Cloud Computing Bible (2011)
Part IV: Understanding Services and Applications
Chapter 15: Working with Cloud-Based Storage
IN THIS CHAPTER
Drowning in a sea of data; saved by the cloud
Categorizing cloud storage system types
Examining file hosting and backing up to the cloud
Comparing unmanaged and managed cloud storage
Developing protocols for cloud storage interoperability
The world is creating massive amounts of data. A large percentage of that data either is already stored in the cloud, will be stored in the cloud, or will pass through the cloud during the data's lifecycle. Cloud storage systems are among the most successful cloud computing applications in use today. This chapter surveys the area of cloud storage systems, categorizes the different cloud storage system types, discusses file-sharing and backup software and systems, and describes the methods being used to get cloud storage systems to interoperate.
Cloud storage can be either unmanaged or managed. Unmanaged storage is presented to a user as if it is a ready-to-use disk drive. The user has little control over the nature of how the disk is used. Most user-oriented software such as file-sharing and backup consume unmanaged cloud storage. Applications using unmanaged cloud storage are Software as a Service (SaaS) Web services.
Managed storage involves the provisioning of raw virtualized disk and the use of that disk to support applications that use cloud-based storage. Storage options involved in formatting, partitioning, replicating data, and other options are available for managed storage. Applications using managed cloud storage are Infrastructure as a Service (IaaS) Web services.
Developing cloud storage interoperability standards are described in this chapter, notably those from the Storage Networking Industry Association (SNIA) and the Open Grid Foundation (OGF). The Cloud Data Management Interface (CDMI) interoperability storage object protocol is described. This interface can store data objects, discover stored data objects, and supply these data objects to subscribing applications. The Open Cloud Computing Interface (OCCI) is another storage data interchange interface for stored data objects. The two protocols interoperate with one another.
Measuring the Digital Universe
The world has an insatiable hunger for storage. This hunger is driven by the capture of rich media, digital communications, the Web, and myriad other factors. When you send an e-mail with a 1GB attachment to three people, this generates an estimated 50GB of stored managed data. Only 25 percent of the data stored is unique; 75 percent of stored data is duplicated. You may be surprised to learn that 70 percent of the data stored in the world is user initiated; the remainder is enterprise-generated content.
Video cameras and surveillance photos, financial transaction event logs, performance data, and so on create what IDC (International Data Corporation; http://www.idc.com/), the research analysis arm of International Data Group has called the “digital shadow”—data that is automatically generated. Shadow data represents more than 50 percent of the data created every day. However, lots of shadow data does get retained, having never been touched by a human being.
Much of the data produced is temporal, stored briefly, and then deleted. That's a good thing, because there is a growing divide between the amount of data that is being produced and the amount of storage available.
The storage giant EMC has an interest in knowing just how much data is being stored worldwide. EMC has funded some studies over the past decade to assess the size of what it calls “The Digital Universe.” The latest study done by IDC in 2007-2008 predicted that by 2011 the world will store 1800 exabytes (EB) or 1.8 zettabytes (ZB) of data. By the year 2020, stored data will reach an astonishing 35ZB. The number of managed objects stored in containers—files, images, packets, records, signals, and so on—is estimated to be roughly 25 quintillion (1018) containers. A container is a term of art in cloud storage.
These numbers are astronomical, and wrapping your mind around them can be hard. Even more astonishing is the fact that the amount of stored data is doubling roughly every five years. In 2007, the last year before the recession of 2008, the amount of stored data grew even faster, by 60 percent annually. You can visit EMC's Digital Universe home page, shown in Figure 15.1, to link to the IDC study, view the Digital Data Consumption Ticker, and get EMC's take on the problems associated with managing vast data sets.
Note
Here are some definitions of scale: a gigabyte is 109 bytes, a petabyte is 1015 bytes; an exabyte is equal to one billion gigabytes or 1018 bytes; a zettabyte is equal to one trillion gigabytes or 1021 bytes; and a yottabyte (YB) is 1024 bytes.
FIGURE 15.1
EMC's Digital Universe Web page located at http://www.emc.com/leadership/digital-universe/expanding-digital-universe.htm
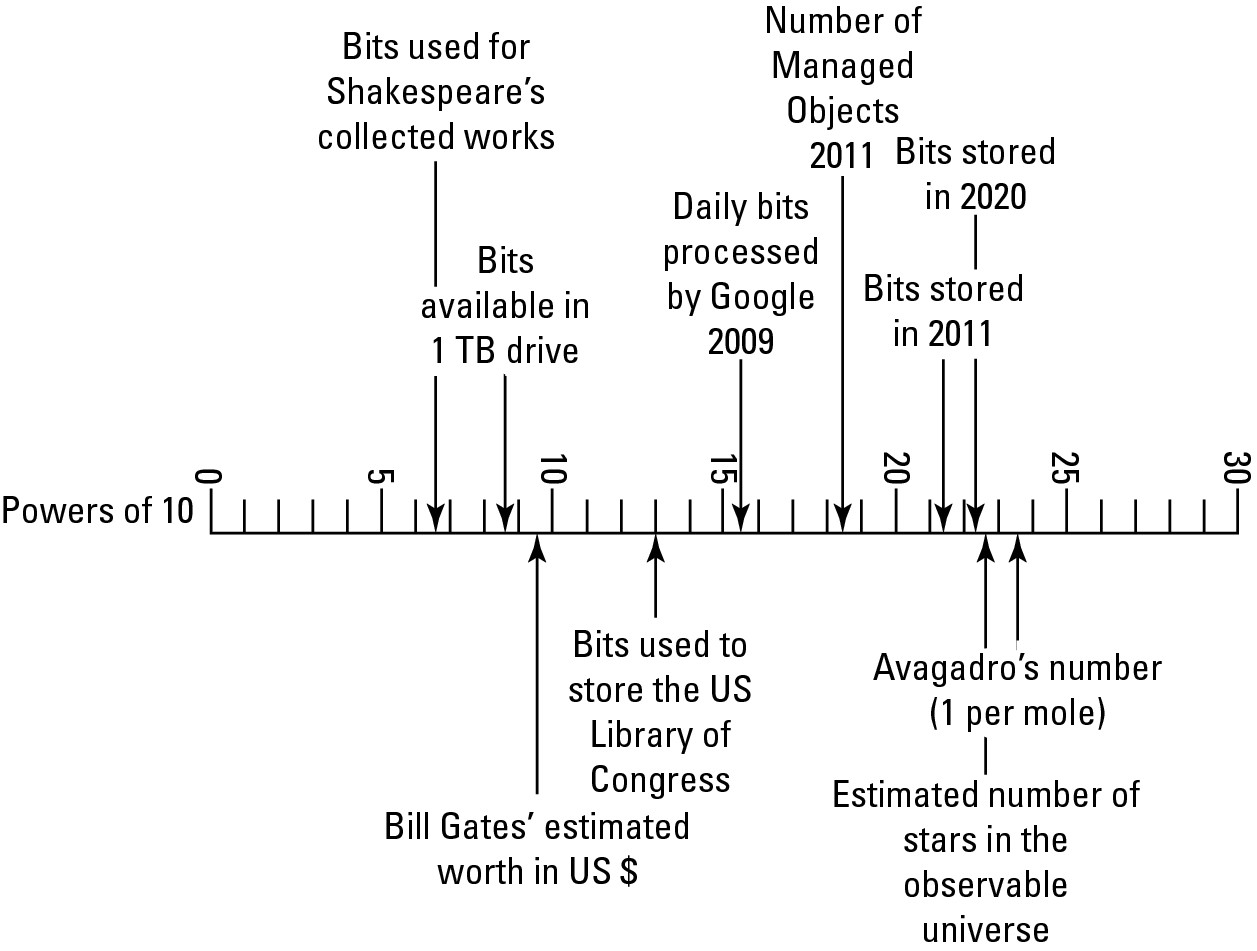
To provide some measure of scale, the size of William Shakespeare's complete works downloaded as text from Gutenburg.org (http://www.gutenberg.org/etext/100) is 5.1MB. The amount of stored information in the United States Library of Congress is about 10 terabytes of data (10,000 gigabytes), and in 2009 Google was processing around 24 petabytes of data per day. Figure 15.2 shows a logarithmic scale with different data storage sizes.
