NoSQL for Mere Mortals (2015)
Part IV: Column Family Databases
Chapter 10. Column Family Database Terminology
“Uttering a word is like striking a note on the keyboard of the imagination.”
—LUDWIG WITTGENSTEIN
PHILOSOPHER
Topics Covered In This Chapter
Basic Components of Column Family Databases
Structures and Processes: Implementing Column Family Databases
Processes and Protocols
When you read documentation and books about column family databases, you will see many familiar terms. Columns, partitions, and keyspaces are just a few of the commonly used terms you will see. When you are trying to understand a new technology, it often helps when the new technology uses the same terms used in existing technology—that is, unless they mean something else.
This chapter consists of descriptions of words and terms used in column family databases. The definitions are specific to column family databases. There are no minimalist definitions designed to satisfy a logician’s desire for parsimony. The descriptions are designed to meet the needs of database designers, software developers, and others interested in understanding what makes column family databases different from other databases.
The next section of this chapter focuses on the elements of column family databases that you should understand to get started working with databases like Cassandra and HBase. Developers of column family databases will regularly deal with these components.
Next, the focus moves onto terms associated with implementing column family databases. Many of these terms refer to data structures or processes that are not obvious to application developers, but are essential for efficient implementation of the database.
![]() Note
Note
To use a column family database, you do not need to know the details of how partitioning works, but it helps—quite a bit. If some of the terminology in the implementation section seems obscure and too low level to matter to you (for example, Bloom filters and gossip protocols), then you can skim the material now.
Basic Components of Column Family Databases
The basic components of a column family database are the data structures developers deal with the most. These are the data structures that developers define explicitly, such as a column. The terms described in this section include
• Keyspace
• Row key
• Column
• Column families
With these basic components, you can start constructing a column family database.
Keyspace
A keyspace is the top-level data structure in a column family database (see Figure 10.1). It is top level in the sense that all other data structures you would create as a database designer are contained within a keyspace. A keyspace is analogous to a schema in a relational database. Typically, you will have one keyspace for each of your applications.
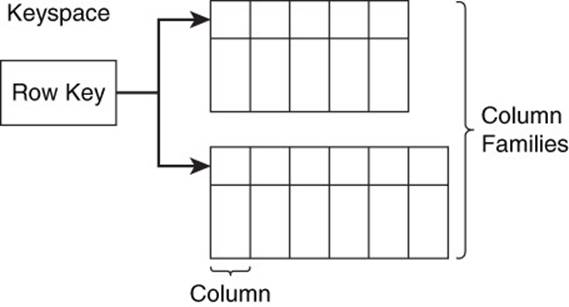
Figure 10.1 A keyspace is a top-level container that logically holds column families, row keys, and related data structures. Typically, there is one keyspace per application.
Row Key
A row key uniquely identifies a row in a column family. It serves some of the same purposes as a primary key in a relational database (see Figure 10.2).
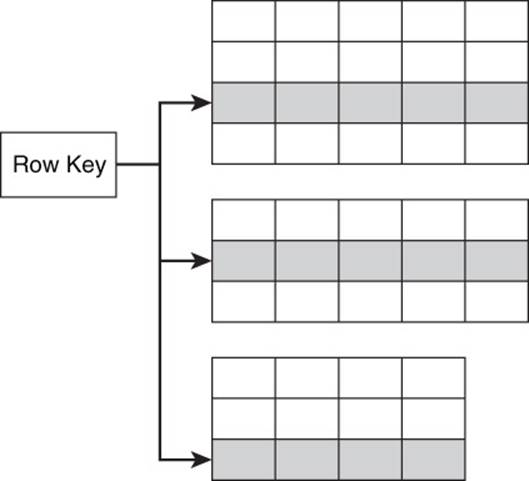
Figure 10.2 A row key uniquely identifies a row and has a role in determining the order in which data is stored.
Row keys are one of the components used to uniquely identify values stored in a database. The others are column family names, column names, and a version ordering mechanism, such as a time stamp.
