Hadoop: The Definitive Guide (2015)
Part IV. Related Projects
Chapter 21. ZooKeeper
So far in this book, we have been studying large-scale data processing. This chapter is different: it is about building general distributed applications using Hadoop’s distributed coordination service, called ZooKeeper.
Writing distributed applications is hard. It’s hard primarily because of partial failure. When a message is sent across the network between two nodes and the network fails, the sender does not know whether the receiver got the message. It may have gotten through before the network failed, or it may not have. Or perhaps the receiver’s process died. The only way that the sender can find out what happened is to reconnect to the receiver and ask it. This is partial failure: when we don’t even know if an operation failed.
ZooKeeper can’t make partial failures go away, since they are intrinsic to distributed systems. It certainly does not hide partial failures, either.[140] But what ZooKeeper does do is give you a set of tools to build distributed applications that can safely handle partial failures.
ZooKeeper also has the following characteristics:
ZooKeeper is simple
ZooKeeper is, at its core, a stripped-down filesystem that exposes a few simple operations and some extra abstractions, such as ordering and notifications.
ZooKeeper is expressive
The ZooKeeper primitives are a rich set of building blocks that can be used to build a large class of coordination data structures and protocols. Examples include distributed queues, distributed locks, and leader election among a group of peers.
ZooKeeper is highly available
ZooKeeper runs on a collection of machines and is designed to be highly available, so applications can depend on it. ZooKeeper can help you avoid introducing single points of failure into your system, so you can build a reliable application.
ZooKeeper facilitates loosely coupled interactions
ZooKeeper interactions support participants that do not need to know about one another. For example, ZooKeeper can be used as a rendezvous mechanism so that processes that otherwise don’t know of each other’s existence (or network details) can discover and interact with one another. Coordinating parties may not even be contemporaneous, since one process may leave a message in ZooKeeper that is read by another after the first has shut down.
ZooKeeper is a library
ZooKeeper provides an open source, shared repository of implementations and recipes of common coordination patterns. Individual programmers are spared the burden of writing common protocols themselves (which is often difficult to get right). Over time, the community can add to and improve the libraries, which is to everyone’s benefit.
ZooKeeper is highly performant, too. At Yahoo!, where it was created, the throughput for a ZooKeeper cluster has been benchmarked at over 10,000 operations per second for write-dominant workloads generated by hundreds of clients. For workloads where reads dominate, which is the norm, the throughput is several times higher.[141]
Installing and Running ZooKeeper
When trying out ZooKeeper for the first time, it’s simplest to run it in standalone mode with a single ZooKeeper server. You can do this on a development machine, for example. ZooKeeper requires Java to run, so make sure you have it installed first.
Download a stable release of ZooKeeper from the Apache ZooKeeper releases page, and unpack the tarball in a suitable location:
% tar xzf zookeeper-x.y.z.tar.gz
ZooKeeper provides a few binaries to run and interact with the service, and it’s convenient to put the directory containing the binaries on your command-line path:
% export ZOOKEEPER_HOME=~/sw/zookeeper-x.y.z
% export PATH=$PATH:$ZOOKEEPER_HOME/bin
Before running the ZooKeeper service, we need to set up a configuration file. The configuration file is conventionally called zoo.cfg and placed in the conf subdirectory (although you can also place it in /etc/zookeeper, or in the directory defined by the ZOOCFGDIR environment variable, if set). Here’s an example:
tickTime=2000
dataDir=/Users/tom/zookeeper
clientPort=2181
This is a standard Java properties file, and the three properties defined in this example are the minimum required for running ZooKeeper in standalone mode. Briefly, tickTime is the basic time unit in ZooKeeper (specified in milliseconds), dataDir is the local filesystem location where ZooKeeper stores persistent data, and clientPort is the port ZooKeeper listens on for client connections (2181 is a common choice). You should change dataDir to an appropriate setting for your system.
With a suitable configuration defined, we are now ready to start a local ZooKeeper server:
% zkServer.sh start
To check whether ZooKeeper is running, send the ruok command (“Are you OK?”) to the client port using nc (telnet works, too):
% echo ruok | nc localhost 2181
imok
That’s ZooKeeper saying, “I’m OK.” Table 21-1 lists the commands, known as the “four-letter words,” for managing ZooKeeper.
Table 21-1. ZooKeeper commands: the four-letter words
|
Category |
Command |
Description |
|
Server status |
ruok |
Prints imok if the server is running and not in an error state. |
|
conf |
Prints the server configuration (from zoo.cfg). |
|
|
envi |
Prints the server environment, including ZooKeeper version, Java version, and other system properties. |
|
|
srvr |
Prints server statistics, including latency statistics, the number of znodes, and the server mode (standalone, leader, or follower). |
|
|
stat |
Prints server statistics and connected clients. |
|
|
srst |
Resets server statistics. |
|
|
isro |
Shows whether the server is in read-only (ro) mode (due to a network partition) or read/write mode (rw). |
|
|
Client connections |
dump |
Lists all the sessions and ephemeral znodes for the ensemble. You must connect to the leader (see srvr) for this command. |
|
cons |
Lists connection statistics for all the server’s clients. |
|
|
crst |
Resets connection statistics. |
|
|
Watches |
wchs |
Lists summary information for the server’s watches. |
|
wchc |
Lists all the server’s watches by connection. Caution: may impact server performance for a large number of watches. |
|
|
wchp |
Lists all the server’s watches by znode path. Caution: may impact server performance for a large number of watches. |
|
|
Monitoring |
mntr |
Lists server statistics in Java properties format, suitable as a source for monitoring systems such as Ganglia and Nagios. |
In addition to the mntr command, ZooKeeper exposes statistics via JMX. For more details, see the ZooKeeper documentation. There are also monitoring tools and recipes in the src/contrib directory of the distribution.
From version 3.5.0 of ZooKeeper, there is an inbuilt web server for providing the same information as the four-letter words. Visit http://localhost:8080/commands for a list of commands.
An Example
Imagine a group of servers that provide some service to clients. We want clients to be able to locate one of the servers so they can use the service. One of the challenges is maintaining the list of servers in the group.
The membership list clearly cannot be stored on a single node in the network, as the failure of that node would mean the failure of the whole system (we would like the list to be highly available). Suppose for a moment that we had a robust way of storing the list. We would still have the problem of how to remove a server from the list if it failed. Some process needs to be responsible for removing failed servers, but note that it can’t be the servers themselves, because they are no longer running!
What we are describing is not a passive distributed data structure, but an active one, and one that can change the state of an entry when some external event occurs. ZooKeeper provides this service, so let’s see how to build this group membership application (as it is known) with it.
Group Membership in ZooKeeper
One way of understanding ZooKeeper is to think of it as providing a high-availability filesystem. It doesn’t have files and directories, but a unified concept of a node, called a znode, that acts both as a container of data (like a file) and a container of other znodes (like a directory). Znodes form a hierarchical namespace, and a natural way to build a membership list is to create a parent znode with the name of the group and child znodes with the names of the group members (servers). This is shown in Figure 21-1.
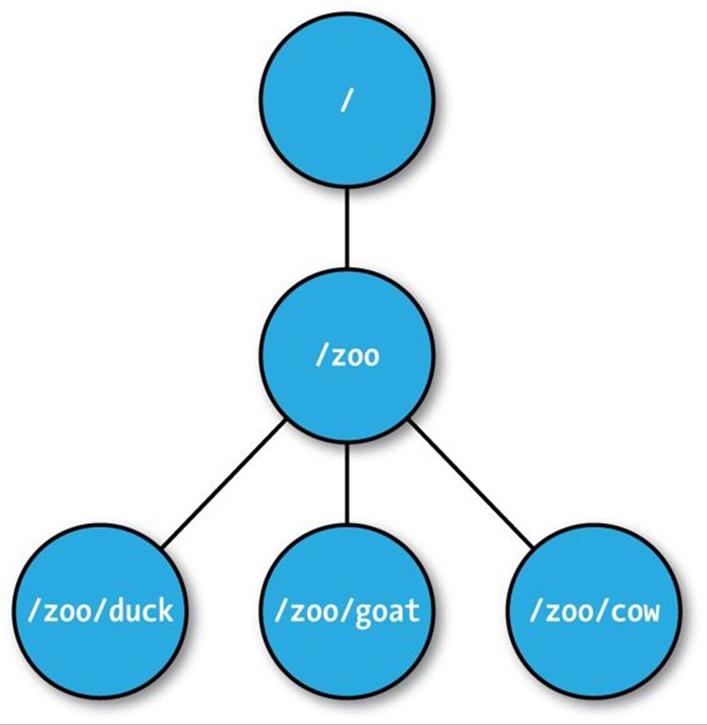
Figure 21-1. ZooKeeper znodes
In this example we won’t store data in any of the znodes, but in a real application you could imagine storing data about the members, such as hostnames, in their znodes.
