NoSQL for Mere Mortals (2015)
Part II: Key-Value Databases
Chapter 4. Key-Value Database Terminology
“I always try to think of a vocabulary to match different musical situations.”
—ROSCOE MITCHELL
JAZZ COMPOSER AND SAXOPHONIST
Topics Covered In This Chapter
Key-Value Database Data Modeling Terms
Key-Value Architecture Terms
Key-Value Implementation Terms
This chapter is different from the first three chapters of this book. The intent of this chapter is to provide an explanation of important terms used when discussing key-value databases. Introducing terminology of a new domain, like NoSQL databases, presents something of a chicken-and-egg problem.
Which should come first? Should you learn about the basic ideas of key-value databases and then delve into a more detailed understanding of the terms and concepts that underlie key-value databases? Or, should you first learn the definition of terms independent of the bigger picture of key-value databases? There are advantages and disadvantages to both approaches.
This book tries to have the best of both worlds by introducing basic concepts and then providing detailed descriptions of key terms followed by an advanced topics chapter that includes a discussion of design patterns, potential pitfalls and traps, and a case study describing a typical use case for key-value databases.
This chapter is organized into three broad, somewhat overlapping topics: data modeling terms, architecture terms, and implementation terms. This structure is somewhat arbitrary and you could make the case that some terms in the architecture section should be in the implementation section and vice versa. The placement of the terms in chapter sections is far less important than the terms themselves.
NoSQL databases do not share the same level of standardization you find in relational databases. There is, for example, no standard NoSQL query language comparable to relational databases’ SQL. Different vendors and open source projects sometimes introduce terms or use data structures not found in other NoSQL databases.
The terminology chapters (there is one for each of the four major types of NoSQL database) offer an opportunity to introduce vendor-or project-specific terminology. Although the For Mere Mortals series of books tends to not focus on specific software, a familiarity with vendor and open source project-specific terms may help when you start implementing your own NoSQL database–based applications.
Key-Value Database Data Modeling Terms
Data models are abstractions that help organize the information conveyed by the data in databases. They are different from data structures.
Data structures are well-defined data storage structures that are implemented using elements of underlying hardware, particularly random access memory and persistent data storage, such as hard drives and flash devices. For example, an integer variable in a programming language may be implemented as a set of four contiguous bytes, or 32 bits.
An array of 100 integers can be implemented as a contiguous set of 4-byte memory addresses. Data structures also have a set of operations that manipulate the data structure. Addition, subtraction, multiplication, and division are some of the operations defined on integers. Reading and writing values based on indices are operations defined on arrays.
Data structures offer a higher level of organization so you do not have to think in low-level terms of memory addresses and machine-level operations on those addresses. Data models serve a similar purpose. They provide a level of organization and abstraction above data structures (seeFigure 4.1).
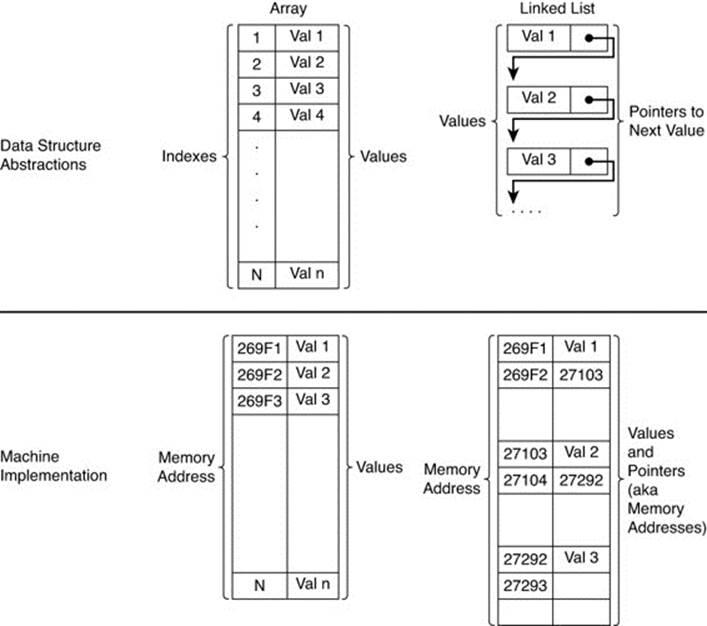
Figure 4.1 Data structures provide higher-level organizations than available at the machine level.
Data models typically organize multiple kinds of related information. A customer management data model could model information about customers’ names, addresses, orders, and payment histories. Clinical databases could include information such as patients’ names, ages, genders, current prescriptions, past surgeries, allergies, and other medically relevant details.
