NoSQL for Mere Mortals (2015)
Part II: Key-Value Databases
Chapter 5. Designing for Key-Value Databases
“Design is not just what it looks like and feels like. Design is how it works.”
—STEVE JOBS
FORMER CEO, APPLE COMPUTER, INC.
Topics Covered In This Chapter
Key Design and Partitioning
Designing Structured Values
Limitations of Key-Value Databases
Design Patterns for Key-Value Databases
Case Study: Key-Value Databases for Mobile Application Configuration
Through the first four chapters of this book, you have learned the basics of NoSQL databases and details of key-value databases in particular. It is now time to put those details to work. When you design an application that uses a key-value database, you should consider several factors, including
• How to structure keys
• What types of information you want to capture in values
• How to compensate for limitations of key-value databases
• How to introduce abstractions that help create higher-level organizational structures than simple key-value pairs
Well-designed keys can make your application code easier to read and streamline the maintenance of your application and your key-value database. Capturing the right data in your key-value pairs is important both for meeting functional requirements and for ensuring adequate performance of your application. As useful as key-value databases are, there are some significant limitations, such as poor support for retrieving a range of values. There are ways to work around these limitations, and this chapter describes design patterns you might want to use in your applications and key-value database designs.
Design Pattern Definition
The Wikipedia definition of a design pattern is “A general reusable solution to a commonly occurring problem within a given context in software design. A design pattern is not a finished design that can be transformed directly into source or machine code. It is a description or template for how to solve a problem that can be used in many different situations.”1
1. http://en.wikipedia.org/wiki/Software_design_pattern
Key Design and Partitioning
How you design your keys can impact the ease of working with your key-value database. At one end of the design spectrum, you could come up with random keys for every value you want to store. Obviously, a key like 'laklsjfdjjd' is virtually useless unless you have an uncanny memory for strings or have a data structure that can map nonsense keys to something meaningful. Keys should have some logical structure to make code readable and extensible, but they should also be designed with storage efficiency in mind.
Keys Should Follow a Naming Convention
The naming convention you choose is less important than choosing one. A well-designed naming convention enables developers to easily devise keys for new entities, instances, and attributes.
Here are some general guidelines. These are not hard-and-fast rules; they are tips that can work well for you in various situations.
• Use meaningful and unambiguous naming components, such as 'cust' for customer or 'inv' for inventory.
• Use range-based components when you would like to retrieve ranges of values. Ranges include dates or integer counters.
• Use a common delimiter when appending components to make a key. The ‘:’ is a commonly used delimiter, but any character that will not otherwise appear in the key will work.
• Keep keys as short as possible without sacrificing the other characteristics mentioned in this list.
![]() Tip
Tip
Anticipating all possible entities’ types can be difficult, so coming up with unambiguous name components isn’t always possible. Try to use at least three or four letters to distinguish an entity type or attribute. 'Cst' or 'cust' are better than 'c' for a customer abbreviation.
Well-Designed Keys Save Code
A well-designed key pattern helps minimize the amount of code a developer needs to write to create functions that access and set values. For example, consider a key pattern that consists of an entity or object type (for example, 'customer'), a unique identifier for that entity or object type (for example, '198277'), an attribute name (for example, 'fname'), and common delimiter (for example, ':'). A single function with two parameters can get any value:
define getCustAttr(p_id, p_attrName)
v_key = 'cust' + ':' + p_id + ':' + p_attrName;
return(AppNameSpace[v_key]);
In this pseudocode example, the function getCustAttr has parameters for the customer identifier and the name of the attribute that should have its value returned. The local variable, v_key, is a string created by concatenating the parts of the key. Because the key follows a standard naming convention, every attribute about a customer can be retrieved using this function. The last line of the pseudocode function returns the value associated with key specified by the string in variable v_key. AppNameSpace is the name of the namespace holding keys and values for this application.
![]() Note
Note
In practice, you should have a naming convention for namespaces, too. For example, a customer management namespace might be 'CstMgtNS'.
The associated set function is similar but uses three parameters. The third parameter is used to pass in the value to be saved:
define setCustAttr(p_id, p_attrName, p_value)
v_key = 'cust' + ':' + p_id + ':' + p_attrName
AppNameSpace[v_key] = p_value
![]() Note
Note
In production applications, you should include appropriate error checking and handling. Set functions should check the status of write operations to ensure the minimum number of replicas has been written. If the database could not save the minimum number of replicas, you might want to attempt the write operation again some number of times before returning an error.
Using generalized set and get functions helps improve the readability of code and reduces the repeated use of low-level operations, such as concatenating strings and looking up values.
Dealing with Ranges of Values
Consider using values that indicate ranges when you want to retrieve groups of values. For example, you might want to include a six-digit date in a key if you want to retrieve all customers who made a purchase on a particular date. In this case, 'cust061514' could be used as a prefix instead of 'cust' to indicate customers who bought products on June 15, 2014. The customer ID would be stored as a value associated with each key.
For example, the following are keys associated with the first 10 customers who purchased products on June 15, 2014:
• cust061514:1:custId
• cust061514:2:custId
• cust061514:3:custId
• cust061514:4:custId
• ...
• cust061514:10:custId
This type of key is useful for querying ranges of keys because you can easily write a function to retrieve a range of values. For example, the following getCustPurchaseByDate function retrieves a list of customerIDs who made purchases on a particular date:
define getCustPurchByDate(p_date)
v_custList = makeEmptyList();
v_rangeCnt = 1;
v_key = 'cust:' + p_date + ':' + v_rangeCnt +
':custId';
while exists(v_key)
v_custList.append(myAppNS[v_key]);
v_rangeCnt = v_rangeCnt + 1;
v_key = 'cust:' + p_date + ':' + v_rangeCnt +
':custId';
return(v_custList);
The function takes one parameter, the date of purchases, although this code could easily generalize to accept a range of dates. The function starts by initializing two local variables: v_custList is set to an empty list, which will hold customer IDs, and v_rangeCnt, which will hold the counters associated with the range of customers that made purchases on the date specified in the parameter p_date.
