NoSQL for Mere Mortals (2015)
Part III: Document Databases
Chapter 6. Introduction to Document Databases
“I am a man of fixed and unbending principles, the first of which is to be flexible at all times.”
—EVERETT DIRKSEN
FORMER U.S. SENATOR
Topics Covered In This Chapter
What Is a Document?
Avoid Explicit Schema Definitions
Basic Operations on Document Databases
Developers often turn to document databases when they need the flexibility of NoSQL databases but need to manage more complex data structures than those readily supported by key-value databases. Like key-value databases, and unlike relational databases, document databases do not require you to define a common structure for all records in the data store. Document databases, however, do have some similar features to relational databases. For example, it is possible to query and filter collections of documents much as you would rows in a relational table. Of course, the syntax, or structure, of queries is different between SQL and NoSQL databases, but the functionality is comparable.
This chapter begins the second section of the book dedicated to document databases. The discussion begins by defining a document with respect to document databases. The focus then moves to the structure of documents and the ability to vary the structure of documents within a collection. The later sections of the chapter address basic database operations, organizing data as well as indexing and retrieving documents.
What Is a Document?
When you see the term document, you might think of a word processing or spreadsheet file or perhaps even a paper document. These are the types of things many people would probably think of when they see the word document. They have nothing to do with document databases, at least with respect to the NoSQL type of database.
![]() Note
Note
There are applications that do maintain databases that store word processing, spreadsheets, emails, and other electronic objects you might describe as a document. Attorneys, for example, might use a relational database to store documents related to their cases. These are reasonably and properly called document databases, but they are not the type referred to when discussing NoSQL document databases. From this point on, references in this book to document databases refer to NoSQL document databases, not databases that store electronic documents.
Documents Are Not So Simple After All
Let’s start with another common type of document: an HTML document. Figure 6.1 shows a simple HTML document rendered according to formatting commands in the file.

Figure 6.1 A simple example of an HTML document with basic formatting commands.
HTML documents store two types of information:
• Content commands
• Formatting commands
Content includes text and references to image, audio, or other media files. This is information the viewer of the document will see and hear when the document is rendered. The document also contains formatting commands that specify how the layout and the format of content should look. For example, the title is rendered in a larger font than major headings or subheadings because of different formatting commands. A subset of the HTML code and content that generates Figure 6.1 is shown in Listing 6.1.
![]() Note
Note
Some HTML code has been removed from Listing 6.1 for clarity.
Listing 6.1 Sample of HTML Code Used to Generate Figure 6.1
<body bgcolor=white lang=EN-US style='tab-interval:.5in'>
<div class=Section1>
<div style='border:none;
border-bottom:solid #4F81BD;
border-bottom:1.0pt;
padding:0in 0in 4.0pt 0in'>
<p class=MsoTitle>The Structure of HTML Documents</p>
</div>
<p><o:p> </o:p></p>
<p>HTML documents combine content, such as
text and images, with layout instructions, such as heading
and table formatting commands. </p>
<p><o:p> </o:p></p>
<h1>Major Headings Look Like This</h1>
<p>Major headings are used to indicate the
start of a high level section. Each high level section may
be divided into subsections.</p>
<p><o:p> </o:p></p>
<h2>Minor Headings Indicate Subsections</h2>
<p style='tab-stops:132.0pt'>Minor
headings are useful when you have a long major section and
want to visually break it up into more manageable pieces
for the reader.</p>
<p style='tab-stops:132.0pt'><o:p>
</o:p></p>
<h1>Summary</h1>
<p style='tab-stops:132.0pt'>HTML combines
structure and content. Other standards for structuring
combinations of structure and content include XML and
JSON.</p>
</div>
</body>
</html>
The formatting commands indicate which text should be displayed with a major heading (for example, surrounded by <h1> and </h1>), when to start a new paragraph (that is, the <p> and </p> tags), and other rendering instructions.
The details of the particular commands are not important for this discussion—the key point is that HTML combines formatting and content in a single document. In much the same way, documents in document databases combine structure and content.
HTML documents use predefined tags to indicate formatting commands. Documents in document databases are not constrained to a predefined set of tags for specifying structure. Instead, developers are free to choose the terms they need to structure their content just as data modelers choose table and column names for relational databases.
