Hadoop: The Definitive Guide (2015)
Part IV. Related Projects
Chapter 18. Crunch
Apache Crunch is a higher-level API for writing MapReduce pipelines. The main advantages it offers over plain MapReduce are its focus on programmer-friendly Java types like String and plain old Java objects, a richer set of data transformation operations, and multistage pipelines (no need to explicitly manage individual MapReduce jobs in a workflow).
In these respects, Crunch looks a lot like a Java version of Pig. One day-to-day source of friction in using Pig, which Crunch avoids, is that the language used to write user-defined functions (Java or Python) is different from the language used to write Pig scripts (Pig Latin), which makes for a disjointed development experience as one switches between the two different representations and languages. By contrast, Crunch programs and UDFs are written in a single language (Java or Scala), and UDFs can be embedded right in the programs. The overall experience feels very like writing a non-distributed program. Although it has many parallels with Pig, Crunch was inspired by FlumeJava, the Java library developed at Google for building MapReduce pipelines.
NOTE
FlumeJava is not to be confused with Apache Flume, covered in Chapter 14, which is a system for collecting streaming event data. You can read more about FlumeJava in “FlumeJava: Easy, Efficient Data-Parallel Pipelines” by Craig Chambers et al.
Because they are high level, Crunch pipelines are highly composable and common functions can be extracted into libraries and reused in other programs. This is different from MapReduce, where it is very difficult to reuse code: most programs have custom mapper and reducer implementations, apart from simple cases such as where an identity function or a simple sum (LongSumReducer) is called for. Writing a library of mappers and reducers for different types of transformations, like sorting and joining operations, is not easy in MapReduce, whereas in Crunch it is very natural. For example, there is a library class, org.apache.crunch.lib.Sort, with a sort() method that will sort any Crunch collection that is passed to it.
Although Crunch was initially written to run using Hadoop’s MapReduce execution engine, it is not tied to it, and in fact you can run a Crunch pipeline using Apache Spark (see Chapter 19) as the distributed execution engine. Different engines have different characteristics: Spark, for example, is more efficient than MapReduce if there is a lot of intermediate data to be passed between jobs, since it can retain the data in memory rather than materializing it to disk like MapReduce does. Being able to try a pipeline on different engines without rewriting the program is a powerful property, since it allows you to treat what the program does separately from matters of runtime efficiency (which generally improve over time as the engines are tuned).
This chapter is an introduction to writing data processing programs in Crunch. You can find more information in the Crunch User Guide.
An Example
We’ll start with a simple Crunch pipeline to illustrate the basic concepts. Example 18-1 shows a Crunch version of the program to calculate the maximum temperature by year for the weather dataset, which we first met in Chapter 2.
Example 18-1. Application to find the maximum temperature, using Crunch
public class MaxTemperatureCrunch {
public static void main(String[] args) throws Exception {
if (args.length != 2) {
System.err.println("Usage: MaxTemperatureCrunch <input path> <output path>");
System.exit(-1);
}
Pipeline pipeline = new MRPipeline(getClass());
PCollection<String> records = pipeline.readTextFile(args[0]);
PTable<String, Integer> yearTemperatures = records
.parallelDo(toYearTempPairsFn(), tableOf(strings(), ints()));
PTable<String, Integer> maxTemps = yearTemperatures
.groupByKey()
.combineValues(Aggregators.MAX_INTS());
maxTemps.write(To.textFile(args[1]));
PipelineResult result = pipeline.done();
System.exit(result.succeeded() ? 0 : 1);
}
static DoFn<String, Pair<String, Integer>> toYearTempPairsFn() {
return new DoFn<String, Pair<String, Integer>>() {
NcdcRecordParser parser = new NcdcRecordParser();
@Override
public void process(String input, Emitter<Pair<String, Integer>> emitter) {
parser.parse(input);
if (parser.isValidTemperature()) {
emitter.emit(Pair.of(parser.getYear(), parser.getAirTemperature()));
}
}
};
}
}
After the customary checking of command-line arguments, the program starts by constructing a Crunch Pipeline object, which represents the computation that we want to run. As the name suggests, a pipeline can have multiple stages; pipelines with multiple inputs and outputs, branches, and iteration are all possible, although in this example we start with a single-stage pipeline. We’re going to use MapReduce to run the pipeline, so we create an MRPipeline, but we could have chosen to use a MemPipeline for running the pipeline in memory for testing purposes, or a SparkPipeline to run the same computation using Spark.
A pipeline receives data from one or more input sources, and in this example the source is a single text file whose name is specified by the first command-line argument, args[0]. The Pipeline class has a convenience method, readTextFile(), to convert a text file into a PCollection ofString objects, where each String is a line from the text file. PCollection<S> is the most fundamental data type in Crunch, and represents an immutable, unordered, distributed collection of elements of type S. You can think of PCollection<S> as an unmaterialized analog ofjava.util.Collection — unmaterialized since its elements are not read into memory. In this example, the input is a distributed collection of the lines of a text file, and is represented by PCollection<String>.
A Crunch computation operates on a PCollection, and produces a new PCollection. The first thing we need to do is parse each line of the input file, and filter out any bad records. We do this by using the parallelDo() method on PCollection, which applies a function to every element in the PCollection and returns a new PCollection. The method signature looks like this:
<T> PCollection<T> parallelDo(DoFn<S,T> doFn, PType<T> type);
The idea is that we write a DoFn implementation that transforms an instance of type S into one or more instances of type T, and Crunch will apply the function to every element in the PCollection. It should be clear that the operation can be performed in parallel in the map task of a MapReduce job. The second argument to the parallelDo() method is a PType<T> object, which gives Crunch information about both the Java type used for T and how to serialize that type.
We are actually going to use an overloaded version of parallelDo() that creates an extension of PCollection called PTable<K, V>, which is a distributed multi-map of key-value pairs. (A multi-map is a map that can have duplicate key-value pairs.) This is so we can represent the year as the key and the temperature as the value, which will enable us to do grouping and aggregation later in the pipeline. The method signature is:
<K, V> PTable<K, V> parallelDo(DoFn<S, Pair<K, V>> doFn, PTableType<K, V> type);
In this example, the DoFn parses a line of input and emits a year-temperature pair:
static DoFn<String, Pair<String, Integer>> toYearTempPairsFn() {
return new DoFn<String, Pair<String, Integer>>() {
NcdcRecordParser parser = new NcdcRecordParser();
@Override
public void process(String input, Emitter<Pair<String, Integer>> emitter) {
parser.parse(input);
if (parser.isValidTemperature()) {
emitter.emit(Pair.of(parser.getYear(), parser.getAirTemperature()));
}
}
};
}
After applying the function we get a table of year-temperature pairs:
PTable<String, Integer> yearTemperatures = records
.parallelDo(toYearTempPairsFn(), tableOf(strings(), ints()));
The second argument to parallelDo() is a PTableType<K, V> instance, which is constructed using static methods on Crunch’s Writables class (since we have chosen to use Hadoop Writable serialization for any intermediate data that Crunch will write). The tableOf() method creates aPTableType with the given key and value types. The strings() method declares that keys are represented by Java String objects in memory, and serialized as Hadoop Text. The values are Java int types and are serialized as Hadoop IntWritables.
