NoSQL for Mere Mortals (2015)
Part III: Document Databases
Chapter 7. Document Database Terminology
“We must dare to think ‘unthinkable’ thoughts. We must learn to explore all the options and possibilities that confront us in a complex and rapidly changing world.”
—J. WILLIAM FULBRIGHT
FORMER U.S. SENATOR
Topics Covered In This Chapter
Document and Collection Terms
Types of Partitions
Data Modeling and Query Processing
The previous chapter introduced the basic concepts of document databases. This chapter focuses on defining commonly used terms in document database theory and practice.
![]() Note
Note
As with the other terminology chapters in this book, the goal is to provide in-depth descriptions of key terms used in document databases. Some of the terminology is generally applicable to other distributed databases as well, whereas some is specific to document databases.
The first set of terms is related to the basic data structures of document databases. You should be familiar with these from the last chapter, but they are presented here as well in somewhat more formal terms.
The second section defines terms you will come across as you learn about document database architecture. The terms defined in this section are used to describe distributed databases in general, especially with regard to how to scale large databases. You will see these terms frequently as you work with NoSQL technologies.
The final section is the most heterogeneous. It contains a mix of document modeling terms and operations. The document modeling terms are high-level broad concepts. The next chapter introduces more specific design patterns. The section concludes with several somewhat miscellaneous but important terms you should be familiar with when working with document databases.
Document and Collection Terms
Documents and collections are the basic data structures of a document database. They are somewhat analogous to rows and tables in relational databases. The informal introduction to these terms in Chapter 6, “Introduction to Document Databases,” was sufficient to introduce the basic concepts of document databases. Now it is time for more formal definitions that allow for more precise descriptions and reasoning about these structures.
The following terms are defined:
• Document
• Collection
• Embedded document
• Schemaless
• Polymorphic schema
At the end of this section, you should have an understanding of how documents are organized into collections. You should also understand important properties of document database organization that allow for flexible database design. This is one of the primary reasons document databases have gained popularity among developers.
Document
A document is a set of ordered key-value pairs. A key value is a data structure that consists of two parts called, not surprisingly, the key and the value.
![]() Note
Note
For those who may have skipped the section of this book on key-value databases, a key is a unique identifier used to look up a value. A value is an instance of any supported data type, such as a string, number, array, or list.
Documents: Ordered Sets of Key-Value Pairs
Because a document is a set, it has one instance of each member. Members are key-value pairs. For example, the following is a set with three members: 'foo': 'a', 'bar': 'b', and 'baz': 'c':
{ 'foo': 'a', 'bar': 'b', 'baz': 'c'}
A slight change turns this set into a nonset (also known as a bag):
{'foo': 'a', 'bar': 'b', 'baz': 'c', 'foo': 'a'}
This list of key values is not a set because there are two instances of the key-value pair 'foo': 'a'.
Sets do not distinguish by order. The following set
{ 'foo': 'a', 'bar': 'b', 'baz': 'c'}
is equivalent to
{'baz': 'c', 'foo': 'a', 'bar': 'b'}
However, for the purposes of designing document databases, these are different documents. The order of key-value pairs matters in determining the identity of a document. The document { 'foo': 'a', 'bar': 'b', 'baz': 'c'} is not the same document as {'baz': 'c', 'foo': 'a', 'bar': 'b'}.
Key and Value Data Types
Keys are generally strings. Some key-value databases support a more extensive set of key data types, so document databases could, in principle, support multiple data types as well.
Values can be a variety of data types. As you might expect, document databases support values of numbers and strings. They also support more structured data types, such as arrays and other documents.
Arrays are useful when you want to track multiple instances of a value and the values are all of one type. For example, if you need to model an employee and a list of her projects, you could use a document such as
{ 'employeeName' : 'Janice Collins',
'department' : 'Software engineering'
'startDate' : '10-Feb-2010',
'pastProjectCodes' : [ 189847, 187731, 176533, 154812]
}
The key pastProjectCodes is a list of project code numbers. All project codes are numbers, so it is appropriate to use an array.