Let’s consider a simple example of a customer record that tracks the customer ID, name, address, first order date, and last order date. Using JavaScript Object Notation (JSON), a sample customer record is
{
"customer_id":187693,
"name": "Kiera Brown",
"address" : {
"street" : "1232 Sandy Blvd.",
"city" : "Vancouver",
"state" : "Washington",
"zip" : "99121"
},
"first_order" : "01/15/2013",
"last_order" : " 06/27/2014"
}
The Structure of JSON Objects
JSON objects are constructed using several simple syntax rules:
• Data is organized in key-value pairs, similar to key-value databases.
• Documents consist of name-value pairs separated by commas.
• Documents start with a { and end with a }.
• Names are strings, such as "customer_id" and "address".
• Values can be numbers, strings, Booleans (true or false), arrays, objects, or the NULL value.
• The values of arrays are listed within square brackets, that is [ and ].
• The values of objects are listed as key-value pairs within curly brackets, that is, { and }.
JSON is just one option for representing documents in a document database. The same information in the preceding example is represented in XML as follows:
<customer_record>
<customer_id>187693</customer_id>
<name>"Kiera Brown"</name>
<address>
<street>"1232 Sandy Blvd."</street>
<city>"Vancouver"</city>
<state>"Washington"</state>
<zip>"99121"</zip>
</address>
<first_order>"01/15/2013"</first_order>
<last_order>"06/27/2014"</last_order>
</customer_record>
![]() Note
Note
Describing the full syntax of XML is beyond the scope of this chapter. See XMLFiles.com or W3Schools.com/xml for details.
To summarize, a document is a set of key-value pairs. Keys are represented as strings of characters. Values may be basic data types (such as numbers, strings, and Booleans) or structures (such as arrays and objects). Documents contain both structure information and data. The name in a name-value pair indicates an attribute and the value in a name-value pair is the data assigned to that attribute. JSON and XML are two formats commonly used to define documents.1
1. Binary JSON, or BSON, is a binary representation of JSON objects and is another method for specifying documents.
Documents and Key-Value Pairs
An advantage of documents over key-value databases is that related attributes are managed within a single object. As you may recall, you can emulate some aspects of relational tables using a naming convention based on the name of the entity modeled, a unique identifier for an instance of that entity, and the name of the attribute.
Documents, like relational tables, organize multiple attributes in a single object. This allows database developers to more easily implement common requirements, such as returning all attributes of an entity based on a filter applied to one of the attributes. For example, in one step you could filter a list of customer documents to identify those whose last purchase was at least six months ago and return their IDs, names, and addresses. If you were using a key-value database, you would need to query all last purchase dates, generate a list of unique identifiers associated with those customers with a purchase date greater than six months, and then query for names and addresses associated with each identifier in the list (see Figure 6.2).

Figure 6.2 Document databases require less code than key-value data stores to query multiple attributes.
Managing Multiple Documents in Collections
The full potential of document databases becomes apparent when you work with large numbers of documents. Documents are generally grouped into collections of similar documents. One of the key parts of modeling document databases is deciding how you will organize your documents into collections.
Getting Started with Collections
Collections can be thought of as lists of documents. Document database designers optimize document databases to quickly add, remove, update, and search for documents. They are also designed for scalability, so as your document collection grows, you can add more servers to your cluster to keep up with demands for your database.
It is important to note that documents in the same collection do not need to have identical structures, but they should share some common structures. For example, Listing 6.2 shows a collection of four documents with similar structures.