At this point, we have a more structured representation of the data, but the number of records is still the same since every line in the input file corresponds to an entry in the yearTemperatures table. To calculate the maximum temperature reading for each year in the dataset, we need to group the table entries by year, then find the maximum temperature value for each year. Fortunately, Crunch provides exactly these operations as a part of PTable’s API. The groupByKey() method performs a MapReduce shuffle to group entries by key and returns the third type ofPCollection, called PGroupedTable<K, V>, which has a combineValues() method for performing aggregation of all the values for a key, just like a MapReduce reducer:
PTable<String, Integer> maxTemps = yearTemperatures
.groupByKey()
.combineValues(Aggregators.MAX_INTS());
The combineValues() method accepts an instance of a Crunch Aggregator, a simple interface for expressing any kind of aggregation of a stream of values, and here we can take advantage of a built-in aggregator from the Aggregators class called MAX_INTS that finds the maximum value from a set of integers.
The final step in the pipeline is writing the maxTemps table to a file by calling write() with a text file target object constructed using the To static factory. Crunch actually uses Hadoop’s TextOutputFormat for this operation, which means that the key and value in each line of output are separated by a tab:
maxTemps.write(To.textFile(args[1]));
The program so far has only been concerned with pipeline construction. To execute a pipeline, we have to call the done() method, at which point the program blocks until the pipeline completes. Crunch returns a PipelineResult object that encapsulates various statistics about the different jobs that were run in the pipeline, as well as whether the pipeline succeeded or not. We use the latter information to set the program’s exit code appropriately.
When we run the program on the sample dataset, we get the following result:
% hadoop jar crunch-examples.jar crunch.MaxTemperatureCrunch \
input/ncdc/sample.txt output
% cat output/part-r-00000
1949 111
1950 22
The Core Crunch API
This section presents the core interfaces in Crunch. Crunch’s API is high level by design, so the programmer can concentrate on the logical operations of the computation, rather than the details of how it is executed.
Primitive Operations
The core data structure in Crunch is PCollection<S>, an immutable, unordered, distributed collection of elements of type S. In this section, we examine the primitive operations on PCollection and its derived types, PTable and PGroupedTable.
union()
The simplest primitive Crunch operation is union(), which returns a PCollection that contains all the elements of the PCollection it is invoked on and the PCollection supplied as an argument. For example:
PCollection<Integer> a = MemPipeline.collectionOf(1, 3);
PCollection<Integer> b = MemPipeline.collectionOf(2);
PCollection<Integer> c = a.union(b);
assertEquals("{2,1,3}", dump(c));
MemPipeline’s collectionOf() method is used to create a PCollection instance from a small number of elements, normally for the purposes of testing or demonstration. The dump() method is a utility method introduced here for rendering the contents of a small PCollection as a string (it’s not a part of Crunch, but you can find the implementation in the PCollections class in the example code that accompanies this book). Since PCollections are unordered, the order of the elements in c is undefined.
When forming the union of two PCollections, they must have been created from the same pipeline (or the operation will fail at runtime), and they must have the same type. The latter condition is enforced at compile time, since PCollection is a parameterized type and the type arguments for the PCollections in the union must match.
parallelDo()
The second primitive operation is parallelDo() for calling a function on every element in an input PCollection<S> and returning a new output PCollection<T> containing the results of the function calls. In its simplest form, parallelDo() takes two arguments: a DoFn<S, T>implementation that defines a function transforming elements of type S to type T, and a PType<T> instance to describe the output type T. (PTypes are explained in more detail in the section Types.)
The following code snippet shows how to use parallelDo() to apply a string length function to a PCollection of strings:
PCollection<String> a = MemPipeline.collectionOf("cherry", "apple", "banana");
PCollection<Integer> b = a.parallelDo(new DoFn<String, Integer>() {
@Override
public void process(String input, Emitter<Integer> emitter) {
emitter.emit(input.length());
}
}, ints());
assertEquals("{6,5,6}", dump(b));
In this case, the output PCollection of integers has the same number of elements as the input, so we could have used the MapFn subclass of DoFn for 1:1 mappings:
PCollection<Integer> b = a.parallelDo(new MapFn<String, Integer>() {
@Override
public Integer map(String input) {
return input.length();
}
}, ints());
assertEquals("{6,5,6}", dump(b));
One common use of parallelDo() is for filtering out data that is not needed in later processing steps. Crunch provides a filter() method for this purpose that takes a special DoFn called FilterFn. Implementors need only implement the accept() method to indicate whether an element should be in the output. For example, this code retains only those strings with an even number of characters:
PCollection<String> b = a.filter(new FilterFn<String>() {
@Override
public boolean accept(String input) {
return input.length() % 2 == 0; // even
}
});
assertEquals("{cherry,banana}", dump(b));
Notice that there is no PType in the method signature for filter(), since the output PCollection has the same type as the input.
TIP
If your DoFn significantly changes the size of the PCollection it is operating on, you can override its scaleFactor() method to give a hint to the Crunch planner about the estimated relative size of the output, which may improve its efficiency.
FilterFn’s scaleFactor() method returns 0.5; in other words, the assumption is that implementations will filter out about half of the elements in a PCollection. You can override this method if your filter function is significantly more or less selective than this.
There is an overloaded form of parallelDo() for generating a PTable from a PCollection. Recall from the opening example that a PTable<K, V> is a multi-map of key-value pairs; or, in the language of Java types, PTable<K, V> is a PCollection<Pair<K, V>>, where Pair<K, V> is Crunch’s pair class.
The following code creates a PTable by using a DoFn that turns an input string into a key-value pair (the key is the length of the string, and the value is the string itself):
PTable<Integer, String> b = a.parallelDo(
new DoFn<String, Pair<Integer, String>>() {
@Override
public void process(String input, Emitter<Pair<Integer, String>> emitter) {
emitter.emit(Pair.of(input.length(), input));
}
}, tableOf(ints(), strings()));
assertEquals("{(6,cherry),(5,apple),(6,banana)}", dump(b));
Extracting keys from a PCollection of values to form a PTable is a common enough task that Crunch provides a method for it, called by(). This method takes a MapFn<S, K> to map the input value S to its key K:
PTable<Integer, String> b = a.by(new MapFn<String, Integer>() {
@Override
public Integer map(String input) {
return input.length();
}
}, ints());
assertEquals("{(6,cherry),(5,apple),(6,banana)}", dump(b));
groupByKey()
The third primitive operation is groupByKey(), for bringing together all the values in a PTable<K, V> that have the same key. This operation can be thought of as the MapReduce shuffle, and indeed that’s how it’s implemented for the MapReduce execution engine. In terms of Crunch types, groupByKey() returns a PGroupedTable<K, V>, which is a PCollection<Pair<K, Iterable<V>>>, or a multi-map where each key is paired with an iterable collection over its values.
