Neo4j in Action (2015)
Part 2. Application Development with Neo4j
Chapter 7. Transactions
This chapter covers
· Why transactions are important
· How Neo4j handles transactions
· How to integrate Neo4j with other transaction management systems
· How to take advantage of transaction events
Neo4j differs from some other NoSQL technologies by being fully ACID-compliant (ACID being an acronym for atomic, consistent, isolated, durable). Being fully ACID-compliant means Neo4j offers the same guarantees you’d have if you were working with a traditional relational database system.
It’s important to have ACID guarantees when you work with Neo4j because it’s commonplace to mutate a number of graph entities (nodes, relationships, and index entries) within the same transaction. It’s also easier to reason about the behavior of systems that are ACID-compliant compared to eventually consistent systems, where you have no real guarantees about when your changes will be visible across a cluster, and compared to technologies where there are no transactions and therefore partial results of a larger business operation may become temporarily visible to competing transactions. The durability aspect of ACID transactions also provides a high degree of confidence that once your transaction is committed, the data won’t be lost.
You’ve seen transactions being called in other chapters in this book. In this chapter we’ll explore transactions in more detail.
7.1. Transaction basics
First, let’s examine the idiomatic way of programmatically creating transactions in Neo4j, as shown in the following snippet:
try (Transaction tx = graphDatabaseService.beginTx()) {
//do something with the database
tx.success();
}
This code begins by making use of the Java 7 try-with-resource statement to create a new transaction and define a block of code against which this transaction will apply. Any statements that interact with the database and are executed within this block will all operate against the same transaction. The call to the success method at the end of the try block signifies that a commit should occur when the transaction finishes (or the resource “closes,” in try-with-resource terminology). The transaction finishes (or closes) when the code block completes. Neo4j will then ensure that this transaction is committed (having detected that the success method was previously called). If an exception is thrown while “doing something with the database,” the success method won’t be called, and the transaction will be rolled back when it finishes. Neo4j’s decision logic regarding whether to commit or roll back a transaction is based on whether the success or failure method was previously called. If you want to roll back a transaction explicitly, such as from a conditional code block, you can invoke the failure method, and the transaction will be unconditionally rolled back at the end of the block. Calling neither the success nor failure method will also result in the transaction being rolled back (default).
Transactions before Neo4j 2.0
In older versions of Neo4j (1.9 and earlier), managing transactions was a bit more complicated, mainly because of the lack of auto-closable resources before Java 7, which Neo4j complies with since version 2.0.
If you’re using an older version of Neo4j, the idiomatic way to handle transactions is as follows:
Transaction tx = graphDatabaseService.beginTx();
try {
//do something
tx.success();
} finally {
tx.finish();
}
This style is still available but has been deprecated in Neo4j 2.0.
Neo4j 2.0 requires a transaction to be initiated for any read or write operation on a graph object including nodes, relationships, schemas, and indexes. Note that in previous versions of Neo4j, there was no such requirement for read operations.
The following listing shows code that first reads a node representing a person, then attempts to set an age property on it.
Listing 7.1. Attempting to update without a transaction

Note
Examples in this chapter deliberately assume a very simple data model that consists of two nodes, John and Bob, representing two people with age properties set on them. This data model will be sufficient to demonstrate the transactional behavior of Neo4j.
When executing this code with a pre-2.0 version of Neo4j, line ![]() will pass but line
will pass but line ![]() will result in a NotInTransactionException. This is because mutating operations in Neo4j 1.X required a transaction, while read-only ones did not.In Neo4j 2.0 and later versions, both
will result in a NotInTransactionException. This is because mutating operations in Neo4j 1.X required a transaction, while read-only ones did not.In Neo4j 2.0 and later versions, both ![]() and
and ![]() will fail with a NotInTransactionException.
will fail with a NotInTransactionException.
7.1.1. Adding in a transaction
The following listing shows the code from listing 7.1 but with transaction management added. For the rest of this chapter, we’ll assume the transactional style and requirements of Neo4j 2.0.
Listing 7.2. Attempting to update with a transaction

This listing represents the general pattern of starting a transaction, carrying out some operations, and assuming they complete without exception. After the success method is called and the code block completes, the changes are committed to the database.
Schema-based operations and transactions
If you’re performing any schema-related activities within the graph, this code will need to be in a separate transaction from all other Neo4j transactional code; otherwise, an exception of the form ConstraintViolationException will be thrown with the message “Cannot perform data updates in a transaction that has performed schema updates.”
