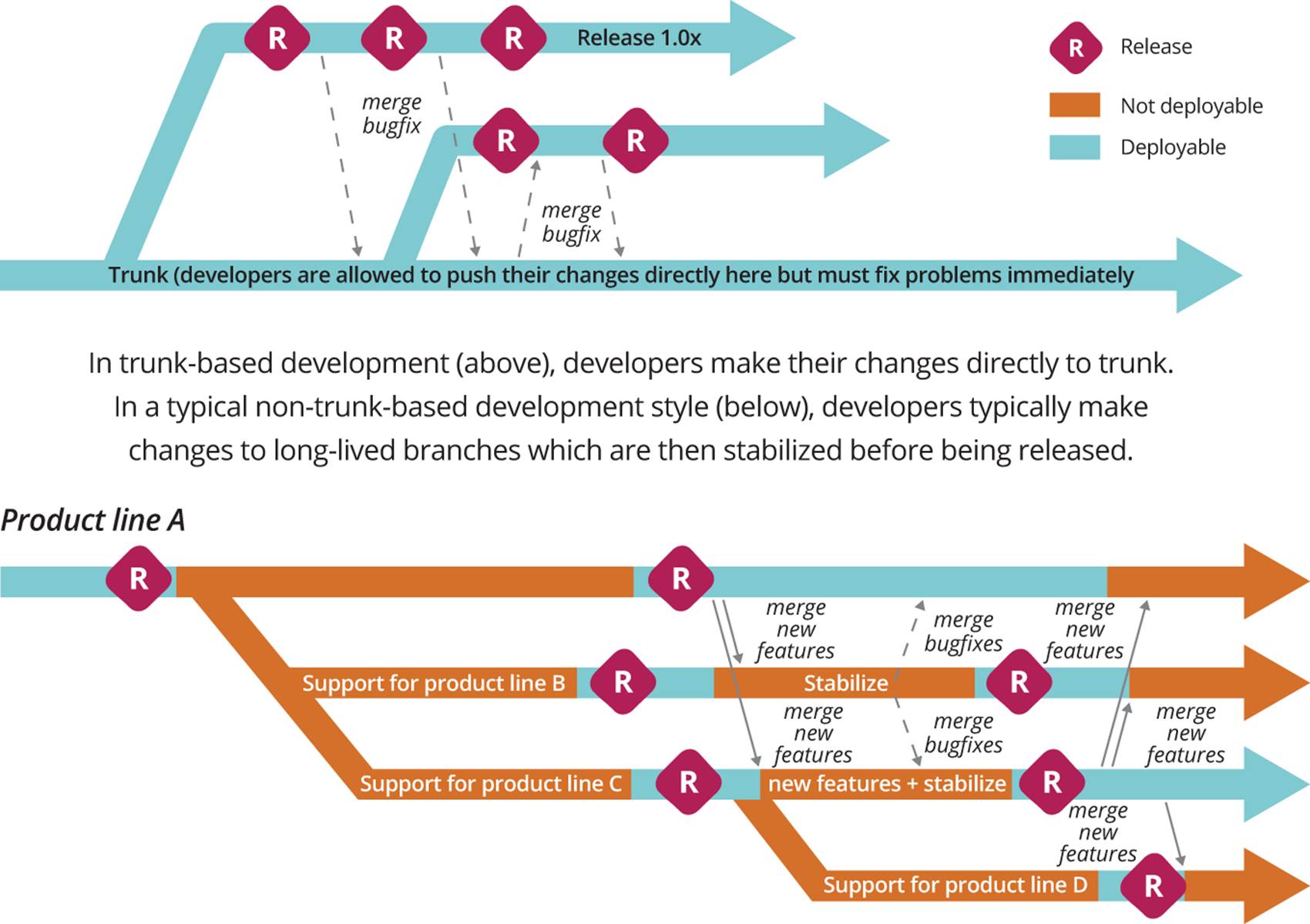
Figure 6-1. Branching versus trunk-based development
It’s all too easy to turn a sequence of events into a story in an attempt to explain the outcome—a cognitive bias that Nassim Taleb terms the narrative fallacy. This is, arguably, how methodologies are born. What struck us when studying the FutureSmart case were the similarities between the program management method of FutureSmart’s engineering management team and the approach Toyota uses to manage innovation as described in Mike Rother’s Toyota Kata: Managing People for Improvement, Adaptiveness, and Superior Results.111
Drive Down Costs Through Continuous Process Innovation Using the Improvement Kata
The Improvement Kata, as described by Mike Rother, is a general-purpose framework and a set of practice routines for reaching goals where the path to the goal is uncertain. It requires us to proceed by iterative, incremental steps, using very rapid cycles of experimentation. Following the Improvement Kata also increases the capabilities and skills of the people doing the work, because it requires them to solve their own problems through a process of continuous experimentation, thus forming an integral part of any learning organization. Finally, it drives down costs through identifying and eliminating waste in our processes.
The Improvement Kata needs to be first adopted by the organization’s management, because it is a management philosophy that focuses on developing the capabilities of those they manage, as well as on enabling the organization to move towards its goals under conditions of uncertainty. Eventually, everybody in the organization should be practicing the Improvement Kata habitually to achieve goals and meet challenges. This is what creates a culture of continuous improvement, experimentation, and innovation.
To understand how this works, let’s examine the concept of kata first. A kata is “a routine you practice deliberately, so its pattern becomes a habit.”112 Think of practicing scales to develop muscle memory and digital dexterity when learning the piano, or practicing the basic patterns of movement when learning a martial art (from which the term derives), or a sport. We want to make continuous improvement a habit, so that when faced with an environment in which the path to our goal is uncertain, we have an instinctive, unconscious routine to guide our behavior.