In theory, you could write software that tracks all of these pieces of data in basic database structures like arrays and linked lists. In practice, such an approach would be an inefficient use of your time. Using data models and databases is a more effective and productive strategy (see Figure 4.2).
Figure 4.2 Data models provide a layer of abstraction above data structures that allows database application developers to focus more on the information that must be managed and less on implementation issues.
The elements of data models vary with the type of database. Relational databases are organized around tables. Tables are used to store information about entities, such as customers, patients, orders, and surgeries. Entities have attributes that capture information about particular entities. Attributes include names, ages, shipping addresses, and so forth.
In a relational database, a table is organized by a set of columns and each column corresponds to an attribute. Rows of the table correspond to a single instance of an entity, such as a particular customer or patient.
The software engineers who design databases choose data structures for implementing tables and other elements of a data model. This relieves application developers of needing to delve into such details. The price application developers must pay, however, is learning the terms and design patterns associated with data models used in their database.
![]() Note
Note
In relational database design, there is a distinction between logical data models and physical data models. Entities and attributes are used in logical data models. Tables and columns are the corresponding elements of physical data models. This book uses both entity and table. Because this is not a book about relational database design, a detailed explanation of the differences of logical and physical data models and when to use terms from each is beyond the scope of this book. For more on relational data modeling, see Michael J. Hernandez’s Database Design for Mere Mortals, Second Edition (Addison-Wesley, 2003).
The following sections discuss some of the most important terms associated with data modeling in key-value databases, including key, value, namespace, partition, partition key, and schemaless.
Key
A key is a reference to a value. It is analogous to an address. The address 1232 NE River St. is a reference to a building located in a particular place. Among other things, it enables postal workers and delivery services to find a particular building and drop off or pick up letters and packages. The string “1232 NE River St.” is obviously not a building, but it is a way to find the corresponding building. Keys in key-value databases are similarly not values but are ways of finding and manipulating values.
A key can take on different forms depending on the key-value database used. At a minimum, a key is specified as a string of characters, such as "Cust9876" or "Patient:A384J:Allergies". Some key-value databases, such as Redis (www.redis.io), support more complex data structures as keys. The supported key data types in Redis version 2.8.13 include
• Strings
• Lists
• Sets
• Sorted sets
• Hashes
• Bit arrays
![]() Note
Note
Redis developers use the term data structures server instead of key-value data store. Visit http://redis.io/topics/data-types-intro for more information.
Lists are ordered collections of strings. Sets are collections of unique items in no particular order. Sorted sets, as the name implies, are collections of unique items in a particular order. Hashes are data structures that have key-value characteristics: They map from one string to another. Bit arrays are binary integer arrays in which each individual bit can be manipulated using various bit array operations.
![]() Refer to the “Hash Functions” section later in this chapter for more detailed information on this topic.
Refer to the “Hash Functions” section later in this chapter for more detailed information on this topic.
It helps to have a naming convention when creating keys, such as described in Chapter 3, “Introduction to Key-Value Databases.” One convention is to use a combination of strings representing an entity type, a unique identifier for a particular entity, and an attribute.
![]() Caution
Caution
Keep in mind that strings should not be too long. Long keys will use more memory and key-value databases tend to be memory-intensive systems already. At the same time, avoid keys that are too short. Short keys are more likely to lead to conflicts in key names. For example, the key
CMP:1897:Name
could refer to the name of a marketing campaign or the name of a component in a product. A better option would be
CAMPN:1897:Name
to refer to a marketing campaign and
COMPT:1897:Name
to refer to a component in a product.
Keys can also play an important role in implementing scalable architectures. Keys are not only used to reference values, but they are also used to organize data across multiple servers. The upcoming “Partition” section describes the use of keys for organizing data across servers.
Value
The definition of value with respect to key-value databases is so amorphous that it is almost not useful. A value is an object, typically a set of bytes, that has been associated with a key. Values can be integers, floating-point numbers, strings of characters, binary large objects (BLOBs), semistructured constructs such as JSON objects, images, audio, and just about any other data type you can represent as a series of bytes.
![]() Note
Note
It is important to understand that different implementations of key-value databases have different restrictions on values. Most key-value databases will have a limit on the size of a value. Redis, for example, can have a string value up to 512MB in length.1 FoundationDB (foundationdb.com), a key-value database known for its support of ACID transactions, limits the size of values to 100,000 bytes.2
1. http://redis.io/topics/data-types
2. https://foundationdb.com/key-value-store/documentation/beta1/known-limitations.html
Key-value implementations will vary in the types of operations supported on values. At the very least, a key-value database will support getting and setting values. Others support additional operations, such as appending a string to an existing value or randomly accessing a section of a string. This can be more efficient than retrieving a value, returning it to a client application, performing the append operation in the client application, and then performing a set operation to update the value.