Schema indexing was covered in chapter 5, and the following snippet is a partial copy of listing 5.5 to demonstrate this case. To recap, you’re defining name as a schema-indexable property on the USER label in one transaction, and then using a separate transaction to actually set the value on a real user node:
Label userLabel = DynamicLabel.label("USER");
// 1. Do schema related work in one transaction.
try (Transaction tx = graphDb.beginTx()) {
graphDb.schema().indexFor(userLabel).on("name").create();
tx.success();
}
// 2. Do other work in a separate transaction.
Node user = null;
try (Transaction tx = graphDb.beginTx()) {
user = graphDb.createNode(userLabel);
user.setProperty("name", "Michael Collins");
tx.success();
}}
7.1.2. Finishing what you start and not trying to do too much in one go
Creating a transaction in a try block, as we said previously, guarantees that transactions are finished appropriately in a timely manner. The stateful nature of transactions requires that you give consideration to the amount of work you attempt to do in a single transaction. This only really becomes an issue for very large transactions, including large inserts or updates, such as the one shown in the following listing. When executed, this code will likely fail with an out-of-memory exception, depending on the amount of memory available for the JVM.
Listing 7.3. A really big transaction can run out of memory
try(Transaction tx = graphDatabaseService.beginTx()) {
for (int i = 0; i < 100000000; i++) {
Node n = this.graphDatabaseService.createNode();
n.setProperty("number", i);
}
tx.success();
}
java.lang.OutOfMemoryError: Java heap space
at java.util.HashMap.addEntry(HashMap.java:766)
at java.util.HashMap.put(HashMap.java:402)
at java.util.HashSet.add(HashSet.java:217)
at org.neo4j.kernel.impl.api.DiffSets.add(DiffSets.java:98)
at ....
In order to avoid out-of-memory exceptions in very large transactions, the work should be broken down into a number of smaller transactions. It’s not, however, generally advisable to create a large number of nodes using a separate transaction for each new node because the computational cost of the transaction will have a significant impact on performance. A better strategy would be to do some hundreds or perhaps thousands of creation operations in a batch with one transaction. The exact number will depend on the amount of data involved in creating each node.
The previous example conflates the server’s and the client’s behavior, because of its use of the embedded mode. In a more traditional client/server scenario, the pressure of handling large transactions mainly affects the server, because it’s the server that needs to keep track of all uncommitted transactions started by a potentially large number of clients.
Batch inserter and transactions
It’s worth noting that Neo4j does in fact provide batch insertion functionality to allow for speedy batch inserts. This class, however, is optimized for speed and doesn’t support transactions, instead writing changes to disk as it goes. Such functionality can often be useful in situations where you have a large dataset that needs to be loaded once, but you need to be fully aware of the implications of using this facility. For more information, please see the “Batch Insertion” chapter of the Neo4j Manual: http://docs.neo4j.org/chunked/stable/batchinsert.html.
In this section, you’ve seen how to programmatically manage transactions when your code needs to interact with the graph. This allows you to define atomic units of work and to have confidence that a successful finish means your changes are durable and that the graph remains in a consistent state at all times. In the next section, we’ll dive a bit deeper into transactions, including how to use locks as a way of controlling the isolation level of read transactions. Although this is not required, it’s something you may do in certain circumstances.
Nested transactions
Neo4j supports flat nested transactions, which means that it’s possible to nest transactions, but inner and outer transactions will ultimately share the same context. If all transactions call the success method, then all their modifications will be committed to the database.
If you need to signal failure explicitly from an inner transaction, you can call the failure method, which will mark the whole transaction as failed. In this case, the transaction will be rolled back and a TransactionFailureException will be thrown at the end of the outermost transaction.
7.2. Transactions in depth
We’ve covered the basic workings of transactions in Neo4j, and that should give you enough knowledge to handle the most common transactional requirements. But if you need to achieve higher isolation guarantees than the default isolation level, or to write code that’s robust and isn’t likely to generate deadlocks, you’ll need some understanding of Neo4j’s transaction management model.
We’ll start by examining how transactions work and the default isolation level offered by Neo4j. After that we’ll look at how you can use explicit locks to obtain stronger isolation guarantees.
7.2.1. Transaction semantics
Let’s examine some of the guarantees that ACID transactions offer and how they’re handled in Neo4j.
Transactions and thread locality
Each new transaction in Neo4j is bound to the current thread. For that reason, it’s absolutely essential to ensure that each transaction finishes properly and that each transactional context is properly cleaned up. Otherwise, the next transaction to run on the same thread could potentially be affected by the stale context, resulting in erroneous and inconsistent outcomes. The coding idioms shown in this chapter will help you avoid such problems.