Because there is no way to know the number of customers that made purchases, the code uses a while loop and checks a terminating condition. In this case, the while loop terminates when it checks for a key and finds it does not exist. If there were only 10 purchases on June 15, 2014, then when the loop checks the key 'cust:061514:11:custId', it does not find a corresponding key-value pair in the database and the while loop terminates.
In the while loop, the key stored in the local variable v_key is used to look up the value in the myAppNS namespace. The key returns the customer ID, and the code appends the value to the local variable v_custList. When the while loop terminates, the list of customer IDs inv_custList is returned.
You might have realized that although using this type of function will standardize your code, it is no more efficient than retrieving each key-value pair individually. In some data stores, values can be ordered on disk in a specific sort order, making it more efficient to read a range of values because they are stored in contiguous blocks. If your key-value database offers ordered key values or allows for secondary indexes, you might find those are more efficient options for retrieving ranges of values than using a function like the one above.
Keys Must Take into Account Implementation Limitations
Different key-value databases have different limitations. Consider those limitations when choosing your key-value database.
Some key-value databases restrict the size of keys. For example, FoundationDB limits the size of keys to 10,000 bytes.2
2. https://foundationdb.com/key-value-store/documentation/known-limitations.html
Others restrict the data types that can be used as keys. Riak treats keys as binary values or strings.3 The Redis data store takes a liberal approach to keys and allows for more complex structures than string. Valid data types for Redis keys include4
3. http://docs.basho.com/riak/1.3.0/references/appendices/concepts/Keys-and-Objects/
4. http://redis.io/topics/data-types-intro
• Binary safe strings
• Lists
• Sets
• Sorted sets
• Hashes
• Bit arrays
• HyperLogLogs (a probabilistic data structure for estimating number of entities in a set)
The variety of data types supported by Redis allows you more flexibility when creating keys. Instead of concatenating entity types, identifiers, and attributes as a string such as 'cust:19873:fname', you could use a list, such as ('cust', '19873', 'fname'). Redis keys can be up to 512MB in length.5 It sounds unlikely that you would create a 512MB string by concatenating components, but large binary objects, such as images, are valid key types and can reach substantial sizes.
5. http://redis.io/topics/data-types
![]() Tip
Tip
Before using large keys in production, be sure to test the performance of key-value databases with large keys so you understand the level of performance you can expect.
How Keys Are Used in Partitioning
Partitioning is the process of grouping sets of key-value pairs and assigning those groups to different nodes in a cluster. Hashing is a common method of partitioning that evenly distributes keys and values across all nodes. Another method that is sometimes used is called range partitioning.
Range partitioning works by grouping contiguous values and sending them to the same node in a cluster (see Figure 5.1). This assumes a sort order is defined over the key. For example, you could partition by customer number, date, or part identifier. Range partitioning requires some kind of table to map from keys to partitions, as shown in Table 5.1.
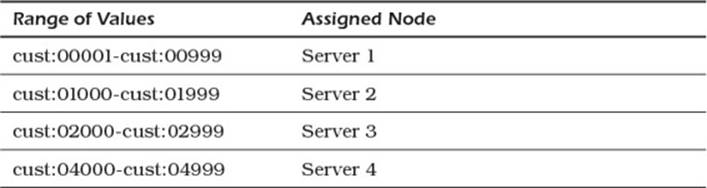
Table 5.1 Sample Range Partition Table
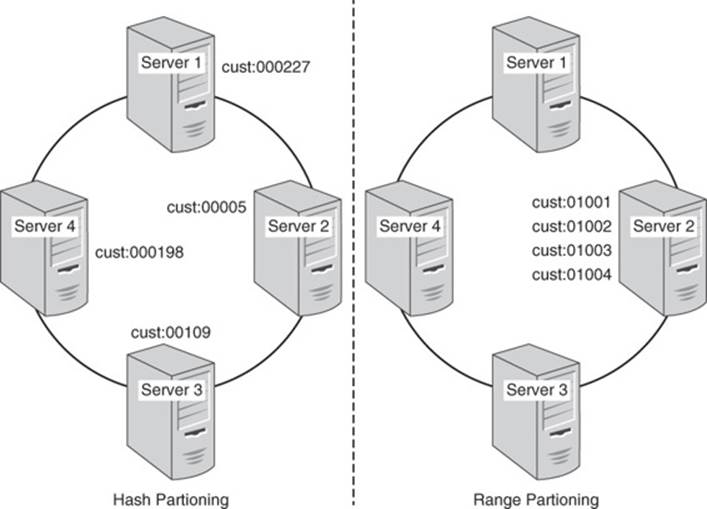
Figure 5.1 Different hashing schemes will lead to different key-to-node assignments.
If you decide to use range partitioning, carefully consider how your data volumes may grow. If you need to restructure your partitioning scheme, some keys may be reassigned to different nodes and data will have to migrate between nodes.
Designing Structured Values
The term values can cover a wide range of data objects, from simple counts to hierarchical data structures with embedded complex structures. All can be assigned as values in a key-value database. But ask yourself, do you really want structured data types in your database? As usual in database design, the answer is “it depends.”
Consider two possible cases. In the first, you have two attributes that are frequently used together. In the second, you have a set of attributes that are logically related, and some but not all of the attributes are frequently used together. As you shall see, each is best managed with a different approach.
Structured Data Types Help Reduce Latency
You should consider the workload on your server as well as on developers when designing applications that use key-value data stores. Consider an application development project in which the customer address is needed about 80% of the time when the customer name is needed. This can occur when you frequently need to display the customer’s name and mailing address, although occasionally you only need the name, for example, as part of a form header.
