eCommerce in the Cloud (2014)
Part III. To the Cloud!
Chapter 10. Deploying Across Multiple Data Centers (Multimaster)
The focus of this chapter is taking a single ecommerce platform and running it out of two or more physical data centers that are geographically separated from each other. While the assumption is that these data centers are within a cloud, most of the principles discussed are applicable to traditional hosting arrangements. We’ll start by discussing the fundamental problem of running eCommerce from multiple data centers, the architecture principles underpinning distributed computing, how to assign customers to individual data centers, and finally the various approaches to operating from multiple data centers.
Many ecommerce vendors already operate out of two data centers in some capacity to ensure the highest possible availability. This trend will only accelerate over the coming years as ecommerce platforms are becoming increasingly important to business. In today’s omnichannel world, an outage increasingly has the effect of shutting down every single channel you have for generating revenue. It used to be that a website failure would, of course, be unpleasant but it was isolated to that channel. Now, many point-of-sale systems, kiosks, and mobile applications, all use the same underlying platform. Outages today tend to be platform-wide and thus affect all channels.
TIP
Next to a security breach, an extended outage or repeated outages are the surest way to become unemployed.
Deploying the same platform across two or more data centers in an active/passive or multimaster configuration helps to ensure availability by providing resiliency against natural disasters (e.g., hurricanes, typhoons, fires, floods), human errors (e.g., cable cuts, misconfigurations), upstream outages (e.g., loss of power, loss of Internet connectivity), and software problems (e.g., bugs, upgrade challenges). It’s highly unlikely, for example, that any two data centers in the world are likely to be affected by the same fire or cable cut. There’s supposed to be redundancy within each data center, and generally it works very well. But would you trust your job to your cloud vendor and the safeguards that vendor has employed in each data center? As we’ve repeatedly seen, the only way to ensure availability is to use multiple data centers, preferably as far apart as possible.
Historically, ecommerce platforms have been designed for the best possible availability, usually just within a single data center. This focus on availability has precedence: retail point-of-sale systems. Most point-of-sale systems have two or more unique methods of connecting back to the home office to perform critical functions such as charging credit cards and issuing returns. Dial-up is still commonly used as a backup. If the primary and backup fail, many retailers will continue to accept orders under $25 or $50 and then run the credit card authorizations through later, when the connection can be reestablished. While it’s possible a few charges aren’t successfully authorized, the loss is likely to be lower than the cost of not being open for business.
Many ecommerce systems function the same way: if the payment gateway, inventory management system, or some other system is down, the system can still collect orders but wait to actually charge credit cards, decrement inventory, and so forth. An advantage ecommerce transactions have is that any problems discovered can be corrected before the goods are shipped. In a physical retail store, customers walk out with the products. If you later discover that a credit card authorization was unsuccessful, you can’t get the products back.
While the need for availability is increasing, cloud and its prerequisites make it even easier and more affordable to operate from multiple data centers. Auto-scaling (Chapter 4), installing software on newly provisioned hardware (Chapter 5), solid architecture (Chapter 8), and Global Server Load Balancing (this chapter) are all fundamental to operating out of multiple data centers.
The cloud itself and the elasticity it brings make operating from multiple data centers incredibly inexpensive. Prior to cloud computing, each data center you operated from had to have enough hardware to be able to support 100% of production traffic in case one of the data centers had an outage. All of this hardware typically sits idle for all but a few minutes of the year. Building up an entire second (or third) replica is enormously expensive—both in terms of up-front capital outlay and ongoing maintenance. The introduction of the cloud completely changes this. You can have a shell infrastructure in place and rapidly scale it up in the event of a failure. All of this depends on how well you install software on newly provisioned hardware, how good your architecture is, whether you’ve employed Global Server Load Balancing, and how well you can auto-scale. Without meeting these prerequisites adequately, you shouldn’t even attempt this. Like the cloud itself, the adoption of a multimaster architecture only exacerbates technical and nontechnical deficiencies.
The Central Problem of Operating from Multiple Data Centers
The central problem with operating from multiple data centers that’s fairly unique to ecommerce is that you can have multiple customers logging in, using the same account (e.g., username/password combination) from different data centers. Each account has its own customer profile, shopping cart, and other data. This data is stored in a database of some sort, with all of that data needing to be replicated across the various data centers a platform is being served from. None of the core data in ecommerce, such as customer profiles and shopping carts, can be lost.
The problem that multiple concurrent logins creates is that if two customers update the same data at the same time from two different locations, one customer’s action is going to succeed and the other is going to fail, possibly corrupting data along the way. Because of latency, a database in one data center doesn’t know in real time what’s going on in a database in another data center. Unless you block concurrent logins, there will always be the problem of multiple updates from different data centers (see Figure 10-1).
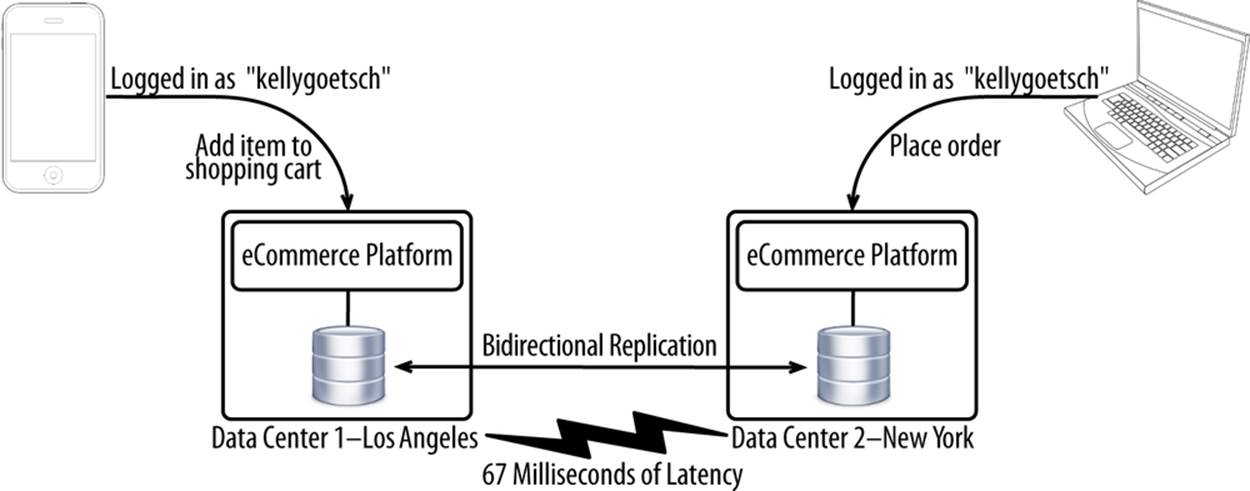
Figure 10-1. The central problem of multimaster
It’s surprisingly common to have multiple concurrent logins for the same account in different data centers. It can happen when customers share their logins within families, with friends, and increasingly, with social media. Loyal customers get special discounts, so there’s a strong incentive to share login credentials to secure a better deal or simply out of convenience. This issue can also happen when contact center agents are modifying an order the same time a customer is. Imagine a scenario where a customer calls in to a contact center to update an order but actively continues to try to fix the problem while on the phone. These scenarios are common. The cost of a failure is generally corrupted data.
This problem is only increasing as:
§ Customers transact across more channels from more devices.
§ ecommerce vendors target segments or specific customers for promotions, thus increasing the incentive to share accounts.
§ Social media continues to enable customers to share accounts.
The way to reduce (but not eliminate) the likelihood of this scenario happening is to use accurate proximity-based Global Server Load Balancing, which ensures that customers in the same city, state, collection of states, country, or continent all hit the same data center. So if a customer is in one room on an iPad shopping and his daughter is in the other on a laptop, the two should at least hit the same data center and transact against the same database. We will discuss this shortly.