Durability
Durability refers to writing data to permanent storage in a way that survives restarting the database. If a transaction succeeds, you can assume that the data has been persisted to the disk in a durable manner.
Under the covers, though, Neo4j maintains a transaction log that gets updated and persisted for each successful transaction with mutating operations. When it reaches a certain size, or when the database shuts down, the transaction log gets flushed and the appropriate store files get updated on the disk. Chapter 11 discusses the role of the transaction log.
Isolation levels and Neo4j Locks
A number of database management systems implement locking mechanisms to manage concurrent access to the same database resources. Neo4j transactions are governed by distinct read and write locks on each graph resource (nodes and relationships).
Read locks are useful because they ensure that the resources you’re interested in are consistently locked and can’t be modified unexpectedly while you’re reading them. More precisely, read locks can optionally be acquired on any graph resource if there is no write lock currently active on the same resource. Read locks are not mutually exclusive; multiple read locks can be acquired on the same resource by multiple threads at the same time. Only one write lock can be acquired on a resource at any given moment, and only if there are no other active locks, either read or write, on the resource in question. The distinction between read and write locks and the way they interact allows developers to flexibly trade off consistency for performance, depending on what’s acceptable for the situation at hand.
By default Neo4j transactions don’t try to acquire read locks automatically. Reads therefore see the latest committed state of nodes, relationships, and index entries, except within their own transaction, where local modifications (even if not committed yet) are visible. Figure 7.1 provides an example that demonstrates this situation.
Figure 7.1. Default isolation level
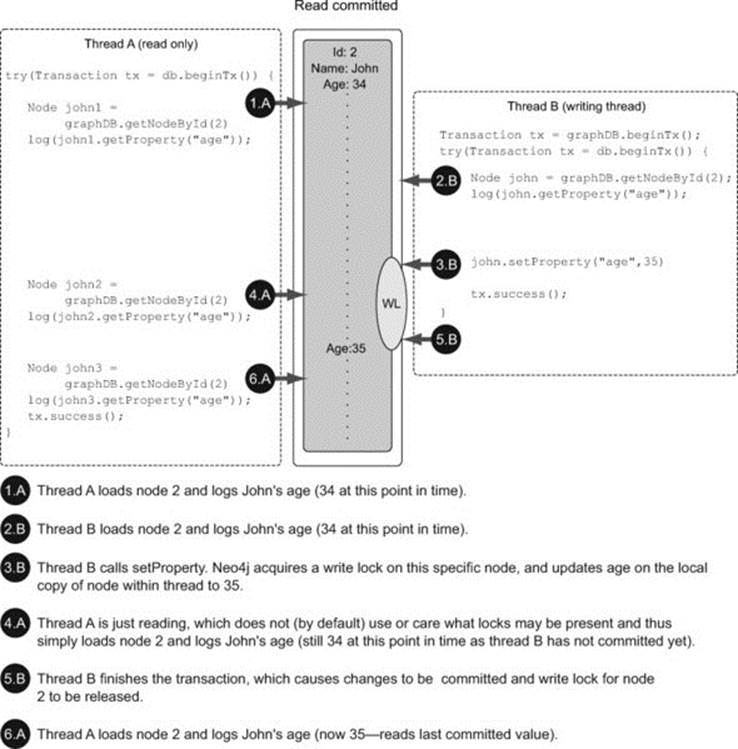
Conversely, write locks are acquired automatically for any graph resource you try to mutate at the point when the mutation occurs, and they’re held for the full duration of the transaction. Every transaction makes sure to release any acquired lock automatically when it completes.
This default behavior is very similar to the Read Committed isolation level in relational databases, which removes the potential for dirty reads, but still allows phantom reads and non-repeatable reads to happen.
What exactly is locked?
Which graph resources are locked and when? When you try to modify a graph object (that is, when you create, delete, or update a property on a node or a relationship), Neo4j has to acquire a write lock on the object in question to protect it against concurrent modification. Equally, when you create a new relationship between two existing nodes, both nodes are locked by the transaction.
A phantom read is the situation in which one transaction can potentially see a different number of nodes and relationships at different times if some entities were added or deleted by another transaction in the meantime.
In non-repeatable reads, a transaction can read the same property of a node or relationship twice and get different values if that property was updated simultaneously by another transaction.