It makes sense to have a function that retrieves both the name and the address in one function call. Here is a sample get function for name and address:
define getCustNameAddr(p_id)
v_fname = getCustAttr(p_id,'fname');
v_lname = getCustAttr(p_id,'lname');
v_addr = getCustAttr(p_id,'addr');
v_city = getCustAttr(p_id,'city');
v_state = getCustAttr(p_id,'state');
v_zip = getCustAttr(p_id,'zip');
v_fullName = v_fname + ' ' + v_lname;
v_fullAddr = v_city + ' ' + v_state + ' ' + v_zip;
return(makeList(v_fullName, v_fullAddr);
This function retrieves six values, creates two local variable strings, creates a list to hold both the name and address, and returns that list. If customer name and address are frequently retrieved, it makes sense to use a function such as getCustNameAddr rather than duplicate the multiplegetCustAttr calls each time the customer name and address are needed.
Assuming the developer needs to call getCustNameAddr frequently, it would help to optimize this code as much as possible. The getCustAttr function is called multiple times so it is a good candidate for optimizing. The code for that function is simple and does not lend itself to significant optimization.
The other operations in the getCustNameAddr, concatenating strings and making a list, are primitive operations that take little time. The best option for optimizing getCustNameAddr is to reduce the number of times the developer has to call getCustAddr.
Each time getCustAddr is called, it builds a key by concatenating strings. This primitive operation does not take much time. Fetching a value from the key-value database can take a long time, at least compared with primitive operations. The reason is that retrieving a value can require reading from a disk. This means that the read operation must wait for the read/write heads to get into position.
The latency, or time you have to wait for the disk read to complete, is significantly longer than the time needed to perform other operations in the function (see Figure 5.2).
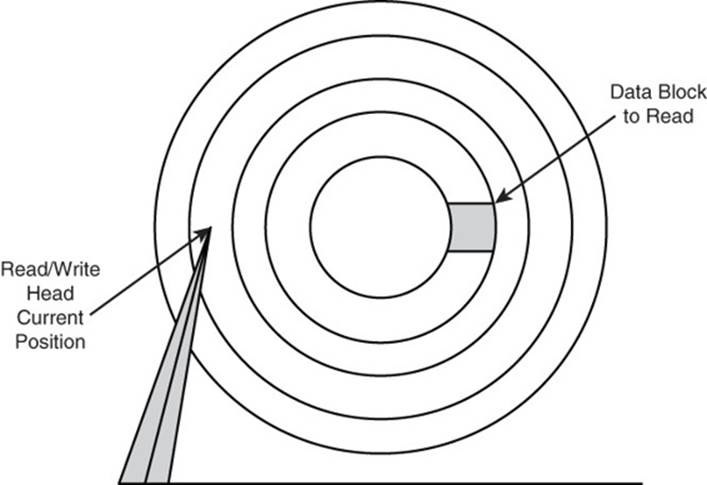
Figure 5.2 Reading a value from disk requires the read/write heads to move to the proper track and the platter to rotate to the proper block. This can lead to long latencies.
One way to improve the speed of fetching values from the key-value database is to store frequently used values in memory. This works well in many cases but is limited by the amount of room in memory allocated to caching keys and values.
Another approach is to store commonly used attribute values together. In the case of a customer management database, you could store a list with both the customer’s name and address together, for example:
cstMgtNS[cust: 198277:nameAddr] = '{ 'Jane Anderson' ,
'39 NE River St. Portland, OR 97222'}
This is a more complex value structure than using several different keys but has significant advantages in some cases. By storing a customer name and address together, you might reduce the number of disk seeks that must be performed to read all the needed data (see Figure 5.3).
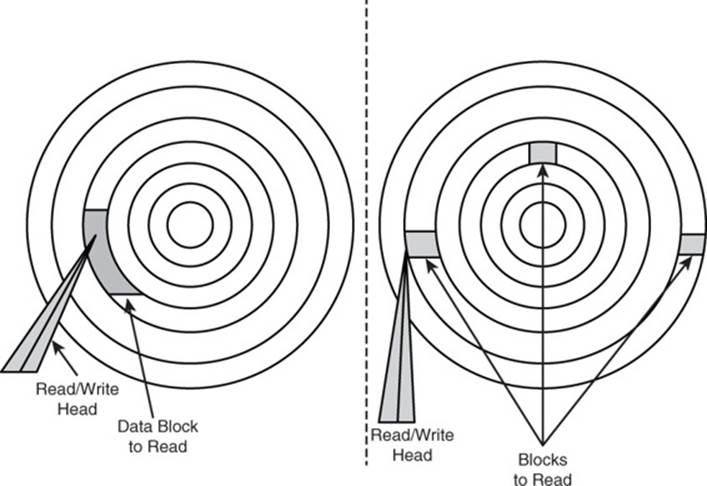
Figure 5.3 Reading a single block of data is faster than reading multiple blocks referenced by multiple keys.
Key-value databases usually store the entire list together in a data block so there is no need to hash multiple keys and retrieve multiple data blocks. An exception to this rule occurs if the data value is larger than the disk data block size. This can occur if you store a large image or other sizeable object as a value.
If there are many times you need a customer name but not the address, you might want to store the name separately. This would duplicate the customer name in your key-value database, but that should not be considered a problem.
![]() Note
Note
Generally, you should avoid duplicating data in relational database design, although it is a common practice in NoSQL databases.
Duplicating data is also a common way to improve the performance of relational database queries. Known as denormalization, duplicating data can reduce the number of joins required to perform a query and substantially improve application performance.
The same pattern holds in NoSQL databases. You can use the name-only key to look up just the name when that is the only attribute needed, and you can use the name and address key when you need both.
There are advantages to storing structures as values, but there are also limits to those advantages. As you will see in the next section, storing too much data in a value can have adverse effects on application performance.