Creating the Group
Let’s introduce ZooKeeper’s Java API by writing a program to create a znode for the group, which is /zoo in Example 21-1.
Example 21-1. A program to create a znode representing a group in ZooKeeper
public class CreateGroup implements Watcher {
private static final int SESSION_TIMEOUT = 5000;
private ZooKeeper zk;
private CountDownLatch connectedSignal = new CountDownLatch(1);
public void connect(String hosts) throws IOException, InterruptedException {
zk = new ZooKeeper(hosts, SESSION_TIMEOUT, this);
connectedSignal.await();
}
@Override
public void process(WatchedEvent event) { // Watcher interface
if (event.getState() == KeeperState.SyncConnected) {
connectedSignal.countDown();
}
}
public void create(String groupName) throws KeeperException,
InterruptedException {
String path = "/" + groupName;
String createdPath = zk.create(path, null/*data*/, Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT);
System.out.println("Created " + createdPath);
}
public void close() throws InterruptedException {
zk.close();
}
public static void main(String[] args) throws Exception {
CreateGroup createGroup = new CreateGroup();
createGroup.connect(args[0]);
createGroup.create(args[1]);
createGroup.close();
}
}
When the main() method is run, it creates a CreateGroup instance and then calls its connect() method. This method instantiates a new ZooKeeper object, which is the central class of the client API and the one that maintains the connection between the client and the ZooKeeper service. The constructor takes three arguments: the first is the host address (and optional port, which defaults to 2181) of the ZooKeeper service;[142] the second is the session timeout in milliseconds (which we set to 5 seconds), explained in more detail later; and the third is an instance of aWatcher object. The Watcher object receives callbacks from ZooKeeper to inform it of various events. In this scenario, CreateGroup is a Watcher, so we pass this to the ZooKeeper constructor.
When a ZooKeeper instance is created, it starts a thread to connect to the ZooKeeper service. The call to the constructor returns immediately, so it is important to wait for the connection to be established before using the ZooKeeper object. We make use of Java’s CountDownLatch class (in the java.util.concurrent package) to block until the ZooKeeper instance is ready. This is where the Watcher comes in. The Watcher interface has a single method:
public void process(WatchedEvent event);
When the client has connected to ZooKeeper, the Watcher receives a call to its process() method with an event indicating that it has connected. On receiving a connection event (represented by the Watcher.Event.KeeperState enum, with value SyncConnected), we decrement the counter in the CountDownLatch, using its countDown() method. The latch was created with a count of one, representing the number of events that need to occur before it releases all waiting threads. After calling countDown() once, the counter reaches zero and the await() method returns.
The connect() method has now returned, and the next method to be invoked on the CreateGroup is the create() method. In this method, we create a new ZooKeeper znode using the create() method on the ZooKeeper instance. The arguments it takes are the path (represented by a string), the contents of the znode (a byte array null here), an access control list (or ACL for short, which here is completely open, allowing any client to read from or write to the znode), and the nature of the znode to be created.
Znodes may be ephemeral or persistent. An ephemeral znode will be deleted by the ZooKeeper service when the client that created it disconnects, either explicitly or because the client terminates for whatever reason. A persistent znode, on the other hand, is not deleted when the client disconnects. We want the znode representing a group to live longer than the lifetime of the program that creates it, so we create a persistent znode.
The return value of the create() method is the path that was created by ZooKeeper. We use it to print a message that the path was successfully created. We will see how the path returned by create() may differ from the one passed into the method when we look at sequential znodes.
To see the program in action, we need to have ZooKeeper running on the local machine, and then we can use the following:
% export CLASSPATH=ch21-zk/target/classes/:$ZOOKEEPER_HOME/*:\
$ZOOKEEPER_HOME/lib/*:$ZOOKEEPER_HOME/conf
% java CreateGroup localhost zoo
Created /zoo
Joining a Group
The next part of the application is a program to register a member in a group. Each member will run as a program and join a group. When the program exits, it should be removed from the group, which we can do by creating an ephemeral znode that represents it in the ZooKeeper namespace.
The JoinGroup program implements this idea, and its listing is in Example 21-2. The logic for creating and connecting to a ZooKeeper instance has been refactored into a base class, ConnectionWatcher, and appears in Example 21-3.
Example 21-2. A program that joins a group
public class JoinGroup extends ConnectionWatcher {
public void join(String groupName, String memberName) throws KeeperException,
InterruptedException {
String path = "/" + groupName + "/" + memberName;
String createdPath = zk.create(path, null/*data*/, Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL);
System.out.println("Created " + createdPath);
}
public static void main(String[] args) throws Exception {
JoinGroup joinGroup = new JoinGroup();
joinGroup.connect(args[0]);
joinGroup.join(args[1], args[2]);
// stay alive until process is killed or thread is interrupted
Thread.sleep(Long.MAX_VALUE);
}
}
Example 21-3. A helper class that waits for the ZooKeeper connection to be established
public class ConnectionWatcher implements Watcher {
private static final int SESSION_TIMEOUT = 5000;
protected ZooKeeper zk;
private CountDownLatch connectedSignal = new CountDownLatch(1);
public void connect(String hosts) throws IOException, InterruptedException {
zk = new ZooKeeper(hosts, SESSION_TIMEOUT, this);
connectedSignal.await();
}
@Override
public void process(WatchedEvent event) {
if (event.getState() == KeeperState.SyncConnected) {
connectedSignal.countDown();
}
}
public void close() throws InterruptedException {
zk.close();
}
}
The code for JoinGroup is very similar to CreateGroup. It creates an ephemeral znode as a child of the group znode in its join() method, then simulates doing work of some kind by sleeping until the process is forcibly terminated. Later, you will see that upon termination, the ephemeral znode is removed by ZooKeeper.
Listing Members in a Group
Now we need a program to find the members in a group (see Example 21-4).
Example 21-4. A program to list the members in a group
public class ListGroup extends ConnectionWatcher {
public void list(String groupName) throws KeeperException,
InterruptedException {
String path = "/" + groupName;
try {
List<String> children = zk.getChildren(path, false);
if (children.isEmpty()) {
System.out.printf("No members in group %s\n", groupName);
System.exit(1);
}
for (String child : children) {
System.out.println(child);
}
} catch (KeeperException.NoNodeException e) {
System.out.printf("Group %s does not exist\n", groupName);
System.exit(1);
}
}
public static void main(String[] args) throws Exception {
ListGroup listGroup = new ListGroup();
listGroup.connect(args[0]);
listGroup.list(args[1]);
listGroup.close();
}
}
In the list() method, we call getChildren() with a znode path and a watch flag to retrieve a list of child paths for the znode, which we print out. Placing a watch on a znode causes the registered Watcher to be triggered if the znode changes state. Although we’re not using it here, watching a znode’s children would permit a program to get notifications of members joining or leaving the group, or of the group being deleted.
We catch KeeperException.NoNodeException, which is thrown in the case when the group’s znode does not exist.
Let’s see ListGroup in action. As expected, the zoo group is empty, since we haven’t added any members yet:
% java ListGroup localhost zoo
No members in group zoo
We can use JoinGroup to add some members. We launch them as background processes, since they don’t terminate on their own (due to the sleep statement):
% java JoinGroup localhost zoo duck &
% java JoinGroup localhost zoo cow &
% java JoinGroup localhost zoo goat &
% goat_pid=$!
The last line saves the process ID of the Java process running the program that adds goat as a member. We need to remember the ID so that we can kill the process in a moment, after checking the members:
% java ListGroup localhost zoo
goat
duck
cow
To remove a member, we kill its process:
% kill $goat_pid
And a few seconds later, it has disappeared from the group because the process’s ZooKeeper session has terminated (the timeout was set to 5 seconds) and its associated ephemeral node has been removed:
% java ListGroup localhost zoo
duck
cow
Let’s stand back and see what we’ve built here. We have a way of building up a list of a group of nodes that are participating in a distributed system. The nodes may have no knowledge of each other. A client that wants to use the nodes in the list to perform some work, for example, can discover the nodes without them being aware of the client’s existence.
Finally, note that group membership is not a substitution for handling network errors when communicating with a node. Even if a node is a group member, communications with it may fail, and such failures must be handled in the usual ways (retrying, trying a different member of the group, etc.).
ZooKeeper command-line tools
ZooKeeper comes with a command-line tool for interacting with the ZooKeeper namespace. We can use it to list the znodes under the /zoo znode as follows:
% zkCli.sh -server localhost ls /zoo
[cow, duck]
You can run the command without arguments to display usage instructions.