Figure 7.1 illustrates the default isolation level in Neo4j. In the figure, two threads are competing to access the same graph resources, resulting in a Read Committed isolation level.
It’s possible to achieve higher transactional guarantees by managing locks explicitly, as you’ll see in the next section.
Transactions in High Availability mode
The transactional behavior described in this chapter focuses mainly on what happens within a single instance of Neo4j. In High Availability (HA) mode, there are two types of Neo4j instances, master and slaves, and transactions ensure that writes are always consistent and durable. Although technically you can target any Neo4j instance for a write operation, writes are first pushed to the master and are eventually propagated to slaves. This behavior is automatic and can be configured to achieve a suitable trade-off between performance and durability. For more details on Neo4j HA and its use in production, see chapter 11.
7.2.2. Reading in a transaction and explicit read locks
As you saw previously, reading values from the graph returns the latest committed value (or the current modified state), which is equivalent to the Read Committed isolation level. The following listing shows some code that reads a property on the node twice—the user’s age in this case—as part of a business operation, doing additional reading between the reads.
Listing 7.4. Reading the same thing twice without a transaction

Depending on the time taken to do that other processing, there may be a significant window during which external modifications might occur. If your code mixes a high number of reads and writes, this might become an issue.
If you need a higher level of isolation to ensure that others can’t change graph resources you’re reading, Neo4j offers the potential for the explicit acquisition of read locks on graph resources. The following listing shows the same code, but this time with the addition of an explicit request to acquire a read lock on the node prior to any property reading.
Listing 7.5. Reading the same thing twice with increased isolation

Figure 7.2 illustrates how using read locks can help you achieve better isolation.
Figure 7.2. Explicit read locks
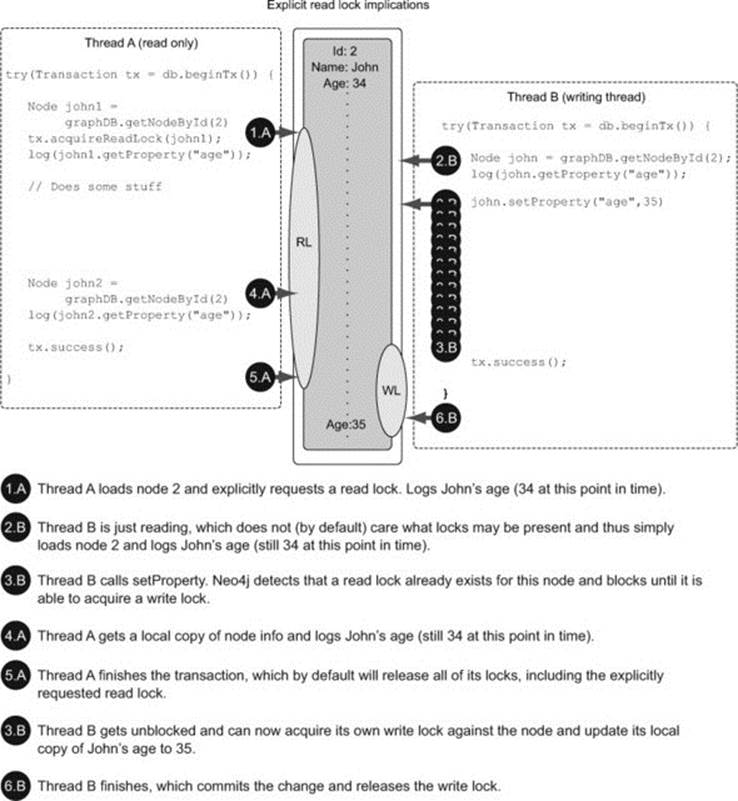
There are two good reasons you should avoid acquiring locks systematically when reading. As previously mentioned, this will generate transactional state, and that uses memory. Second, the main trade-off here is write concurrency, because threads wishing to update any node or relationship where there is an explicit read lock will be blocked until the lock is released or the transaction finishes.
7.2.3. Writing in a transaction and explicit write locks
As discussed previously, the current transaction will acquire individual write locks automatically for you on each resource when you try to mutate it. These locks, however, do not necessarily all get acquired at the same time. There may well be cases where your business logic will need to modify a collection of nodes or relationships in a consistent way, and you want to guarantee that no other transaction is able to modify them concurrently. If your application requires such a high transaction isolation level, which is very similar to the Serializable isolation level in RDMS, you can acquire write locks on a set of graph resources explicitly at the beginning of a transaction, before you mutate the data. As usual, those locks will be released automatically when the transaction completes.