Large Values Can Lead to Inefficient Read and Write Operations
Ancient Greek philosophers advocated sophrosyne, a state of mind that led to self-control and moderation. It is a practice that will serve you well when designing data structures for key-value databases.
Using structured data types, such as lists and sets, can improve the overall efficiency of some applications by minimizing the time required to retrieve data. It is important to also consider how increasing the size of a value can adversely impact read and write operations. Consider a data structure that maintains customer order information in a single value, such as the following:
{
'custFname': 'Liona',
'custLname': 'Williams',
'custAddr' : '987 Highland Rd',
'custCity' : 'Springfield',
'custState': 'NJ',
'custZip' : 21111,
'ordItems' [
{
'itemID' : '85838A',
'itemQty' : 2 ,
'descr' : 'Intel Core i7-4790K Processor
(8M Cache,
4.40 GHz)',
'price:' : $325.00
} ,
{
'itemID' : '38371R',
'itemQty' : 1 ,
'descr' : 'Intel BOXDP67BGB3 Socket 1155, Intel
P67',
CrossFireX & SLI SATA3&USB3.0, A&GbE, ATX
Motherboard',
'price' : $140.00
} ,
{
'itemID' : '10484K',
'itemQty' : 1,
'descr' : 'EVGA GeForce GT 740 Superclocked Single
Slot 4GB
DDR3 Graphics Card'
'price': '$201.00'
} ,
{
'itemID' : '67594M',
'itemQty' : 1,
'descr': 'Rosewill Black Gaming ATX Mid Tower
Computer Case',
'price' : $47.98
} ,
{
'itemID' : '46328A',
'itemQty' : 2,
'descr': 'WD Blue 1 TB Desktop Hard Drive: 3.5
Inch, 7200 RPM,
SATA 6 Gb/s, 64 MB Cache - WD10EZEX',
'price' : $63.50
}
]
}
This data structure includes customer information as well as order information. The customer information is stored as a set of string values and corresponding attribute names. The order items are stored in an array in which each element is a list structure with item identifier, quantity, product description, and price. This entire list can be stored under an order key, such as 'ordID:781379'.
The advantage of using a structure such as this is that much of the information about orders is available with a single key lookup. Let’s consider how this data structure might be built.
When the customer adds her first item to her cart, the list is created and the customer name and address are copied from the customer database. An order array is created and a list with the item identifier, quantity, description, and price is added to the array. The key value is hashed and the entire data structure is written to disk. The customer then adds another item to the cart, and a new entry is added to the array of ordered items. Because the value is treated as an atomic unit, the entire list (for example, customer information and ordered items) is written to the disk again. This process continues for each of the additional items.
Assume the key-value database allocates enough storage for an average order size when the value is first created. Adding the fifth order item causes the size of the data structure to exceed the allocated space. When an additional item is added to the ordItems array, the new item will be written to a new block.
As values grow in size, the time required to read and write the data can increase. Data is generally read in blocks. If the size of a value exceeds the size of a block, then multiple blocks must be read. During write operations, an entire value has to be written, even if only a small part of the value has changed.
You might think that because a read operation must read an entire block, as long as the size of the value is less than the size of a data block on disk, there is no additional penalty. It is true the time to position the read/write heads and read the data block is the same. However, there is an indirect penalty. When values are smaller than the disk data block size, multiple values can be stored in a single block. When a block is read, all the values in the block can be added to the in-memory cache. This increases the likelihood that a future read will find the value it needs in the cache. This saves the time required to perform a disk read.
Of course, if an entire large-sized value is in the cache, then any of the embedded attributes are available for low-latency reads from the cache. This could help performance if there are multiple reads to multiple parts of the value data structure. If, however, you load a large value into the cache and only reference a small percentage of the data, you are essentially wasting valuable memory (see Figure 5.4).

Figure 5.4 Data is read in blocks. Blocks may store a large number of small-sized values or few large-sized values. The former can lead to better performance if frequently used attributes are available in the cache.
If you find yourself needing to frequently design large value structures, you might want to consider using a document database rather than a key-value database. Document databases are discussed in depth in Chapters 6 through 8.
Limitations of Key-Value Databases
Key-value databases are the simplest of the NoSQL databases. This makes them easy to learn and use, but it also brings with them important limitations. You have just read about the disadvantages of using large data values. There are some others to keep in mind as well. In particular, it is important to remember the following:
• The only way to look up values is by key.
• Some key-value databases do not support range queries.
• There is no standard query language comparable to SQL for relational databases.
These are limitations with key-value databases in general. As you will no doubt learn as you work with different key-value database implementations, vendors and open source project developers take it upon themselves to devise ways to mitigate the disadvantages of these limitations.
Look Up Values by Key Only
Imagine what it would be like if you had to look up every piece of information about someone using only an identifier, like a Social Security number or a student ID number. You might have no trouble remembering the identifier for a handful of friends and family, but after that, tracking down information will start to get difficult.
The same thing can occur with key-value databases. At times, you will want to look up information about an object without already knowing the key value. In the most basic versions of key-value databases, this is not possible. Fortunately, key-value database developers have added extended features to address this limitation.
One approach is to use text search capabilities. Riak, for example, provides a search mechanism and API that indexes data values as they are added to the database. The API supports common search features, such as wildcard searches, proximity searches, range searches, and Boolean operators. Search functions return a set of keys that have associated values that satisfy the search criteria. If you wanted to list all orders that included the purchase of a computer case and motherboard but not a CPU, you might use a statement such as the following:
field: { 'motherboard' AND 'computer case') AND NOT 'CPU'
This type of search is useful, for example, when you want to find all customers from Illinois who placed orders in the past two weeks.
![]() Note
Note
More on Riak search is available at http://docs.basho.com/riak/latest/dev/using/search/.
Another way to get around key-only lookup is to use secondary indexes. If your key-value database supports secondary indexes directly, you will be able to specify an attribute in a value to index. For example, you could create an index on state or city in an address value to enable lookup by state or city name.