Listing 6.2 Documents with Similar Structures
{
{
"customer_id":187693,
"name": "Kiera Brown"
"address" : {
"street" : "1232 Sandy Blvd.",
"city" : "Vancouver",
"state" : "WA",
"zip" : "99121"
},
"first_order" : "01/15/2013",
"last_order" : " 06/27/2014"
}
{
"customer_id":187694,
"name": "Bob Brown",
"address" : {
"street" : "1232 Sandy Blvd.",
"city" : "Vancouver",
"state" : "WA",
"zip" : "99121"
},
"first_order" : "02/25/2013",
"last_order" : " 05/12/2014"
}
{
"customer_id":179336,
"name": "Hui Li",
"address" : {
"street" : "4904 Main St.",
"city" : "St Louis",
"state" : "MO",
"zip" : "99121"
},
"first_order" : "05/29/2012",
"last_order" : " 08/31/2014",
"loyalty_level" : "Gold",
"large_purchase_discount" : 0.05,
"large_purchase_amount" : 250.00
}
{
"customer_id":290981,
"name": "Lucas Lambert",
"address" : {
"street" : "974 Circle Dr.",
"city" : "Boston",
"state" : "MA",
"zip" : "02150"
},
"first_order" : "02/14/2014",
"last_order" : " 02/14/2014",
"number_of_orders" : 1,
"number_of_returns" : 1
}
}
Notice that the first two documents have the same structure while the third and fourth documents have additional attributes. The third document contains three new fields: loyalty_level, large_purchase_discount, and large_purchase_amount. These are used to indicate this person is considered a valued customer who should receive a 5% discount on all orders over $250. (The currency type is implicit.) The fourth document has two other new fields, number_of_orders and number_of_returns. In this case, it appears that the customer made one purchase on February 14, 2014, and returned it.
One of the advantages of document databases is that they provide flexibility when it comes to the structure of documents. If only 10% of your documents need to record loyalty and discount information, why should you have to clutter the other 90% with unused fields? You do not have to when using document databases. The next section addresses this issue in more detail.
Tips on Designing Collections
Collections are sets of documents. Because collections do not impose a consistent structure on documents in the collection, it is possible to store different types of documents in a single collection. You could, for example, store customer, web clickstream data, and server log data in the same collection. In practice, this is not advisable.
In general, collections should store documents about the same type of entity. The concept of an entity is fairly abstract and leaves a lot of room for interpretation. You might consider both web clickstream data and server log data as a “system event” entity and, therefore, they should be stored in the same collection.
Avoid Highly Abstract Entity Types
A system event entity such as this is probably too abstract for practical modeling. This is because web clickstream data and server log data will have few common fields. They may share an ID field and a time stamp but few other attributes. The web clickstream data will have fields capturing information about web pages, users, and transitions from one page to another. The server log documents will contain details about the server, event types, severity levels, and perhaps some descriptive text. Notice how dissimilar web clickstream data is from server log data:
{ "id" : 12334578,
"datetime" : "201409182210",
"session_num" : 987943,
"client_IP_addr" : "192.168.10.10",
"user_agent" : "Mozilla / 5.0",
"referring_page" : "http://www.example.com/page1"
}
{ "id" : 31244578,
"datetime" : "201409172140",
"event_type" : "add_user",
"server_IP_addr" : "192.168.11.11",
"descr" : "User jones added with sudo privileges"
}
If you were to store these two document types in a single collection, you would likely need to add a type indicator so your code could easily distinguish between a web clickstream document and a server log event document.
In the preceding example, the documents would be modified to include a type indicator:
{ "id" : 12334578,
"datetime" : "201409182210",
"doc_type": "click_stream",
"session_num" : 987943,
"client_IP_addr" : "192.168.10.10",
"user_agent" : "Mozilla / 5.0",
"referring_page" : "http://www.example.com/page1"
}
{ "id" : 31244578,
"datetime" : "201409172140"
"doc_type" : "server_log"
"event_type" : "add_user"
"server_IP_addr" : "192.168.11.11"
"descr" : "User jones added with sudo privileges"
}
![]() Tip
Tip
If you find yourself using a 'doc_type' field and frequently filtering your collection to select a single document type, carefully review your documents. You might have a mix of entity types.
Filtering collections is often slower than working directly with multiple collections, each of which contains a single document type. Consider if you had a system event collection with 1 million documents: 650,000 clickstream documents and 350,000 server log events. Because both types of events are added over time, the document collection will likely store a mix of clickstream and server log documents in close proximity to each other.
If you are using disk storage, you will likely retrieve blocks of data that contain both clickstream and server log documents. This will adversely impact performance (see Figure 6.3).