In Toyota, one of the main tasks of managers is to teach the Improvement Kata pattern to their teams and to facilitate running it (including coaching learners) as part of everyday work. This equips teams with a method to solve their own problems. The beauty of this approach is that if the goal or our organization’s environment changes, we don’t need to change the way we work—if everybody is practicing the Improvement Kata, the organization will automatically adapt to the new conditions.
The Improvement Kata has four stages that we repeat in a cycle, as shown in Figure 6-2.
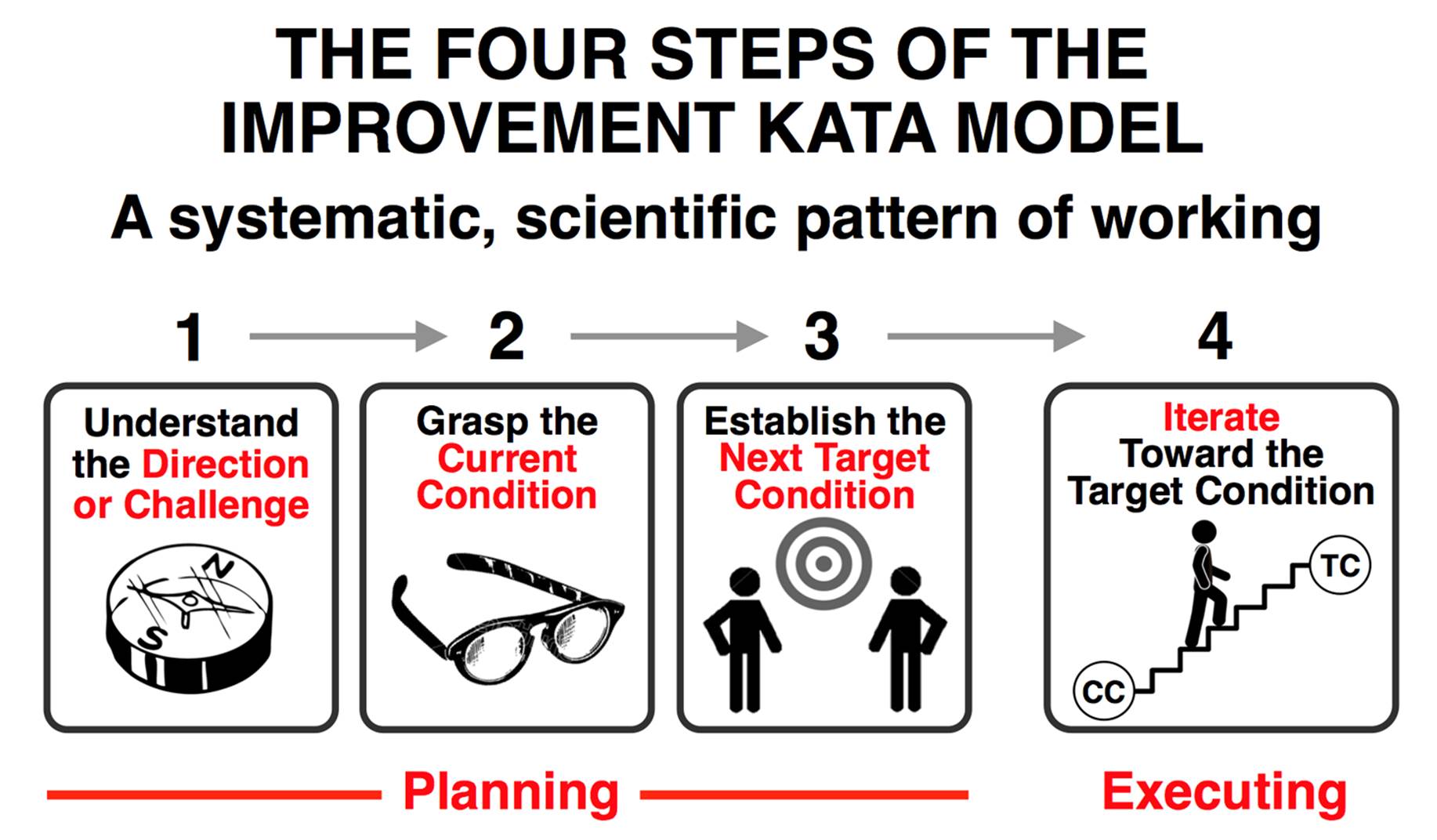
Figure 6-2. The Improvement Kata, courtesy of Mike Rother
Understand the Direction
We begin with understanding the direction. Direction is derived from the vision set by the organization’s leadership. A good vision is one that is inspiring—and, potentially, unattainable in practice. For example, the long-term vision for Toyota’s production operations is “One-piece flow at lowest possible cost.” In Leading Lean Software Development, Mary and Tom Poppendieck describe Paul O’Neill setting the objective for Alcoa to be “Perfect safety for all people who have anything to do with Alcoa” when he became CEO in 1987.113
People need to understand that they must always be working towards the vision and that they will never be done with improvement. We will encounter problems as we move towards the vision. The trick is to treat them as obstacles to be removed through experimentation, rather than objections to experimentation and change.
Based on our vision and following the Principle of Mission, we must understand the direction we are working in, at the level of the whole organization and at the value stream level. This challenge could be represented in the form of a future-state value stream map (see Chapter 7 for more on value stream mapping). It should result in a measurable outcome for our customers, and we should plan to achieve it in six months to three years.