Architecture Principles
While there are methods to reduce the likelihood of collisions from occurring, the problem needs to be comprehensively addressed. You’ll corrupt your data and upset customers if you do nothing or if you implement a poor solution.
The principle to adhere to is to ensure that all customers logged in to the same account are updating the same database (or other system of record) within a single logical database.
NOTE
You can have two or more active databases with full bidirectional replication, but all writes for a given account must hit the same logical database within the same data center.
Two factors will largely determine the approach you choose:
Recovery time objective (RTO)
How quickly must you recover from the failure of a data center? Values range from zero to many hours, depending on the approach you choose. If you deploy out of only one data center, this value could be weeks. Active/passive is typically at least an hour. Forms of active/active usually offer zero downtime, even in the event of an entire data center outage. The lower the RTO, the more work and the greater the expense.
Ability to execute
How good are you and your organization at doing difficult things? This is all very complicated, especially with the cloud thrown in the mix. Implementation requires considerable technical expertise, time, full organizational support, and plenty of money. If you’re struggling with keeping the platform available from one data center that you manage, deploying it across two or more data centers in a cloud isn’t something you should even consider.
Recovery point objective (RPO) defines how much data can be lost and is usually a staple of business continuity planning. However, nobody involved with ecommerce is OK with anything less than zero for core data such as customer profiles and shopping carts. Data loss is simply not acceptable for certain classes of data. The principles and approaches in this chapter are all oriented around this assumption.
Principles Governing Distributed Computing
There’s an enormous amount of academic and industry literature on the computer science behind distributed computing. An in-depth discussion of these principles is not in the scope of this book, but a brief overview of the principles and the trade-offs involved in distributed computing are in order before continuing.
Consistency models govern the conditions under which a write in a distributed database will be visible to other readers.[65] A distributed database could be a single database instance comprised of multiple nodes or multiple database instances in different data centers. Databases tend to follow one consistency model, or a variation of that model. Consistency models apply to all distributed computing problems in computer science, from filesystems to memory.
Strong consistency, known as ACID, stands for the following:[66]
Atomicity
The whole transaction either succeeds or fails.
Consistency
A transaction is committed without violating any integrity constraints (e.g., data type, whether column is nullable, foreign-key constraints).
Isolation
Each transaction is executed in its own private sandbox and not visible to any other transaction until it is committed.
Durability
A committed transaction will not be lost.
The assumption would be that all transactions should be ACID compliant, but that’s often unnecessary. For example, product-related data (e.g., description, attributes, and search engine optimization–related metadata) can probably be written on one node in one database and propagated across other nodes and databases asynchronously. If readers see inconsistent data for a few seconds, it’s probably not a big deal. Very little data needs to be strongly consistent. Customers won’t tolerate not seeing customer profile and order-related changes reflected immediately. Core customer data should always be stored in an ACID-compliant database. By forcing all customers logged in to the same account to use the same database, you ensure strong consistency for a specific customer’s data across database instances.
Weak consistency, known as BASE, eschews the tight confines of ACID:[67]
Basic Availability
The system is generally available for updates.
Soft-state
Data is not durable—it may reside in memory and could be lost in the event of a failure.
Eventual consistency
A reader may not see the most up-to-date copy of data, as replication happens asynchronously.
BASE is becoming increasingly common as writes are much faster and systems are much more scalable, with the trade-off in consistency that is good enough for many types of data. All of the popular social media platforms are mostly BASE. Again, only a relatively small subset needs full ACID compliance.
There’s a continuum between ACID and BASE. You have to pick what works best for you and each type of data you need to store. Often databases themselves allow you to specify the desired consistency model on a fairly granular basis. Clearly, BASE is probably good enough for writing an audit log, whereas ACID is required for orders. But what about things like inventory and prices? That’s a bit of a grey area. Careful consideration and then implementation is required. Table 10-1 provides a quick summary of the two approaches to consistency.
Table 10-1. ACID/strong consistency vs. BASE/weak consistency
|
ACID/strong consistency |
BASE/weak consistency |
|
|
Defining adjectives |
Synchronous, smart, slow |
Asynchronous, dumb, fast |
|
Design priorities |
Data validity |
Availability/Scalability/Performance |
|
Examples |
ecommerce orders, online banking |
Caching, DNS |
|
Database implementations |
Traditional relational databases |
Object-based key-value stores/NoSQL |
|
Consistency |
Immediate |
Eventual |
No discussion of consistency models is complete without a brief discussion of Eric Brewer’s CAP theorem, which states any distributed system can guarantee two of the following three:[68]
Consistency
No data conflicts
Availability
No single point of failure
Partition tolerance
System maintains availability and consistency if a network problem isolates part of the system
Distributed systems, especially with cloud computing, cannot guarantee partition tolerance because connections between databases are inherently unreliable. Therefore, you have to make a trade-off between consistency (favors ACID) and availability (favors BASE). You can’t have both.
For more information on this topic, read Cloud Architecture Patterns by Bill Wilder (O’Reilly).
Avoiding conflicts
Bidirectional database replication tools all have the ability to detect and resolve conflicts. Conflict detection and resolution is an integral part of these offerings. If two customers are updating the same order at the same time from two data centers 100 milliseconds apart, and they both update the same record at the same time within that 100-millisecond window, there will be a collision. Likewise, if two customers are updating the same object (such as a customer profile or an order), there will also be a collision. The following examples illustrate this potential issue.
Customer 1, account “kellygoetsch,” data center A:
updateorderset submitted = 1 where order_id='12345';
(100 milliseconds of latency)
Customer 2, account “kellygoetsch,” data center B:
insertinto order_lines (order_id, sku_id, quantity)
values ('12345', '54321', 1);
In this example, two customers are performing opposing actions: one is submitting an order (executing final pricing, submitting it to a backend system), while the other is adding another item to the order. This obviously will lead to problems. You can’t add an item to the order if the order is submitted but the other customer doesn’t know it’s been submitted yet because of that 100 milliseconds of latency. This example highlights the central problem with conflict detection and resolution. Yes, it often can technically work, but the results may not be as you expected. Would this customer’s order ship with SKU 54321 included? Would her credit card be charged? Did this customer want that item to be added to the cart, or was it her child who was playing on an iPad in the other room? Who knows. That’s the problem.
A more technical issue is that most ecommerce platforms write to the database through an object-relational mapping (ORM) system. These systems allow your code to interact with actual objects represented in code, as opposed to SQL. For example, you can callorder.setProperty("submitted", true) as opposed to manually constructing the update order set submitted = 1 where order_id=12345; SQL by hand. These systems produce an enormous number of SQL statements, as they’re built for maximum flexibility and portability, as opposed to SQL efficiency. With a single action (e.g., add to cart) producing potentially dozens of individual SQL statements, you can run into potential inconsistencies as some of the updates and inserts succeed, while others fail. It’s hard, if not impossible, to demarcate actions based on database transaction. SQL statements tend to flow from applications down to the database in messy, overlapping, overly granular transactions, or with no transactions at all. It’s exceedingly difficult to demarcate an action (e.g., adding an item to a cart) with clear database transaction boundaries.
Even if you did manage to get conflict resolution and detection working, you would deal with the issue of cache staleness. Platforms liberally cache data at all layers. How do you refresh those higher-level, object-level caches when a change is applied through database replication? Caches are usually set to update only if the change is made through the ORM layer. But when the change is applied directly to the database, it’s tough to tell the platform how to update its caches.
If you don’t use a traditional relational database, you still have many of these same problems but just in a different form. When you’re dealing with objects or key-value pairs, you end up overwriting more data because these systems aren’t as granular as a proper relational database with normalized data. You’ll just overwrite the whole order as opposed to a property of the order, but that’s just as bad because of all the inter-dependencies between objects.