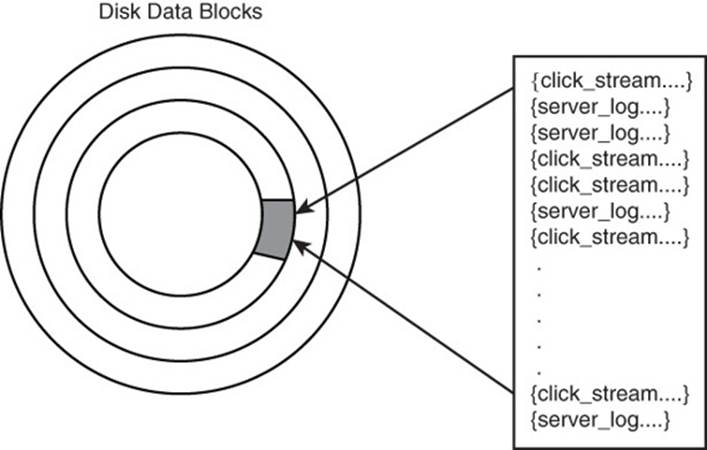
Figure 6.3 Mixing document types can lead to multiple document types in a disk data block. This can lead to inefficiencies because data is read from disk but not used by the application that filters documents based on type.
You might argue that indexes could be used to improve performance. Indexes certainly improve data access performance in some cases. However, indexes may be cached in memory or stored on disk. Retrieving indexes from disk will add time to processing. Also, if indexes reference a data block that contains both clickstream and server log data, the disk will read both types of records even though one will be filtered out in your application.
Depending on the size of the collection, the index, and the number of distinct document types (this is known as cardinality in relational database terminology), it may be faster to scan the full document collection rather than use an index. Finally, consider the overhead of writing indexes as new documents are added to the collection.
Watch for Separate Functions for Manipulating Different Document Types
Another clue that a collection should be broken into multiple collections is your application code. The application code that manipulates a collection should have substantial amounts of code that apply to all documents and some amount of code that accommodates specialized fields in some documents.
For example, most of the code you would write to insert, update, and delete documents in the customer collection would apply to all documents. You would probably have additional code to handle loyalty and discount fields that would apply to only a subset of all documents.
![]() Tip
Tip
If your code at the highest levels consists of if statements conditionally checking document types that branch to separate functions to manipulate separate document types, it is a good indication you probably have mixed document types that should go in separate collections (seeFigure 6.4).

Figure 6.4 High-level branching in functions manipulating documents can indicate a need to create separate collections. Branching at lower levels is common when some documents have optional attributes.
Use Document Subtypes When Entities Are Frequently Aggregated or Share Substantial Code
The document collection design tips have so far focused on ensuring you do not mix dissimilar documents in a single collection. If there were no more design tips, you might think that you should never use type indicators in documents. That would be wrong—very wrong.
There are times when it makes sense to use document type indicators and have separate code to handle the different types.
![]() Note
Note
When it comes to designing NoSQL databases, remember design principles but apply them flexibly. Always consider the benefits and drawbacks of a design principle in a particular situation. That is what the designers of NoSQL databases did when they considered the benefits and drawbacks of relational databases and decided to devise their own data model that broke many of the design principles of relational databases.
It is probably best to start this tip with an example. In addition to tracking customers and their clickstream data, you would like to track the products customers have ordered. You have decided the first step in this process is to create a document collection containing all products, which for our purposes, includes books, CDs, and small kitchen appliances. There are only three types of products now, but your client is growing and will likely expand into other product types as well.
All of the products have the following information associated with them:
• Product name
• Short description
• SKU (stock keeping unit)
• Product dimensions
• Shipping weight
• Average customer review score
• Standard price to customer
• Cost of product from supplier
Each of the product types will have specific fields. Books will have fields with information about
• Author name
• Publisher
• Year of publication
• Page count
The CDs will have the following fields:
• Artist name
• Producer name
• Number of tracks
• Total playing time
The small kitchen appliances will have the following fields:
• Color
• Voltage
• Style
How should you go about deciding how to organize this data into one or more document collections? Start with how the data will be used. Your client might tell you that she needs to be able to answer the following queries:
• What is the average number of products bought by each customer?
• What is the range of number of products purchased by customers (that is, the lowest number to the highest number of products purchased)?
• What are the top 20 most popular products by customer state?
• What is the average value of sales by customer state (that is, Standard price to customer – Cost of product from supplier)?
• How many of each type of product were sold in the last 30 days?