FIGURE 15.2
Data storage plotted on a logarithmic scale
Cloud storage in the Digital Universe
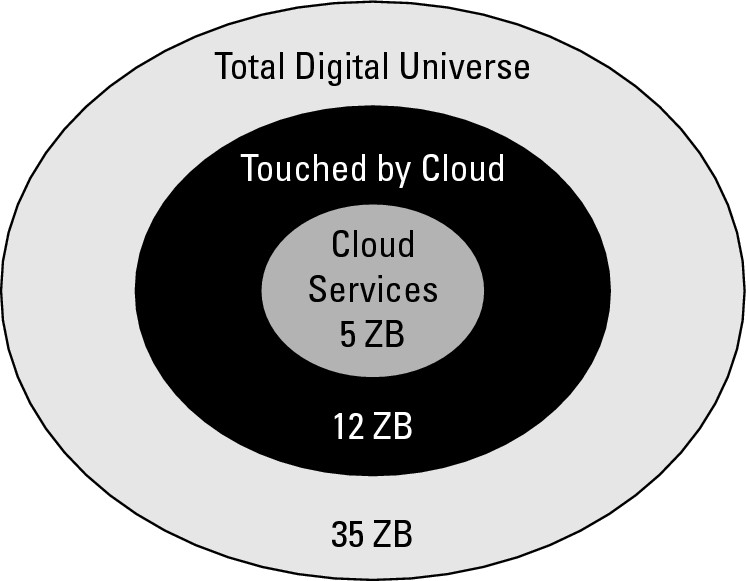
A very significant fraction of this data is now or will be residing in cloud storage. Even more will pass through cloud storage in its use. IDC's 2010 study attempted to estimate the percentage of data that will be stored in the cloud or passed through the cloud in the year 2020. There will be a steady growth of cloud storage at the expense of online storage over the next decade. Figure 15.3 shows a graphical illustration of the impact of cloud storage systems on the overall Digital Universe in 2020.
FIGURE 15.3
Cloud storage data usage in the year 2020 is estimated to be 14 percent resident and 34 percent passing through the cloud by IDC. Source: IDC Digital Universe, May 2010.
Cloud storage definition
Think of cloud storage as storage accessed by a Web service API. The characteristics that separate cloud storage include network access most often through a browser, on-demand provisioning, user control, and most often adherence to open standards so that cloud storage may be operating-system-neutral and file-system-neutral. These characteristics, taken as a whole define an offering that is best described as an Infrastructure as a Service model. However, most users do not provision storage under IaaS systems such as Amazon S3 (described in Chapter 9). Instead, most users interact with cloud storage using backup, synchronization, archiving, staging, caching, or some other sort of software. The addition of a software package on top of a cloud storage volume makes most cloud storage offerings conform to a Software as a Service model.
Storage devices may be broadly categorized as either block storage devices or file storage devices. A block storage device exposes its storage to clients as Raw storage that can be partitioned to create volumes. It is up to the operating system to create and manage the file system; from the standpoint of the storage device, data is transferred in blocks. The alternative type of storage is a file server, most often in the form of a Network Attached Storage (NAS) device. NAS exposes its storage to clients in the form of files, maintaining its own file system. Block storage devices offer faster data transfers, but impose additional overhead on clients. File-oriented storage devices are generally slower (with the exception of large file-streaming applications), but require less overhead from attached clients. Cloud storage devices can be either block or file storage devices.
Provisioning Cloud Storage
Cloud storage may be broadly categorized into two major classes of storage: unmanaged and managed storage. In unmanaged storage, the storage service provider makes storage capacity available to users, but defines the nature of the storage, how it may be used, and by what applications. The options a user has to manage this category of storage are severely limited. However, unmanaged storage is reliable, relatively cheap to use, and particularly easy to work with. Most of the user-based applications that work with cloud storage are of this type.
Managed cloud storage is mainly meant for developers and to support applications built using Web services. Managed cloud storage is provisioned and provided as a raw disk. It is up to the user to partition and format the disk, attach or mount the disk, and make the storage assets available to applications and other users.
The sections that follow describe these two storage types and their uses in more detail.
Unmanaged cloud storage
With the development of high-capacity disk storage starting in the mid- to late-1990s, a new class of service provider appeared called a Storage Service Provider (SSP). Fueled by venture capital and the dot.com boom, dozens of companies created datacenters around the world with the intent of doing for online storage what Internet service providers (ISP) did for communications.
With so much excess capacity in place, companies with names like iDrive (now at http://www.driveway.com/), FreeDrive (http://www.freedrive.com/) MyVirtualDrive (defunct), OmniDrive (gonzo), XDrive (kaput), and others were formed to offer file-hosting services in the form of unmanaged cloud storage. It is unmanaged storage in the sense that the storage is preconfigured for you, you can't format as you like, nor can you install your own file system, or change drive properties such as compression or encryption.
Storage was offered to users by these file-hosting services as fixed online volumes. These volumes were first accessible using FTP, then from a utility, and then from within a browser. Often the service offered a certain capacity for free, with the opportunity to purchase more online storage as needed. FreeDrive is an example of an unmanaged storage utility set up to do automated backups, a class of Web services that is discussed in the section “Exploring Cloud Backup Solutions” later in this chapter.
Three factors led to the demise of many of the early SSPs and to many hosted file services:
• The Dot.com bust in 2000
• The inability of file-hosting companies to successfully monetize online storage
• The continued commoditization of large disk drives, which led to free online storage from large vendors such as Google
These SSPs and file-hosting services were ahead of their time, but in many cases—through acquisitions and offspring ventures—their legacy remains.
The simplest of these unmanaged cloud storage services falls into the category of a file transfer utility. You can upload files to the service where that file is stored (for a while) and made available to you for downloading from another location. Some of these services allow the transfer of only a single file. File transfer services may be shared by other users you allow, and the files that are uploaded may be discoverable for some services. That is, you can query the system for a file or information that meets the criteria you set. The service FreeDrive is storage that allows Facebook users to view the content of others.
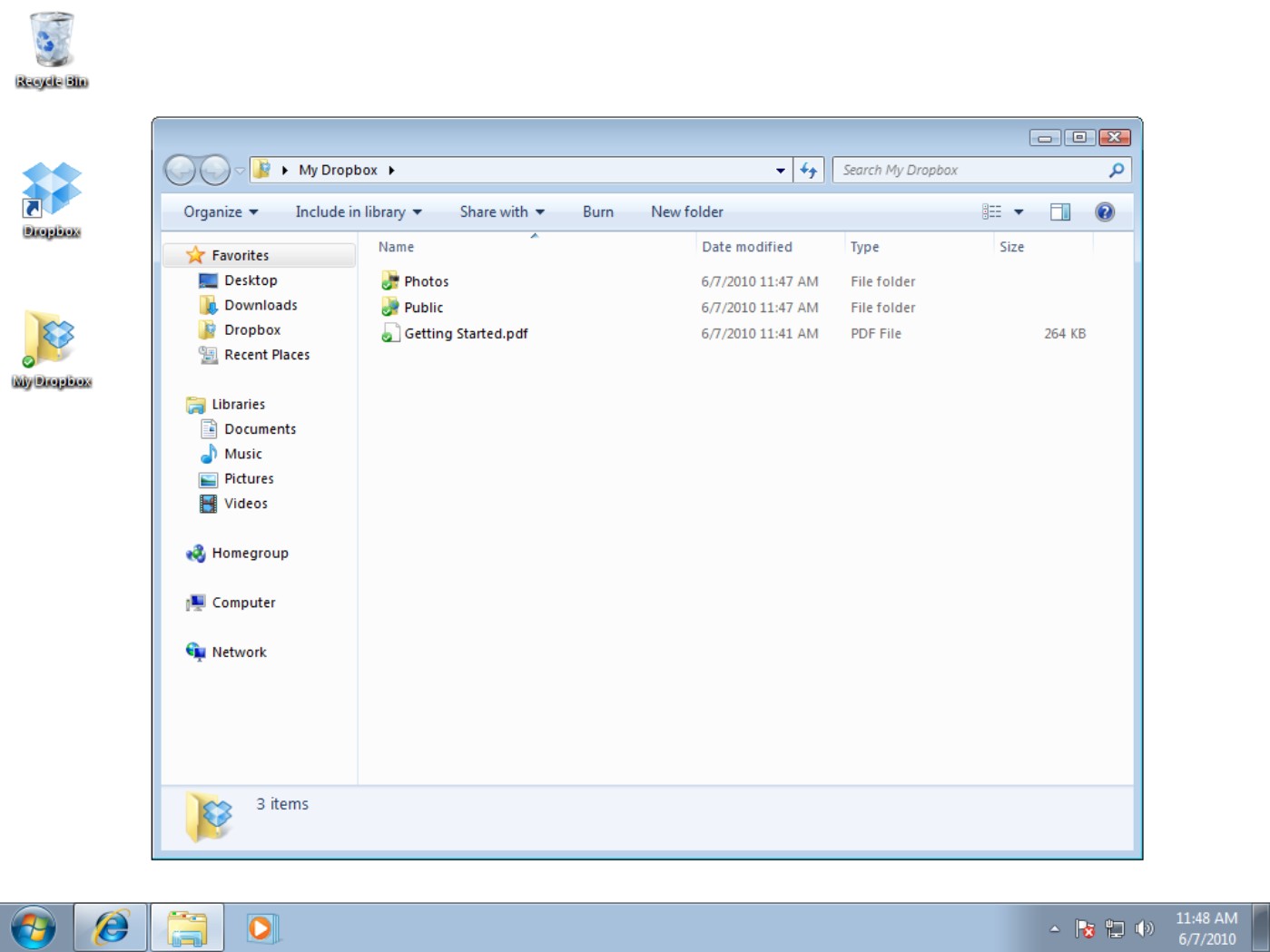
Dropbox, shown in Figure 15.4, is an example of a file transfer utility. You install the Dropbox utility on your system and create an account, and the Dropbox folder appears. Dropbox also installs a System Tray icon in Windows for you. You can then drag and drop files and folders to your Dropbox. When a remote user logs into a Dropbox account, he installs the Dropbox folder for that account on his system, creating what is in effect a shared folder over the Web.
