Oracle Database 12c DBA Handbook (2015)
PART
III
High Availability
CHAPTER
12
Real Application Clusters
Chapter 4 presented an overview of Automatic Storage Management (ASM) and Oracle Managed Files (OMF) and how they can ease administration, enhance performance, and improve availability. You can add one or more disk volumes to a rapidly growing database without bringing down the instance.
Chapter 6 discussed bigfile tablespaces and how they not only allow the total size of the database to be much larger than in previous versions of Oracle, but also ease administration by moving the maintenance point from the datafile to the tablespace. Chapter 17 will focus on Oracle Net, providing you with the basics for ensuring that your clients can reach the database servers in an efficient and prompt manner. Chapter 16 will expand our coverage of bigfile tablespaces in addition to presenting other tools to make large database management easier, such as partitioned table support, transportable tablespaces, and Oracle Data Pump introduced in Oracle Database 10g.
As your databases get larger, and the number of users increases, the need for availability becomes even more critical. Real Application Clusters (RAC) will tie together OMF, bigfile tablespaces, a robust network infrastructure, and ASM into key elements of the RAC architecture. In this chapter, we will revisit many of these database features, but with an emphasis on how they can be leveraged in a RAC environment.
This chapter focuses on some key RAC topics, including the differences between the hardware, software, and network configuration in a RAC environment compared to a single-server database environment. I’ll also touch upon how a single SPFILE controls the initialization parameters for one, many, or all instances in your RAC database. Finally, I’ll give some examples of how RAC can give you scalability and availability features not available in most single-database environments.
During the installation of a RAC, you can configure the Enterprise Manager agent and Enterprise Manager Cloud Control 12c to manage your cluster. Cloud Control 12c extends the functionality available to manage a single instance by providing a cluster-aware layer; you can manage both the Oracle instances and the underlying cluster configuration from a single web interface.
Subsequent chapters present other ways to ensure high database availability and recoverability: Chapter 15 will give a detailed look at Oracle Data Guard for near-real-time failover capabilities, and Chapter 19 will cover Oracle Streams for advanced replication. In Chapter 16, we’ll finish up our discussion on Oracle Flashback options started in Chapter 7 by examining how to perform Flashback Drop and Flashback Database as well as how to use LogMiner to undo individual transactions.
Overview of Real Application Clusters
A Real Application Cluster is highly available and scalable. The failure of one node in the cluster does not affect client sessions or the availability of the cluster itself until the last node in the cluster fails; the only impact a lost node has on the cluster is a slight degradation in response time, depending on the total number of nodes in the cluster.
A RAC database has a few disadvantages. Licensing costs are higher, because each node in the cluster has to have its own Oracle license plus the license for the RAC option. The close physical proximity of the nodes in the cluster due to the high-speed requirements of the cluster interconnect means that a natural disaster can take out the entire cluster; using a remote standby database can help alleviate some of these concerns. You will have to weigh the cost of high availability (or the lack thereof) compared to the increased cost and slight increase in maintenance of a RAC.

NOTE
A stretch cluster, or a cluster using RAC technology over a wide-area network (WAN), protects against the loss of an entire data center, but it increases the cost of the infrastructure, since the already-redundant storage systems must be duplicated across the sites and the network bandwidth must be high enough to keep up with synchronization tasks during peak transaction periods.
In the next few sections, I’ll cover some of the hardware and software requirements for a RAC database as well as detail the network configuration and disk storage requirements to build a successful cluster.
Hardware Configuration
A complete discussion of all possible RAC hardware configurations is beyond the scope of this book. You want to have at least two and preferably three nodes for a RAC, each with redundant power supplies, network cards, dual CPUs, and error-correcting memory; these are desirable characteristics for any type of server, not just an Oracle server! The higher the number of nodes configured in the cluster, the lower the performance hit you will take when one of the cluster’s nodes fails.
The shared disk subsystem should also have hardware redundancy built in—multiple power supplies, RAID-enabled disks (or just leverage an engineered system such as Oracle Exadata!), and so forth. You will balance the redundancy built into the shared disk with the types of disk groups you will create for the RAC. The higher redundancy built into the disk subsystem hardware can potentially reduce the amount of software redundancy you specify when you create the database’s disk groups.