In the following listing, you acquire write locks explicitly on two nodes to guarantee they’re updated collectively in a serializable fashion.
Listing 7.6. Acquiring write locks explicitly
try (Transaction tx = graphDatabaseService.beginTx()) {
Index<Node> nodeIndex = graphDatabaseService.index().forNodes("byName");
Node n1 = nodeIndex.get("name", "John").getSingle();
Node n2 = nodeIndex.get("name", "Bob").getSingle();
tx.acquireWriteLock(n1);
tx.acquireWriteLock(n2);
n1.setProperty("age", 35);
n2.setProperty("age", 37);
tx.success();
}
Again, in doing this you need to be very careful and weigh consistency against performance and resource consumption.
7.2.4. The danger of deadlocks
Although the locking techniques discussed earlier allow you to manage isolation levels flexibly, locks inevitably introduce the possibility for deadlocks to happen. Deadlocks are a sort of “chicken or egg” situation that can happen if two or more transactions are competing to acquire the locks on the same graph resources. If transaction A tries to lock nodes 1 and 2 in that order, while transaction B tries to acquire the locks for the same nodes in the reverse order, then potentially each transaction could lock one node and wait indefinitely for the other node to be released, thus creating a deadlock.
Neo4j has a built-in mechanism to detect deadlocks when they happen, in which case a DeadlockDetectedException will be thrown and the transaction will be rolled back. Deadlock detection is only possible when locking is exclusively managed by Neo4j; that is, by relying on Neo4j’s automatic default locking mechanism, or by only using the Neo4j API locking-related methods (acquireReadLock and acquireWriteLock) that we discussed previously. If any other locking mechanism is used, such as using the Java synchronized keyword, deadlocks won’t be detected if they happen, and your application is likely to appear to hang.
To deal with deadlocks effectively, there are a number of simple things you can do. The first is to stick to the core API provided by Neo4j and not to use any external locking mechanism. This will ensure Neo4j’s deadlock-detection mechanism will kick in, ensuring your application doesn’t completely lock up, and that data will remain consistent. All operations in the core Neo4j API (unless otherwise specified) are thread-safe, so you should generally have no need for external synchronization. The other simple thing you can do is avoid deadlocks altogether by making sure that graph resources are consistently accessed in the same order.
We’ve now covered Neo4j transactions in detail. In the next sections, we’ll focus on issues related to integrating Neo4j transactions with other transaction management systems.
7.3. Integration with other transaction management systems
The transaction-handling code we’ve looked at so far has exclusively used Neo4j’s core API to initiate and complete transactions; it didn’t make any assumptions about the nature of the environment that the code is executed from.
If you’re building a typical enterprise application, though, it’s likely that you’ll need to integrate with an existing transaction manager, such as a JTA transaction manager provided by the application server. The org.neo4j.kernel.impl.transaction package contains a number of classes to support this use case.
Equally, if the application is built on top of the popular Spring Framework, you can benefit from Spring’s declarative transaction support to make your code more robust. The following listing creates a Spring JTA transaction manager, wired into the Neo4j TransactionManagerServiceand UserTransactionService.
Listing 7.7. Configuring Spring transaction manager
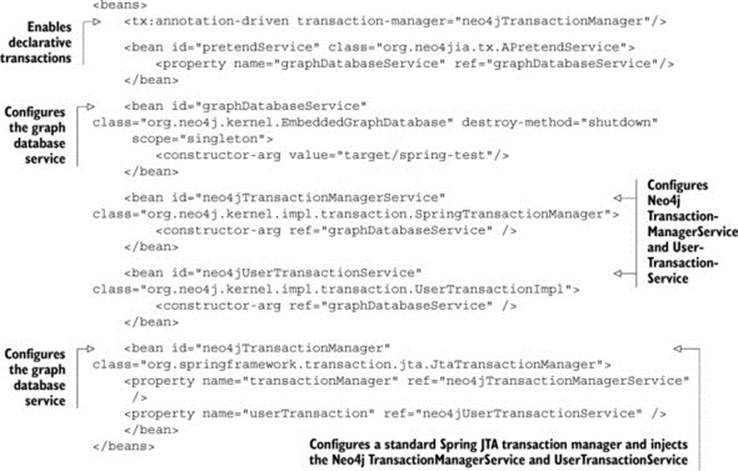
This configuration gives the APretendService bean the ability to annotate its public methods with Spring’s @Transactional annotation and therefore to avoid the need to manage transactions manually.