Planning: Grasp the Current Condition and Establish a Target Condition
After we have understood the direction at the organizational and value stream levels, we incrementally and iteratively move towards it at the process level. Rother recommends setting target conditions with a horizon between one week and three months out, with a preference for shorter horizons for beginners. For teams that are using iterative, incremental methods to perform product development, it makes sense to use the same iteration (or sprint) boundaries for both product development and Improvement Kata iterations. Teams that use flow-based methods such as the Kanban Method (for which see Chapter 7) and continuous delivery (described in Chapter 8) can create Improvement Kata iterations at the program level.
As with all iterative product development methods, Improvement Kata iterations involve a planning part and an execution part. Here, planning involves grasping the current condition at the process level and setting a target condition that we aim to achieve by the end of the next iteration.
Analyzing the current condition “is done to obtain the facts and data you need in order to then describe an appropriate next target condition. What you’re doing is trying to find the current pattern of operation, so you can establish a desired pattern of operation (a target condition).” The target condition “describes in measurable detail how you want a process to function…[It is] a description and specification of the operating pattern you want a process or system to have on a future date.”114
The team grasps the current condition and establishes a target condition together. However, in the planning phase the team does not plan how to move to the target condition. In the Improvement Kata, people doing the work strive to achieve the target condition by performing a series of experiments, not by following a plan.
A target condition identifies the process being addressed, sets the date by which we aim to achieve the specified condition, and specifies measurable details of the process as we want it to exist. Examples of target conditions include WIP (work in progress) limits, the implementation of Kanban or a continuous integration process, the number of good builds we expect to get per day, and so forth.
Getting to the Target Condition
Since we are engaging in process innovation in conditions of uncertainty, we cannot know in advance how we will achieve the target condition. It’s up to the people doing the work to run a series of experiments using the Deming cycle (plan, do, check, act), as described in Chapter 3. The main mistakes people make when following the Deming cycle are performing it too infrequently and taking too long to complete a cycle. With Improvement Kata, everybody should be running experiments on a daily basis.
Each day, people in the team go through answering the following five questions:115
1. What is the target condition?
2. What is the actual condition now?
3. What obstacles do you think are preventing you from reaching the target condition? Which one are you addressing now?
4. What is your next step? (Start of PDCA cycle.) What do you expect?
5. When can we go and see what we learned from taking that step?
As we continuously repeat the cycle, we reflect on the last step taken to introduce improvement. What did we expect? What actually happened? What did we learn? We might work on the same obstacle for several days.
This experimental approach is already central to how engineers and designers work. Designers who create and test prototypes to reduce the time taken by a user to complete a task are engaged in exactly this process. For software developers using test-driven development, every line of production code they write is essentially part of an experiment to try and make a unit test pass. This, in turn, is a step on the way to improving the value provided by a program—which can be specified in the form of a target condition, as we describe in Chapter 9.
The Improvement Kata is simply a generalization of this approach to improvement, combined with applying it at multiple levels of the organization, as we discuss when presenting strategy deployment in Chapter 15.
How the Improvement Kata Differs from Other Methodologies
You can think of the Improvement Kata as a meta-methodology since it does not apply to any particular domain, nor does it tell you what to do. It is not a playbook; rather, as with the Kanban Method, it teaches teams how to evolve their existing playbook. In this sense, it differs from other agile frameworks and methodologies. With the Improvement Kata, there is no need to make existing processes conform to those specified in the framework; process and practices you use are expected to evolve over time. This is the essence of agile: teams do not become agile by adopting a methodology. Rather, true agility means that teams are constantly working to evolve their processes to deal with the particular obstacles they are facing at any given time.
SINGLE-LOOP LEARNING AND DOUBLE-LOOP LEARNING
Changing the way we think and behave in reaction to a failure is crucial to effective learning. This is what distinguishes single-loop learning from double-loop learning (see Figure 6-3). These terms were coined by management theorist Chris Argyris, who summarizes them as follows: “When the error detected and corrected permits the organization to carry on its present policies or achieve its present objectives, then that error-and-correction process is single-loop learning. Single-loop learning is like a thermostat that learns when it is too hot or too cold and turns the heat on or off. The thermostat can perform this task because it can receive information (the temperature of the room) and take corrective action. Double-loop learning occurs when error is detected and corrected in ways that involve the modification of an organization’s underlying norms, policies and objectives.”116 Argyris argues that the main barrier to double-loop learning is defensiveness when confronted with evidence that we need to change our thinking, which can operate at both individual and organizational levels. We discuss how to overcome this anxiety and defensiveness in Chapter 11.