Alternatively, if you want to store, or embed, more information about projects along with the employee information, you could include another document within the employee document. One such version is
{ 'employeeName' : 'Janice Collins',
'department' : 'Software engineering',
'startDate' : '10-Feb-2010',
'pastProjects' : {
{'projectCode' : 189847,
'projectName' : 'Product Recommendation System',
'projectManager' : 'Jennifer Delwiney' },
{'projectCode' : 187731,
'projectName' : 'Finance Data Mart version 3',
'projectManager' : 'James Ross'},
{'projectCode': 176533,
'projectName' : 'Customer Authentication',
'projectManager' : 'Nick Clacksworth'},
{'projectCode': 154812,
'projectName' : 'Monthly Sales Report',
'projectManager': 'Bonnie Rendell'}
}
To summarize, documents are ordered sets of key-value pairs. Keys are used to reference particular values. Values can be either basic or structured data types.
Collection
A collection is a group of documents. The documents within a collection are usually related to the same subject entity, such as employees, products, logged events, or customer profiles. It is possible to store unrelated documents in a collection, but this is not advised.
At the most basic level, collections allow you to operate on groups of related documents. If you maintain a collection of employee records, you can iterate over all employee records in the collection looking for particular employees, such as all employees with startDates earlier than January 1, 2011. If you have a large number of employees, this can be inefficient because you would have to compare every employee record to your search criteria.
In addition to allowing you to easily operate on groups of documents, collections support additional data structures that make such operations more efficient. For example, a more-efficient approach to scanning all documents in a collection is to use an index. Indexes on collections are like indexes in the back of book: a structured set of information that maps from one attribute, such as a key term, to related information, such as a list of page numbers (see Figure 7.1).
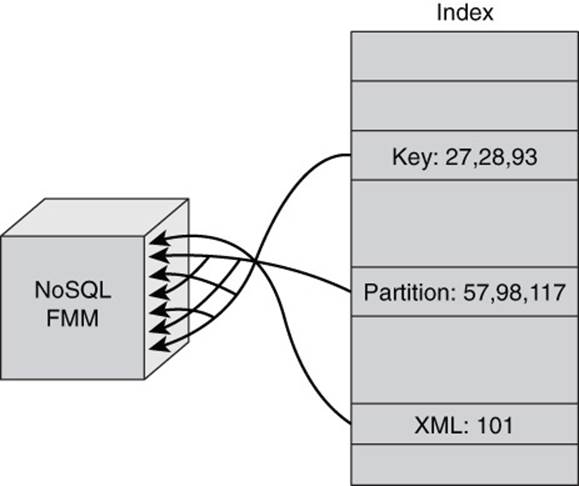
Figure 7.1 Indexes map attributes, such as key terms, to related information, such as page numbers. Using an index is faster than scanning an entire book for key terms.
Collections are groups of similar documents that allow you to easily access or operate on all documents in the group. Collections support additional data structures, such as indexes, to improve the efficiency of operations on those groups of documents.
Embedded Document
One of the advantages of document databases is that they allow developers to store related data in more flexible ways than typically done in relational databases. If you were to model employees and the projects they work on in a relational database, you would probably create two tables: one for employee information and one for project information (see Figure 7.2).
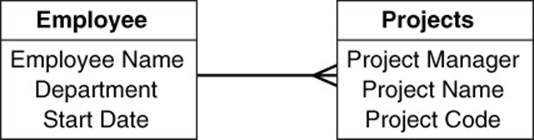
Figure 7.2 Relational data models separate data about different entities into separate tables. This requires looking up information in both tables using a process known as joining.
An embedded document enables document database users to store related data in a single document. This allows the document database to avoid a process called joining in which data from one table, called the foreign key, is used to look up data in another table.
Joining two large tables can be potentially time consuming and require a significant number of read operations from disk. Embedded documents allow related data to be stored together. When the document is read from disk, both the primary and the related information are read without the need for a join operation. Figure 7.3 shows embedded documents within a document.