Deleting a Group
To round off the example, let’s see how to delete a group. The ZooKeeper class provides a delete() method that takes a path and a version number. ZooKeeper will delete a znode only if the version number specified is the same as the version number of the znode it is trying to delete — an optimistic locking mechanism that allows clients to detect conflicts over znode modification. You can bypass the version check, however, by using a version number of –1 to delete the znode regardless of its version number.
There is no recursive delete operation in ZooKeeper, so you have to delete child znodes before parents. This is what we do in the DeleteGroup class, which will remove a group and all its members (Example 21-5).
Example 21-5. A program to delete a group and its members
public class DeleteGroup extends ConnectionWatcher {
public void delete(String groupName) throws KeeperException,
InterruptedException {
String path = "/" + groupName;
try {
List<String> children = zk.getChildren(path, false);
for (String child : children) {
zk.delete(path + "/" + child, -1);
}
zk.delete(path, -1);
} catch (KeeperException.NoNodeException e) {
System.out.printf("Group %s does not exist\n", groupName);
System.exit(1);
}
}
public static void main(String[] args) throws Exception {
DeleteGroup deleteGroup = new DeleteGroup();
deleteGroup.connect(args[0]);
deleteGroup.delete(args[1]);
deleteGroup.close();
}
}
Finally, we can delete the zoo group that we created earlier:
% java DeleteGroup localhost zoo
% java ListGroup localhost zoo
Group zoo does not exist
The ZooKeeper Service
ZooKeeper is a highly available, high-performance coordination service. In this section, we look at the nature of the service it provides: its model, operations, and implementation.
Data Model
ZooKeeper maintains a hierarchical tree of nodes called znodes. A znode stores data and has an associated ACL. ZooKeeper is designed for coordination (which typically uses small datafiles), not high-volume data storage, so there is a limit of 1 MB on the amount of data that may be stored in any znode.
Data access is atomic. A client reading the data stored in a znode will never receive only some of the data; either the data will be delivered in its entirety or the read will fail. Similarly, a write will replace all the data associated with a znode. ZooKeeper guarantees that the write will either succeed or fail; there is no such thing as a partial write, where only some of the data written by the client is stored. ZooKeeper does not support an append operation. These characteristics contrast with HDFS, which is designed for high-volume data storage with streaming data access and provides an append operation.
Znodes are referenced by paths, which in ZooKeeper are represented as slash-delimited Unicode character strings, like filesystem paths in Unix. Paths must be absolute, so they must begin with a slash character. Furthermore, they are canonical, which means that each path has a single representation, and so paths do not undergo resolution. For example, in Unix, a file with the path /a/b can equivalently be referred to by the path /a/./b because “.” refers to the current directory at the point it is encountered in the path. In ZooKeeper, “.” does not have this special meaning and is actually illegal as a path component (as is “..” for the parent of the current directory).
Path components are composed of Unicode characters, with a few restrictions (these are spelled out in the ZooKeeper reference documentation). The string “zookeeper” is a reserved word and may not be used as a path component. In particular, ZooKeeper uses the /zookeeper subtree to store management information, such as information on quotas.
Note that paths are not URIs, and they are represented in the Java API by a java.lang.String, rather than the Hadoop Path class (or the java.net.URI class, for that matter).
Znodes have some properties that are very useful for building distributed applications, which we discuss in the following sections.
Ephemeral znodes
As we’ve seen, znodes can be one of two types: ephemeral or persistent. A znode’s type is set at creation time and may not be changed later. An ephemeral znode is deleted by ZooKeeper when the creating client’s session ends. By contrast, a persistent znode is not tied to the client’s session and is deleted only when explicitly deleted by a client (not necessarily the one that created it). An ephemeral znode may not have children, not even ephemeral ones.
Even though ephemeral nodes are tied to a client session, they are visible to all clients (subject to their ACL policies, of course).
Ephemeral znodes are ideal for building applications that need to know when certain distributed resources are available. The example earlier in this chapter uses ephemeral znodes to implement a group membership service, so any process can discover the members of the group at any particular time.
Sequence numbers
A sequential znode is given a sequence number by ZooKeeper as a part of its name. If a znode is created with the sequential flag set, then the value of a monotonically increasing counter (maintained by the parent znode) is appended to its name.
If a client asks to create a sequential znode with the name /a/b-, for example, the znode created may actually have the name /a/b-3.[143] If, later on, another sequential znode with the name /a/b- is created, it will be given a unique name with a larger value of the counter — for example,/a/b-5. In the Java API, the actual path given to sequential znodes is communicated back to the client as the return value of the create() call.
Sequence numbers can be used to impose a global ordering on events in a distributed system and may be used by the client to infer the ordering. In A Lock Service, you will learn how to use sequential znodes to build a shared lock.
Watches
Watches allow clients to get notifications when a znode changes in some way. Watches are set by operations on the ZooKeeper service and are triggered by other operations on the service. For example, a client might call the exists operation on a znode, placing a watch on it at the same time. If the znode doesn’t exist, the exists operation will return false. If, some time later, the znode is created by a second client, the watch is triggered, notifying the first client of the znode’s creation. You will see precisely which operations trigger others in the next section.
Watchers are triggered only once.[144] To receive multiple notifications, a client needs to reregister the watch. So, if the client in the previous example wishes to receive further notifications for the znode’s existence (to be notified when it is deleted, for example), it needs to call theexists operation again to set a new watch.
There is an example in A Configuration Service demonstrating how to use watches to update configuration across a cluster.
Operations
There are nine basic operations in ZooKeeper, listed in Table 21-2.
Table 21-2. Operations in the ZooKeeper service
|
Operation |
Description |
|
create |
Creates a znode (the parent znode must already exist) |
|
delete |
Deletes a znode (the znode must not have any children) |
|
exists |
Tests whether a znode exists and retrieves its metadata |
|
getACL, setACL |
Gets/sets the ACL for a znode |
|
getChildren |
Gets a list of the children of a znode |
|
getData, setData |
Gets/sets the data associated with a znode |
|
sync |
Synchronizes a client’s view of a znode with ZooKeeper |
Update operations in ZooKeeper are conditional. A delete or setData operation has to specify the version number of the znode that is being updated (which is found from a previous exists call). If the version number does not match, the update will fail. Updates are a nonblocking operation, so a client that loses an update (because another process updated the znode in the meantime) can decide whether to try again or take some other action, and it can do so without blocking the progress of any other process.
Although ZooKeeper can be viewed as a filesystem, there are some filesystem primitives that it does away with in the name of simplicity. Because files are small and are written and read in their entirety, there is no need to provide open, close, or seek operations.
WARNING
The sync operation is not like fsync() in POSIX filesystems. As mentioned earlier, writes in ZooKeeper are atomic, and a successful write operation is guaranteed to have been written to persistent storage on a majority of ZooKeeper servers. However, it is permissible for reads to lag the latest state of the ZooKeeper service, and the sync operation exists to allow a client to bring itself up to date. This topic is covered in more detail in Consistency.
Multiupdate
There is another ZooKeeper operation, called multi, that batches together multiple primitive operations into a single unit that either succeeds or fails in its entirety. The situation where some of the primitive operations succeed and some fail can never arise.
Multiupdate is very useful for building structures in ZooKeeper that maintain some global invariant. One example is an undirected graph. Each vertex in the graph is naturally represented as a znode in ZooKeeper, and to add or remove an edge we need to update the two znodes corresponding to its vertices because each has a reference to the other. If we used only primitive ZooKeeper operations, it would be possible for another client to observe the graph in an inconsistent state, where one vertex is connected to another but the reverse connection is absent. Batching the updates on the two znodes into one multi operation ensures that the update is atomic, so a pair of vertices can never have a dangling connection.
APIs
There are two core language bindings for ZooKeeper clients, one for Java and one for C; there are also contrib bindings for Perl, Python, and REST clients. For each binding, there is a choice between performing operations synchronously or asynchronously. We’ve already seen the synchronous Java API. Here’s the signature for the exists operation, which returns either a Stat object that encapsulates the znode’s metadata or null if the znode doesn’t exist:
public Stat exists(String path, Watcher watcher) throws KeeperException,
InterruptedException
The asynchronous equivalent, which is also found in the ZooKeeper class, looks like this:
public void exists(String path, Watcher watcher, StatCallback cb, Object ctx)
In the Java API, all the asynchronous methods have void return types, since the result of the operation is conveyed via a callback. The caller passes a callback implementation whose method is invoked when a response is received from ZooKeeper. In this case, the callback is theStatCallback interface, which has the following method:
public void processResult(int rc, String path, Object ctx, Stat stat);
The rc argument is the return code, corresponding to the codes defined by KeeperException. A nonzero code represents an exception, in which case the stat parameter will be null. The path and ctx arguments correspond to the equivalent arguments passed by the client to theexists() method, and can be used to identify the request for which this callback is a response. The ctx parameter can be an arbitrary object that may be used by the client when the path does not give enough context to disambiguate the request. If not needed, it may be set to null.