Continuing from the previous code snippet, if we group the PTable of length-string mappings by key, we get the following (where the items in square brackets indicate an iterable collection):
PGroupedTable<Integer, String> c = b.groupByKey();
assertEquals("{(5,[apple]),(6,[banana,cherry])}", dump(c));
Crunch uses information on the size of the table to set the number of partitions (reduce tasks in MapReduce) to use for the groupByKey() operation. Most of the time the default is fine, but you can explicitly set the number of partitions by using the overloaded form, groupByKey(int), if needed.
combineValues()
Despite the suggestive naming, PGroupedTable is not actually a subclass of PTable, so you can’t call methods like groupByKey() on it. This is because there is no reason to group by key on a PTable that was already grouped by key. Another way of thinking about PGroupedTable is as an intermediate representation before generating another PTable. After all, the reason to group by key is so you can do something to the values for each key. This is the basis of the fourth primitive operation, combineValues().
In its most general form, combineValues() takes a combining function CombineFn<K, V>, which is a more concise name for DoFn<Pair<K, Iterable<V>>, Pair<K, V>>, and returns a PTable<K, V>. To see it in action, consider a combining function that concatenates all the string values together for a key, using a semicolon as a separator:
PTable<Integer, String> d = c.combineValues(new CombineFn<Integer, String>() {
@Override
public void process(Pair<Integer, Iterable<String>> input,
Emitter<Pair<Integer, String>> emitter) {
StringBuilder sb = new StringBuilder();
for (Iterator i = input.second().iterator(); i.hasNext(); ) {
sb.append(i.next());
if (i.hasNext()) { sb.append(";"); }
}
emitter.emit(Pair.of(input.first(), sb.toString()));
}
});
assertEquals("{(5,apple),(6,banana;cherry)}", dump(d));
NOTE
String concatenation is not commutative, so the result is not deterministic. This may or may not be important in your application!
The code is cluttered somewhat by the use of Pair objects in the process() method signature; they have to be unwrapped with calls to first() and second(), and a new Pair object is created to emit the new key-value pair. This combining function does not alter the key, so we can use an overloaded form of combineValues() that takes an Aggregator object for operating only on the values and passes the keys through unchanged. Even better, we can use a built-in Aggregator implementation for performing string concatenation found in the Aggregators class. The code becomes:
PTable<Integer, String> e = c.combineValues(Aggregators.STRING_CONCAT(";",
false));
assertEquals("{(5,apple),(6,banana;cherry)}", dump(e));
Sometimes you may want to aggregate the values in a PGroupedTable and return a result with a different type from the values being grouped. This can be achieved using the mapValues() method with a MapFn for converting the iterable collection into another object. For example, the following calculates the number of values for each key:
PTable<Integer, Integer> f = c.mapValues(new MapFn<Iterable<String>, Integer>() {
@Override
public Integer map(Iterable<String> input) {
return Iterables.size(input);
}
}, ints());
assertEquals("{(5,1),(6,2)}", dump(f));
Notice that the values are strings, but the result of applying the map function is an integer, the size of the iterable collection computed using Guava’s Iterables class.
You might wonder why the combineValues() operation exists at all, given that the mapValues() method is more powerful. The reason is that combineValues() can be run as a MapReduce combiner, and therefore it can improve performance by being run on the map side, which has the effect of reducing the amount of data that has to be transferred in the shuffle (see Combiner Functions). The mapValues() method is translated into a parallelDo() operation, and in this context it can only run on the reduce side, so there is no possibility for using a combiner to improve its performance.
Finally, the other operation on PGroupedTable is ungroup(), which turns a PGroupedTable<K, V> back into a PTable<K, V> — the reverse of groupByKey(). (It’s not a primitive operation though, since it is implemented with a parallelDo().) Calling groupByKey() then ungroup() on aPTable has the effect of performing a partial sort on the table by its keys, although it’s normally more convenient to use the Sort library, which implements a total sort (which is usually what you want) and also offers options for ordering.
Types
Every PCollection<S> has an associated class, PType<S>, that encapsulates type information about the elements in the PCollection. The PType<S> determines the Java class, S, of the elements in the PCollection, as well as the serialization format used to read data from persistent storage into the PCollection and, conversely, write data from the PCollection to persistent storage.
There are two PType families in Crunch: Hadoop Writables and Avro. The choice of which to use broadly corresponds to the file format that you are using in your pipeline; Writables for sequence files, and Avro for Avro data files. Either family can be used with text files. Pipelines can use a mixture of PTypes from different families (since the PType is associated with the PCollection, not the pipeline), but this is usually unnecessary unless you are doing something that spans families, like file format conversion.
In general, Crunch strives to hide the differences between different serialization formats, so that the types used in code are familiar to Java programmers. (Another benefit is that it’s easier to write libraries and utilities to work with Crunch collections, regardless of the serialization family they belong to.) Lines read from a text file, for instance, are presented as regular Java String objects, rather than the Writable Text variant or Avro Utf8 objects.
The PType used by a PCollection is specified when the PCollection is created, although sometimes it is implicit. For example, reading a text file will use Writables by default, as this test shows:
PCollection<String> lines = pipeline.read(From.textFile(inputPath));
assertEquals(WritableTypeFamily.getInstance(), lines.getPType().getFamily());
However, it is possible to explicitly use Avro serialization by passing the appropriate PType to the textFile() method. Here we use the static factory method on Avros to create an Avro representation of PType<String>:
PCollection<String> lines = pipeline.read(From.textFile(inputPath,
Avros.strings()));
Similarly, operations that create new PCollections require that the PType is specified and matches the type parameters of the PCollection.[118] For instance, in our earlier example the parallelDo() operation to extract an integer key from a PCollection<String>, turning it into aPTable<Integer, String>, specified a matching PType of:
tableOf(ints(), strings())
where all three methods are statically imported from Writables.
Records and tuples
When it comes to working with complex objects with multiple fields, you can choose between records or tuples in Crunch. A record is a class where fields are accessed by name, such as Avro’s GenericRecord, a plain old Java object (corresponding to Avro Specific or Reflect), or a custom Writable. For a tuple, on the other hand, field access is by position, and Crunch provides a Tuple interface as well as a few convenience classes for tuples with a small number of elements: Pair<K, V>, Tuple3<V1, V2, V3>, Tuple4<V1, V2, V3, V4>, and TupleN for tuples with an arbitrary but fixed number of values.