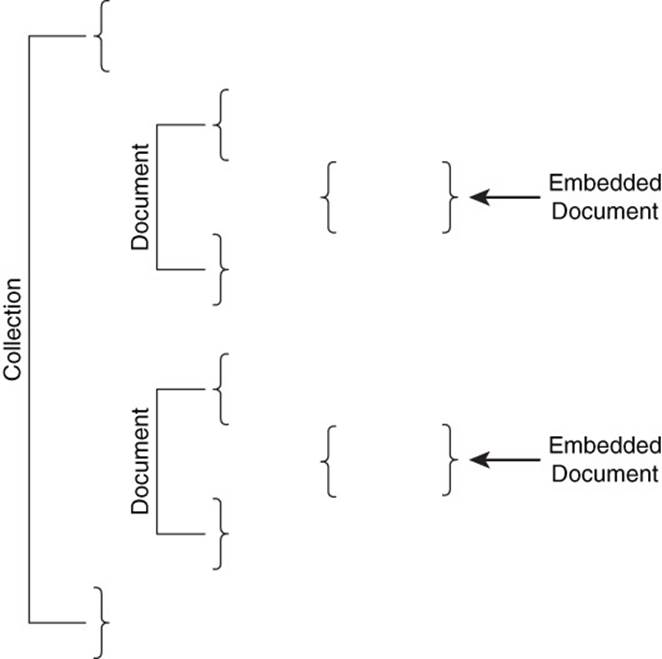
Figure 7.3 Embedded documents are documents within a document. Embedding is used to efficiently store and retrieve data that is frequently used together.
Embedded documents are documents within documents. They are used to improve database performance by storing together data that is frequently used together.
Schemaless
Document databases do not require data modelers to formally specify the structure of documents. A formal structure specification is known as a schema. Relational databases do require schemas. They typically include specifications for
• Tables
• Columns
• Primary keys
• Foreign keys
• Constraints
These all help the relational database management system manage the data in the database. It also helps the database catch errors when data is added to the database. If, for example, someone tries to enter a string when a number is expected, the database management system will issue a warning.
Constraints are rules that describe what kind of data or relation between data is allowed. You could indicate in a schema that a column must always have a value and can never be empty.
![]() Tip
Tip
An empty column in a relational database is referred to as having a NULL value.
Document databases do not require this specification step prior to adding documents to a collection. For this reason, document databases are called schemaless. Schemaless databases have two important differences compared with relational databases:
• More flexibility
• More responsibility
Schemaless Means More Flexibility
In a schemaless database, developers and applications can add new key-value pairs to documents at any time. Once a collection is created, you can add documents to it. There is no need to tell the document database about the structure of the document. In fact, the structures will often vary between documents in a collection. The two documents
{ 'employeeName' : 'Janice Collins',
'department' : 'Software engineering'
'startDate' : '10-Feb-2010',
'pastProjectCodes' : [ 189847, 187731, 176533, 154812]
}
and
{ 'employeeName' : 'Robert Lucas,
'department' : 'Finance'
'startDate' : '21-May-2009',
'certifications' : 'CPA'
}
both describe employees, but the first is tailored to someone in the software engineering department and the second is designed for someone in the finance department.
These and variations on these documents are simply added to the collection as needed. There is no need to specify that some documents will have 'pastProjectCodes' and some will have 'certifications' keys. There is also no need to indicate that some values will be strings while others will be arrays.
![]() Note
Note
The document database management system infers the information it needs from the structure of the documents in the collection, not from a separate structure specification.
Schemaless Means More Responsibility
Schemaless databases are something of a double-edged sword. On the one hand, the flexibility of working without a schema makes it easy to accommodate differences in document structures. On the other hand, the document database management cannot enforce rules based on structure. Because there is no way to indicate that a key-value pair should always exist in a document, the document database management system will not check for it.
If the database management system does not enforce rules about data, what will? The answer is your application code.
![]() Tip
Tip
An exception to this rule is the use of unique identifiers. If you specify a document without a unique identifier, the document database will probably add one for you. Check your document database’s documentation for details.
Some of your application code should be dedicated to verifying rules about the structure of data. If you always require a name in an employee document, then your code that adds employees should check for that when new employees are added. This is a simple case of a data validation rule, but not all are so simple.
Over time, the keys and values you track in documents in a collection may change. You may have started collecting information about employees’ certifications last year. Employees added since last year may all have a certification key. Employees whose documents have been updated may have a certification key and value as well. The remaining employee documents do not have a certification key.
In this situation, it is your code that uses and processes employee documents, not the code that adds employee documents, which must check for valid data structures or at least handle a case where an expected key does not exist (see Figure 7.4).