FIGURE 15.4
Dropbox is a file transfer utility that creates a shared folder metaphor using a Web service.
In an unmanaged cloud storage service, disk space is made available to users as a sized partition. That is, the remote storage appears as a mapped drive inside a folder like My Computer. File-hosting services allow the user to READ and WRITE to the drive and, in some cases, share the drive with other users, and often little more. As unmanaged storage offerings progressed in sophistication, they began to offer value-added software services such as folder synchronization and backup. Table 15.1 lists some of the current file-sharing services offered on unmanaged cloud storage.
|
TABLE 15.1 |
||||||
|
Unmanaged Cloud Storage |
||||||
|
Service |
Site |
Storage Size |
Maximum File Size |
Direct Access |
Remote Upload |
Developer API |
|
4Shared |
http://www.4shared.com/ |
10GB free t0 100GB paid |
200MB |
Yes |
Yes |
WebDAV |
|
Adrive |
http://www.adrive.com/ |
50GB free to 1 TB paid |
2GB |
No, through a Web page |
Yes |
WebDAV |
|
Badongo |
http://www.badongo.com/ |
Unlimited |
1GB |
No, through Captcha |
Only for paid users |
|
|
Box.net |
http://www.box.net/ |
1GB free, 5 - 15GB paid |
25MB free, 1GB paid |
Yes |
||
|
Dropbox |
https://www.dropbox.com/ |
2GB free, up to 8GB |
Unlimited |
Yes |
Yes |
No |
|
Drop.io |
http://drop.io/ |
100MB free |
100MB |
Yes |
Yes |
|
|
eSnips |
http://www.esnips.com/ |
5GB |
Yes |
Yes |
||
|
Freedrive |
http://www.freedrive.com/ |
1GB |
Yes |
Yes |
||
|
FileFront |
http://www.filefront.com/ |
Unlimited |
600MB |
Yes |
||
|
FilesAnywhere |
http://filesanywhere.com/ |
1GB, more can be purchased |
Yes |
Yes |
FA API |
|
|
Hotfile |
http://hotfile.com/ |
Unlimited |
400MB free |
No, through Captcha |
FTP |
|
|
Humyo |
http://www.humyo.com/ |
10GB free |
None |
Yes |
||
|
iDisk |
http://www.apple.com/mobileme/ |
20/40/60GB |
1GB |
Yes |
Yes |
WebDAV |
|
Google Docs Storage |
http://docs.google.com/# |
1GB free, more can be purchased |
250MB |
|||
|
MagicVortex |
http://magicvortex.com/ |
2GB |
2GB |
Yes |
Yes |
|
|
MediaFire |
http://www.mediafire.com/ |
Unlimited |
200MB |
Yes |
Only for paid |
|
|
Megaupload |
http://www.megaupload.com/ |
200GB free, Unlimited paid |
2GB |
No, through Captcha |
Only for paid |
|
|
RapidShare |
http://www.rapidshare.com/ |
20GB |
200MB free, 2GB paid |
No, imposed wait time |
Yes |
Yes |
|
sendspace |
http://www.sendspace.com/ |
300MB free, 1.5GB paid |
Yes |
Yes, through a wizard |
||
|
SkyDrive |
http://skydrive.live.com/ |
25GB |
50MB |
Yes |
Yes |
WebDAV |
|
Steek |
http://www.steek.com/ |
1GB |
Yes |
Yes, through DriveDrive |
||
|
Wu.ala |
http://wua.la/ |
1GB free, additional paid |
None |
Yes |
Yes |
|
|
ZumoDrive |
http://www.zumodrive.com/ |
2GB free, 10 - 500GB paid |
None |
Yes |
Yes |
|
Source: Based on http://en.wikipedia.org/wiki/Comparison_of_file_hosting_services, June 7, 2010, and other sources.
If you are considering one of these services and require an automated backup solution, you also should consult Table 15.2 for those related products.
Managed cloud storage
The most basic service that online storage can serve is to provide disk space on demand. In the previous section, you saw examples of services where the service provider prepares and conditions the disk space for use by the user, provides the applications that the user can use with that disk space, and assigns disk space to the user with a persistent connection between the two. The user may be able to purchase additional space, but often that requires action by the service provider to provision the storage prior to use. That type of storage is considered unmanaged cloud storage because the user can't proactively manage his storage.
The second class of cloud storage is what I call managed cloud storage. You saw an example of a managed cloud storage system in Chapter 9 where Amazon's Simple Storage System (S3) was described. In a managed cloud storage system, the user provisions storage on demand and pays for the storage using a pay-as-you-go model. The system presents what appears to the user to be a raw disk that the user must partition and format. This type of system is meant to support virtual cloud computing as the virtualized storage component of that system.
Note
SNIA (Storage Networking Industry Association; http://www.snia.org/) has coined the term Data Storage as a Service (DaaS) to describe the delivery of storage on demand to clients over a distributed system. Others have called these types of system services Storage as a Service (STaaS).
Managed cloud storage providers include the following:
• Amazon.com Simple Storage Service (S3; http://aws.amazon.com/s3/): This hosting service is described in Chapter 9.
• EMC Atmos (http://www.emc.com/products/family/atmos.htm): With Atmos, you can create your own cloud storage system or leverage a public cloud service with Atmos online.
• Google Storage for Developers (http://code.google.com/apis/storage/docs/overview.html): Code named “Platypus,” this service currently in beta allows developers to store their data in Google's cloud storage infrastructure. It will share Google's authentication and data sharing platforms.
• IBM Smart Business Storage Cloud (http://www-935.ibm.com/services/us/index.wss/offering/its/a1031610): IBM has both infrastructure and software offerings that allow businesses to create and manage a private storage cloud.
IBM is a major player in cloud computing (http://www.ibm.com/ibm/cloud/), particularly for businesses. The company offers a hardware platform called CloudBurst, as well as a portfolio of software that leverages cloud infrastructure such as IBM Smart Analytics Cloud, IBM Information Archive, IBM LotusLive, and LotusLive iNotes.
• Iron Mountain (http://www.ironmountain.com/storage/storage-as-a-service.html): Iron Mountain's service is mainly focused on backup and digital archiving, not on storage hosting.
• Nirvanix (formerly Streamload; http://www.nirvanix.com/): The company's MossoFS offers a managed cloud service.
• Rackspace Cloud (http://www.rackspace.com/index.php): Rackspace is a direct competitor to Amazon's S3 service.
Creating cloud storage systems
The Internet was designed to be a fault-tolerant network that could survive a nuclear attack. Paths between endpoints are redundant, message transfer is packetized, and dropped or lost packets can be retransmitted and travel different paths. Networks are redundant, name servers are redundant, and overall the system is highly fault tolerant. These features help make cloud-based storage systems highly reliable, particularly when multiple copies of data are stored on multiple servers and in multiple locations. Failover can involve a system simply changing the pointers to the stored object's location.
In Chapter 9, you saw how Amazon Web Services (AWS) adds redundancy to its IaaS systems by allowing EC2 virtual machine instances and S3 storage containers (bucket) to be created in any one of its four datacenters or regions. AWS S3 essentially lets you create your own cloud storage, provided you distribute your provisioned storage appropriately on Amazon's system.
AWS created “Availability Zones” within regions, which are sets of systems that are isolated from one another. In theory, instances in different availability zones shouldn't fail at the same time. In practice, entire regions can be affected, and storage and system redundancy needs to be established on a multi-regional basis. AWS can perform load balancing on multiple instances and can perform failover from one geographical location to another, but this is an additional service that you must purchase. The important point about redundancy is that for it to be effective, it has to be implemented at the highest architectural level.