Where possible, you should prefer records over tuples, since the resulting Crunch programs are more readable and understandable. If a weather record is represented by a WeatherRecord class with year, temperature, and station ID fields, then it is easier to work with this type:
Emitter<Pair<Integer, WeatherRecord>>
than this:
Emitter<Pair<Integer, Tuple3<Integer, Integer, String>>
The latter does not convey any semantic information through its type names, unlike WeatherRecord, which clearly describes what it is.
As this example hints, it’s is not possible to entirely avoid using Crunch Pair objects, since they are a fundamental part of the way Crunch represents table collections (recall that a PTable<K, V> is a PCollection<Pair<K, V>>). However, there are opportunities to limit the use of Pairobjects in many cases, which will make your code more readable. For example, use PCollection’s by() method in favor of parallelDo() when creating a table where the values are the same as the ones in the PCollection (as discussed in parallelDo()), or use PGroupedTable’scombineValues() with an Aggregator in preference to a CombineFn (see combineValues()).
The fastest path to using records in a Crunch pipeline is to define a Java class that has fields that Avro Reflect can serialize and a no-arg constructor, like this WeatherRecord class:
public class WeatherRecord {
private int year;
private int temperature;
private String stationId;
public WeatherRecord() {
}
public WeatherRecord(int year, int temperature, String stationId) {
this.year = year;
this.temperature = temperature;
this.stationId = stationId;
}
// ... getters elided
}
From there, it’s straightforward to generate a PCollection<WeatherRecord> from a PCollection<String>, using parallelDo() to parse each line into a WeatherRecord object:
PCollection<String> lines = pipeline.read(From.textFile(inputPath));
PCollection<WeatherRecord> records = lines.parallelDo(
new DoFn<String, WeatherRecord>() {
NcdcRecordParser parser = new NcdcRecordParser();
@Override
public void process(String input, Emitter<WeatherRecord> emitter) {
parser.parse(input);
if (parser.isValidTemperature()) {
emitter.emit(new WeatherRecord(parser.getYearInt(),
parser.getAirTemperature(), parser.getStationId()));
}
}
}, Avros.records(WeatherRecord.class));
The records() factory method returns a Crunch PType for the Avro Reflect data model, as we have used it here; but it also supports Avro Specific and Generic data models. If you wanted to use Avro Specific instead, then you would define your custom type using an Avro schema file, generate the Java class for it, and call records() with the generated class. For Avro Generic, you would declare the class to be a GenericRecord.
Writables also provides a records() factory method for using custom Writable types; however, they are more cumbersome to define since you have to write serialization logic yourself (see Implementing a Custom Writable).
With a collection of records in hand, we can use Crunch libraries or our own processing functions to perform computations on it. For example, this will perform a total sort of the weather records by the fields in the order they are declared (by year, then by temperature, then by station ID):
PCollection<WeatherRecord> sortedRecords = Sort.sort(records);
Sources and Targets
This section covers the different types of sources and targets in Crunch, and how to use them.
Reading from a source
Crunch pipelines start with one or more Source<T> instances specifying the storage location and PType<T> of the input data. For the simple case of reading text files, the readTextFile() method on Pipeline works well; for other types of source, use the read() method that takes aSource<T> object. In fact, this:
PCollection<String> lines = pipeline.readTextFile(inputPath);
is shorthand for:
PCollection<String> lines = pipeline.read(From.textFile(inputPath));
The From class (in the org.apache.crunch.io package) acts as a collection of static factory methods for file sources, of which text files are just one example.
Another common case is reading sequence files of Writable key-value pairs. In this case, the source is a TableSource<K, V>, to accommodate key-value pairs, and it returns a PTable<K, V>. For example, a sequence file containing IntWritable keys and Text values yields aPTable<Integer, String>:
TableSource<Integer, String> source =
From.sequenceFile(inputPath, Writables.ints(), Writables.strings());
PTable<Integer, String> table = pipeline.read(source);
You can also read Avro datafiles into a PCollection as follows:
Source<WeatherRecord> source =
From.avroFile(inputPath, Avros.records(WeatherRecord.class));
PCollection<WeatherRecord> records = pipeline.read(source);
Any MapReduce FileInputFormat (in the new MapReduce API) can be used as a TableSource by means of the formattedFile() method on From, providing Crunch access to the large number of different Hadoop-supported file formats. There are also more source implementations in Crunch than the ones exposed in the From class, including:
§ AvroParquetFileSource for reading Parquet files as Avro PTypes.
§ FromHBase, which has a table() method for reading rows from HBase tables into PTable<ImmutableBytesWritable, Result> collections. ImmutableBytesWritable is an HBase class for representing a row key as bytes, and Result contains the cells from the row scan, which can be configured to return only cells in particular columns or column families.
Writing to a target
Writing a PCollection to a Target is as simple as calling PCollection’s write() method with the desired Target. Most commonly, the target is a file, and the file type can be selected with the static factory methods on the To class. For example, the following line writes Avro files to a directory called output in the default filesystem:
collection.write(To.avroFile("output"));
This is just a slightly more convenient way of saying:
pipeline.write(collection, To.avroFile("output"));
Since the PCollection is being written to an Avro file, it must have a PType belonging to the Avro family, or the pipeline will fail.
The To factory also has methods for creating text files, sequence files, and any MapReduce FileOutputFormat. Crunch also has built-in Target implementations for the Parquet file format (AvroParquetFileTarget) and HBase (ToHBase).
NOTE
Crunch tries to write the type of collection to the target file in the most natural way. For example, a PTable is written to an Avro file using a Pair record schema with key and value fields that match the PTable. Similarly, a PCollection’s values are written to a sequence file’s values (the keys are null), and a PTable is written to a text file with tab-separated keys and values.
Existing outputs
If a file-based target already exists, Crunch will throw a CrunchRuntimeException when the write() method is called. This preserves the behavior of MapReduce, which is to be conservative and not overwrite existing outputs unless explicitly directed to by the user (see Java MapReduce).
A flag may be passed to the write() method indicating that outputs should be overwritten as follows:
collection.write(To.avroFile("output"), Target.WriteMode.OVERWRITE);
If output already exists, then it will be deleted before the pipeline runs.
There is another write mode, APPEND, which will add new files[119] to the output directory, leaving any existing ones from previous runs intact. Crunch takes care to use a unique identifier in filenames to avoid the possibility of a new run overwriting files from a previous run.[120]
The final write mode is CHECKPOINT, which is for saving work to a file so that a new pipeline can start from that point rather than from the beginning of the pipeline. This mode is covered in Checkpointing a Pipeline.
Combined sources and targets
Sometimes you want to write to a target and then read from it as a source (i.e., in another pipeline in the same program). For this case, Crunch provides the SourceTarget<T> interface, which is both a Source<T> and a Target. The At class provides static factory methods for creatingSourceTarget instances for text files, sequence files, and Avro files.
Functions
At the heart of any Crunch program are the functions (represented by DoFn) that transform one PCollection into another. In this section, we examine some of the considerations in writing your own custom functions.