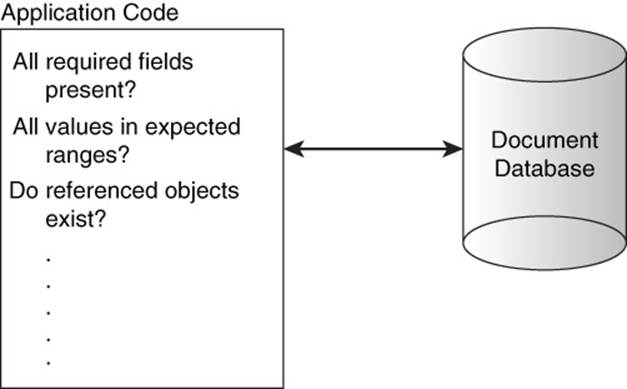
Figure 7.4 Data validation code and error-handling code is used throughout applications to compensate for the lack of automatic, schema-based validation checks.
Schemaless databases do not require formal structure specifications. Necessary information is inferred from documents within collections. This allows for more flexibility than in databases that require schemas, but there is less opportunity to automatically enforce data and document integrity rules.
Polymorphic Schema
Another term you might encounter about document databases is polymorphic schema. It might seem odd that a database can be without a schema (schemaless) while at the same time having many schemas (polymorphic schema). It is actually quite logical when you consider the distinction between a formal specification of a structure and the structure that is implied by the documents in a collection.
![]() Tip
Tip
Again, document databases are schemaless because you do not have to specify a formal definition of the structure of documents, keys, and values.
A document database is polymorphic because the documents that exist in collections can have many different forms (see Figure 7.5).
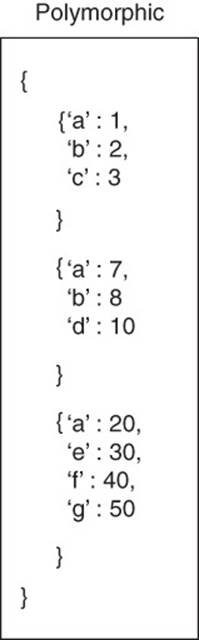
Figure 7.5 Schemaless means there is no formal definition of structure. Polymorphic schema means there are many document structures implied in the set of documents that occur in a collection.
Types of Partitions
Partitioning is a word that gets a lot of use in the NoSQL world—perhaps too much.
Chapter 2, “Variety of NoSQL Databases,” introduced the CAP theorem, which you might remember describes limits on consistency, availability, and partition tolerance. In this context, the word partition refers to partitioning or separating a network into separate parts that are unreachable from each other.
This is an important concept for all distributed databases, but it is not the focus of partitioning with respect to document databases. Instead, when people use the term partitioning when discussing document databases, they are probably referring to splitting a document database and distributing different parts of the database to different servers.
There are two types of database partitioning: vertical partitioning and horizontal partitioning.
It is important to distinguish the meaning of the term partitioning based on the context in which it is used (see Figure 7.6).
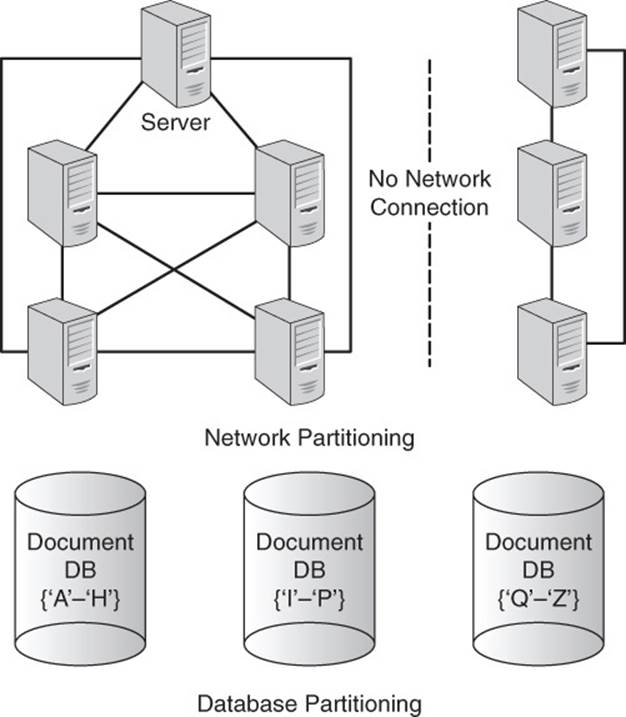
Figure 7.6 The term partitioning has multiple meanings that are distinguished by the context, such as in the context of networks versus in the context of databases.