Software Configuration
Although Oracle clustering solutions have been available since version 6, not until version 10g has there been a native clusterware solution that more tightly couples the database to the volume management solution. Cluster Ready Services (CRS) is the clustering solution that can be used on all major platforms instead of an OS vendor or third-party clusterware.
CRS is installed before the RDBMS and must be in its own home directory, referred to as the CRS_HOME. If you are only using a single instance in the near future but plan to cluster at a later date, it is useful to install CRS first so that the components of CRS that are needed for ASM and RAC are in the RDBMS directory structure. If you do not install CRS first, you will have to perform some extra steps later to remove the CRS-related process executables from the RDBMS home directory.
After CRS is installed, you install the database software in the home directory, referred to as the ORACLE_HOME. On some platforms, such as Microsoft Windows, this directory can be a directory common to all nodes, whereas other platforms, such as Linux, require OCFS version 2.x or later. Otherwise, each node will have its own copy of the binary executables.
Network Configuration
Each node in a RAC has a minimum of three IP addresses: one for the public network, one for the private network interconnect, and a virtual IP address to support faster failover in the event of a node failure. As a result, a minimum of two physical network cards are required to support RAC; additional network cards are used to provide redundancy on the public network and thus an alternate network path for incoming connections. For the private network, additional network cards can boost performance by providing more total bandwidth for interconnect traffic. Figure 12-1 shows a two-node RAC with one network card on each node for the private interconnect and one network card on each node to connect to the public network.
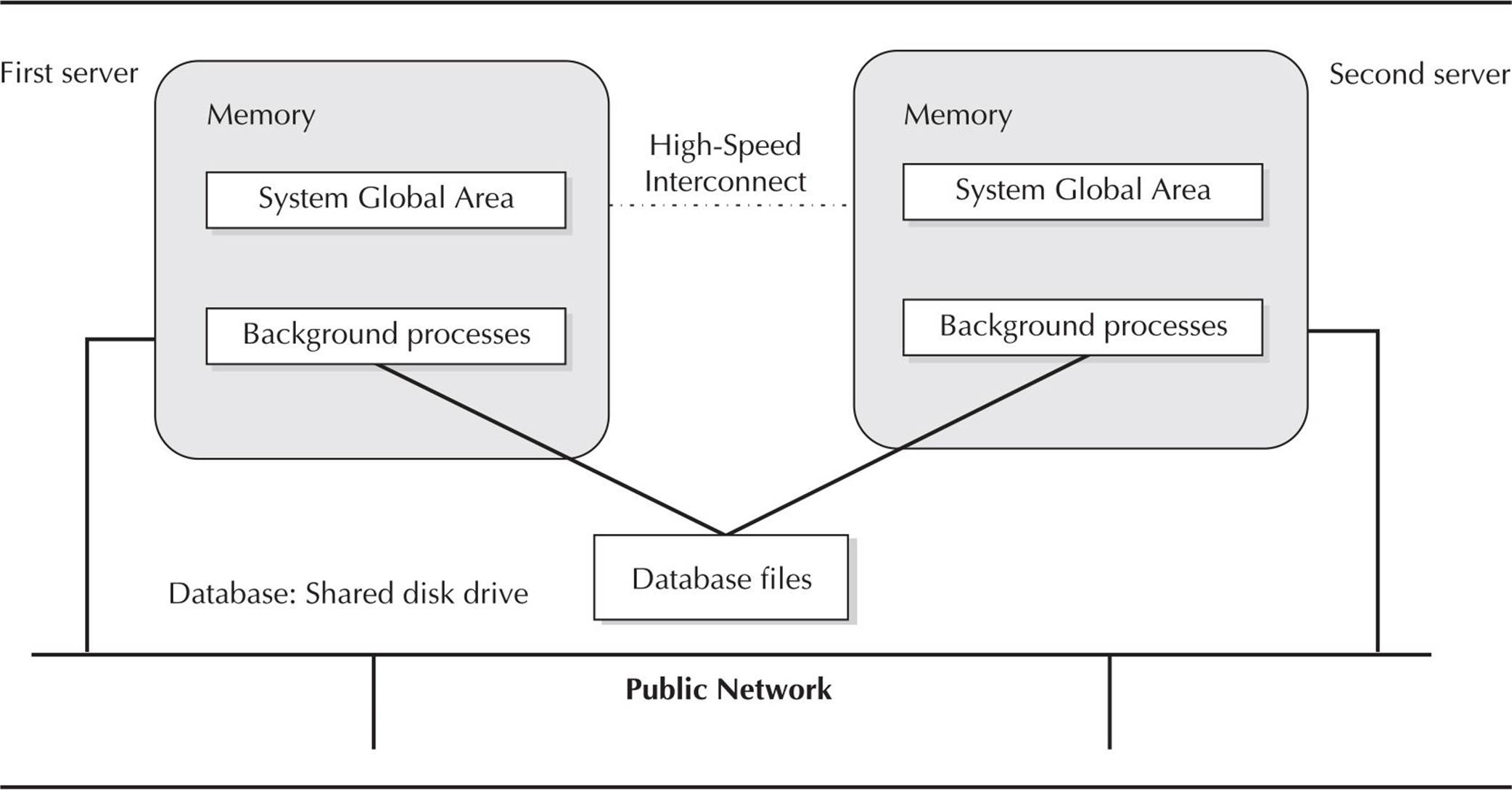