In addition to uniquely identifying rows, row keys are also used to partition and order data. In HBase, rows are stored in lexicographic order of row keys. You can think of this as alphabetic ordering with additional orderings for nonalphabetic characters.
In Cassandra, rows are stored in an order determined by an object known as a partitioner. Cassandra uses a random partitioner by default. As the name implies, the partitioner randomly distributes rows across nodes. Cassandra also provides an order-preserving partitioner, which can provide lexicographic ordering.
Column
A column is the data structure for storing a single value in a database (see Figure 10.3). Depending on the type of column family database you are using, you might find values are represented simply as a string of bytes. This minimizes the overhead on the database because it does not validate data types. HBase takes this approach.
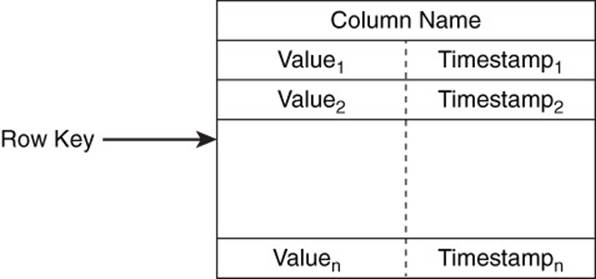
Figure 10.3 A column, along with a row key and version stamp, uniquely identifies values.
In other cases, you might be able to specify data types ranging from integers and strings to lists and maps. Cassandra’s Query Language (CQL) offers almost 20 different data types.
Values can vary in length. For example, a value could be as simple as a single integer, such as 12, or as complex as a highly structured XML document.
Columns are members of column family databases. Database designers define column families when they create a database. However, developers can add columns any time after that. Just as you can insert data into a relational table, you can create new columns in column family databases.
Columns have three parts:
• A column name
• A time stamp or other version stamp
• A value
The column name serves the same function as a key in a key-value pair: It refers to a value.
The time stamp or other version stamp is a way to order values of a column. As the value of a column is updated, the new value is inserted into the database and a time stamp or other version stamp is recorded along with the column name and value. The version mechanism allows the database to store multiple values associated with a column while maintaining the ability to readily identify the latest value. Column family databases vary in the types of version control mechanisms used.
Column Families
Column families are collections of related columns. Columns that are frequently used together should be grouped into the same column family. For example, a customer’s address information, such as street, city, state, and zip code, should be grouped together in a single column family.
Column families are stored in a keyspace. Each row in a column family is uniquely identified by a row key. This makes a column family analogous to a table in a relational database (see Figure 10.4). There are important differences, however. Data in relational database tables is not necessarily maintained in a predefined order. Rows in relational tables are not versioned the way they are in column family databases.
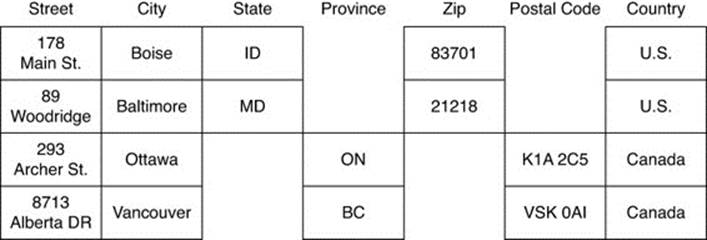
Figure 10.4 Column families are analogous to relational database tables: They store multiple rows and multiple columns. There are, however, significant differences between the two, including varying columns by row.
Perhaps most importantly, columns in a relational database table are not as dynamic as in column family databases. Adding a column in a relational database requires changing its schema definition. Adding a column in a column family database just requires making a reference to it from a client application, for example, inserting a value to a column name.
In many ways, the data structures that database application designers work with are just the tip of the column family database iceberg. There are many more components of column family databases that support the more apparent structures.
The next section focuses on these underlying structures and processes that implement essential functions of column family databases.
Structures and Processes: Implementing Column Family Databases
Column family databases are complicated. There are many processes that continually run in order to ensure the database functions as expected. There are also sophisticated data structures that significantly improve performance over more naive implementations.