Vertical Partitioning
Vertical partitioning is a technique for improving database performance by separating columns of a relational table into multiple separate tables (see Figure 7.7).
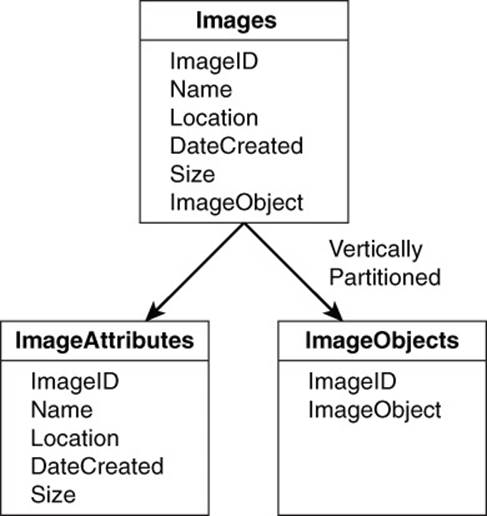
Figure 7.7 Vertical partitioning is typically used with relational tables because they have a fixed structure.
This technique is particularly useful when you have some columns that are frequently accessed and others that are not. Consider a table with images and attributes about those images, such as name, location, date image created, and so on. The table of images may be used in an application that allows users to look up images by characteristics.
Someone might want pictures from Paris, France, taken within the last three months. The database management system would probably use an index to find the rows of the table that meet the search criteria. If the application only lists the attributes in the resultset and waits for a user to pick a particular record before showing the image, then there is no reason to retrieve the image from the database along with the attributes.
If the image attributes and the image object were stored in the same table, reading the attributes could also force a reading of the image because of layout of data on the disk. By separating the image table into a table of image attributes and the image object, the database can more efficiently retrieve data for the application (see Figure 7.8).
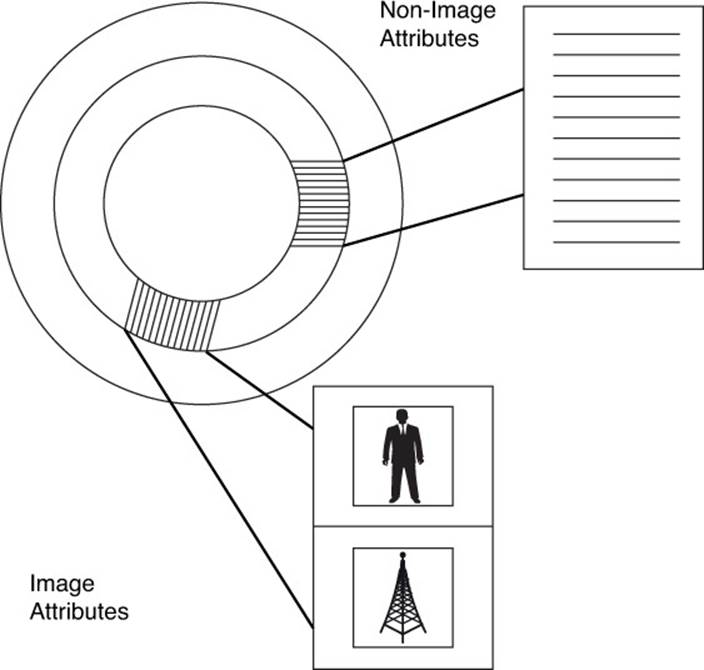
Figure 7.8 Separating columns into separate tables can improve the efficiency of reads because data that is not needed (for example, an image object) is not retrieved along with data that is likely needed (for example, image attributes).
Vertical partitioning is more frequently used with relational database management systems than with document management systems. There are methods for implementing vertical partitioning in nonrelational databases, but horizontal partitioning, or sharding, is more common.
![]() Note
Note
For an example of sharding, see J. Kaur, et al. “A New and Improved Vertical Partitioning Scheme for Non-Relational Databases Using Greedy Method,” International Journal of Advanced Research in Computer and Communication Engineering 2, no. 8 (August 2013).