FIGURE 12-1. RAC network configuration
The public network is used for all routine connections to and from the server; the interconnect network, or private network, supports communication between the nodes in the cluster, such as node status information and the actual data blocks shared between the nodes. This interface should be as fast as possible, and no other types of communication between the nodes should occur on the private interface; otherwise, the performance of the RAC may suffer.
The virtual IP address is the address assigned to the Oracle listener process and supports rapid connect-time failover, which is able to switch the network traffic and Oracle connection to a different instance in the RAC much faster than a third-party, high-availability solution.
Disk Storage
The shared disk drive may or may not be a RAID device to support redundancy; more importantly, the disk controllers and connections to the shared storage should be multiplexed to ensure high availability. If the disks in the shared drive are not mirrored, you can use the mirroring capabilities of ASM to provide performance and availability benefits.
RAC Characteristics
A RAC instance is different in many ways from a standalone instance; in this section, I will review some of the initialization parameters that are specific to a RAC database. In addition, I’ll show you some of the data dictionary views and dynamic performance views that are either unique to a RAC or have columns that are only populated when the instance is part of a RAC.
Server Parameter File Characteristics
The server parameter file (SPFILE) typically resides on an ASM disk group and therefore is shared by each node in the cluster. Within the SPFILE, you can assign different values for given parameters on an instance-by-instance basis; in other words, the value for an initialization parameter can differ between instances. If an initialization parameter is the same for all nodes in the cluster, it is prefixed with “*.”; otherwise, it is prefixed with the node name.