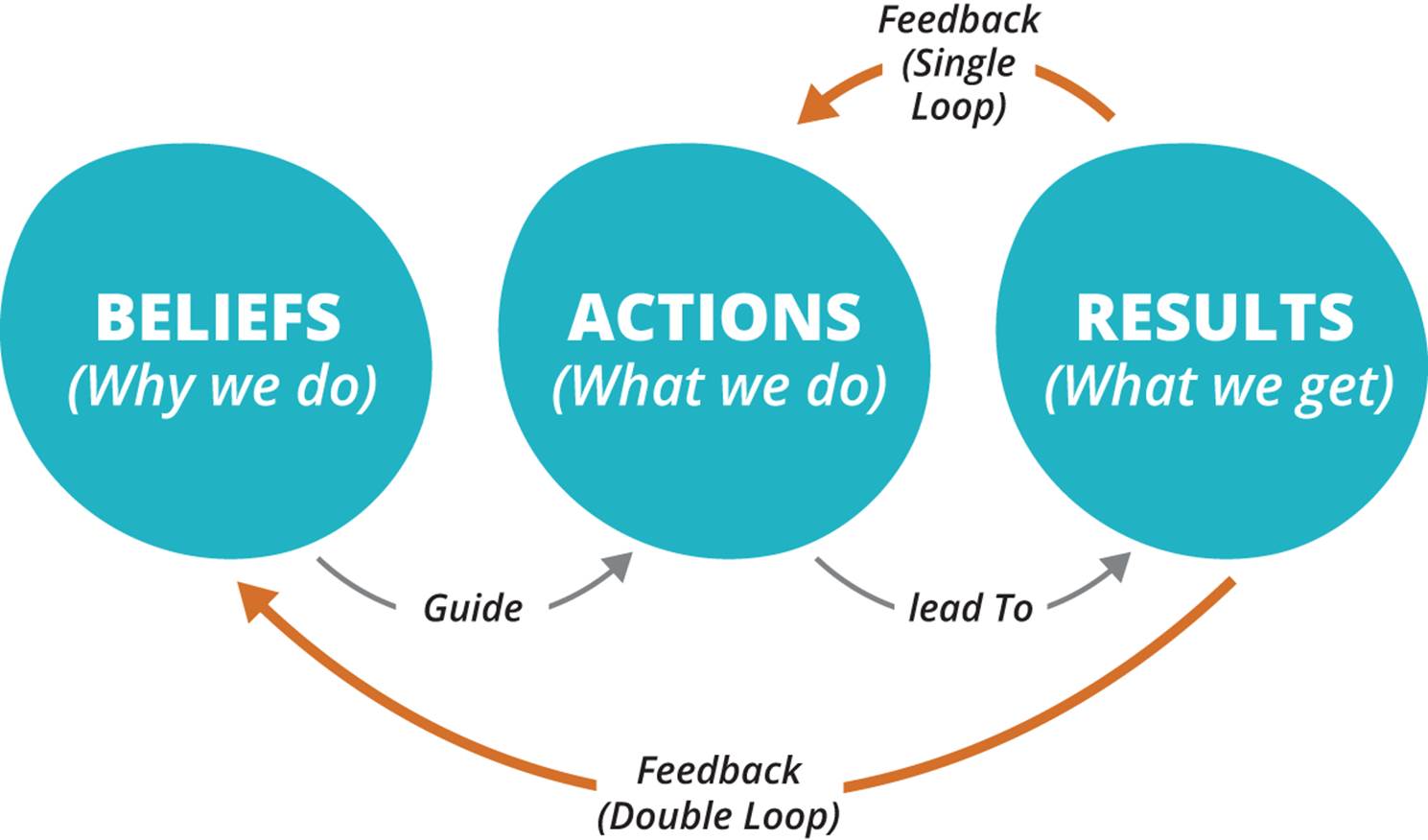
Figure 6-3. Single-loop and double-loop learning
When you practice the Improvement Kata, process improvement becomes planned work, similar to building product increments. The key is that we don’t plan how we will achieve the target condition, nor do we create epics, features, stories, or tasks. Rather, the team works this out through experimentation over the course of an iteration.
DEPLOYING THE IMPROVEMENT KATA
Rother’s work on the Improvement Kata was a direct result of his enquiry into how people become managers at Toyota. There is no formal training program, nor is there any explicit instruction. However, to become a manager at Toyota, one must have first worked on the shop floor and therefore participated in the Improvement Kata. Through this process, managers receive implicit training in how to manage at Toyota.
This presents a problem for people who want to learn to manage in this way or adopt the Improvement Kata pattern. It is also a problem for Toyota—which is aiming to scale faster than is possible through what is effectively an apprenticeship model for managers.
Consequently, Rother presents the Coaching Kata in addition to the Improvement Kata. It is part of deploying the Improvement Kata, but it is also as a way to grow people capable of working with the Improvement Kata, including managers.
Rother has made a guide to deploying the Improvement Kata, The Improvement Kata Handbook, available for free on his website at http://bit.ly/11iBzlY.
How the HP LaserJet Team Implemented the Improvement Kata
The direction set by the HP LaserJet leadership was to improve developer productivity by a factor of 10, so as to get firmware off the critical path for product development and reduce costs.117 They had three high-level goals:
1. Create a single platform to support all devices
2. Increase quality and reduce the amount of stabilization required prior to release
3. Reduce the amount of time spent on planning
They did not know the details of the path to these goals and didn’t try to define it. The key decision was to work in iterations, and set target conditions for the end of each four-week iteration. The target conditions for Iteration 30 (about 2.5 years into the development of the FutureSmart platform) are shown in Figure 6-4.
The first thing to observe is that the target conditions (or “exit criteria” as they are known in FutureSmart) are all measurable conditions. Indeed, they fulfill all the elements of SMART objectives: they are specific, measurable, achievable, relevant, and time bound (the latter by virtue of the iterative process). Furthermore, many of the target conditions were not focused on features to be delivered but on attributes of the system, such as quality, and on activities designed to validate these attributes, such as automated tests. Finally, the objectives for the entire 400-person distributed program for a single month was captured in a concise form that fit on a single piece of paper—similar to the standard A3 method used in the Toyota Production System.