Horizontal Partitioning or Sharding
Horizontal partitioning is the process of dividing a database by documents in a document database or by rows in a relational database. These parts of the database, known as shards, are stored on separate servers. (Horizontal partitioning of a document database is often referred to as sharding.) A single shard may be stored on multiple servers when a database is configured to replicate data. If data is replicated or not, a server within a document database cluster will have only one shard per server (see Figure 7.9).
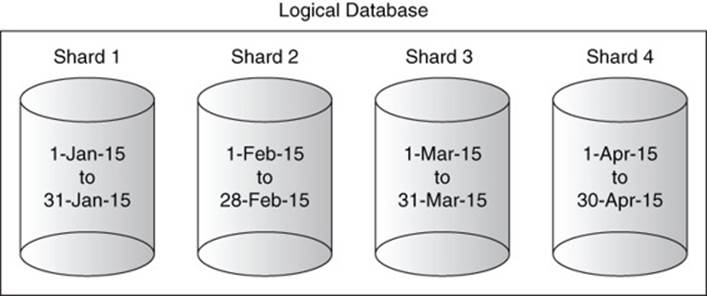
Figure 7.9 Horizontal sharding splits a database by document or row and distributes sections of the database, known as shards, to different servers. When a cluster implements replication, a single shard will be available on multiple servers.
Sharding offers a number of advantages when implementing large document databases. A large number of users or other heavy loads on a single server can tax the available CPU, memory, and bandwidth. One way to address this is to deploy a larger server with more CPU cores, more memory, and more bandwidth.
This solution, referred to as vertical scaling, can require significantly more money and time than sharding. Additional servers can be added to a cluster as demand for a document database grows. Existing servers are not replaced but continue to be used.
To implement sharding, database designers have to select a shard key and a partitioning method. These topics are discussed in the next sections.
Separating Data with Shard Keys
A shard key is one or more keys or fields that exist in all documents in a collection that is used to separate documents. A shard key could be virtually any atomic field in a document:
• Unique document ID
• Name
• Date, such as creation date
• Category or type
• Geographical region
![]() Note
Note
In spite of the discussion that document databases are schemaless, some elements of document databases parallel the schema of relational databases. The use of indexes is one such parallel. Indexes are part of the physical data model of a relational database, which means there is a data structure in the database that implements the index. Indexes are part of the schema of relational databases. Schemaless databases, such as document databases, can have schemalike objects such as indexes as well. Indexes help improve the speed of read operations and are useful when implementing sharding. Because all documents in a collection need to be placed into a shard, it is important for all documents to have the shard key.
The shard key specifies the values to use when grouping documents into different shards. The partitioning algorithm uses the shard key as input and determines the appropriate shard for that key (see Figure 7.10).
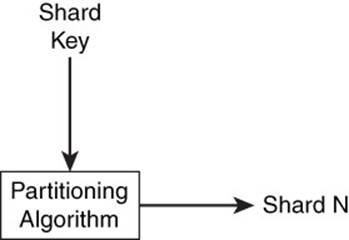
Figure 7.10 Shard keys are input to the partitioning algorithm that outputs a shard.
Distributing Data with a Partitioning Algorithm
There are a number of different ways to horizontally partition data, including
• Range
• Hash
• List
A range partition is useful when you have an ordered set of values for shard keys, such as dates and numbers. For example, if all documents in a collection had a creation date field, it could be used to partition documents into monthly shards. Documents created between January 1, 2015, and January 31, 2015, would go into one shard, whereas documents created between February 1, 2015, and February 28, 2015, would go into another.
![]() Note
Note
Business intelligence and other analytic systems that produce time-based reports—for example, a report comparing this month’s sales with last month’s sales—often use time-based range partitioning.
A hash partition uses a hash function to determine where to place a document. Hash functions are designed to generate values evenly across the range of values of the hash function. If, for example, you have an eight-server cluster, and your hash function generated values between 1 and 8, you should have roughly equal numbers of documents placed on all eight servers.
List-based partitioning uses a set of values to determine where to place data. You can imagine a product database with several types, including electronics, appliances, household goods, books, and clothes. These product types could be used as a shard key to allocate documents across five different servers.
If you needed even more partitions, you could combine product types with some other field, such as sales region, which could have values such as northeast, southeast, midwest, northwest, and southwest. Each of the five product types could be used with each of the five sales regions to create 25 possible shards, including
• Electronic—northeast
• Electronics—southeast
• Electronics—midwest
• Electronics—southwest
• Electronics—northwest
• Appliances—northeast
• Appliances—southeast
• Appliances—midwest
• And so forth...