![]() Note
Note
Another example of extended functionality is found in Riak (www.basho.com), which supports full text indexing of values so you can use an API to find keys and values using search queries.3
3. http://docs.basho.com/riak/latest/dev/using/search/
Keys and values are the basic building blocks of key-value databases, but they are only the beginning.
Namespace
A namespace is a collection of key-value pairs. You can think of a namespace as a set, a collection, a list of key-value pairs without duplicates, or a bucket for holding key-value pairs. A namespace could be an entire key-value database. The essential characteristic of a namespace is it is a collection of key-value pairs that has no duplicate keys. It is permissible to have duplicate values in a namespace.
Namespaces are helpful when multiple applications use a key-value database. Developers of different applications should not have to coordinate their key-naming strategy unless they are sharing data (see Figure 4.3).
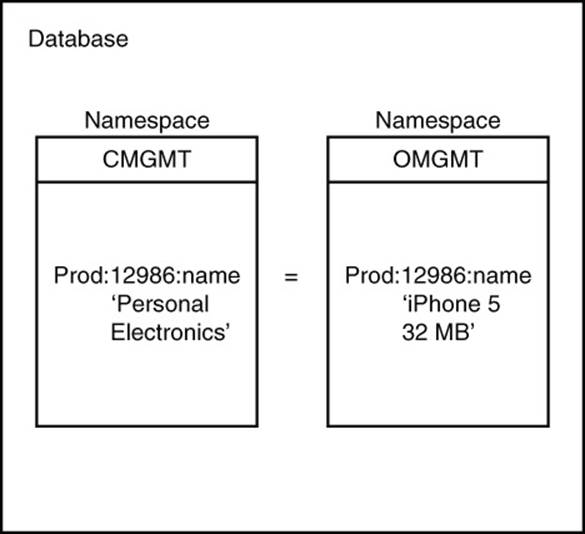
Figure 4.3 Namespaces enable duplicate keys to exist without causing conflicts by maintaining separate collections of keys.
For example, one development team might work on a customer management system while another is working on an order-tracking system. Both will need to use customers’ names and addresses. In this case, it makes sense to have a single set of customers used by both teams. It would avoid duplicate work to maintain two customer lists and eliminate the possibility of inconsistent data between the two databases.
When the two teams need to model data specific to their application, there is a potential for key-naming conflicts. The team working on the customer management system might want to track the top type of products each customer purchases, for example, personal electronics, clothing, sports, and so on. The team decides to use the prefix Prod for their product type keys. The team working on order tracking also needs to track products but at a more detailed level. Instead of tracking broad categories, like personal electronics, they track specific products, such as an iPhone 5 32MB. They also decide to use the prefix Prod.
You can probably see the problem this raises. Imagine both applications use the same customer data and, therefore, customer IDs. The customer management team might create a key such as 'Prod:12986:name' and assign the value ‘personal electronic.’ Meanwhile, the order management team wants to track the last product ordered by a customer and creates the key 'Prod:12986:name' and assigns it the value ‘iPhone 5 32MB.’
In this situation, the value of the key is set to the last value written by one of the applications. When the other application reads the data, it will find not only an incorrect value, but also one that is out of the range of expected values.
Namespaces solve this problem by implicitly defining an additional prefix for keys. The customer management team could create a namespace called custMgmt, and the order management team could create a namespace called ordMgmt. They would then store all keys and values in their respective namespaces. The key that caused problems before effectively becomes two unique keys: custMgmt: Prod:12986:name and ordMgmt: Prod:12986:name.
Partition
Just as it is helpful to organize data into subunits—that is, namespaces—it is also helpful to organize servers in a cluster into subunits. A partitioned cluster is a group of servers in which servers or instances of key-value database software running on servers are assigned to manage subsets of a database. Let’s consider a simple example of a two-server cluster. Each server is running key-value database software. Ideally, each server should handle 50% of the workload. There are several ways to handle this.
You could simply decide that all keys starting with the letters A through L are handled by Server 1 and all keys starting with M through Z are managed by Server 2. (Assume for the moment that all keys start with a letter.) In this case, you are partitioning data based on the first letter of the key (see Figure 4.4).
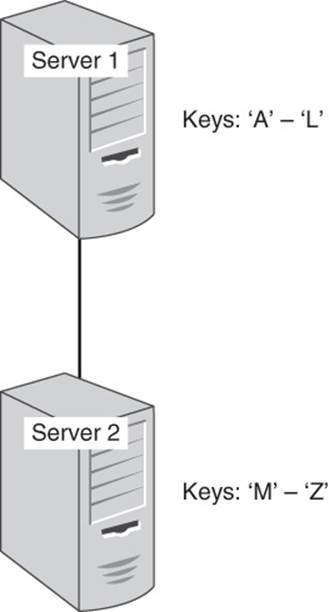
Figure 4.4 Servers in a cluster are assigned subsets of data to manage.