There are actually two C shared libraries. The single-threaded library, zookeeper_st, supports only the asynchronous API and is intended for platforms where the pthread library is not available or stable. Most developers will use the multithreaded library, zookeeper_mt, as it supports both the synchronous and asynchronous APIs. For details on how to build and use the C API, refer to the README file in the src/c directory of the ZooKeeper distribution.
SHOULD I USE THE SYNCHRONOUS OR ASYNCHRONOUS API?
Both APIs offer the same functionality, so the one you use is largely a matter of style. The asynchronous API is appropriate if you have an event-driven programming model, for example.
The asynchronous API allows you to pipeline requests, which in some scenarios can offer better throughput. Imagine that you want to read a large batch of znodes and process them independently. Using the synchronous API, each read would block until it returned, whereas with the asynchronous API, you can fire off all the asynchronous reads very quickly and process the responses in a separate thread as they come back.
Watch triggers
The read operations exists, getChildren, and getData may have watches set on them, and the watches are triggered by write operations: create, delete, and setData. ACL operations do not participate in watches. When a watch is triggered, a watch event is generated, and the watch event’s type depends both on the watch and the operation that triggered it:
§ A watch set on an exists operation will be triggered when the znode being watched is created, deleted, or has its data updated.
§ A watch set on a getData operation will be triggered when the znode being watched is deleted or has its data updated. No trigger can occur on creation because the znode must already exist for the getData operation to succeed.
§ A watch set on a getChildren operation will be triggered when a child of the znode being watched is created or deleted, or when the znode itself is deleted. You can tell whether the znode or its child was deleted by looking at the watch event type: NodeDeleted shows the znode was deleted, and NodeChildrenChanged indicates that it was a child that was deleted.
The combinations are summarized in Table 21-3.
Table 21-3. Watch creation operations and their corresponding triggers
|
Watch trigger |
|||||
|
Watch creation |
create znode |
create child |
delete znode |
delete child |
setData |
|
exists |
NodeCreated |
NodeDeleted |
NodeDataChanged |
||
|
getData |
NodeDeleted |
NodeDataChanged |
|||
|
getChildren |
NodeChildrenChanged |
NodeDeleted |
NodeChildrenChanged |
||
A watch event includes the path of the znode that was involved in the event, so for NodeCreated and NodeDeleted events, you can tell which node was created or deleted simply by inspecting the path. To discover which children have changed after a NodeChildrenChanged event, you need to call getChildren again to retrieve the new list of children. Similarly, to discover the new data for a NodeDataChanged event, you need to call getData. In both of these cases, the state of the znodes may have changed between receiving the watch event and performing the read operation, so you should bear this in mind when writing applications.
ACLs
A znode is created with a list of ACLs, which determine who can perform certain operations on it.
ACLs depend on authentication, the process by which the client identifies itself to ZooKeeper. There are a few authentication schemes that ZooKeeper provides:
digest
The client is authenticated by a username and password.
sasl
The client is authenticated using Kerberos.
ip
The client is authenticated by its IP address.
Clients may authenticate themselves after establishing a ZooKeeper session. Authentication is optional, although a znode’s ACL may require an authenticated client, in which case the client must authenticate itself to access the znode. Here is an example of using the digest scheme to authenticate with a username and password:
zk.addAuthInfo("digest", "tom:secret".getBytes());
An ACL is the combination of an authentication scheme, an identity for that scheme, and a set of permissions. For example, if we wanted to give a client with the IP address 10.0.0.1 read access to a znode, we would set an ACL on the znode with the ip scheme, an ID of 10.0.0.1, and READ permission. In Java, we would create the ACL object as follows:
new ACL(Perms.READ,
new Id("ip", "10.0.0.1"));
The full set of permissions are listed in Table 21-4. Note that the exists operation is not governed by an ACL permission, so any client may call exists to find the Stat for a znode or to discover that a znode does not in fact exist.
Table 21-4. ACL permissions
|
ACL permission |
Permitted operations |
|
CREATE |
create (a child znode) |
|
READ |
getChildren |
|
getData |
|
|
WRITE |
setData |
|
DELETE |
delete (a child znode) |
|
ADMIN |
setACL |
There are a number of predefined ACLs in the ZooDefs.Ids class, including OPEN_ACL_UNSAFE, which gives all permissions (except ADMIN permission) to everyone.
In addition, ZooKeeper has a pluggable authentication mechanism, which makes it possible to integrate third-party authentication systems if needed.
Implementation
The ZooKeeper service can run in two modes. In standalone mode, there is a single ZooKeeper server, which is useful for testing due to its simplicity (it can even be embedded in unit tests) but provides no guarantees of high availability or resilience. In production, ZooKeeper runs inreplicated mode on a cluster of machines called an ensemble. ZooKeeper achieves high availability through replication, and can provide a service as long as a majority of the machines in the ensemble are up. For example, in a five-node ensemble, any two machines can fail and the service will still work because a majority of three remain. Note that a six-node ensemble can also tolerate only two machines failing, because if three machines fail, the remaining three do not constitute a majority of the six. For this reason, it is usual to have an odd number of machines in an ensemble.
Conceptually, ZooKeeper is very simple: all it has to do is ensure that every modification to the tree of znodes is replicated to a majority of the ensemble. If a minority of the machines fail, then a minimum of one machine will survive with the latest state. The other remaining replicas will eventually catch up with this state.
The implementation of this simple idea, however, is nontrivial. ZooKeeper uses a protocol called Zab that runs in two phases, which may be repeated indefinitely:
Phase 1: Leader election
The machines in an ensemble go through a process of electing a distinguished member, called the leader. The other machines are termed followers. This phase is finished once a majority (or quorum) of followers have synchronized their state with the leader.
Phase 2: Atomic broadcast
All write requests are forwarded to the leader, which broadcasts the update to the followers. When a majority have persisted the change, the leader commits the update, and the client gets a response saying the update succeeded. The protocol for achieving consensus is designed to be atomic, so a change either succeeds or fails. It resembles a two-phase commit.
DOES ZOOKEEPER USE PAXOS?
No. ZooKeeper’s Zab protocol is not the same as the well-known Paxos algorithm.[145] Zab is similar, but it differs in several aspects of its operation, such as relying on TCP for its message ordering guarantees.[146]
Google’s Chubby Lock Service,[147] which shares similar goals with ZooKeeper, is based on Paxos.
If the leader fails, the remaining machines hold another leader election and continue as before with the new leader. If the old leader later recovers, it then starts as a follower. Leader election is very fast, around 200 ms according to one published result, so performance does not noticeably degrade during an election.
All machines in the ensemble write updates to disk before updating their in-memory copies of the znode tree. Read requests may be serviced from any machine, and because they involve only a lookup from memory, they are very fast.
Consistency
Understanding the basis of ZooKeeper’s implementation helps in understanding the consistency guarantees that the service makes. The terms “leader” and “follower” for the machines in an ensemble are apt because they make the point that a follower may lag the leader by a number of updates. This is a consequence of the fact that only a majority and not all members of the ensemble need to have persisted a change before it is committed. A good mental model for ZooKeeper is of clients connected to ZooKeeper servers that are following the leader. A client may actually be connected to the leader, but it has no control over this and cannot even know if this is the case.[148] See Figure 21-2.
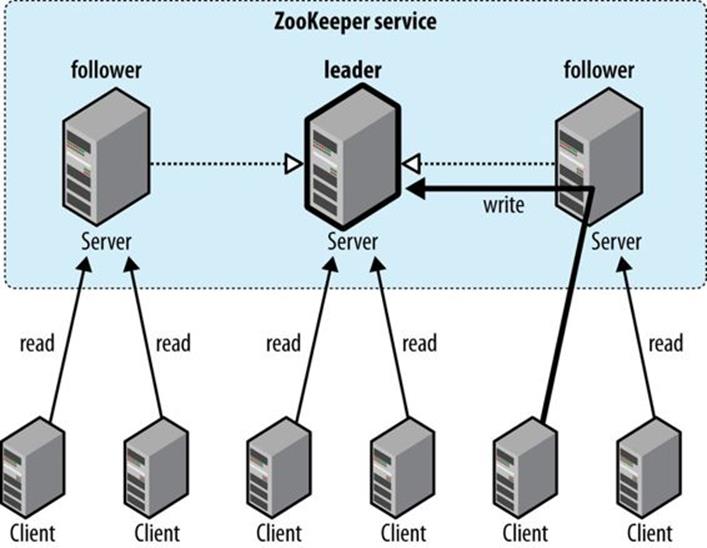
Figure 21-2. Reads are satisfied by followers, whereas writes are committed by the leader
Every update made to the znode tree is given a globally unique identifier, called a zxid (which stands for “ZooKeeper transaction ID”). Updates are ordered, so if zxid z1 is less than z2, then z1 happened before z2, according to ZooKeeper (which is the single authority on ordering in the distributed system).