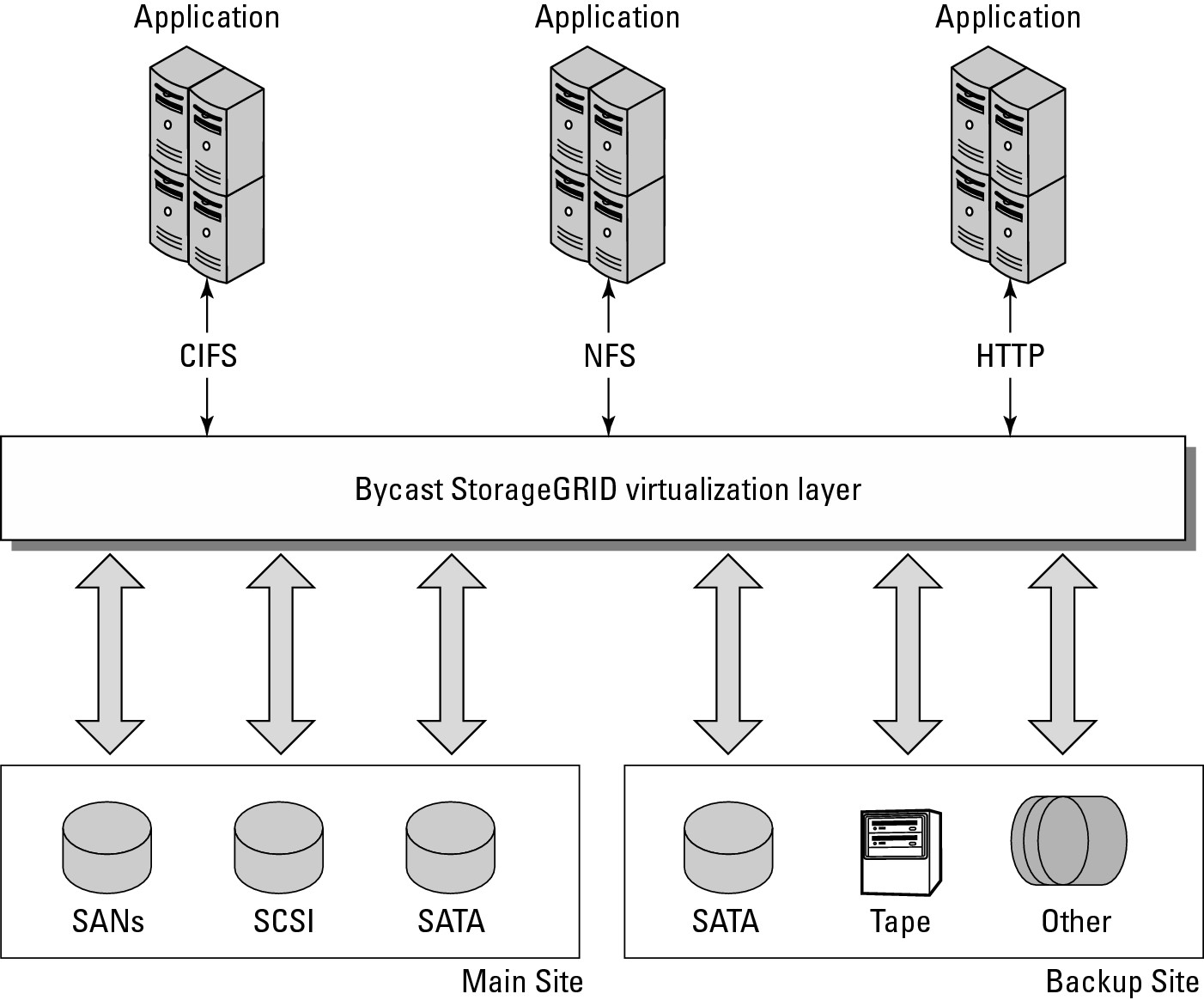
Companies wishing to aggregate storage assets into cloud storage systems can use an enterprise software product like StorageGRID. This storage virtualization software from Bycast (now a part of NetApp; http://bycast.com/) creates a virtualization layer that pools storage from different storage devices into a single management system. You can potentially pool petabytes of data storage, use different storage system types, and transport protocols even over geographically dispersed locations. Figure 15.5 shows how SystemGRID virtualizes storage into storage clouds.
StorageGRID can manage data from CIFS and NFS file systems over HTTP networks. Data can be replicated, migrated to different locations, and failed over upon demand. The degree of data replication can be set by policy, and when storage in the pool fails, StorageGRID can failover to other copies of the data on redundant systems. StorageGRID can enforce policies and create a tiered storage system.
FIGURE 15.5
ByCast's StorageGRID allows you to create fault-tolerant cloud storage systems by creating a virtualization layer between storage assets and application servers.
Virtual storage containers
In traditional pooled storage deployments, storage partitions can be assigned and provide a device label called a Logical Unit Number (LUN). A LUN is a logical unit that serves as the target for storage operations, such as the SCSI protocol's READs and WRITEs (PUTs and GETs). The two main protocols used to build large disk pools, particularly in the form of Storage Area Networks (SANs), Fibre Channel and iSCSI both use LUNs to define a storage volume that appears to a connected computer as a device. Unused LUNs are the equivalent of a raw disk from which one or more volumes may be created.
Traditionally, pooled online storage assigns a LUN and then uses an authorization process called LUN masking to limit which connected computers (or hosts) can see which LUNs. LUN masking isn't as strong a security feature as the direct identification of a physical Host Bus Adapters (HBAs), which are the storage networking equivalent of NICs (Network Interface Cards). LUN addresses can have their unique addresses spoofed more easily than a hardware address can. However, LUNs do protect against a server being able to write to a disk to which it shouldn't have access. Storage partitioning in large storage deployments also may be achieved using SAN zoning, as well as a partitioning disk based on physical location.
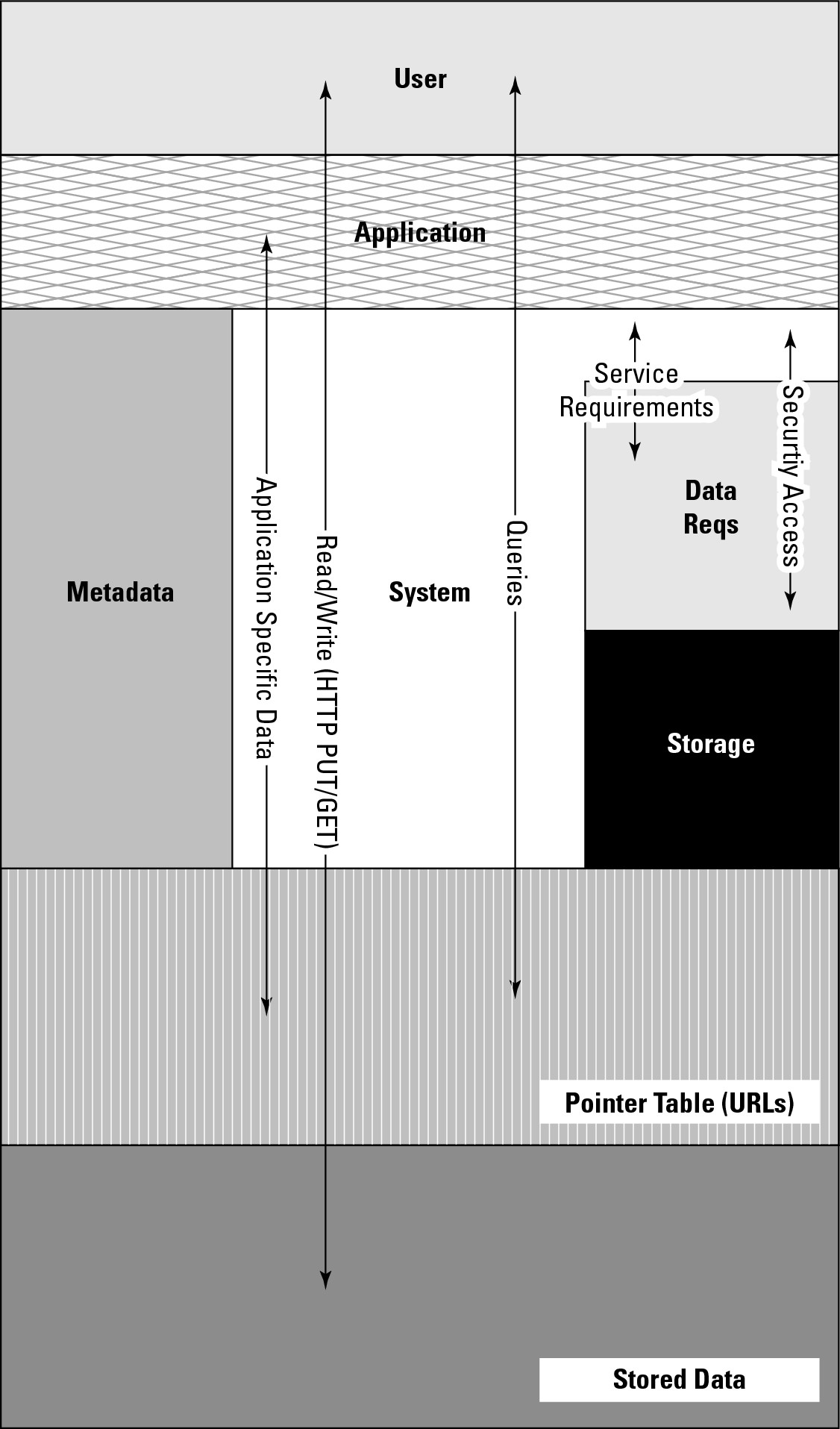
When online storage is converted for use in a cloud storage system, none of these partitioning methods allows for easy, on-the-fly storage assignment and the high disk utilization rates that are required in a multi-tenancy storage system. Delivering effective cloud storage solutions requires the use of a virtual storage container, which allows a tenant to perform storage operations on the virtual storage container consistent with the capabilities of the underlying storage system. Different storage vendors call their virtual storage containers by different names, but all use this entity as a construct to create high-performance cloud storage systems. LUNs, files, and other objects are then created within the virtual storage container. Figure 15.6 shows a model for a virtual storage container, which defines a cloud storage domain. This model, based on the SNIA model but modified somewhat, includes the interface operations that are needed to use that domain.