The only way to ensure consistency is to make sure that all customers logged in to the same account are updating the same database or other system of record. That still has challenges, but it’s at least the status quo, and those issues can be dealt with.
Selecting a Data Center
Prior to cloud computing, the fixed cost to operate from a data center was very high. You had to physically build the data center or lease some space in an existing data center. Then you had to statically build out your environment, such that it could handle 100% of the production load in the event it was the sole data center or that another data center went offline. The cloud makes it exceedingly easy to run from multiple data centers by eliminating the overhead of operating from a new data center and by allowing you to elastically scale up. No longer do you have to scale up an environment only to have it sit entirely idle. From an API standpoint, the data center is often just one more variable.
The optimal number of data centers to operate from is two or three. Anything more than that is fairly wasteful. Anything less than that, and you don’t have enough redundancy to guard against outages. Many cite wanting to reduce latency as a reason for building out so many data centers. As we discussed in Chapter 7, the server-side response time and latency are a small fraction of the total time it takes for a page to display. Customers routinely access ecommerce platforms hosted on different continents. Just because the cloud offers the ability to easily use many data centers doesn’t mean you should.
Cloud vendors have many data centers around the world, but they can be segmented by the concept of a fault domain. Each vendor has its own name for this concept, but what it amounts to is that there are few to no dependencies or connections between data centers in different fault domains.This isolation should stop issues from propagating across different domains, thus ensuring the highest level of availability. For example, software upgrades tend to happen based on fault domains. You should always pick data centers that are geographically separated (to avoid the same natural disaster, power outage, or fire) but that also are in different fault domains. Again, all you need are two (or maybe three) data centers, but they must be properly chosen.
Cloud-wide outages are exceptionally rare but do occur, as discussed in Chapter 3. To protect yourself against a cloud-wide outage, you can deploy to multiple cloud vendors. It’s counterintuitive, but that may actually reduce your uptime, as two vendors creates at least double the complexity. Complexity and misconfiguration arising from complexity is the number one cause of outages. When coupled with the extremely high availability, running across two data centers may not give you the extra boost in availability you’d expect.
Initializing Each Data Center
The use of the cloud for ecommerce differs substantially from traditional static deployments because of the elasticity that the cloud provides. You no longer need to scale up each of your data centers to handle 100% of your production load. You can now scale up and down freely to meet real-time demands. The problem with that approach is that in the event of a sudden failure, the surviving environment(s) is unlikely to have enough capacity pre-provisioned to handle the sudden rush of traffic. At this point, your auto-scaling system should kick in (see Chapter 4) to start provisioning more hardware. Once the hardware is provisioned, each server must have software installed on it per Chapter 5. Provisioning hardware and then building each server takes time—potentially tens of minutes.
You must set up each cloud data center ahead of time with a skeletal structure that you can then scale out. It’s not practical to build up a whole new data center on the fly in response to an outage. But it is practical to take something that’s in a data center and scale it out very quickly. Each data center should contain at least two instances (for redundancy) of everything you need for your environment to function—from a cache grid, to application servers, to a service bus. Think of this environment as being the size of a development environment but configured for production. This can all be on dedicated hardware, as opposed to the hourly fees normally charged. Dedicated hardware is often substantially cheaper than per-hour pricing, but using dedicated hardware requires up-front payment for a fixed term, usually a year. Again, this should be a fairly small footprint, consisting of only a handful of servers. The cost shouldn’t be much.
If you’re deploying your own relational database, it needs to be built out ahead of time. It’s hard to add database nodes for relational databases in real time, as entire database restarts and other configuration changes are often required. A database node for a relational database isn’t like an application server or web server, where you can just add another one and register it with the load balancer. Databases offered by cloud vendors are more elastic, but of course there are downsides to using shared resources. Your database utilization should be fairly light if you have the right architecture in place. The vast majority of page views are from anonymous customers (or search engine bots) for static cacheable pages, such as home pages and category detail pages. You can offload most reads to slave databases. Full use of a cache grid helps. Your core database for transactional data (e.g., orders, customer profiles) ends up being fairly small, usually no more than a few nodes using no more than a few terabytes of storage.
Removing Singletons
Every platform, it seems, has software that may be deployed on exactly one server per environment. Common examples include coordination servers, messaging servers, lock brokers, administrative user interfaces, and servers that execute batch jobs. These instances, known as singletons, are a classic example of Pareto’s principle, whereby you spend 80% of your time on 20% of your servers. The 20% tends to be singletons.
Problems with singletons include the following:
§ They may be a single point of failure. You’ll have to spend extensive time and effort to ensure the highest possible availability.
§ Each server must generally point to the singleton, either with a unique name, URL, IP address, or domain name. It takes a lot of work to update dozens, if not hundreds, of individual servers every time the name or location of the singleton changes.
§ Some singletons must be unique to an environment, while others must be unique to a database. If a singleton must be unique to an environment, at least half of the requests to that singleton must be made cross–data center. If a singleton is unique to a database, you’ll potentially have to deal with database replication conflicts as each singleton updates its own database and the data is unidirectionally replicated between the two.
§ With active/active, you’ll have to activate the singleton in the newly active data center following a failover.
§ As your environment grows, your singleton may run into limits as to how far it can be vertically scaled. In a normal environment that you control, you can throw a lot of hardware at problems like this. In a cloud, you’re limited to the maximum amount of hardware the vendor offers you for a single server.
§ You must create a deployment unit (Chapter 5) for that singleton.
It’s best to architect your solution to avoid singletons entirely, or if they must exist, allow any instance to assume that responsibility. For example, rather than have a dedicated server that is responsible for periodically rebuilding a search index, each server that responds to queries could build a small part of the index on the side. Or, have your nodes nominate one node to perform that task periodically. Architecture that doesn’t rely on singletons tends to be better by almost every measure.
Never Replicate Configuration
Avoid the temptation to replicate configuration, whether it happens to be in a database or a filesystem. It makes logical sense to replicate everything, but keep in mind that most outages are caused by the introduction of bad configuration. If you replicate configuration, you just replicate the problem. This is exactly the reason you don’t deploy code to two or more data centers simultaneously. Wait to see how it works out and then deploy it elsewhere. The same applies for configuration.
Assigning Customers to Data Centers
DNS
DNS primer
As we briefly discussed in Chapter 2, DNS exists so customers don’t have to remember IP addresses. Instead, they can remember short names like website.com, which are paired up with IP addresses. Each data center you operate from is typically exposed to the world as a single IP address.
At the heart of the system is a record. A standard record looks something like Figure 10-2.

Figure 10-2. Sample “A” record
Each domain name has an authoritative DNS server, which is the sole source of truth for that domain name. Your client (e.g., web browser, mobile device) will probably have its own cache of DNS records. Your client’s operating system likely has its own cache. Your ISP most likely has DNS servers, which also cache records. DNS servers recursively cascade the resolution request up to the authoritative DNS server, with each intermediary caching the record along the way. Each record has a time to live (TTL), designating how long a record can be cached by any intermediary between the client and authoritative server. TTL values range anywhere from zero seconds to several days, with records typically expiring after five minutes. DNS is an eventually consistent system, whereby records may be stale for a period not to exceed the TTL.
DNS does support multiple A records, meaning you can have website.com resolve to two or more unique IP addresses, with each IP address representing a data center. Results are ordered, so that the first IP address returned is supposed to be the first IP address the client connects to.
Every website on the Internet needs an authoritative DNS server. You can self-host DNS or outsource to a DNS Software-as-a-Service vendor. Software-as-a-Service vendors include standalone vendors, your cloud vendor, or your CDN vendor. All typically offer some form of DNS. Definitely use a third-party vendor for DNS. The risk of outages are too high to self-host DNS.