All the queries use data from all product types, and only the last query subtotals the number of products sold by type. This is a good indication that all the products should be in a single document collection (see Figure 6.5). Unlike the example of the collection with clickstream and server log data, the product document types are frequently used together to respond to queries and calculate derived values.
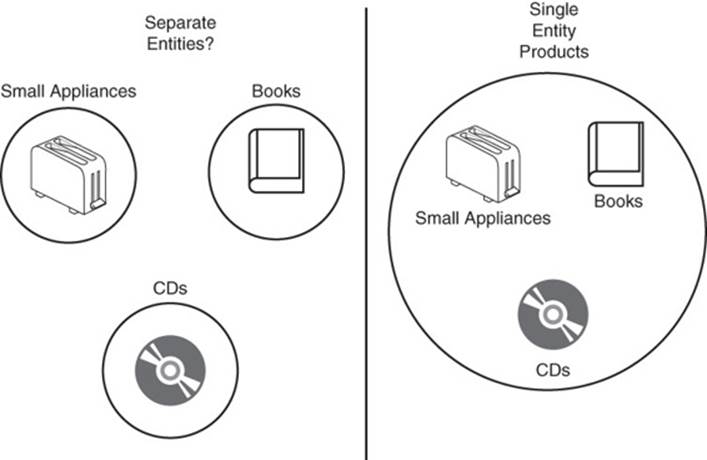
Figure 6.5 When is a toaster the same as a database design book? When they are treated the same by application queries. Queries can help guide the organization of documents and collections.
Another reason to favor a single document collection is that the client is growing and will likely add new product types. If the number of product types grows into the tens or even hundreds, the number of collections would become unwieldy.
![]() Note
Note
Relational databases are often used to support a broad range of query types. NoSQL databases complement relational databases by providing functionality optimized for particular aspects of application support. Rather than start with data and try to figure out how to organize your collections, it can help to start with queries to understand how your data will be used. This can help inform your decisions about how to structure collections and documents.
To summarize, avoid overly abstract document types. If you find yourself writing separate code to process different document subtypes, you should consider separating the types into different collections. Poor collection design can adversely affect performance and slow your application. There are cases where it makes sense to group somewhat dissimilar objects (for example, small kitchen appliances and books) if they are treated as similar (for example, they are all products) in your application.
Documents and collections are the organizing structures of document database storage. You might be wondering when and where you define the specification describing documents. Programmers define structures and record types before using them in their programs. Relational database designers spend a substantial amount of time crafting and tuning data models that define tables, columns, and other data structures.
Now it is time to consider how such specifications, known as schemas, are used in document databases.
Avoid Explicit Schema Definitions
If you have worked with relational databases, you are probably familiar with defining database schemas. A schema is a specification that describes the structure of an object, such as a table. A pseudoschema specification for the customer record discussed above is
CREATE TABLE customer (
customer_ID integer,
name varchar(100),
street varchar(100),
city varchar(100),
state varchar(2),
zip varchar(5),
first_purchase_date date,
last_purchase_date date
)
This schema defines a table to hold customer and address information. All customer records have the same eight columns: customer_id, name, street, city, state, zip, first_purchase_date, and last_purchase_date. Each column is assigned a specific data type, either integer, date, or varchar. Varchar is a variable character string. The number in parentheses following varchar is the maximum length of the value stored in that attribute.
Data modelers have to define tables in a relational database before developers can execute code to add, remove, or update rows in the table. Document databases do not require this formal definition step. Instead, developers can create collections and documents in collections by simply inserting them into the database (see Figure 6.6).