When a tenant is granted access to a virtual storage container, he performs standard disk operations such as partitioning, formatting, file system modifications, and CRUD (Create, Read, Update, and Delete) operations as desired. Data stored in a virtual storage container may be stored in chunks or buckets as the Amazon Simple Storage Service (Amazon S3) does, or it may be stored in containers that are in a hierarchical relationship typical of most file systems. The main requirement is that however cloud storage data is organized that data and its associated metadata may be discoverable.
Making cloud storage data discoverable on a TCP/IP network using HTTP or some other protocol requires that objects be assigned a unique identifier such as a URI (Uniform Resource Identifier) and that the relationship between objects and their metadata be specified. In the section “Developing Cloud System Interoperability,” I describe the OCCI protocol for discovering and retrieving objects from a cloud.
Because virtual storage containers must be secured, these objects must carry a set of security attributes that protect a tenant's data from snooping, denial of service attacks, spoofing, inappropriate deletion, or unauthorized discovery. The main mechanism for securing one tenant's virtual storage container from another is to assign an IP address to the virtual storage container and then bind that container to a separate VLAN connecting storage to the tenant (host). Traffic flowing over the VLAN is encrypted, and the tenant is carefully authenticated by the system. Usually, data sent over the VLAN is compressed to improve data throughput over a WAN connection.
Different cloud storage vendors may implement their own proprietary management interfaces to connect distributed hosts or tenants to their provisioned storage in the cloud and to provide for security services. One open interface standard is the Storage Networking Industry Association's Cloud Data Management Interface (CDMI) described later in this chapter.
FIGURE 15.6
A cloud storage domain model and the interface commands needed to access those elements
In evaluating cloud storage solutions, these factors are deemed to be important considerations:
• Client self-service
• Strong management capabilities
• Performance characteristics such as throughput
• Appropriate block-based storage protocol support such as iSCSI or FC SAN, or file-based storage protocol support such as NFS or CIFS to support your systems
• Seamless maintenance and upgrades
In addition to assigning security-provisioned cloud storage to a client or service requester, a cloud storage service provider must be able to deliver a measured level of service as captured by its stated Service Level Agreement (SLA). An SLA might specify that a particular Quality of Service (QoS) for a virtual storage container may be measured in terms of the I/O per second or IOPS that may be provided, as well as the reliability and availability of the service. QoS levels may be applied to different services against a single virtual storage container or a single service applied to the client's multiple assigned storage containers. In situations where multiple virtual storage containers are assigned to a client, a mechanism would need to be provided to federate the different containers into a consolidated management console.
One unique characteristic of cloud-based storage solutions is that they permit rapid scaling, both in terms of performance and storage capacity. To provide for scaling, a virtual storage container must be easily migrated from one storage system to another. To increase the capacity of a storage provision, it is necessary to provide the capability to scale up or scale out across storage systems. To scale up, the service must allow for more disks and more spindles to be provisioned. To scale out, the service must allow for stored data to span additional storage systems. Cloud storage systems that successfully scale their provisioned storage for clients often allow for the multiple storage systems to be geographically dispersed and often provide load-balancing services across different storage instances.
Exploring Cloud Backup Solutions
Cloud storage is uniquely positioned to serve as a last line of defense in a strong backup routine, and backing up to the cloud is one of the most successful applications of cloud computing. This area is a cornucopia of solutions, many inexpensive and feature rich.
Backup types
Backups may be categorized as belonging to one of the following types:
• Full system or image backups: An image backup creates a complete copy of a volume, including all system files, the boot record, and any other data contained on the disk. To create an image backup of an active system, you may need to stop all applications (quiesce the system). An image backup allows a system to do what is referred to as a bare metal restore. Ghost is an example of software that supplies this type of backup.
• Point-in-time (PIT) backups or snapshots: The data is backed up, and then every so often changes are amended to the backup creating what is referred to as an incremental backup. This type of backup lets you restore your data to a point in time and saves multiple copies of any file that has been changed. At least 10 to 30 copies of previous versions of files should be saved.
The first backup is quite slow over an Internet connection, but the incremental backup can be relatively fast. For example, software such as Carbonite may take several days to backup a system, but minutes to create the snapshot.
Note
The amount of time needed to backup a system is referred to as its backup window.
• Differential and incremental backups: A differential backup is related to an incremental backup, but with some subtle differences in the way the archive bit is handled. During an incremental backup, any changed files are copied to the backup media and their archive attribute is cleared by the incremental backup. In a differential backup, all of the changed files since the last full backup are copied by the backup software, which requires that the software leave the archive bit set to ON for any differential backup, as only a full backup can clear all files' archive bit.
An archive bit is used by backup software to specify whether a file should be backed up or not. The bit is set on for backup and cleared when backup has copied the file. In a sense, an archive bit is a directive to the software. The archive bit comes into play in backup software in the sense that an incremental backup solution must examine the full backup data and then analyze all subsequent increments to find the latest file(s). In a differential backup, the backup software can obtain the up-to-date backup from the last full backup and the last incremental backup alone. Files in intervening incremental backups may be taken as temporary or scratch versions. While incremental backups are faster and more efficient from a storage perspective, they are also less fault tolerant.
• Reverse Delta backup: A reverse delta backup creates a full backup first and then periodically synchronizes the full copy with the live version. The older versions of files that have been changed are archived so that a historical record of the backup exists. Among the software that uses this system is Apple's Time Machine and the RDIFF-BACKUP utility.
• Continuous Data Protection (CDP) or mirroring: The goal of this type of backup system is to create a cloned copy of your current data or drive. A cloud storage system contains a certain built-in latency, so unless the original data set is quiescent, the mirror lags behind the original in concurrency.
• Open file backup: Some applications such as database systems and messaging systems are mission critical and cannot be shut down before being backed up. An open file backup analyzes the transactions that are in progress, compares them to the file(s) at the start of the backup and the file(s) at the end of the backup, and creates a backup that represents a complete file as it would exist at the time the backup started after all the transactions have been processed. This is a difficult proposition, and open file backup systems are expensive and highly customized to a particular application such as SQL Server or Exchange.
3-2-1 Backup Rule
Peter Krogh's 3-2-1 Rule for data protection is a good one to follow. Krogh is a professional photographer, a member of the American Society of Media Photographers, and a consultant in the area of data storage and archiving. One of his clients is the Library of Congress, where data archival is a mission-critical task. As Krogh states on the site dpBestflow.org (http://www.dpbestflow.org/backup/backup-overview#321), a simple but effective backup scenario includes the following elements:
3. Retain three copies of any file—an original and two backups.
2. Files must be on two different media types (such as hard drives and optical media) to protect against different types of hazards.
1. One copy must be stored offsite (or at least online).
If you have a local version of a file, then a version of that file stored in the cloud conforms to all three of the 3-2-1 backup rules.
• Data archival: The term archiving is used to specify the migration of data that is no longer in use to secondary or tertiary long-term data storage for retention. An archive is useful for legal compliance or to provide a long-term historical record.
Note
Data archives are often confused with backups, but the two operations are quite different. A backup creates a copy of the data, whereas an archive removes older information that is no longer operational and saves it for long-term storage. You can't restore your current data set from an archive.
Cloud backup features
Features of cloud storage backup solutions that are valuable listed roughly in order of importance include the following:
• Logon authentication.
• High encryption (at least 128-bit) of data transfers, preferably end-to-end, but at least for the data that is transferred over the Internet.
• Lossless data compression to improve throughput. A related feature called differential compression transfers only binary data that has changed since the last backup.
• Automated, scheduled backups.
• Fast backup (snapshots) after full online backup, with 10 to 30 historical versions of a file retained.
• Data versioning with the ability to retrieve historical versions of files from different backups.
• Multiplatform support. The most important clients to back up are Windows, Macintosh, and Linux/Unix.
• Bare file/folder restore.
• Adequate bandwidth and perhaps scalable bandwidth options to which to upgrade.
• Web-based management console with ease-of-use features such as drag and drop, e-mail updates, and file sharing.
• 24x7 technical support.