DNS, while an incredibly resilient and innovative system, has shortcomings:
§ Inability to load balance with any real intelligence. You’re limited to round-robin or basic algorithms of that nature.
§ Inability to determine whether the IP addresses you’ve put in your record actually work. That determination is left to clients, which don’t do it at all or do it poorly.
§ Intermediaries between the authoritative DNS server and client can change the order of the IP addresses in an attempt to load balance. This is very bad for active/passive.
§ Intermediaries extending to the client itself can ignore the TTLs you specify in an attempt to reduce DNS queries.
Global Server Load Balancing (GSLB), which we’ll discuss shortly, seeks to address many of the deficiencies in plain DNS.
Assigning customers to a single data center
Until fairly recently, most large ecommerce platforms were served out of only one data center, with a single virtual IP address (VIP) exposed for that one data center. With one data center, you can just use plain DNS to tie your friendly domain name (website.com) to the IP address (161.170.248.20). You could set TTL of a few hours and, provided you had a reliable DNS vendor, never think about DNS again.
Your DNS record would look something like that shown in Figure 10-3.
Figure 10-3. Sample record with one IP address returned
Active/passive data center assignment
With the addition of passive data centers in an active/passive configuration, you have to lower your TTL so changes can take effect quickly. If you have a 12-hour TTL, it could be up to 12 hours for any DNS changes to take effect. A TTL of a few minutes works well. Anything shorter than that, and you force your clients to unnecessarily query DNS servers, which harms performance. Following the proper TTL, you then have to be able to publish updates to your DNS record quickly in the event you need to failover from your primary data center to your standby data center.
Your DNS record would look something like Figure 10-4.

Figure 10-4. Sample record with one IP address returned
As previously mentioned, DNS does support multiple A records, meaning you can have website.com resolve to two or more unique IP addresses, with each IP address representing a data center. Results are ordered, so that the first IP address returned is supposed to be the first IP address the client connects to. The three problems with that approach for active/passive are as follows:
§ You can’t guarantee that the order of IP addresses won’t be changed by an intermediary.
§ You can’t guarantee that the clients will always connect to the first IP address listed.
§ Short outages may occur, as there are hiccups in Internet connectivity and the like. You don’t want clients connecting to your passive data center until you flip the switch by publishing an updated A record.
TIP
Any IP address in your A record can be connected to at any time by any client. There are no guarantees.
Instead, it’s best to use proper GSLB with in-depth health checking, or use standard DNS but have only one IP address listed in your A record. GSLB will be discussed shortly.
Active/active data center assignment
When two or more data centers are actually receiving traffic from customers, each customer must be presented with an accurate ordered list of IP addresses that the client should try connecting to. DNS does support having multiple A records, but this feature should be used only when it is acceptable for a client to connect to any IP address returned. Clients are supposed to connect in the order the IP addresses are returned, but it’s entirely possible that an intermediary changed the order of the IP addresses or that a client disregards the order of the addresses that are returned. TTLs tend to be fairly low too, as you want to be able to quickly push changes in the event of a failure.
Your DNS record would look something like Figure 10-5.

Figure 10-5. Sample record with two IP addresses returned
Again, clients can connect to any IP address listed, so make sure you return IP addresses that can actively handle traffic.
Global Server Load Balancing
Global Server Load Balancing primer
GSLB amounts to very intelligent DNS that can pick the optimal data center for a given customer. Factors it uses can include the following:
§ Availability of a data center (both whether IP responds to pings as well as more in-depth health checking)
§ Geographic location of the client
§ Roundtrip latency between the client and each data center
§ Real-time capacity of each data center
§ A number of load-balancing algorithms
The most substantial difference from standard DNS is that it allows you to do much more advanced health checking of a data center, with the ability to automatically drop a data center in real time if it becomes unhealthy. With standard DNS, the only health checking involved is entirely performed on the client side. If a client cannot connect to the IP address returned in the A record, it continues on to the next one in the list. Each client performs this checking slightly differently or sometimes not at all. Worse yet, there are numerous ways an IP address could respond to a ping but not be healthy. Clients don’t know the difference between HTTP 200, 404, and 500 responses, for example. GSLB assumes those health-checking responsibilities from the client and can perform a much more thorough interrogation as to the health of a data center. We’ll talk about that in , but broadly you should apply the health-checking approach from Chapter 5 to an entire data center and configure your GSLB service to probe that page to test the health of a data center. If you’re running your platform from two or more data centers, the benefit is that failover happens automatically, without any interaction. Pushing DNS records manually takes time.
In addition to health checking, a GSLB’s ability to pinpoint the location of a customer can be incredibly beneficial. Uses include the following:
§ Directing customers to the closest data center best able to service their requests. This improves performance and increases conversion rates.
§ Making the concurrent login problem discussed earlier in this chapter much less likely to occur. With two data centers and no geolocation, any two customers sharing the same account have a 50% chance of hitting the same data center. With proper geolocation offered by GSLB, you reduce the problem substantially. People in the same household, city, state, or region, are far more likely to be sharing logins, and with proper geolocation are far more likely to hit the same data center.
§ You can personalize the experience for customers. For example, you may want to show your Wisconsin customers winter gloves and your Florida customers swimming suits in January.
§ You may need to restrict certain functionality based on the physical location of a customer. For example, a promotion may be legal in one state but illegal in another. Rather than show customers a contest that they cannot participate in, it’s best to simply remove it for those where it is illegal.
§ You can roll out functionality slowly. Say you’re cutting over to a new platform. You can do it on a city-by-city basis as you pilot it. This is how consumer packaged-goods companies test out new products.
GSLB can be offered like DNS—self-hosted or as a service. When hosted in-house, it’s often through the use of hardware appliances. These appliances likely cannot be used in a cloud. Like DNS, it’s best to choose a GSLB Software-as-a-Service vendor rather than trying to do it in-house.
CDNs that offer GSLB are best because they can respond to customers’ requests from the edge rather than from a centralized server. That leads to improved performance, as every customer will be making a request to the authoritative DNS server at the beginning of the session. With traditional DNS, there’s far more caching involved because the same record can be used for every customer. GSLB returns a unique record for each customer.
CDNs that serve as a reverse proxy also have a substantial advantage over standard DNS for the full active/active approach, whereby a small fraction of customers are forcibly moved from one data center to another. Rather than try to force you to switch IP addresses for a given domain name, you can instead instruct your CDN to proxy the requests at the edge, as shown in Figure 10-6.