Internal Structures and Configuration Parameters of Column Family Databases
Internal structures and configuration parameters of column family databases span the full range of the database—from the lowest level of storing a single value up to the high-level components of the database. Several are particularly important for database application designers and developers to understand:
• Cluster
• Partition
• Commit log
• Bloom filter
• Replication count
• Consistency level
Clusters and partitions are commonly used in distributed databases and are probably familiar topics by now. Vector clocks are used in version management. The commit log and Bloom filter are supporting data structures that improve integrity and availability of data as well as the performance of read operations.
Replication count and consistency level are configuration parameters that allow database administrators to customize functionality of the column family database according to the needs of applications using it.
Old Friends: Clusters and Partitions
Clusters and partitions enable distributed databases to coordinate processing and data storage across a set of servers.
Cluster
A cluster is a set of servers configured to function together. Servers sometimes have differentiated functions and sometimes they do not (see Figure 10.5).
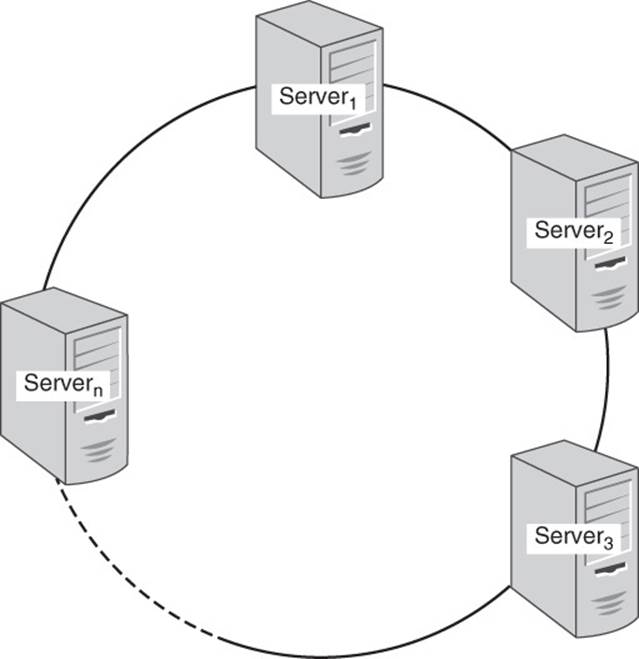
Figure 10.5 Clusters are collections of servers functioning together to implement a distributed service, such as a column family database.
HBase is a part of the Hadoop infrastructure. It uses the various types of servers to implement the functional requirements of Hadoop. Hadoop implementation details are outside the scope of this book.1
1. The interested reader should see Professional Hadoop Solutions by Boris Lublinsky, Kevin T. Smith, and Alexy Yakubovich (Worx, 2013).
Cassandra, on the other hand, uses a single type of node. There are no master or slave nodes. Each node shares similar responsibilities, including
• Accepting read and write requests
• Forwarding read and write requests to servers able to fulfill the requests
• Gathering and sharing information about the state of servers in the clusters
• Helping compensate for failed nodes by storing write requests for the failed node until it is restored
These operations are all required to maintain a functional distributed database. At the same time, these operations are too low level to concern database application developers. If they had to write code to ensure they sent read and write requests to the proper server or had to maintain state information about each server in the cluster, it would add significantly more code to the application.
Partition
A partition is a logical subset of a database. Partitions are usually used to store a set of data based on some attribute of the data (see Figure 10.6). For example, a database might assign data to a particular partition based on one of the following:
• A range of values, such as the value of a row ID
• A hash value, such as the hash value of a column name
• A list of values, such as the names of states or provinces
• A composite of two or more of the above options
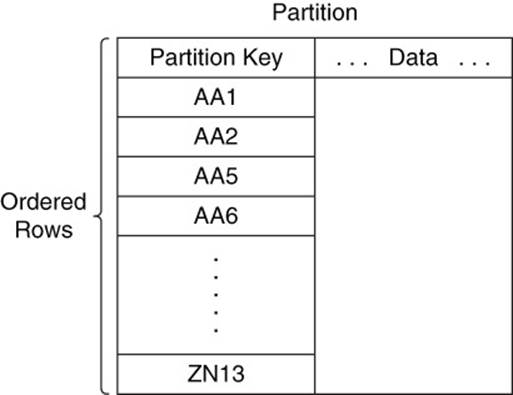
Figure 10.6 Partitions store data ordered by partition key.