Like so many simple strategies that sound reasonable at first, this one is vulnerable to significant problems. For example, most of the keys may start with the letter C, as in cust (customer), cmpg (campaign), comp (component), and so on, whereas very few keys start with letters from the latter half of the alphabet, for example, warh (warehouse). This imbalance in keys leads to an imbalance in the amount of work done by each server in the cluster.
Partition schemes should be chosen to distribute the workload as evenly as possible across the cluster. The “Partition Key” section describes a widely used method to help ensure a fairly even distribution of data and, therefore, workloads (see Figure 4.5).
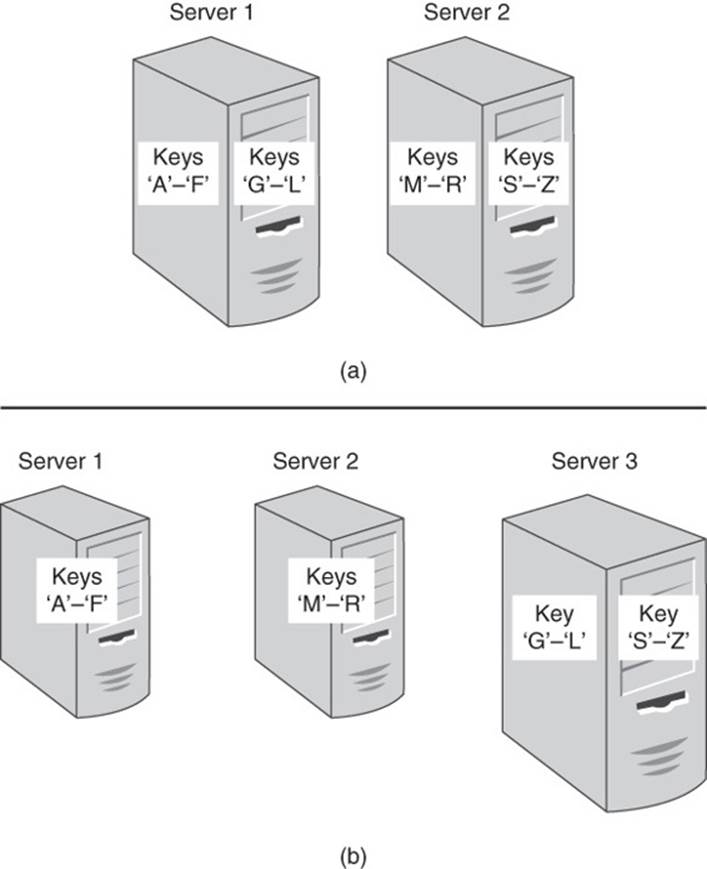
Figure 4.5 When multiple instances of key-value database software run on servers in a cluster, servers can be added to the cluster and instances reallocated to balance the workload.
![]() Note
Note
Note that a server may support more than one partition. This can happen if servers are running virtual machines and each virtual machine supports a single partition. Alternatively, key-value databases may run multiple instances of partition software on each server. This allows for a number of partitions larger than the number of servers.
Partition Key
A partition key is a key used to determine which partition should hold a data value. In key-value databases, all keys are used to determine where the associated value should be stored. Later, you see that other NoSQL database types, such as document databases, use one of several attributes in a document as a partition key.
In the previous example, the first letter of a key name is used to determine which partition manages it. Other simple strategies are partitioning by numeric value and string value. Any key in a key-value database is used as a partition key; good partition keys are ones that distribute workloads evenly.
In some cases, you may not have a key that by itself naturally distributes workloads evenly. In these cases, it helps to use a hash function. Hash functions map an input string to a fixed-sized string that is usually unique to the input string.
You can find out more about hash functions in the “Key-Value Architecture Terms” section later in this chapter. For now, it is sufficient to think of a hash function as a way to map from an imbalanced set of keys to a more equally distributed set of keys.
Key, value, namespace, partition, and partition key are all constructs that help you organize data within a key-value database. The key-value database software that you use makes use of particular architectures, or arrangements of hardware and software components. It is now time to describe important terms related to key-value database architecture.
Schemaless
Schemaless is a term that describes the logical model of a database. In the case of key-value databases, you are not required to define all the keys and types of values you will use prior to adding them to the database. If you would like to store a customer name as a full name using a key such as
cust:8983:fullName = 'Jane Anderson'
you can do so without first specifying a description of the key or indicating the data type of the values is a string. Schemaless data models allow you to make changes as needed without changing a schema that catalogs all keys and value types (see Figure 4.6).