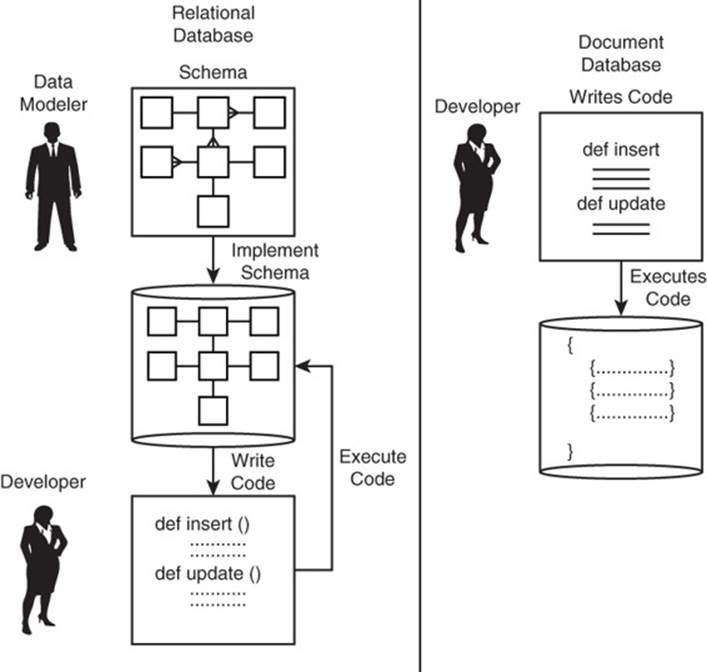
Figure 6.6 Relational databases require an explicitly defined schema, but document databases do not.
Document databases are designed to accommodate variations in documents within a collection. Because any document could be different from all previously inserted documents, it does not make sense to require data modelers to specify all possible document fields prior to building and populating the database. This freedom from the need to predefine the database structure is captured in the term often used to describe document databases: schemaless.
Although it is true that you do not have to define a schema prior to adding documents, there is an organization implicit in the set of documents you insert into the database. The organization is apparent in the code that manipulates the documents from the database.
For example, if you were building the product database described previously, you would have code that sets the value of artist, producer, number of tracks, and total play time for each CD inserted. Similarly, you would have code to set small appliance fields and book fields as well. Presumably, you would use the same code to set common fields, such as product name and SKU.
Polymorphic schema is another term that describes document databases. Polymorphic is derived from Latin and literally means “many shapes.” This makes it an apt description for a document database that supports multiple types of documents in a single collection.
Basic Operations on Document Databases
The basic operations on document databases are the same as other types of databases and include the following:
• Inserting
• Deleting
• Updating
• Retrieving
There is no standard data manipulation language used across document databases to perform these operations. The examples that follow use a command structure similar to that of MongoDB, currently the most commonly used document database.2
2. DB-Engines Rankings. http://db-engines.com/en/ranking.
Before introducing the basic operations, there is one additional data structure to introduce and that is the database. The database is the container for collections and containers are for documents. The logical relationship between these three data structures is shown in Figure 6.7.

Figure 6.7 The database is the highest-level logical structure in a document database and contains collections of documents.
![]() Note
Note
By convention, the database container is referred to as ‘db’ in sample code. To refer to a collection, you prefix the collection name with ‘db’. For example, the collection customer is indicated by ‘db.customer.’ The basic operations are performed on collections specified in this way.
Inserting Documents into a Collection
Collections are objects that can perform a number of different operations. The insert method adds documents to a collection. For example, the following adds a single document describing a book by Kurt Vonnegut to the books collection:
db.books.insert( {"title":" Mother Night", "author": "Kurt
Vonnegut, Jr."} )
![]() Tip
Tip
It is a good practice to include a unique identifier with each document when it is inserted.
Instead of simply adding a book document with the title and author name, a better option would be to include a unique identifier as in
db.books.insert( {book_id: 1298747,
"title":"Mother Night",
"author": "Kurt Vonnegut, Jr."} )
![]() Note
Note
Different document databases have different recommendations for unique identifiers. MongoDB adds a unique identifier if one is not provided. CouchDB supports any string as a unique identifier but recommends using a Universally Unique Identifier (UUID). Check your document database documentation for details on unique identifiers.
In many cases, it is more efficient to perform bulk inserts instead of a series of individual inserts. For example, the following three insert commands could be used to add three books to the book collection:
db.books.insert( {"book_id": 1298747,
"title":"Mother Night",
"author": "Kurt Vonnegut, Jr."} )
db.books.insert( {"book_id": 639397,
"title":"Science and the Modern World",
"author": "Alfred North Whitehead"} )
db.books.insert( {"book_id": 1456701,
"title":"Foundation and Empire",
"author": "Isaac Asimov"} )
Each of these commands would incur the overhead of the write operation. A single bulk insert would incur that overhead only once, so it is especially useful for loading a large number of documents at once. The same three documents listed above could be added with the following command:
db.books.insert(
[
{"book_id": 1298747,
"title":"Mother Night",
"author": "Kurt Vonnegut, Jr."},
{"book_id": 639397,
"title":"Science and the Modern World",
"author": "Alfred North Whitehead"},
{"book_id": 1456701,
"title":"Foundation and Empire",
"author": "Isaac Asimov"}
]
}
The [ and ] in the parameter list delimit an array of documents to insert.