The following guarantees for data consistency flow from ZooKeeper’s design:
Sequential consistency
Updates from any particular client are applied in the order that they are sent. This means that if a client updates the znode z to the value a, and in a later operation, it updates z to the value b, then no client will ever see z with value a after it has seen it with value b (if no other updates are made to z).
Atomicity
Updates either succeed or fail. This means that if an update fails, no client will ever see it.
Single system image
A client will see the same view of the system, regardless of the server it connects to. This means that if a client connects to a new server during the same session, it will not see an older state of the system than the one it saw with the previous server. When a server fails and a client tries to connect to another in the ensemble, a server that is behind the one that failed will not accept connections from the client until it has caught up with the failed server.
Durability
Once an update has succeeded, it will persist and will not be undone. This means updates will survive server failures.
Timeliness
The lag in any client’s view of the system is bounded, so it will not be out of date by more than some multiple of tens of seconds. This means that rather than allow a client to see data that is very stale, a server will shut down, forcing the client to switch to a more up-to-date server.
For performance reasons, reads are satisfied from a ZooKeeper server’s memory and do not participate in the global ordering of writes. This property can lead to the appearance of inconsistent ZooKeeper states from clients that communicate through a mechanism outside ZooKeeper: for example, client A updates znode z from a to a’, A tells B to read z, and B reads the value of z as a, not a’. This is perfectly compatible with the guarantees that ZooKeeper makes (the condition that it does not promise is called “simultaneously consistent cross-client views”). To prevent this condition from happening, B should call sync on z before reading z’s value. The sync operation forces the ZooKeeper server to which B is connected to “catch up” with the leader, so that when B reads z’s value, it will be the one that A set (or a later value).
NOTE
Slightly confusingly, the sync operation is available only as an asynchronous call. This is because you don’t need to wait for it to return, since ZooKeeper guarantees that any subsequent operation will happen after the sync completes on the server, even if the operation is issued before the sync completes.
Sessions
A ZooKeeper client is configured with the list of servers in the ensemble. On startup, it tries to connect to one of the servers in the list. If the connection fails, it tries another server in the list, and so on, until it either successfully connects to one of them or fails because all ZooKeeper servers are unavailable.
Once a connection has been made with a ZooKeeper server, the server creates a new session for the client. A session has a timeout period that is decided on by the application that creates it. If the server hasn’t received a request within the timeout period, it may expire the session. Once a session has expired, it may not be reopened, and any ephemeral nodes associated with the session will be lost. Although session expiry is a comparatively rare event, since sessions are long lived, it is important for applications to handle it (we will see how in The Resilient ZooKeeper Application).
Sessions are kept alive by the client sending ping requests (also known as heartbeats) whenever the session is idle for longer than a certain period. (Pings are automatically sent by the ZooKeeper client library, so your code doesn’t need to worry about maintaining the session.) The period is chosen to be low enough to detect server failure (manifested by a read timeout) and reconnect to another server within the session timeout period.
Failover to another ZooKeeper server is handled automatically by the ZooKeeper client, and crucially, sessions (and associated ephemeral znodes) are still valid after another server takes over from the failed one.
During failover, the application will receive notifications of disconnections and connections to the service. Watch notifications will not be delivered while the client is disconnected, but they will be delivered when the client successfully reconnects. Also, if the application tries to perform an operation while the client is reconnecting to another server, the operation will fail. This underlines the importance of handling connection loss exceptions in real-world ZooKeeper applications (described in The Resilient ZooKeeper Application).
Time
There are several time parameters in ZooKeeper. The tick time is the fundamental period of time in ZooKeeper and is used by servers in the ensemble to define the schedule on which their interactions run. Other settings are defined in terms of tick time, or are at least constrained by it. The session timeout, for example, may not be less than 2 ticks or more than 20. If you attempt to set a session timeout outside this range, it will be modified to fall within the range.
A common tick time setting is 2 seconds (2,000 milliseconds). This translates to an allowable session timeout of between 4 and 40 seconds.
There are a few considerations in selecting a session timeout. A low session timeout leads to faster detection of machine failure. In the group membership example, the session timeout is the time it takes for a failed machine to be removed from the group. Beware of setting the session timeout too low, however, because a busy network can cause packets to be delayed and may cause inadvertent session expiry. In such an event, a machine would appear to “flap”: leaving and then rejoining the group repeatedly in a short space of time.
Applications that create more complex ephemeral state should favor longer session timeouts, as the cost of reconstruction is higher. In some cases, it is possible to design the application so it can restart within the session timeout period and avoid session expiry. (This might be desirable to perform maintenance or upgrades.) Every session is given a unique identity and password by the server, and if these are passed to ZooKeeper while a connection is being made, it is possible to recover a session (as long as it hasn’t expired). An application can therefore arrange a graceful shutdown, whereby it stores the session identity and password to stable storage before restarting the process, retrieving the stored session identity and password, and recovering the session.
You should view this feature as an optimization that can help avoid expired sessions. It does not remove the need to handle session expiry, which can still occur if a machine fails unexpectedly, or even if an application is shut down gracefully but does not restart before its session expires, for whatever reason.
As a general rule, the larger the ZooKeeper ensemble, the larger the session timeout should be. Connection timeouts, read timeouts, and ping periods are all defined internally as a function of the number of servers in the ensemble, so as the ensemble grows, these periods decrease. Consider increasing the timeout if you experience frequent connection loss. You can monitor ZooKeeper metrics — such as request latency statistics — using JMX.
States
The ZooKeeper object transitions through different states in its lifecycle (see Figure 21-3). You can query its state at any time by using the getState() method:
public States getState()
States is an enum representing the different states that a ZooKeeper object may be in. (Despite the enum’s name, an instance of ZooKeeper may be in only one state at a time.) A newly constructed ZooKeeper instance is in the CONNECTING state while it tries to establish a connection with the ZooKeeper service. Once a connection is established, it goes into the CONNECTED state.
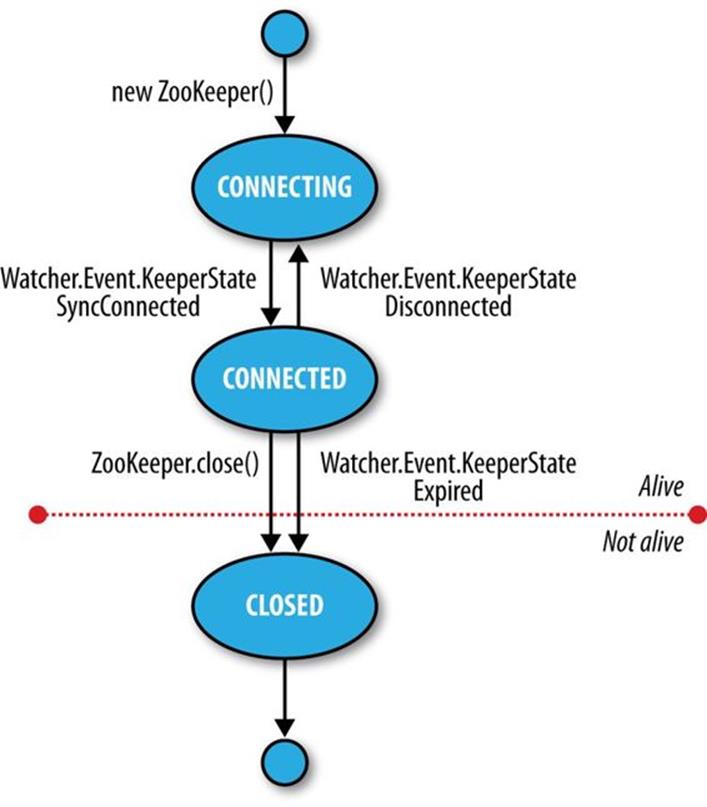
Figure 21-3. ZooKeeper state transitions
A client using the ZooKeeper object can receive notifications of the state transitions by registering a Watcher object. On entering the CONNECTED state, the watcher receives a WatchedEvent whose KeeperState value is SyncConnected.
NOTE
A ZooKeeper Watcher object serves double duty: it can be used to be notified of changes in the ZooKeeper state (as described in this section), and it can be used to be notified of changes in znodes (described in Watch triggers). The (default) watcher passed into the ZooKeeper object constructor is used for state changes, but znode changes may either use a dedicated instance ofWatcher (by passing one in to the appropriate read operation) or share the default one if using the form of the read operation that takes a Boolean flag to specify whether to use a watcher.
The ZooKeeper instance may disconnect and reconnect to the ZooKeeper service, moving between the CONNECTED and CONNECTING states. If it disconnects, the watcher receives a Disconnected event. Note that these state transitions are initiated by the ZooKeeper instance itself, and it will automatically try to reconnect if the connection is lost.