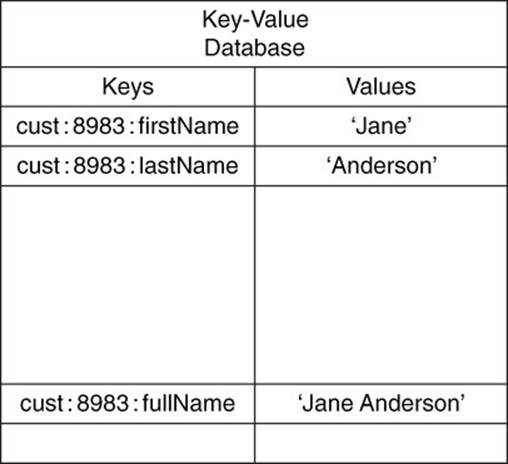
Figure 4.6 Schemaless data models allow for multiple types of representations of the same data to exist simultaneously.
For example, you might decide that storing a customer’s full name in a single value is a bad idea. You conclude that using separate first and last names would be better. You could simply change your code to save keys and values using statements such as the following:
cust:8983:firstName = 'Jane'
cust:8983:lastName = 'Anderson'
The full name and first/last name keys and values can coexist without a problem.
![]() Tip
Tip
You would, of course, need to update your code to handle both ways of representing customer names or convert all instances of one form into the other.
Part III, “Document Databases,” returns to the concept of schemaless databases and discusses the related concept of a polymorphic database, which is something of a middle ground between fixed schemas found in relational databases and schemaless models used in key-value databases.
Key-Value Architecture Terms
The architecture of a key-value database is a set of characteristics about the servers, networking components, and related software that allows multiple servers to coordinate their work. Three terms frequently appear when discussing key-value architectures:
• Clusters
• Rings
• Replication
Cluster
Clusters are sets to connected computers that coordinate their operations (see Figure 4.7). Clusters may be loosely or tightly coupled. Loosely coupled clusters consist of fairly independent servers that complete many functions on their own with minimal coordination with other servers in the cluster. Tightly coupled clusters tend to have high levels of communication between servers. This is needed to support more coordinated operations, or calculations, on the cluster. Key-value clusters tend to be loosely coupled.
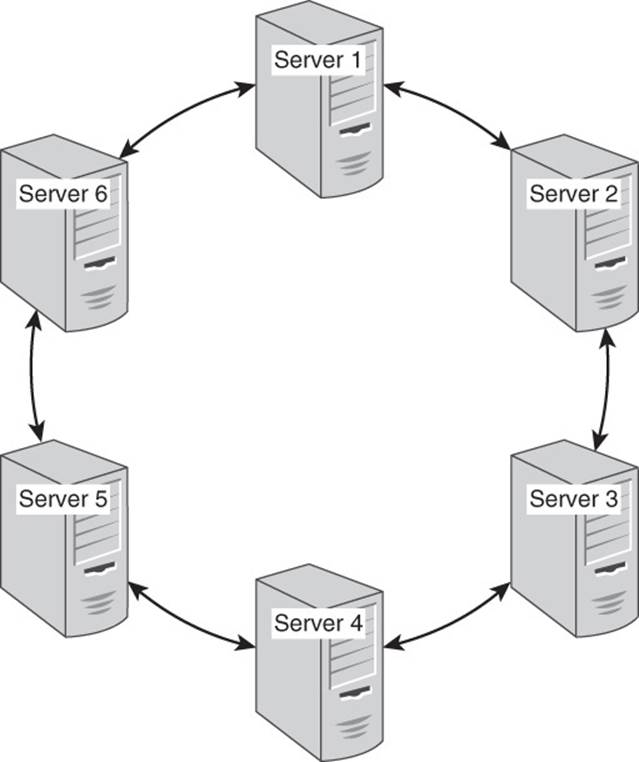
Figure 4.7 A ring architecture of key-value databases links adjacent nodes in the cluster.
Servers, also known as nodes, in a loosely coupled cluster share information about the range of data the server is responsible for and routinely send messages to each other to indicate they are still functioning. The latter message exchange is used to detect failed nodes. When a node fails, the other nodes in the cluster can respond by taking over the work of that node.
Some clusters have a master node. The master node in Redis, for example, is responsible for accepting read and write operations and copying, or replicating, copies of data to slave nodes that respond to read requests. If a master node fails, the remaining nodes in the cluster will elect a new master node. If a slave node fails, the other nodes in the cluster can continue to respond to read requests.