Serialization of functions
When writing MapReduce programs, it is up to you to package the code for mappers and reducers into a job JAR file so that Hadoop can make the user code available on the task classpath (see Packaging a Job). Crunch takes a different approach. When a pipeline is executed, all theDoFn instances are serialized to a file that is distributed to task nodes using Hadoop’s distributed cache mechanism (described in Distributed Cache), and then deserialized by the task itself so that the DoFn can be invoked.
The upshot for you, the user, is that you don’t need to do any packaging work; instead, you only need to make sure that your DoFn implementations are serializable according to the standard Java serialization mechanism.[121]
In most cases, no extra work is required, since the DoFn base class is declared as implementing the java.io.Serializable interface. Thus, if your function is stateless, there are no fields to serialize, and it will be serialized without issue.
There are a couple of problems to watch out for, however. One problem occurs if your DoFn is defined as an inner class (also called a nonstatic nested class), such as an anonymous class, in an outer class that doesn’t implement Serializable:
public class NonSerializableOuterClass {
public void runPipeline() throws IOException {
// ...
PCollection<String> lines = pipeline.readTextFile(inputPath);
PCollection<String> lower = lines.parallelDo(new DoFn<String, String>() {
@Override
public void process(String input, Emitter<String> emitter) {
emitter.emit(input.toLowerCase());
}
}, strings());
// ...
}
}
Since inner classes have an implicit reference to their enclosing instance, if the enclosing class is not serializable, then the function will not be serializable and the pipeline will fail with a CrunchRuntimeException. You can easily fix this by making the function a (named) static nested class or a top-level class, or you can make the enclosing class implement Serializable.
Another problem is when a function depends on nonserializable state in the form of an instance variable whose class is not Serializable. In this case, you can mark the nonserializable instance variable as transient so Java doesn’t try to serialize it, then set it in the initialize()method of DoFn. Crunch will call the initialize() method before the process() method is invoked for the first time:
public class CustomDoFn<S, T> extends DoFn<S, T> {
transient NonSerializableHelper helper;
@Override
public void initialize() {
helper = new NonSerializableHelper();
}
@Override
public void process(S input, Emitter<T> emitter) {
// use helper here
}
}
Although not shown here, it’s possible to pass state to initialize the transient instance variable using other, nontransient instance variables, such as strings.
Object reuse
In MapReduce, the objects in the reducer’s values iterator are reused for efficiency (to avoid the overhead of object allocation). Crunch has the same behavior for the iterators used in the combineValues() and mapValues() methods on PGroupedTable. Therefore, if you retain a reference to an object outside the body of the iterator, you should make a copy to avoid object identity errors.
We can see how to go about this by writing a general-purpose utility for finding the set of unique values for each key in a PTable; see Example 18-2.
Example 18-2. Finding the set of unique values for each key in a PTable
public static <K, V> PTable<K, Collection<V>> uniqueValues(PTable<K, V> table) {
PTypeFamily tf = table.getTypeFamily();
final PType<V> valueType = table.getValueType();
return table.groupByKey().mapValues("unique",
new MapFn<Iterable<V>, Collection<V>>() {
@Override
public void initialize() {
valueType.initialize(getConfiguration());
}
@Override
public Set<V> map(Iterable<V> values) {
Set<V> collected = new HashSet<V>();
for (V value : values) {
collected.add(valueType.getDetachedValue(value));
}
return collected;
}
}, tf.collections(table.getValueType()));
}
The idea is to group by key, then iterate over each value associated with a key and collect the unique values in a Set, which will automatically remove duplicates. Since we want to retain the values outside the iteration, we need to make a copy of each value before we put it in the set.
Fortunately, we don’t need to write code that knows how to perform the copy for each possible Java class; we can use the getDetachedValue() method that Crunch provides for exactly this purpose on PType, which we get from the table’s value type. Notice that we also have to initialize the PType in the DoFn’s initialize() method so that the PType can access the configuration in order to perform the copying.
For immutable objects like Strings or Integers, calling getDetachedValue() is actually a no-op, but for mutable Avro or Writable types, a deep copy of each value is made.
Materialization
Materialization is the process of making the values in a PCollection available so they can be read in your program. For example, you might want to read all the values from a (typically small) PCollection and display them, or send them to another part of your program, rather than writing them to a Crunch target. Another reason to materialize a PCollection is to use the contents as the basis for determining further processing steps — for example, to test for convergence in an iterative algorithm (see Iterative Algorithms).
There are a few ways of materializing a PCollection; the most direct way to accomplish this is to call materialize(), which returns an Iterable collection of its values. If the PCollection has not already been materialized, then Crunch will have to run the pipeline to ensure that the objects in the PCollection have been computed and stored in a temporary intermediate file so they can be iterated over.[122]
Consider the following Crunch program for lowercasing lines in a text file:
Pipeline pipeline = new MRPipeline(getClass());
PCollection<String> lines = pipeline.readTextFile(inputPath);
PCollection<String> lower = lines.parallelDo(new ToLowerFn(), strings());
Iterable<String> materialized = lower.materialize();
for (String s : materialized) { // pipeline is run
System.out.println(s);
}
pipeline.done();
The lines from the text file are transformed using the ToLowerFn function, which is defined separately so we can use it again later:
public class ToLowerFn extends DoFn<String, String> {
@Override
public void process(String input, Emitter<String> emitter) {
emitter.emit(input.toLowerCase());
}
}
The call to materialize() on the variable lower returns an Iterable<String>, but it is not this method call that causes the pipeline to be run. It is only once an Iterator is created from the Iterable (implicitly by the for each loop) that Crunch runs the pipeline. When the pipeline has completed, the iteration can proceed over the materialized PCollection, and in this example the lowercase lines are printed to the console.
PTable has a materializeToMap() method, which might be expected to behave in a similar way to materialize(). However, there are two important differences. First, since it returns a Map<K, V> rather than an iterator, the whole table is loaded into memory at once, which should be avoided for large collections. Second, although a PTable is a multi-map, the Map interface does not support multiple values for a single key, so if the table has multiple values for the same key, all but one will be lost in the returned Map.
To avoid these limitations, simply call materialize() on the table in order to obtain an Iterable<Pair<K, V>>.
PObject
Another way to materialize a PCollection is to use PObjects. A PObject<T> is a future, a computation of a value of type T that may not have been completed at the time when the PObject is created in the running program. The computed value can be retrieved by calling getValue() on the PObject, which will block until the computation is completed (by running the Crunch pipeline) before returning the value.