• Backed up data set validation; checking to determine if the backed up data matches the original data.
• Logging and reporting of operations.
• Open file backups of mission-critical transactional systems such as enterprise databases or e-mail/messaging applications.
• Multisite storage or replication, enabling data failover.
Table 15.2 lists some of the current backup services offered on unmanaged cloud storage.
Caution
It is important that data backed up to the cloud cannot be viewed without adequate safeguards or restrictions due to legal regulations concerning stored data in the area of health care and other sensitive endeavors.
|
TABLE 15.2 |
||||||
|
Cloud Storage Backup Solutions |
||||||
|
Service |
Site |
Windows/Linux/Mac |
Encryption |
Network Drive |
Synchronization |
File Hosting |
|
ADrive |
http://www.adrive.com/ |
Yes/Yes/Yes |
Optional |
Yes |
||
|
Backblaze |
http://www.backblaze.com/ |
Yes/No/Yes |
Yes; per user |
|||
|
Barracuda Backup Service |
http://www.barracudanetworks.com |
Yes/Yes/Yes |
Yes |
Yes |
Yes |
No |
|
Carbonite |
http://www.carbonite.com/ |
Yes/No/Yes |
Optional |
Yes (Pro) |
Yes |
|
|
Crashplan |
http://b5.crashplan.com/ |
Yes/Yes/Yes |
Yes; per user |
|||
|
Datapreserve |
http://www.datapreserve.com/ |
Yes/Yes/Yes |
Yes |
No |
Yes |
No |
|
Dell Datasafe |
https://www.delldatasafe.com/ |
Yes/No/No |
Yes |
No |
Yes |
No |
|
DriveHG |
http://www.drivehq.com/ |
Yes |
No (free); Yes (Premium) |
|||
|
Dropbox |
https://www.dropbox.com/ |
Yes/Yes/Yes |
Yes; per user |
Yes |
Yes |
|
|
ElephantDrive |
http://www.elephantdrive.com/ |
Yes/Partial/Yes |
Yes |
|||
|
Engyte |
http://www.egnyte.com/ |
Yes/Yes/Yes |
Yes |
Yes |
Yes |
|
|
Evault (Seagate i365) |
http://www.i365.com/ |
Yes/Yes/No |
Yes |
No |
No |
No |
|
Humyo |
http://www.humyo.com/ |
Yes/Partial/Yes |
Yes |
Yes |
Yes |
Yes |
|
IBackup |
http://www.ibackup.com/ |
Yes/Yes/Yes |
Yes |
No |
No |
No |
|
iDrive |
http://www.idrive.com/ |
Yes/No/No |
Yes |
Yes |
Yes |
Yes |
|
Jungle Disk |
https://www.jungledisk.com/ |
Yes/Yes/Yes |
Yes; per user |
|||
|
KeepVault |
http://www.keepvault.com/ |
Yes/No/No |
Yes; per user |
|||
|
Memopal |
http://www.memopal.com/en/ |
Yes/Yes/Yes |
Yes |
Yes |
Yes |
|
|
Mindtime Backup |
http://www.mindtimebackup.com/ |
Yes/Yes/Yes |
No |
Yes |
No |
|
|
MobileMe (Apple) |
http://www.me.com |
Yes/No/Yes |
No |
No |
Yes |
Yes |
|
Mozy |
http://mozy.com/ |
Yes/No/Yes |
Optional; per user |
|||
|
OrbitFiles |
http://www.orbitfiles.com/ |
Yes/Yes/Yes |
Yes |
Yes |
||
|
SOS Online Backup |
http://www.sosonlinebackup.com/ |
Yes/No/No |
Yes; per user |
Yes |
||
|
SpiderOak |
https://spideroak.com/ |
Yes/Yes/Yes |
Yes; per user |
|||
|
Steek |
http://www.steek.com/ |
Yes/?/? |
||||
|
SugarSync (formerly Sharpcast) |
http://www.sugarsync.com/ |
Yes/No/Yes |
Yes |
Yes |
Yes |
Yes |
|
Symantec Online Backup |
http://www.spn.com |
Yes/No/Yes |
Yes |
No |
No |
No |
|
Ubuntu One |
https://one.ubuntu.com/ |
No/Yes/No |
Yes |
N/A |
Yes |
No |
|
Unitrends Vault2Cloud |
http://www.unitrends.com/ |
Yes/Yes/Yes |
No |
Yes |
Yes |
No |
|
UpdateStar Online Backup |
http://client.updatestar.com/ |
Yes/No/No |
Yes; per user |
|||
|
Windows Live Mesh |
www.mesh.com |
Yes/No/Yes |
Partial; transmission only |
Yes |
||
|
Windows Live SkyDrive |
http://skydrive.live.com/ |
Yes/No/No |
Yes |
|||
|
Windows Live Sync |
http://sync.live.com/ |
Yes/No/Yes |
Yes |
|||
|
Wu.ala |
http://wua.la/ |
Yes/Yes/Yes |
Yes |
|||
|
Yuntaa |
http://www.yuntaa.com/ |
Yes/No/No |
Yes |
Yes |
Yes |
Yes |
|
ZumoDrive |
http://www.zumodrive.com/ |
Yes/Yes/Yes |
Yes |
Yes |
Yes |
Yes |
Source: Based on http://en.wikipedia.org/wiki/Comparison_of_online_backup_services, June 7, 2010, http://tomuse.com/ultimate-review-list-of-best-free-online-storage-and-backup-application-services/, and other sources.
Cloud attached backup
The backup solutions described have been client- or software-based solutions that are useful for an individual desktop or server. However, some interesting hardware-based solutions are available for backing up your systems to cloud-based storage.
CTERA (http://www.ctera.com/home/cloud-attached-storage.html) sells a server referred to as Cloud Attached Storage, which is meant for the Small and Medium Business (SMB) market, branch offices, and the Small Office Home Office (SOHO) market.
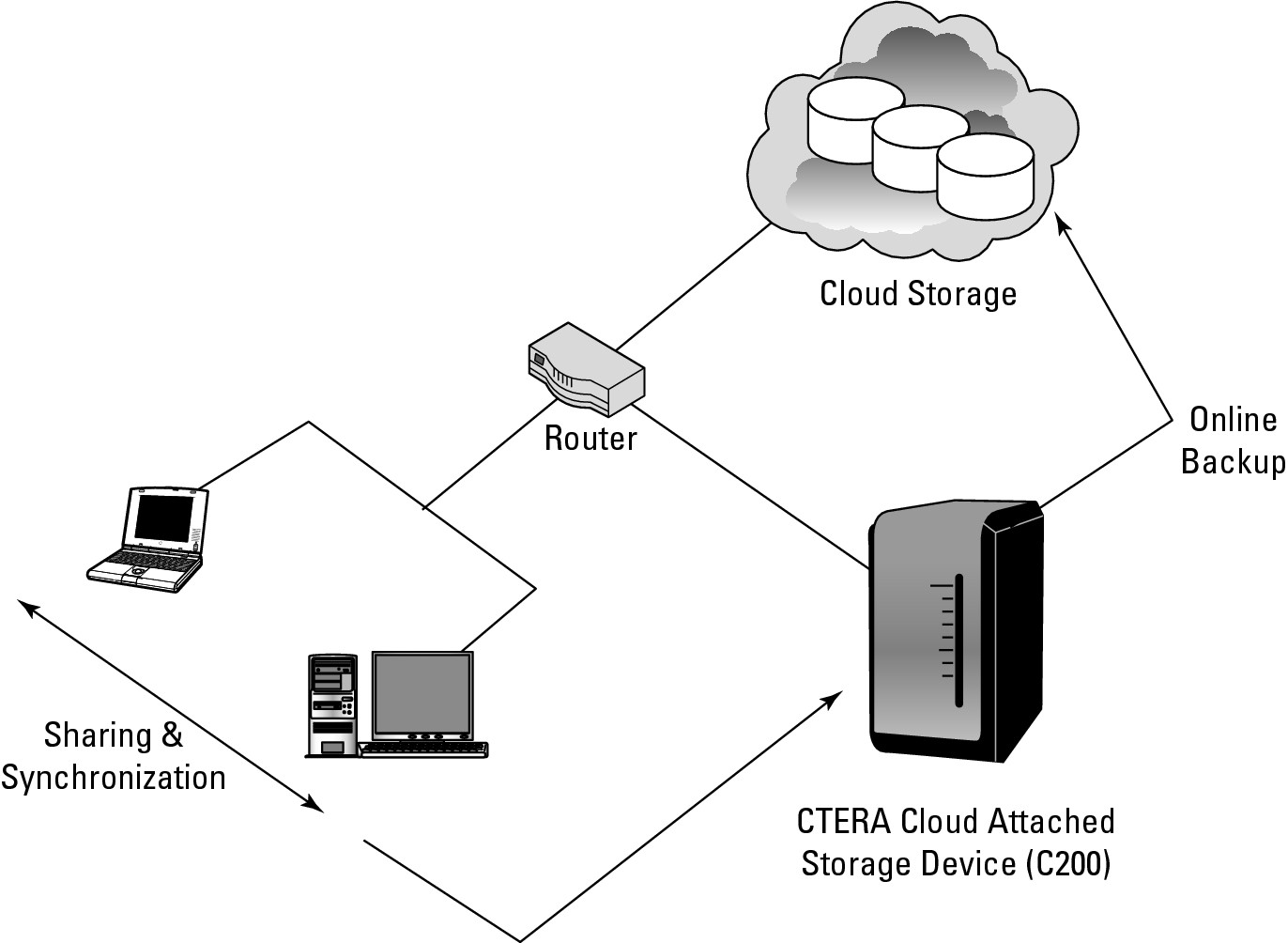
The CTERA Cloud Attached Storage backup server has the attributes of a NAS (Network Attached Storage), with the added feature that after you set up which systems you want to back up, create user accounts, and set the backup options through a browser interface, the system runs automated backup copying and synchronizing of your data with cloud storage. Backed up data may be shared between users. Figure 15.7 shows how the CTERA Cloud Attached Storage Device is deployed in practice.