Masterless clusters, such as used by Riak, have nodes that all carry out operations to support read and write operations. If one of those nodes fails, other nodes will take on the read and write responsibilities of the failed node.
Because the failed node was also responsible for writes, the nodes that take over for the failed node must have copies of the failed node’s data. Ensuring there are multiple copies of data on different nodes is the responsibility of the replication subsystem. This is described in the section “Replication,” later in this chapter.
Each node in a masterless cluster is responsible for managing some set of partitions. One way to organize partitions is in a ring structure.
Ring
A ring is a logical structure for organizing partitions. A ring is a circular pattern in which each server or instance of key-value database software running on a server is linked to two adjacent servers or instances. Each server or instance is responsible for managing a range of data based on a partition key.
Consider a simple hashlike function that maps a partition key from a string; for example, 'cust:8983:firstName' to a number between 0 and 95. Now assume that you have an eight-node cluster and the servers are labeled Server 1, Server 2, Server 3, and so on. With eight servers and 96 possible hashlike values, you could map the partitions to servers, as shown in Table 4.1.
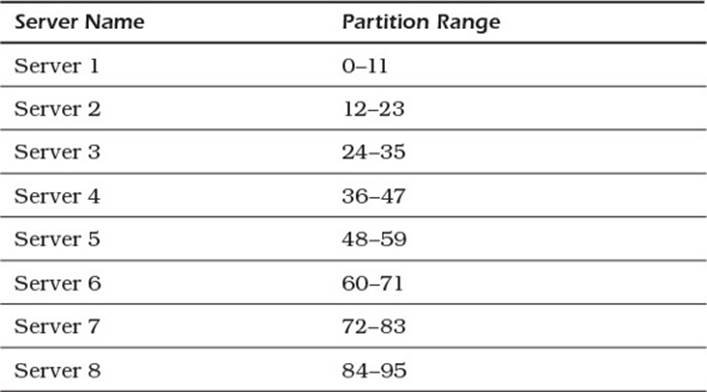
Table 4.1 Server to Partition Mapping
In this model, Server 2 is linked to Server 1 and Server 3; Server 3 is linked to Server 2 and Server 4; and so on. Server 1 is linked to Server 8 and Server 2. Refer to Figure 4.7 to see a graphical depiction of a ring architecture.
A ring architecture helps to simplify some otherwise potentially complex operations. For example, whenever a piece of data is written to a server, it is also written to the two servers linked to the original server. This enables high availability of a key-value database. For example, if Server 4 fails, both Server 3 and Server 5 could respond to read requests for the data on Server 4. Servers 3 and 5 could also accept write operations destined for Server 4. When Server 4 is back online, Servers 3 and 5 can update Server 4 with the writes that occurred while it was down (see Figure 4.8).
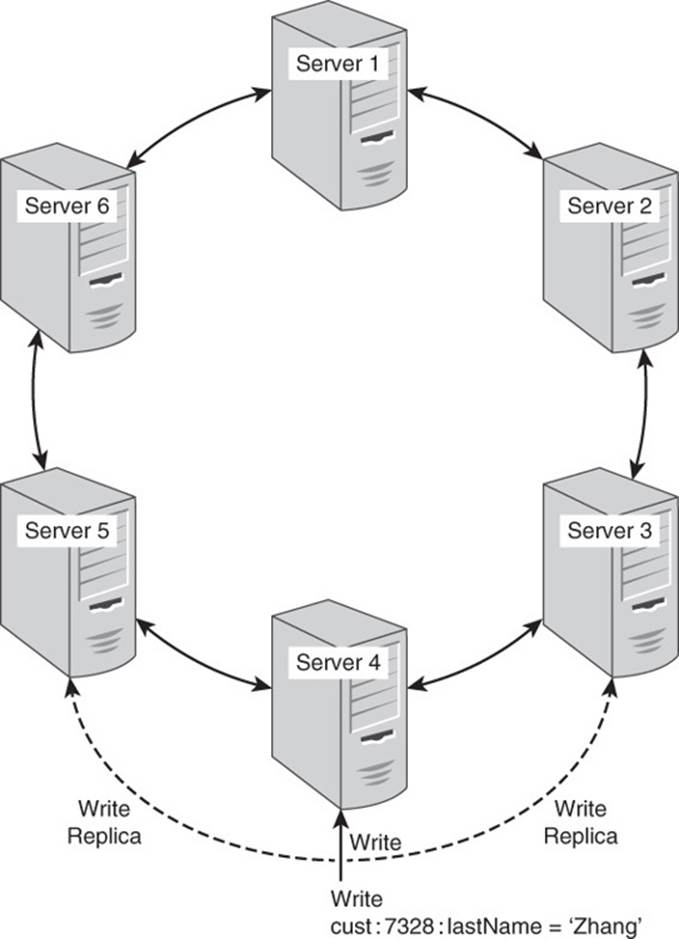
Figure 4.8 One way to replicate data is to write copies of data to adjacent nodes in the cluster ring.