In this example, the physical memory on the cluster server oc2 is temporarily reduced due to other applications that are currently running on the server (ideally, though, you have no other applications running on the server except for Oracle!). Therefore, to reduce the demands of the instance on the server, you will change the value of MEMORY_TARGET for the instance rac2:
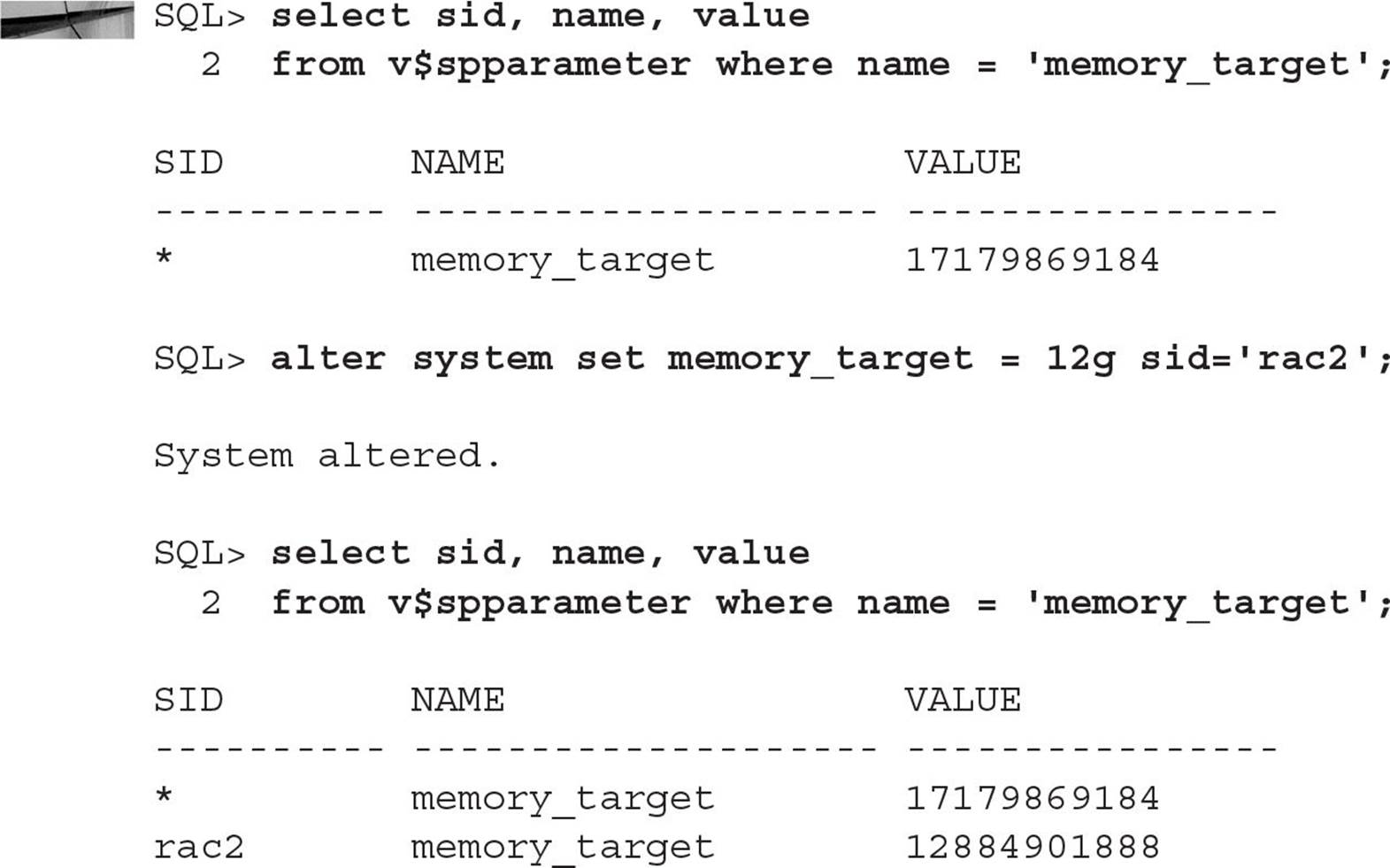
Depending on your hardware and the amount of memory you’re allocating or deallocating, the memory resize operation might take a few seconds or possibly a few minutes depending on the current system load. Once the memory issue has been resolved, you can restore the size of the SGA on the rac2 instance as follows:

Alternatively, and usually more simply, you want to reset the value to the same value for the rest of the cluster; in this situation, you can use the RESET option of the ALTER SYSTEM command:


RAC-Related Initialization Parameters
A number of initialization parameters are used only in a RAC environment. Although these initialization parameters exist in any instance, in a single-instance environment they are either null or have a value of 1 (for example, INSTANCE_NUMBER). Table 12-1 provides an overview of some of the key RAC-related initialization parameters.

TABLE 12-1. RAC-Related Initialization Parameters
Dynamic Performance Views
In a single-instance environment, all dynamic performance views that begin with V$ have a corresponding view beginning with GV$, with the additional column INST_ID always set to 1. For a RAC environment with two nodes, the GV$ views have twice as many rows as the corresponding V$ views; for a three-node RAC, there are three times as many rows, and so forth. In the sections that follow, we’ll review some of the V$ dynamic performance views that show the same contents regardless of the node you are connected to, along with some of the GV$ views that can show you the contents of the V$ views on each node without connecting to each node explicitly.