Key-Value Databases Do Not Support Range Queries
Range queries, such as selecting records with dates between a start and end date or names in some range of the alphabet, are fairly common in database applications. The basic key-value database does not support these types of queries unless you use a specialized naming convention and lookup table described earlier in the section, “Dealing with Ranges of Values.” A specialized type of key-value database, known as an ordered key-value database, keeps a sorted structure that allows for range queries.
If you use a key-value database that supports secondary indexes, you may have the ability to perform range queries on the indexed values. Some text search engines also support range searches over text.
No Standard Query Language Comparable to SQL for Relational Databases
Key-value databases are designed for simple lookup operations. It should be no surprise that there is not a standard query language for key-value databases.
You will find, however, that some key-value databases understand commonly used structures, such as XML and JavaScript Object Notation (JSON). Many programming languages have libraries that support constructing and parsing XML and JSON. Search applications, such as Solr (http://lucene.apache.org/solr/) and Lucene (http://lucene.apache.org/), have mechanisms for parsing XML and JSON as well. This combination of structured formats and programming libraries is not equivalent to a standard query language, but they do start to provide some of the capabilities you would expect in such a query language.
There are limitations to the basic key-value data model, but today there are multiple implementations that offer enhanced features that enable developers to more easily implement frequently needed application features.
Design Patterns for Key-Value Databases
Design patterns, or general software solutions, were popularized by Erich Gamma, Richard Helm, Ralph Jackson, and John Vlissides in their book Design Patterns: Elements of Reusable Object-Oriented Software. This book is popularly known as the Gang of Four, or the GoF, book.
The idea that you can reuse solutions in different applications is well understood and known to all but the most novice programmers. The value of the Gang of Four book is that it cataloged and described a number of useful software patterns that could be applied in a variety of languages. Design patterns appear in database applications as well.
It is now time to consider several design patterns that may prove useful when using key-value databases to develop your applications. These include
• Time to Live (TTL) keys
• Emulating tables
• Aggregates
• Atomic aggregates
• Enumerable keys
• Indexes
Design patterns can be useful as described or can require some modification to fit your needs. Think of design patterns as guides to solving common problems, not dogmatic solutions handed down by a cadre of design elders that must be followed precisely.
Just as importantly, pay attention to the solutions you repeatedly use when developing applications. You might find some of your most frequently used design patterns are ones you discover yourself.
Time to Live (TTL) Keys
Time to Live is a term frequently used in computer science to describe a transient object. For example, a packet of data sent from one computer to another can have a Time to Live parameter that indicates the number of times it should be forwarded to another router or server while en route to its destination. If the packet is routed through more devices than specified by the TTL parameter, it is dropped and the packet is undelivered.
TTL is sometimes useful with keys in a key-value database, especially when caching data in limited memory servers or when keys are used to hold a resource for some specified period of time. A large e-commerce company selling tickets to sporting and music events might have thousands of users active at any time. When a customer indicates he wants to purchase tickets for several seats, the ticketing application may add key-value pairs to the database to hold those seats while the customer’s payment is processed. The e-commerce company does not want one customer buying seats that another customer has already added to his or her cart. At the same time, the company does not want seats held for long periods of time, especially if customers abandon their carts. A TTL parameter associated with a key can help here (see Figure 5.5).
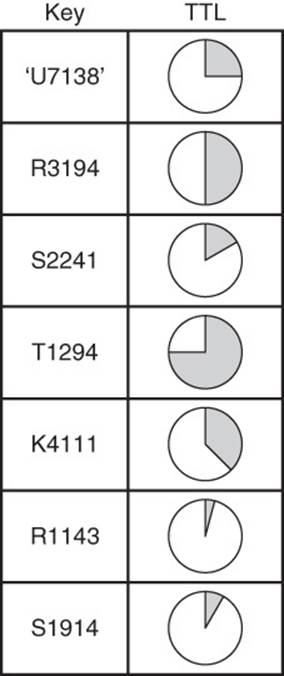
Figure 5.5 Time to Live keys are useful for allowing users to reserve a product or resource for a limited time while other operations, such as making a payment, complete.
The application may create a key that references the seat being saved and the value could be the identifier of the customer purchasing the seat. Setting a five-minute Time to Live parameter would provide enough time for someone to enter his or her payment information without unduly delaying access to the ticket if the payment authorization fails or the customer abandons the cart. This also saves the application developer from needing to develop a custom method that might include keeping a time stamp with a key and checking multiple keys at regular intervals to determine whether any have expired.
![]() Tip
Tip
Time to Live properties are database-specific, so check the documentation of your key-value database to see whether they are supported and how to specify an expiration.
Emulating Tables
Although most key-value databases do not explicitly support a data structure like the relational table, it can be a useful construct.
![]() Note
Note
The Oracle NoSQL database is unlike most key-value databases and provides an API for manipulating data using a table metaphor.6
6. See Chapter 4 of “Getting Started with Oracle NoSQL Database Tables.” http://docs.oracle.com/cd/NOSQL/html/GettingStartedGuideTables/tablesapi.html
A method of emulating tables has been partially described in earlier chapters using a key-naming convention based on entity name, unique identifier, and attribute name. See the “Key Design and Partitioning” section found earlier in this chapter.
It is not practical to fully emulate the features of relational tables. For example, this design pattern does not include a SQL-like query capability. Instead, it focuses on implementing basic get and set operations.