Each node or server within a column family cluster maintains one or more partitions.
When a client application requests data, the request is routed to a server with the partition containing the requested data. A request could go to a central server in a master-slave architecture or to any server in a peer-to-peer architecture. In either case, the request is forwarded to the appropriate server.
In practice, multiple servers may store copies of the same partition. This improves the chances of successfully reading and writing data even in the event of server failures. It can also help improve performance because all servers with copies of a partition can respond to requests for data from that partition. This model effectively implements load balancing.
Taking a Look Under the Hood: More Column Family Database Components
In addition to the structures and procedures you will routinely work with, there are a few less visible components of column family databases worth understanding. These include
• Commit logs
• Bloom filter
• Consistency level
These components are not obvious to most developers, but they play crucial roles in achieving availability and performance.
Commit Log
If your application writes data to a database and receives a successful status response, you reasonably expect the data to be stored on persistent storage. Even if a server fails immediately after sending a write success response, you should be able to retrieve your data once the server restarts (see Figure 10.7).
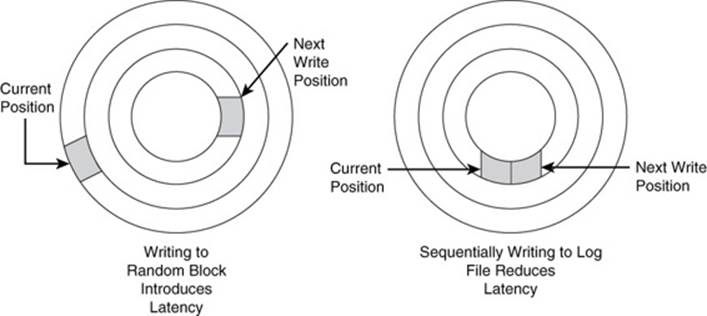
Figure 10.7 A commit log saves data written to the database prior to writing it to partitions. This reduces the latency introduced by random writes on disks.
One way to ensure this is to have the database write data to disk (or other persistent storage) before sending the success response. The database could do this, but it would have to wait for the read/write heads to be in the correct position on the disk before writing the data. If the database did this for every write, it could significantly cut down on write performance.
Instead of writing data immediately to its partition and disk block, column family databases can employ commit logs. These are append only files that always write data to the end of the file.
![]() Tip
Tip
When database administrators dedicate a disk to a commit log, there are no other write processes competing to write data to the disk. This reduces the need for random seeks and reduces latency.
In the event of a failure, the database management system reads the commit log on recovery. Any entries in the commit log that have not been saved to partitions are then written to appropriate partitions (see Figure 10.8).
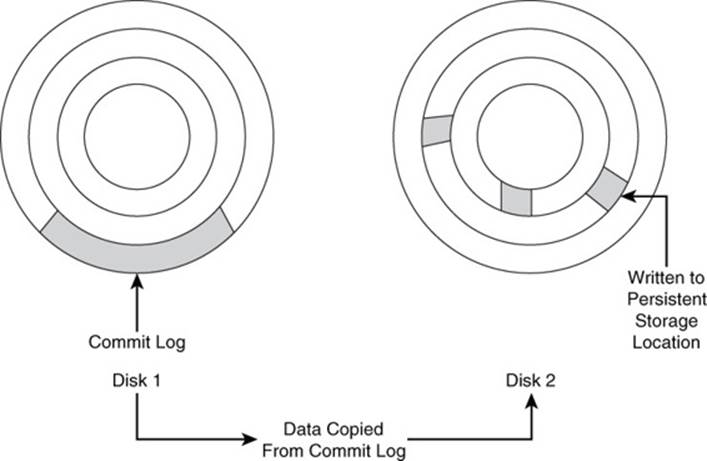
Figure 10.8 After a database failure, the recovery process reads the commit log and writes entries to partitions. The database remains unavailable to users until all commit log entries are written to partitions.