Common Database File Views
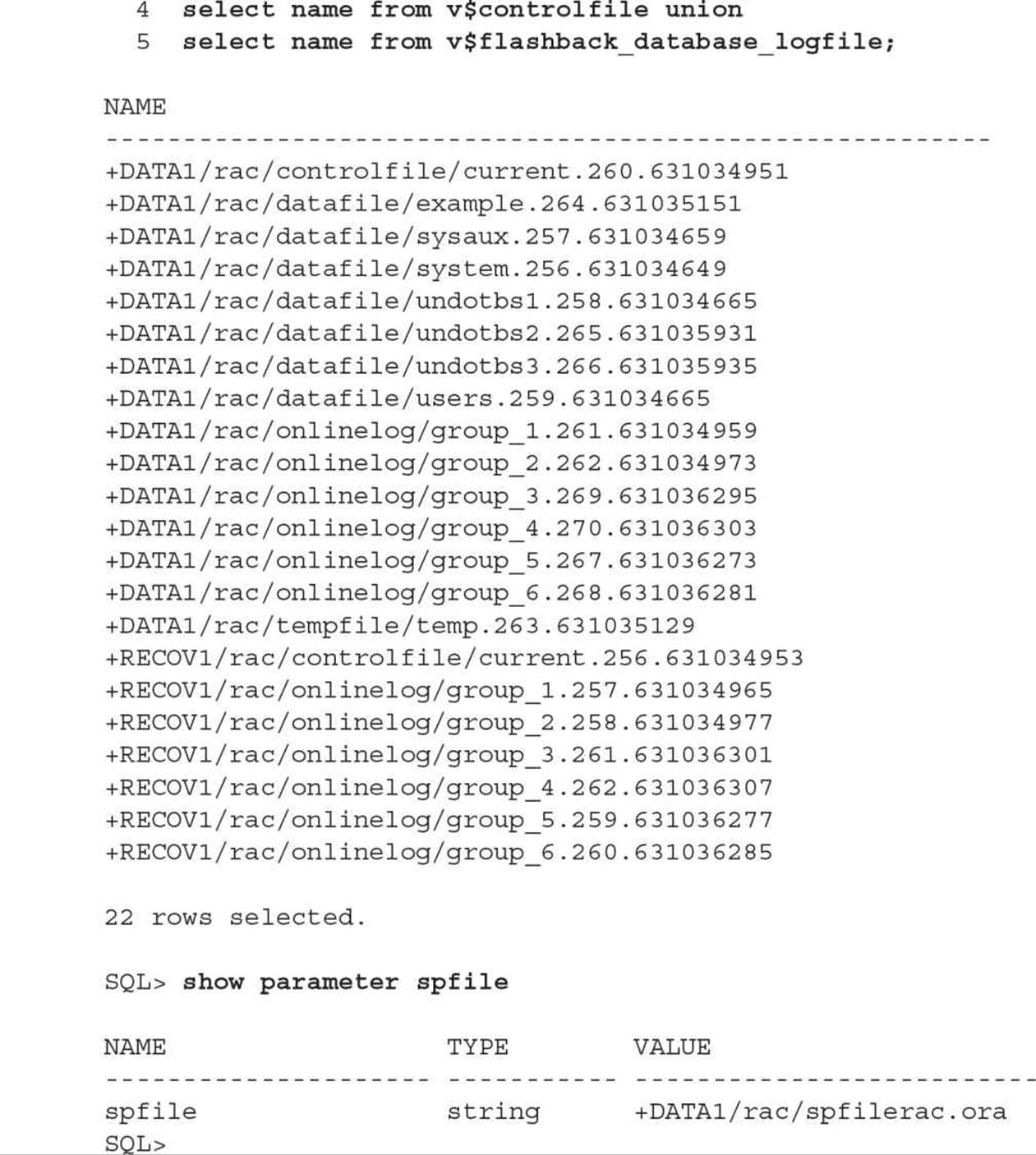
Some dynamic performance views are the same whether you’re in a RAC environment or a single-instance environment; the ASM configuration is a perfect example of this. In this query run on any database instance in the cluster, you want to verify that all your database files are stored in one of the two ASM disk groups, +DATA1 or +RECOV1:

Cluster-Aware Dynamic Performance Views
The GV$ views make it easy to view each instance’s characteristics in a single SELECT statement, while at the same time filtering out nodes that you do not want to see; these views also make it easier to aggregate totals from some or all of the nodes in the cluster, as in this example:

From this query, you can see the number of sessions per instance and the total number of instances for the cluster using the view GV$SESSION.