The two functions defined earlier, getCustAttr and setCustAttr, are sample building blocks for building row-level-like functions, such as addCustRecord and getCustRecord. Assume a customer record consists of a name and address. The following is a pseudocode function of the addCustRecord:
define addCustRecord (p_id, p_fname, p_lname, p_addr,
p_city, p_state, p_zip)
begin
setCustAttr(p_id,'fname', p_fname);
setCustAttr(p_id,'lname',p_lname);
setCustAttr(p_id,'addr',p_addr);
setCustAttr(p_id,'city',p_city);
setCustAttr(p_id,'state',p_state);
setCustAttr(p_id,'zip', p_zip);
end;
The following is the corresponding get record function:
define getCustRecord (p_id)
begin
v_custRec = make_list (
getCustAttr(p_id,'fname', p_fname),
getCustAttr(p_id,'lname',p_lname),
getCustAttr(p_id,'addr',p_addr),
getCustAttr(p_id,'city',p_city),
getCustAttr(p_id,'state',p_state),
getCustAttr(p_id,'zip', p_zip)
);
return(v_custRec);
end;
Emulating tables is helpful when you routinely get or set a related set of attributes. This pattern is useful when you are dealing with a small number of emulated tables.
If you find yourself emulating many tables or implementing complicated filtering conditions and range searches, you should consider alternative approaches. These can include using key-value databases that support
• Table constructs, such as Oracle’s NoSQL database
• Advanced search features, such as Riak
• Relational databases, such as MySQL
Aggregates
Aggregation is a pattern that supports different attributes for different subtypes of an entity. In a relational database, you can handle subtypes in a couple of different ways. You could create a single table with all attributes across all subtypes.
You could also create a table with the attributes common to all subtypes and then create an additional table for each of the subtypes. Consider the concert ticket sales system. Many concerts are held in large stadiums with assigned seats, some are held in smaller venues with no assigned seating, and still others are multiday festivals with multiple stages and open seating. Table 5.2 shows a list of attributes that must be tracked for the various kinds of concerts.
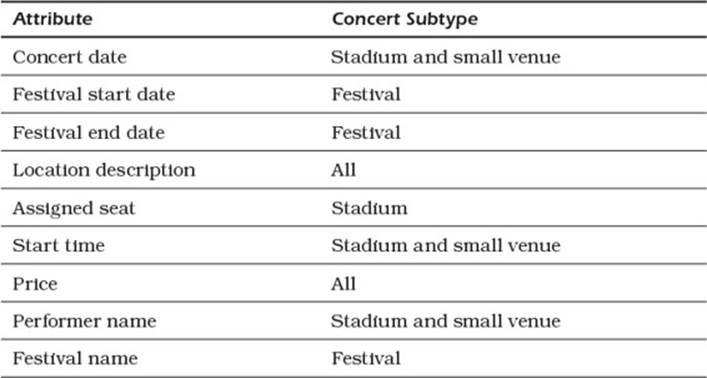
Table 5.2 Sample Attributes for Multiple Types of Concerts
Two attributes are used by all concert types, three are used by stadium and small venue concerts, three are used by festivals only, and one is used by stadiums only.
In a relational database, you could create a single table with all the attributes listed in Table 5.2, or you could create a table with common attributes and subtype tables, as shown in Figure 5.6. The single table would have unused columns and could become unwieldy as the number of subtypes and attributes grows. Using a table with common attributes and subtype tables requires join operations to get all data about a concert ticket. Aggregation in key-value databases takes a different approach.
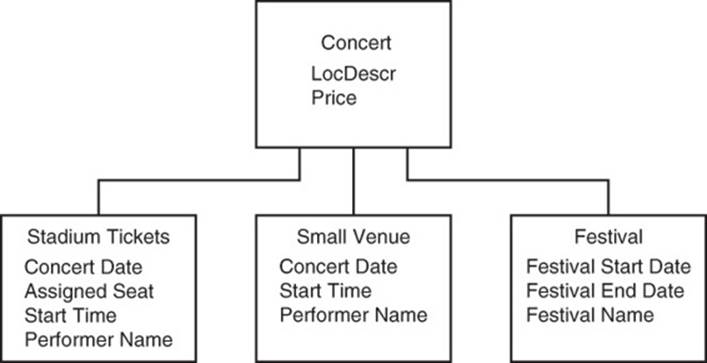
Figure 5.6 Entity subtypes can be modeled in relational databases as a common table with tables to store attributes of each subtype.
A single entity type, that is, 'concert', can be used for all types and the values can be lists of attribute value pairs specific to each type. In addition, a type indicator is used in the list to distinguish the concert type. For example, a value of a stadium ticket could be
{'type':'stadium', 'conDate':15-Mar-2015, 'locDescr':
'Springfield Civic Center', 'assgnSeat': 'J38',
'startTime':'17:30', 'price':'$50.00', 'perfName':
'The National' }
The following is a sample small venue concert ticket:
{'type':'small venue', 'conDate': 12-Jun-2015,
'locDescr': 'Plymoth Concert Hall', 'startTime':'17:30',
'price':'$75.00', 'perfName':'Joshua Redman' }
Finally, a sample festival ticket is
{'type':'festival', 'festStartDate': 01-Feb-2015,
'festEndDate': 01-Feb-2015, 'locDescr': 'Portland, OR',
price:'$100.00', 'festName':'PDX Jazz Festival'}
Each of these lists can be assigned to a ticket key stored in a namespace called ConcertApp, such as
ConcertApp[ticket:18380] = {'type':'stadium',
'conDate':15-Mar-2015, 'locDescr': 'Springfield
Civic Center', 'assgnSeat': 'J38', 'startTime':'17:30',
'price':'$50.00', 'perfName': 'The National' }
ConcertApp[ticket:18381] = {'type':'small venue',
'conDate': 12-Jun-2015, 'locDescr': 'Plymoth Concert
Hall', 'startTime':'17:30', 'price':'$75.00',
'perfName':'Joshua Redman' }
ConcertApp[ticket:18382] = {'type':'festival',
'festStartDate': 01-Feb-2015, 'festEndDate':
01-Feb-2015, 'locDescr': 'Portland, OR',
'price':'$100.00', 'festName':'PDX Jazz Festival'}
You can write set and get functions to check the type of ticket and then assign or retrieve the appropriate attribute values.