Sharding is a fundamental process that enables many document databases to scale to meet demands of applications with a large number of users or other heavy loads. Vertical partitioning is possible with document databases. Horizontal partitioning, or sharding, is widely used.
Developers using document databases can choose keys to use for sharding. However, the developers of document database management systems are the ones who choose the sharding algorithms provided in the database.
The final section of this chapter introduces a few terms that do not fit well into any of the previous sections, but are important to understand before moving on to the document database modeling discussion in Chapter 8, “Designing for Document Databases.”
Data Modeling and Query Processing
Document databases are flexible. They can accommodate a wide range of document types and variations within document collections. If you were to sit down right now and start designing a document database, you would probably start with a list of queries you would like to run against your database. (At least that is one good way to start.) If you were designing a relational database, you would probably start by thinking about the entities you have to model and their relationship to each other.
After you have a basic understanding of the entities and their relations, you would probably engage in an exercise known as normalization. If you experience performance problems with your database, you might engage in a process known as denormalization. This process would be guided, to some degree, about what you learn about poorly performing queries by reviewing the output of the query processor.
You should be familiar with normalization and denormalization because you will likely encounter these terms when modeling document databases. The processes are less formal with document databases than relational databases so the explanations here will be much simpler than you would find in a book on relational databases. Document databases also implement query processors to attempt to find the optimal sequence of steps to retrieve data specified by a query.
Normalization
Database normalization is the process of organizing data into tables in such a way as to reduce the potential for data anomalies. An anomaly is an inconsistency in the data. For example, consider if your database had a table like the one shown in Table 7.1. A user queries the database for the address of a customer named Janice Washington. What address(es) should be returned?

Table 7.1 User Address Queries
The query could return 873 Morton Dr, Houston, TX; 187 River St, Seattle, WA; or both. It is possible that Janice Washington resides at both addresses, but it is also possible that one is a current address and one is a prior address. There is no indication in Table 7.1.
Normalization reduces the amount of redundant data in the database. Rather than repeat customer names and addresses with each order, those attributes would be placed in their own tables. Additional attributes could be associated with both customers and addresses. In particular, the address table could have an active address indicator to identify which of multiple addresses are current.
There are several rules for normalizing databases. Databases are said to be in different normal form depending on how many of the normalization rules are followed. It is common for data modelers to design to something called Third Normal Form, which means the first three rules of normalization are followed.1
1. For a basic introduction to normalization, see William Kent “A Simple Guide to Five Normal Forms in Relational Database Theory.” September, 1982. http://www.bkent.net/Doc/simple5.htm
Normalization is sometimes used to describe the way you design documents. When designers use multiple collections to store related data, it is considered normalized.
Normalized documents imply that you will have references to other documents so you can look up additional information. For example, a server log document might have a field with the identifier of the server that generates log event data. A collection of server documents would have additional information about each server so it does not have to be repeated in each log event document (see Figure 7.11).
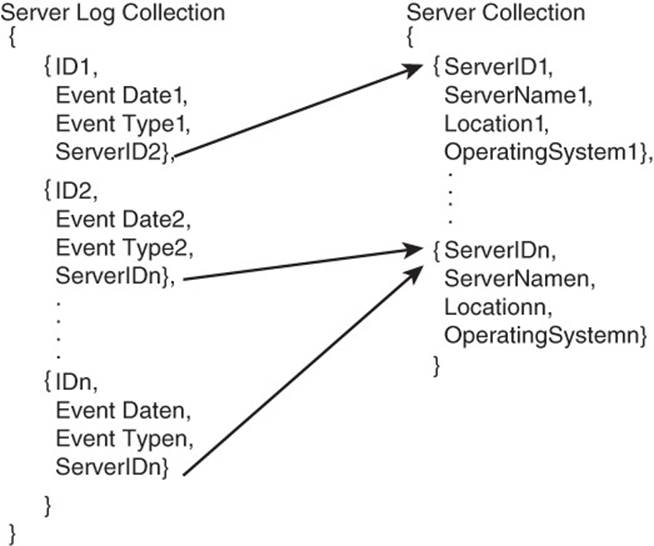
Figure 7.11 Normalized documents reduce redundant data by referencing a single copy of data rather than repeating it in each document.