RAC Maintenance
Most of the maintenance operations you perform on a single-node instance apply directly to a multiple-node RAC environment. In this section, I will review the basics for maintaining a RAC—including how to start up a RAC and how redo logs and undo tablespaces work—and then work through an example of an instance failure scenario using Transparent Application Failover (TAF).
Starting Up a RAC
Starting up a RAC is not much different from starting up a standalone instance; the nodes in a RAC can start up in any order, and they can be shut down and started up at any time with minimal impact to the rest of the cluster. During database startup, first the ASM instance starts and mounts the shared disk groups; next, the RDBMS instance starts and joins the cluster.
On Linux, the file /etc/oratab can be modified to auto-start the instances (both the ASM instance and the RDBMS instance) on each cluster:

Redo Logs in a RAC Environment
As with a single-node instance, online redo logs are used for instance recovery in a RAC environment; each instance in a RAC environment has its own set of online redo log files that are used to roll forward all information in the redo logs and then roll back any uncommitted transactions initiated on that node using the undo tablespace.
Even before the failed instance has restarted, one of the surviving instances detects the instance failure and uses the online redo log files to ensure that no committed transactions are lost; if this process completes before the failed instance restarts, the restarted instance does not need instance recovery. Even if more than one instance fails, all that is required for instance recovery is one remaining node. If all instances in a RAC fail, the first instance that starts up will perform instance recovery for the database using the online redo log files from all instances in the cluster.
If media recovery is required and the entire database must be recovered, all instances except for one must be shut down and media recovery is performed from a single instance. If you are recovering noncritical database files, all nodes may be up as long as the tablespaces containing the files to be recovered are marked as OFFLINE.
Undo Tablespaces in a RAC Environment
As with redo logs, each instance in a RAC environment must have its own undo tablespace on a shared drive or disk group. This undo tablespace is used for rolling back transactions during normal transactional operations or during instance recovery. In addition, the undo tablespace is used by other nodes in the cluster to support read consistency for transactions that are reading rows from a table on node rac2 while a data-entry process on node rac1 makes updates to the same table and has not yet committed the transaction. The user on rac2 needs to see the before-image data stored in rac1’s undo tablespace. This is why all undo tablespaces must be visible to all nodes in the cluster.
Failover Scenarios and TAF
If you have configured your client correctly and the instance to which the client is connected to fails, the client connection is rapidly switched to another instance in the cluster and processing can continue with only a slight delay in response time.
Here is the tnsnames.ora entry for the service racsvc:

This will show you what happens and how you will know if a session is connected to the cluster and its instance fails. First, you connect to the cluster via racsvc and find out the node and instance that you are connected to:

You are using the columns from V$INSTANCE to give you the instance name and host name that you are connected to and then joining this to V$SESSION and retrieving the columns related to failover, which are only populated in a RAC environment. In this case, the session has not yet failed over, and the failover type is BASIC, as specified when the service was created.
Next, you will shut down instance rac1 from another session while you are still connected to the first session:

Back at your user session, you rerun the query to find out what node you are connected to:

If you were running a query at the time the instance was shut down, your query would pause for a brief moment and then continue as if nothing happened. If your result set is quite large and you already retrieved most of the result set, the pause will be slightly longer since the first part of the result set must be re-queried and discarded.
Tuning a RAC Node
The first step in tuning a RAC is to tune the instance. If an individual instance is not tuned correctly, the performance of the entire RAC will not be optimal. You can use the Automatic Workload Repository (AWR) to tune an instance as if it was not part of a cluster.
Using Cloud Control 12c, you can further leverage the statistics from the AWR to produce reports on a RAC-wide basis. In Figure 12-2, you can see how Cloud Control 12c makes it easy to analyze the performance of the shared global cache as well as the cache performance on an instance-by-instance basis, even comparing the cluster-wide performance for a given day to a similar time period in the past.