Atomic Aggregates
Atomic aggregates contain all values that must be updated together or not at all. Recall that relational databases support the ACID properties, and the A in ACID stands for atomicity. Relational databases and some key-value databases provide transactions to ensure multiple statements are all completed successfully or not at all.
![]() Tip
Tip
If you are using a key-value database that does not support transactions, you might want to use the atomic aggregate pattern in place of transactions.
The atomic aggregate pattern uses a single assignment statement to save multiple values. For example, if the concert ticket application logged a record each time a stadium ticket is purchased, it should record the date, location, and seat assignment. For example:
ConcertApp[ticketLog:9888] = {'conDate':15-Mar-2015,
'locDescr':
'Springfield Civic Center', 'assgnSeat': 'J38'}
This will save all three values or none at all. If you tried to log each attribute separately, you would run the risk of completing some but not all of the operations.
Consider, if you used the following three statements instead of the one atomic aggregate statement above:
ConcertApp[ticketLog:9888:conDate] = 15-Mar-2015
ConcertApp[ticketLog:9888:locDescr] = 'Springfield Civic
Center'
ConcertApp[ticketLog:9888:assgnSeat] = 'J38'
If the server writing this data to disk failed after writing the locDescr attribute but before writing the assgnSeat attribute, then you would lose a critical piece of data. The atomic aggregate pattern is not a full substitute for transaction support, but it does help avoid partially writing a set of attributes.
Enumerable Keys
Enumerable keys are keys that use counters or sequences to generate new keys. This on its own would not be too useful; however, when combined with other attributes, this can be helpful when working with groups of keys. Take logging, for example.
You saw in the “Atomic Aggregates” section that you could save information about each ticket sale using an assignment, such as the following:
ConcertApp[ticketLog:9888] = {'conDate':15-Mar-2015,
'locDescr':
'Springfield Civic Center', 'assgnSeat': 'J38'}
The key is a combination of the entity name 'ticketLog' and a counter. Presumably, the counter starts at 1 and increases by one each time a ticket is sold. This is suitable for recording information, but it does not help if you want to work with a range of logged values.
For example, if you wanted to retrieve log entries for all tickets sold on a particular day, a better key format would be 'ticketLog' concatenated to a date concatenated with a counter, such as 'ticketLog:20140617:10', which is the key assigned to the tenth ticket sold on June 17, 2014.
You can retrieve a range of ticket keys by generating a series of keys, for example, 'ticketLog:20140617:1', 'ticketLog:20140617:2', 'ticketLog:20140617:3', and so on until you generate a key that does not exist or until you reach a number of keys you specify.
Indexes
Inverted indexes are sets of key-value pairs that allow for looking up keys or values by other attribute values of the same entity. Let’s revisit the ticket logging key-value example:
ConcertApp[ticketLog:9888] = {'conDate':15-Mar-2015,
'locDescr':
'Springfield Civic Center', 'assgnSeat': 'J38'}
This is useful for recording all seats assigned across concerts, but it is not easy to list only seats assigned in a particular location unless your key-value database provides search capabilities. For those that do not, inverted indexes can help. If you want to track all seats assigned in the Springfield Civic Center, you could use a function such as the following:
define addLocAssgnSeat(p_locDescr, p_seat)
begin
v_seatList = ConcertApp[p_locDescr]
v_seatList = append(v_seatList, p_seat)
ConcertApp[p_locDescr] = v_seatList
end;
This function accepts the location name and seat as parameters. v_seatList is a local variable to store a copy of the current list of sold seats at the location. The append statement adds the parameter p_list to v_seatList, and the following statement assigns the new set of sold seats to the value associated with the location specified by the parameter p_locDescr.
If the function is initially called as the following, it would set the value of ConcertApp['Springfield Civic Center'] to {'J38'}:
addLocAssgnSeat('Springfield Civic Center', 'J38')
If the application then sold the following seats ‘J39’, ‘A17’, ‘A18’, ‘A19’, and ‘R22’ and called the addLocAssngSeat function for each sale, the value of ConcertApp[('Springfield Civic Center'] would be {'J38', 'J39', 'A17', 'A18', 'A19', 'R22'}.
The design patterns discussed here solve some common problems you may face when developing applications using key-value attributes. The Time to Live pattern is useful when you have operations that may be disrupted and can be safely ignored after some period of inactivity or inability to finish the operation.
Emulating tables streamlines the getting and setting of multiple attributes related to a single instance of an entity, but should not be overused. Frequent use of emulating tables can indicate a misuse of a key-value database.
A document database or relational database may be a better option. Aggregates provide a means for working with entities that need to manage subtypes and different attributes associated with each subtype. The atomic aggregate pattern is used when you have multiple attributes that should be set together. It is not a full substitute for transactions, but it serves some of the purposes of transactions. Enumerable keys provide a crude range functionality by allowing a program to generate and test for the existence of keys. Finally, indexes allow you to look up attribute values starting with something other than a key.
![]() Tip
Tip
It is important to remember that these patterns are like templates: They are starting points for solving a problem, but you should feel free to modify and adjust as needed to meet your requirements.
Chapter 1, “Different Databases for Different Requirements,” briefly introduced a case study about a fictional company called TransGlobal Transport and Shipping. Now that you have reviewed the structure, function, and design of key-value databases and related applications, it is time to consider how they can be applied in realistic use cases.
Summary
Key-value databases are the simplest of the NoSQL databases, but they can satisfy the needs of application developers who need basic storage and retrieval services. Designing for key-value databases requires several steps. You should define a naming convention for keys that allows developers to easily create keys and document the types of values associated with the keys. Values can be basic data types or more complicated data structures. Data structures allow for storing multiple attributes together, but large values can have adverse performance consequences. Design patterns described in this chapter can provide starter solutions to common problems as well as help organize applications by introducing an additional level of abstraction. Some key-value database implementations provide additional features such as search and secondary indexes. Take advantage of these when possible. They are likely to be more efficient and require less code than a “do-it-yourself” version of the same functionality.