Calling getValue() on a PObject is analogous to calling materialize() on a PCollection, since both calls will trigger execution of the pipeline to materialize the necessary collections. Indeed, we can rewrite the program to lowercase lines in a text file to use a PObject as follows:
Pipeline pipeline = new MRPipeline(getClass());
PCollection<String> lines = pipeline.readTextFile(inputPath);
PCollection<String> lower = lines.parallelDo(new ToLowerFn(), strings());
PObject<Collection<String>> po = lower.asCollection();
for (String s : po.getValue()) { // pipeline is run
System.out.println(s);
}
pipeline.done();
The asCollection() method converts a PCollection<T> into a regular Java Collection<T>.[123] This is done by way of a PObject, so that the conversion can be deferred to a later point in the program’s execution if necessary. In this case, we call PObject’s getValue() immediately after getting the PObject so that we can iterate over the resulting Collection.
WARNING
asCollection() will materialize all the objects in the PCollection into memory, so you should only call it on small PCollection instances, such as the results of a computation that contain only a few objects. There is no such restriction on the use of materialize(), which iterates over the collection, rather than holding the entire collection in memory at once.
At the time of writing, Crunch does not provide a way to evaluate a PObject during pipeline execution, such as from within a DoFn. A PObject may only be inspected after the pipeline execution has finished.
Pipeline Execution
During pipeline construction, Crunch builds an internal execution plan, which is either run explicitly by the user or implicitly by Crunch (as discussed in Materialization). An execution plan is a directed acyclic graph of operations on PCollections, where each PCollection in the plan holds a reference to the operation that produces it, along with the PCollections that are arguments to the operation. In addition, each PCollection has an internal state that records whether it has been materialized or not.
Running a Pipeline
A pipeline’s operations can be explicitly executed by calling Pipeline’s run() method, which performs the following steps.
First, it optimizes the execution plan as a number of stages. The details of the optimization depend on the execution engine — a plan optimized for MapReduce will be different from the same plan optimized for Spark.
Second, it executes each stage in the optimized plan (in parallel, where possible) to materialize the resulting PCollection. PCollections that are to be written to a Target are materialized as the target itself — this might be an output file in HDFS or a table in HBase. IntermediatePCollections are materialized by writing the serialized objects in the collection to a temporary intermediate file in HDFS.
Finally, the run() method returns a PipelineResult object to the caller, with information about each stage that was run (duration and MapReduce counters[124]), as well as whether the pipeline was successful or not (via the succeeded() method).
The clean() method removes all of the temporary intermediate files that were created to materialize PCollections. It should be called after the pipeline is finished with to free up disk space on HDFS. The method takes a Boolean parameter to indicate whether the temporary files should be forcibly deleted. If false, the temporary files will only be deleted if all the targets in the pipeline have been created.
Rather than calling run() followed by clean(false), it is more convenient to call done(), which has the same effect; it signals that the pipeline should be run and then cleaned up since it will not be needed any more.
Asynchronous execution
The run() method is a blocking call that waits until the pipeline has completed before returning. There is a companion method, runAsync(), that returns immediately after the pipeline has been started. You can think of run() as being implemented as follows:
public PipelineResult run() {
PipelineExecution execution = runAsync();
execution.waitUntilDone();
return execution.getResult();
}
There are times when you may want to use the runAsync() method directly; most obviously if you want to run other code while waiting for the pipeline to complete, but also to take advantage of the methods exposed by PipelineExecution, like the ones to inspect the execution plan, find the status of the execution, or stop the pipeline midway through.
PipelineExecution implements Future<PipelineResult> (from java.util.concurrent), offering the following simple idiom for performing background work:
PipelineExecution execution = pipeline.runAsync();
// meanwhile, do other things here
PipelineResult result = execution.get(); // blocks
Debugging
To get more debug information in the MapReduce task logs in the event of a failure, you can call enableDebug() on the Pipeline instance.
Another useful setting is the configuration property crunch.log.job.progress, which, if set to true, will log the MapReduce job progress of each stage to the console:
pipeline.getConfiguration().setBoolean("crunch.log.job.progress", true);
Stopping a Pipeline
Sometimes you might need to stop a pipeline before it completes. Perhaps only moments after starting a pipeline you realized that there’s a programming error in the code, so you’d like to stop the pipeline, fix the problem, and then restart.
If the pipeline was run using the blocking run() or done() calls, then using the standard Java thread interrupt mechanism will cause the run() or done() method to return. However, any jobs running on the cluster will continue running — they will not be killed by Crunch.
Instead, to stop a pipeline properly, it needs to be launched asynchronously in order to retain a reference to the PipelineExecution object:
PipelineExecution execution = pipeline.runAsync();
Stopping the pipeline and its jobs is then just a question of calling the kill() method on PipelineExecution, and waiting for the pipeline to complete:
execution.kill();
execution.waitUntilDone();
At this point, the PipelineExecution’s status will be PipelineExecution.Status.KILLED, and any previously running jobs on the cluster from this pipeline will have been killed. An example of where this pattern could be effectively applied is in a Java VM shutdown hook to safely stop a currently executing pipeline when the Java application is shut down using Ctrl-C.
NOTE
PipelineExecution implements Future<PipelineResult>, so calling kill() can achieve the same effect as calling cancel(true).
Inspecting a Crunch Plan
Sometimes it is useful, or at least enlightening, to inspect the optimized execution plan. The following snippet shows how to obtain a DOT file representation of the graph of operations in a pipeline as a string, and write it to a file (using Guava’s Files utility class). It relies on having access to the PipelineExecution returned from running the pipeline asynchronously:
PipelineExecution execution = pipeline.runAsync();
String dot = execution.getPlanDotFile();
Files.write(dot, new File("pipeline.dot"), Charsets.UTF_8);
execution.waitUntilDone();
pipeline.done();
The dot command-line tool converts the DOT file into a graphical format, such as PNG, for easy inspection. The following invocation converts all DOT files in the current directory to PNG format, so pipeline.dot is converted to a file called pipeline.dot.png:
% dot -Tpng -O *.dot
NOTE
There is a trick for obtaining the DOT file when you don’t have a PipelineExecution object, such as when the pipeline is run synchronously or implicitly (see Materialization). Crunch stores the DOT file representation in the job configuration, so it can be retrieved after the pipeline has finished:
PipelineResult result = pipeline.done();
String dot = pipeline.getConfiguration().get("crunch.planner.dotfile");
Files.write(dot, new File("pipeline.dot"), Charsets.UTF_8);
Let’s look at a plan for a nontrivial pipeline for calculating a histogram of word counts for text files stored in inputPath (see Example 18-3). Production pipelines can grow to be much longer than this one, with dozens of MapReduce jobs, but this illustrates some of the characteristics of the Crunch planner.
Example 18-3. A Crunch pipeline for calculating a histogram of word counts
PCollection<String> lines = pipeline.readTextFile(inputPath);
PCollection<String> lower = lines.parallelDo("lower", new ToLowerFn(), strings());
PTable<String, Long> counts = lower.count();
PTable<Long, String> inverseCounts = counts.parallelDo("inverse",
new InversePairFn<String, Long>(), tableOf(longs(), strings()));
PTable<Long, Integer> hist = inverseCounts
.groupByKey()
.mapValues("count values", new CountValuesFn<String>(), ints());
hist.write(To.textFile(outputPath), Target.WriteMode.OVERWRITE);
pipeline.done();
The plan diagram generated from this pipeline is shown in Figure 18-1.