Denormalization
Normalization helps avoid data anomalies, but it can cause performance problems. This is especially true if you have to look up data in two or more large tables. This process is called joining, and it is a basic operation in relational databases. A great deal of effort has gone into developing efficient ways to join data. Database administrators and data modelers can spend substantial amounts of time trying to improve the performance of join operations. It does not always lead to improvement.
Designing databases entails trade-offs. You could design a highly normalized database with no redundant data but suffer poor performance. When that happens, many designers turn to denormalization.
As the name implies, denormalization undoes normalization—specifically, it introduces redundant data. You might wonder, why introduce redundant data? It can cause data anomalies like that in Table 7.1. It obviously requires more storage to keep redundant copies of data. The reason to risk data anomalies and use additional storage is that denormalization can significantly improve performance.
When data is denormalized, there is no need to read data from multiple tables and perform joins on the data from the multiple collections. Instead, data is retrieved from a single collection or document. This can be much faster than retrieving from multiple collections, especially when indexes are available.
Query Processor
Getting data from a document database is more complicated than getting it from key-value databases. Remember, if you have a key, you can retrieve an associated value from a key-value database.
Document databases offer more options for retrieving data. For example, you could retrieve documents created before a particular date, or documents that are a specific type, documents that contain the string “long distance running” in a product description, or some combination of all of these.
The query processor is an important part of a database management system. It takes as input queries and data about the documents and collections in the database and produces a sequence of operations that retrieve the selected data.
Key-value databases do not need query processors; they function by looking up values by keys. There is no need to analyze logical statements such as the following:
(createDate > '1-Jan-2015') AND (productType =
'electronics')
When there can be multiple conditions on selecting documents, the query processor must make decisions, such as which criteria it should apply first. Should it find all documents with a creation date greater than January 1, 2015, or should it retrieve all documents about electronics products?
If there are fewer documents with a creation date after January 1, 2015, than there are documents with an electronics type, then it would make sense to retrieve documents based on creation date because it will return fewer documents than the other criteria. This means the second criterion is applied to a smaller number of documents.
This is a simple example of the kinds of options a query processor evaluates as it builds its plan to retrieve data.
Summary
Document databases have some terminology specific to their type of NoSQL database, but they also share vocabulary with other NoSQL databases as well as relational databases. Documents parallel rows in relational tables, whereas collections are comparable to tables in relational tables. Partitioning, especially sharding, is used in document databases to split large databases over multiple servers to improve performance. Normalization, denormalization, and query processors also play crucial roles in the overall performance of document databases.
Chapter 8 delves into design issues particular to document databases.
Review Questions
1. Describe how documents are analogous to rows in relational databases.
2. Describe how collections are analogous to tables in relational databases.
3. Define a schema.
4. Why are document databases considered schemaless?
5. Why are document databases considered polymorphic?
6. How does vertical partitioning differ from horizontal partitioning, or sharding?
7. What is a shard key?
8. What is the purpose of the partitioning algorithm in sharding?
9. What is normalization?
10. Why would you want to denormalize collections in a document database?
References
Brewer, Eric. “CAP Twelve Years Later: How the ‘Rules’ Have Changed.” Computer vol. 45, no. 2 (Feb 2012): 23–29.
Brewer, Eric A. “Towards Robust Distributed Systems.” PODC. vol. 7. 2000.
Chodorow, Kristina. 50 Tips and Tricks for MongoDB Developers. Sebastopol, CA: O’Reilly Media, Inc., 2011.
Chodorow, Kristina. MongoDB: The Definitive Guide. Sebastopol, CA: O’Reilly Media, Inc., 2013.
Copeland, Rick. MongoDB Applied Design Patterns. Sebastopol, CA: O’Reilly Media, Inc., 2013.
Couchbase. Couchbase Documentation: http://docs.couchbase.com/.
Han, Jing, et al. “Survey on NoSQL Database.” Pervasive computing and applications (ICPCA), 2011 6th International Conference on IEEE, 2011.
MongoDB. MongoDB 2.6 Manual: http://docs.mongodb.org/manual/.
O’Higgins, Niall. MongoDB and Python: Patterns and Processes for the Popular Document-Oriented Database. Sebastopol, CA: O’Reilly Media, Inc., 2011.