CTERA cloud backup provides a solution that optimizes the backup based on bandwidth availability. It performs incremental backups from the server, compressing and encrypting the data that is transmitted to CTERA's cloud storage servers where de-duplication is performed. The CTERA server performs the backups of clients without requiring any client-based software. Clients have browser-based access to the backups or can locally access files using CTERA's “Virtual Cloud Drive” network drive. Snapshots are captured on the CTERA Next3 file system, which is based on the open source Ext3 file system.
FIGURE 15.7
CTERA's cloud-attached storage network backup scenario
The development of systems on a chip has enabled CTERA to create a scaled-down version of the CTERA server called the CTERA CloudPlug for the SOHO market. This palm-sized low-power device converts a USB/eSATA drive and your Ethernet network and turns the hard drive into a NAS server. CloudPlug performs backup and synchronization services and then performs automated or on-demand backups and snapshots of your systems.
CloudPlug uses UPnP (Universal Plug and Play) and Bonjour to discover systems on the network and then installs a small agent on those systems. The software works with Microsoft Active Directory and allows for role-based user access. Among the protocols it supports are the Common Internet File Sharing (CIFS) used by Windows and Apple File Sharing (AFP) systems. It can back up NTFS, FAT32, EXT3, and the NEXT3 file systems. Laptops may be backed up from any location because they are assigned a roaming profile with dynamic IP support. The system also backs up locked files.
Cloud Storage Interoperability
Large network storage deployments tend to get populated by vendors who provide unique functionality for their systems by creating proprietary APIs for the storage hardware that they sell. This problem exists for online network storage, Storage Area Networks (SANs), and to an even greater extent for cloud storage systems. Storage vendors have encouraged adoption of their proprietary APIs by making them “open,” but cloud system vendors have not responded by making any single API an industry standard. The development of Open Source APIs from the Open Source community has only added more storage APIs to the mix.
Cloud Data Management Interface (CDMI)
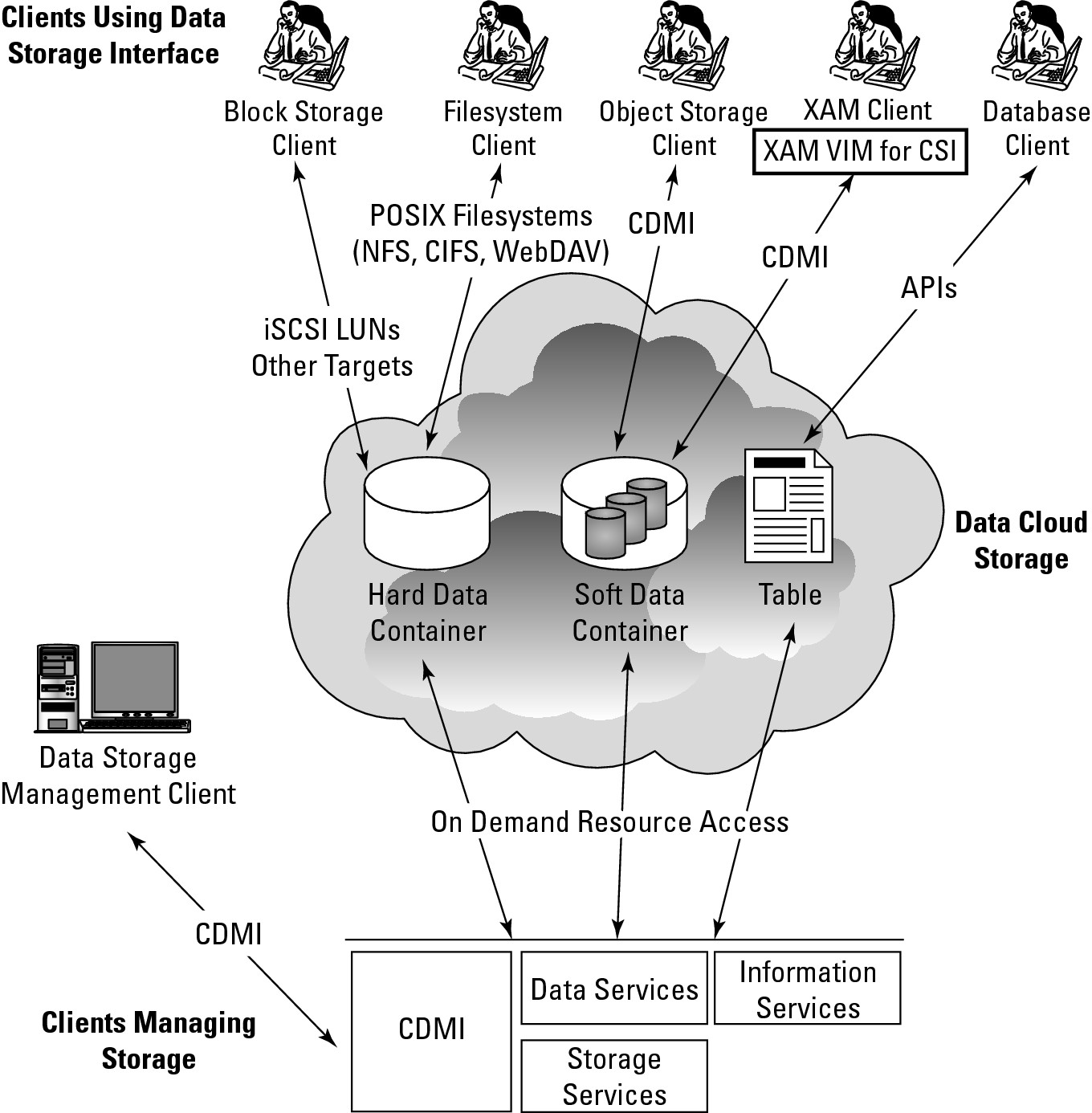
An example of an open cloud storage management standard is the Storage Networking Industry Association's (SNIA; http://www.snia.org) Cloud Data Management Interface (CDMI). CDMI works with the storage domain model shown in Figure 15.8 to allow for interoperation between different cloud systems, whether on public, private, or hybrid cloud systems. CDMI includes commands that allow applications to access cloud storage and create, retrieve, update, and delete data objects; provides for data object discovery; enables storage data systems to communicate with one another; and provides for security using standard storage protocols, monitoring and billing, and authentication methods. CDMI uses the same authorization and authentication mechanism as NFS (Network File System) does.
In the Cloud Data Management Interface (CDMI), the storage space is partitioned into units called containers. A container stores a set of data in it and serves as the named object upon which data service operations are performed. The CDMI data object can manage CDMI containers, as well as containers that are accessible in cloud storage through other supported protocols.
Figure 15.8 shows the SNIA cloud storage management model. In the figure, XAM stands for the eXtensible Access Method, a storage API developed by SNIA for accessing content on storage devices. VIM stands for Vendor Interface Modules, which is an interface that converts XAM requests into native commands that are supported by the storage hardware operating systems.
CDMI can access objects stored in the cloud by using standard HTTP command and the REST (Representational State Transfer) protocol to manipulate those objects. CDMI also can discover objects and can export and manage those exported objects as part of a storage space called a container. CDMI provides an interface through which applications can gain access to the storage objects in a container over the Web. Other features of CDMI are access controls, usage accounting, and the ability to advertise containers so that applications see these containers as if they are volumes (LUNs with a certain size).
CDMI uses metadata for HTTP, system, user, and storage media attributes accessing them through a standard interface using a schema that is known as the Resource Oriented Architecture (ROA). In this architecture, every resource is identified by a standardized URI (Uniform Resource Identifier) that may be translated into both hypertext (HTTP) and other forms. CDMI uses the SNIA eXtensible Access Method (XAM) to discover and access metadata associated with each data object.
