HTML5, JavaScript and jQuery (Programmer to Programmer) - 2015
Part IV HTML5 APIs
Lesson 30 Web Storage
When the World Wide Web was first envisioned, it was intended as a repository for static documents, primarily academic papers. The key distinguishing feature of the World Wide Web was hyperlinks, which allowed one document to provide a link to another document, and therefore allowed convenient navigation from one piece of information to another.
It wasn't long before web pages started providing more advanced features, such as online shopping. This required web pages to dynamically respond to user interaction. As you have seen, this was facilitated by technologies such as the DOM API, which allows a web page to be modified after it was loaded.
HTML and JavaScript could only take you so far, however. It still was not possible to create web pages or web applications that exhibited the features typically found in native desktop applications. For instance, web pages lacked the following capabilities:
· The ability to interact with the file system beyond the simple file input type.
· The ability to store large amounts of data or configuration information inside the browser (on the client).
· The ability to function without a network connection. Even if a page is cached inside a browser, it typically is not usable without a network connection.
· The ability to perform intensive processing on a background thread without impacting the user experience. Because all JavaScript processing occurs on a single thread, any intensive processing will cause the web page to “lock up.”
· The ability to request additional data from a server after a page had loaded without performing a refresh of the entire web page.
You can think of these features as the services accessible to a software application. For a traditional desktop application, the operating system provides these services. Web pages cannot interact directly with the operating system; they can only interact with the browser. Therefore, unless the browser provided these services, web pages would always be constrained from achieving a higher level of sophistication.
Despite the historic limitations of HTML and JavaScript, there has been a strong push toward browser-based web applications as opposed to native applications. Browser-based web applications are enormously convenient because the same web application can be accessed on any device, from any location, at any time. This push has only intensified with the move toward cloud computing, as more and more data is pushed into globally available cloud computers.
Browser-based web applications also have the advantage that they do not need to be installed, and they can be automatically updated without any action from the user.
In order to allow web applications to achieve the same level of sophistication as native applications, the HTML5 specification provides a set of JavaScript APIs for implementing all the features just listed, along with several others. This section will cover these APIs in detail, starting with client-side storage.
Client-Side Storage
The HTTP protocol used to retrieve resources from a web server was designed as a stateless protocol. It begins with the browser establishing a network connection to the web server and requesting a resource. The web server finds the resource and returns it as a response to the browser. Once the response is received, the connection between the two is closed, and no link is retained that the two ever communicated.
Note
This is a slightly simplified view of HTTP. Because establishing connections can be time consuming, the HTTP protocol was extended early on to support a keep-alive option. This meant that multiple requests could be made on the same connection. This feature cannot be relied on in order to continue a conversation with the web server, however, because it is up to the web server to decide how long to leave the connection open for.
This model clearly does not work well for a number of scenarios. If you consider a shopping website, the server will need to retain a shopping cart for the user as he progresses from page to page: Clearly this relies on the web server remembering each particular browser, and the history of their actions—for instance, the products they have purchased. I will refer to all the actions performed by the same browser as a session.
In order to support this, a technology was introduced called cookies. A cookie is simply a key/value pair that can be sent by the web server to the browser on an HTTP response. The browser will then store the information in this cookie for a configurable period of time (usually as small files on the file system). Every time the browser sends a request to the same web server in the future, it will include all the cookies that have been sent to it.
Although cookies can be used to store any textual information, typically they are used to store a unique session ID for each browser. The web server generates this session ID whenever it receives a request from a browser it has not seen before (where there is no cookie in the HTTP request), which the browser then stores, and provides automatically on future requests. The web server can then store information against this session ID, and provide that information back to the browser when required, such as when the user decides to check out.
Although cookies are great for storing small amounts of data, they do come with a number of limitations. The principle limitation is that browsers are only required to allow 20 cookies per domain name, and each cookie is limited to 4096 bytes of data. If you work through the sums, a domain may only be able to store 80 kilobytes inside the browser, which, by modern standards, is not a lot of data.
There are, however, very good reasons why a web application may want to store larger amounts of data on the client, the two main ones being:
· Performance: If the data is stored on the client, it is much faster to process and display in the browser than if it needs to be retrieved from the web server. Despite the increase in network speeds, accessing data locally is still many orders of magnitude faster.
· Availability: If the data is stored on the client, it can be accessed even when the browser is not connected to a network.
HTML5 adds not one, but three distinct APIs for storing data inside the browser:
· Web storage: This is the subject of this lesson. This is the oldest storage API and has excellent support across all browsers.