The ZooKeeper instance may transition to a third state, CLOSED, if either the close() method is called or the session times out, as indicated by a KeeperState of type Expired. Once in the CLOSED state, the ZooKeeper object is no longer considered to be alive (this can be tested using theisAlive() method on States) and cannot be reused. To reconnect to the ZooKeeper service, the client must construct a new ZooKeeper instance.
Building Applications with ZooKeeper
Having covered ZooKeeper in some depth, let’s turn back to writing some useful applications with it.
A Configuration Service
One of the most basic services that a distributed application needs is a configuration service, so that common pieces of configuration information can be shared by machines in a cluster. At the simplest level, ZooKeeper can act as a highly available store for configuration, allowing application participants to retrieve or update configuration files. Using ZooKeeper watches, it is possible to create an active configuration service, where interested clients are notified of changes in configuration.
Let’s write such a service. We make a couple of assumptions that simplify the implementation (they could be removed with a little more work). First, the only configuration values we need to store are strings, and keys are just znode paths, so we use a znode to store each key-value pair. Second, there is a single client performing updates at any one time. Among other things, this model fits with the idea of a master (such as the namenode in HDFS) that wishes to update information that its workers need to follow.
We wrap the code up in a class called ActiveKeyValueStore:
public class ActiveKeyValueStore extends ConnectionWatcher {
private static final Charset CHARSET = Charset.forName("UTF-8");
public void write(String path, String value) throws InterruptedException,
KeeperException {
Stat stat = zk.exists(path, false);
if (stat == null) {
zk.create(path, value.getBytes(CHARSET), Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT);
} else {
zk.setData(path, value.getBytes(CHARSET), -1);
}
}
}
The contract of the write() method is that a key with the given value is written to ZooKeeper. It hides the difference between creating a new znode and updating an existing znode with a new value by testing first for the znode using the exists operation and then performing the appropriate operation. The other detail worth mentioning is the need to convert the string value to a byte array, for which we just use the getBytes() method with a UTF-8 encoding.
To illustrate the use of the ActiveKeyValueStore, consider a ConfigUpdater class that updates a configuration property with a value. The listing appears in Example 21-6.
Example 21-6. An application that updates a property in ZooKeeper at random times
public class ConfigUpdater {
public static final String PATH = "/config";
private ActiveKeyValueStore store;
private Random random = new Random();
public ConfigUpdater(String hosts) throws IOException, InterruptedException {
store = new ActiveKeyValueStore();
store.connect(hosts);
}
public void run() throws InterruptedException, KeeperException {
while (true) {
String value = random.nextInt(100) + "";
store.write(PATH, value);
System.out.printf("Set %s to %s\n", PATH, value);
TimeUnit.SECONDS.sleep(random.nextInt(10));
}
}
public static void main(String[] args) throws Exception {
ConfigUpdater configUpdater = new ConfigUpdater(args[0]);
configUpdater.run();
}
}
The program is simple. A ConfigUpdater has an ActiveKeyValueStore that connects to ZooKeeper in the ConfigUpdater’s constructor. The run() method loops forever, updating the /config znode at random times with random values.
Next, let’s look at how to read the /config configuration property. First, we add a read method to ActiveKeyValueStore:
public String read(String path, Watcher watcher) throws InterruptedException,
KeeperException {
byte[] data = zk.getData(path, watcher, null/*stat*/);
return new String(data, CHARSET);
}
The getData() method of ZooKeeper takes the path, a Watcher, and a Stat object. The Stat object is filled in with values by getData() and is used to pass information back to the caller. In this way, the caller can get both the data and the metadata for a znode, although in this case, we pass a null Stat because we are not interested in the metadata.
As a consumer of the service, ConfigWatcher (see Example 21-7) creates an ActiveKeyValueStore and, after starting, calls the store’s read() method (in its displayConfig() method) to pass a reference to itself as the watcher. It displays the initial value of the configuration that it reads.
Example 21-7. An application that watches for updates of a property in ZooKeeper and prints them to the console
public class ConfigWatcher implements Watcher {
private ActiveKeyValueStore store;
public ConfigWatcher(String hosts) throws IOException, InterruptedException {
store = new ActiveKeyValueStore();
store.connect(hosts);
}
public void displayConfig() throws InterruptedException, KeeperException {
String value = store.read(ConfigUpdater.PATH, this);
System.out.printf("Read %s as %s\n", ConfigUpdater.PATH, value);
}
@Override
public void process(WatchedEvent event) {
if (event.getType() == EventType.NodeDataChanged) {
try {
displayConfig();
} catch (InterruptedException e) {
System.err.println("Interrupted. Exiting.");
Thread.currentThread().interrupt();
} catch (KeeperException e) {
System.err.printf("KeeperException: %s. Exiting.\n", e);
}
}
}
public static void main(String[] args) throws Exception {
ConfigWatcher configWatcher = new ConfigWatcher(args[0]);
configWatcher.displayConfig();
// stay alive until process is killed or thread is interrupted
Thread.sleep(Long.MAX_VALUE);
}
}
When the ConfigUpdater updates the znode, ZooKeeper causes the watcher to fire with an event type of EventType.NodeDataChanged. ConfigWatcher acts on this event in its process() method by reading and displaying the latest version of the config.
Because watches are one-time signals, we tell ZooKeeper of the new watch each time we call read() on ActiveKeyValueStore, which ensures we see future updates. We are not guaranteed to receive every update, though, because the znode may have been updated (possibly many times) during the span of time between the receipt of the watch event and the next read, and as the client has no watch registered during that period, it is not notified. For the configuration service, this is not a problem, because clients care only about the latest value of a property, as it takes precedence over previous values. However, in general you should be aware of this potential limitation.
Let’s see the code in action. Launch the ConfigUpdater in one terminal window:
% java ConfigUpdater localhost
Set /config to 79
Set /config to 14
Set /config to 78
Then launch the ConfigWatcher in another window immediately afterward:
% java ConfigWatcher localhost
Read /config as 79
Read /config as 14
Read /config as 78
The Resilient ZooKeeper Application
The first of the Fallacies of Distributed Computing states that “the network is reliable.” As they stand, our programs so far have been assuming a reliable network, so when they run on a real network, they can fail in several ways. Let’s examine some possible failure modes and what we can do to correct them so that our programs are resilient in the face of failure.
Every ZooKeeper operation in the Java API declares two types of exception in its throws clause: InterruptedException and KeeperException.
InterruptedException
An InterruptedException is thrown if the operation is interrupted. There is a standard Java mechanism for canceling blocking methods, which is to call interrupt() on the thread from which the blocking method was called. A successful cancellation will result in anInterruptedException. ZooKeeper adheres to this standard, so you can cancel a ZooKeeper operation in this way. Classes or libraries that use ZooKeeper usually should propagate the InterruptedException so that their clients can cancel their operations.[149]
An InterruptedException does not indicate a failure, but rather that the operation has been canceled, so in the configuration application example it is appropriate to propagate the exception, causing the application to terminate.
KeeperException
A KeeperException is thrown if the ZooKeeper server signals an error or if there is a communication problem with the server. For different error cases, there are various subclasses of KeeperException. For example, KeeperException.NoNodeException is a subclass of KeeperExceptionthat is thrown if you try to perform an operation on a znode that doesn’t exist.
Every subclass of KeeperException has a corresponding code with information about the type of error. For example, for KeeperException.NoNodeException, the code is KeeperException.Code.NONODE (an enum value).
There are two ways, then, to handle KeeperException: either catch KeeperException and test its code to determine what remedying action to take, or catch the equivalent KeeperException subclasses and perform the appropriate action in each catch block.
KeeperExceptions fall into three broad categories.
State exceptions
A state exception occurs when the operation fails because it cannot be applied to the znode tree. State exceptions usually happen because another process is mutating a znode at the same time. For example, a setData operation with a version number will fail with aKeeperException.BadVersionException if the znode is updated by another process first because the version number does not match. The programmer is usually aware that this kind of conflict is possible and will code to deal with it.
Some state exceptions indicate an error in the program, such as KeeperException.NoChildrenForEphemeralsException, which is thrown when trying to create a child znode of an ephemeral znode.
Recoverable exceptions
Recoverable exceptions are those from which the application can recover within the same ZooKeeper session. A recoverable exception is manifested by KeeperException.ConnectionLossException, which means that the connection to ZooKeeper has been lost. ZooKeeper will try to reconnect, and in most cases the reconnection will succeed and ensure that the session is intact.
However, ZooKeeper cannot tell if the operation that failed with a KeeperException.ConnectionLossException was applied. This is an example of partial failure (which we introduced at the beginning of the chapter). The onus is therefore on the programmer to deal with the uncertainty, and the action that should be taken depends on the application.