How are the target conditions chosen? They are “aggressive goals the team feels are possible and important to achieve in 4 weeks…We typically drive hard for these stretch goals but usually end up hitting around 80% of what we thought we could at the beginning of the month.”118 Often, target conditions would be changed or even dropped if the team found that the attempt to achieve them results in unintended consequences: “It’s surprising what you learn in a month and have to adjust based on discovery in development.”119
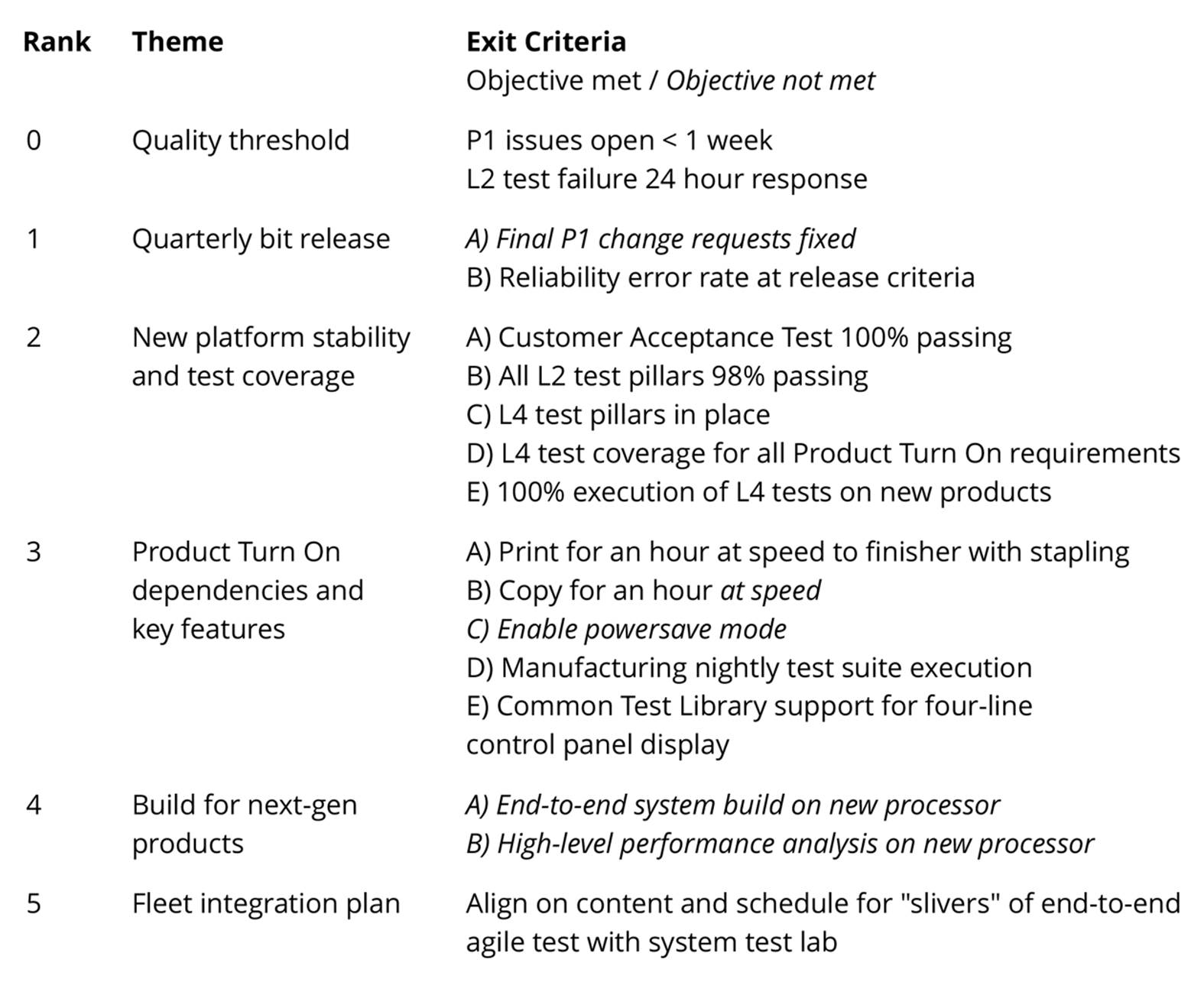
Figure 6-4. Target conditions for iteration 30120
WHAT HAPPENS WHEN WE DO NOT ACHIEVE OUR TARGET CONDITIONS?
In bureaucratic or pathological organizational cultures, not achieving 100% of the specified target conditions is typically considered a failure. In a generative culture, however, we expect to not be able to achieve all our target conditions. The purpose of setting aggressive target conditions is to reveal obstacles so we can overcome them through further improvement work. Every iteration should end with a retrospective (described in Chapter 11) in which we investigate how we can get better. The results form part of the input for the next iteration’s target conditions. For example, if we fail to achieve a target condition for the number of good builds of the system per day, we may find that the problem is that it takes too long to provision test environments. We may then set a target condition to reduce this in the next iteration.
This approach is a common thread running through all of Lean Thinking. The subtitle of Mary and Tom Poppendieck’s book Leading Lean Software Development reads: “Results are not the point.” This is a provocative statement that gets to the heart of the lean mindset. If we achieve the results by ignoring the process, we do not learn how to improve the process. If we do not improve the process, we cannot repeatably achieve better results. Organizations that put in place unmodifiable processes that everybody is required to follow, but which get bypassed in a crisis situation, fail on both counts.
This adaptive, iterative approach is not new. Indeed it has a great deal in common with what Tom Gilb proposed in his 1988 work Principles of Software Engineering Management:121
We must set measurable objectives for each next small delivery step. Even these are subject to constant modification as we learn about reality. It is simply not possible to set an ambitious set of multiple quality, resource, and functional objectives, and be sure of meeting them all as planned. We must be prepared for compromise and trade-off. We must then design (engineer) the immediate technical solution, build it, test it, deliver it—and get feedback. This feedback must be used to modify the immediate design (if necessary), modify the major architectural ideas (if necessary), and modify both the short-term and the long-term objectives (if necessary).