The next listing shows what APretendService looks like, including declarative transaction management using annotations.
Listing 7.8. Declarative transaction management
public class APretendService {
private GraphDatabaseService gds;
@Transactional
public Node createNodeViaAnnotatedMethod(String name, int age) {
Node node = gds.createNode();
node.setProperty("name", name);
node.setProperty("age", age);
return node;
}
public void setGraphDatabaseService(GraphDatabaseService gds) {
this.gds = gds;
}
}
You’ve seen how you can integrate Neo4j with a typical Spring application. For a more object-oriented programming model, chapter 9 discusses Spring Data Neo4j, which provides a mapping solution between domain classes and Neo4j.
Next, let’s look at how you can add custom logic around Neo4j transactions using transaction events.
7.4. Transaction events
Some databases implement triggers to enable custom code execution around database transactions. Neo4j has transaction event handlers to fulfill this functionality.
The TransactionEventHandler interface contains three methods, beforeCommit, afterCommit, and afterRollback, that when implemented and registered with the database will be invoked at these key points for each transaction. The beforeCommit method can optionally return an object that will be passed on to the other two methods if any context or state needs to be communicated.
The following listing shows the skeleton of a transaction event handler created from the GraphDatabaseService object.
Listing 7.9. Transaction event handlers
graphDatabaseService.registerTransactionEventHandler(new TransactionEventHandler<Object>() {
@Override
public Object beforeCommit(TransactionData data) throws Exception {
// do some work
// no need to return state
return null;
}
@Override
public void afterCommit(TransactionData data, Object state) {
// do some work
}
@Override
public void afterRollback(TransactionData data, Object state) {
// do some work
}
});
The TransactionData objects will inform you about the changed graph resources within the transaction. Typical use cases for event handlers include auditing and integration with external systems. For example, you could publish an event to update a dashboard every time a new user is added to the system.
Be extra careful with the code that you run from a transaction event handler, though, as it will be running from the same thread as your transaction—slow-running code will have an impact on the performance of your system. Also, an exception thrown from an event handler will cause the transaction to fail.
Transactions and Neo4j server
This chapter has focused on demonstrating the use of programmatic transaction handling for an embedded Neo4j setup. Neo4j can also be run in server mode, where clients access the Neo4j server via a well-established HTTP REST-based API, and chapter 10 provides details about what’s required to do this. It’s important to understand the considerations and the way in which transactions are handled when running in server mode in order to be able to build robust, performant applications. This sidebar aims to highlight some of the key points relating to transactions that you should look out for when running in server mode, without going into explicit details. Please see section 10.4.3 for more information.
By default, every request made to the Neo4j server is done via a REST API call, and each call will occur within its own transaction. But making a lot of fine-grained REST calls will likely have a negative impact on the performance of your application. Besides the overhead added by creating a new transaction for each request, the multiple network calls alone could prove catastrophic for performance. In order to help address some of these issues, the following options for handling transaction scenarios in a server context should be considered:
· Using the REST Cypher endpoint —Provides the ability to execute a single Cypher statement, which may result in multiple nodes and/or relationships needing to be updated. All affected nodes/relationships will be updated as part of the single HTTP request.
· Using the REST transactional endpoint —Provides the ability to execute a series of Cypher statements within the scope of a transaction, but unlike the Cypher endpoint, over multiple HTTP requests.
· Using the REST batch endpoint —Provides the ability to define a job—a set of low-level REST API calls to be executed as a single transaction when sent to the batch REST endpoint.
· Using server plugins or unmanaged extensions —Provides the ability to define Java code that can be run within the Neo4j server itself as a result of a REST call, providing full programmatic control (including transaction handling).
7.5. Summary
Transactions can be a complicated topic, but hopefully you now understand how Neo4j allows you to take full advantage of ACID-based transactions to manage concurrent access to graph resources.
We’ve covered how transactions work in detail: the default transaction behavior is satisfactory for most common cases, but we’ve examined the implications of transactions trying to access the same graph resources at the same time and how higher isolation levels can be achieved by using read and write locks explicitly.
Enterprise applications are often built on top of a framework such as Spring, and we’ve covered how Neo4j transactions can be integrated with Spring’s transaction management system, taking advantage of Spring’s declarative approach.
Finally, we’ve covered transaction event handlers, which are useful for adding custom behavior around your transactions, like triggers in traditional RDBMSs do.
Now that you know how to use transactions, the next chapter will teach you more about traversal operations, so that you can query the data in more sophisticated ways.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.