Bloom Filter
Anything that reduces the number of blocks read from disk or solid state device can help improve performance. Applying Bloom filters is one such technique.
A Bloom filter tests whether or not an element is a member of a set (see Figure 10.9). Unlike a typical member function, the Bloom filter sometimes returns an incorrect answer. It could return a positive response in cases where the tested element is not a member of the set. This is known as a false-positive. Bloom filters never return a negative response unless the element is not in the set.
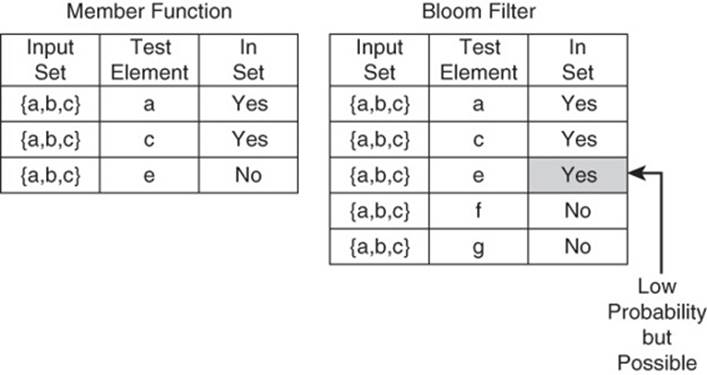
Figure 10.9 Member functions always return accurate results. Bloom filters usually return accurate results but sometimes make false-positive errors.
Bloom filters help reduce the number of read operations by avoiding reading partitions or other data structures that definitely do not contain a sought-after piece of data.
Another way to achieve the same benefit is to use a hash function. For example, assume you partition customer data using a hash function on a person’s last name and city. The hash function would return a single value for each last name–city combination. The application would only need to read that one partition. Why should database developers use Bloom filters that sometimes return incorrect?
Bloom filters use less memory than typical hash functions, and the savings can be significant for the large-scale databases typically deployed in column family databases. Because a Bloom filter is a probabilistic data structure, you can tune your implementation according to the error rate you would like to achieve. The more memory you allocate for the Bloom filter, the smaller your error rate. If you can tolerate a 1% false-positive rate, you can implement a Bloom filter using about 10 bits per element. If you can afford another 5 bits per element, your error rate can reduce to 0.1%.
Both HBase and Cassandra make use of Bloom filters to avoid unnecessary disk seeks.
Consistency Level
Consistency level refers to the consistency between copies of data on different replicas. In the strictest sense, data is consistent only if all replicas have the same data. At the other end of the spectrum, you could consider the data “consistent” as long as it is persistently written to at least one replica. There are several intermediate levels as well.
Consistency level is set according to several, sometimes competing, requirements:
• How fast should write operations return a success status after saving data to persistent storage?
• Is it acceptable for two users to look up a set of columns by the same row ID and receive different data?
• If your application runs across multiple data centers and one of the data centers fails, must the remaining functioning data centers have the latest data?
• Can you tolerate some inconsistency in reads but need updates saved to two or more replicas?
In many cases, a low consistency level can satisfy requirements. Consider an application that collects sensor data every minute from hundreds of industrial sensors. If data is occasionally lost, the data sets will have missing values.
![]() Note
Note
A small number of missing values may not even be noticeable because this kind of data is often aggregated into sums, averages, standard deviations, and other descriptive statistics. In addition, missing data is a common problem in scientific and social science research; statisticians have developed a number of methods of compensating for missing data.
Other situations call for a moderate consistency level. Players using an online game reasonably expect to have the state of their game saved when they pause or stop playing on one device to switch to another. Even losing a small amount of data could frustrate users who have to repeat play and possibly lose gains made in the game.