DESIGNING FOR ITERATIVE DEVELOPMENT
In large programs, demonstrating improvement within an iteration requires ingenuity and discipline. It’s common to feel we can’t possibly show significant progress within 2-4 weeks. Always try to find something small to bite off to achieve a little bit of improvement, instead of trying to do something you think will have more impact but will take longer.
This is not a new idea, of course. Great teams have been working this way for decades. One high-profile example is the Apple Macintosh project where a team of about 100 people—co-located in a single building—designed the hardware, operating system, and applications for what was to become Apple’s breakthrough product.
The teams would frequently integrate hardware, operating system, and software to show progress. The hardware designer, Burrell Smith, employed programmable logic chips (PALs) so he could prototype different approaches to hardware design rapidly in the process of developing the system, delaying the point at which it became fixed—a great example of the use of optionality to delay making final decisions.122
After two years of development, the new firmware platform, FutureSmart, was launched. As a result, HP had evolved a set of processes and tools that substantially reduced the cost of no-value-add activities in the delivery process while significantly increasing productivity. The team was able to achieve “predictable, on-time, regular releases so new products could be launched on time.”123 Firmware moved off the critical path for new product releases for the first time in twenty years. This, in turn, enabled them to build up trust with the product marketing department.
As a result of the new relationship between product marketing and the firmware division, the FutureSmart team was able to considerably reduce the time spent on planning. Instead of “committing to a final feature list 12 months in advance that we could never deliver due to all the plan changes over the time,”124 they looked at each planned initiative once every 6 months and did a 10-minute estimate of the number of months of engineering effort required for a given initiative, broken down by team. More detailed analysis would be performed once work was scheduled into an iteration or mini-milestone. An example of the output from one of these exercises is shown in Figure 6-5.
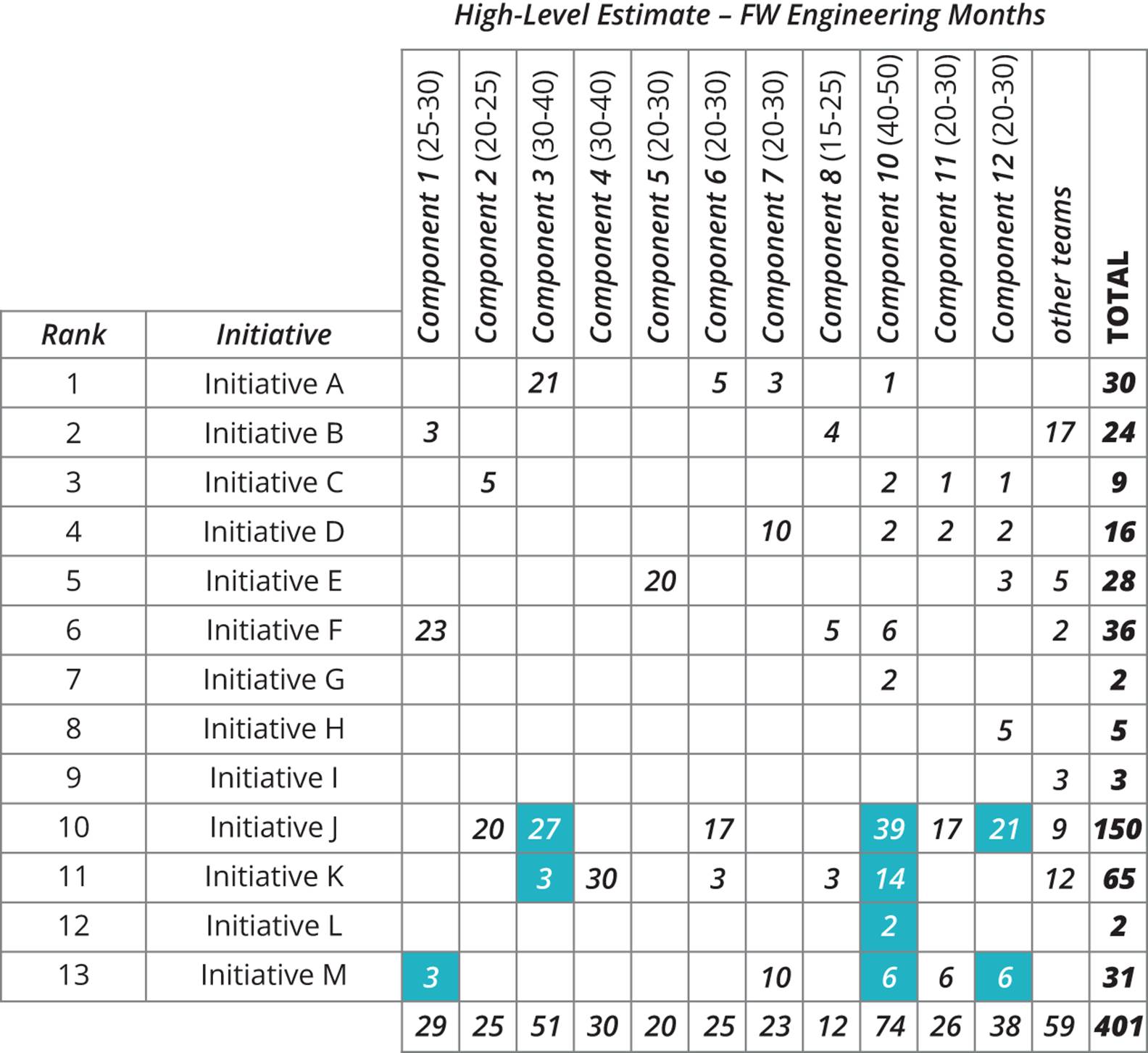
Figure 6-5. Ballpark estimation of upcoming initiatives125
This is significantly different from how work is planned and estimated in large projects that often create detailed functional and architectural epics which must be broken down into smaller and smaller pieces, analyzed in detail, estimated, and placed into a prioritized backlog before they are accepted into development.