![]() Tip
Tip
Check your document database documentation for limits on the size of bulk inserts. If you have many large documents, you may need to perform multiple bulk inserts to ensure that your array of documents does not exceed the bulk insert size limit.
Deleting Documents from a Collection
You can delete documents from a collection using the remove methods. The following command deletes all documents in the books collection:
db.books.remove()
Note that the collection still exists, but it is empty.
The remove command is probably more frequently used for selective deleting rather than removing all documents from a collection. To delete a single document, you can specify a query document that matches the document you would like to delete. A query document is a list of keys and values that are matched against documents. The query document
{"book_id": 639397}
uniquely identifies the book titled Science and the Modern World. (For those familiar with SQL, this is analogous to specifying a WHERE clause.) To delete the book titled Science and the Modern World, you would issue the following command:
db.books.remove({"book_id": 639397})
The remove command deletes all documents that match the query document. This example used the unique identifier for a book, so only one book is deleted. Suppose you have removed all books from the books collection and then execute the following command:
db.books.insert(
[
{"book_id": 1298747,
"title":"Mother Night",
"author": "Kurt Vonnegut, Jr."},
{"book_id": 1298770,
"title":"Cat's Cradle",
"author": "Kurt Vonnegut, Jr."},
{"book_id": 639397,
"title":"Science and the Modern
World",
"author": "Alfred North
Whitehead"},
{"book_id": 1456701,
"title":"Foundation and Empire",
"author": "Isaac Asimov"}
]
The books collection now has four books. Executing the following remove command will delete the two books by Kurt Vonnegut, Jr.:
db.books.remove({"author": "Kurt Vonnegut, Jr."})
You should be especially careful when deleting documents that may be referenced in other documents. For example, assume you have a simple orders collection that contains customers and books they ordered:
{
{"customer_id" : 183747, "book_id": 639397},
{"customer_id" : 165301, "book_id": 639397},
{"customer_id" : 183747, "book_id":1298770},
...
}
If you execute the following command, you will remove two books with IDs 1298747 and 1298770:
db.books.remove({"author": "Kurt Vonnegut, Jr."})
The orders collection, however, will still have references to these IDs. If your application code were to try to look up the book with ID 1298770, it would fail.
![]() Note
Note
Relational databases can be designed to prevent this type of problem, but document databases depend on application code to manage this type of data integrity.
Updating Documents in a Collection
Once a document has been inserted into a collection, it can be modified with the update method. The update method requires two parameters to update:
• Document query
• Set of keys and values to update
![]() Note
Note
Because we are using MongoDB syntax, it should be noted that the MongoDB update method takes three optional parameters in addition to the two described here. They are out of the scope of this chapter.
Like the remove method, the document query of the update command is a set of keys and values identifying the documents to update. To indicate you want to update Kurt Vonnegut Jr.’s Mother Night, you would use the following query document:
{"book_id": 1298747}
![]() Note
Note
When using MongoDB syntax, you should note that the MongoDB update method takes three optional parameters in addition to the two described here. However, the other options are out of the scope of this chapter.
MongoDB uses the $set operator to specify which keys and values should be updated. For example, the following command adds the quantity key with the value of 10 to the collection:
db.books.update ({"book_id": 1298747},
{$set {"quantity" : 10 }})
The full document would then be
{"book_id": 1298747,
"title":"Mother Night",
"author": "Kurt Vonnegut, Jr.",
"quantity" : 10}
The update command adds a key if it does not exist and sets the value as indicated. If the key already exists, the update command changes the value associated with it.
Document databases sometimes provide other operators in addition to set commands. For example, MongoDB has an increment operator ($inc), which is used to increase the value of a key by the specified amount. The following command would change the quantity of Mother Night from 10 to 15:
db.books.update ({"book_id": 1298747},
{$inc {"quantity" : 5 }})
Check your document database documentation for details on update operators.