To avoid disrupting players’ games in the event of a server failure, an underlying column family database could be configured with a consistency level requiring writes to two or three replicas. Using a higher level of consistency would increase availability but at the cost of slowing write operations and possibly adversely affecting gameplay.
The highest levels of consistency, such as writing replicas to multiple replicas in multiple data centers, should be saved for the most demanding fault-tolerant applications.
Processes and Protocols
In addition to the data structures described above, a number of important background processes are responsible for maintaining a functional column family database.
Replication
Replication is a process closely related to consistency level. Whereas the consistency level determines how many replicas to keep, the replication process determines where to place replicas and how to keep them up to date.
In the simplest case, the server for the first replica is determined by hash function, and additional replicas are placed according to the relative position of other servers. For example, all nodes in Cassandra are in a logical ring. Once the first replica is placed, additional replicas are stored on successive nodes in the ring in the clockwise direction.
Column family databases can also use network topology to determine where to place replicas. For example, replicas may be created on different racks within a data center to ensure availability in the event of a rack failure.
Anti-Entropy
Anti-entropy is the process of detecting differences in replicas. From a performance perspective, it is important to detect and resolve inconsistencies with a minimum amount of data exchange.
The naive way to compare replicas is to send a copy of one replica to the node storing another replica and compare the two. This is obviously inefficient. Even with high-write applications, much of the data sent from the source is the same as the data on the target node. Column family databases can exploit the fact that much of replica data may not change between anti-entropy checks. They do this by sending hashes of data instead of the data itself.
One method employs a tree of hashes, also known as a Merkle tree (see Figure 10.10). The leaf nodes contain hashes of a data set. The nodes above the leaf nodes contain a hash of the hashes in the leaf nodes. Each successive layer contains the hash of hashes in the level below. The root node contains the hash of the entire collection of data sets.
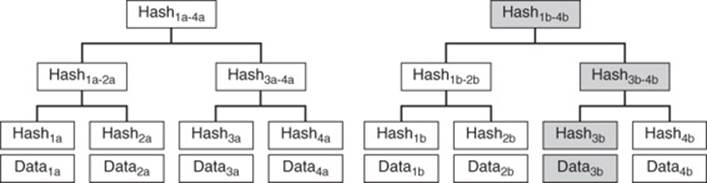
Figure 10.10 Hash trees, or Merkle trees, allow for rapid checks on consistency between two data sets. In this example, data3a and data3b are different, resulting in different hash values in each level from the data block to the root.
Anti-entropy processes can calculate hash trees on all replicas. One replica sends its hash tree to another node. That node compares the hash values in the two root nodes. If both are the same, then there is no difference in the replicas. If there is a difference, then the anti-entropy process can compare the hash values at the next level down.
At least one pair of these hash values will differ between replicas. The process of traversing the tree continues until the process reaches one or more leaf nodes that have changed. Only the data associated with those leaf nodes needs to be exchanged.
Gossip Protocol
A fundamental challenge in any distributed system is keeping member nodes up to date on information about other members of the system. This is not too much of a problem when the number of nodes in a cluster is small, say fewer than 10 servers. If every node in a server has to communicate with every other node, then the number of messages can quickly grow.
Table 10.1 shows how the number of messages that must be sent in complete communications protocol increases at the rate of n×(n–1)/2, where n is the number of nodes in the cluster.