At this point, it is useful to make a distinction between idempotent and nonidempotent operations. An idempotent operation is one that may be applied one or more times with the same result, such as a read request or an unconditional setData. These can simply be retried.
A nonidempotent operation cannot be retried indiscriminately, as the effect of applying it multiple times is not the same as that of applying it once. The program needs a way of detecting whether its update was applied by encoding information in the znode’s pathname or its data. We discuss how to deal with failed nonidempotent operations in Recoverable exceptions, when we look at the implementation of a lock service.
Unrecoverable exceptions
In some cases, the ZooKeeper session becomes invalid — perhaps because of a timeout or because the session was closed (both of these scenarios get a KeeperException.SessionExpiredException), or perhaps because authentication failed (KeeperException.AuthFailedException). In any case, all ephemeral nodes associated with the session will be lost, so the application needs to rebuild its state before reconnecting to ZooKeeper.
A reliable configuration service
Going back to the write() method in ActiveKeyValueStore, recall that it is composed of an exists operation followed by either a create or a setData:
public void write(String path, String value) throws InterruptedException,
KeeperException {
Stat stat = zk.exists(path, false);
if (stat == null) {
zk.create(path, value.getBytes(CHARSET), Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT);
} else {
zk.setData(path, value.getBytes(CHARSET), -1);
}
}
Taken as a whole, the write() method is idempotent, so we can afford to unconditionally retry it. Here’s a modified version of the write() method that retries in a loop. It is set to try a maximum number of retries (MAX_RETRIES) and sleeps for RETRY_PERIOD_SECONDS between each attempt:
public void write(String path, String value) throws InterruptedException,
KeeperException {
int retries = 0;
while (true) {
try {
Stat stat = zk.exists(path, false);
if (stat == null) {
zk.create(path, value.getBytes(CHARSET), Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT);
} else {
zk.setData(path, value.getBytes(CHARSET), stat.getVersion());
}
return;
} catch (KeeperException.SessionExpiredException e) {
throw e;
} catch (KeeperException e) {
if (retries++ == MAX_RETRIES) {
throw e;
}
// sleep then retry
TimeUnit.SECONDS.sleep(RETRY_PERIOD_SECONDS);
}
}
}
The code is careful not to retry KeeperException.SessionExpiredException, because when a session expires, the ZooKeeper object enters the CLOSED state, from which it can never reconnect (refer to Figure 21-3). We simply rethrow the exception[150] and let the caller create a newZooKeeper instance, so that the whole write() method can be retried. A simple way to create a new instance is to create a new ConfigUpdater (which we’ve actually renamed ResilientConfigUpdater) to recover from an expired session:
public static void main(String[] args) throws Exception {
while (true) {
try {
ResilientConfigUpdater configUpdater =
new ResilientConfigUpdater(args[0]);
configUpdater.run();
} catch (KeeperException.SessionExpiredException e) {
// start a new session
} catch (KeeperException e) {
// already retried, so exit
e.printStackTrace();
break;
}
}
}
An alternative way of dealing with session expiry would be to look for a KeeperState of type Expired in the watcher (that would be the ConnectionWatcher in the example here), and create a new connection when this is detected. This way, we would just keep retrying the write()method, even if we got a KeeperException.SessionExpiredException, since the connection should eventually be reestablished. Regardless of the precise mechanics of how we recover from an expired session, the important point is that it is a different kind of failure from connection loss and needs to be handled differently.
NOTE
There’s actually another failure mode that we’ve ignored here. When the ZooKeeper object is created, it tries to connect to a ZooKeeper server. If the connection fails or times out, then it tries another server in the ensemble. If, after trying all of the servers in the ensemble, it can’t connect, then it throws an IOException. The likelihood of all ZooKeeper servers being unavailable is low; nevertheless, some applications may choose to retry the operation in a loop until ZooKeeper is available.
This is just one strategy for retry handling. There are many others, such as using exponential backoff, where the period between retries is multiplied by a constant each time.
A Lock Service
A distributed lock is a mechanism for providing mutual exclusion between a collection of processes. At any one time, only a single process may hold the lock. Distributed locks can be used for leader election in a large distributed system, where the leader is the process that holds the lock at any point in time.
NOTE
Do not confuse ZooKeeper’s own leader election with a general leader election service, which can be built using ZooKeeper primitives (and in fact, one implementation is included with ZooKeeper). ZooKeeper’s own leader election is not exposed publicly, unlike the type of general leader election service we are describing here, which is designed to be used by distributed systems that need to agree upon a master process.
To implement a distributed lock using ZooKeeper, we use sequential znodes to impose an order on the processes vying for the lock. The idea is simple: first, designate a lock znode, typically describing the entity being locked on (say, /leader); then, clients that want to acquire the lock create sequential ephemeral znodes as children of the lock znode. At any point in time, the client with the lowest sequence number holds the lock. For example, if two clients create the znodes at /leader/lock-1 and /leader/lock-2 around the same time, then the client that created/leader/lock-1 holds the lock, since its znode has the lowest sequence number. The ZooKeeper service is the arbiter of order because it assigns the sequence numbers.
The lock may be released simply by deleting the znode /leader/lock-1; alternatively, if the client process dies, it will be deleted by virtue of being an ephemeral znode. The client that created /leader/lock-2 will then hold the lock because it has the next lowest sequence number. It ensures it will be notified that it has the lock by creating a watch that fires when znodes go away.
The pseudocode for lock acquisition is as follows:
1. Create an ephemeral sequential znode named lock- under the lock znode, and remember its actual pathname (the return value of the create operation).
2. Get the children of the lock znode and set a watch.
3. If the pathname of the znode created in step 1 has the lowest number of the children returned in step 2, then the lock has been acquired. Exit.
4. Wait for the notification from the watch set in step 2, and go to step 2.
The herd effect
Although this algorithm is correct, there are some problems with it. The first problem is that this implementation suffers from the herd effect. Consider hundreds or thousands of clients, all trying to acquire the lock. Each client places a watch on the lock znode for changes in its set of children. Every time the lock is released or another process starts the lock acquisition process, the watch fires, and every client receives a notification. The “herd effect” refers to a large number of clients being notified of the same event when only a small number of them can actually proceed. In this case, only one client will successfully acquire the lock, and the process of maintaining and sending watch events to all clients causes traffic spikes, which put pressure on the ZooKeeper servers.
To avoid the herd effect, the condition for notification needs to be refined. The key observation for implementing locks is that a client needs to be notified only when the child znode with the previous sequence number goes away, not when any child znode is deleted (or created). In our example, if clients have created the znodes /leader/lock-1, /leader/lock-2, and /leader/lock-3, then the client holding /leader/lock-3 needs to be notified only when /leader/lock-2 disappears. It does not need to be notified when /leader/lock-1 disappears or when a new znode,/leader/lock-4, is added.
Recoverable exceptions
Another problem with the lock algorithm as it stands is that it doesn’t handle the case when the create operation fails due to connection loss. Recall that in this case we do not know whether the operation succeeded or failed. Creating a sequential znode is a nonidempotent operation, so we can’t simply retry, because if the first create had succeeded we would have an orphaned znode that would never be deleted (until the client session ended, at least). Deadlock would be the unfortunate result.
The problem is that after reconnecting, the client can’t tell whether it created any of the child znodes. By embedding an identifier in the znode name, if it suffers a connection loss, it can check to see whether any of the children of the lock node have its identifier in their names. If a child contains its identifier, it knows that the create operation succeeded, and it shouldn’t create another child znode. If no child has the identifier in its name, the client can safely create a new sequential child znode.
The client’s session identifier is a long integer that is unique for the ZooKeeper service and therefore ideal for the purpose of identifying a client across connection loss events. The session identifier can be obtained by calling the getSessionId() method on the ZooKeeper Java class.
The ephemeral sequential znode should be created with a name of the form lock-<sessionId>-, so that when the sequence number is appended by ZooKeeper, the name becomes lock-<sessionId>-<sequenceNumber>. The sequence numbers are unique to the parent, not to the name of the child, so this technique allows the child znodes to identify their creators as well as impose an order of creation.
Unrecoverable exceptions
If a client’s ZooKeeper session expires, the ephemeral znode created by the client will be deleted, effectively relinquishing the lock (or at least forfeiting the client’s turn to acquire the lock). The application using the lock should realize that it no longer holds the lock, clean up its state, and then start again by creating a new lock object and trying to acquire it. Notice that it is the application that controls this process, not the lock implementation, since it cannot second-guess how the application needs to clean up its state.
Implementation
Accounting for all of the failure modes is nontrivial, so implementing a distributed lock correctly is a delicate matter. ZooKeeper comes with a production-quality lock implementation in Java called WriteLock that is very easy for clients to use.