Case Study: Key-Value Databases for Mobile Application Configuration
TransGlobal Transport and Shipping (TGTS) coordinates the movement of goods around the globe for businesses of all sizes. Customers of TGTS contact the shipper and provide detailed information about packages and cargo that need to be shipped. Simple orders can be a single package shipped across the country, and more complicated orders can entail hundreds of parcels or shipping containers that are transported internationally. To help their customers track their shipments, TGTS is developing a mobile app called TGTS Tracker.
TGTS Tracker will run on the most popular mobile device platforms. To allow customers to monitor their shipments from any of their mobile devices, application designers have decided to keep configuration information about each customer in a centralized database. This configuration information includes
• Customer name and account number
• Default currency for pricing information
• Shipment attributes to appear in the summary dashboard
• Alerts and notification preferences
• User interface options, such as preferred color scheme and font
In addition to configuration information, designers want the app to quickly display summary information in a dashboard. Slower response times are acceptable when customers need to look up more detailed information about shipments. The database supporting TGTS Tracker should support up to 10,000 simultaneous users, with reads making up 90% of all I/O operations.
The design team evaluated relational databases and key-value databases. Relational databases are well suited to manage complex relations between multiple tables, but the need for scalability and fast read operations convinced them that a key-value database was the better choice for TGTS Tracker.
The range of data that is required by the mobile app is fairly limited so the designers felt confident that a single namespace would be sufficient. They chose TrackerNS as the name of the app’s namespace.
Each customer has an account number, so this was selected as a unique identifier for each customer.
The designers then moved on to decide on the structure of values. After reviewing preliminary designs of the user interface, they determined that name and account number appear frequently together, so it made sense to keep them together in a single list of values. The default currency is also frequently required, so it is included in the list of values along with customer name and account number. Because this app is designed to track the status of shipments, there is little need for administrative information, such as billing address, so it is not stored in the key-value database.
The app designers decided to use the following naming convention for keys: entity type:account number. Given the list of data types the tracker manages, the designers decided the database should support four entity types:
• Customer information, abbreviated ‘cust’
• Dashboard configuration options, abbreviated ‘dshb’
• Alerts and notification specifications, abbreviated ‘alrt’
• User interface configurations, abbreviated ‘ui’
The next step in the design process is determining attributes for each entity. The customer entity maintains the customer name and preferred currency. The account number is part of the key, so there is no need to store it again in the list of values. The following is a sample customer key-value pair:
TrackerNS['cust:4719364'] = {'name':'Prime Machine, Inc.',
'currency':'USD'}
The dashboard configuration detail is a list of up to six attributes about a shipment that will appear on a summary screen. The following are options, with abbreviations in parentheses:
• Ship to company (shpComp)
• Ship to city (shpCity)
• Ship to state (shpState)
• Ship to country (shpCountry)
• Date shipped (shpDate)
• Expected date of delivery (shpDelivDate)
• Number of packages/containers shipped (shpCnt)
• Type of packages/containers shipped (shpType)
• Total weight of shipment (shpWght)
• Note on shipment (shpNotes)
The following is a sample dashboard configuration specification:
TrackerNS['dash:4719364'] =
{'shpComp','shpState','shpDate','shpDelivDate'}
The alerts and notification data indicate when messages should be sent to a customer. An alert and notification can be sent when a shipment is picked up, delivered, or delayed. The message can be sent as either an email address or as a text message to a phone. Multiple people can receive messages, and each person receiving a message can be notified under different conditions.
This is modeled with a list of lists as a value. For example, the person with email address ‘jane.washingon@primemachineinc.com’ might get emails when packages are picked up and the person with phone number (202)555-9812 might get a text message when packages are delayed. The key-value pair for that would look like the following:
TrackerNS[alrt:4719364] =
{ altList :
{'jane.washingon@primemachineinc.com','pickup'},
{'(202)555-9812','delay'}
}
Finally, the user interface configuration options are a simple list of attribute value pairs, such as font name, font size, and color scheme. A key-value pair for a user interface specification could be
TrackerNS[alrt:4719364] = { 'fontName': 'Cambria',
'fontSize': 9,
'colorScheme' : 'default'
}
Now that the designers have defined the entity types, key-naming conventions, and structure of values, developers can write supporting code to set and retrieve keys and their values.
Review Questions
1. Describe four characteristics of a well-designed key-naming convention.
2. Name two types of restrictions key-value databases can place on keys.
3. Describe the difference between range partitioning and hash partitioning.
4. How can structured data types help reduce read latency (that is, the time needed to retrieve a block of data from a disk)?
5. Describe the Time to Live (TTL) key pattern.
6. Which design pattern provides some of the features of relational transactions?
7. When would you want to use the Aggregate pattern?
8. What are enumerable keys?
9. How can enumerable keys help with range queries?
10. How would you modify the design of TGTS Tracker to include a user’s preferred language in the configuration?
References
Basho Technologies, Inc., Riak Documentation: http://docs.basho.com/riak/latest/.
FoundationDB. Key-Value Store 2.0 Documentation: https://foundationdb.com/key-value-store/documentation/index.html.
Katsov, Ilya. “NoSQL Data Modeling Techniques.” Highly Scalable Blog: http://highlyscalable.wordpress.com/2012/03/01/nosql-data-modeling-techniques/.
Oracle Corporation. “Oracle NoSQL Database, 12c Release 1”: http://docs.oracle.com/cd/NOSQL/html/index.html.
Redis Documentation: http://redis.io/documentation.
Wikipedia. “Software Design Patterns”: http://en.wikipedia.org/wiki/Software_design_pattern.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.