Sources and targets are rendered as folder icons. The top of the diagram shows the input source, and the output target is shown at the bottom. We can see that there are two MapReduce jobs (labeled Crunch Job 1 and Crunch Job 2), and a temporary sequence file that Crunch generates to write the output of one job to so that the other can read it as input. The temporary file is deleted when clean() is called at the end of the pipeline execution.
Crunch Job 2 (which is actually the one that runs first; it was just produced by the planner second) consists of a map phase and a reduce phase, depicted by labeled boxes in the diagram. Each map and reduce is decomposed into smaller operations, shown by boxes labeled with names that correspond to the names of primitive Crunch operations in the code. For example, the first parallelDo() operation in the map phase is the one labeled lower, which simply lowercases each string in a PCollection.
TIP
Use the overloaded methods of PCollection and related classes that take a name to give meaningful names to the operations in your pipeline. This makes it easier to follow plan diagrams.
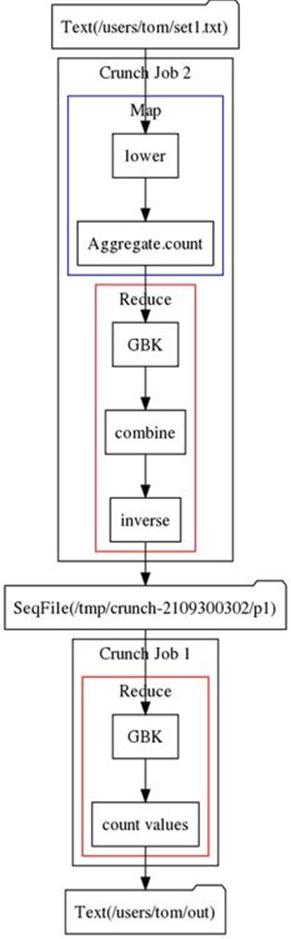
Figure 18-1. Plan diagram for a Crunch pipeline for calculating a histogram of word counts
After the lowercasing operation, the next transformation in the program is to produce a PTable of counts of each unique string, using the built-in convenience method count(). This method actually performs three primitive Crunch operations: a parallelDo() named Aggregate.count, agroupByKey() operation labeled GBK in the diagram, and a combineValues() operation labeled combine.
Each GBK operation is realized as a MapReduce shuffle step, with the groupByKey() and combineValues() operations running in the reduce phase. The Aggregate.count parallelDo() operation runs in the map phase, but notice that it is run in the same map as the lower operation: the Crunch planner attempts to minimize the number of MapReduce jobs that it needs to run for a pipeline. In a similar way, the inverse parallelDo() operation is run as a part of the preceding reduce.[125]
The last transformation is to take the inverted counts PTable and find the frequency of each count. For example, if the strings that occur three times are apple and orange, then the count of 3 has a frequency of 2. This transformation is another GBK operation, which forces a new MapReduce job (Crunch Job 1), followed by a mapValues() operation that we named count values. The mapValues() operation is simply a parallelDo() operation that can therefore be run in the reduce.
Notice that the map phase for Crunch Job 1 is omitted from the diagram since no primitive Crunch operations are run in it.
Iterative Algorithms
A common use of PObjects is to check for convergence in an iterative algorithm. The classic example of a distributed iterative algorithm is the PageRank algorithm for ranking the relative importance of each of a set of linked pages, such as the World Wide Web.[126] The control flow for a Crunch implementation of PageRank looks like this:
PTable<String, PageRankData> scores = readUrls(pipeline, urlInput);
Float delta = 1.0f;
while (delta > 0.01) {
scores = pageRank(scores, 0.5f);
PObject<Float> pDelta = computeDelta(scores);
delta = pDelta.getValue();
}
Without going into detail on the operation of the PageRank algorithm itself, we can understand how the higher-level program execution works in Crunch.
The input is a text file with two URLs per line: a page and an outbound link from that page. For example, the following file encodes the fact that A has links to B and C, and B has a link to D:
www.A.com www.B.com
www.A.com www.C.com
www.B.com www.D.com
Going back to the code, the first line reads the input and computes an initial PageRankData object for each unique page. PageRankData is a simple Java class with fields for the score, the previous score (this will be used to check for convergence), and a list of outbound links:
public static class PageRankData {
public float score;
public float lastScore;
public List<String> urls;
// ... methods elided
}
The goal of the algorithm is to compute a score for each page, representing its relative importance. All pages start out equal, so the initial score is set to be 1 for each page, and the previous score is 0. Creating the list of outbound links is achieved using the Crunch operations of grouping the input by the first field (page), then aggregating the values (outbound links) into a list.[127]
The iteration is carried out using a regular Java while loop. The scores are updated in each iteration of the loop by calling the pageRank() method, which encapsulates the PageRank algorithm as a series of Crunch operations. If the delta between the last set of scores and the new set of scores is below a small enough value (0.01), then the scores have converged and the algorithm terminates. The delta is computed by the computeDelta() method, a Crunch aggregation that finds the largest absolute difference in page score for all the pages in the collection.
So when is the pipeline run? The answer is each time pDelta.getValue() is called. The first time through the loop, no PCollections have been materialized yet, so the jobs for readUrls(), pageRank(), and computeDelta() must be run in order to compute delta. On subsequent iterations only the jobs to compute the new scores (pageRank()) and delta (computeDelta()) need be run.
NOTE
For this pipeline, Crunch’s planner does a better job of optimizing the execution plan if scores.materialize().iterator() is called immediately after the pageRank() call. This ensures that the scores table is explicitly materialized, so it is available for the next execution plan in the next iteration of the loop. Without the call to materialize(), the program still produces the same result, but it’s less efficient: the planner may choose to materialize different intermediate results, and so for the next iteration of the loop some of the computation must be re-executed to get the scores to pass to the pageRank() call.
Checkpointing a Pipeline
In the previous section, we saw that Crunch will reuse any PCollections that were materialized in any previous runs of the same pipeline. However, if you create a new pipeline instance, then it will not automatically share any materialized PCollections from other pipelines, even if the input source is the same. This can make developing a pipeline rather time consuming, since even a small change to a computation toward the end of the pipeline means Crunch will run the new pipeline from the beginning.
The solution is to checkpoint a PCollection to persistent storage (typically HDFS) so that Crunch can start from the checkpoint in the new pipeline.
Consider the Crunch program for calculating a histogram of word counts for text files back in Example 18-3. We saw that the Crunch planner translates this pipeline into two MapReduce jobs. If the program is run for a second time, then Crunch will run the two MapReduce jobs again and overwrite the original output, since WriteMode is set to OVERWRITE.