· Web SQL: This standard proposes a relational database–based API, but is not widely supported, and is unlikely to see support across all browsers in the future. Although this API has a lot to recommend it, it will be ignored in this book, because without universal browser support, the API is unlikely to find widespread adoption.
· IndexedDB: This is the subject of the next lesson. This API is considerably more complicated than the web storage API, but does offer a number of important additional features.
Web Storage API
The web storage API is by far the simplest of the three data storage APIs specified in HTML5, and, as mentioned, it also has the best support across all major browser vendors.
The web storage API does come with certain limitations, however:
· It can only be used for storing textual data (JavaScript Strings). It is not possible to store other types of data such as JavaScript objects.
· Browsers may restrict a domain to 5MB of storage. Although this is a huge amount of data in comparison to cookies, it may not be feasible for all scenarios.
Note
The 5MB limit is an even bigger constraint than it may sound. This is due to the fact that each character in a JavaScript string uses 2 bytes of storage. JavaScript uses a character encoding called UTF-16, which allows any Unicode character to be represented in 2 or more bytes. Other encodings such as UTF-8 are now far more common, and only use 1 byte for the most common Unicode characters (provided you are using a Western alphabet).
The web storage API is remarkably simple to use; it relies on simple key/value pairs. In order to see it in action, open the contacts.html web page using the relevant address for your web server (for example, localhost:8080/contacts.html), and enter the following code in the JavaScript console:
> localStorage.setItem("test", "this is a test");
In this case, test is the key, and this is a test is the value. As you can see, the localStorage object provided by the browser exposes the web storage API.
Note
The browser also exposes the web storage API via a companion object called sessionStorage. Any data stored via localStorage is retained indefinitely (or until the user deletes it), whereas data stored via sessionStorage is automatically cleared when the browser is closed. You should always be conscious of the fact that data stored via the web storage API is not encrypted; therefore, it is not appropriate for sensitive data.
If you now open the Resources tab of the developer tools, and expand the Local Storage option, you will see that the key/value pair has been captured (see Figure 30.1).
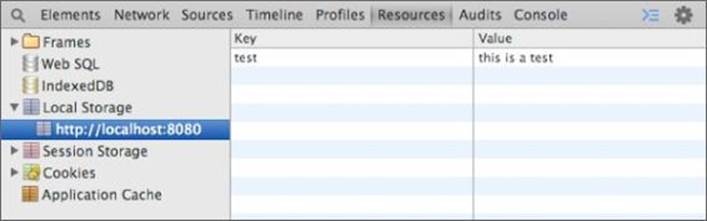
Figure 30.1
Notice that this data is associated with the origin localhost:8080. Only pages served from this origin will have access to this data.
The companion method for setItem is getItem. This allows an item to be retrieved based on a key. For example:
> localStorage.getItem("test");
"this is a test"
This method will always return a JavaScript string, or undefined if there is no value stored against the key specified. Two other useful methods are included in the API. The removeItem method can be used to remove a value based on a key. For example:
> localStorage.removeItem("test");
Finally, the clear method can be used to remove all data stored by the origin:
> localStorage.clear();
These simple methods are all that is required to use web storage.
Storing Structured Data
As mentioned earlier, the web storage API can only be used for storing textual data; it cannot be used for storing structured data such as JavaScript objects. This presents a problem for your CRM web application because you would ideally like to store the JavaScript contact objects in web storage so that they are retained when the page is refreshed or the browser is closed.
Note
The web storage API will not actually complain if you specify a JavaScript object as the value for a key; it will simply convert the object into a string by invoking its toString method. This will usually mean that the value persisted is [object Object]because this is the default value of toString.
Fortunately, there is a simple solution to this: You can use the JSON.stringify function to convert JavaScript objects to JSON encoded strings, and then store these strings in web storage. When you need to retrieve data from web storage, you can convert it back into JavaScript objects with JSON.parse.
For instance, if you want to save a contact object, you can create the following function in contacts.js:
function store(contact) {
var c = JSON.stringify(contact);
localStorage.setItem('contacts', c);
}
This function adds a single contact to web storage.
Because you need to store multiple contacts, you may decide to create an array for holding the objects. Additionally, you need to retrieve the existing array from web storage before adding a new contact. The following function therefore provides the necessary functionality for storing multiple contacts:
function store(contact) {
var contactsStored = localStorage.getItem('contacts');
var contacts = [];
if (contactsStored) {
contacts = JSON.parse(contactsStored);
}
contacts.push(contact);
localStorage.setItem('contacts', JSON.stringify(contacts));
}
The first line of this function extracts the existing array from web storage. If it exists, it converts it from a string into a JavaScript array. If no contacts have been saved, you simply create an empty array to hold contacts. You then push the new contact onto the array, and persist the array to web storage.