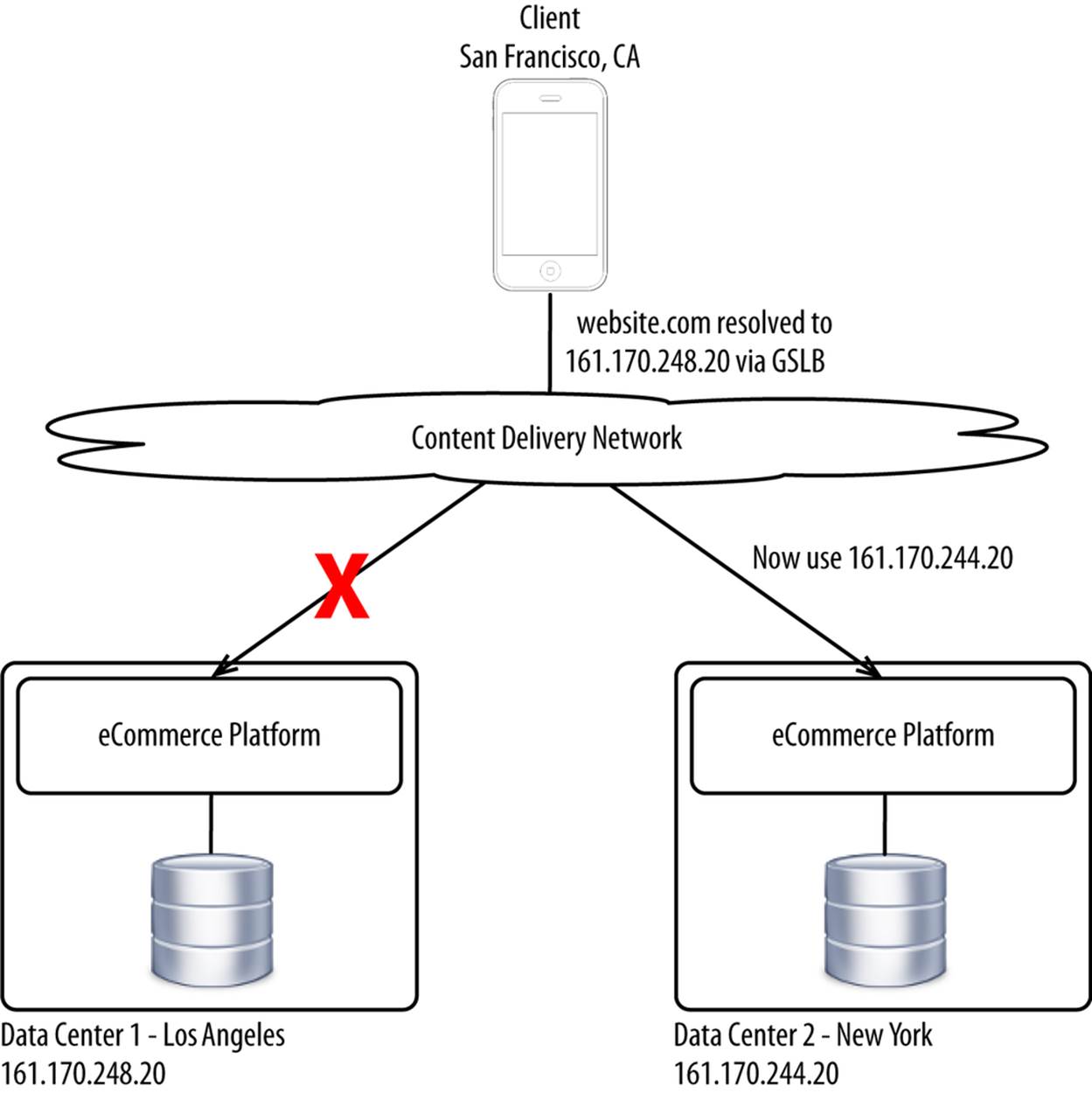
Figure 10-6. Edge-based proxying
Even though a client may still map website.com back to the wrong IP address, your CDN will simply ignore it and redirect the request to the right data center. The CDN can be told of this change through an HTTP response header, cookie, or similar.
Traditional appliance-based GSLB solutions offer this through proxying. A request may hit the wrong data center, but the appliances can cooperate to proxy the request over to the right data center. The downside is you’ll always be proxied through an intermediary data center, perhaps traveling thousands of miles out of the way with each request.
Global Server Load Balancing health checking
Just as we discussed health checks for individual deployment units (Chapter 5) within a data center, you’ll need to health check an entire data center in a way that makes sense for your platform.
For a single application server, representative tests include these:
§ Querying the cache grid for a product
§ Adding a product to the shopping cart
§ Writing a new order to a database and then deleting it
§ Querying the service bus for inventory availability
§ Executing a query against the search engine
If all of the tests came back OK, the response would be the string PASS. Otherwise, the response would come back FAIL. You can configure load balancers to poll for an HTTP 200 response code and PASS in the response. A simple TCP ping isn’t good enough.
The same concept holds true for assessing the health of an entire data center (see Figure 10-7). Responding to a simple TCP ping tells you nothing about its health. It’s best to build a small standalone web application to poll the dynamic health-check pages of each stack and any other monitoring points. If, say, 75% of the tests come back as a PASS, then report PASS. Have your GSLB query for this page and make it highly available.
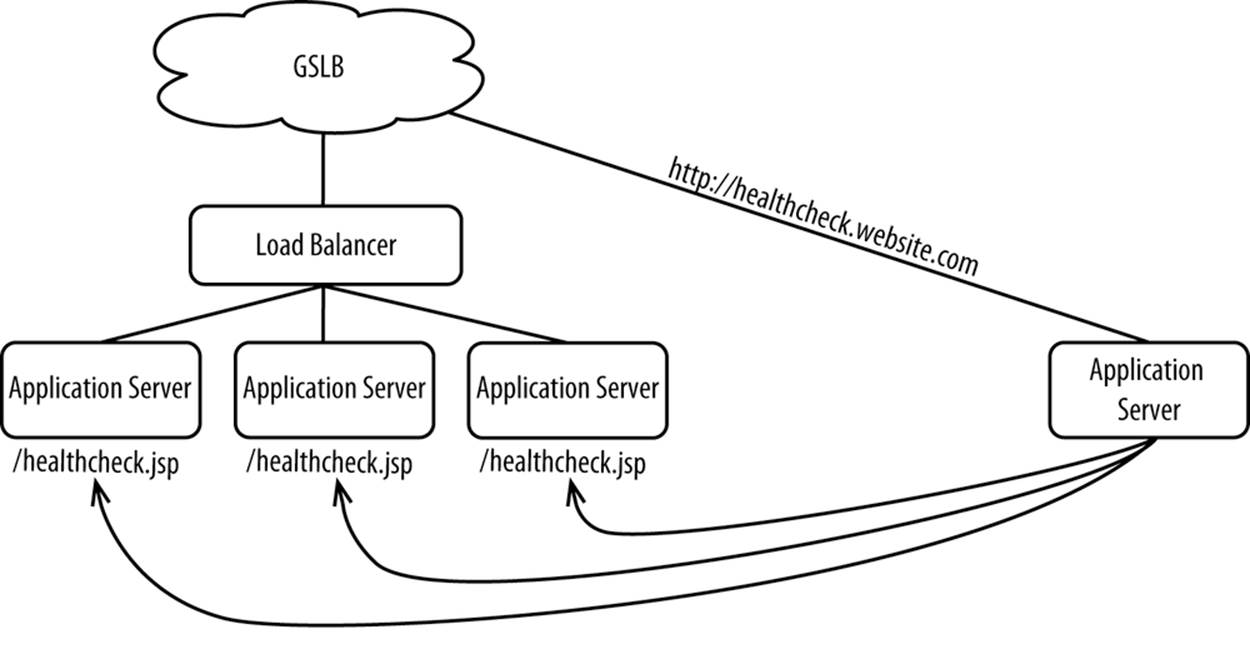
Figure 10-7. Health checking a data center
Whereas in the past you had to check the capacity of each data center, you no longer need to do that because you can scale each data center out as required. In other words, the capacity of each data center will be dictated by the amount of traffic GSLB gives it as opposed to how much capacity the data center reports back to GSLB.
Approaches to Operating from Multiple Data Centers
Pragmatism should be your guiding force as you operate from two or more data centers and, more generally, as you adopt cloud computing. It’s important to do your research and then do what works well for you. The approaches outlined here are simply starting points, meant to be customized and extended to suit your exact needs. Broad approaches are described in the following sections.
Active/Passive
This approach is fairly traditional, whereby only one application tier and database tier in a data center are active at a time (see Figure 10-8). One data center is active, and the other is passive. Replication is often limited to just the database and is unidirectional. A data center failure is unlikely to result in any data being lost (called recovery point objective) but is very likely to result in lengthy downtime (called recovery time objective).