Metadata is stored not only for data objects, but for data containers so that any data placed into a container assumes the metadata associated with that container. Should there be conflicting metadata at different levels of the hierarchy (container, object, and so on), the most granular level object's metadata attribute takes precedence.
FIGURE 15.8
CDMI allows data in cloud storage to be managed from a variety of resources.
Source: “Cloud Storage for Cloud Computing” SNIA/OGF, September 2009, http://ogf.org/Resources/documents/CloudStorageForCloudComputing.pdf.
In CDMI, resources are identified as nouns, which have attributes in the form of key-value pairs, upon which actions in the form of verbs may be performed. Standard actions include the standard CRUD operations: Create, Retrieve, Update, and Delete; which translates into the standard HTTP action verbs POST, GET, PUT, and DELETE. Additionally, the HEAD and OPTIONS verbs provide a wrapper for metadata and operational instructions.
A typical action might be a PUT or GET operation, as follows:
PUT http://www.cloudy.com/store/<myfile>
GET http://www.cloudy.com/compute/<myfile>
The domain cloudy.com would be the service provider, myfile is the instance, and compute is the folder containing the file. In a PUT operation, the container (store) is created if it didn't exist previously. The metadata KEY/VALUE pair MIME is required in a PUT; other metadata KEY/VALUE pairs are optional in a PUT. A variety of KEY/VALUE pairs describing object attributes in CDMI is defined by the standard.
Open Cloud Computing Interface (OCCI)
SNIA and the Open Grid Forum (OGF; http://www.ogf.org/) have created a joint working group to create the Open Cloud Computing Interface (OCCI), an open standard API for cloud computing infrastructure systems. OCCI is meant to span the different vendors' standards and allow for system interoperability.
Note
To view the Cloud Standards Wiki with information about all the different standards groups working in this area of technology, go to: http://cloud-standards.org/wiki/index.php?title=Main_Page. This page contains links to the work of groups in cloud storage, virtual machines, protocols, and more.
The OCCI interface standard is based on the Resource Oriented Architecture (ROA) and uses the URI definition for OCCI that was previously defined by SNIA's Cloud Data Management Interface (CDMI) that OCCI interoperates with CDMI. Associations between resources appear in the HTTP header in the Atom Publishing Protocol (AtomPub or APP) that transfers the Atom Syndication Format (XML) used for XML Web news feeds. The OCCI API maps to other formats such as Atom/Pub, JSON, and Plain Text.
OCCI specifies, but does not mandate, what is called a service life cycle. In a service life cycle, a client (service requestor) instantiates or invokes a new application and through OCCI commands provisions its storage resources, manages the application's use, and then manages the application's destruction and the release of its cloud storage.
Cloud storage devices can be either a block or file system storage device, and in that regard they are no different than online network storage devices or even local storage. It is the ability to provide storage on a demand basis and pay as you go that is the key differentiator for cloud storage. The ability to provide storage on demand from a storage pool is referred to as thin provisioning, a term that also applies to compute resources such as virtual machines. Management of cloud storage is performed by out-of-band management systems through a data storage interface. Out-of-band refers to a management console that isn't on the storage network, but is most often on an Ethernet network inside a browser. From the management console, additional data services such as cloning, compression, de-duplication, and snapshots may be invoked.
As previously mentioned, CDMI and OCCI are meant to interoperate, and CDMI containers can be accessed through a data path and over other protocols. A CDMI container can be exported and then used as a virtual disk by Virtual Machines in the cloud. The cloud infrastructure management console can be used to attach exported CDMI containers to the Virtual Machine that is desired. CDMI exports containers so the information that is obtained from the OCCI interface is part of the exported container. OCCI also can create containers that are interoperable with CDMI containers. These export operations can be initiated from either the OCCI or CDMI interfaces, with similar results. However, there are syntactical differences between using either interface as the export starting point. In Figure 15.9, CDMI and OCCI are shown interoperating with cloud resources of different types.
FIGURE 15.9
CDMI and OCCI interoperating in an integrated cloud system
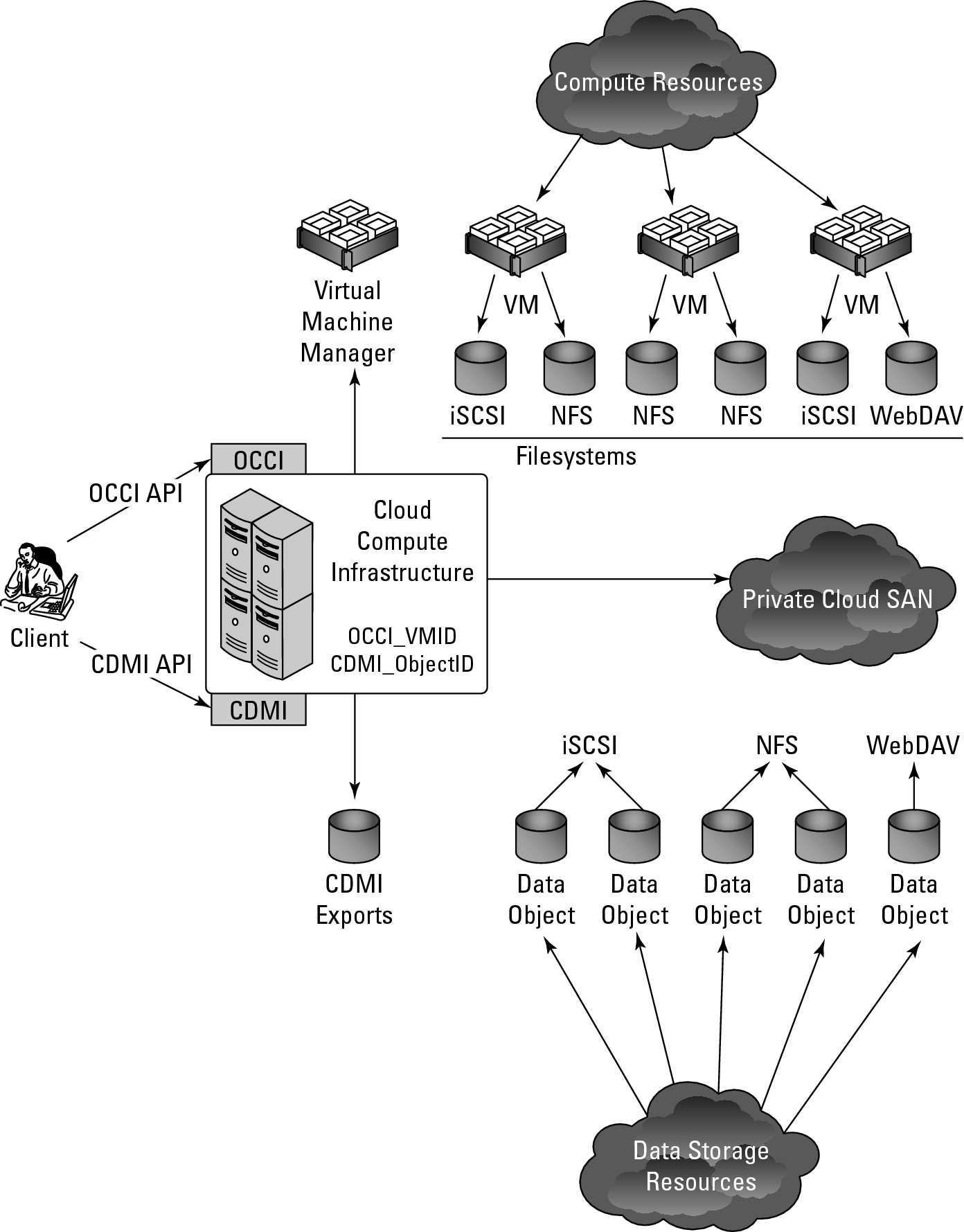
Source: “Cloud Storage for Cloud Computing” SNIA/OGF, September 2009, http://ogf.org/Resources/documents/CloudStorageForCloudComputing.pdf.
Summary
In this chapter, you learned about the nature of stored digital data and the role that cloud storage will play in the future in storing and processing data.
Cloud storage is classified as either unmanaged or managed storage. Most user applications work with unmanaged storage. The two major classes of cloud-based storage applications described in this chapter were file sharing and backup utilities. Managed storage is cloud storage that you provision for Web services or applications using cloud storage that you are developing. Managed storage requires you to prepare the disk and manage its use.
All cloud storage vendors partition storage on the basis of a virtual storage container. A model describing the virtual storage container is described. Efforts to make cloud storage systems interoperate, particularly the CDMI and OCCI protocols, were described.
In Chapter 16, “Working with Productivity Software,” I consider desktop applications that replace office suite applications. These applications have the potential to displace a major portion of their commercial shrink-wrapped software counterparts over time, and while not as feature-filled as commercial software, they are surprisingly good. The chapter discusses the state of the art in this area and makes some predictions of what to expect over time.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.