Replication
Replication is the process of saving multiple copies of data in your cluster. This provides for high availability as described previously.
One parameter you will want to consider is the number of replicas to maintain. The more replicas you have, the less likely you will lose data; however, you might have lower performance with a large number of replicas. If your data is easily regenerated and reloaded into your key-value database, you might want to use a small number of replicas. If you have little tolerance for losing data, a higher replica number is recommended.
Some NoSQL databases enable you to specify how many replicas must be written before a write operation is considered complete from the perspective of the application sending the write request. For example, you may configure your database to store three replicas. You may also specify that as soon as two of the replicas are successfully written, a successful write return value can be sent to the application making the write request. The third replica will still be written, but it will be done while the application continues to do other work.
You should take replicas into consideration with reads as well. Because key-value databases do not typically enforce two-phase commits, it is possible that replicas have different versions of data. All the versions will eventually be consistent, but sometimes they may be out of sync for short periods.
To minimize the risk of reading old, out-of-date data, you can specify the number of nodes that must respond with the same answer to a read request before a response is returned to the calling application. If you are keeping three replicas of data, you may want to have at least two responses from replicas before issuing a response to the calling program.
The higher the number required, the more likely you are to send the latest response. This can add to the latency of the read because you might have to wait longer for the third server to respond.
Up to this point, most of the terms described have dealt with logical modeling and the organization of servers and related processes. Now it is time to address algorithms implemented in and processes that run within the key-value database software to implement higher-level functions.
Key-Value Implementation Terms
The terms discussed in this last set of key-value vocabulary deal with topics you generally do not work with directly. These terms cover operations that happen behind the scenes of application programs but are nonetheless crucial to the functioning of a key-value database.
Hash Function
Hash functions are algorithms that map from an input—for example, a string of characters—to an output string. The size of the input can vary, but the size of the output is always the same. For example, a simple string like 'Hello world' maps to
2aae6c35c94fcfb415dbe95f408b9ce91ee846ed
While longer text, such as the following:
“There is a theory which states that if ever anyone discovers exactly what the Universe is for and why it is here, it will instantly disappear and be replaced by something even more bizarre and inexplicable. There is another theory which states that this has already happened.”
DOUGLAS ADAMS
THE RESTAURANT AT THE END OF THE UNIVERSE, 1980
yields an equal-sized output string:
3f4d004fcb7c40b02deb393d34db9bd02b067f56
Clearly, the two output strings are quite different. This would be expected when the inputs are so different. One of the important characteristics of hash algorithms is that even small changes in the input can lead to large changes in the output. For example, if you hash 'Hello World'instead of 'Hello world', the output string is
0a4d55a8d778e5022fab701977c5d840bbc486d0
Hash functions are generally designed to distribute inputs evenly over the set of all possible outputs. The output space can be quite large. For example, the SHA-1 has 2160 possible output values. This is especially useful when hashing keys. No matter how similar your keys are, they are evenly distributed across the range of possible output values. The ranges of output values can be assigned to partitions and you can be reasonably assured that each partition will receive approximately the same amount of data.
For example, assume you have a cluster of 16 nodes and each node is responsible for one partition. You can use the first digit output by the SHA-1 function to determine which partition should receive the data.
![]() Note
Note
As you might recall, the SHA-1 function outputs a hexadecimal, or base-16, number. The hexadecimal digits are 0–9 and a–f for a total of 16 digits.
The key 'cust:8983:firstName' has a hash value of
4b2cf78c7ed41fe19625d5f4e5e3eab20b064c24
and would be assigned to partition 4, while the key 'cust:8983:lastName' has a hash value of
c0017bec2624f736b774efdc61c97f79446fc74f
and would be assigned to node 12 (c is the hexadecimal digit for the base-10 number 12).
Although there are many possible outputs for hash functions, it is possible for two distinct input strings to map to the same output string.
Collision
A collision occurs when two distinct inputs to a hash function produce the same output. When it is difficult to find two inputs that map to the same hash function output, the hash function is known as collision resistant. If a hash table is not collision resistant or if you encounter one of those rare cases in which two inputs map to the same output, you will need a collision resolution strategy.
Basically, a collision resolution strategy is a way to deal with the fact that you have two inputs that map to the same output. If the hash table only has room for one value, then one of the hashed values will be lost.