Note
It is also possible to extract items from localStorage using traditional dot notation—for instance, localStorage.contacts. In order to use this approach, item keys must conform to the JavaScript property name standards.
The setItem method will overwrite any existing entry for the same key; thus, every time a new contact is saved, the array stored in web storage will be entirely replaced.
The store function should be added to the contactsScreen function, immediately after the following line:
var initialized = false;
The save method should then be changed to invoke this function:
save: function(evt) {
if ($(evt.target).parents('form')[0].checkValidity()) {
var fragment = $(screen).find('#contactRow')[0].content.cloneNode(true);
var row = $('<tr>').append(fragment);
var contact = this.serializeForm();
store(contact);
row = bind(row, contact);
$(row).find('time').setTime();
$(screen).find('table tbody').append(row);
$(screen).find('form :input[name]').val('');
$(screen).find('#contactDetails').toggle( "blind" );
this.updateTableCount();
}
}
You now need to add functionality to load existing contacts when the contacts.html web page loads. This can be achieved by adding the following method to contacts.js (immediately after the save method):
loadContacts: function() {
var contactsStored = localStorage.getItem('contacts');
if (contactsStored) {
contacts = JSON.parse(contactsStored);
$.each(contacts, function(i, v) {
var fragment = $(screen).find('#contactRow')[0].content.cloneNode(true);
var row = $('<tr>').append(fragment);
row = bind(row, v);
$(row).find('time').setTime();
$(screen).find('table tbody').append(row);
});
}
},
This function is relatively straightforward; it simply extracts the contacts array from web storage, iterates through the items, and adds each one to the table onscreen using code from earlier in the book.
This function should then be invoked at the end of the init method with the following line of code:
this.loadContacts();
If you now save a contact and re-open the contacts.html web page, you should see any contacts that are retained.
Try It
In this Try It, you will enhance the functionality added in this lesson by providing delete functionality. Currently, the delete button removes the relevant row from the table, but it does not remove the record from web storage: This means that once the page is refreshed, the contact will immediately come back.
Lesson Requirements
To complete this lesson, you will need a text editor for writing code, and Chrome for running the completed web page. It is also expected that you have completed the steps in the body of the lesson before starting this Try It.
Step-by-Step
1. Open the contacts.js file in your text editor. You will make a change to the saving process: When you save a new contact, you will assign it a unique ID. This will allow you to uniquely identify the contact that is being deleted. The ID you will create will be based on the current time in milliseconds. In order to achieve this, add a new line after this line:
var contact = this.serializeForm();
This line should set an ID property on the contact to have a value derived from the $.now() function call. This is another jQuery helper, and returns the current time in milliseconds (as a JavaScript number).
2. Because any existing contacts will not have id properties, it is important that you delete them. Use the localStorage.clear() method call from the command line to delete all data from web storage.
3. When contact rows are added to the table in loadContacts, you will add a data attribute to the tr element specifying the ID of the contact in the row. The delete event listener will use this to determine the ID of the contact that should be deleted. Identify the following line of code:
var row = $('<tr>').append(fragment);
Now, change this so that the tr element created has an attribute called data-id with the value from v.id. Hint: I split this into three separate lines of code.
4. The contacts.js file already has a delete method that removes a contact from the table. You need to add code before the following line to identify the data-id associated with the tr:
$(evt.target).parents('tr').remove();
Assign the ID to a variable called contactId.
5. Look up the contacts from web storage and convert it back into a JavaScript array using JSON.parse.
6. Use the filter method on the array to retain any items that do not match this ID. Assign the newly created array to a variable called newContacts.
7. Update the contacts in web storage so that the array stored is the newly created array. Remember to use JSON.stringify on the array before adding it to web storage.
Note
You may be wondering why you needed an id to uniquely identify contacts. Typically, adding a key such as this is the easiest way to uniquely identify an object because none of the other properties on the object is guaranteed to be unique. In this case, it may have been possible to make the email address the unique key, but even this can be shared by multiple people in the real world.
Reference
Please go to the book's website at www.wrox.com/go/html5jsjquery24hr to view the video for Lesson 30, as well as download the code and resources for this lesson.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.