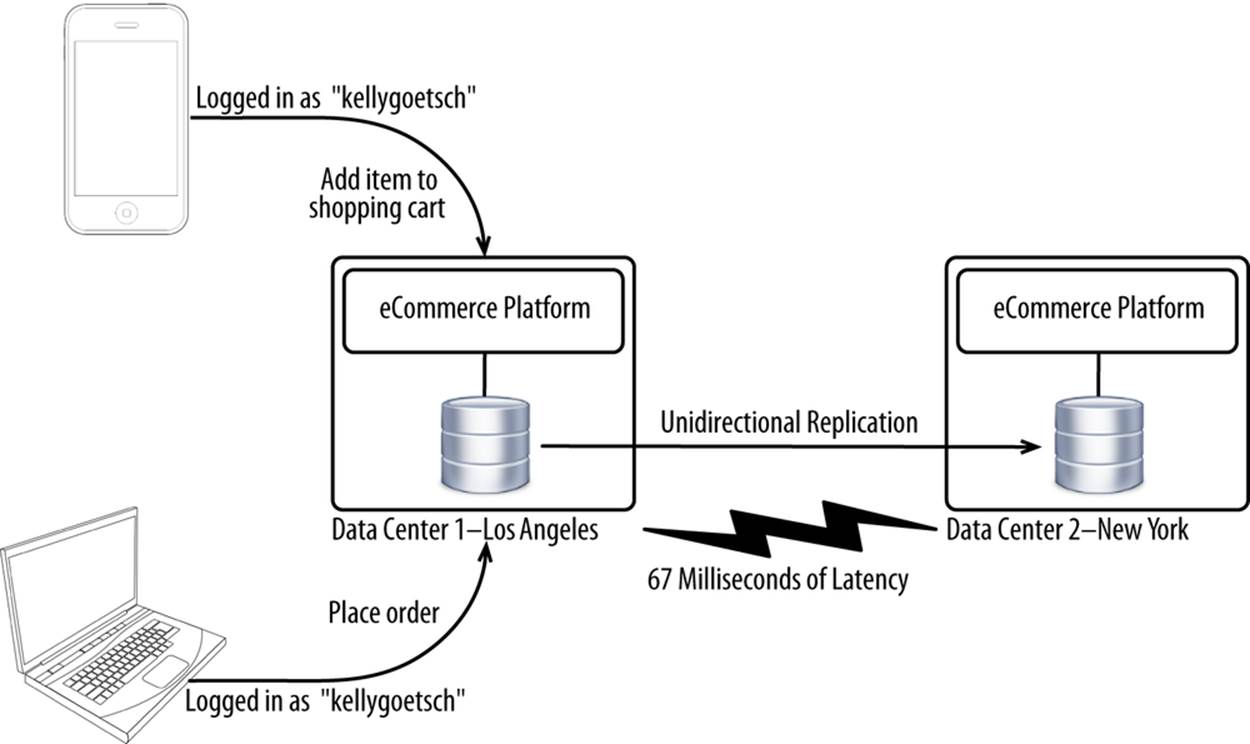
Figure 10-8. Active/passive deployment architecture
Lengthy downtime is expected because switching over to the passive data center entails the following:
§ Provisioning hardware (Chapter 4)
§ Installing software on the newly provisioned hardware (Chapter 4)
§ Initializing your database
§ Reversing the database synchronization so you have a backup for your newly active database
§ Pointing your Global Server Load Balancer to your new data center
This all takes time, with the system down while these activities take place. Unless you invest a lot of time in automating this, it will probably have to be done manually.
With a traditional hosting model, the passive data center would be fully built out with dedicated hardware. This reduces your downtime but at the cost of having double the hardware you would otherwise need sitting completely idle for the vast majority of the year. It’s enormously wasteful, but the waste may be outweighed by the reduction in the length of outages.
Active/passive is easiest to use when you want to make as few changes as possible to your applications and your deployment architectures. Since replication happens at the database only and tools exist to do that, you don’t have to change any of your other software if you don’t want to. That saves a lot of time and money, especially if you’re working with software that is difficult to change. You may not even be able to change some software, making this the only viable approach.
Active/Active Application Tiers, Active/Passive Database Tiers
With this approach, shown in Figure 10-9, you have two or more data centers fully built up and operating independently, with only the database being active/passive. This approach is a great middle ground that avoids most of the headaches of full multimaster (where both your application and database tiers are fully active) but comes with the limitation that your data centers can’t be too far apart.
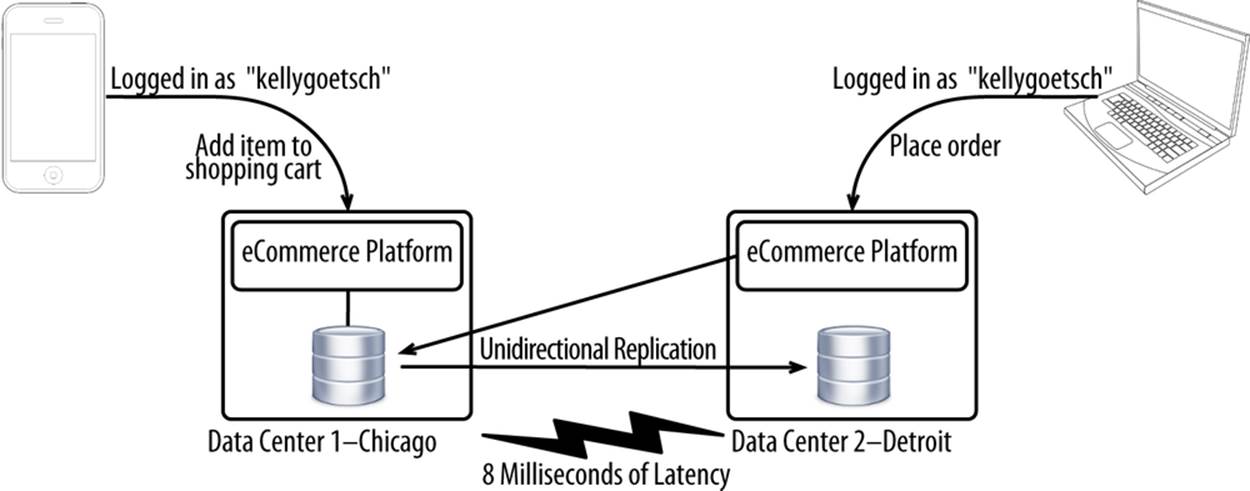
Figure 10-9. Active/passive application tiers, active/passive database tiers deployment architecture
Because half of your application tiers will be writing to a database residing in a different data center, the success of this approach depends very much on how often you write to your database, whether those writes are synchronous, and how much latency there is between your application tiers and database. If you’re writing to the database five times for every page view and you have 20 milliseconds of latency, you’re looking at overhead of 100 milliseconds in pure latency on top of however long it takes for your database to generate the response. The key is picking data centers that are close enough together to minimize the impact of latency, but far enough apart to not be affected by the same natural disasters, human errors, and upstream outages. For example, round-trip latency between Chicago and Detroit is only 8 milliseconds. You could make 12 round-trips between the two and add only 96 milliseconds of latency. By choosing data centers there, you get some good physical separation yet incur very little latency.
If you have an issue with a data center or your software deployed in that data center, you can just stop directing traffic to it and failover to the other data center. You can switch your customers over to the surviving data center within seconds, either through the automated health checking–based approach we discussed earlier in this chapter or by manually making the change.
The real advantage is that you shouldn’t have to change your applications all that much. The changes are mostly at the database level. You may have to optimize your code to reduce the number of calls to your database, but that’s about it.