A simple method to deal with this is to implement a list in each cell of a hash table. Most entries will include a single value, but if there are collisions, the hash table cell will maintain a list of keys and values, as shown in Figure 4.9. This is a logical representation of a generic solution to the collision problem; actual implementations may vary.
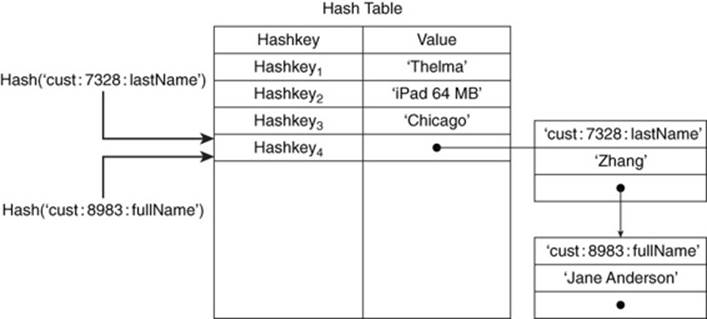
Figure 4.9 Collisions with hash functions are managed using collision resolution strategies, such as maintaining linked lists of values.
Compression
Key-value databases are memory intensive. Large numbers of large values can quickly consume substantial amounts of memory. Operating systems can address this problem with virtual memory management, but that entails writing data to disk or flash storage.
Reading from and writing to disk is significantly slower than reading from random access memory, so avoid it when possible. One option is to add more memory to your servers. There are both technical and cost limitations on this option. In the case of disk-based, key-value stores, such as the LevelDB library (code.google.com/p/leveldb/), there is still a motivation to optimize storage because the time required to read and write data is a function of the size of the data.
One way to optimize memory and persistent storage is to use compression techniques. A compression algorithm for key-value stores should perform compression and decompression operations as fast as possible. This often entails a trade-off between the speed of compression/decompression and the size of the compressed data.
Faster compression algorithms can lead to larger compressed data than other, slower algorithms (see Figure 4.10). For example, the Snappy compression algorithm compresses 250MB per second and decompresses 500MB per second on a Core i7, 64-bit mode processor but produces compressed data that is 20% to 100% larger than the same data compressed by other algorithms.4
4. https://code.google.com/p/snappy/
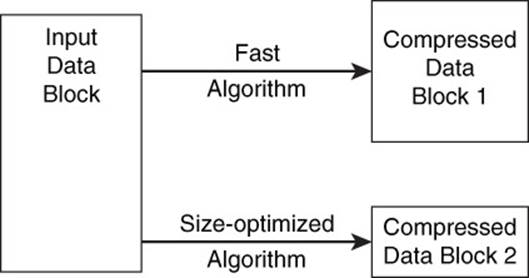
Figure 4.10 Compression algorithms may be designed to optimize for speed or data size.
Summary
Key-value databases come with their own terminology used to describe data models, architecture, and implementation components. Keys, values, partitions, and partition keys are important concepts related to data models. You will see some of the terms again when you learn about other types of NoSQL databases.
It is also important to understand the architecture employed with key-value databases. Clusters, rings, and replication are key topics with regard to architecture.
Database application developers do not need to work with implementation issues on a regular basis, but it helps to understand them, particularly when tuning parameters. Key concepts related to implementation include hash functions, collision, and compression.
Now that you understand key-value database terminology and were introduced to key-value databases in Chapter 3, it is time to examine more advanced applications of key-value databases and review established design patterns that can help you develop robust, scalable, key-value database applications.
Review Questions
1. What are data models? How do they differ from data structures?
2. What is a partition?
3. Define two types of clusters. Which type is typically used with key-value data stores?
4. What are the advantages of having a large number of replicas? What are the disadvantages?
5. Why would you want to receive a response from more than one replica when reading a value from a key-value data store?
6. Under what circumstances would you want to have a large number of replicas?
7. Why are hash functions used with key-value databases?
8. What is a collision?
9. Describe one way to handle a collision so that no data is lost.
10. Discuss the relation between speed of compression and the size of compressed data.
References
Adams, Douglas. The Restaurant at the End of the Universe. Reprint Edition, Del Rey. 1995.
Basho Technologies, Inc. Riak Documentation: http://docs.basho.com/riak/latest/
Google, Snappy Documentation: https://code.google.com/p/snappy/
Key-Value Store 2.0 Documentation: https://foundationdb.com/key-value-store/documentation/index.html
Redis Documentation: http://redis.io/documentation
Redman, Eric. “A Little Riak Book.” http://littleriakbook.com/
Seeger, Marc. “Key-Value Stores: A Practical Overview”: http://blog.marc-seeger.de/assets/papers/Ultra_Large_Sites_SS09-Seeger_Key_Value_Stores.pdf
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.