Ultimately the most important test of the planning process is whether we are able to keep the commitments we make to our stakeholders, including end users. As we saw, a more lightweight planning process resulted in firmware development moving off the critical path, while at the same time reducing both development costs and failure demand. Since we would expect failure demand to increase as we increase throughput, this is doubly impressive.
Three years after their initial measurements, a second activity-accounting exercise offered a snapshot of the results the FutureSmart team had achieved with their approach, shown in Table 6-2.
|
% of costs |
Activity |
Previously |
|
2% |
Continuous integration |
10% |
|
5% |
Agile planning |
20% |
|
15% |
One main branch |
25% |
|
10% |
Product support |
25% |
|
5% |
Manual testing |
15% |
|
23% |
Creating and maintaining automated test suites |
0% |
|
~40% |
Innovation |
~5% |
|
Table 6-2. Activity of the HP LaserJet Firmware Team in 2011 |
||
Overall, the HP LaserJet Firmware division changed the economics of the software delivery process by adopting continuous delivery, comprehensive test automation, an iterative and adaptive approach to program management, and a more agile planning process.
ECONOMIC BENEFITS OF HP FUTURESMART’S AGILE TRANSFORMATION
§ Overall development costs were reduced by ~40%.
§ Programs under development increased by ~140%.
§ Development costs per program went down 78%.
§ Resources driving innovation increased eightfold.
The most important point to remember from this case study is that the enormous cost savings and improvements in productivity were only possible on the basis of a large and ongoing investment made by the team in test automation and continuous integration. Even today, many people think that Lean is a management-led activity and that it’s about simply cutting costs. In reality, it requires investing to remove waste and reduce failure demand—it is a worker-led activity that, ultimately, can continuously drive down costs and improve quality and productivity.
Managing Demand
Up to now, we’ve been discussing how to improve the throughput and quality of the delivery process. However, it is very common for this kind of improvement work to get crowded out by business demands, such as developing new features. This is ironic, given that the whole purpose of improvement work is to increase the rate at which we can deliver as well as the quality of what gets delivered. It’s often hard to make the outcome of improvement work tangible—which is why it’s important to make it visible by activity accounting, including measuring the cycle time and the time spent serving failure demand such as rework.
The solution is to use the same mechanism to manage both demand and improvement work. One of the benefits of using the Improvement Kata approach is that it creates alignment to the outcomes we wish to achieve over the next iteration across the whole program. In the original Improvement Kata, the target conditions are concerned with process improvement, but we can use them to manage demand as well.
There are two ways to do this. In organizations with a generative culture (see Chapter 1), we can simply specify the desired business goals as target conditions, let the teams come up with ideas for features, and run experiments to measure whether they will have the desired impact. We describe how to use impact mapping and hypothesis-driven development to achieve this in Chapter 9. However, more traditional enterprises will typically have a backlog of work prioritized at the program level by its lines of business or by product owners.
We can take a few different approaches to integrating a program-level backlog with the Improvement Kata. One possibility is for teams working within the program to deploy the Kanban Method, as described in Chapter 7. This includes the specification of work in process (WIP) limits which are owned and managed by these teams. New work will only be accepted when existing work is completed (where “completed” means it is at least integrated, fully tested with all test automation completed, and shown to be deployable).
Managing Cross-Cutting Work
Implementing some features within a program will involve multiple teams working together. To achieve this, the HP FutureSmart division would set up a small, temporary “virtual” feature team whose job is to coordinate work across the relevant teams.
The HP FutureSmart program, some of whose teams were using Scrum, took the approach of specifying a target velocity at the program level. Work adding up to the target velocity was accepted for each iteration, approximating a WIP limit. In order to implement this approach, all work was analyzed and estimated at a high level before being accepted. Analysis and estimation was kept to the bare minimum required to be able to consistently meet the overall program-level target conditions, as shown in Figure 6-5.
DO NOT USE TEAM VELOCITY OUTSIDE TEAMS
It is important to note that specifying a target velocity at the program level does not require that we attempt to measure or manage velocity at the team level, or that teams must use Scrum. Program-level velocity specifies the expected work capacity of all teams based on high-level estimates, as shown in Figure 6-5. If a team using Scrum accepts work based on these high-level feature specifications, they then create lower-level stories with which to work.
Scrum’s team-level velocity measure is not all that meaningful outside of the context of a particular team. Managers should never attempt to compare velocities of different teams or aggregate estimates across teams. Unfortunately, we have seen team velocity used as a measure to compare productivity between teams, a task for which it is neither designed nor suited. Such an approach may lead teams to “game” the metric, and even to stop collaborating effectively with each other. In any case, it doesn’t matter how many stories we complete if we don’t achieve the business outcomes we set out to achieve in the form of program-level target conditions.
In this and the next chapter, we describe a much more effective way to measure progress and manage productivity—one that does not require all teams to use Scrum or “standardize” estimates or velocity. We use activity accounting and value stream mapping (described in Chapter 7) to measure productivity, and we use value stream mapping combined with the Improvement Kata to increase it—crucially, at the value stream level rather than at the level of individual teams. We measure and manage progress through the use of target conditions at the program level, and if we need to increase visibility, we reduce the duration of iterations.