Active/Active Application Tiers, Mostly Active/Active Database Tiers
As discussed earlier in this chapter, the central problem with multimaster is having multiple logins to the same account. When that happens, you can run into data conflicts as the same data is updated from two different databases. The two approaches mentioned don’t have this issue because there’s only one live database. Even though there may be multiple physical data centers, all writes occur to the same ACID-compliant database. This approach is the first in which each data center has its own active database.
Each data center in this approach, shown in Figure 10-10, has its own application and database stack. By default, customers write to the local database in the data center they’ve been assigned to. But when the application detects that a customer already has a concurrent login in another data center, the customer will write cross-WAN to the data center having the active session. By doing this, you have full active/active except for the very small percentage of customers with multiple concurrent logins.
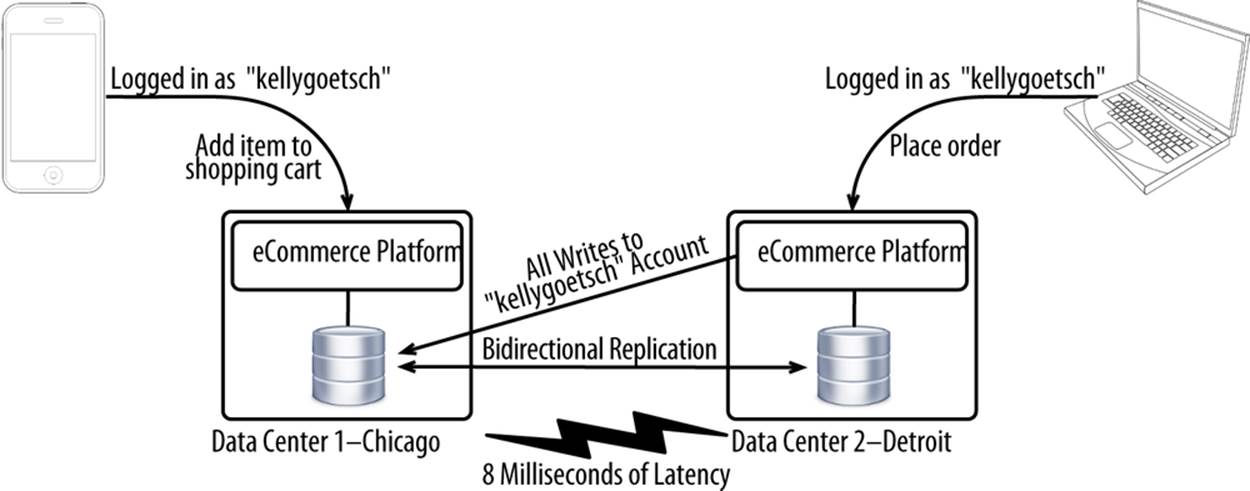
Figure 10-10. Active/passive application tiers, mostly active/active database tiers deployment architecture
To implement this approach, you need to change your login process to tag each account with the data center the account is signed in from and the time that a login was last performed. All logins then need to check those two values to see whether someone else is already signed in using those credentials in a different data center. If during the login process you find that somebody else is already logged in to that account from a different data center, you point that customer to the database in the data center where there’s already an active login. All reads can still happen from the local database.
Since this is the first approach that uses two or more live databases, all primary keys (or other persistent identifiers) must be prefixed with a unique identifier. For example, a data center in New York could have all of the primary keys generated there prefixed with ny. This allows primary keys to remain unique across all data centers.
A complicating factor is how you assign databases to individual customers. The key is to configure your application server to have multiple connection pools, each representing a unique database. If you have a data source for your orders, you would define a data source with an identifier ofOrder_DS_Local and another one with an identifier of Order_DS_Remote. Then in your application tier, you change data source resolution from a global scoped variable to a session scoped variable. Pseudocode would look something like this:
publicboolean handleLogin(HttpServletRequest request,
HttpServletResponse response)
{
if (!super.handleLogin(request, response)) // loads Account into session
{
returnfalse;
}
Account account = (Account)request.getSession()
.getAttribute("CurrentAccount"); // returns "Chicago"
String thisDataCenterName = Constants.CURRENT_DATA_CENTER_NAME;
// if account.getCurrentDataCenter() = "Chicago"
if (account.getCurrentDataCenter().equals(thisDataCenter))
{
request.getSession().setAttribute("Order_Data_Source",
Constants.LOCAL_ORDER_DATA_SOURCE);
// sets to "Order_DS_Local"
}
else // if account.getCurrentDataCenter() = "Detroit"
{
request.getSession().setAttribute("Order_Data_Source",
Constants.REMOTE_ORDER_DATA_SOURCE);
// sets to "Order_DS_Remote"
}
returntrue;
}
Your implementation will be substantially different, but the logic should be fairly similar.
Full Active/Active
This approach (Figure 10-11), like the previous approach, has data centers that operate autonomously, with each data center equipped with its own application and database tiers. Rather than writing cross-WAN for the handful of customers with active logins in another data center, this approach requires those customers be forcibly moved to the data center having the active login. This allows all customers to always be served from a local database, with no communication occurring cross-WAN.
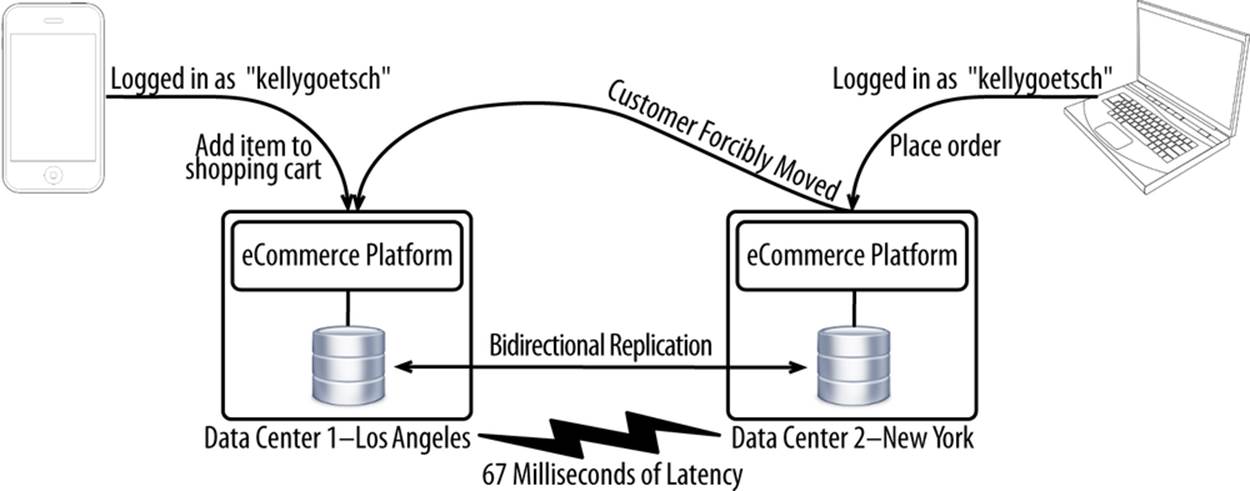
Figure 10-11. Full active/active deployment architecture
The implementation of this approach starts out being the same as the prior one. You need to tag each account with the data center the account signed in from and the time that a login was last performed. You then need to write a bit of code to determine whether the customer is signed in somewhere else. This is all the same as the prior approach. The difference is that a customer found to be in the “wrong” data center is forcibly moved to the data center that has an active session for the account. Following the redirection, all HTTP requests and HTTP sessions belonging to that account are served from the same data center, application tier, and database. Anonymous customers never need to be redirected because they don’t have a home data center.