If instead we checkpointed inverseCounts, a subsequent run would only launch one MapReduce job (the one for computing hist, since it is entirely derived from inverseCounts). Checkpointing is simply a matter of writing a PCollection to a target with the WriteMode set toCHECKPOINT:
PCollection<String> lines = pipeline.readTextFile(inputPath);
PTable<String, Long> counts = lines.count();
PTable<Long, String> inverseCounts = counts.parallelDo(
new InversePairFn<String, Long>(), tableOf(longs(), strings()));
inverseCounts.write(To.sequenceFile(checkpointPath),
Target.WriteMode.CHECKPOINT);
PTable<Long, Integer> hist = inverseCounts
.groupByKey()
.mapValues(new CountValuesFn<String>(), ints());
hist.write(To.textFile(outputPath), Target.WriteMode.OVERWRITE);
pipeline.done();
Crunch compares the timestamps of the input files with those of the checkpoint files; if any inputs have later timestamps than the checkpoints, then it will recompute the dependent checkpoints automatically, so there is no risk of using out-of-date data in the pipeline.
Since they are persistent between pipeline runs, checkpoints are not cleaned up by Crunch, so you will need to delete them once you are happy that the code is producing the expected results.
Crunch Libraries
Crunch comes with a powerful set of library functions in the org.apache.crunch.lib package — they are summarized in Table 18-1.
Table 18-1. Crunch libraries
|
Class |
Method name(s) |
Description |
|
Aggregate |
length() |
Returns the number of elements in a PCollection wrapped in a PObject. |
|
min() |
Returns the smallest value element in a PCollection wrapped in a PObject. |
|
|
max() |
Returns the largest value element in a PCollection wrapped in a PObject. |
|
|
count() |
Returns a table of the unique elements of the input PCollection mapped to their counts. |
|
|
top() |
Returns a table of the top or bottom N key-value pairs in a PTable, ordered by value. |
|
|
collectValues() |
Groups the values for each unique key in a table into a Java Collection, returning a PTable<K, Collection<V>>. |
|
|
Cartesian |
cross() |
Calculates the cross product of two PCollections or PTables. |
|
Channels |
split() |
Splits a collection of pairs (PCollection<Pair<T, U>>) into a pair of collections (Pair<PCollection<T>, PCollection<U>>). |
|
Cogroup |
cogroup() |
Groups the elements in two or more PTables by key. |
|
Distinct |
distinct() |
Creates a new PCollection or PTable with duplicate elements removed. |
|
Join |
join() |
Performs an inner join on two PTables by key. There are also methods for left, right, and full joins. |
|
Mapred |
map() |
Runs a mapper (old API) on a PTable<K1, V1> to produce a PTable<K2, V2>. |
|
reduce() |
Runs a reducer (old API) on a PGroupedTable<K1, V1> to produce a PTable<K2, V2>. |
|
|
Mapreduce |
map(), reduce() |
Like Mapred, but for the new MapReduce API. |
|
PTables |
asPTable() |
Converts a PCollection<Pair<K, V>> to a PTable<K, V>. |
|
keys() |
Returns a PTable’s keys as a PCollection. |
|
|
values() |
Returns a PTable’s values as a PCollection. |
|
|
mapKeys() |
Applies a map function to all the keys in a PTable, leaving the values unchanged. |
|
|
mapValues() |
Applies a map function to all the values in a PTable or PGroupedTable, leaving the keys unchanged. |
|
|
Sample |
sample() |
Creates a sample of a PCollection by choosing each element independently with a specified probability. |
|
reservoirSample() |
Creates a sample of a PCollection of a specified size, where each element is equally likely to be included. |
|
|
SecondarySort |
sortAndApply() |
Sorts a PTable<K, Pair<V1, V2>> by K then V1, then applies a function to give an output PCollection or PTable. |
|
Set |
difference() |
Returns a PCollection that is the set difference of two PCollections. |
|
intersection() |
Returns a PCollection that is the set intersection of two PCollections. |
|
|
comm() |
Returns a PCollection of triples that classifies each element from two PCollections by whether it is only in the first collection, only in the second collection, or in both collections. (Similar to the Unix comm command.) |
|
|
Shard |
shard() |
Creates a PCollection that contains exactly the same elements as the input PCollection, but is partitioned (sharded) across a specified number of files. |
|
Sort |
sort() |
Performs a total sort on a PCollection in the natural order of its elements in ascending (the default) or descending order. There are also methods to sort PTables by key, and collections of Pairs or tuples by a subset of their columns in a specified order. |
One of the most powerful things about Crunch is that if the function you need is not provided, then it is simple to write it yourself, typically in a few lines of Java. For an example of a general-purpose function (for finding the unique values in a PTable), see Example 18-2.
The methods length(), min(), max(), and count() from Aggregate have convenience method equivalents on PCollection. Similarly, top() (as well as the derived method bottom()) and collectValues() from Aggregate, all the methods from PTables, join() from Join, and cogroup()from Cogroup are all duplicated on PTable.
The code in Example 18-4 walks through the behavior of some of the aggregation methods.
Example 18-4. Using the aggregation methods on PCollection and PTable
PCollection<String> a = MemPipeline.typedCollectionOf(strings(),
"cherry", "apple", "banana", "banana");
assertEquals((Long) 4L, a.length().getValue());
assertEquals("apple", a.min().getValue());
assertEquals("cherry", a.max().getValue());
PTable<String, Long> b = a.count();
assertEquals("{(apple,1),(banana,2),(cherry,1)}", dump(b));
PTable<String, Long> c = b.top(1);
assertEquals("{(banana,2)}", dump(c));
PTable<String, Long> d = b.bottom(2);
assertEquals("{(apple,1),(cherry,1)}", dump(d));
Further Reading
This chapter has given a short introduction to Crunch. To find out more, consult the Crunch User Guide.
[118] Some operations do not require a PType, since they can infer it from the PCollection they are applied to. For example, filter() returns a PCollection with the same PType as the original.
[119] Despite the name, APPEND does not append to existing output files.
[120] HBaseTarget does not check for existing outputs, so it behaves as if APPEND mode is used.
[121] See the documentation.
[122] This is an example of where a pipeline gets executed without an explicit call to run() or done(), but it is still good practice to call done() when the pipeline is finished with so that intermediate files are disposed of.
[123] There is also an asMap() method on PTable<K, V> that returns an object of type PObject<Map<K, V>>.
[124] You can increment your own custom counters from Crunch using DoFn’s increment() method.
[125] This optimization is called parallelDo fusion; it explained in more detail in the FlumeJava paper referenced at the beginning of the chapter, along with some of the other optimizations used by Crunch. Note that parallelDo fusion is what allows you to decompose pipeline operations into small, logically separate functions without any loss of efficiency, since Crunch fuses them into as few MapReduce stages as possible.
[126] For details, see Wikipedia.
[127] You can find the full source code in the Crunch integration tests in a class called PageRankIT.
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.