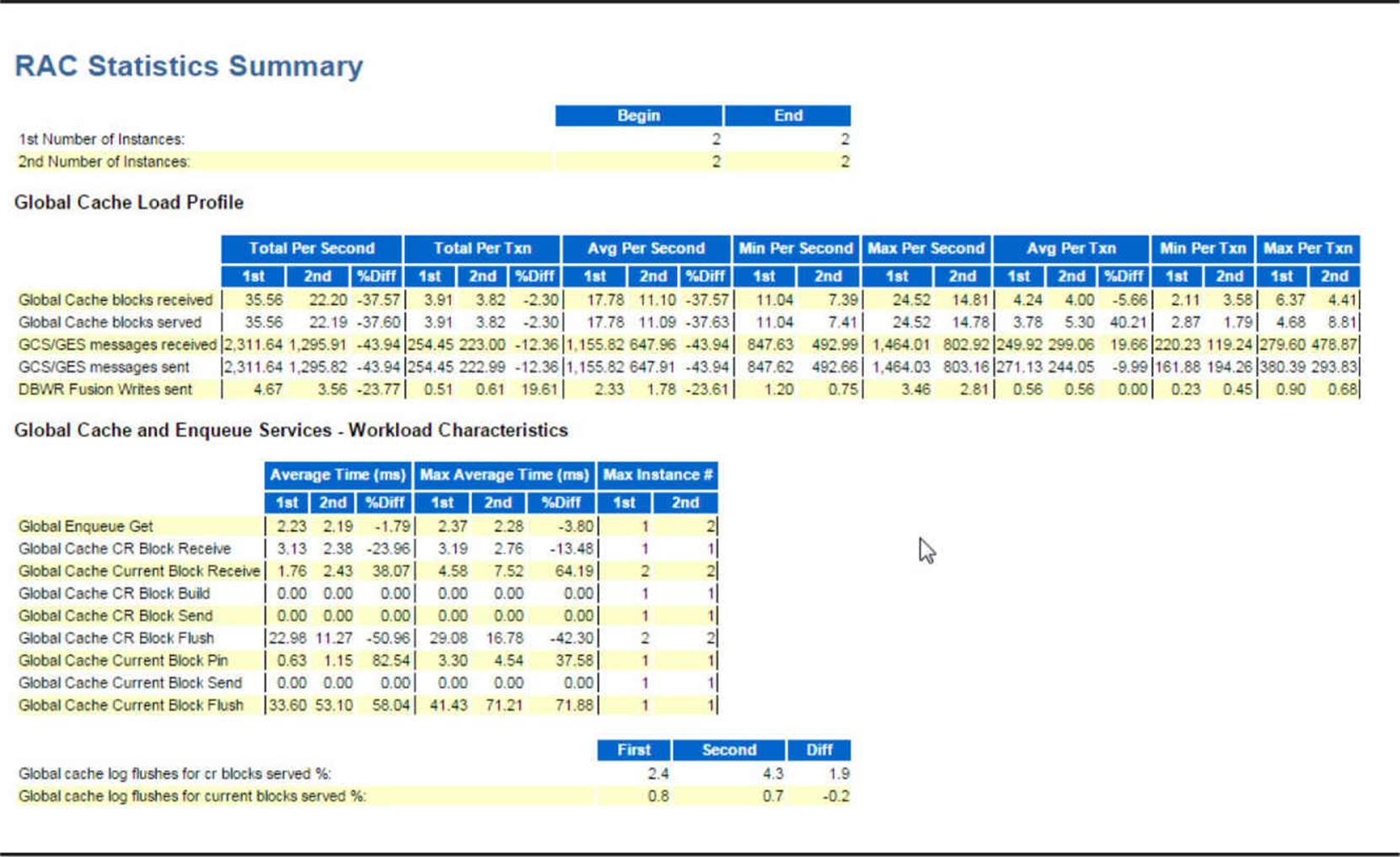
FIGURE 12-2. Cloud Control 12c RAC cache statistics
Summary
In this chapter I provided a brief but informative summary of Oracle’s primary availability and scalability solution: Real Application Clusters. Managing the components of RAC is much the same as managing a single-instance database: you use many of the same tools to manage users, tablespaces, and other server resources. Using RAC makes it easier for the users too: in virtually all cases, a failure of any node in the cluster is completely transparent to any user who is running a query or DML statement. The processing for that SQL statement continues to completion without the user having to resubmit the statement.


All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.