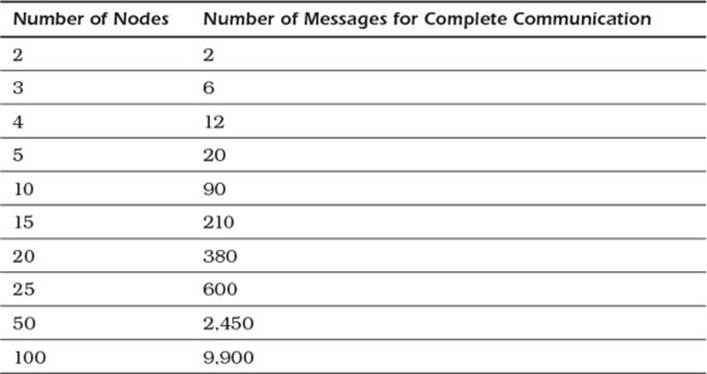
Table 10.1 Number of Messages Sent Per Node
Instead of having every node communicate with every other node, it is more efficient to have nodes share information about themselves as well as other nodes from which they have received updates. Consider a cluster with 10 nodes. If each node communicated with every other node, the system will send a total of 90 messages to ensure all nodes have up-to-date information.
Figure 10.11 shows that when using a gossip protocol—in which each node sends information about itself and all information it has received from other nodes—all nodes can be updated with a fraction of the number of messages required for complete communication.
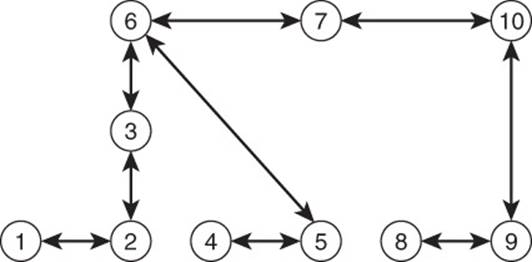
Figure 10.11 Gossip protocols spread information with fewer messages than a protocol that requires all nodes to communicate with all other nodes.
Hinted Handoff
Replicas enable read availability even if some nodes have failed. They do not address how to handle a write operation that is directed to a node that is down. The hinted handoff mechanism is designed to solve this problem.
If a write operation is directed to a node that is unavailable, the operation can be redirected to another node, such as another replica node or a node designated to receive write operations when the target node is down.
The node receiving the redirected write message creates a data structure to store information about the write operation and where it should ultimately be sent. The hinted handoff periodically checks the status of the target server and sends the write operation when the target is available.
Storing a hinted handoff data structure is not the same as writing to a replica. Hinted handoffs are stored in their own data structures and are managed by the hinted handoff process. Once the write data is successfully written to the target node, it can be considered a successful write for the purposes of consistency and replication.
Summary
Column family databases share some terminology with relational databases, but there are important differences in how those terms are used. Columns, for example, can have similar characteristics in both relational and column family databases, but they are implemented differently. Columns can be programmatically added to column family databases but require schema changes in relational databases. It is important to keep these differences in mind when working with column family databases.
The basic, logical components of a column family database are namespaces, column families, columns, and row keys. You should be familiar with these components when working with any column family database.
To understand the physical implementation of a column family database, you should understand at least partitions and clusters. To ensure you have adequately addressed availability and performance requirements, you should understand how commit logs are used and the trade-offs in setting replication parameters and consistency levels. For those who like to dig into details, it helps to understand Bloom filters, anti-entropy, gossip protocols, and hinted handoffs.
Review Questions
1. What is a keyspace? What is an analogous data structure in a relational database?
2. How do columns in column family databases differ from columns in relational databases?
3. When should columns be grouped together in a column family? When should they be in separate column families?
4. Describe how partitions are used in column family databases.
5. What are the performance advantages of using a commit log?
6. What are the advantages of using a Bloom filter?
7. What factors should you consider when setting a consistency level?
8. What factors should you consider when setting a replication strategy?
9. Why are hash trees used in anti-entropy processes?
10. What are the advantages of using a gossip protocol?
11. Describe how hinted handoff can help improve the availability of write operations.
References
Apache Cassandra Glossary: http://io.typepad.com/glossary.html
Apache HBase Reference Guide: http://hbase.apache.org/book.html
Bloom Filter: http://en.wikipedia.org/wiki/Bloom_filter
Hewitt, Eben. Cassandra: The Definitive Guide. Sebastopol, CA: O’Reilly Media, Inc., 2010.
Merkle Filter: http://en.wikipedia.org/wiki/Merkle_tree
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.