More Distributed Data Structures and Protocols
There are many distributed data structures and protocols that can be built with ZooKeeper, such as barriers, queues, and two-phase commit. One interesting thing to note is that these are synchronous protocols, even though we use asynchronous ZooKeeper primitives (such as notifications) to build them.
The ZooKeeper website describes several such data structures and protocols in pseudocode. ZooKeeper comes with implementations of some of these standard recipes (including locks, leader election, and queues); they can be found in the recipes directory of the distribution.
The Apache Curator project also provides an extensive set of ZooKeeper recipes, as well as a simplified ZooKeeper client.
BookKeeper and Hedwig
BookKeeper is a highly available and reliable logging service. It can be used to provide write-ahead logging, which is a common technique for ensuring data integrity in storage systems. In a system using write-ahead logging, every write operation is written to the transaction log before it is applied. Using this procedure, we don’t have to write the data to permanent storage after every write operation, because in the event of a system failure, the latest state may be recovered by replaying the transaction log for any writes that were not applied.
BookKeeper clients create logs called ledgers, and each record appended to a ledger is called a ledger entry, which is simply a byte array. Ledgers are managed by bookies, which are servers that replicate the ledger data. Note that ledger data is not stored in ZooKeeper; only metadata is.
Traditionally, the challenge has been to make systems that use write-ahead logging robust in the face of failure of the node writing the transaction log. This is usually done by replicating the transaction log in some manner. HDFS high availability, described , uses a group of journal nodes to provide a highly available edit log. Although it is similar to BookKeeper, it is a dedicated service written for HDFS, and it doesn’t use ZooKeeper as the coordination engine.
Hedwig is a topic-based ipublish-subscribe system built on BookKeeper. Thanks to its ZooKeeper underpinnings, Hedwig is a highly available service and guarantees message delivery even if subscribers are offline for extended periods of time.
BookKeeper is a ZooKeeper subproject, and you can find more information on how to use it, as well as Hedwig, at http://zookeeper.apache.org/bookkeeper/.
ZooKeeper in Production
In production, you should run ZooKeeper in replicated mode. Here, we will cover some of the considerations for running an ensemble of ZooKeeper servers. However, this section is not exhaustive, so you should consult the ZooKeeper Administrator’s Guide for detailed, up-to-date instructions, including supported platforms, recommended hardware, maintenance procedures, dynamic reconfiguration (to change the servers in a running ensemble), and configuration properties.
Resilience and Performance
ZooKeeper machines should be located to minimize the impact of machine and network failure. In practice, this means that servers should be spread across racks, power supplies, and switches, so that the failure of any one of these does not cause the ensemble to lose a majority of its servers.
For applications that require low-latency service (on the order of a few milliseconds), it is important to run all the servers in an ensemble in a single data center. Some use cases don’t require low-latency responses, however, which makes it feasible to spread servers across data centers (at least two per data center) for extra resilience. Example applications in this category are leader election and distributed coarse-grained locking, both of which have relatively infrequent state changes, so the overhead of a few tens of milliseconds incurred by inter-data-center messages is not significant relative to the overall functioning of the service.
NOTE
ZooKeeper has the concept of an observer node, which is like a non-voting follower. Because they do not participate in the vote for consensus during write requests, observers allow a ZooKeeper cluster to improve read performance without hurting write performance.[151] Observers can be used to good advantage to allow a ZooKeeper cluster to span data centers without impacting latency as much as regular voting followers. This is achieved by placing the voting members in one data center and observers in the other.
ZooKeeper is a highly available system, and it is critical that it can perform its functions in a timely manner. Therefore, ZooKeeper should run on machines that are dedicated to ZooKeeper alone. Having other applications contend for resources can cause ZooKeeper’s performance to degrade significantly.
Configure ZooKeeper to keep its transaction log on a different disk drive from its snapshots. By default, both go in the directory specified by the dataDir property, but if you specify a location for dataLogDir, the transaction log will be written there. By having its own dedicated device (not just a partition), a ZooKeeper server can maximize the rate at which it writes log entries to disk, which it does sequentially without seeking. Because all writes go through the leader, write throughput does not scale by adding servers, so it is crucial that writes are as fast as possible.
If the process swaps to disk, performance will be adversely affected. This can be avoided by setting the Java heap size to less than the amount of unused physical memory on the machine. From its configuration directory, the ZooKeeper scripts will source a file called java.env, which can be used to set the JVMFLAGS environment variable to specify the heap size (and any other desired JVM arguments).
Configuration
Each server in the ensemble of ZooKeeper servers has a numeric identifier that is unique within the ensemble and must fall between 1 and 255. The server number is specified in plain text in a file named myid in the directory specified by the dataDir property.
Setting each server number is only half of the job. We also need to give every server all the identities and network locations of the others in the ensemble. The ZooKeeper configuration file must include a line for each server, of the form:
server.n=hostname:port:port
The value of n is replaced by the server number. There are two port settings: the first is the port that followers use to connect to the leader, and the second is used for leader election. Here is a sample configuration for a three-machine replicated ZooKeeper ensemble:
tickTime=2000
dataDir=/disk1/zookeeper
dataLogDir=/disk2/zookeeper
clientPort=2181
initLimit=5
syncLimit=2
server.1=zookeeper1:2888:3888
server.2=zookeeper2:2888:3888
server.3=zookeeper3:2888:3888
Servers listen on three ports: 2181 for client connections; 2888 for follower connections, if they are the leader; and 3888 for other server connections during the leader election phase. When a ZooKeeper server starts up, it reads the myid file to determine which server it is, and then reads the configuration file to determine the ports it should listen on and to discover the network addresses of the other servers in the ensemble.
Clients connecting to this ZooKeeper ensemble should use zookeeper1:2181,zookeeper2:2181,zookeeper3:2181 as the host string in the constructor for the ZooKeeper object.
In replicated mode, there are two extra mandatory properties: initLimit and syncLimit, both measured in multiples of tickTime.
initLimit is the amount of time to allow for followers to connect to and sync with the leader. If a majority of followers fail to sync within this period, the leader renounces its leadership status and another leader election takes place. If this happens often (and you can discover if this is the case because it is logged), it is a sign that the setting is too low.
syncLimit is the amount of time to allow a follower to sync with the leader. If a follower fails to sync within this period, it will restart itself. Clients that were attached to this follower will connect to another one.
These are the minimum settings needed to get up and running with a cluster of ZooKeeper servers. There are, however, more configuration options, particularly for tuning performance, which are documented in the ZooKeeper Administrator’s Guide.
Further Reading
For more in-depth information about ZooKeeper, see ZooKeeper by Flavio Junqueira and Benjamin Reed (O’Reilly, 2013).
[140] This is the message of Jim Waldo et al. in “A Note on Distributed Computing” (Sun Microsystems, November 1994). Distributed programming is fundamentally different from local programming, and the differences cannot simply be papered over.
[141] Detailed benchmarks are available in the excellent paper “ZooKeeper: Wait-free coordination for Internet-scale systems,” by Patrick Hunt et al. (USENIX Annual Technology Conference, 2010).
[142] For a replicated ZooKeeper service, this parameter is the comma-separated list of servers (host and optional port) in the ensemble.
[143] It is conventional (but not required) to have a trailing dash on pathnames for sequential nodes, to make their sequence numbers easy to read and parse (by the application).
[144] Except for callbacks for connection events, which do not need reregistration.
[145] Leslie Lamport, “Paxos Made Simple,” ACM SIGACT News December 2001.
[146] Zab is described in Benjamin Reed and Flavio Junqueira’s “A simple totally ordered broadcast protocol,” LADIS ’08 Proceedings of the 2nd Workshop on Large-Scale Distributed Systems and Middleware, 2008.
[147] Mike Burrows, “The Chubby Lock Service for Loosely-Coupled Distributed Systems,” November 2006.
[148] It is possible to configure ZooKeeper so that the leader does not accept client connections. In this case, its only job is to coordinate updates. Do this by setting the leaderServes property to no. This is recommended for ensembles of more than three servers.
[149] For more detail, see the excellent article “Java theory and practice: Dealing with InterruptedException” by Brian Goetz (IBM, May 2006).
[150] Another way of writing the code would be to have a single catch block, just for KeeperException, and a test to see whether its code has the value KeeperException.Code.SESSIONEXPIRED. They both behave in the same way, so which method you use is simply a matter of style.
[151] This is discussed in more detail in “Observers: Making ZooKeeper Scale Even Further” by Henry Robinson (Cloudera, December 2009).
All materials on the site are licensed Creative Commons Attribution-Sharealike 3.0 Unported CC BY-SA 3.0 & GNU Free Documentation License (GFDL)
If you are the copyright holder of any material contained on our site and intend to remove it, please contact our site administrator for approval.
© 2016-2026 All site design rights belong to S.Y.A.