Retrieving Documents from a Collection
The find method is used to retrieve documents from a collection. As you might expect, the find method takes an optional query document that specifies which documents to return. The following command matches all documents in a collection:
db.books.find()
This is useful if you want to perform an operation on all documents in a collection.
If, however, you only want a subset of documents in the database, you would specify selection criteria using a document. For example, the following returns all books by Kurt Vonnegut, Jr.:
db.books.find({"author": "Kurt Vonnegut, Jr."})
These two find examples both return all the keys and values in the documents. There are times when it is not necessary to return all key-value pairs. In those cases, you can specify an optional second argument that is a list of keys to return along with a “1” to indicate the key should be returned.
db.books.find({"author": "Kurt Vonnegut, Jr."},
{"title" : 1} )
This returns only the titles of books by Kurt Vonnegut, Jr.
![]() Tip
Tip
By default, MongoDB returns the unique identifier as well, even if it is not explicitly listed in the set of keys to return.
More complex queries are built using conditionals and Boolean operators. To retrieve all books with a quantity greater than or equal to 10 and less than 50, you could use the following command:
Db.books.find( {"quantity" : {"$gte" : 10, "$lt" : 50 }} )
Notice that even more complex criteria are still constructed as query documents.
The conditionals and Booleans supported in MongoDB include the following:
• $lt—Less than
• $let—Less than or equal to
• $gt—Greater than
• $gte—Greater than or equal to
• $in—Query for values of a single key
• $or—Query for values in multiple keys
• $not—Negation
Document databases can provide more extensive query capabilities, including the ability to match regular expressions or apply full-text search. Check the documentation for your document database for additional information.
![]() In addition to these basic operations, document databases support advanced functions such as indexing. These more advanced features are covered in Chapter 8, “Designing for Document Databases.”
In addition to these basic operations, document databases support advanced functions such as indexing. These more advanced features are covered in Chapter 8, “Designing for Document Databases.”
Summary
Documents are flexible data structures. They do not require predefined schemas and they readily accommodate variations in the structure of documents. Documents are organized into related sets called collections. Collections are analogous to a relational table, and documents are analogous to rows in a relational table.
The flexibility of document databases enables you to make poor design decisions with regard to organizing collections. Collections should contain similar types of entities, although the keys and values may differ across documents.
There are times when modeling documents using highly abstract entities, such as the system event entity discussed previously, can adversely affect performance and lead to more complicated application code than necessary. There are other times, however, when abstract entities, such as products, are appropriate. Analyze the types of queries your database will support to guide your design decisions.
Unlike relational databases, there is not a standard query language for document databases. The examples in this chapter, and subsequent chapters, are based on the syntax of a commonly used document database. The principles and concepts described here should apply across document databases, although implementation details will vary.
Review Questions
1. Define a document with respect to document databases.
2. Name two types of formats for storing data in a document database.
3. List at least three syntax rules for JSON objects.
4. Create a sample document for a small appliance with the following attributes: appliance ID, name, description, height, width, length, and shipping weight. Use the JSON format.
5. Why are highly abstract entities often avoided when modeling document collections?
6. When is it reasonable to use highly abstract entities?
7. Using the db.books collection described in this chapter, write a command to insert a book to the collection. Use MongoDB syntax.
8. Using the db.books collection described in this chapter, write a command to remove books by Isaac Asimov. Use MongoDB syntax.
9. Using the db.books collection described in this chapter, write a command to retrieve all books with quantity greater than or equal to 20. Use MongoDB syntax.
10. Which query operator is used to search for values in a single key?
References
Chodorow, Kristina. 50 Tips and Tricks for MongoDB Developers. Sebastopol, CA: O’Reilly Media, Inc., 2011.
Chodorow, Kristina. MongoDB: The Definitive Guide. Sebastopol, CA: O’Reilly Media, Inc., 2013.
Copeland, Rick. MongoDB Applied Design Patterns. Sebastopol, CA: O’Reilly Media, Inc., 2013.
Couchbase Documentation: http://docs.couchbase.com/
MongoDB 2.6 Manual: http://docs.mongodb.org/manual/
O’Higgins, Niall. MongoDB and Python: Patterns and Processes for the Popular Document-Oriented Database. Sebastopol, CA: O’Reilly Media, Inc., 2011.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.