The problem with this approach is that it’s very difficult to unstick a customer from a data center. IP addresses (with data centers each represented by a single domain name and each IP address mapping back to a single data center) are cached through various intermediaries. For example, many web browsers cache IP address/domain name combinations longer than called for by the DNS record (time to live). You can’t just force a client to reliably re-resolve a domain name and have that change take effect immediately. We’ll discuss this in greater detail shortly, but at a high level you have to intercept the HTTP requests at the edge by using a Content Delivery Network and have proxying done there. There may be some ways to force clients to re-resolve the IP address, but that would be even more challenging to do than the CDN/proxying approach. With full active/active, this may not even be possible to do, but this approach offers substantial benefits above the previous. Again, we’ll discuss this in more detail shortly.
Stateless Frontends, Stateful Backends
This approach will be discussed extensively in Chapter 11, but it amounts to separating your frontend from your backend as part of an architecture for omnichannel (see Figure 10-12).
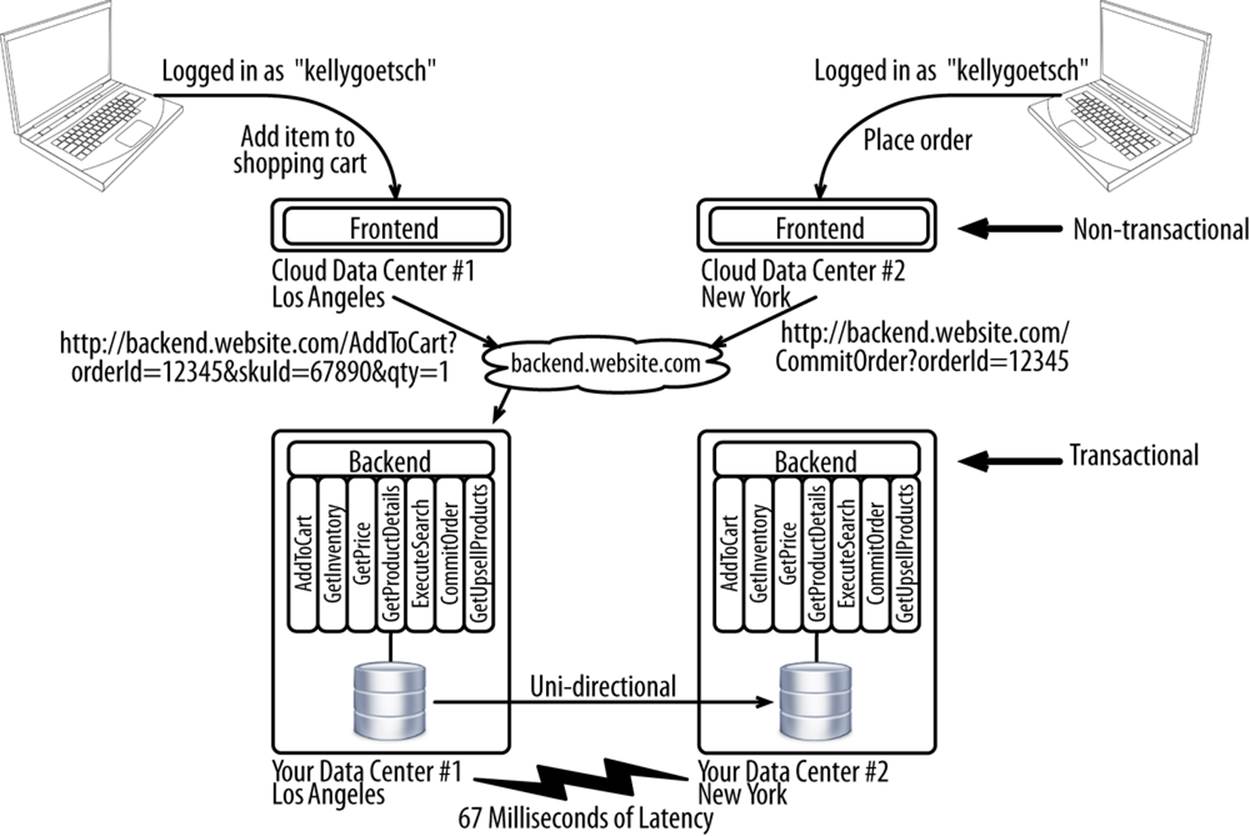
Figure 10-12. Stateless frontends, stateful backends deployment architecture
In this scenario, your backend is used only for transactional actions, like placing an order or finding out which products to pitch to a customer. You interact with it through basic HTTP requests, like this:
http://backend.website.com/CommitOrder?orderId=12345
Your responses are JSON, XML, or some other generic format that your frontend can parse and display back to the customer:
{
"success": true,
"message": "Your order has been successfully placed.",
...
}
Your backend is deployed to data centers that you control, leveraging the hardware and software you want. This requires statically provisioning hardware and scaling for the peak, but the difference is that your backend is now handling a much smaller amount of traffic because your frontend is serving much of it. Refer to the traffic funnel: most of your traffic is for anonymously browsed pages that don’t require any interaction with your backend. Your frontend is deployed in a cloud, where it can be elastically scaled.
A key advantage of this approach is that you can throw many frontends on the platform and maintain a consistent customer experience across all the channels and devices. The frontends become dumb presentation layers. They’re more or less disposable. Almost all native iPhone and Android applications work like this today, with the trend increasing as more channels and device types must continue to be supported. This architecture is a significant departure from the past, where frontends were tangled up with the backends, to the point where you couldn’t separate the two. Many ecommerce platforms still ship the backend (e.g., classes, libraries) in the same package (e.g., an EAR file) as the frontend (e.g., JSP, ASP, HTML, CSS, or JavaScript). Rendering HTML is what consumes most of the CPU cycles. If you skip the user interface, you can get far more throughput than you otherwise would be able to if the two were combined.
The other advantage of this approach is that you can now deploy your backends active/passive across two data centers. So long as your frontends all point back to the same backend, you won’t run into any of the problems mentioned in this chapter because every update to a given customer’s data ultimately terminates in the same database.
Again, we’ll discuss this approach further in Chapter 11.
Review of Approaches
As we’ve discussed, there are numerous approaches to operating from multiple data centers. Table 10-2 quickly summarizes each approach.
Table 10-2. Approaches to operating from multiple data centers
|
Approach |
Number of active databases |
Recovery point objective |
Recovery time objective |
Max distance between data centers |
Changes to application |
Database replication |
Competency required for implementation |
|
Active/passive |
1 |
Zero |
1 hour+ |
Unlimited |
None |
Unidirectional |
Low |
|
Active/active application tiers, active/passive database tiers |
1 |
Zero |
5 minutes |
<25 ms |
Minor |
Unidirectional |
Low |
|
Active/active application tiers, mostly active/active database tiers |
2+ |
Zero |
Zero |
<25 ms |
Moderate |
Bidirectional |
Moderate |
|
Full active/active |
2+ |
Zero |
Zero |
Unlimited |
High |
Bidirectional |
High |
|
Stateless frontends, stateful backends |
1+ |
Zero |
Zero |
<100 ms |
High |
Unidirectional or bidirectional |
High |
As discussed earlier, pragmatism should be your guiding force as you select the approach that works for you and then customize it to meet your needs.
Summary
While all forms of operating from multiple data centers take work, it’s something that the industry is rapidly adopting because of the increasing importance of ecommerce. Outages simply cannot happen in today’s world.
Operating from multiple data centers is also a prerequisite for a hybrid model of cloud computing, which we’ll discuss in the next chapter.
[65] Wikipedia, “Consistency Model,” (2014), http://en.wikipedia.org/wiki/Consistency_model.
[66] Wikipedia, “ACID,” (2014), http://en.wikipedia.org/wiki/ACID.
[67] Wikipedia, “Eventual Consistency,” (2014), http://en.wikipedia.org/wiki/Eventual_consistency.
[68] Dr. Eric A. Brewer, “NoSQL: Past, Present, Future,” (8 November 2012), http://bit.ly/1gAdvwO.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.