Creating an Agile Enterprise
Many organizations look to try and adopt agile methods to improve the productivity of their teams. However, agile methods were originally designed around small, cross-functional teams, and many organizations have struggled to use these methods at scale. Some frameworks for scaling agile focus on creating such small teams and then adding structures to coordinate their work at the program and portfolio level.
Gary Gruver, Director of Engineering for FutureSmart, contrasts this approach of “trying to enable the efficiencies of small agile teams in an enterprise” with the FutureSmart team’s approach of “trying to make an enterprise agile using the basic agile principles.”126 In the FutureSmart approach, while the teams ran within tight guide rails in terms of engineering practices (which we discuss in more detail in Chapter 8), there was relatively little attention paid to whether they had, for example, implemented Scrum at the team level. Instead, teams have relative autonomy to choose and evolve their own processes, provided they are able to meet the program-level target conditions for each iteration.
This required that engineering management had the freedom to set their own program-level objectives. That is, they didn’t have to get budget approval to pay for process improvement work such as test automation or building out the toolchain for continuous integration. Indeed, the business wasn’t even consulted on this work. All business demand was also managed at the program level. Notably, product marketing requests always went through the program-level process, without feeding work directly to teams.
Another important consideration is the way enterprises treat metrics. In a control culture, metrics and targets are often set centrally and never updated in response to the changes in behavior they produce. Generative organizations don’t manage by metrics and targets. Instead, the FutureSmart management “use[s] the metrics to understand where to have conversations about what is not getting done.”127 This is part of the strategy of “Management by Wandering Around” pioneered by HP founders Bill Hewlett and Dave Packard.128 Once we discover a problem, we ask the team or person having a hard time what we can do to help. We have discovered an opportunity to improve. If people are punished for failing to meet targets or metrics, one of the fallouts is that they start manipulating work and information to look like they are meeting the targets. As FutureSmart’s experience shows, having good real-time metrics is a better approach than relying on scrums, or scrums of scrums, or Project Management Office reporting meetings to discover what is going on.
Conclusion
The Improvement Kata provides a way to align teams and, more generally, organizations by taking goals and breaking them down into small, incremental outcomes (target conditions) that get us closer to our goal. The Improvement Kata is not just a meta-methodology for continuous improvement at the enterprise and program level; it is a way to push ownership for achieving those outcomes to the edges of the organization, following the Principle of Mission. As we show in Chapter 9, it can also be used to run large programs of work.
The key characteristics of the Improvement Kata are its iterativeness and the ability to drive an experimental approach to achieve the desired target conditions, which makes it suitable for working in conditions of uncertainty. The Improvement Kata is also an effective way to develop the capabilities of people throughout the enterprise so they can self-organize in response to changing conditions.
The FutureSmart case study shows how a large, distributed team applied the Improvement Kata meta-method to increase productivity eightfold, improving quality and substantially reducing costs. The processes and tools the team used to achieve this transformation changed and evolved substantially over the course of the project. This is characteristic of a truly agile organization.
Implementing an enterprise-level continuous improvement process is a prerequisite for any ongoing large-scale transformation effort (such as adopting an agile approach to software delivery) at scale. True continuous improvement never ends because, as our organization and environment evolve, we find that what works for us today will not be effective when conditions change. High-performance organizations are constantly evolving to adapt to their environment, and they do so in an organic way, not through command and control.
Questions for readers:
§ Do you know how much time your engineering organization is spending on no-value-add activities and servicing failure demand versus serving value demand, and what the major sources of waste are?
§ Must engineering teams get permission to invest in work that reduces waste and no-value-add activity across the value stream as a whole, such as build, test, and deployment automation and refactoring? Are such requests denied for reasons such as “there is no budget” or “we don’t have time”?
§ Does everyone within the organization know the short- and long-term outcomes they are trying to achieve? Who decides these outcomes? How are they set, communicated, reviewed, and updated?
§ Do teams in your organization regularly reflect on the processes they use and find ways to experiment to improve them? What feedback loops are in place to find out which ideas worked and which didn’t? How long does it take to get this feedback?
108 [schpilberg]
109 This case study is taken from [gruver], supplemented by numerous discussions with Gary Gruver.
110 The distinction between failure demand and value demand comes from John Seddon, who noticed that when banks outsourced their customer service to call centers, the volume of calls rose enormously. He showed that up to 80% of the calls were “failure demand” of people calling back because their problems were not solved correctly the first time [seddon].
111 [rother-2010]
112 [rother]
113 [poppendieck-09], Frame 13, “Visualize Perfection.”
114 [rother]
115 [rother]
116 [argyris], pp. 2-3.
117 [gruver], p. 144.
118 [gruver], p. 40.
119 Ibid.
120 Gruver, Gary, Young, Mike, Fulghum, Pat. A Practical Approach to Large-Scale Agile Development: How HP Transformed LaserJet FutureSmart Firmware, 1st Edition, (c) 2013. Reprinted by permission of Pearson Education, Inc. Upper Saddle River, NJ.
121 [gilb-88], p. 91.
122 http://folklore.org/StoryView.py?story=Macintosh_Prototypes.txt
123 [gruver], p. 89.
124 [gruver], p. 67.
125 Gruver, Gary, Young, Mike, Fulghum, Pat. A Practical Approach to Large-Scale Agile Development: How HP Transformed LaserJet FutureSmart Firmware, 1st Edition, (c) 2013. Reprinted by permission of Pearson Education, Inc. Upper Saddle River, NJ.
126 [gruver], Chapter 15.
127 [gruver], p. 38.
128 Perhaps it’s better characterized as “Management by Wandering Around and Asking Questions.” In the Toyota Production System, this is known as a gemba walk.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.